În acest articol vom învăța cum să implementați și să utilizați modelul GPT4All pe computerul dvs. numai cu CPU (Eu folosesc un Macbook Pro fără GPU!)

Utilizați GPT4All pe computerul dvs. — Imagine a autorului
În acest articol vom instala pe computerul nostru local GPT4All (un LLM puternic) și vom descoperi cum să interacționăm cu documentele noastre cu python. O colecție de PDF-uri sau articole online va fi baza de cunoștințe pentru întrebările/răspunsurile noastre.
De la site-ul oficial GPT4All este descris ca un chatbot gratuit, care rulează local și care ține cont de confidențialitate. Nu este necesar GPU sau internet.
GTP4All este un ecosistem de antrenat și implementat puternic și personalizate modele de limbaj mari care rulează la nivel local pe CPU-uri de consum.
Modelul nostru GPT4All este un fișier de 4 GB pe care îl puteți descărca și conecta la software-ul ecosistemului open-source GPT4All. Nomic AI facilitează ecosisteme software de înaltă calitate și sigure, determinând efortul de a permite indivizilor și organizațiilor să se antreneze și să implementeze fără efort propriile modele de limbă mari la nivel local.
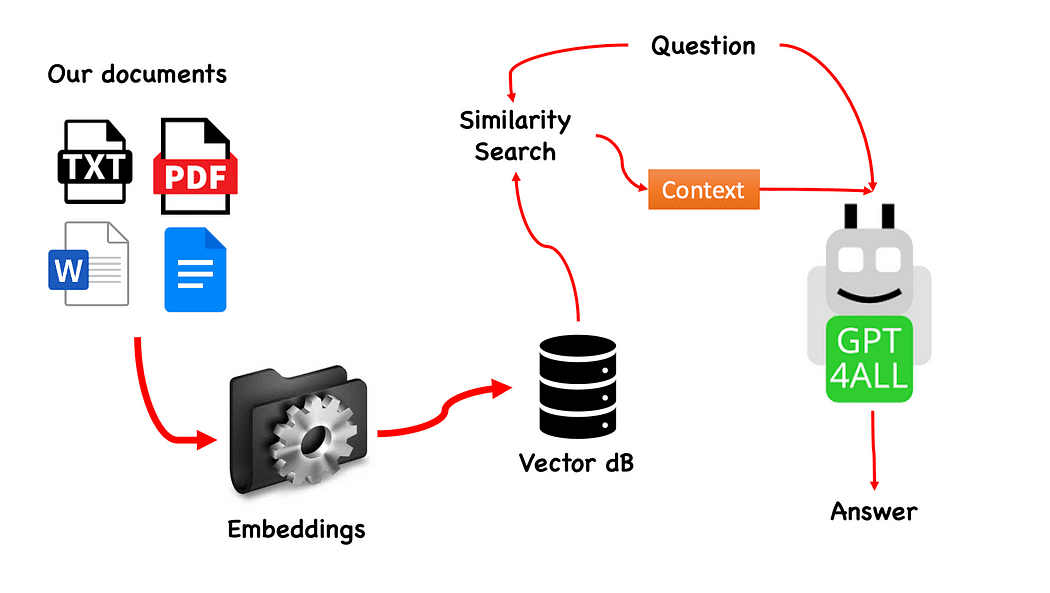
Fluxul de lucru al QnA cu GPT4All — creat de autor
Procesul este foarte simplu (când îl știți) și poate fi repetat și cu alte modele. Pașii sunt următorii:
- încărcați modelul GPT4All
- utilizare Langchain pentru a ne prelua documentele și a le încărca
- împărțiți documentele în bucăți mici digerabile prin încorporare
- Utilizați FAISS pentru a crea baza noastră de date vectorială cu înglobările
- Efectuați o căutare de similaritate (căutare semantică) în baza noastră de date vectorială pe baza întrebării pe care vrem să o transmitem la GPT4All: aceasta va fi folosită ca un context pentru intrebarea noastra
- Introduceți întrebarea și contextul la GPT4All cu Langchain și așteptați răspunsul.
Deci avem nevoie de Embeddings. O încorporare este o reprezentare numerică a unei informații, de exemplu, text, documente, imagini, audio etc. Reprezentarea surprinde semnificația semantică a ceea ce este încorporat și exact de asta avem nevoie. Pentru acest proiect nu ne putem baza pe modele GPU grele: așa că vom descărca modelul nativ Alpaca și vom folosi de la Langchain il LlamaCppEmbeddings. Nu vă faceți griji! Totul este explicat pas cu pas
Creați un mediu virtual
Creați un folder nou pentru noul dvs. proiect Python, de exemplu GPT4ALL_Fabio (puneți-vă numele...):
mkdir GPT4ALL_Fabio
cd GPT4ALL_FabioApoi, creați un nou mediu virtual Python. Dacă aveți mai multe versiuni python instalate, specificați versiunea dorită: în acest caz voi folosi instalarea mea principală, asociată cu python 3.10.
python3 -m venv .venvComanda python3 -m venv .venv creează un nou mediu virtual numit .venv (punctul va crea un director ascuns numit venv).
