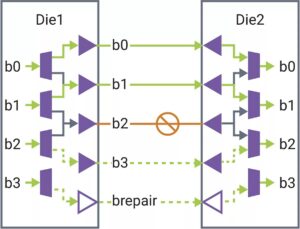
Технический документ под названием «Эффективное решение для вывода LLM на графическом процессоре Intel» был опубликован исследователями корпорации Intel.
Абстрактные:
«Модели большого языка (LLM) на основе преобразователей широко используются во многих областях, и эффективность вывода LLM становится горячей темой в реальных приложениях. Однако LLM обычно имеют сложную структуру модели с большим количеством операций и выполняют вывод в авторегрессионном режиме, что делает разработку системы с высокой эффективностью сложной задачей.
В этой статье мы предлагаем эффективное решение LLM-вывода с низкой задержкой и высокой пропускной способностью. Во-первых, мы упрощаем уровень декодера LLM, объединяя перемещение данных и поэлементные операции, чтобы уменьшить частоту доступа к памяти и снизить задержку системы. Мы также предлагаем политику сегментного кэширования KV, позволяющую хранить ключ/значение токенов запроса и ответа в отдельной физической памяти для эффективного управления памятью устройства, помогая увеличить размер пакета времени выполнения и повысить пропускную способность системы. Настраиваемое ядро Scaled-Dot-Product-Attention разработано в соответствии с нашей политикой объединения на основе решения сегментного кэша KV. Мы реализуем наше решение для вывода LLM на графическом процессоре Intel и публикуем его публично. По сравнению со стандартной реализацией HuggingFace предлагаемое решение обеспечивает до 7 раз меньшую задержку токена и в 27 раз более высокую пропускную способность для некоторых популярных LLM на графическом процессоре Intel».
Найдите технический документ здесь. Опубликовано в декабре 2023 г. (препринт).
У, Хуэй, И Ган, Фэн Юань, Цзин Ма, Вэй Чжу, Ютао Сюй, Хун Чжу, Юхуа Чжу, Сяоли Лю и Цзинхуэй Гу. «Эффективное решение для вывода LLM на графическом процессоре Intel». Препринт arXiv arXiv:2401.05391 (2023 г.).
Связанные Чтение
Вывод LLM по процессорам (Intel)
Технический документ под названием «Эффективный вывод LLM о процессорах» был опубликован исследователями Intel.
Искусственный интеллект стремится к пределу
По мере распространения ИИ в новых приложениях обработка выводов и некоторое обучение переносится на устройства меньшего размера.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://semiengineering.com/llm-inference-on-gpus-intel/
- :является
- $UP
- 2023
- a
- доступ
- Достигает
- AI
- причислены
- an
- и
- Приложения
- МЫ
- AS
- At
- основанный
- становится
- было
- не являетесь
- by
- кэш
- сложные
- сравненный
- КОРПОРАЦИЯ
- подгонянный
- данным
- Декабрь
- Проект
- предназначенный
- устройство
- Устройства
- Эффективный
- затрат
- эффективный
- увеличивать
- Поля
- Что касается
- частота
- фьюзинг
- слияние
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- Графические процессоры
- Есть
- помощь
- здесь
- High
- высший
- Hong
- ГОРЯЧИЙ
- Однако
- HTTPS
- ОбниматьЛицо
- осуществлять
- реализация
- улучшать
- in
- Intel
- IT
- JPG
- Сохранить
- язык
- большой
- Задержка
- слой
- LLM
- Низкий
- ниже
- Создание
- управление
- многих
- массивный
- Совпадение
- Память
- режим
- модель
- Модели
- движение
- Новые
- of
- on
- открытый
- Операционный отдел
- наши
- бумага & картон
- выполнять
- физический
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- политика
- Популярное
- предлагает
- предложило
- публично
- публиковать
- опубликованный
- толкнул
- скачки
- реальные
- уменьшить
- запросить
- исследователи
- ответ
- сегмент
- отдельный
- упростить
- Размер
- меньше
- Решение
- некоторые
- Спреды
- стандарт
- Структура
- система
- Сложность задачи
- Технический
- Ассоциация
- этой
- пропускная способность
- титулованный
- в
- знак
- Лексемы
- тема
- Обучение
- используемый
- обычно
- законопроект
- we
- широко
- юань
- зефирнет