Введение
Большие языковые модели (магистр права) и Генеративный ИИ представляют собой революционный прорыв в области искусственного интеллекта и обработки естественного языка. Они могут понимать и генерировать человеческий язык, а также создавать такой контент, как текст, изображения, аудио и синтетические данные, что делает их очень универсальными в различных приложениях. Генеративный искусственный интеллект имеет огромное значение в реальных приложениях, автоматизируя и улучшая создание контента, персонализируя пользовательский опыт, оптимизируя рабочие процессы и способствуя творчеству. В этом чтении мы сосредоточимся на том, как предприятия могут интегрироваться с Open LLM, эффективно обосновывая подсказки с помощью графиков знаний предприятия.
Цели обучения
- Приобретайте знания в области заземления и оперативного построения при взаимодействии с системами LLM/Gen-AI.
- Понимание актуальности заземления для предприятия и выгоды для бизнеса от интеграции с открытыми системами Gen-AI на примере.
- Анализ двух основных графов знаний, конкурирующих между собой, и векторных хранилищ по различным направлениям и понимание того, что подходит и когда.
- Изучите образец корпоративного проекта по обоснованию и построению подсказок, используя графы знаний, моделирование обучающих данных и графовое моделирование в JAVA для сценария персонализированных рекомендаций для клиентов.
Эта статья была опубликована в рамках Блогатон по Data Science.
Содержание
Что такое большие языковые модели?
Модель большого языка — это усовершенствованная модель искусственного интеллекта, обученная с использованием методов глубокого обучения на огромных объемах текстовых | неструктурированных данных. Эти модели способны взаимодействовать с человеческим языком, генерировать текст, изображения и звук, похожий на человеческий, а также выполнять различные действия. обработки естественного языка Задачи.
Напротив, определение языковой модели относится к присвоению вероятностей последовательностям слов на основе анализа текстовых корпусов. Языковая модель может варьироваться от простых моделей n-грамм до более сложных моделей нейронных сетей. Однако термин «большая языковая модель» обычно относится к моделям, которые используют методы глубокого обучения и имеют большое количество параметров, которые могут варьироваться от миллионов до миллиардов. Эти модели могут улавливать сложные закономерности языка и создавать текст, часто неотличимый от текста, написанного людьми.
Что такое подсказка?
Подсказка для любой LLM или аналогичной системы искусственного интеллекта чат-бота — это текстовый ввод или сообщение, которое вы предоставляете для начала разговора или взаимодействия с искусственным интеллектом. LLM универсальны, обучены на широком спектре больших данных и могут использоваться для различных задач; следовательно, контекст, объем, качество и ясность вашего запроса существенно влияют на ответы, которые вы получаете от систем LLM.
Что такое заземление/ТРЯПКА?
Заземление, также известное как Поисково-дополненная генерация (RAG), в контексте обработки LLM на естественном языке означает обогащение подсказки контекстом, дополнительными метаданными и объемом, которые мы предоставляем LLM для улучшения и получения более адаптированных и точных ответов. Эта связь помогает системам искусственного интеллекта понимать и интерпретировать данные таким образом, чтобы они соответствовали требуемому объему и контексту. Исследования LLM показывают, что качество их ответа зависит от качества подсказки.
Это фундаментальная концепция ИИ, поскольку она устраняет разрыв между необработанными данными и способностью ИИ обрабатывать и интерпретировать эти данные в соответствии с человеческим пониманием и ограниченным контекстом. Это повышает качество и надежность систем искусственного интеллекта, а также их способность предоставлять точную и полезную информацию или ответы.
Каковы недостатки LLM?
Модели больших языков (LLM), такие как GPT-3, привлекли значительное внимание и используются в различных приложениях, но они также имеют ряд недостатков. К основным минусам LLM можно отнести:
1. Предвзятость и справедливость: LLM часто наследуют предвзятости от обучающих данных. Это может привести к созданию предвзятого или дискриминационного контента, который может укрепить вредные стереотипы и увековечить существующие предубеждения.
2. Галлюцинации: LLM не совсем понимают контент, который они создают; они генерируют текст на основе шаблонов обучающих данных. Это означает, что они могут предоставлять фактически неверную или бессмысленную информацию, что делает их непригодными для критически важных приложений, таких как медицинская диагностика или юридические консультации.
3. Вычислительные ресурсы: Обучение и запуск LLM требуют огромных вычислительных ресурсов, включая специализированное оборудование, такое как графические процессоры и TPU. Это делает их разработку и обслуживание дорогостоящими.