Un mediu virtual oferă o instalare Python izolată, care vă permite să instalați pachete și dependențe doar pentru un anumit proiect, fără a afecta instalarea Python la nivel de sistem sau alte proiecte. Această izolare ajută la menținerea coerenței și la prevenirea potențialelor conflicte între diferitele cerințe ale proiectului.
Odată creat mediul virtual, îl puteți activa folosind următoarea comandă:
source .venv/bin/activate 
Mediu virtual activat
Bibliotecile de instalat
Pentru proiectul pe care îl construim nu avem nevoie de prea multe pachete. Avem nevoie doar de:
- legături python pentru GPT4All
- Langchain pentru a interacționa cu documentele noastre
LangChain este un cadru pentru dezvoltarea aplicațiilor bazate pe modele de limbaj. Vă permite nu numai să apelați la un model de limbă prin intermediul unui API, ci și să conectați un model de limbă la alte surse de date și să permiteți unui model de limbă să interacționeze cu mediul său.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4Pentru LangChain vedeți că am specificat și versiunea. Această bibliotecă primește o mulțime de actualizări recent, așa că pentru a fi siguri că setarea noastră va funcționa și mâine, este mai bine să specificați o versiune despre care știm că funcționează bine. Nestructurat este o dependență necesară pentru încărcătorul PDF și pitesseract și pdf2imagine de asemenea.
NOTĂ: în depozitul GitHub există un fișier requirements.txt (sugerat de jl adcr) cu toate versiunile asociate acestui proiect. Puteți face instalarea dintr-o singură lovitură, după ce o descărcați în directorul principal al fișierului de proiect cu următoarea comandă:
pip install -r requirements.txtLa finalul articolului am creat un secțiune pentru depanare. Depozitul GitHub are, de asemenea, un READ.ME actualizat cu toate aceste informații.
Țineți minte că unii bibliotecile au versiuni disponibile în funcție de versiunea python rulați în mediul dvs. virtual.
Descărcați pe computer modelele
Acesta este un pas cu adevărat important.
Pentru proiect avem nevoie cu siguranță de GPT4All. Procesul descris pe Nomic AI este cu adevărat complicat și necesită hardware pe care nu toți îl avem (ca mine). Asa de aici este linkul spre model deja convertit și gata de utilizare. Doar faceți clic pe descărcare.
Descărcați modelul GPT4All
După cum este descris pe scurt în introducere, avem nevoie și de modelul pentru înglobare, un model pe care îl putem rula pe procesorul nostru fără a zdrobi. Apasă pe link aici pentru a descărca alpaca-native-7B-ggml deja convertit la 4 biți și gata de utilizare pentru a acționa ca modelul nostru pentru încorporare.

Faceți clic pe săgeata de descărcare de lângă ggml-model-q4_0.bin
De ce avem nevoie de încorporare? Dacă vă amintiți din diagrama de flux, primul pas necesar, după ce colectăm documentele pentru baza noastră de cunoștințe, este să încastra lor. Embedding-urile LLamaCPP de la acest model Alpaca se potrivesc perfect cu munca si acest model este si el destul de mic (4 Gb). Apropo, puteți folosi și modelul Alpaca pentru QnA!
Actualizare 2023.05.25: Utilizatorii Mani Windows se confruntă cu probleme de utilizare a înglobărilor llamaCPP. Acest lucru se întâmplă în principal deoarece în timpul instalării pachetului python llama-cpp-python cu:
pip install llama-cpp-pythonpachetul pip va compila din sursă biblioteca. De obicei, Windows nu are CMake sau compilatorul C instalat implicit pe mașină. Dar nu vă îngrijorați, există o soluție
Rularea instalării llama-cpp-python, cerută de LangChain cu llamaEmbeddings, pe Windows CMake C complier nu este instalat în mod implicit, deci nu puteți construi din sursă.
Pe utilizatorii Mac cu Xtools și pe Linux, de obicei, C complier este deja disponibil pe sistemul de operare.
Pentru a evita problema TREBUIE să utilizați roata pre-respectată.
