Apache Hudi este un format de tabel deschis care aduce baze de date și capabilități de depozit de date la lacurile de date. Apache Hudi îi ajută pe inginerii de date să gestioneze provocările complexe, cum ar fi gestionarea setului de date în continuă evoluție cu tranzacții, menținând în același timp performanța interogărilor. Inginerii de date folosesc Apache Hudi pentru fluxuri de lucru, precum și pentru a crea conducte eficiente de date incrementale. Hudi oferă tabele, tranzacții, upsertări și ștergeri eficiente, indici avansati, servicii de asimilare în flux, date clustering și compactare optimizări și controlul concurentei, toate în timp ce vă păstrați datele în formate de fișiere open source. Optimizările avansate ale performanței Hudi fac sarcinile de lucru analitice mai rapide cu oricare dintre motoarele de interogare populare, inclusiv Apache Spark, Presto, Trino, Hive și așa mai departe.
Mulți clienți AWS au adoptat Apache Hudi pe lacurile lor de date construite pe Amazon S3 folosind AWS Adeziv, un serviciu de integrare a datelor fără server care facilitează descoperirea, pregătirea, mutarea și integrarea datelor din mai multe surse pentru analiză, învățare automată (ML) și dezvoltare de aplicații. AWS Glue Crawler este o componentă a AWS Glue, care vă permite să creați automat metadate de tabel din conținutul de date, fără a necesita definirea manuală a metadatelor.
Crawlerele AWS Glue acceptă acum tabele Apache Hudi, simplificând adoptarea Catalogul de date AWS Glue ca catalogul pentru mesele Hudi. Un caz tipic de utilizare este înregistrarea tabelelor Hudi, care nu are definiție de tabel de catalog. Un alt caz de utilizare tipic este migrarea din alte cataloage Hudi, cum ar fi metamagazinul Hive. Când migrați din alte cataloage Hudi, puteți crea și programa un crawler AWS Glue și puteți furniza una sau mai multe căi Amazon S3 unde se află fișierele tabelului Hudi. Aveți opțiunea de a furniza adâncimea maximă a căilor Amazon S3 pe care le poate parcurge crawler-ul AWS Glue. La fiecare rulare, crawlerele AWS Glue vor extrage informații despre schemă și partiție și vor actualiza AWS Glue Data Catalog cu modificările schemei și ale partițiilor. Crawlerele AWS Glue actualizează cea mai recentă locație a fișierului de metadate din Catalogul de date AWS Glue pe care motoarele analitice AWS o pot folosi direct.
Cu această lansare, puteți crea și programa un crawler AWS Glue pentru a înregistra tabelele Hudi în AWS Glue Data Catalog. Puteți furniza apoi una sau mai multe căi Amazon S3 unde se află tabelele Hudi. Aveți opțiunea de a furniza adâncimea maximă a căilor Amazon S3 pe care o pot parcurge crawlerele. Cu fiecare rulare a crawler-ului, crawler-ul inspectează fiecare dintre căile S3 și cataloghează informațiile despre schemă, cum ar fi tabele noi, ștergeri și actualizări ale schemelor din Catalogul de date AWS Glue. Crawlerele inspectează informațiile despre partiții și adaugă partiții nou adăugate la AWS Glue Data Catalog. De asemenea, crawlerele actualizează cea mai recentă locație a fișierului de metadate din Catalogul de date AWS Glue pe care motoarele analitice AWS o pot folosi direct.
Această postare demonstrează cum funcționează această nouă capacitate de accesare cu crawlere a tabelelor Hudi.
Cum funcționează crawlerul AWS Glue cu tabelele Hudi
Tabelele Hudi au două categorii, cu implicații specifice pentru fiecare:
- Copiere la scriere (CoW) – Datele sunt stocate într-un format de coloană (Parquet), iar fiecare actualizare creează o nouă versiune de fișiere în timpul unei scrieri.
- Îmbinare la citire (MoR) – Datele sunt stocate folosind o combinație de formate coloane (Parquet) și pe rând (Avro). Actualizările sunt înregistrate pe rând
deltafișiere și sunt compactate după cum este necesar pentru a crea versiuni noi ale fișierelor de coloană.
Cu seturile de date CoW, de fiecare dată când există o actualizare a unei înregistrări, fișierul care conține înregistrarea este rescris cu valorile actualizate. Cu un set de date MoR, de fiecare dată când există o actualizare, Hudi scrie doar rândul pentru înregistrarea modificată. MoR este mai potrivit pentru sarcinile de lucru grele de scriere sau modificare, cu mai puține citiri. CoW este mai potrivit pentru sarcini de lucru grele de citire pe date care se modifică mai rar.
Hudi oferă trei tipuri de interogări pentru accesarea datelor:
- Interogări instantanee – Interogări care văd cel mai recent instantaneu al tabelului la o anumită acțiune de comitere sau de compactare. Pentru tabelele MoR, interogările instantanee expun cea mai recentă stare a tabelului prin îmbinarea fișierelor de bază și delta ale celei mai recente secțiuni de fișier la momentul interogării.
- Interogări incrementale – Interogările văd doar date noi scrise în tabel, de la o anumită comitere sau compactare. Acest lucru oferă în mod eficient fluxuri de modificări pentru a activa conducte de date incrementale.
- Citiți interogări optimizate – Pentru tabelele MoR, interogările văd cele mai recente date compactate. Pentru tabelele CoW, interogările văd cele mai recente date comise.
Pentru tabelele de copiere la scriere, crawlerele creează un singur tabel în Catalogul de date AWS Glue cu ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
Pentru tabelele de îmbinare la citire, crawlerele creează două tabele în AWS Glue Data Catalog pentru aceeași locație a tabelului:
- Un tabel cu sufix
_ro, care utilizează ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - Un tabel cu sufix
_rt, care utilizează RealTime Serde care permite interogări Snapshot:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
În timpul fiecărei accesări cu crawlere, pentru fiecare cale Hudi furnizată, crawlerele efectuează un apel API Amazon S3 list, filtrul pe baza .hoodie foldere și găsiți cel mai recent fișier de metadate sub acel dosar de metadate din tabelul Hudi.
Accesați cu crawlere o masă Hudi CoW folosind crawlerul AWS Glue
În această secțiune, să vedem cum să accesați cu crawlere o vaca Hudi folosind crawlerele AWS Glue.
Cerințe preliminare
Iată premisele pentru acest tutorial:
- Instalați și configurați Interfață linie de comandă AWS (AWS CLI).
- Creați-vă bucket-ul S3 dacă nu îl aveți.
- Creați-vă rolul IAM pentru AWS Glue daca nu il ai. Ai nevoie
s3:GetObjectpentrus3://your_s3_bucket/data/sample_hudi_cow_table/. - Rulați următoarea comandă pentru a copia exemplul de tabel Hudi în compartimentul dvs. S3. (A inlocui
your_s3_bucketcu numele găleții dvs. S3.)
Această instrucțiune vă îndrumă să copiați date eșantion, dar puteți crea cu ușurință orice tabel Hudi folosind AWS Glue. Aflați mai multe în Prezentarea suportului nativ pentru Apache Hudi, Delta Lake și Apache Iceberg pe AWS Glue pentru Apache Spark, Partea 2: Editor vizual AWS Glue Studio.
Creați un crawler Hudi
În această instrucțiune, creați crawler-ul prin consolă. Parcurgeți următorii pași pentru a crea un crawler Hudi:
- Pe consola AWS Glue, alegeți crawlere.
- Alege Creați un crawler.
- Pentru Nume si Prenume, introduce
hudi_cow_crawler. Alege Pagina Următoare →. - În Configurarea sursei de date, alege Adăugați o sursă de date.
