By David Wendt și Gregory Kimball
Procesarea eficientă a șirurilor de date este vitală pentru multe aplicații de știință a datelor. Pentru a extrage informații valoroase din șir de date, RAPIDS libcudf oferă instrumente puternice pentru accelerarea transformărilor șirurilor de date. libcudf este o bibliotecă C++ GPU DataFrame utilizată pentru încărcarea, unirea, agregarea și filtrarea datelor.
În știința datelor, datele șirurilor reprezintă vorbirea, textul, secvențele genetice, înregistrarea în jurnal și multe alte tipuri de informații. Când lucrați cu date șiruri pentru învățarea automată și ingineria caracteristicilor, datele trebuie frecvent normalizate și transformate înainte de a putea fi aplicate unor cazuri de utilizare specifice. libcudf furnizează atât API-uri de uz general, cât și utilitare pe partea dispozitivului pentru a permite o gamă largă de operațiuni cu șir personalizate.
Această postare demonstrează cum să transformați cu îndemânare coloanele cu șiruri de caractere cu API-ul de uz general libcudf. Veți dobândi cunoștințe noi despre cum să deblocați performanța maximă utilizând nuclee personalizate și utilitare libcudf de pe partea dispozitivului. Această postare vă prezintă, de asemenea, exemple despre cum să gestionați cel mai bine memoria GPU și să construiți eficient coloane libcudf pentru a accelera transformările șirurilor.
libcudf stochează date șiruri în memoria dispozitivului folosind Format săgeată, care reprezintă coloanele cu șiruri de caractere ca două coloane copil: chars and offsets (Figura 1).
chars coloana deține șirul de date ca octeți de caractere codificați UTF-8 care sunt stocați contiguu în memorie.
offsets coloana conține o secvență crescătoare de numere întregi care sunt poziții de octeți care identifică începutul fiecărui șir individual din matricea de date chars. Elementul de offset final este numărul total de octeți din coloana Chars. Aceasta înseamnă dimensiunea unui șir individual la rând i este definit ca (offsets[i+1]-offsets[i]).
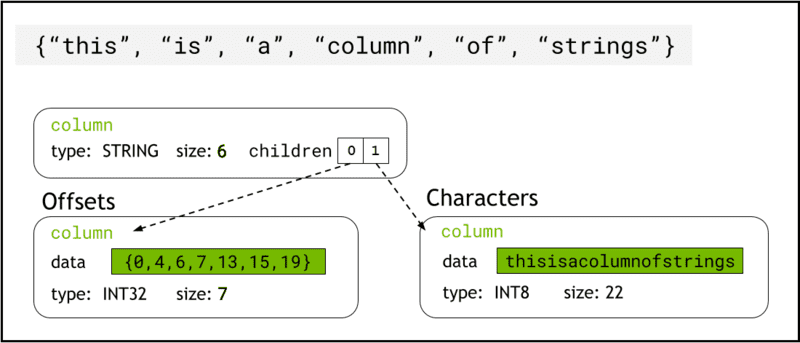 Figura 1. Schemă care arată modul în care formatul săgeată reprezintă coloanele cu șiruri
Figura 1. Schemă care arată modul în care formatul săgeată reprezintă coloanele cu șiruri chars și offsets coloane copil
Pentru a ilustra un exemplu de transformare de șir, luați în considerare o funcție care primește două coloane de șiruri de intrare și produce o coloană de șiruri de ieșire redactată.
Datele de intrare au următoarea formă: o coloană „nume” care conține prenumele și numele de familie separate printr-un spațiu și o coloană „vizibilități” care conține statutul „public” sau „privat”.
Propunem funcția „redact” care operează asupra datelor de intrare pentru a produce date de ieșire constând din prima inițială a numelui urmată de un spațiu și întregul prenume. Cu toate acestea, dacă coloana de vizibilitate corespunzătoare este „privată”, atunci șirul de ieșire ar trebui să fie complet redactat ca „X X”.