Du-te aici https://github.com/abetlen/llama-cpp-python/releases
și căutați roata conformă pentru arhitectura dvs. și versiunea python - TREBUIE să luați Weels Versiunea 0.1.49 deoarece versiunile superioare nu sunt compatibile.
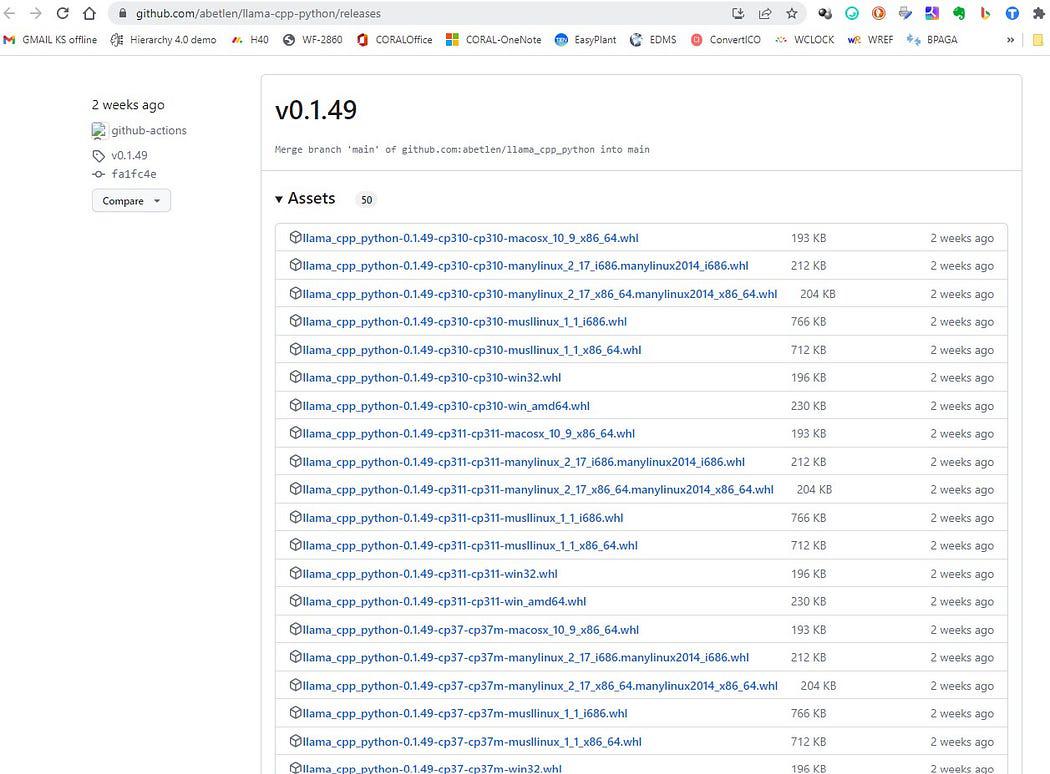
Captură de ecran de la https://github.com/abetlen/llama-cpp-python/releases
În cazul meu am Windows 10, 64 de biți, python 3.10
deci fișierul meu este llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
Acest problema este urmărită în depozitul GitHub
După descărcare, trebuie să puneți cele două modele în directorul de modele, așa cum se arată mai jos.

Structura directorului și unde să plasați fișierele model
Deoarece dorim să avem controlul asupra interacțiunii noastre cu modelul GPT, trebuie să creăm un fișier python (să-l numim pygpt4all_test.py), importați dependențele și dați instrucțiunile modelului. Veți vedea că este destul de ușor.
from pygpt4all.models.gpt4all import GPT4AllAceasta este legarea python pentru modelul nostru. Acum putem să-l sunăm și să începem să întrebăm. Să încercăm unul creativ.
Creăm o funcție care citește apelul înapoi din model și îi cerem lui GPT4All să completeze propoziția.
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)Prima declarație spune programului nostru unde să găsească modelul (amintiți-vă ce am făcut în secțiunea de mai sus)
A doua afirmație cere modelului să genereze un răspuns și să completeze promptul nostru „A fost odată ca niciodată”.
Pentru a-l rula, asigurați-vă că mediul virtual este încă activat și pur și simplu rulați:
python3 pygpt4all_test.pyAr trebui să vedeți un text de încărcare al modelului și completarea propoziției. În funcție de resursele hardware, poate dura puțin timp.