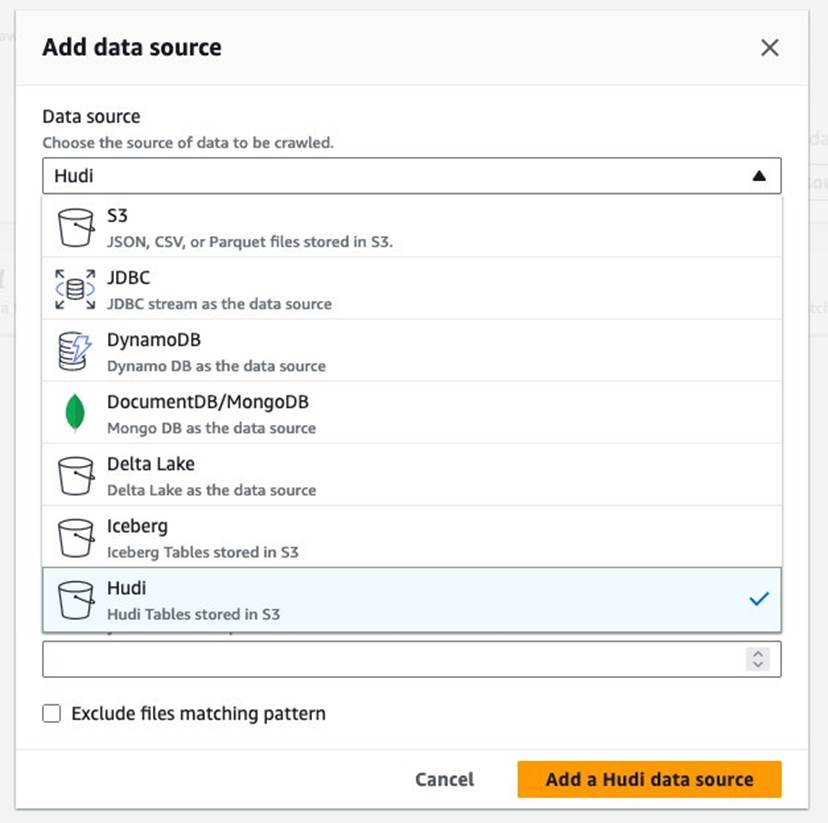
- Pentru Sursă de date, alege Hudi.
- Pentru Includeți căile pentru tabelul hudi, introduce
s3://your_s3_bucket/data/sample_hudi_cow_table/. (A inlocuiyour_s3_bucketcu numele găleții dvs. S3.) - Alege Adăugați sursa de date Hudi.
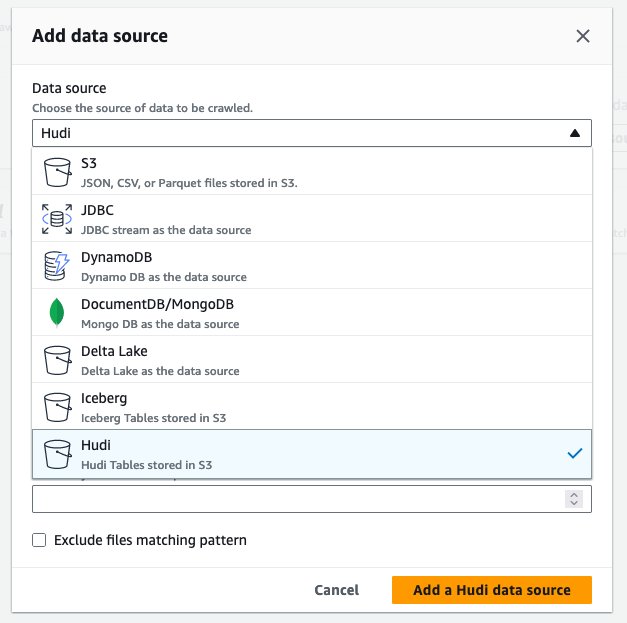
- Alege Pagina Următoare →.
- Pentru Rol IAM existent, alegeți rolul dvs. IAM, apoi alegeți Pagina Următoare →.
- Pentru Baza de date țintă, alege Adăugați o bază de date, apoi Adăugați o bază de date apare dialogul. Pentru Numele bazei de date, introduce
hudi_crawler_blog, Apoi alegeți Crea. Alege Pagina Următoare →. - Alege Creați un crawler.
Acum un nou crawler Hudi a fost creat cu succes. Crawler-ul poate fi declanșat să ruleze prin consolă sau prin SDK-ul sau AWS CLI folosind StartCrawl API. De asemenea, ar putea fi programat prin consolă pentru a declanșa crawlerele la anumite ore. În această instrucțiune, rulați crawler-ul prin consolă.
- Alege Rulați crawlerul.
- Așteptați ca crawler-ul să se finalizeze.
După rularea crawler-ului, puteți vedea definiția tabelului Hudi în consola AWS Glue:
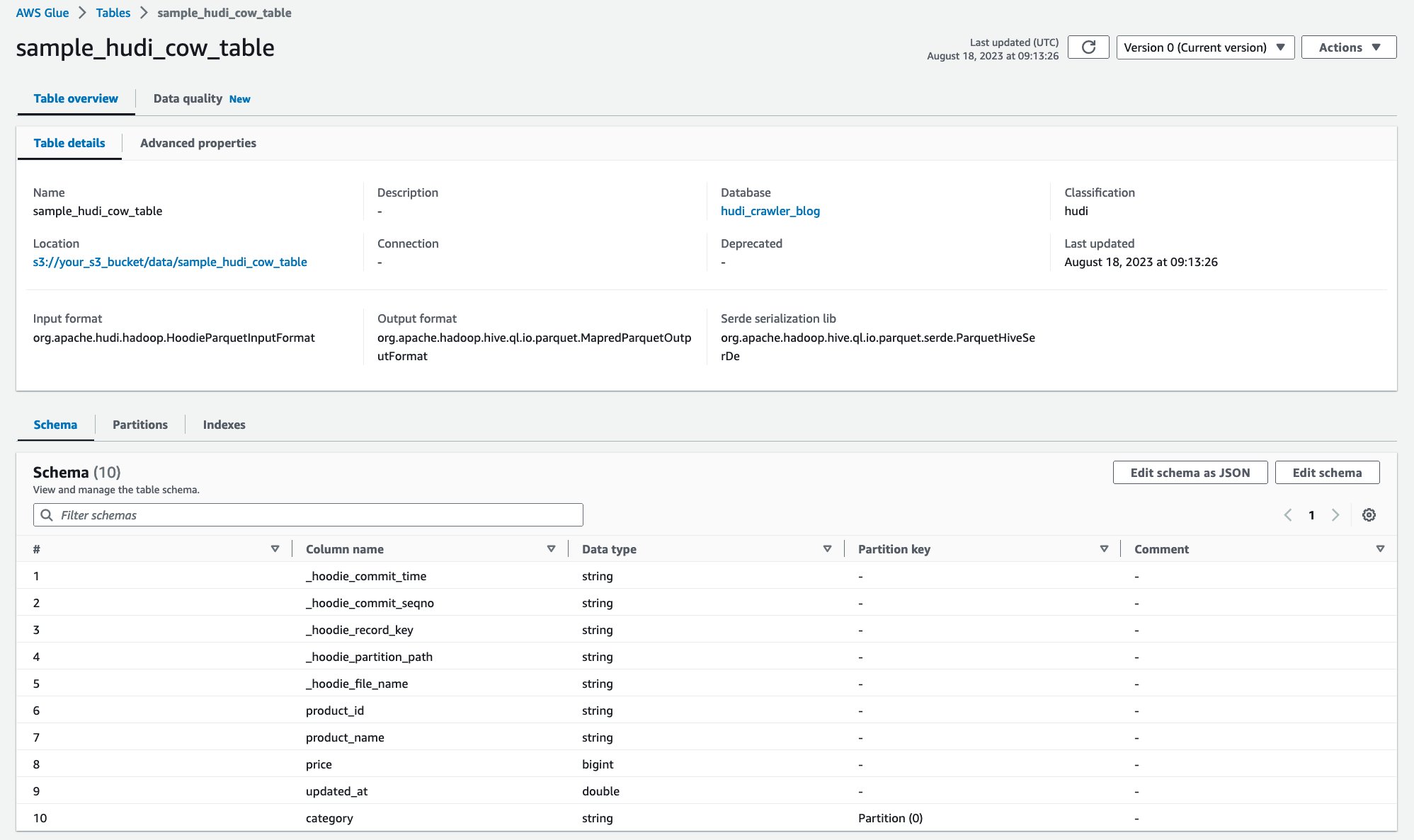
Ați accesat cu crawlere tabelul Hudi CoR cu date de pe Amazon S3 și ați creat un tabel AWS Glue Data Catalog cu schema populată. După ce creați definiția tabelului în AWS Glue Data Catalog, serviciile de analiză AWS, cum ar fi Amazon Athena, pot interoga tabelul Hudi.
