
20 сентября, 2023
Фундаментальные модели (ФМ) знаменуют начало новой эры в машинное обучение (ML) и искусственный интеллект (ИИ), что ведет к более быстрой разработке искусственного интеллекта, который можно адаптировать к широкому спектру последующих задач и точно настроить для множества приложений.
Учитывая растущую важность обработки данных во время выполнения работы, обслуживание моделей ИИ на периферии предприятия позволяет делать прогнозы практически в реальном времени, соблюдая при этом требования суверенитета данных и конфиденциальности. Объединив IBM-ватсонкс Возможности платформы данных и искусственного интеллекта для FM с периферийными вычислениями позволяют предприятиям запускать рабочие нагрузки искусственного интеллекта для точной настройки FM и получения логических выводов на периферии операционной системы. Это позволяет предприятиям масштабировать развертывания ИИ на периферии, сокращая время и затраты на развертывание и ускоряя время отклика.
Обязательно ознакомьтесь со всеми статьями этой серии статей о периферийных вычислениях:
Что такое базовые модели?
Фундаментальные модели (FM), которые обучаются на широком наборе неразмеченных данных в любом масштабе, стимулируют современные приложения искусственного интеллекта (ИИ). Их можно адаптировать к широкому спектру последующих задач и точно настроить для множества приложений. Современные модели ИИ, выполняющие конкретные задачи в одной области, уступают место FM, поскольку они учатся более широко и работают в разных областях и задачах. Как следует из названия, FM может стать основой для многих приложений модели ИИ.
FM решают две ключевые проблемы, которые мешают предприятиям масштабировать внедрение ИИ. Во-первых, предприятия производят огромное количество неразмеченных данных, лишь часть из которых помечена для обучения моделей ИИ. Во-вторых, эта задача по маркировке и аннотированию чрезвычайно трудоемка и часто требует нескольких сотен часов времени эксперта в данной области (SME). Это делает масштабирование различных сценариев использования непомерно дорогостоящим, поскольку для этого потребуются