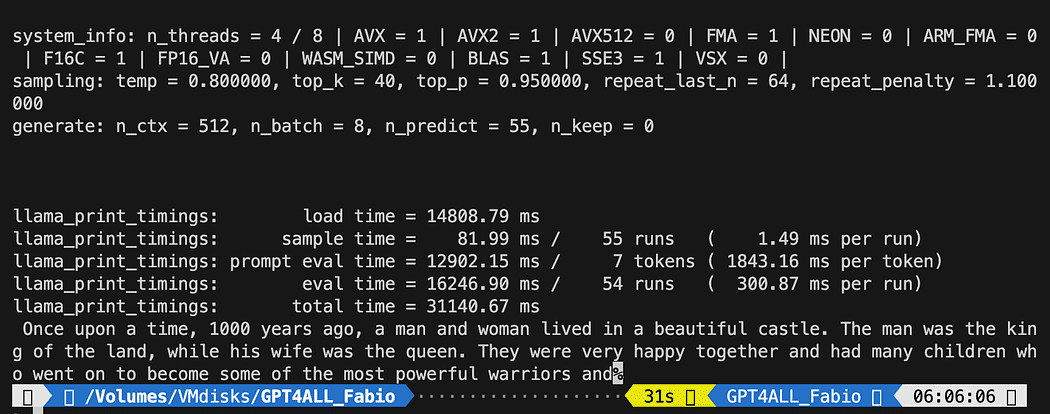
Rezultatul poate fi diferit de al tău... Dar pentru noi, important este că funcționează și putem continua cu LangChain pentru a crea niște lucruri avansate.
NOTĂ (actualizat 2023.05.23): dacă vă confruntați cu o eroare legată de pygpt4all, verificați secțiunea de depanare pe acest subiect cu soluția dată de Rajneesh Aggarwal or de Oscar Jeong.
Cadrul LangChain este o bibliotecă cu adevărat uimitoare. Oferă Componente pentru a lucra cu modele lingvistice într-un mod ușor de utilizat și, de asemenea, oferă Lanţuri. Lanțurile pot fi considerate ca asamblarea acestor componente în moduri speciale pentru a realiza cel mai bine un anumit caz de utilizare. Acestea sunt menite să fie o interfață de nivel superior prin care oamenii pot începe cu ușurință cu un anumit caz de utilizare. Aceste lanțuri sunt, de asemenea, proiectate pentru a fi personalizate.
În următorul nostru test python vom folosi a Șablon prompt. Modelele de limbă iau textul ca intrare - acel text este denumit în mod obișnuit prompt. De obicei, acesta nu este doar un șir codificat, ci mai degrabă o combinație între un șablon, câteva exemple și intrarea utilizatorului. LangChain oferă mai multe clase și funcții pentru a facilita construirea și lucrul cu prompturi. Să vedem cum o putem face și noi.
Creați un nou fișier Python și apelați-l my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])Am importat din LangChain șablonul și lanțul prompt și clasa llm GPT4All pentru a putea interacționa direct cu modelul nostru GPT.
Apoi, după ce ne-am stabilit calea llm (cum am făcut înainte), instanțiem managerii de apel invers, astfel încât să fim capabili să prindem răspunsurile la interogarea noastră.
Pentru a crea un șablon este foarte ușor: urmând tutorial de documentare putem folosi asa ceva...
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])șablon variabila este un șir cu mai multe linii care conține structura noastră de interacțiune cu modelul: în acolade inserăm variabilele externe în șablon, în scenariul nostru este întrebare.
Deoarece este o variabilă, puteți decide dacă este o întrebare codificată sau o întrebare introdusă de utilizator: aici sunt cele două exemple.
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")Pentru rularea noastră de testare vom comenta cea introdusă de utilizator. Acum trebuie doar să conectăm împreună șablonul nostru, întrebarea și modelul de limbă.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)Nu uitați să verificați că mediul dvs. virtual este încă activat și să rulați comanda:
python3 my_langchain.pyS-ar putea să obții rezultate diferite de ale mele. Ceea ce este uimitor este că poți vedea întregul raționament urmat de GPT4All încercând să obțină un răspuns pentru tine. Ajustarea întrebării vă poate oferi și rezultate mai bune.