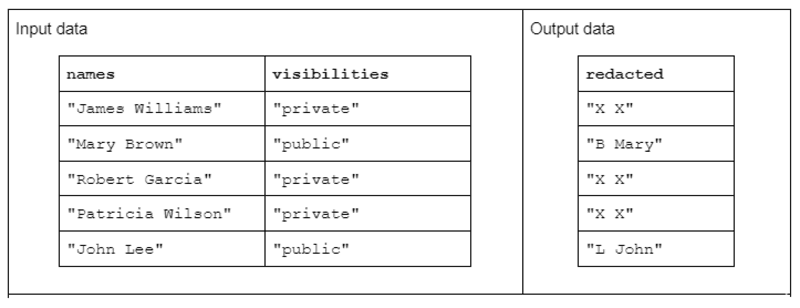 Tabel 1. Exemplu de transformare de șir „redactată” care primește nume și coloane de șiruri de vizibilitate ca intrare și date redactate parțial sau complet ca ieșire
Tabel 1. Exemplu de transformare de șir „redactată” care primește nume și coloane de șiruri de vizibilitate ca intrare și date redactate parțial sau complet ca ieșire
În primul rând, transformarea șirurilor poate fi realizată folosind libcudf șiruri API. API-ul de uz general este un punct de plecare excelent și o bază bună pentru compararea performanței.
Funcțiile API operează pe o întreagă coloană de șiruri, lansând cel puțin un nucleu per funcție și atribuind câte un fir pe șir. Fiecare thread gestionează un singur rând de date în paralel pe GPU și scoate un singur rând ca parte a unei noi coloane de ieșire.
Pentru a finaliza funcția exemplu de redactare folosind API-ul de uz general, urmați acești pași:
- Convertiți coloana cu șiruri de caractere „vizibilități” într-o coloană booleană folosind
contains - Creați o nouă coloană cu șiruri din coloana de nume prin copierea „XX” ori de câte ori intrarea de rând corespunzătoare din coloana booleană este „falsă”
- Împărțiți coloana „exprimată” în coloane cu prenume și prenume
- Tăiați primul caracter al numelor de familie ca inițialele numelui de familie
- Construiți coloana de ieșire prin concatenarea coloanei cu ultimele inițiale și a coloanei cu prenumele cu un separator de spațiu (" ").
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
Această abordare durează aproximativ 3.5 ms pe un A6000 cu 600 de rânduri de date. Acest exemplu folosește contains, copy_if_else, split, slice_strings și concatenate pentru a realiza o transformare de șir personalizată. O analiză de profilare cu Nsight Systems arată că split funcția durează cea mai mare perioadă de timp, urmată de slice_strings și concatenate.
Figura 2 prezintă datele de profilare de la Nsight Systems din exemplul de redactare, arătând procesarea șirurilor de caractere end-to-end cu până la ~600 de milioane de elemente pe secundă. Regiunile corespund intervalelor NVTX asociate cu fiecare funcție. Intervalele de albastru deschis corespund perioadelor în care rulează nucleele CUDA.
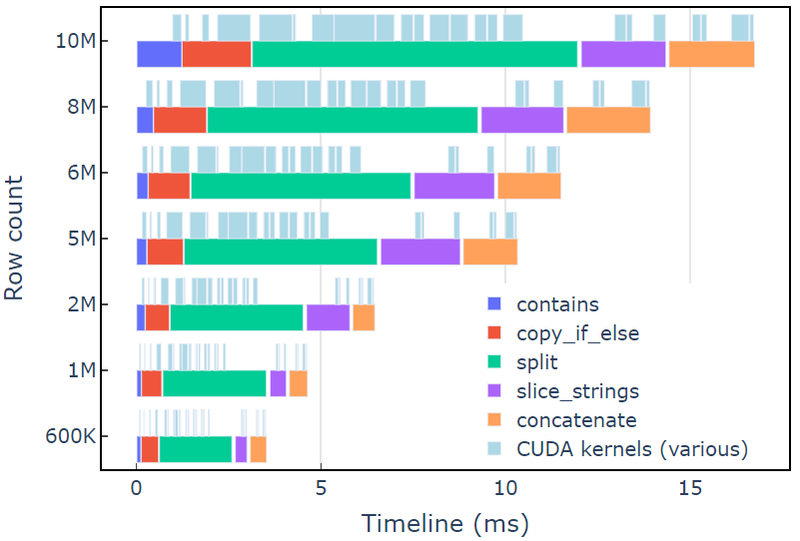 Figura 2. Date de profilare din Nsight Systems din exemplul de redactare
Figura 2. Date de profilare din Nsight Systems din exemplul de redactare
API-ul libcudf strings este un set de instrumente rapid și eficient pentru transformarea șirurilor, dar uneori funcțiile critice pentru performanță trebuie să ruleze și mai repede. O sursă cheie de lucru suplimentar în libcudf strings API este crearea a cel puțin unei noi coloane de șiruri în memoria globală a dispozitivului pentru fiecare apel API, deschizând posibilitatea de a combina mai multe apeluri API într-un nucleu personalizat.