армии МСП и экспертов по данным. Принимая огромные объемы неразмеченных данных и используя методы самоконтроля для обучения моделей, менеджеры по управлению устранили эти узкие места и открыли путь для широкомасштабного внедрения ИИ на предприятии. Эти огромные объемы данных, которые существуют в каждом бизнесе, ждут, чтобы их высвободили и позволили получить ценную информацию.
Что такое большие языковые модели?
Большие языковые модели (LLM) — это класс фундаментальных моделей (FM), которые состоят из слоев нейронные сети которые были обучены на этих огромных объемах неразмеченных данных. Они используют алгоритмы самоконтроля обучения для выполнения различных задач. обработка естественного языка (НЛП) задачи аналогично тому, как люди используют язык (см. рисунок 1).
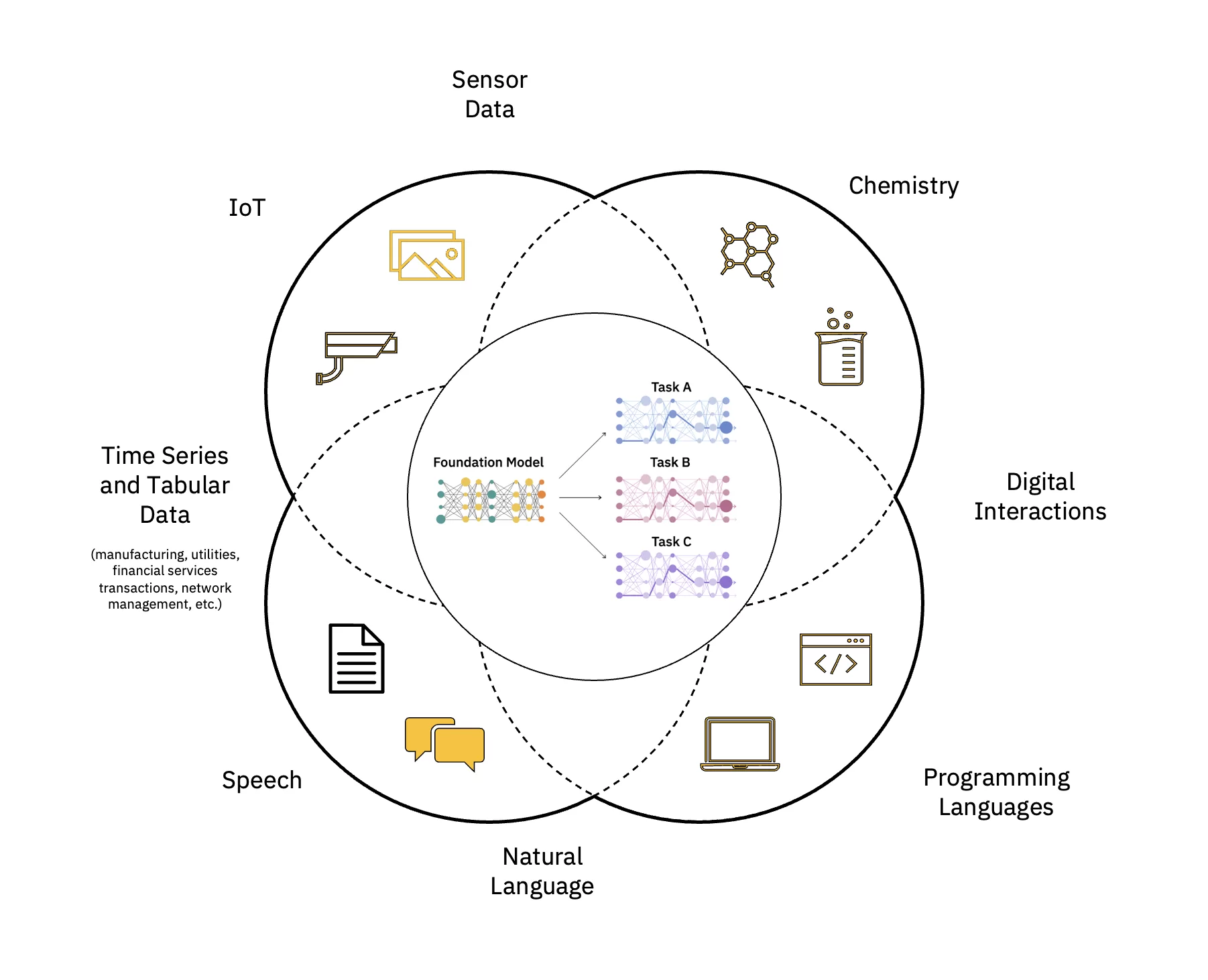
Масштабируйте и ускоряйте воздействие ИИ
Существует несколько шагов для создания и развертывания базовой модели (FM). К ним относятся прием данных, выбор данных, предварительная обработка данных, предварительное обучение FM, настройка модели для одной или нескольких последующих задач, обработка выводов, а также управление данными и моделями искусственного интеллекта и управление жизненным циклом - все это можно описать как ФМОпс.
Чтобы помочь во всем этом, IBM предлагает предприятиям необходимые инструменты и возможности для использования возможностей этих FM через IBM-ватсонкс, готовая к использованию ИИ и платформа данных, предназначенная для увеличения влияния ИИ на предприятие. IBM watsonx состоит из следующего:
- IBM watsonx.ai приносит новые генеративный ИИ возможностей, основанных на FM и традиционном машинном обучении (ML), в мощную студию, охватывающую жизненный цикл ИИ.
- IBM watsonx.data — это специализированное хранилище данных, построенное на открытой архитектуре Lakehouse для масштабирования рабочих нагрузок ИИ для всех ваших данных в любом месте.
- IBM watsonx.governance — это комплексный автоматизированный набор инструментов для управления жизненным циклом ИИ, созданный для обеспечения ответственных, прозрачных и объяснимых рабочих процессов ИИ.