Parcurgeți următorii pași pentru a începe interogări pe Athena:
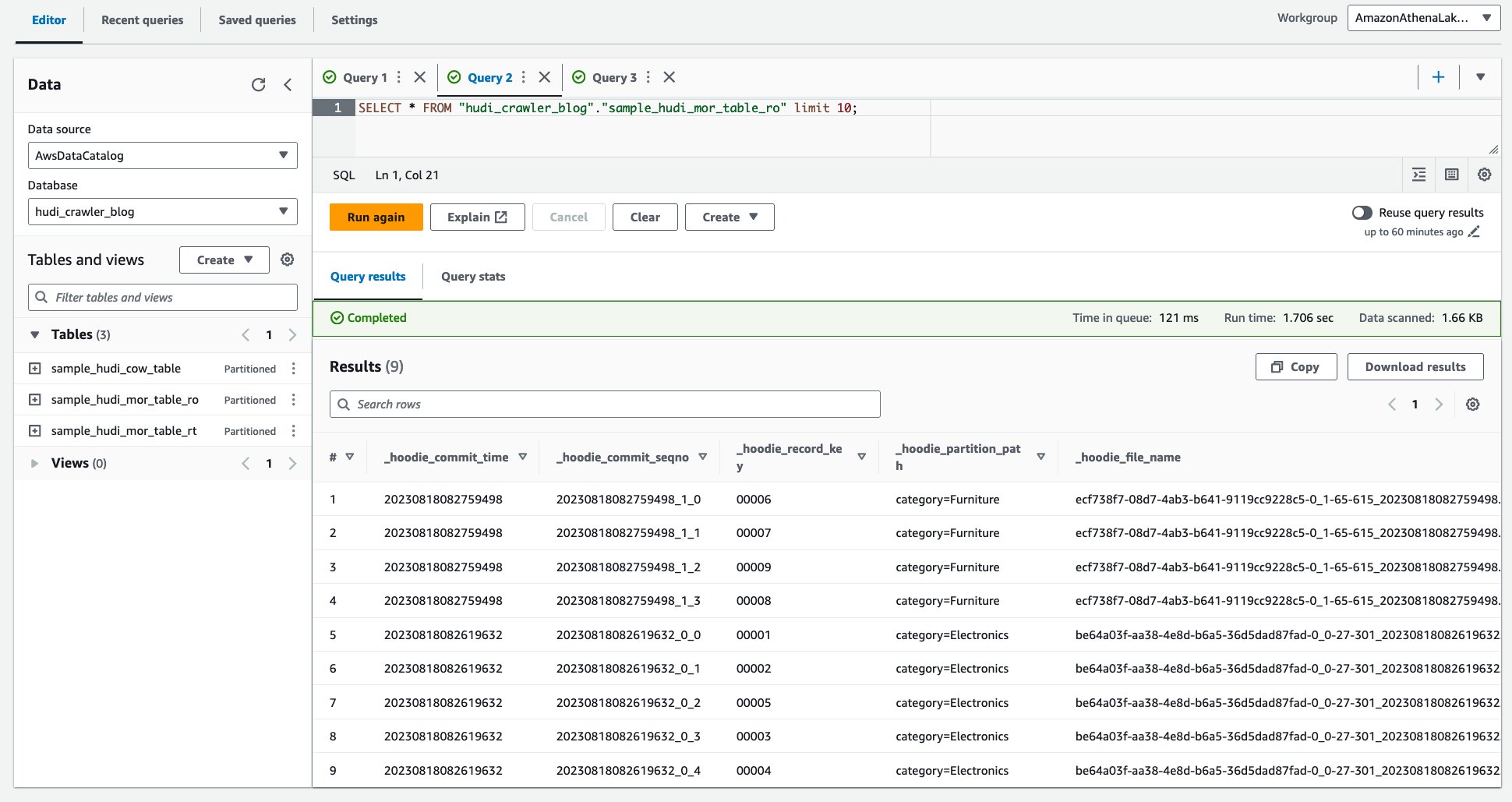
- Deschideți consola Amazon Athena.
- Rulați următoarea interogare.
Următoarea captură de ecran arată rezultatul nostru:
Accesați cu crawlere un tabel Hudi MoR utilizând crawlerul AWS Glue cu permisiuni pentru date AWS Lake Formation
În această secțiune, să vedem cum să accesați cu crawlere un tabel Hudi MoR folosind AWS Glue. De data aceasta, utilizați permisiunea de date AWS Lake Formation pentru accesarea cu crawlere a surselor de date Amazon S3 în loc de permisiunea IAM și Amazon S3. Acest lucru este opțional, dar simplifică configurațiile de permisiuni atunci când lacul dvs. de date este gestionat de permisiunile AWS Lake Formation.
Cerințe preliminare
Iată premisele pentru acest tutorial:
- Instalați și configurați Interfață linie de comandă AWS (AWS CLI).
- Creați-vă bucket-ul S3 dacă nu îl aveți.
- Creați-vă rolul IAM pentru AWS Glue daca nu il ai. Ai nevoie
lakeformation:GetDataAccess. Dar nu ai nevoies3:GetObjectpentrus3://your_s3_bucket/data/sample_hudi_mor_table/deoarece folosim permisiunea de date Lake Formation pentru a accesa fișierele. - Rulați următoarea comandă pentru a copia exemplul de tabel Hudi în compartimentul dvs. S3. (A inlocui
your_s3_bucketcu numele găleții dvs. S3.)
În plus față de pașii de procesare, parcurgeți următorii pași pentru a actualiza setările AWS Glue Data Catalog pentru a utiliza permisiunile Lake Formation pentru a controla resursele de catalog în loc de controlul accesului bazat pe IAM:
- Conectați-vă la consola Lake Formation ca administrator al lacului de date.
- Dacă aceasta este prima dată când accesați consola Lake Formation, adăugați-vă ca administrator al lacului de date.
- În Administrare, alege Setări pentru catalogul de date.
- Pentru Permisiuni implicite pentru bazele de date și tabele nou create, deselectați Utilizați numai controlul accesului IAM pentru noile baze de date și Utilizați numai controlul accesului IAM pentru tabele noi din bazele de date noi.