4. Конфиденциальность и безопасность данных: LLM могут генерировать убедительный фальшивый контент, включая текст, изображения и аудио. Это ставит под угрозу конфиденциальность и безопасность данных, поскольку они могут быть использованы для создания мошеннического контента или выдачи себя за отдельных лиц.
5. Этические проблемы: Использование LLM в различных приложениях, таких как дипфейки или автоматическая генерация контента, поднимает этические вопросы об их потенциальном неправильном использовании и влиянии на общество.
6. Нормативные проблемы: Быстрое развитие технологии LLM опережает нормативную базу, что затрудняет разработку соответствующих руководств и правил для устранения потенциальных рисков и проблем, связанных с LLM.
Важно отметить, что многие из этих недостатков не присущи LLM, а скорее отражают то, как они разрабатываются, внедряются и используются. Продолжаются попытки смягчить эти недостатки и сделать LLM более ответственным и полезным для общества. Именно здесь можно использовать заземление и маскировку, которые принесут предприятиям огромное преимущество.
Актуальность заземления для предприятия
Предприятия стремятся использовать модели большого языка (LLM) в своих критически важных приложениях. Они понимают потенциальную ценность, которую LLM могут принести в различных областях. Создание LLM, предварительное обучение и тонкая настройка для них довольно дорого и обременительно. Скорее, они могли бы использовать открытые системы искусственного интеллекта, доступные в отрасли, с обоснованием и маскировкой подсказок вокруг корпоративных сценариев использования.
Следовательно, заземление является основным фактором для предприятий и более актуально и полезно для них как для улучшения качества ответов, так и для преодоления галлюцинаций, безопасности данных и соблюдения требований, поскольку оно может принести огромную ценность для бизнеса из открытых источников. LLM доступны на рынке для многочисленных случаев использования, автоматизировать которые сегодня сложно.
Преимущества для предприятий
Внедрение заземления с помощью LLM дает предприятиям несколько преимуществ:
1. Повышенная достоверность: Гарантируя, что информация и контент, создаваемые LLM, основаны на проверенных источниках данных, предприятия могут повысить доверие к своим сообщениям, отчетам и контенту. Это может помочь укрепить доверие со стороны заказчиков, клиентов и заинтересованных сторон.
2. Улучшенное принятие решений: В корпоративных приложениях, особенно связанных с анализом данных и поддержкой принятия решений, использование LLM с обоснованием данных может обеспечить более достоверную информацию. Это может привести к более обоснованному принятию решений, что имеет решающее значение для стратегического планирования и роста бизнеса.
3. Соответствие нормативам: Во многих отраслях действуют нормативные требования к точности и соответствию данных. Обоснование данных с помощью LLM может помочь в соблюдении этих стандартов соответствия, снижая риск юридических или нормативных проблем.
4. Генерация качественного контента: LLM часто используются при создании контента, например, для маркетинга, поддержки клиентов и описаний продуктов. Обоснование данных гарантирует, что сгенерированный контент является фактически точным, что снижает риск распространения ложной или вводящей в заблуждение информации или галлюцинаций.
5. Сокращение дезинформации: В эпоху фейковых новостей и дезинформации обоснование данных может помочь предприятиям бороться с распространением ложной информации, гарантируя, что контент, который они создают или которым делятся, основан на проверенных источниках данных.
6. Удовлетворенность клиентов: Предоставление клиентам точной и достоверной информации может повысить их удовлетворенность и доверие к продуктам или услугам предприятия.
7. Снижение рисков: Обоснование данных может помочь снизить риск принятия решений на основе неточной или неполной информации, что может привести к финансовому или репутационному ущербу.
Пример: сценарий рекомендации продукта клиенту
Давайте посмотрим, как заземление данных может помочь в случае корпоративного использования с использованием openAIchatGPT.
Основные подсказки
Generate a short email adding coupons on recommended products to customer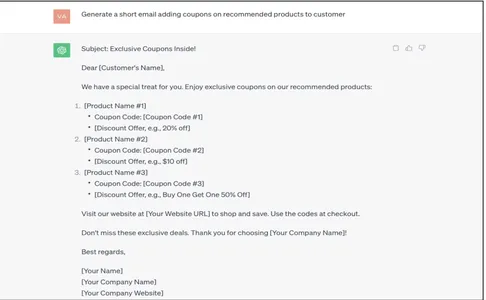
Ответ, генерируемый ChatGPT, очень общий, неконтекстуализированный и необработанный. Это необходимо вручную обновлять/сопоставлять с правильными данными корпоративных клиентов, что обходится дорого. Давайте посмотрим, как это можно автоматизировать с помощью методов заземления данных.