Другим ключевым вектором является растущая важность вычислений на периферии предприятия, например, на промышленных объектах, производственных площадках, розничных магазинах, периферийных площадках телекоммуникационных компаний и т. д. В частности, ИИ на периферии предприятия позволяет обрабатывать данные, где выполняется работа для анализ практически в реальном времени. Периферия предприятия — это место, где генерируются огромные объемы корпоративных данных и где искусственный интеллект может предоставить ценную, своевременную и полезную бизнес-информацию.
Обслуживание моделей ИИ на периферии позволяет делать прогнозы практически в реальном времени, соблюдая при этом требования суверенитета данных и конфиденциальности. Это значительно снижает задержку, часто связанную со сбором, передачей, преобразованием и обработкой данных контроля. Работа на периферии позволяет нам защитить конфиденциальные корпоративные данные и сократить затраты на передачу данных за счет более быстрого реагирования.
Однако масштабирование развертываний ИИ на периферии — непростая задача на фоне проблем, связанных с данными (неоднородность, объем и нормативные требования) и ограниченными ресурсами (вычисления, сетевое подключение, хранение и даже ИТ-навыки). В общих чертах их можно разделить на две категории:
- Время/стоимость развертывания: Каждое развертывание состоит из нескольких уровней аппаратного и программного обеспечения, которые необходимо установить, настроить и протестировать перед развертыванием. Сегодня специалисту по обслуживанию может потребоваться до недели или двух для установки. в каждом месте, серьезно ограничивая скорость и экономичность масштабирования развертываний в масштабах организации.
- Управление дня-2: Огромное количество развернутых периферийных устройств и географическое расположение каждого развертывания часто могут сделать непомерно дорогим предоставление локальной ИТ-поддержки в каждом месте для мониторинга, обслуживания и обновления этих развертываний.
Развертывания Edge AI
IBM разработала периферийную архитектуру, которая решает эти проблемы, предлагая интегрированную модель аппаратного и программного обеспечения (HW/SW) для периферийных развертываний ИИ. Он состоит из нескольких ключевых парадигм, которые помогают масштабировать развертывание ИИ:
- Автоматическое предоставление всего стека программного обеспечения на основе политик.
- Непрерывный мониторинг состояния периферийной системы
- Возможности управления и распространения обновлений программного обеспечения, безопасности и конфигурации в многочисленные периферийные местоположения — и все это из центрального облачного местоположения для управления со второго дня.
