Pandas este o bibliotecă open-source puternică și utilizată pe scară largă pentru manipularea și analiza datelor folosind Python. Una dintre caracteristicile sale cheie este capacitatea de a grupa date folosind funcția groupby prin împărțirea unui DataFrame în grupuri bazate pe una sau mai multe coloane și apoi aplicând diferite funcții de agregare fiecăruia dintre ele.

Imagine de la Unsplash
groupby funcția este incredibil de puternică, deoarece vă permite să rezumați și să analizați rapid seturi de date mari. De exemplu, puteți grupa un set de date după o anumită coloană și puteți calcula media, suma sau numărul coloanelor rămase pentru fiecare grup. De asemenea, puteți grupa după mai multe coloane pentru a obține o înțelegere mai detaliată a datelor dvs. În plus, vă permite să aplicați funcții de agregare personalizate, care pot fi un instrument foarte puternic pentru sarcini complexe de analiză a datelor.
În acest tutorial, veți învăța cum să utilizați funcția groupby din Pandas pentru a grupa diferite tipuri de date și a efectua diferite operațiuni de agregare. Până la sfârșitul acestui tutorial, ar trebui să puteți utiliza această funcție pentru a analiza și a rezuma datele în diferite moduri.
Conceptele sunt interiorizate atunci când sunt practicate bine și aceasta este ceea ce vom face în continuare, adică să punem la punct funcția Pandas groupby. Se recomandă utilizarea a Jupiter Notebook pentru acest tutorial, deoarece puteți vedea rezultatul la fiecare pas.
Generați eșantion de date
Importați următoarele biblioteci:
- Pandas: pentru a crea un cadru de date și a aplica gruparea după
- Aleatoriu – Pentru a genera date aleatorii
- Pprint – Pentru a tipări dicționare
import pandas as pd
import random
import pprint
În continuare, vom inițializa un cadru de date gol și vom completa valori pentru fiecare coloană, așa cum se arată mai jos:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Sfat bonus – o modalitate mai curată de a face aceeași sarcină este prin crearea unui dicționar cu toate variabilele și valorile și ulterior convertirea acestuia într-un cadru de date.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
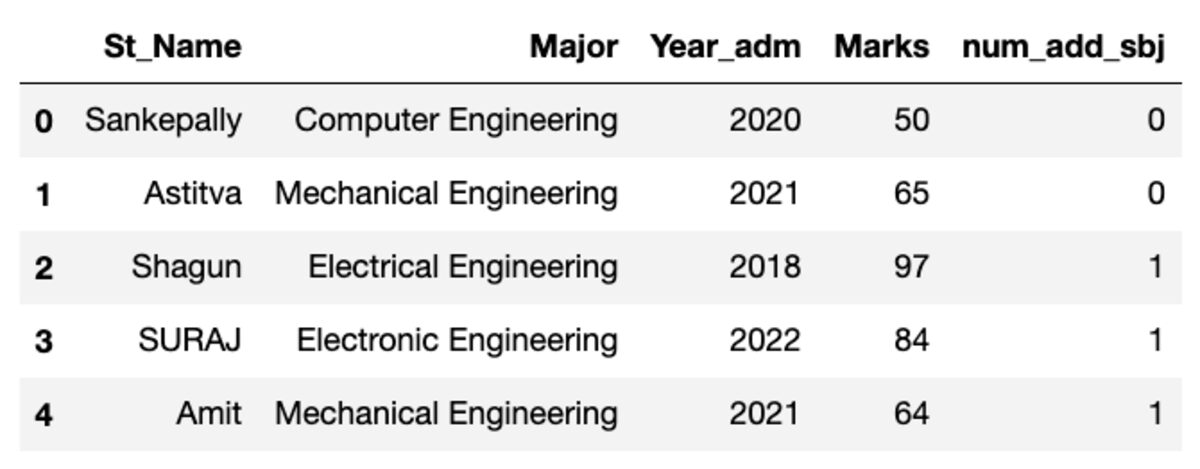
Cadrul de date arată ca cel prezentat mai jos. Când rulați acest cod, unele dintre valori nu se vor potrivi deoarece folosim un eșantion aleatoriu.