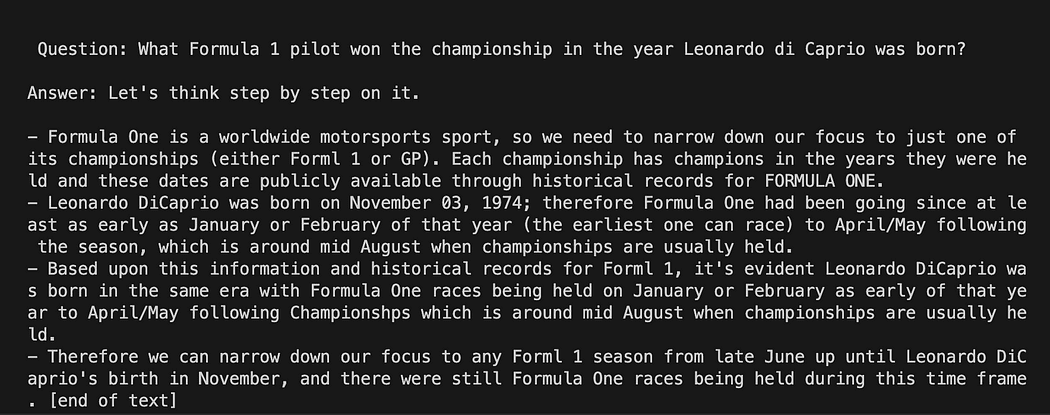
Langchain cu șablon prompt pe GPT4All
Aici începem partea uimitoare, pentru că vom vorbi cu documentele noastre folosind GPT4All ca un chatbot care răspunde la întrebările noastre.
Secvența de pași, referitor la Fluxul de lucru al QnA cu GPT4All, este să încărcăm fișierele noastre pdf, să le transformăm în bucăți. După aceea, vom avea nevoie de un magazin de vectori pentru înglobarile noastre. Trebuie să alimentăm documentele noastre în bucăți într-un magazin de vectori pentru regăsirea informațiilor și apoi le vom încorpora împreună cu căutarea de similaritate în această bază de date ca context pentru interogarea noastră LLM.
În acest scop vom folosi FAISS direct de la Langchain bibliotecă. FAISS este o bibliotecă open-source de la Facebook AI Research, concepută pentru a găsi rapid articole similare în colecții mari de date cu dimensiuni mari. Oferă metode de indexare și căutare pentru a facilita și mai rapid identificarea celor mai asemănătoare elemente dintr-un set de date. Este deosebit de convenabil pentru noi, deoarece simplifică regăsirea informațiilor și ne permite să salvăm local baza de date creată: asta înseamnă că după prima creare va fi încărcată foarte repede pentru orice utilizare ulterioară.
Crearea indicelui vectorial db
Creați un fișier nou și apelați-l my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimePrimele biblioteci sunt aceleași pe care le folosim înainte: în plus, le folosim Langchain pentru crearea indexului de stocare vectorială, the LlamaCppEmbeddings pentru a interacționa cu modelul nostru Alpaca (cuantizat la 4 biți și compilat cu biblioteca cpp) și cu încărcătorul PDF.
Să încărcăm, de asemenea, LLM-urile noastre cu propriile căi: una pentru încorporare și una pentru generarea textului.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)Pentru testare, să vedem dacă am reușit să citim toate fișierele pfd: primul pas este să declarăm 3 funcții de utilizat pe fiecare document. Prima este de a împărți textul extras în bucăți, a doua este de a crea indexul vectorial cu metadatele (cum ar fi numerele de pagină etc...) iar ultima este pentru a testa căutarea de similaritate (voi explica mai bine mai târziu).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesAcum putem testa generarea indexului pentru documentele din docs director: trebuie să punem acolo toate pdf-urile noastre. Langchain are și o metodă de încărcare a întregului folder, indiferent de tipul fișierului: deoarece este complicat procesul de postare, o voi trata în următorul articol despre modelele LaMini.

directorul meu documente conține 4 fișiere pdf
Vom aplica funcțiile noastre la primul document din listă
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)În primele rânduri folosim biblioteca os pentru a obține lista de fișiere pdf în directorul docs. Apoi încărcăm primul document (doc_list[0]) din folderul documente cu Langchain, împărțiți în bucăți și apoi creăm baza de date vectorială cu Lamă înglobări.
După cum ați văzut, folosim metoda pyPDF. Acesta este puțin mai lung de utilizat, deoarece trebuie să încărcați fișierele unul câte unul, dar încărcați PDF folosind pypdf în matrice de documente vă permite să aveți o matrice în care fiecare document conține conținutul paginii și metadate page număr. Acest lucru este foarte convenabil atunci când doriți să cunoașteți sursele contextului pe care le vom oferi GPT4All cu interogarea noastră. Iată exemplul din readthedocs:
Captură de ecran de la Documentație Langchain
Putem rula fișierul python cu comanda din terminal:
python3 my_knowledge_qna.pyDupă încărcarea modelului pentru înglobare veți vedea token-urile la lucru pentru indexare: nu vă speriați că va dura, mai ales dacă rulați doar pe CPU, ca mine (a durat 8 minute).