Limitări de performanță în apelurile malloc ale nucleului
Mai întâi, vom construi un nucleu personalizat pentru a implementa transformarea exemplu de redactare. Când proiectăm acest nucleu, trebuie să ținem cont de faptul că coloanele de șiruri libcudf sunt imuabile.
Coloanele cu șiruri de caractere nu pot fi modificate la locul lor, deoarece octeții de caractere sunt stocați contigu și orice modificare a lungimii unui șir ar invalida datele offset-urilor. De aceea redact_kernel Nucleul personalizat generează o nouă coloană cu șiruri de caractere folosind o fabrică de coloane libcudf pentru a le construi pe ambele offsets și chars coloane copil.
În această primă abordare, șirul de ieșire pentru fiecare rând este creat în memorie dinamică a dispozitivului folosind un apel malloc în interiorul nucleului. Ieșirea personalizată a nucleului este un vector de pointeri de dispozitiv către fiecare ieșire de rând, iar acest vector servește ca intrare într-o fabrică de coloane de șiruri.
Nucleul personalizat acceptă a cudf::column_device_view pentru a accesa datele coloanei șiruri și folosește element metoda de a returna a cudf::string_view reprezentând datele șirului la indexul de rând specificat. Ieșirea nucleului este un vector de tip cudf::string_view care deține pointeri către memoria dispozitivului care conține șirul de ieșire și dimensiunea acelui șir în octeți.
cudf::string_view clasa este similară cu clasa std::string_view, dar este implementată special pentru libcudf și include o lungime fixă a datelor de caractere în memoria dispozitivului codificată ca UTF-8. Are multe dintre aceleași caracteristici (find și substr funcții, de exemplu) și limitări (fără terminator nul) ca std echivalent. A cudf::string_view reprezintă o secvență de caractere stocată în memoria dispozitivului și, astfel, o putem folosi aici pentru a înregistra memoria malloc pentru un vector de ieșire.
Miez de Malloc
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
Aceasta ar putea părea o abordare rezonabilă, până când performanța nucleului este măsurată. Această abordare durează aproximativ 108 ms pe un A6000 cu 600 de rânduri de date - de peste 30 de ori mai lentă decât soluția furnizată mai sus folosind API-ul libcudf strings.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
Principalul blocaj este malloc/free apeluri în interiorul celor două nuclee de aici. Memoria dinamică a dispozitivului CUDA necesită malloc/free apelurile la un nucleu pentru a fi sincronizate, determinând execuția paralelă să degenereze în execuție secvențială.
Prealocarea memoriei de lucru pentru a elimina blocajele
Eliminați malloc/free blocaj prin înlocuirea malloc/free apelează în nucleu cu memorie de lucru prealocată înainte de lansarea nucleului.
Pentru exemplul de redactare, dimensiunea de ieșire a fiecărui șir din acest exemplu nu ar trebui să fie mai mare decât șirul de intrare în sine, deoarece logica elimină doar caractere. Prin urmare, un singur buffer de memorie pentru dispozitiv poate fi utilizat cu aceeași dimensiune ca și tamponul de intrare. Utilizați decalajele de intrare pentru a localiza fiecare poziție de rând.