Скажем, предположим, что предприятие уже располагает данными о корпоративных клиентах и интеллектуальной системой рекомендаций, которая может генерировать купоны и рекомендации для клиентов; мы вполне могли бы обосновать приведенное выше приглашение, обогатив его правильными метаданными, чтобы сгенерированный текст электронного письма из ChatGPT был точно таким, каким мы хотим, и вполне мог быть автоматизирован для отправки электронного письма клиенту без ручного вмешательства.
Предположим, что наш механизм заземления получит нужные дополнительные метаданные из данных клиентов и обновит приглашение ниже. Давайте посмотрим, каким будет ответ ChatGPT на заземленное приглашение.
Заземленная подсказка
Generate a short email adding below coupons and products to customer Taylor and wish him a Happy holiday season from Team Aatagona, Atagona.com
Winter Jacket Mens - [https://atagona.com/men/winter/jackets/123.html] - 20% off
Rodeo Beanie Men’s - [https://atagona.com/men/winter/beanies/1234.html] - 15% off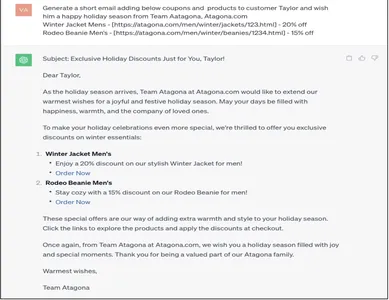
Ответ, генерируемый с помощью наземного запроса, — это именно то, что предприятие хотело бы уведомить клиента. Встраивание расширенных данных о клиентах в ответ по электронной почте от Gen AI — это автоматизация, которая была бы замечательной для масштабирования и поддержки предприятий.
Корпоративные решения LLM по заземлению для программных систем
Существует несколько способов заземления данных в корпоративных системах, и комбинация этих методов может использоваться для эффективного заземления данных и генерации подсказок, специфичных для конкретного варианта использования. Двумя основными претендентами на роль потенциальных решений для реализации дополненной генерации (заземления) являются
- Данные приложения | Графики знаний
- Векторные вложения и семантический поиск
Использование этих решений будет зависеть от варианта использования и обоснования, которое вы хотите применить. Например, предоставленные векторными хранилищами ответы могут быть неточными и расплывчатыми, тогда как графы знаний будут возвращать точные, точные и сохраненные в удобочитаемом формате.
Несколько других стратегий, которые можно было бы смешать с вышеперечисленными, могли бы быть следующими:
- Связывание с внешними API, поисковыми системами
- Системы маскировки данных и обеспечения соответствия требованиям
- Интеграция с внутренними хранилищами данных, системами
- Объединение данных из нескольких источников в реальном времени
В этом блоге давайте рассмотрим пример разработки программного обеспечения, показывающий, как можно добиться результатов с помощью графиков данных корпоративных приложений.
Графики корпоративных знаний
Граф знаний может представлять семантическую информацию о различных сущностях и отношениях между ними. В корпоративном мире они хранят знания о клиентах, продуктах и многом другом. Графики корпоративных клиентов станут мощным инструментом для эффективного обоснования данных и создания расширенных подсказок. Графы знаний обеспечивают поиск на основе графов, позволяя пользователям исследовать информацию через связанные концепции и сущности, что может привести к более точным и разнообразным результатам поиска.