Finalizarea primului vector db
După cum explicam, metoda pyPDF este mai lentă, dar ne oferă date suplimentare pentru căutarea de similaritate. Pentru a itera toate fișierele noastre, vom folosi o metodă convenabilă de la FAISS, care ne permite să FUNCĂM diferite baze de date împreună. Ceea ce facem acum este că folosim codul de mai sus pentru a genera primul db (îl vom numi db0) și cu o buclă for creăm indexul următorului fișier din listă și îl îmbinăm imediat cu db0.
Iată codul: rețineți că am adăugat câteva jurnale pentru a vă oferi starea progresului utilizării datetime.datetime.now() și tipărirea deltei orei de încheiere și a orei de începere pentru a calcula cât timp a durat operațiunea (o puteți elimina dacă nu vă place).
Instrucțiunile de îmbinare sunt așa
# merge dbi with the existing db0
db0.merge_from(dbi)Una dintre ultimele instrucțiuni este pentru salvarea bazei noastre de date local: întreaga generație poate dura chiar și ore (depinde de câte documente aveți) așa că este foarte bine că trebuie să o facem o singură dată!
# Save the databasae locally
db0.save_local("my_faiss_index")Aici tot codul. Vom comenta multe din el atunci când interacționăm cu GPT4All, încărcând indexul direct din folderul nostru.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  Rularea fișierului python a durat 22 de minute
Rularea fișierului python a durat 22 de minute
Pune întrebări lui GPT4All pe documentele tale
Acum suntem aici. Avem indexul nostru, îl putem încărca și cu un șablon prompt putem cere GPT4All să ne răspundă la întrebări. Începem cu o întrebare codificată și apoi vom parcurge întrebările de intrare.
Pune următorul cod într-un fișier python db_loading.py și rulați-l cu comanda de la terminal python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])Textul tipărit este lista celor 3 surse care se potrivește cel mai bine cu interogarea, oferindu-ne și numele documentului și numărul paginii.
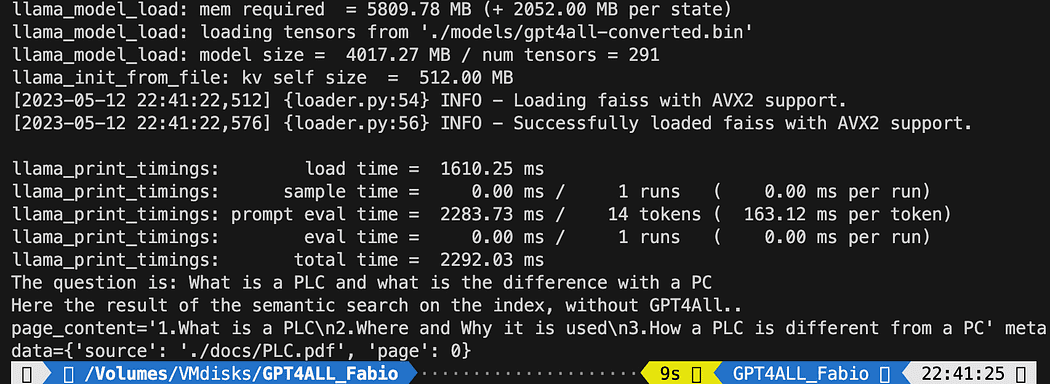
Rezultatele căutării semantice care rulează fișierul db_loading.py
Acum putem folosi căutarea de similaritate ca context pentru interogarea noastră folosind șablonul prompt. După cele 3 funcții, înlocuiți tot codul cu următoarele:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))După rulare, veți obține un rezultat ca acesta (dar poate varia). Uimitor nu!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.Dacă doriți ca o întrebare introdusă de utilizator să înlocuiască linia
question = "What is a PLC and what is the difference with a PC"cu ceva de genul asta:
question = input("Your question: ")Este timpul să experimentezi. Puneți întrebări diferite pe toate subiectele legate de documentele dvs. și vedeți rezultatele. Există un spațiu mare de îmbunătățire, cu siguranță în ceea ce privește promptul și șablonul: puteți arunca o privire aici pentru câteva inspirații. Dar Langchain documentația este cu adevărat uimitoare (aș putea să o urmăresc!!).
Puteți urmări codul din articol sau îl puteți verifica depozitul meu github.
Fabio Matricardi un educator, profesor, inginer și pasionat de învățare. Predă de 15 ani tinerilor studenți, iar acum pregătește noi angajați la Key Solution Srl. Mi-a început cariera ca inginer în automatizări industriale în 2010. Pasionat de programare încă de când era adolescent, a descoperit frumusețea construirii de software și a interfețelor om-mașină pentru a aduce ceva la viață. Predarea și coachingul fac parte din rutina mea zilnică, precum și studiul și învățarea cum să fiu un lider pasionat, cu abilități moderne de management. Alăturați-vă mie în călătoria către un design mai bun, o integrare a sistemului predictiv folosind Machine Learning și Inteligența Artificială de-a lungul întregului ciclu de viață de inginerie.