Распределенная звездообразная архитектура может использоваться для масштабирования корпоративных развертываний искусственного интеллекта на периферии, при этом центральное облако или корпоративный центр обработки данных действует как концентратор, а периферийное устройство выступает в качестве периферийного местоположения.. Эта звездообразная модель, распространяющаяся на гибридные облачные и периферийные среды, лучше всего иллюстрирует баланс, необходимый для оптимального использования ресурсов, необходимых для операций FM (см. рис. 2).
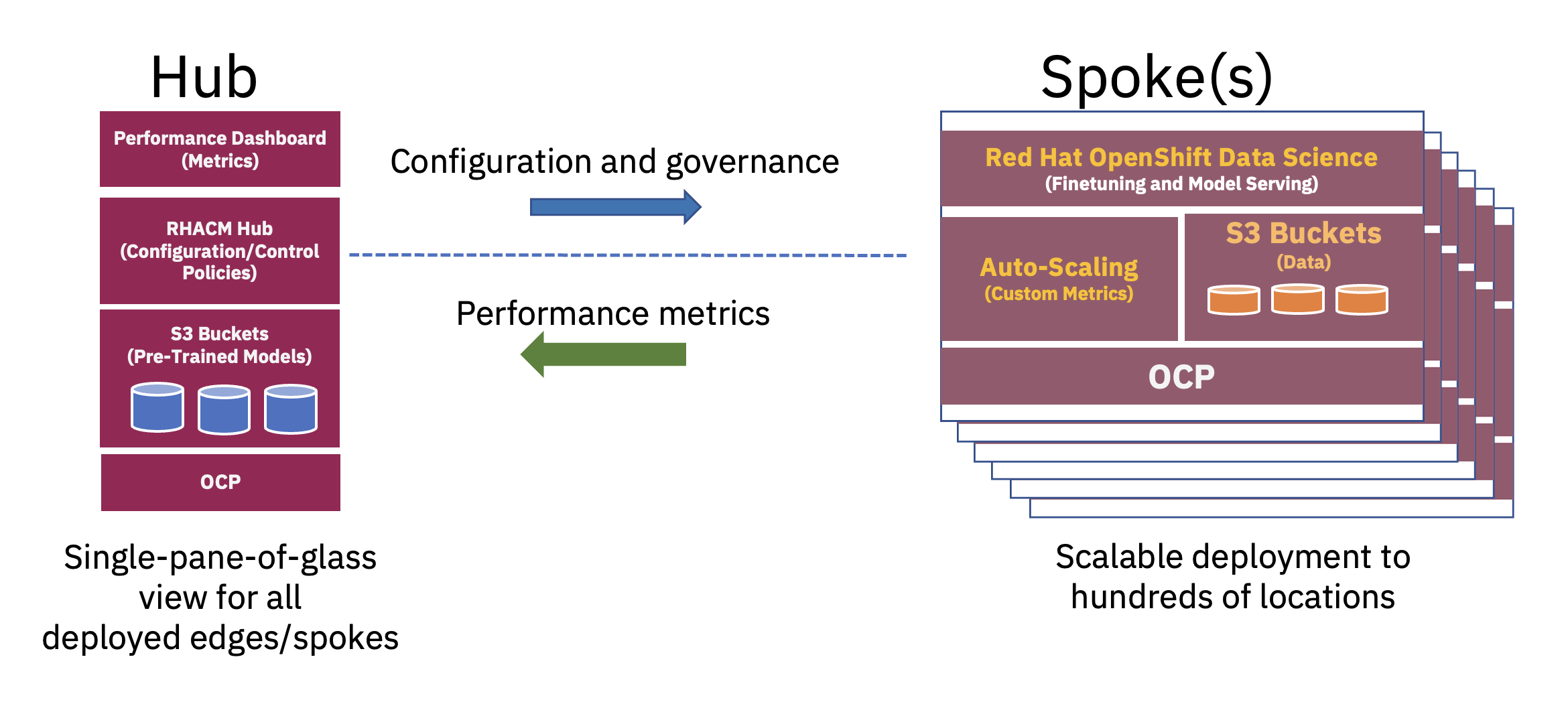
Предварительное обучение этих базовых моделей большого языка (LLM) и других типов базовых моделей с использованием методов самоконтроля на огромных неразмеченных наборах данных часто требует значительных вычислительных ресурсов (GPU), и его лучше всего выполнять в хабе. Практически безграничные вычислительные ресурсы и большие массивы данных, часто хранящиеся в облаке, позволяют предварительно обучать модели с большими параметрами и постоянно повышать точность этих базовых базовых моделей.
С другой стороны, настройка этих базовых FM для последующих задач, для которых требуется всего лишь несколько десятков или сотен помеченных выборок данных и обслуживания выводов, может быть выполнена с использованием всего лишь нескольких графических процессоров на границе предприятия. Это позволяет конфиденциальным помеченным данным (или корпоративным данным) безопасно оставаться в операционной среде предприятия, а также снижает затраты на передачу данных.
Используя комплексный подход к развертыванию приложений на периферии, специалист по данным может выполнять точную настройку, тестирование и развертывание моделей. Этого можно добиться в единой среде, сократив при этом жизненный цикл разработки для предоставления конечным пользователям новых моделей ИИ. Такие платформы, как Red Hat OpenShift Data Science (RHODS) и недавно анонсированная Red Hat OpenShift AI, предоставляют инструменты для быстрой разработки и развертывания готовых к производству моделей ИИ в распределенное облако и периферийные среды.
Наконец, обслуживание точно настроенной модели ИИ на периферии предприятия значительно снижает задержку, часто связанную со сбором, передачей, преобразованием и обработкой данных. Отделение предварительного обучения в облаке от точной настройки и обработки логических выводов на периферии снижает общие эксплуатационные затраты за счет сокращения требуемого времени и затрат на перемещение данных, связанных с любой задачей вывода (см. рис. 3).
