Изображение от редактора
Основные выводы
- Стьюдент-критерий — это статистический критерий, который можно использовать для определения того, существует ли значительная разница между средними значениями двух независимых выборок данных.
- Мы показываем, как можно применять t-критерий, используя набор данных iris и библиотеку Python Scipy.
Стьюдент-критерий — это статистический критерий, который можно использовать для определения того, существует ли значительная разница между средними значениями двух независимых выборок данных. В этом руководстве мы проиллюстрируем самую базовую версию t-критерия, для которого мы будем предполагать, что две выборки имеют равные отклонения. Другие расширенные версии t-критерия включают t-критерий Уэлча, который является адаптацией t-критерия и является более надежным, когда две выборки имеют неравные дисперсии и, возможно, неравные размеры выборки.
Статистика t или t-значение рассчитывается следующим образом:
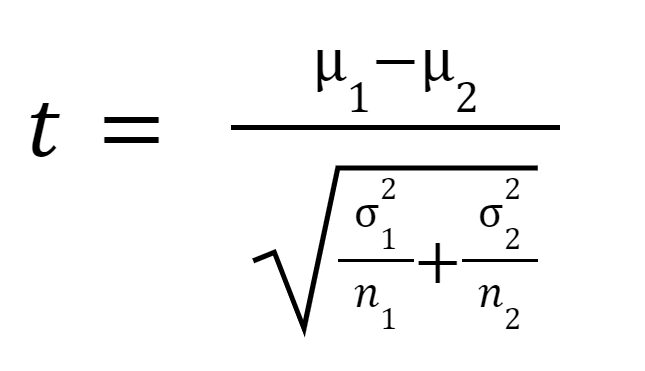
в котором
среднее значение выборки 1,
среднее значение выборки 2,
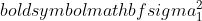 - дисперсия выборки 1,
- дисперсия выборки 1, 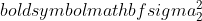 - дисперсия выборки 2,
- дисперсия выборки 2, 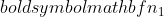 - размер выборки выборки 1, и
- размер выборки выборки 1, и 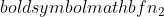 - размер выборки выборки 2.
- размер выборки выборки 2.
Чтобы проиллюстрировать использование t-теста, мы покажем простой пример с использованием набора данных радужной оболочки. Предположим, мы наблюдаем две независимые выборки, например, длину чашелистиков цветков, и рассматриваем, были ли эти две выборки взяты из одной и той же популяции (например, одного вида цветка или двух видов с одинаковыми характеристиками чашелистиков) или из двух разных популяций.
Стьюдентный критерий определяет разницу между средними арифметическими двух выборок. Значение p количественно определяет вероятность получения наблюдаемых результатов при условии, что нулевая гипотеза (выборки взяты из совокупности с одинаковыми средними значениями) верна. Значение p, превышающее выбранный порог (например, 5% или 0.05), указывает на то, что наше наблюдение не так уж маловероятно, что оно произошло случайно. Поэтому мы принимаем нулевую гипотезу о равных средних значениях населения. Если p-значение меньше нашего порога, то у нас есть доказательства против нулевой гипотезы о равных средних значениях населения.
Ввод Т-теста
Входные данные или параметры, необходимые для выполнения t-теста:
- Два массива a и b содержащий данные для образца 1 и образца 2
Результаты Т-теста
Стьюдент-тест возвращает следующее:
- Рассчитанная t-статистика
- Р-значение
Импортировать необходимые библиотеки
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Загрузить набор данных Iris
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Вычислить выборочные средние и выборочные дисперсии
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Реализовать t-тест
stats.ttest_ind(a_1, b_1, equal_var = False)
Результат
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
Результат
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
Результат
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Наблюдения
Мы наблюдаем, что использование «true» или «false» для параметра «equal-var» не сильно меняет результаты t-теста. Мы также наблюдаем, что изменение порядка выборочных массивов a_1 и b_1 дает отрицательное значение t-теста, но не меняет величину значения t-теста, как ожидалось. Поскольку рассчитанное значение p намного превышает пороговое значение 0.05, мы можем отклонить нулевую гипотезу о том, что разница между средними значениями выборки 1 и выборки 2 значительна. Это показывает, что длины чашелистиков для образца 1 и образца 2 были взяты из одних и тех же данных о популяции.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Вычислить выборочные средние и выборочные дисперсии
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Реализовать t-тест
stats.ttest_ind(a_1, b_1, equal_var = False)
Результат
stats.ttest_ind(a_1, b_1, equal_var = False)Наблюдения
Мы наблюдаем, что использование выборок разного размера существенно не меняет t-статистику и p-значение.