Accesarea decalajelor coloanei șiruri implică înfășurarea cudf::column_view cu cudf::strings_column_view și numindu-i offsets_begin metodă. Dimensiunea lui chars coloana copil poate fi accesată și folosind chars_size metodă. Apoi o rmm::device_uvector este pre-alocat înainte de a apela nucleul pentru a stoca datele de ieșire a caracterelor.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);Nucleu pre-alocat
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
Nucleul produce un vector de cudf::string_view obiecte care sunt transmise la cudf::make_strings_column funcția din fabrică. Al doilea parametru al acestei funcții este utilizat pentru identificarea intrărilor nule în coloana de ieșire. Exemplele din această postare nu au intrări nule, deci un substituent nullptr cudf::string_view{nullptr,0} este folosit.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
Această abordare durează aproximativ 1.1 ms pe un A6000 cu 600 de rânduri de date și, prin urmare, depășește linia de bază de peste 2 ori. Defalcarea aproximativă este prezentată mai jos:
redact_kernel 66us make_strings_column 400us
Timpul rămas este petrecut în cudaMalloc, cudaFree, cudaMemcpy, care este tipic pentru overhead pentru gestionarea instanțelor temporare de rmm::device_uvector. Această metodă funcționează bine dacă toate șirurile de ieșire sunt garantate a fi de aceeași dimensiune sau mai mici ca șirurile de intrare.
În general, trecerea la o alocare de memorie de lucru în bloc cu RAPIDS RMM este o îmbunătățire semnificativă și o soluție bună pentru o funcție de șiruri personalizate.
Optimizarea creării coloanelor pentru timpi de calcul mai rapid
Există vreo modalitate de a îmbunătăți acest lucru și mai mult? Blocajul este acum cudf::make_strings_column funcția din fabrică care construiește cele două componente ale coloanei șiruri, offsets și chars, din vectorul de cudf::string_view obiecte.
În libcudf, multe funcții din fabrică sunt incluse pentru construirea coloanelor cu șiruri. Funcția din fabrică utilizată în exemplele anterioare ia a cudf::device_span of cudf::string_view obiecte și apoi construiește coloana efectuând a gather pe datele de caractere subiacente pentru a construi offset-urile și coloanele copil de caractere. A rmm::device_uvector este automat convertibil în a cudf::device_span fără a copia date.
Cu toate acestea, dacă vectorul de caractere și vectorul de decalaje sunt construite direct, atunci poate fi utilizată o funcție de fabrică diferită, care creează pur și simplu coloana de șiruri fără a necesita o colectare pentru a copia datele.
sizes_kernel face o primă trecere peste datele de intrare pentru a calcula dimensiunea exactă de ieșire a fiecărui rând de ieșire:
Nucleu optimizat: Partea 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
Dimensiunile de ieșire sunt apoi convertite în compensații prin efectuarea unui in-place exclusive_scan. Rețineți că offsets vectorul a fost creat cu names.size()+1 elemente. Ultima intrare va fi numărul total de octeți (toate dimensiunile adăugate împreună), în timp ce prima intrare va fi 0. Ambii sunt gestionați de către exclusive_scan apel. Dimensiunea lui chars coloana este preluată din ultima intrare a offsets coloană pentru a construi vectorul de caractere.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
redact_kernel logica este încă foarte aproape aceeași, cu excepția faptului că acceptă rezultatul d_offsets vector pentru a rezolva locația de ieșire a fiecărui rând:
Nucleu optimizat: Partea 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
Dimensiunea ieșirii d_chars coloana este preluată din ultima intrare a d_offsets coloană pentru a aloca vectorul caractere. Nucleul se lansează cu vectorul de offset precalculat și returnează vectorul de caractere populat. În cele din urmă, fabrica de coloane de șiruri libcudf creează coloanele de șiruri de ieșire.
Acest cudf::make_strings_column funcția fabrică construiește coloana șiruri de caractere fără a face o copie a datelor. The offsets date și date chars datele sunt deja în formatul corect, așteptat și această fabrică pur și simplu mută datele din fiecare vector și creează structura coloanei în jurul acestuia. Odată finalizat, rmm::device_uvectors pentru offsets și chars sunt goale, datele lor fiind mutate în coloana de ieșire.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
Această abordare durează aproximativ 300 us (0.3 ms) pe un A6000 cu 600 rânduri de date și se îmbunătățește de peste 2 ori față de abordarea anterioară. S-ar putea să observi asta sizes_kernel și redact_kernel împărtășesc o mare parte din aceeași logică: o dată pentru a măsura dimensiunea ieșirii și apoi din nou pentru a popula ieșirea.