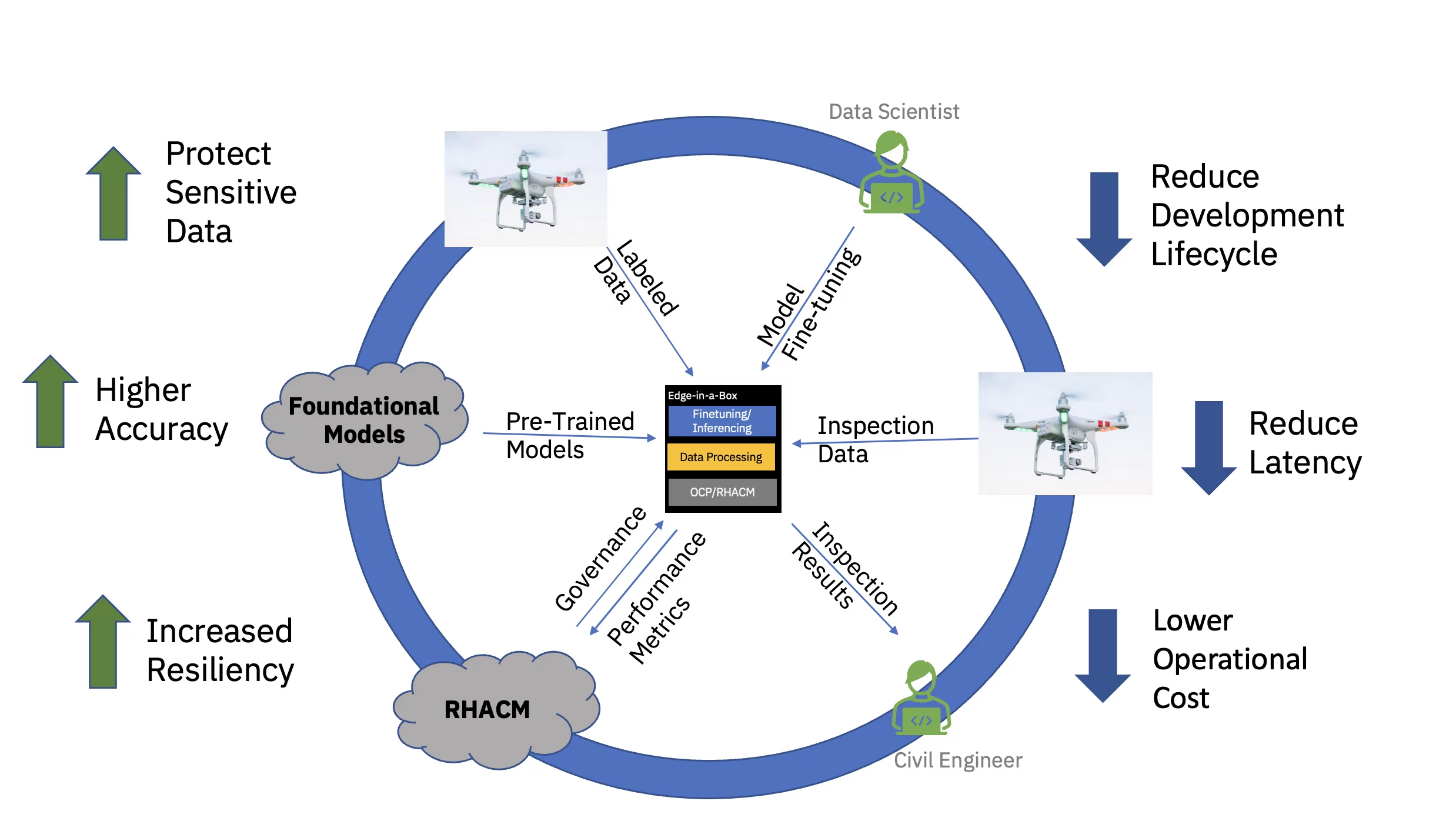
Чтобы продемонстрировать это ценностное предложение от начала до конца, образцовая базовая модель для гражданской инфраструктуры на основе преобразователя видения (предварительно обученная с использованием общедоступных и пользовательских наборов отраслевых данных) была точно настроена и развернута для вывода на трехузловой границе. (спицевый) кластер. Программный стек включал в себя Red Hat OpenShift Container Platform и Red Hat OpenShift Data Science. Этот пограничный кластер также был подключен к экземпляру хаба Red Hat Advanced Cluster Management for Kubernetes (RHACM), работающему в облаке.