- Pentru Setarea versiunii pentru mai multe conturi, alege versiune 3.
- Alege Economisiți.
Următorul pas este să vă înregistrați găleata S3 în locațiile lacurilor de date Lake Formation:
- Pe consola Lake Formation, alegeți Locațiile lacului de dateși alegeți Înregistrați locația.
- Pentru Calea Amazon S3, introduce
s3://your_s3_bucket/. (A inlocuiyour_s3_bucketcu numele găleții dvs. S3.) - Alege Înregistrați locația.
Apoi, acordați rolului crawler Glue acces la locația datelor, astfel încât crawler-ul să poată folosi permisiunea Lake Formation pentru a accesa datele și a crea tabele în locație:
- Pe consola Lake Formation, alegeți Locațiile datelor Și alegeți Grant.
- Pentru Utilizatori și roluri IAM, selectați rolul IAM pe care l-ați folosit pentru crawler.
- Pentru Locație de depozitare, introduce
s3://your_s3_bucket/data/. (A inlocuiyour_s3_bucketcu numele găleții dvs. S3.) - Alege Grant.
Apoi, acordați rolul crawlerului pentru a crea tabele în baza de date hudi_crawler_blog:
- Pe consola Lake Formation, alegeți Permisiunile lacului de date.
- Alege Grant.
- Pentru Directorii, alege Utilizatori și roluri IAMși alegeți rolul crawlerului.
- Pentru Etichete LF sau resurse de catalog, alege Resurse de catalog de date denumite.
- Pentru Baza de date, alege baza de date
hudi_crawler_blog. - În Permisiunile bazei de date, Selectați Creați tabel.
- Alege Grant.
Creați un crawler Hudi cu permisiuni pentru date Lake Formation
Parcurgeți următorii pași pentru a crea un crawler Hudi:
- Pe consola AWS Glue, alegeți crawlere.
- Alege Creați un crawler.
- Pentru Nume si Prenume, introduce
hudi_mor_crawler. Alege Pagina Următoare →. - În Configurarea sursei de date, alege Adăugați o sursă de date.
- Pentru Sursă de date, alege Hudi.
- Pentru Includeți căile pentru tabelul hudi, introduce
s3://your_s3_bucket/data/sample_hudi_mor_table/. (A inlocuiyour_s3_bucketcu numele găleții dvs. S3.) - Alege Adăugați sursa de date Hudi.
- Alege Pagina Următoare →.
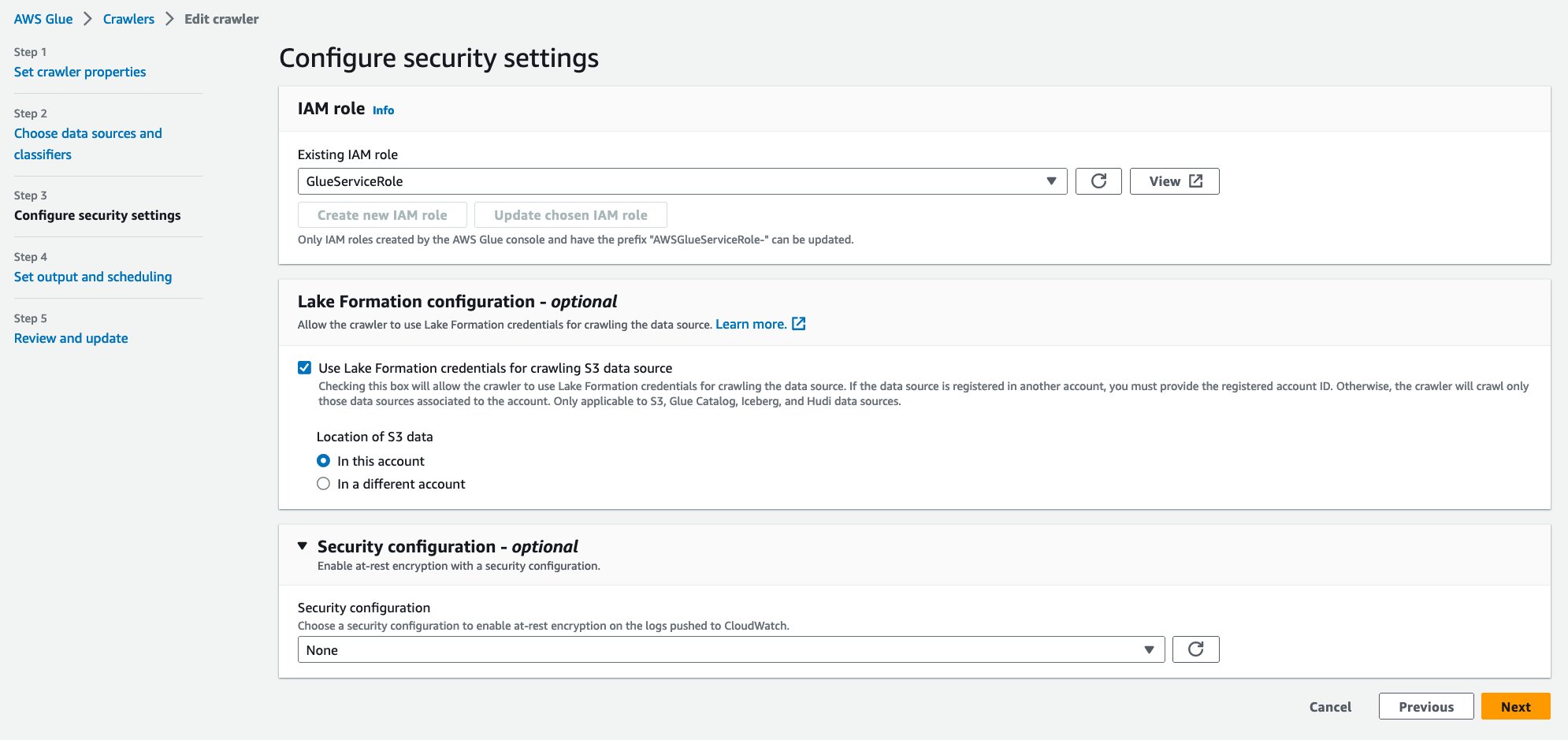
- Pentru Rol IAM existent, alegeți rolul dvs. IAM.
- În Configurația Lake Formation – opțional, Selectați Utilizați acreditările Lake Formation pentru accesarea cu crawlere a sursei de date S3.
- Alege Pagina Următoare →.
- Pentru Baza de date țintă, alege
hudi_crawler_blog. Alege Pagina Următoare →. - Alege Creați un crawler.
Acum un nou crawler Hudi a fost creat cu succes. Crawler-ul folosește acreditările Lake Formation pentru accesarea cu crawlere a fișierelor Amazon S3. Să rulăm noul crawler:
- Alege Rulați crawlerul.
- Așteptați ca crawler-ul să se finalizeze.