Din perspectiva calității codului, este benefic să refactorăm transformarea ca o funcție a dispozitivului numită atât de nuclee de dimensiuni, cât și de redactare. Din punct de vedere al performanței, ați putea fi surprins să vedeți că costul de calcul al transformării este plătit de două ori.
Beneficiile pentru gestionarea memoriei și crearea mai eficientă a coloanei depășesc adesea costul de calcul al efectuării transformării de două ori.
Tabelul 2 arată timpul de calcul, numărul nucleului și octeții procesați pentru cele patru soluții discutate în această postare. „Lansări totale de nuclee” reflectă numărul total de nuclee lansate, inclusiv nuclee de calcul și helper. „Total octeți procesați” este debitul cumulativ de citire și scriere a DRAM, iar „octeți minimi procesați” este o medie de 37.9 octeți pe rând pentru intrările și ieșirile noastre de testare. Carcasa ideală „limitată cu lățime de bandă de memorie” presupune o lățime de bandă de 768 GB/s, debitul maxim teoretic al A6000.
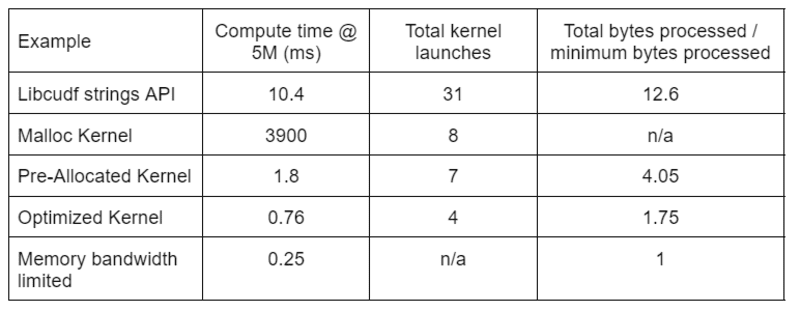 Tabelul 2. Timpul de calcul, numărul de nuclee și octeții procesați pentru cele patru soluții discutate în această postare
Tabelul 2. Timpul de calcul, numărul de nuclee și octeții procesați pentru cele patru soluții discutate în această postare
„Optimized Kernel” oferă cel mai mare debit datorită numărului redus de lansări de nucleu și a mai puțini octeți totali procesați. Cu nuclee personalizate eficiente, numărul total de lansări de nucleu scade de la 31 la 4, iar totalul de octeți procesați de la 12.6x la 1.75x din dimensiunea de intrare plus ieșire.
Ca rezultat, nucleul personalizat realizează un debit de >10 ori mai mare decât API-ul de șiruri de uz general pentru transformarea redactării.
Resursa de memorie pool în Manager de memorie RAPIDS (RMM) este un alt instrument pe care îl puteți folosi pentru a crește performanța. Exemplele de mai sus folosesc „resursa de memorie CUDA” implicită pentru alocarea și eliberarea memoriei globale a dispozitivului. Cu toate acestea, timpul necesar pentru a aloca memoria de lucru adaugă o latență semnificativă între pașii transformărilor șirurilor. „Resursa de memorie pool” din RMM reduce latența prin alocarea unui pool mare de memorie în avans și alocarea subalocărilor după cum este necesar în timpul procesării.
Cu resursa de memorie CUDA, „Optimized Kernel” arată o accelerare de 10x-15x care începe să scadă la un număr mai mare de rânduri din cauza creșterii dimensiunii alocării (Figura 3). Utilizarea resursei de memorie pool atenuează acest efect și menține accelerări de 15x-25x față de abordarea libcudf strings API.