Сравнение с векторными базами данных
Выбор решения по заземлению будет зависеть от конкретного случая использования. Однако графы имеют множество преимуществ перед такими векторами, как
| Критерии | Граф заземления | Векторное заземление |
| Аналитические запросы | Графики данных подходят для структурированных данных и аналитических запросов, обеспечивая точные результаты благодаря абстрактному расположению графиков. | Хранилища векторных данных могут не так хорошо работать с аналитическими запросами, поскольку они в основном работают с неструктурированными данными, семантическим поиском с встраиванием векторов и полагаются на оценку сходства. |
| Точность и достоверность | Графы знаний используют узлы и связи для хранения данных, возвращая только имеющуюся информацию. Они избегают неполных или нерелевантных результатов. | Базы данных векторов могут предоставлять неполные или нерелевантные результаты, главным образом из-за того, что они полагаются на оценку сходства и заранее определенные пределы результатов. |
| Коррекция галлюцинаций | Графики знаний прозрачны и представляют данные в удобочитаемом виде. Они помогают выявлять и исправлять дезинформацию, отслеживать путь запроса и вносить в него исправления, повышая точность LLM (большой языковой модели). | Базы данных векторов часто рассматриваются как черные ящики, которые не хранятся в читаемом формате и не могут облегчить идентификацию и исправление дезинформации. |
| Безопасность и управление | Графики знаний обеспечивают лучший контроль над созданием данных, управлением и соблюдением требований, включая такие правила, как GDPR. | Базы данных векторов могут столкнуться с проблемами при введении ограничений и управлении из-за их непрозрачного характера. |
Дизайн высокого уровня
Давайте посмотрим на очень высоком уровне, как система может искать предприятие, которое использует графы знаний и открытые LLM для обоснования.
Базовый уровень — это место, где данные и метаданные корпоративных клиентов хранятся в различных базах данных, хранилищах данных и озерах данных. Может существовать служба, создающая графики знаний данных из этих данных и сохраняющая их в базе данных графов. В распределенном облачном мире может существовать множество корпоративных сервисов и микросервисов, которые будут взаимодействовать с этими хранилищами данных. Над этими службами могут находиться различные приложения, которые будут использовать базовую инфраструктуру.
Приложения могут иметь множество вариантов использования для внедрения ИИ в свои сценарии или интеллектуальные автоматизированные потоки клиентов, что требует взаимодействия с внутренними и внешними системами ИИ. В случае сценариев генеративного искусственного интеллекта давайте возьмем простой пример рабочего процесса, когда предприятие хочет направить клиентов по электронной почте, предлагая несколько скидок на персонализированные рекомендуемые продукты во время курортного сезона. Они могут добиться этого с помощью первоклассной автоматизации и более эффективного использования искусственного интеллекта.
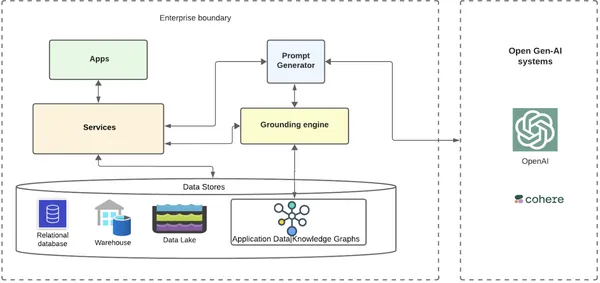
Рабочий процесс
- Рабочий процесс, который хочет отправить электронное письмо, может воспользоваться помощью открытых систем Gen-AI, отправив обоснованное приглашение с контекстуальными данными клиента.
- Приложение рабочего процесса отправит запрос в свою серверную службу для получения текста электронного письма с использованием систем GenAI.
- Внутренняя служба будет направлять службу в службу быстрого генератора, которая направляет ее к заземляющему механизму.
- Механизм заземления собирает все метаданные клиентов из одной из своих служб и извлекает граф знаний данных клиентов.
- Механизм заземления пересекает граф по узлам и соответствующим связям, извлекает необходимую окончательную информацию и отправляет ее обратно в генератор подсказок.
- Генератор подсказок добавляет обоснованные данные к уже существующему шаблону для варианта использования и отправляет обоснованную подсказку в открытые системы искусственного интеллекта, с которыми предприятие решает интегрироваться (например, OpenAI/Cohere).
- Открытые системы GenAI возвращают предприятию гораздо более актуальный и контекстуализированный ответ, отправленный клиенту по электронной почте.
Давайте разобьем это на две части и разберемся подробно:
1. Создание графиков знаний клиентов
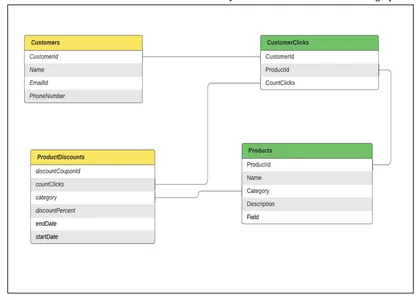
Приведенный ниже дизайн соответствует приведенному выше примеру, моделирование может выполняться различными способами в зависимости от требований.