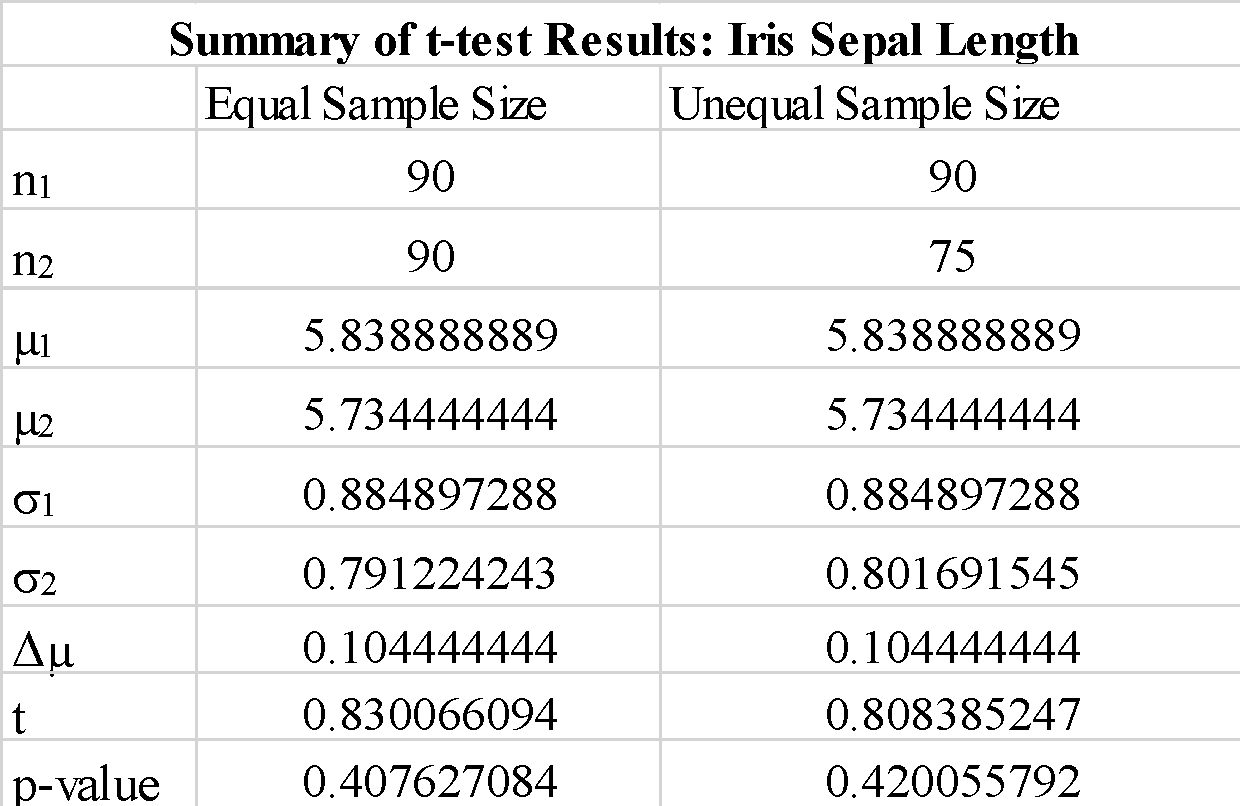
Таким образом, мы показали, как можно реализовать простой t-тест с использованием библиотеки scipy в python.
Бенджамин О. Тайо является физиком, преподавателем науки о данных и писателем, а также владельцем DataScienceHub. Ранее Бенджамин преподавал инженерное дело и физику в Университете Центральной Оклахомы, Университете Гранд-Каньон и Университете штата Питтсбург.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- Принять
- продвинутый
- против
- и
- прикладной
- основной
- Вениамин
- между
- рассчитанный
- центральный
- шанс
- изменение
- характеристика
- выбранный
- принимая во внимание
- может
- данным
- наука о данных
- Наборы данных
- Определять
- разница
- различный
- обращается
- Проект и
- , поскольку большинство сенаторов
- пример
- ожидаемый
- цветок
- после
- следующим образом
- от
- Как
- HTTPS
- в XNUMX году
- Импортировать
- in
- включают
- независимые
- указывает
- КДнаггетс
- больше
- Библиотека
- Matplotlib
- означает
- БОЛЕЕ
- самых
- необходимо
- отрицательный
- NumPy
- наблюдать
- получение
- произошло
- Оклахома
- заказ
- Другое
- владелец
- параметр
- параметры
- выполнения
- Физика
- Pittsburgh
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- население
- популяции
- предварительно
- вероятность
- Питон
- складская
- Итоги
- Возвращает
- то же
- Наука
- показывать
- показанный
- Шоу
- значительный
- существенно
- аналогичный
- просто
- с
- Размер
- Размеры
- меньше
- So
- Область
- статистический
- Статистика
- РЕЗЮМЕ
- Обучение
- тестXNUMX
- Ассоциация
- следовательно
- порог
- в
- правда
- учебник
- использование
- ценностное
- версия
- будь то
- который
- будете
- писатель
- доходность
- зефирнет