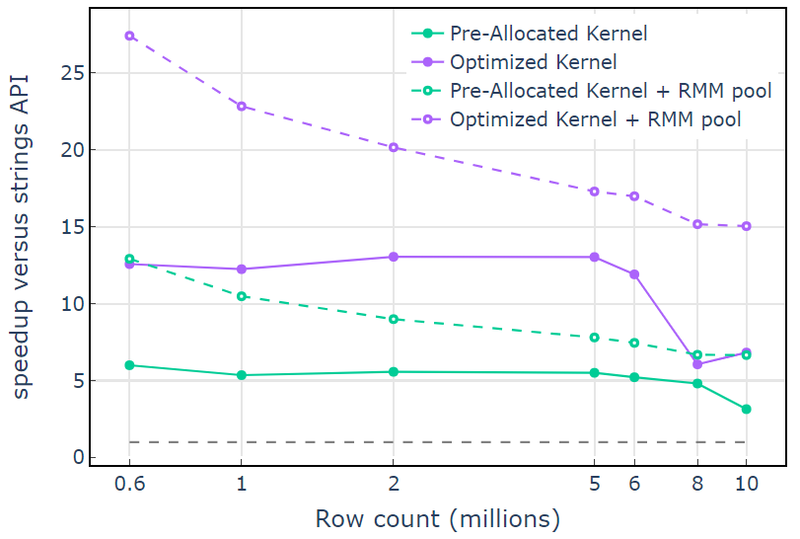 Figura 3. Accelerarea de la nucleele personalizate „Pre-Alocated Kernel” și „Optimized Kernel” cu resursa implicită de memorie CUDA (solid) și resursa de memorie pool (liniată), față de API-ul șir libcudf folosind resursa de memorie CUDA implicită
Figura 3. Accelerarea de la nucleele personalizate „Pre-Alocated Kernel” și „Optimized Kernel” cu resursa implicită de memorie CUDA (solid) și resursa de memorie pool (liniată), față de API-ul șir libcudf folosind resursa de memorie CUDA implicită
Cu resursa de memorie pool, se demonstrează un debit de memorie end-to-end care se apropie de limita teoretică pentru un algoritm cu două treceri. „Optimized Kernel” atinge un debit de 320-340 GB/s, măsurat folosind dimensiunea intrărilor plus dimensiunea ieșirilor și timpul de calcul (Figura 4).
Abordarea în două treceri măsoară mai întâi dimensiunile elementelor de ieșire, alocă memorie și apoi setează memoria cu ieșirile. Având în vedere un algoritm de procesare în două treceri, implementarea în „Optimized Kernel” funcționează aproape de limita de lățime de bandă a memoriei. „Debitul de memorie end-to-end” este definit ca dimensiunea de intrare plus ieșire în GB împărțită la timpul de calcul. *Lățimea de bandă a memoriei RTX A6000 (768 GB/s).
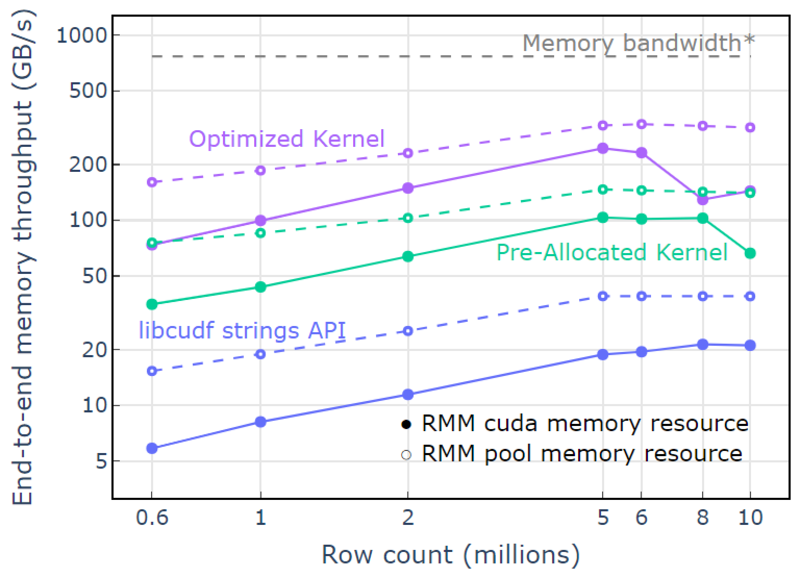 Figura 4. Debitul de memorie pentru „Optimized Kernel”, „Pre-Alocated Kernel” și „libcudf strings API” ca o funcție a numărului de rânduri de intrare/ieșire
Figura 4. Debitul de memorie pentru „Optimized Kernel”, „Pre-Alocated Kernel” și „libcudf strings API” ca o funcție a numărului de rânduri de intrare/ieșire
Această postare demonstrează două abordări pentru scrierea transformărilor eficiente de date șiruri în libcudf. API-ul de uz general libcudf este rapid și simplu pentru dezvoltatori și oferă performanțe bune. libcudf oferă, de asemenea, utilități pe partea dispozitivului concepute pentru a fi utilizate cu nuclee personalizate, în acest exemplu deblocând performanțe >10 ori mai rapide.