După rularea crawler-ului, puteți vedea două tabele cu definiția tabelului Hudi în consola AWS Glue:
sample_hudi_mor_table_ro(citește tabelul optimizat)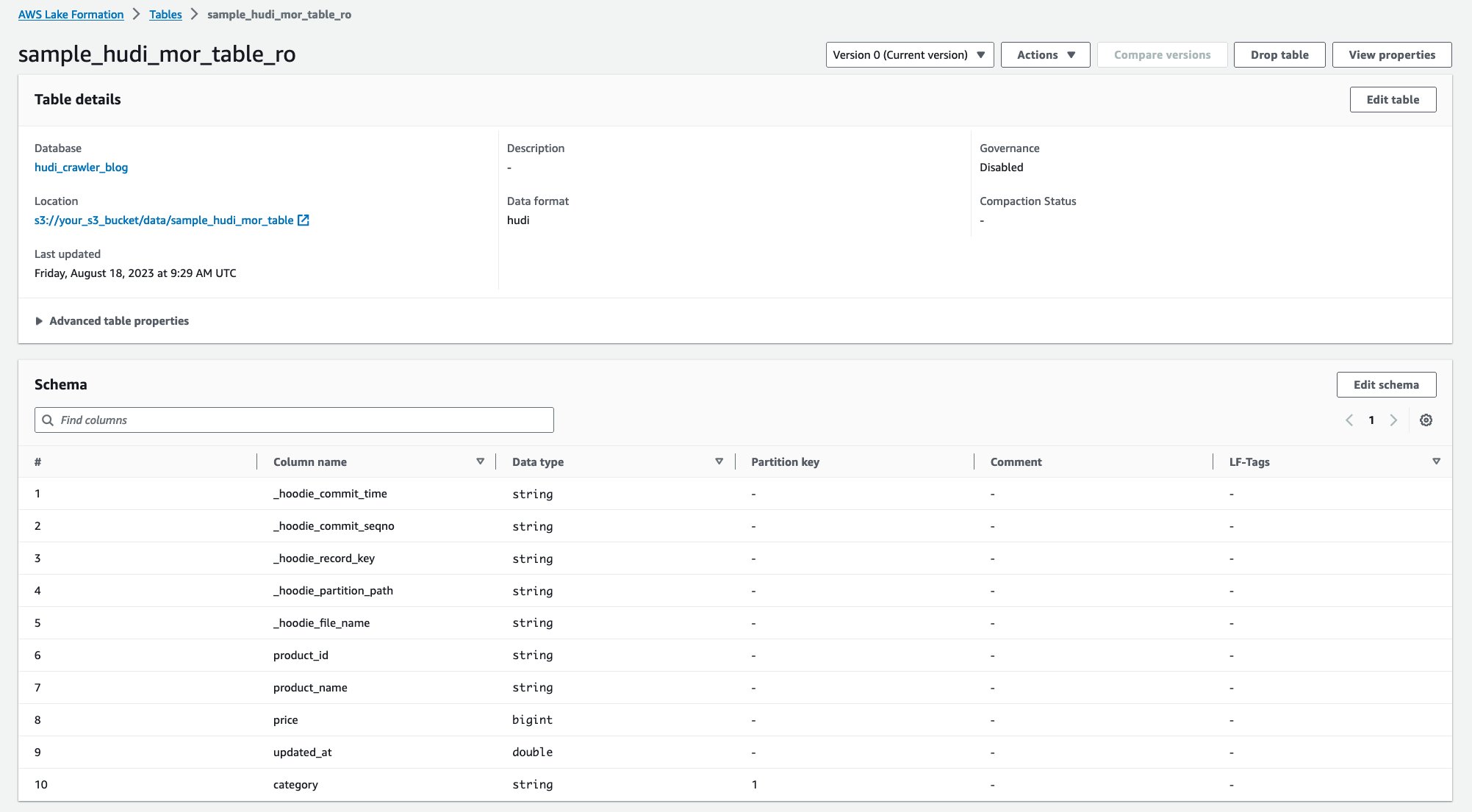
sample_hudi_mor_table_rt(tabel în timp real)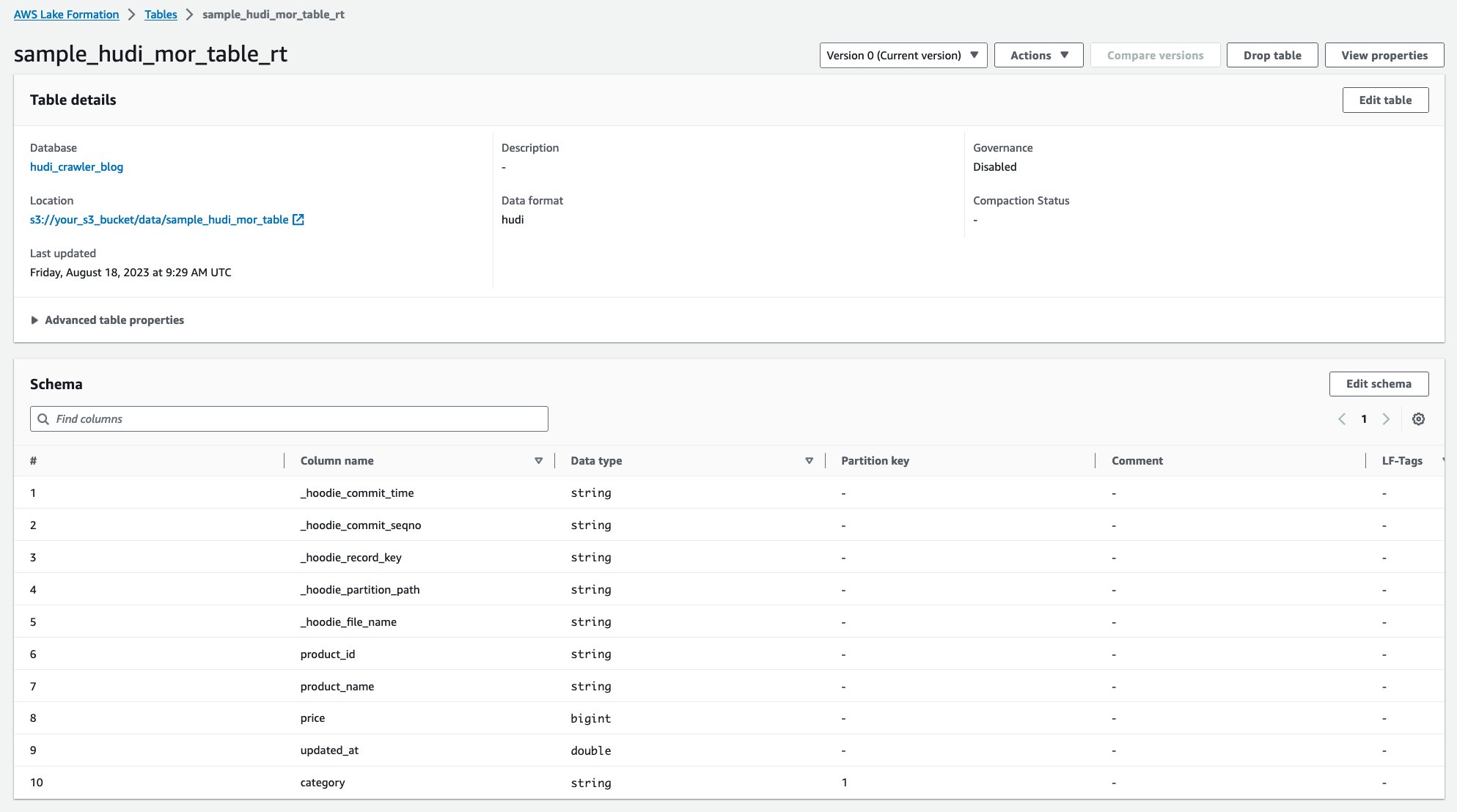
Ați înregistrat compartimentul lacului de date cu Lake Formation și ați activat accesul cu crawlere la lacul de date folosind permisiunile Lake Formation. Ați accesat cu crawlere tabelul Hudi MoR cu date de pe Amazon S3 și ați creat un tabel AWS Glue Data Catalog cu schema populată. După ce creați definițiile tabelelor în AWS Glue Data Catalog, serviciile de analiză AWS, cum ar fi Amazon Athena, pot interoga tabelul Hudi.