Original. Repostat cu permisiunea.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- EVM Finance. Interfață unificată pentru finanțare descentralizată. Accesați Aici.
- Grupul Quantum Media. IR/PR amplificat. Accesați Aici.
- PlatoAiStream. Web3 Data Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- :are
- :este
- :nu
- :Unde
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- ani 15
- 15%
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- capacitate
- Capabil
- Despre Noi
- mai sus
- realiza
- act
- activată
- adăugat
- plus
- Suplimentar
- avansat
- care afectează
- După
- AI
- cercetare ai
- TOATE
- permite
- permite
- deja
- de asemenea
- am
- uimitor
- an
- analiză
- și
- răspunde
- Orice
- api
- aplicatii
- Aplică
- arhitectură
- SUNT
- Mulțime
- articol
- bunuri
- artificial
- inteligență artificială
- AS
- asociate
- At
- audio
- Automata
- în mod automat
- Automatizare
- disponibil
- evita
- de bază
- bazat
- BE
- Frumuseţe
- deoarece
- fost
- înainte
- fiind
- de mai jos
- CEL MAI BUN
- Mai bine
- între
- Dincolo de
- Mare
- BIN
- legare
- Pic
- născut
- scurt
- aduce
- construi
- Clădire
- construit-in
- Autobuze
- dar
- by
- calcula
- apel
- denumit
- apeluri
- CAN
- nu poti
- Capacitate
- capturi
- Carieră
- transporta
- caz
- Captură
- CD
- sigur
- cu siguranță
- lanţ
- lanţuri
- campionat
- chatbot
- Chat GPT
- verifica
- chimic
- clasă
- clase
- clic
- coaching-ul
- cod
- Coduri
- colecta
- colectare
- colecții
- combinaţie
- comentariu
- în mod obișnuit
- comunica
- Comunicare
- compatibil
- Completă
- Terminat
- completare
- complex
- complicat
- componente
- calculator
- Calculatoare
- Conectați
- legat
- construirea
- consumator
- conține
- conţinut
- context
- Control
- controlor
- controale
- Convenabil
- convertit
- ar putea
- acoperi
- Procesor
- crea
- a creat
- creează
- Crearea
- creaţie
- Creator
- critic
- personalizabil
- zilnic
- de date
- Baza de date
- baze de date
- Data
- datetime
- decide
- Mod implicit
- definit
- Deltă
- Dependenţă
- În funcție
- depinde de
- implementa
- descris
- Amenajări
- proiectat
- dorit
- în curs de dezvoltare
- dispozitiv
- Dispozitive
- FĂCUT
- diferenţă
- diferit
- digerabil
- digital
- direct
- descoperi
- a descoperit
- do
- document
- documentaţie
- documente
- face
- nu
- făcut
- Dont
- DOT
- Descarca
- conducere
- în timpul
- fiecare
- mai ușor
- cu ușurință
- uşor
- ecosistem
- ecosistemele
- efort
- încastra
- încorporat
- Încorporarea
- de angajați
- permite
- capăt
- inginer
- Inginerie
- Intrați
- entuziast
- Întreg
- Mediu inconjurator
- eroare
- mai ales
- etc
- Eter (ETH)
- Chiar
- tot
- exact
- exemplu
- exemple
- execuție
- existent
- experiment
- Explica
- a explicat
- explicând
- extern
- Față
- facilitează
- cu care se confruntă
- FAST
- mai repede
- Fișier
- Fişiere
- Găsi
- capăt
- First
- potrivi
- debit
- urma
- a urmat
- următor
- urmează
- Pentru
- formă
- format
- formulă
- Formula 1
- Cadru
- din
- funcţie
- funcții
- mai mult
- genera
- generator
- generaţie
- obține
- GitHub
- Da
- dat
- oferă
- Oferirea
- merge
- bine
- GPU
- calitate
- Manipularea
- se întâmplă
- Greu
- Piese metalice
- Avea
- he
- greu
- ajută
- aici
- Ascuns
- Înalt
- superior
- ORE
- Cum
- Cum Pentru a
- HTML
- http
- HTTPS
- uman
- i
- ICS
- if
- imagini
- imediat
- punerea în aplicare a
- import
- important
- îmbunătățire
- in
- include
- index
- indexurile
- persoane fizice
- industrial
- automatizare industriala
- industrii
- informații
- intrare
- intrare ieșire
- intrări
- instala
- instalare
- instanță
- instrucțiuni
- integrare
- Inteligență
- destinate
- interacţiona
- interacţiune
- interfaţă
- interfeţe
- Internet
- în
- Introducere
- izolat
- izolare
- IT
- articole
- repetare
- ESTE
- Loc de munca
- alătura
- călătorie
- doar
- KDnuggets
- Cheie
- Cunoaște
- cunoştinţe
- limbă
- mare
- Nume
- mai tarziu
- lider
- învăţare
- Nivel
- biblioteci
- Bibliotecă
- Viaţă
- ciclu de viață
- ca
- linii
- LINK
- linux
- Listă
- mic
- încărca
- încărcător
- încărcare
- local
- la nivel local
- logică
- Lung
- mai lung
- Uite
- Lot
- mac
- maşină
- masina de învățare
- mașini
- Principal
- mai ales
- menține
- face
- gestionate
- administrare
- manager
- Manageri
- de fabricaţie
- multe
- Mai..