Aplicați cunoștințele dvs
Pentru a începe cu RAPIDS cuDF, vizitați rapidsai/cudf Repoziție GitHub. Dacă nu ați încercat încă cuDF și libcudf pentru sarcinile de lucru de procesare a șirurilor, vă încurajăm să testați cea mai recentă versiune. Docker containere sunt furnizate pentru lansări, precum și pentru versiuni de noapte. Pachete Conda sunt, de asemenea, disponibile pentru a facilita testarea și implementarea. Dacă utilizați deja cuDF, vă încurajăm să rulați noul exemplu de transformare a șirurilor vizitând rapidsai/cudf/tree/HEAD/cpp/examples/strings pe GitHub.
David Wendt este inginer senior de software de sisteme la NVIDIA, care dezvoltă cod C++/CUDA pentru RAPIDS. David deține o diplomă de master în inginerie electrică de la Universitatea Johns Hopkins.
Gregory Kimball este manager de inginerie software la NVIDIA care lucrează în echipa RAPIDS. Gregory conduce dezvoltarea pentru libcudf, biblioteca CUDA/C++ pentru procesarea datelor în coloană care alimentează RAPIDS cuDF. Gregory deține un doctorat în fizică aplicată de la Institutul de Tehnologie din California.
Original. Repostat cu permisiunea.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- Despre Noi
- mai sus
- accelerarea
- acceptă
- acces
- accesate
- realizat
- peste
- adăugat
- Adaugă
- Algoritmul
- TOATE
- alocari
- alocare
- deja
- sumă
- analiză
- și
- O alta
- Apache
- api
- API-uri
- aplicatii
- aplicat
- abordare
- abordari
- se apropie
- în jurul
- Mulțime
- asociate
- Auto
- în mod automat
- disponibil
- in medie
- Lățime de bandă
- De bază
- deoarece
- înainte
- fiind
- de mai jos
- benefică
- Beneficiile
- CEL MAI BUN
- între
- Albastru
- Defalcarea
- tampon
- construi
- Clădire
- construiește
- construit
- C ++
- California
- apel
- denumit
- apel
- apeluri
- nu poti
- caz
- cazuri
- provocând
- Modificări
- caracter
- caractere
- copil
- clasă
- Închide
- cod
- Coloană
- Coloane
- combina
- compararea
- Completă
- Terminat
- componente
- calcul
- Calcula
- Lua în considerare
- Constând
- construi
- conține
- converti
- convertit
- copiere
- Corespunzător
- A costat
- crea
- a creat
- creează
- creaţie
- personalizat
- de date
- de prelucrare a datelor
- știința datelor
- David
- Mod implicit
- Grad
- Oferă
- demonstrat
- desfășurarea
- proiectat
- proiect
- Dezvoltatorii
- în curs de dezvoltare
- Dezvoltare
- dispozitiv
- diferit
- direct
- discutat
- împărțit
- Docher
- Picătură
- în timpul
- dinamic
- fiecare
- mai ușor
- efect
- eficient
- eficient
- Inginerie Electrică
- element
- elimina
- permite
- încuraja
- un capăt la altul
- inginer
- Inginerie
- Întreg
- intrare
- Eter (ETH)
- Chiar
- tot
- exemplu
- exemple
- excelent
- Cu excepția
- execuție
- de aşteptat
- extern
- suplimentar
- extrage
- fabrică
- FAST
- mai repede
- Caracteristică
- DESCRIERE
- Figura
- filtrare
- final
- În cele din urmă
- First
- fixată
- urma
- a urmat
- următor
- formă
- format
- Gratuit
- frecvent
- din
- faţă
- complet
- funcţie
- funcții