Автоматическая подготовка
Автоматическая подготовка на основе политик осуществлялась с помощью Red Hat Advanced Cluster Management for Kubernetes (RHACM) с помощью политик и тегов размещения, которые привязывают определенные пограничные кластеры к набору программных компонентов и конфигураций. Эти программные компоненты, охватывающие весь стек и охватывающие вычисления, хранилище, сеть и рабочую нагрузку искусственного интеллекта, были установлены с использованием различных операторов OpenShift, предоставления необходимых сервисов приложений и корзины S3 (хранилище).
Предварительно обученная базовая модель (FM) для гражданской инфраструктуры была точно настроена с помощью Jupyter Notebook в Red Hat OpenShift Data Science (RHODS) с использованием размеченных данных для классификации шести типов дефектов, обнаруженных на бетонных мостах. Обработка вывода этого точно настроенного FM также была продемонстрирована с использованием сервера Triton. Кроме того, мониторинг работоспособности этой периферийной системы стал возможен благодаря агрегированию показателей наблюдаемости аппаратных и программных компонентов через Prometheus на центральную панель управления RHACM в облаке. Предприятия гражданской инфраструктуры могут развернуть эти FM в своих периферийных местоположениях и использовать снимки дронов для обнаружения дефектов практически в реальном времени, что ускоряет время получения аналитической информации и снижает затраты на перемещение больших объемов данных высокой четкости в облако и из него.
Обзор
Объединяя IBM-ватсонкс Возможности платформы данных и искусственного интеллекта для базовых моделей (FM) с готовым устройством позволяют предприятиям запускать рабочие нагрузки искусственного интеллекта для точной настройки FM и получения логических выводов на операционной периферии. Это устройство готово к работе со сложными сценариями использования и создает комплексную структуру для централизованного управления, автоматизации и самообслуживания. Развертывание Edge FM можно сократить с недель до часов, обеспечивая повторяемый успех, более высокую отказоустойчивость и безопасность.
Узнайте больше о базовых моделях
Обязательно ознакомьтесь со всеми статьями этой серии статей о периферийных вычислениях:
Еще от Облака




- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :имеет
- :является
- :нет
- :куда
- $UP
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- О нас
- ускорять
- доступ
- выполнено
- точность
- приобретение
- через
- акты
- адаптированный
- Дополнительно
- адрес
- адреса
- Принятие
- продвинутый
- достижения
- Реклама
- AI
- Принятие AI
- AI модели
- Платформа AI
- помощь
- алгоритмы
- Все
- позволять
- позволяет
- причислены
- Среди
- количество
- суммы
- amp
- an
- анализ
- аналитика
- и
- объявило
- любой
- откуда угодно
- Применение
- Приложения
- подхода
- архитектура
- МЫ
- массив
- гайд
- искусственный
- искусственный интеллект
- Искусственный интеллект (AI)
- AS
- связанный
- At
- автор
- Автоматизированный
- автоматизация
- доступен
- Проспект
- назад
- Баланс
- Банка
- Банки
- Использование темпера с изогнутым основанием
- BE
- , так как:
- становиться
- становление
- было
- начало
- не являетесь
- верить
- ЛУЧШЕЕ
- связывать
- Блог
- Сообщения в блоге
- блоги
- изоферменты печени
- Коробка
- мосты
- Приведение
- Приносит
- широкий
- широко
- Строительство
- строит
- построенный
- бизнес
- by
- CAN
- возможности
- столица
- Захват
- углерод
- карта
- Карты
- случаев
- КПП
- категории
- Вызывать
- Центр
- центральный
- Центральный банк
- цифровые валюты центрального банка
- централизованная
- цепь
- проблемы
- изменение