- sens
- mijloace
- Memorie
- Îmbina
- care fuzionează
- Metadata
- metodă
- Metode
- minte
- minute
- model
- Modele
- mai mult
- cele mai multe
- multiplu
- trebuie sa
- my
- nume
- nativ
- Nevoie
- rețele
- Nou
- următor
- acum
- număr
- numere
- obiect
- of
- promoții
- on
- dată
- ONE
- on-line
- afară
- open-source
- operaţie
- Operațiuni
- or
- comandă
- organizații
- OS
- Altele
- al nostru
- afară
- producție
- peste
- propriu
- pachet
- ofertele
- pagină
- Paralel
- parte
- special
- în special
- trece
- pasionat
- cale
- PC
- oameni
- efectua
- permisiune
- personal
- imagine
- bucată
- pilot
- plante
- Plato
- Informații despre date Platon
- PlatoData
- PLC
- "vă rog"
- ștecher
- porturi
- poziţie
- Post
- potenţial
- putere
- centrale electrice
- alimentat
- puternic
- pre
- împiedica
- tipărire
- probleme
- proces
- prelucrate
- procese
- Program
- programat
- Programare
- Progres
- proiect
- Proiecte
- protocoale
- furnizează
- scopuri
- pune
- Piton
- calitate
- întrebare
- Întrebări
- repede
- mai degraba
- Citeste
- gata
- într-adevăr
- primire
- recent
- menționat
- se referă
- Fără deosebire
- registre
- legate de
- încredere
- se bazează
- minte
- scoate
- repetat
- înlocui
- raportează
- depozit
- reprezentare
- necesar
- Cerinţe
- Necesită
- cercetare
- Resurse
- răspuns
- răspunsuri
- rezultat
- REZULTATE
- reveni
- Cameră
- Alerga
- funcţionare
- s
- Siguranţă
- acelaşi
- Economisiți
- economisire
- scenariu
- Caută
- căutare
- Al doilea
- Secțiune
- sigur
- vedea
- senzori
- propoziție
- Secvenţă
- de serie
- instalare
- configurarea
- câteva
- shot
- să
- indicat
- asemănător
- simplu
- pur şi simplu
- întrucât
- singur
- aptitudini
- mic
- So
- Software
- soluţie
- unele
- ceva
- Sursă
- Surse
- de specialitate
- special
- specific
- specificată
- împărţi
- Loc
- Începe
- început
- Pornire
- Declarație
- Stare
- Pas
- paşi
- Încă
- stoca
- Şir
- structura
- Elevi
- Studiu
- astfel de
- sistem
- Lua
- Vorbi
- sarcini
- profesor
- Predarea
- adolescent
- șablon
- Terminal
- test
- Testarea testului
- Testarea
- generarea textului
- decât
- acea
- lor
- Lor
- apoi
- Acolo.
- Acestea
- ei
- crede
- acest
- gândit
- Prin
- de-a lungul
- timp
- la
- împreună
- indicativele
- mâine
- de asemenea
- a luat
- subiect
- subiecte
- spre
- Tren
- încerca
- Două
- tip
- tipic
- tipic
- actualizat
- actualizări
- pe
- us
- Folosire
- USB
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizatorii
- folosind
- obișnuit
- utilizate
- diverse
- verifica
- versiune
- foarte
- de
- Virtual
- W3
- aștepta
- vrea
- a fost
- Cale..
- modalități de
- we
- website
- BINE
- Ce
- Ce este
- Roată
- cand
- care
- OMS
- de ce
- pe larg
- voi
- ferestre
- Utilizatorii Windows
- cu
- în
- fără
- Castigat
- Apartamente
- de lucru
- an
- ani
- tu
- tineri
- Ta
- zephyrnet