Моделирование данных: Предположим, у нас есть различные таблицы, смоделированные как узлы в графе, и соединения между таблицами являются отношениями между узлами. Для приведенного выше примера нам понадобится
- таблица, содержащая данные Клиента,
- таблица, содержащая данные о продукте,
- таблица, содержащая данные CustomerInterests(Clicks) для персонализированных рекомендаций.
- таблица, содержащая данные ProductDiscounts
В обязанности предприятия входит получение всех этих данных из нескольких источников данных и их регулярное обновление для эффективного охвата клиентов.
Давайте посмотрим, как можно смоделировать эти таблицы и как их можно преобразовать в график клиентов.
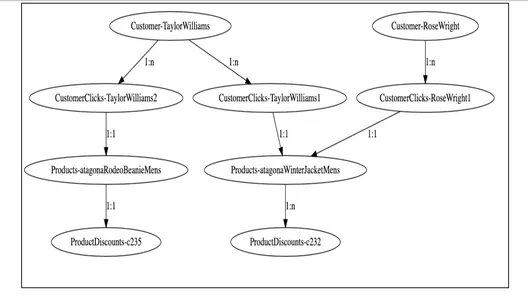
2. Графическое моделирование
Из приведенного выше визуализатора графика мы можем видеть, как узлы клиентов связаны с различными продуктами на основе данных об их кликах, а также с узлами скидок. Службе заземления легко запросить эти графы клиентов, пройти через эти узлы через связи и получить необходимую информацию о скидках, имеющих право на соответствующих клиентов.
Пример узла графа и JAVA POJO отношений для приведенного выше примера может выглядеть примерно так, как показано ниже.
public class KnowledgeGraphNode implements Serializable { private final GraphNodeType graphNodeType; private final GraphNode nodeMetadata;
} public interface GraphNode {
} public class CustomerGraphNode implements GraphNode { private final String name; private final String customerId; private final String phone; private final String emailId;
}
public class ClicksGraphNode implements GraphNode { private final String customerId; private final int clicksCount;
} public class ProductGraphNode implements GraphNode { private final String productId; private final String name; private final String category; private final String description; private final int price;
} public class ProductDiscountNode implements GraphNode { private final String discountCouponId; private final int clicksCount; private final String category; private final int discountPercent; private final DateTime startDate; private final DateTime endDate;
}
public class KnowledgeGraphRelationship implements Serializable { private final RelationshipCardinality Cardinality; } public enum RelationshipCardinality { ONE_TO_ONE, ONE_TO_MANY }Пример необработанного графика в этом сценарии может выглядеть так, как показано ниже.
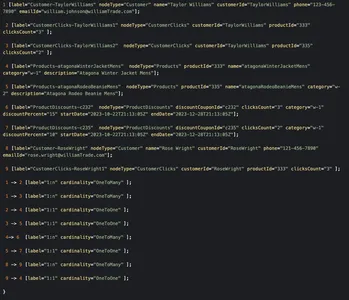
Обход графика от узла клиента «Тейлор Уильямс» решил бы для нас проблему и позволил бы получить правильные рекомендации по продуктам и соответствующие скидки.
3. Популярные магазины Graph в отрасли
На рынке доступно множество графических хранилищ, которые подходят для корпоративных архитектур. Neo4j, TigerGraph, Amazon Neptune и OrientDB широко используются в качестве графовых баз данных.
Мы представляем новую парадигму Graph Data Lakes, которая позволяет выполнять графические запросы к табличным данным (структурированные данные в озерах, складах и домиках у озер). Это достигается с помощью новых решений, перечисленных ниже, без необходимости гидратации или сохранения данных в хранилищах графических данных с использованием Zero-ETL.
- PuppyGraph (озеро графических данных)
- Тимбр.ай
Соответствие требованиям и этические соображения
Защита данных: Предприятия должны нести ответственность за хранение и использование данных клиентов в соответствии с GDPR и другими требованиями PII. Хранимые данные необходимо контролировать и очищать перед обработкой и повторным использованием для получения аналитической информации или применения ИИ.
Галлюцинации и примирение: Предприятия также могут добавлять службы сверки, которые будут выявлять дезинформацию в данных, отслеживать путь запроса и вносить в него исправления, что может помочь повысить точность LLM. С графами знаний, поскольку хранящиеся данные прозрачны и удобочитаемы, этого должно быть относительно легко достичь.
Ограничительная политика хранения: Чтобы обеспечить защиту данных и предотвратить неправомерное использование данных клиентов при взаимодействии с открытыми системами LLM, очень важно иметь политику нулевого хранения, чтобы внешние системы, с которыми взаимодействуют предприятия, не хранили запрошенные быстрые данные для каких-либо дальнейших аналитических или деловых целей.