Parcurgeți următorii pași pentru a începe interogări pe Athena:
- Deschideți consola Amazon Athena.
- Rulați următoarea interogare.
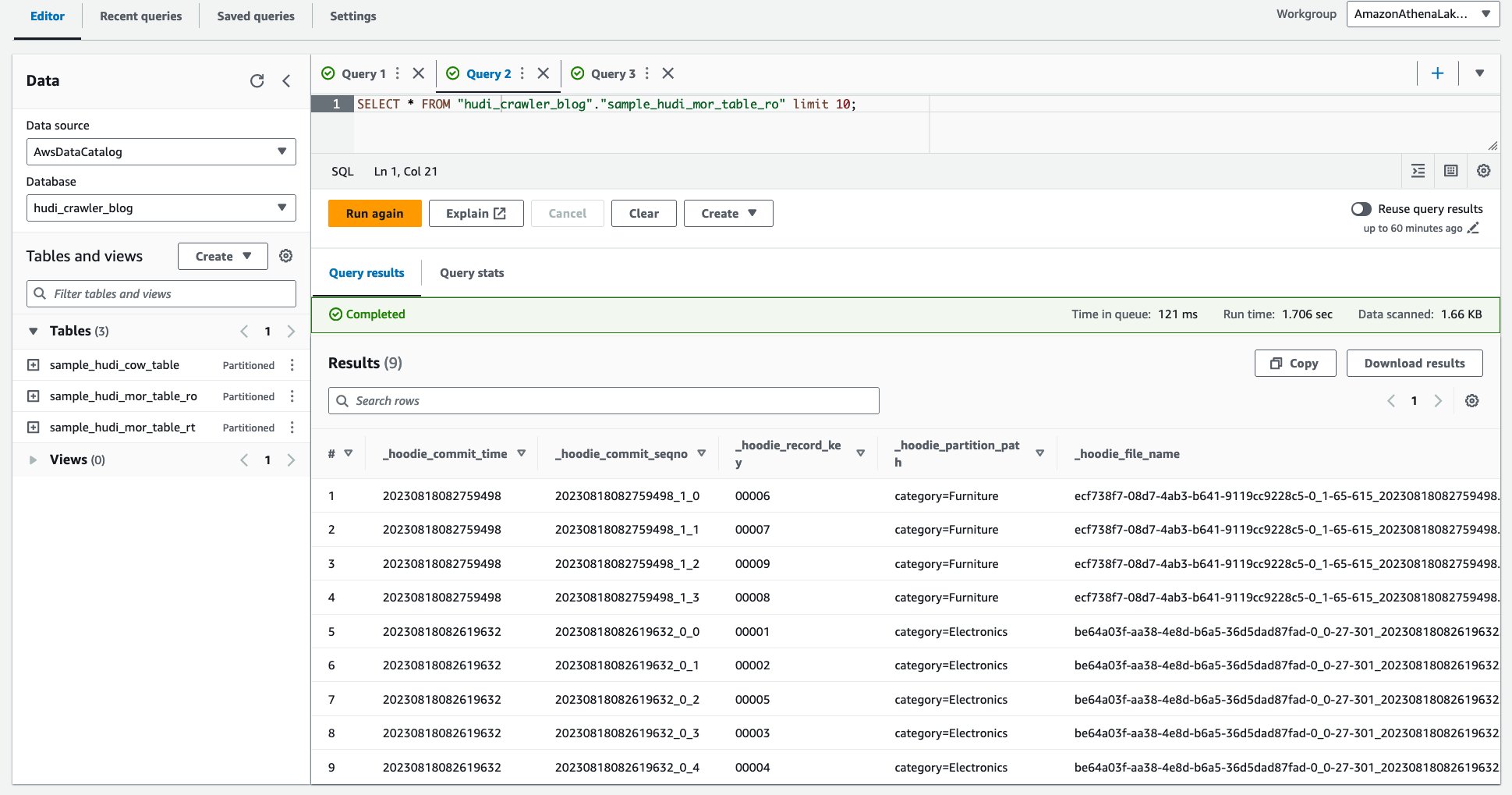
Următoarea captură de ecran arată rezultatul nostru:
- Rulați următoarea interogare.
Următoarea captură de ecran arată rezultatul nostru:
Control precis al accesului folosind permisiunile AWS Lake Formation
Pentru a aplica un control precis al accesului pe tabelul Hudi, puteți beneficia de permisiunile AWS Lake Formation. Permisiunile Lake Formation vă permit să restricționați accesul la anumite tabele, coloane sau rânduri și apoi să interogați tabelele Hudi prin Amazon Athena cu un control de acces precis. Să configuram permisiunea Lake Formation pentru tabelul Hudi MoR.
Cerințe preliminare
Iată premisele pentru acest tutorial:
- Completați secțiunea anterioară Accesați cu crawlere un tabel Hudi MoR utilizând crawlerul AWS Glue cu permisiuni pentru date AWS Lake Formation.
- Creați un utilizator IAM DataAnalyst, care are o politică gestionată de AWS AmazonAthenaFullAccess.
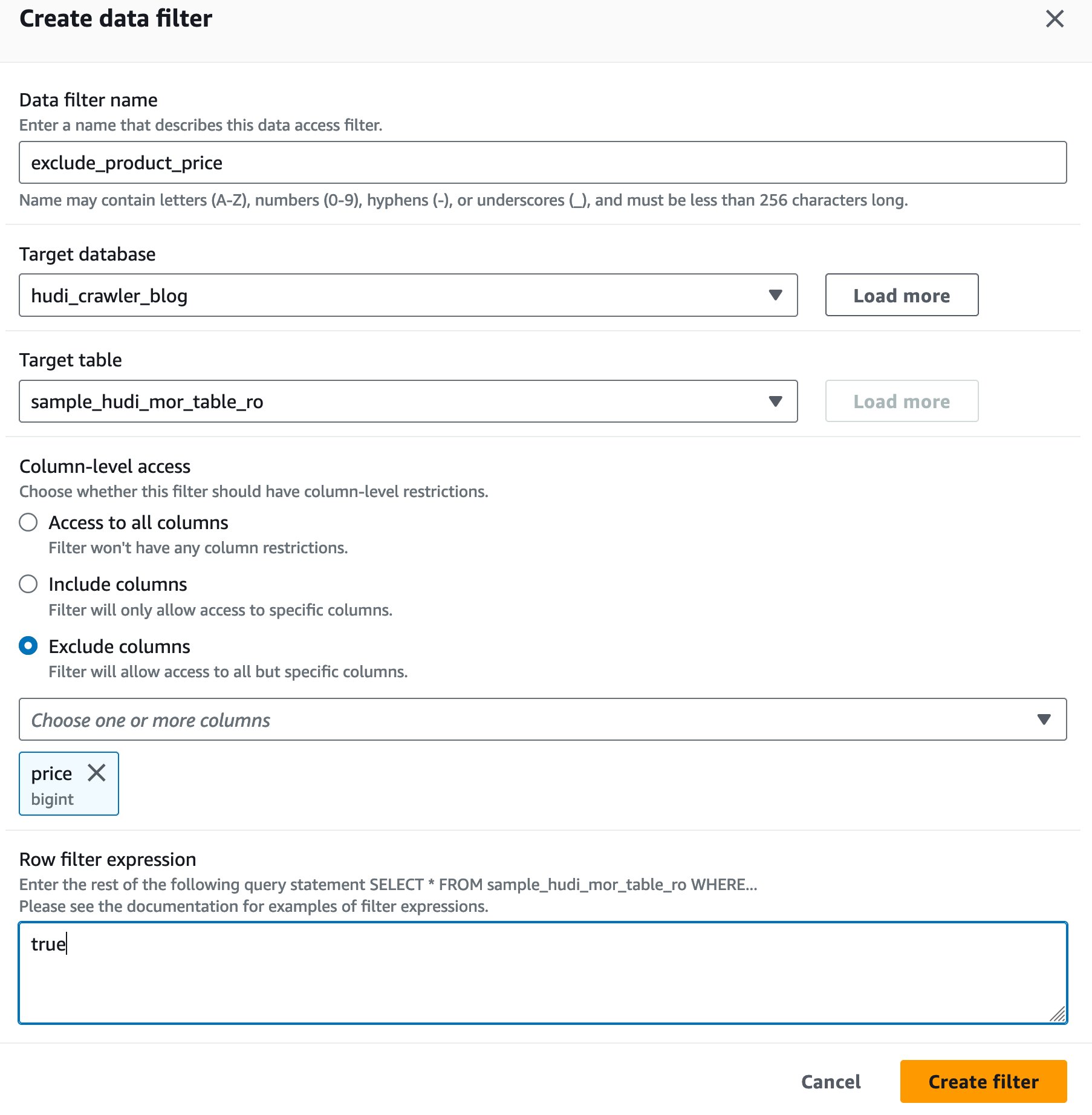
Creați un filtru de celule de date Lake Formation
Să setăm mai întâi un filtru pentru tabelul optimizat pentru citire MoR.