- mai mult
- Câştig
- General
- generează
- obține
- GitHub
- dat
- Caritate
- bine
- GPU
- garantat
- Mânere
- având în
- aici
- superior
- cea mai mare
- deține
- Cum
- Cum Pentru a
- Totuși
- HTML
- HTTPS
- ideal
- identificarea
- imuabil
- punerea în aplicare a
- implementarea
- implementat
- îmbunătăţi
- îmbunătățire
- îmbunătăţeşte
- in
- inclus
- Inclusiv
- Crește
- crescând
- index
- individ
- informații
- inițială
- intrare
- Institut
- intern
- IT
- în sine
- Johns Hopkins
- Universitatea Johns Hopkins
- aderarea
- KDnuggets
- A pastra
- Cheie
- cunoştinţe
- Etichetă
- mare
- mai mare
- Nume
- Latență
- Ultimele
- ultima lansare
- a lansat
- lansează
- lansare
- Conduce
- învăţare
- Lungime
- Bibliotecă
- ușoară
- LIMITĂ
- limitări
- încărcare
- locaţie
- maşină
- masina de învățare
- Principal
- susține
- face
- FACE
- Efectuarea
- administra
- administrare
- manager
- de conducere
- multe
- maestru
- Stăpânirea
- Meci
- mijloace
- măsura
- măsuri
- Memorie
- metodă
- ar putea
- milion
- minte
- mai mult
- mai eficient
- mişcă
- MS
- multiplu
- nume
- nume
- Nevoie
- necesar
- Nou
- număr
- Nvidia
- obiecte
- compensa
- ONE
- de deschidere
- funcionar
- opereaza
- Operațiuni
- Oportunitate
- Altele
- plătit
- Paralel
- parametru
- parte
- Trecut
- Vârf
- performanță
- efectuarea
- efectuează
- perioadele
- permisiune
- perspectivă
- Fizică
- Loc
- Plato
- Informații despre date Platon
- PlatoData
- la care se adauga
- Punct
- piscină
- populat
- poziţie
- poziţii
- Post
- puternic
- competenţelor
- precedent
- prelucrare
- produce
- profilare
- propune
- prevăzut
- furnizează
- public
- scop
- calitate
- gamă
- aTINGE
- Citeste
- rezonabil
- primește
- record
- Redus
- reduce
- Refactorizare
- reflectă
- regiuni
- eliberaţi
- Lansări
- rămas
- reprezentând
- reprezintă
- resursă
- rezultat
- reveni
- Returnează
- RÂND
- Alerga
- funcţionare
- acelaşi
- Ştiinţă
- Al doilea
- senior
- Secvenţă
- servește
- Seturi
- Distribuie
- să
- indicat
- Emisiuni
- semnificativ
- asemănător
- pur şi simplu
- întrucât
- singur
- Mărimea
- dimensiuni
- mai mici
- So
- Software
- Inginer Software
- Inginerie software
- solid
- soluţie
- soluţii
- Sursă
- Spaţiu
- specific
- specific
- specificată
- discurs
- viteză
- uzat
- împărţi
- Începe
- început
- Pornire
- Stare
- paşi
- Încă
- stoca
- stocate
- magazine
- simplu
- curent
- structura
- uimit
- sisteme
- ia
- echipă
- Tehnologia
- temporar
- test
- Testarea
- lor
- teoretic
- prin urmare
- Prin
- debit
- timp
- la
- împreună
- instrument
- Toolkit
- Unelte
- Total
- Transforma
- Transformare
- transformări
- transformat
- transformare
- tv
- Tipuri
- tipic
- care stau la baza
- universitate
- deschide
- deblocare
- us
- utilizare
- utilitati
- Valoros
- Informatie pretioasa
- Impotriva
- vizibilitate
- vizibil
- vital
- care
- în timp ce
- larg
- Gamă largă
- voi
- în
- fără
- Apartamente
- de lucru
- fabrică
- ar
- scrie
- scris
- X
- Ta
- zephyrnet