Заключение
В заключение, модели большого языка (LLM) представляют собой выдающийся прогресс в области искусственного интеллекта и обработки естественного языка. Они могут трансформировать различные отрасли и приложения: от понимания и создания естественного языка до помощи в решении сложных задач. Однако успех и ответственное использование LLM требуют прочной основы и знаний в различных ключевых областях.
Основные выводы
- Предприятия могут получить огромную выгоду от эффективного обучения и подсказок при использовании программ LLM для различных сценариев.
- Графы знаний и векторные хранилища являются популярными решениями для заземления, и выбор одного из них будет зависеть от цели решения.
- Графы знаний могут содержать более точную и надежную информацию по сравнению с векторными хранилищами, что дает преимущество в корпоративных сценариях использования без необходимости добавления дополнительных уровней безопасности и соответствия требованиям.
- Преобразуйте традиционное моделирование данных с помощью сущностей и связей в графы знаний с узлами и ребрами.
- Интегрируйте графики корпоративных знаний с различными источниками данных с существующими предприятиями по хранению больших данных.
- Графики знаний идеально подходят для аналитических запросов. Озера графовых данных позволяют запрашивать табличные данные в виде графиков в корпоративном хранилище данных.
Часто задаваемые вопросы
О. LLM — это алгоритм искусственного интеллекта, который использует методы глубокого обучения и огромные наборы данных для понимания, обобщения, создания и прогнозирования нового контента.
О. Граф данных приложения — это структура данных, хранящая данные в виде узлов и ребер. Смоделируйте их как отношения между различными узлами данных.
А. База данных векторов хранит и управляет неструктурированными данными, такими как текст, аудио и видео. Он превосходно справляется с быстрой индексацией и поиском данных для таких приложений, как системы рекомендаций, машинное обучение и Gen-AI.
А. В векторном хранилище вложения — это числовые представления объектов, слов или точек данных в многомерном векторном пространстве. Эти внедрения фиксируют семантические отношения и сходства между элементами, обеспечивая эффективный анализ данных, поиск сходства и задачи машинного обучения.
А. Структурированные данные хорошо организованы с определенными таблицами и схемой. Неструктурированные данные, такие как текст, изображения, аудио или видео, сложнее анализировать из-за отсутствия формата.
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2023/11/the-role-of-enterprise-knowledge-graphs-in-llms/
- :имеет
- :является
- :нет
- :куда
- $UP
- 11
- 12
- 13
- 15%
- 19
- 22
- 49
- 500
- 52
- 53
- 750
- 8
- 9
- a
- способность
- О нас
- выше
- АБСТРАКТ НАЯ
- По
- точность
- точный
- Достигать
- достигнутый
- через
- Добавить
- добавить
- дополнительный
- адрес
- Добавляет
- придерживаться
- соблюдение
- придерживаясь
- принял
- продвинутый
- продвижение
- плюс
- Преимущества
- совет
- AI
- Системы искусственного интеллекта
- ака
- алгоритм
- Выравнивает
- Все
- Позволяющий
- уже
- причислены
- удивительный
- Amazon
- Амазонка Нептун
- среди
- суммы
- an
- анализ
- Аналитические фармацевтические услуги
- аналитика
- Аналитика Видхья
- анализировать
- и
- любой
- API
- Применение
- Приложения
- Применить
- Применение
- соответствующий
- МЫ
- области
- около
- гайд
- искусственный
- искусственный интеллект
- AS
- помощь
- содействие
- связанный
- предполагать
- At
- внимание
- аудио
- дополненная
- Автоматизированный
- Автоматизация
- автоматизация
- доступен
- избежать
- назад
- Backend
- Использование темпера с изогнутым основанием
- основанный
- BE
- до
- ниже
- полезный
- польза
- Преимущества
- Лучшая
- между
- Beyond
- пристрастный
- предубеждения
- большой
- Big Data