- изменения
- проверка
- выбор
- круги
- СНГ
- гражданский
- класс
- классифицировать
- Очистить
- клиентов
- тесно
- облако
- Кластер
- цвет
- красочный
- комбинируя
- конкурентоспособный
- комплекс
- сложность
- Соответствие закону
- компоненты
- Вычисление
- вычисление
- Конфигурация
- настроить
- подключенный
- связь
- состоит
- Container
- продолжать
- контроль
- Цена
- Расходы
- может
- покрытие
- криптовалюта
- CSS
- валюты
- изготовленный на заказ
- клиент
- опыт работы с клиентами
- Клиенты
- приборная панель
- данным
- Центр обработки данных
- Платформа данных
- наука о данных
- ученый данных
- Наборы данных
- Время
- преданный
- По умолчанию
- Определения
- доставить
- демонстрировать
- убивают
- развертывание
- развернуть
- развертывание
- развертывание
- развертывания
- описано
- описание
- предназначенный
- развивать
- развитый
- Развитие
- Интернет
- цифровые валюты
- оцифровка
- Нарушение
- подрывной
- Разрушители
- распределенный
- район
- домен
- доменов
- сделанный
- управлять
- вождение
- трутень
- каждый
- легко
- экосистема
- Edge
- краевые вычисления
- ELEVATE
- возвышенный
- включить
- позволяет
- конец
- впритык
- инженер
- Проект и
- Enter
- Предприятие
- предприятий
- входящий
- Окружающая среда
- средах
- Эпоха
- особенно
- и т.д
- Эфир (ETH)
- Даже
- События
- Каждая
- эволюционировали
- Изучение
- Примеры
- выполнять
- существовать
- Выход
- дорогим
- опыт
- эксперты
- Объясняемый ИИ
- объясняя
- простирающийся
- чрезвычайно
- факторы
- БЫСТРО
- быстрее
- несколько
- поле
- фигура
- финансовый
- Финансовые институты
- финансирование
- Во-первых,
- этажей
- следовать
- после
- шрифты
- Что касается
- Передний край
- найденный
- Год основания
- доля
- Рамки
- от
- полный
- Полный стек
- Более того
- в общем
- генерируется
- генератор
- географический
- геополитика
- Отдаете
- Глобальный
- мировая торговля
- управление
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- Графические процессоры
- сетка
- рука
- обрабатывать
- Аппаратные средства
- имеет
- Есть
- Медицина
- высота
- помощь
- помощь
- помогает
- высокой четкости
- высший
- очень
- история
- кашель
- ЧАСЫ
- Как
- How To
- Однако
- HTTPS
- хаб
- Людей
- Сотни
- Гибридный
- Гибридное облако
- IBM
- IBM Cloud
- ICO
- ICON
- иллюстрирует
- изображение
- Влияние
- значение
- улучшение
- in
- включают
- включены
- повышение
- все больше и больше
- индекс
- промышленность
- промышленности
- промышленность
- отраслевые
- инфляция
- сгибание
- Точка перегиба
- влияние
- Инфраструктура
- Инициатива
- Инновации
- инновационный
- затраты
- размышления
- пример
- учреждения
- интегрированный
- Интеллекта
- внутренний
- введение
- IT
- ИТ-поддержка
- Путешествия
- JPG
- Прыгать
- Jupyter Notebook
- всего
- только один
- хранится
- Основные
- Kubernetes
- маркировка
- язык
- большой
- в значительной степени
- Задержка
- последний
- слоев
- ведущий
- УЧИТЬСЯ
- изучение
- Кредитное плечо
- Жизненный цикл
- такое как
- безграничный
- Linux
- локальным
- местный
- расположение
- места
- Длинное
- посмотреть
- машина
- обучение с помощью машины
- сделанный
- поддерживать
- сделать
- ДЕЛАЕТ
- управлять
- управление
- производство
- многих
- маркировка
- массивный
- мастер
- Вопрос
- макс-ширина
- механизмы
- методы
- Метрика
- мин
- минимизация
- минут
- ML
- Мобильный телефон
- модель
- Модели
- Модерн
- модернизация
- модернизировать
- монитор
- Мониторинг
- БОЛЕЕ
- движение
- перемещение
- имя
- Навигация
- Возле
- необходимо
- Необходимость
- необходимый
- потребности
- сеть
- Новые
- следующий
- НЛП
- ноутбук
- ничего
- сейчас
- номер
- многочисленный
- of
- предлагающий
- .