- Conectați-vă la consola Lake Formation ca administrator al lacului de date.
- Alege Filtre de date.
- Alege Creați un filtru nou.
- Pentru Numele filtrului de date, introduce
exclude_product_price. - Pentru Baza de date țintă, alege baza de date
hudi_crawler_blog. - Pentru Tabel țintă, alegeți masa
sample_hudi_mor_table_ro. - Pentru La nivel de coloană accesați, selectați Excludeți coloaneleși alegeți prețul coloanei.
- Pentru Expresie filtru rând, introduce
true. - Alege Creați filtru.
Acordați permisiuni pentru Lake Formation utilizatorului DataAnalyst
Parcurgeți următorii pași pentru a acorda permisiunea Lake Formation DataAnalyst utilizator
- Pe consola Lake Formation, alegeți Permisiunile lacului de date.
- Alege Grant.
- Pentru Directorii, alege Utilizatori și roluri IAMși alegeți utilizatorul
DataAnalyst. - Pentru Etichete LF sau resurse de catalog, alege Resurse de catalog de date denumite.
- Pentru Baza de date, alege baza de date
hudi_crawler_blog. - Pentru Masa – optional, alegeți masa
sample_hudi_mor_table_ro. - Pentru Filtre de date – opțional, Selectați
exclude_product_price. - Pentru Permisiuni de filtrare a datelor, Selectați Selectați.
- Alege Grant.
Ați acordat permisiunea Lake Formation în baza de date hudi_crawler_blog si masa sample_hudi_mor_table_ro, excluzând coloana price către utilizatorul DataAnalyst. Acum să validăm accesul utilizatorului la date folosind Athena.
- Conectați-vă la consola Athena ca utilizator DataAnalyst.
- În editorul de interogări, rulați următoarea interogare:
Următoarea captură de ecran arată rezultatul nostru:
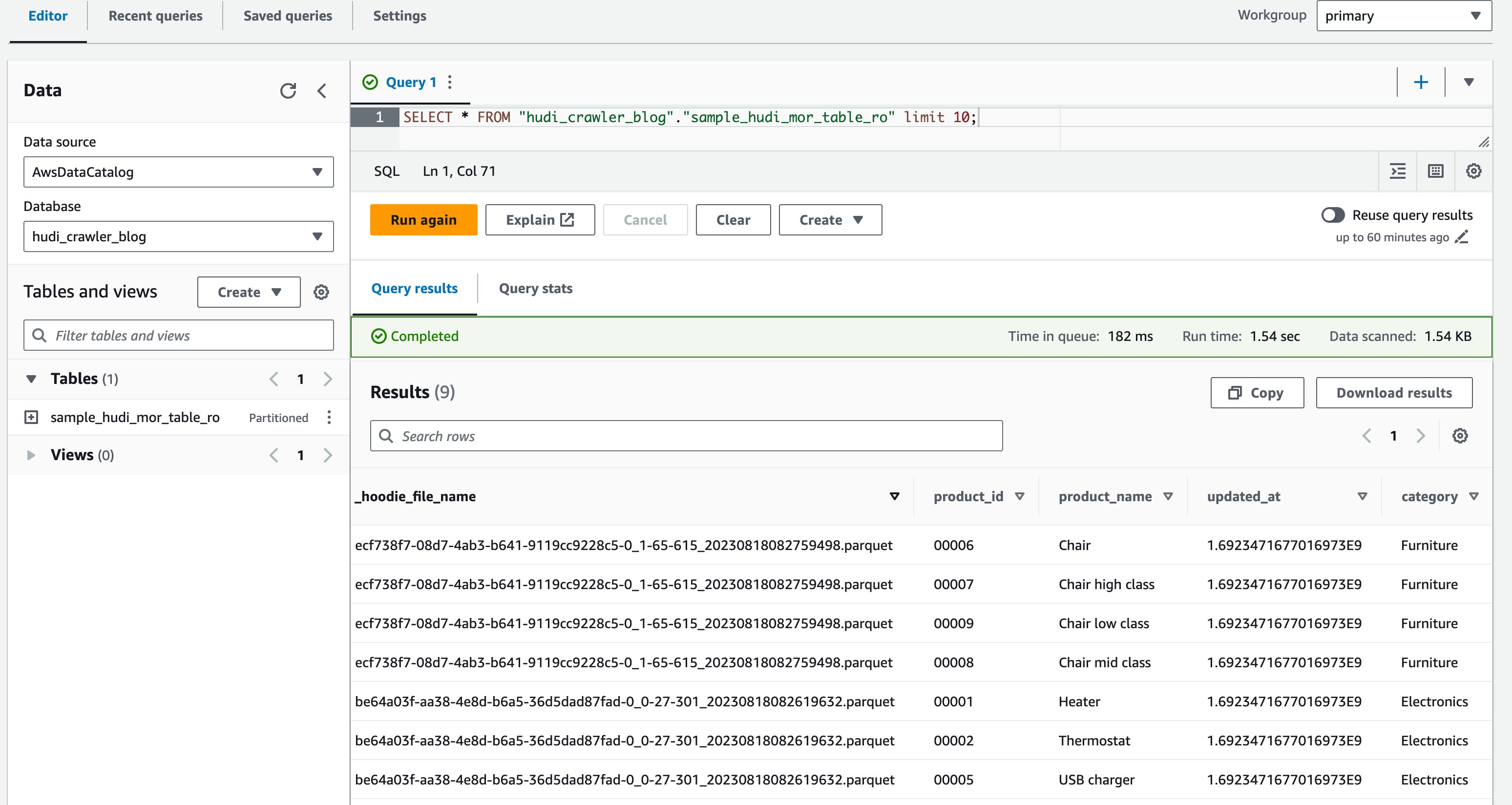
Acum ați validat că coloana price nu este afișat, dar celelalte coloane product_id, product_name, update_at, și category sunt afișate.
A curăța
Pentru a evita taxele nedorite către contul dvs. AWS, ștergeți următoarele resurse AWS:
- Ștergeți baza de date AWS Glue
hudi_crawler_blog. - Ștergeți crawlerele AWS Glue
hudi_cow_crawlerșihudi_mor_crawler. - Ștergeți fișierele Amazon S3 de sub
s3://your_s3_bucket/data/sample_hudi_cow_table/șis3://your_s3_bucket/data/sample_hudi_mor_table/.