- хранилище больших данных
- миллиарды
- Черный
- Блог
- изоферменты печени
- коробки
- Ломать
- прорыв
- мосты
- строить
- строить доверие
- Строительство
- бизнес
- но
- by
- CAN
- способный
- захватить
- случаев
- случаев
- Категории
- вызов
- проблемы
- сложные
- Chatbot
- ChatGPT
- Выбирая
- ясность
- класс
- клиентов
- облако
- Облако родное
- COM
- борьбы с
- сочетание
- как
- Связь
- комплекс
- Соответствие закону
- вычислительный
- сама концепция
- понятия
- Беспокойство
- заключение
- связи
- Минусы
- рассмотрение
- последовательный
- содержание
- контентного создание
- контекст
- контраст
- контроль
- Разговор
- исправить
- исправления
- может
- Создайте
- создание
- креативность
- Доверие
- критической
- решающее значение
- громоздкий
- клиент
- данные клиентов
- служба поддержки
- Клиенты
- данным
- анализ данных
- Озеро данных
- точки данных
- конфиденциальность данных
- Конфиденциальность и безопасность данных
- защита данных
- безопасность данных
- наборы данных
- хранение данных
- хранилища данных
- База данных
- базы данных
- Дата и время
- решение
- Принятие решений
- решения
- глубоко
- глубокое обучение
- deepfakes
- определенный
- определение
- доставить
- зависит
- развернуть
- описание
- Проект
- подробность
- развивать
- развитый
- Развитие
- диагностика
- разница
- различный
- скидки
- усмотрение
- распределенный
- Разное
- do
- доменов
- сделанный
- недостатки
- управлять
- два
- в течение
- e
- легко
- Edge
- Эффективный
- фактически
- эффективный
- усилия
- право
- вставлять
- вложения
- включить
- позволяет
- позволяет
- обязательство
- Двигатель
- Двигатели
- повышать
- расширение
- Усиливает
- повышение
- огромный
- обогащенный
- обогащение
- обеспечивает
- обеспечение
- Предприятие
- предприятий
- лиц
- Эпоха
- особенно
- установить
- Эфир (ETH)
- этический
- точно,
- пример
- существующий
- дорогим
- Впечатления
- Эксплуатируемый
- Больше
- и, что лучший способ
- Экстракты
- Face
- содействовал
- не настоящие
- поддельные новости
- ложный
- несколько
- окончательный
- финансовый
- Потоки
- Фокус
- Что касается
- форма
- формат
- содействие
- Год основания
- каркасы
- и мошенническими
- от
- фундаментальный
- далее
- получила
- разрыв
- GDPR
- Gen
- порождать
- генерируется
- порождающий
- поколение
- генеративный
- Генеративный ИИ
- генератор
- дает
- управление
- регулируется
- Графические процессоры
- захваты
- график
- Графики
- земля
- Рост
- методические рекомендации
- счастливый
- Сильнее
- Аппаратные средства
- вред
- вредный
- Есть
- имеющий
- помощь
- полезный
- помогает
- следовательно
- здесь
- High
- на высшем уровне
- очень
- его
- держать
- имеет
- Выходные
- Как
- Однако
- HTML
- HTTPS
- огромный
- Очень
- человек
- человек читаемый
- Людей
- идеальный
- Идентификация
- определения
- изображений
- огромный
- Влияние
- Осуществляющий
- инвентарь
- значение
- важную
- внушительный
- улучшать
- улучшение
- in
- неточный
- включают
- В том числе
- лиц
- промышленности
- промышленность
- повлиять
- информация
- свойственный
- инициировать
- вход
- размышления
- интегрировать
- интеграции.
- Интеллекта
- Умный
- взаимодействовать
- взаимодействующий
- взаимодействие
- Интерфейс
- в нашей внутренней среде,
- вмешательство
- в
- вводить
- вопросы
- IT
- пункты
- ЕГО
- Java
- присоединиться
- JPG
- Основные
- Ключевые области
- знания
- Отсутствие
- озеро
- озера
- язык
- большой
- слой
- слоев
- Планировка
- вести
- ведущий
- изучение
- Юр. Информация
- уровень
- Кредитное плечо
- заемные средства
- Используя
- такое как
- рамки
- связанный
- Включенный в список
- посмотреть
- выглядит как
- машина
- обучение с помощью машины
- Главная
- в основном
- поддерживать
- основной
- сделать
- ДЕЛАЕТ
- Создание
- управляет
- руководство
- вручную
- многих
- рынок
- Маркетинг
- массивный
- массивно
- макс-ширина
- Май..