- on
- ONE
- только
- открытый
- открытый
- оперативный
- Операционный отдел
- Операторы
- оптимизированный
- or
- организация
- Другое
- наши
- внешний
- общий
- пакеты
- страница
- параметр
- оплата
- способы оплаты
- платежи
- выполнять
- выполнены
- PHP
- размещение
- Платформа
- Платформы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- плагин
- Точка
- сборах
- политика
- должность
- возможное
- После
- Блог
- потенциал
- мощностью
- мощный
- Predictions
- Предварительный
- политикой конфиденциальности.
- частная
- проблемам
- обработка
- производит
- профессиональный
- предложение.
- обеспечивать
- что такое варган?
- Push
- ассортимент
- быстро
- Reading
- реального времени
- недавно
- запись
- запись
- Red
- Red Hat
- уменьшить
- Цена снижена
- снижает
- снижение
- правила
- Регулирующие органы
- регуляторы
- Связанный
- удален
- повторяемый
- требовать
- обязательный
- Требования
- реквизит
- исследованиям
- Полезные ресурсы
- ответ
- ответственный
- отзывчивый
- розничный
- Рост
- Роботы
- Run
- Бег
- безопасно
- то же
- Масштабируемость
- Шкала
- масштаб ай
- масштабирование
- Наука
- Ученый
- экран
- скрипты
- Во-вторых
- безопасно
- безопасность
- посмотреть
- видя
- выбор
- Самообслуживание
- чувствительный
- поисковая оптимизация
- сентябрь
- Серии
- сервер
- обслуживание
- Услуги
- выступающей
- Сессия
- сессиях
- набор
- несколько
- Поделиться
- показывать
- значительный
- существенно
- аналогичный
- с
- Сингапур
- одинарной
- единая среда
- сайте
- Сайтов
- ШЕСТЬ
- навыки
- небольшой
- EMS
- МСП
- Software
- программные компоненты
- Решение
- суверенитет
- Space
- напряженность
- конкретный
- конкретно
- Спонсоров
- стек
- Начало
- современное состояние
- оставаться
- Шаги
- диск
- магазин
- хранить
- магазины
- буря
- студия
- предмет
- успех
- такие
- Предлагает
- поставка
- цепочками поставок
- поддержка
- Убедитесь
- система
- взять
- приняты
- Сложность задачи
- задачи
- снижения вреда
- Технологии
- Telco
- Temenos
- десятки
- Terraform
- проверенный
- Тестирование
- который
- Ассоциация
- их
- тема
- Там.
- Эти
- они
- этой
- Через
- время
- своевременно
- раз
- Название
- в
- сегодня
- вместе
- Инструментарий
- инструменты
- топ
- торговать
- традиционный
- Train
- специалистов
- Обучение
- перевод
- Transform
- трансформация
- преобразований
- прозрачный
- Тритон
- два
- напишите
- Типы
- развязали
- Обновление ПО
- Updates
- URL
- us
- использование
- используемый
- пользователей
- через
- использовать
- использовать
- ценный
- ценностное
- ценностное предложение
- разнообразие
- различный
- Огромная
- с помощью
- Вид
- фактически
- объем
- тома
- W
- Ожидание
- Кошелек
- законопроект
- Wave
- Путь..
- способы
- we
- неделя
- Недели
- Что
- Что такое
- когда
- который
- в то время как
- КТО
- зачем
- широкий
- Широкий диапазон
- в
- женщина
- WordPress
- Работа
- Рабочие процессы
- работает
- бы
- письменный
- ВАШЕ
- зефирнет