Concluzie
Această postare a demonstrat cum funcționează crawlerele AWS Glue pentru tabelele Hudi. Cu suportul pentru crawler Hudi, puteți trece rapid la utilizarea AWS Glue Data Catalog ca catalog principal de tabel Hudi. Puteți începe să vă construiți lacul de date tranzacționale fără server folosind Hudi pe AWS folosind AWS Glue, AWS Glue Data Catalog și Lake Formation controale de acces cu granulație fină pentru tabelele și formatele acceptate de motoarele analitice AWS.
Despre autori
 Noritaka Sekiyama este arhitect principal de date mari în echipa AWS Glue. Lucrează în Tokyo, Japonia. El este responsabil pentru construirea de artefacte software pentru a ajuta clienții. În timpul liber, îi place să meargă cu bicicleta cu bicicleta de drum.
Noritaka Sekiyama este arhitect principal de date mari în echipa AWS Glue. Lucrează în Tokyo, Japonia. El este responsabil pentru construirea de artefacte software pentru a ajuta clienții. În timpul liber, îi place să meargă cu bicicleta cu bicicleta de drum.
 Kyle Duong este inginer de dezvoltare software în echipa AWS Glue and Lake Formation. Este pasionat de construirea de tehnologii de date mari și sisteme distribuite.
Kyle Duong este inginer de dezvoltare software în echipa AWS Glue and Lake Formation. Este pasionat de construirea de tehnologii de date mari și sisteme distribuite.
 Sandeep Adwankar este Senior Technical Product Manager la AWS. Cu sediul în California Bay Area, el lucrează cu clienți din întreaga lume pentru a traduce cerințele de afaceri și tehnice în produse care le permit clienților să îmbunătățească modul în care gestionează, securizează și accesează datele.
Sandeep Adwankar este Senior Technical Product Manager la AWS. Cu sediul în California Bay Area, el lucrează cu clienți din întreaga lume pentru a traduce cerințele de afaceri și tehnice în produse care le permit clienților să îmbunătățească modul în care gestionează, securizează și accesează datele.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :are
- :este
- :nu
- :Unde
- $UP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- Capabil
- Despre Noi
- acces
- Acces la date
- accesarea
- Cont
- Acțiune
- adăuga
- adăugat
- plus
- adoptată
- Adoptare
- avansat
- După
- TOATE
- permite
- Permiterea
- permite
- de asemenea
- Amazon
- Amazon Atena
- Amazon Web Services
- an
- Analitic
- Google Analytics
- și
- O alta
- Orice
- Apache
- Apache Spark
- api
- apare
- aplicație
- Dezvoltare de Aplicații
- Aplică
- SUNT
- ZONĂ
- în jurul
- AS
- At
- în mod automat
- evita
- AWS
- AWS Adeziv
- Formația lacului AWS
- de bază
- bazat
- Golf
- BE
- deoarece
- fost
- beneficia
- Mai bine
- Mare
- Datele mari
- Aduce
- Clădire
- construit
- afaceri
- dar
- by
- California
- apel
- CAN
- capacități
- capacitate
- caz
- catalog
- cataloage
- categorii
- celulă
- provocări
- Schimbare
- si-a schimbat hainele;
- Modificări
- taxe
- Alege
- Coloană
- Coloane
- combinaţie
- comite
- comise
- Completă
- complex
- component
- Configuraţie
- Consoleze
- conține
- conţinut
- continuu
- Control
- controale
- ar putea
- tractor pe şenile
- crea
- a creat
- creează
- scrisori de acreditare
- clienţii care
- de date
- integrarea datelor
- Lacul de date
- depozit de date
- Baza de date
- baze de date
- seturi de date
- definiție
- Definitii
- Deltă
- demonstrat
- demonstrează
- adâncime
- Dezvoltare
- direct
- descoperi
- distribuite
- sisteme distribuite
- do
- face
- în timpul
- fiecare
- mai ușor
- cu ușurință
- editor
- în mod eficient
- eficient
- permite
- activat
- inginer
- inginerii
- Motoare
- Intrați
- Eter (ETH)
- evoluție
- F? r?
- extrage
- mai repede
- mai puține
- Fișier
- Fişiere
- filtru
- Filtre
- Găsi
- First
- prima dată
- următor
- Pentru
- format
- formare
- frecvent
- din
- dat
- glob
- Go
- acordarea
- acordate
- Ghiduri
- Hadoop
- Avea
- he
- ajutor
- ajută
- lui
- Stup
- Cum
- Cum Pentru a
- HTML
- HTTPS
- IAM
- if
- implicații
- îmbunătăţi
- in
- Inclusiv
- incrementală
- informații
- in schimb
- integra
- integrare
- interfaţă
- în
- introducerea
- IT
- Japonia
- jpg
- păstrare
- lac
- lacuri
- Ultimele
- lansa
- AFLAȚI
- învăţare
- mai puțin
- LIMITĂ
- Linie
- Listă
- situat
- locaţie
- Locații
- autentificat
- maşină
- masina de învățare
- mentine
- face
- FACE
- administra
- gestionate
- manager
- de conducere
- manual
- maxim
- care fuzionează
- Metadata
- Migrarea
- migrațiune
- ML
- mai mult
- cele mai multe
- muta
- multiplu
- nume
- nativ
- Nevoie
- necesar
- Nou
- recent
- următor
- acum
- of
- on
- ONE
- afară
- deschide
- open-source
- optimizate
- Opțiune
- or
- Altele
- al nostru
- producție
- parte
- pasionat
- cale
- căi
- performanță
- permisiune
- permisiuni
- Plato
- Informații despre date Platon
- PlatoData
- Popular
- populat
- Post
- Pregăti
- premise
- precedent
- preţ
- primar
- Principal
- prelucrare
- Produs
- manager de produs
- Produse
- furniza
- prevăzut
- furnizează
- interogări
- repede
- Citeste
- real
- în timp real
- în timp real
- recent
- record
- Inregistreaza-te
- înregistrată
- înlocui
- Cerinţe
- Resurse
- responsabil
- restrânge
- drum
- Rol
- RÂND
- Alerga
- acelaşi
- programa
- programată
- sdk
- Secțiune
- sigur
- vedea
- selecta
- senior
- serverless
- serviciu
- Servicii
- set
- setări
- indicat
- Emisiuni
- Simplifică
- întrucât
- singur
- Felie
- Instantaneu
- So
- Software
- de dezvoltare de software
- Sursă
- Surse
- Scânteie
- specific
- Începe
- Stat
- Pas
- paşi
- stocate
- de streaming
- fluxuri
- studio
- Reușit
- astfel de
- a sustine
- Suportat
- sincronizare
- sisteme
- tabel
- echipă
- Tehnic
- Tehnologii
- acea
- lor
- apoi
- Acolo.
- ei
- acest
- trei
- Prin
- timp
- ori
- la
- Tokyo
- top
- tranzacțional
- Tranzacții
- Traduceți
- traversa
- declanşa
- a declanșat
- tutorial
- Două
- Tipuri
- tipic
- în
- nedorit
- Actualizează
- actualizat
- actualizări
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizatorii
- utilizări
- folosind
- VALIDA
- validate
- Valori
- versiune
- vizual
- Depozit
- we
- web
- servicii web
- BINE
- cand
- care
- în timp ce
- OMS
- voi
- cu
- fără
- Apartamente
- fabrică
- scrie
- scris
- tu
- Ta
- te
- zephyrnet