- означает
- Медиа
- основным медицинским
- заседания
- сообщение
- Метаданные
- миллионы
- дезинформация
- дезориентировать
- злоупотреблять
- смягчать
- смягчение
- модель
- моделирование
- Модели
- БОЛЕЕ
- в основном
- много
- с разными
- должен
- имя
- родной
- натуральный
- Естественный язык
- Обработка естественного языка
- Изучение естественного языка
- природа
- Необходимость
- потребности
- Neptune
- сеть
- нервный
- нейронной сети
- Новые
- новые решения
- Новости
- узел
- узлы
- в своих размышлениях
- номер
- многочисленный
- объекты
- получать
- of
- от
- предлагают
- предлагающий
- .
- on
- ONE
- постоянный
- только
- открытый
- OpenAI
- работать
- or
- Другое
- наши
- внешний
- за
- преодоление
- принадлежащих
- парадигма
- параметры
- часть
- части
- путь
- паттеранами
- выполнять
- выполнения
- Персонализированные
- Телефон
- PII
- планирование
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- пунктов
- сборах
- Популярное
- потенциал
- мощный
- необходимость
- предсказывать
- представить
- предотвращать
- цена
- первичный
- политикой конфиденциальности.
- Конфиденциальность и безопасность
- частная
- Проблема
- процесс
- обработка
- производит
- Продукт
- Продукция
- защиту
- обеспечивать
- при условии
- обеспечение
- что такое варган?
- опубликованный
- цель
- целей
- Запросы
- Вопросы
- САЙТ
- вполне
- повышения
- ассортимент
- быстро
- скорее
- Сырье
- необработанные данные
- достигать
- Читать
- реальный мир
- Получать
- Рекомендация
- рекомендаций
- Управление по борьбе с наркотиками (DEA)
- примиряющий
- уменьшить
- снижение
- понимается
- отражать
- регулярно
- правила
- регуляторы
- усиливает
- Связанный
- отношения
- Отношения
- относительно
- актуальность
- соответствующие
- надежность
- складская
- опора
- полагаться
- замечательный
- Отчеты
- представлять
- представление
- запросить
- просил
- требовать
- обязательный
- требование
- Требования
- требуется
- исследованиям
- Полезные ресурсы
- те
- ответ
- ответы
- ответственность
- ответственный
- Ограничения
- результат
- Итоги
- сохранение
- возвращают
- возвращение
- правую
- Снижение
- рисках,
- Роли
- дорога
- маршруты
- Бег
- то же
- удовлетворение
- Шкала
- сценарий
- Сценарии
- Наука
- сфера
- счет
- Поиск
- поиск
- Время года
- безопасность
- посмотреть
- видел
- Отправить
- отправка
- посылает
- послать
- обслуживание
- Услуги
- Наборы
- несколько
- Поделиться
- Короткое
- должен
- показанный
- Шоу
- значительный
- существенно
- аналогичный
- сходство
- просто
- с
- So
- Общество
- Software
- Решение
- Решения
- РЕШАТЬ
- некоторые
- сложный
- Источники
- Space
- специализированный
- конкретный
- распространение
- заинтересованных сторон
- стандартов
- диск
- магазин
- хранить
- магазины
- Стратегический
- стратегий
- упорядочение
- строка
- сильный
- Структура
- структурированный
- структурированные и неструктурированные данные
- предмет
- успех
- такие
- Костюм
- подходящее
- суммировать
- поддержка
- синтетический
- синтетические данные
- система
- системы
- ТАБЛИЦЫ
- с учетом
- взять
- цель
- задачи
- Тейлор
- команда
- снижения вреда
- Технологии
- шаблон
- срок
- текст
- который
- Ассоциация
- График
- информация
- их
- Их
- Там.
- Эти
- они
- этой
- те
- Thrive
- Через
- в
- сегодня
- инструментом
- топ
- прослеживать
- традиционный
- специалистов
- Обучение
- Transform
- преобразующей
- преобразован
- прозрачный
- траверс
- по-настоящему
- Доверие
- два
- окончательный
- лежащий в основе
- понимать
- понимание
- Обновление ПО
- обновление
- us
- использование
- прецедент
- используемый
- Полезная информация
- Информация о пользователе
- пользователей
- использования
- через
- обычно
- подтверждено
- ценностное
- разнообразие
- различный
- проверено
- разносторонний
- очень
- с помощью
- Видео
- хотеть
- хочет
- законопроект
- Путь..
- способы
- we
- WebP
- ЧТО Ж
- Что
- Что такое
- когда
- в то время как
- который
- в то время как
- широкий
- широко
- будете
- Зима
- без
- слова
- рабочий
- Рабочие процессы
- Мир
- бы
- письменный
- являетесь
- ВАШЕ
- зефирнет
- нуль