Realizarea Grupurilor
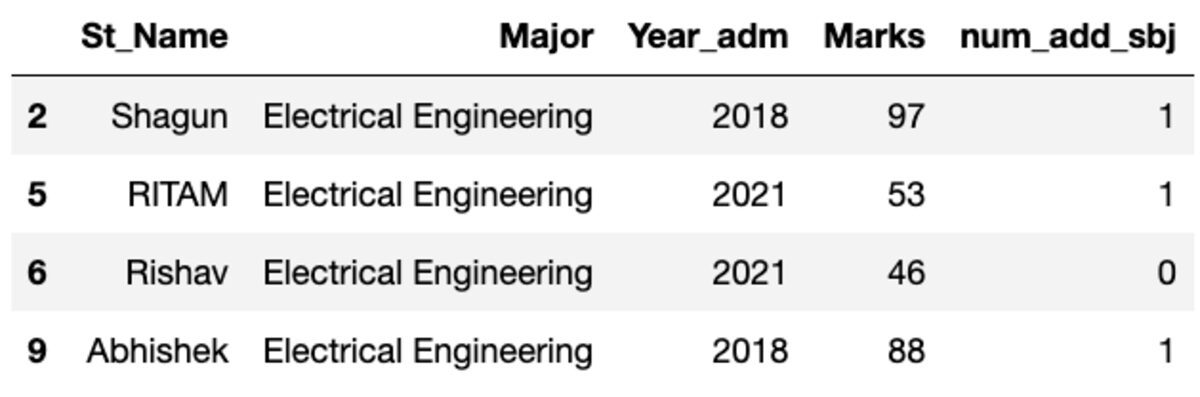
Să grupăm datele după subiectul „Major” și să aplicăm filtrul de grup pentru a vedea câte înregistrări se încadrează în acest grup.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Deci, patru studenți aparțin specializării Inginerie electrică.
De asemenea, puteți grupa după mai multe coloane (Major și num_add_sbj în acest caz).
groups = df.groupby(['Major', 'num_add_sbj'])
Rețineți că toate funcțiile agregate care pot fi aplicate grupurilor cu o singură coloană pot fi aplicate grupurilor cu mai multe coloane. Pentru restul tutorialului, să ne concentrăm asupra diferitelor tipuri de agregare folosind o singură coloană ca exemplu.
Să creăm grupuri folosind groupby în coloana „Major”.
groups = df.groupby('Major')Aplicarea funcțiilor directe
Să presupunem că doriți să găsiți notele medii la fiecare Major. Ce ai face?
- Alegeți coloana Marks
- Aplicați funcția medie
- Aplicați funcția de rotunjire pentru a rotunji semnele la două zecimale (opțional)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
Agregat
O altă modalitate de a obține același rezultat este utilizarea unei funcții de agregare, așa cum se arată mai jos:
groups['Marks'].aggregate('mean').round(2)
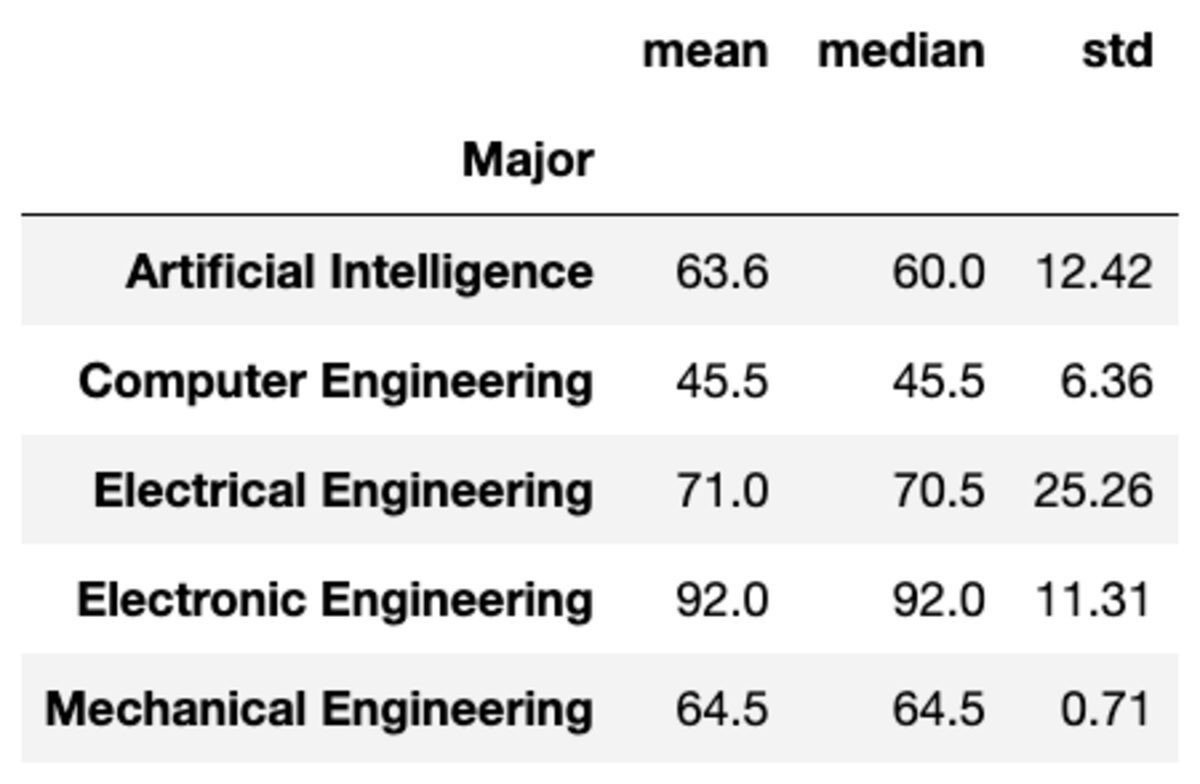
De asemenea, puteți aplica mai multe agregări la grupuri, trecând funcțiile ca o listă de șiruri.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
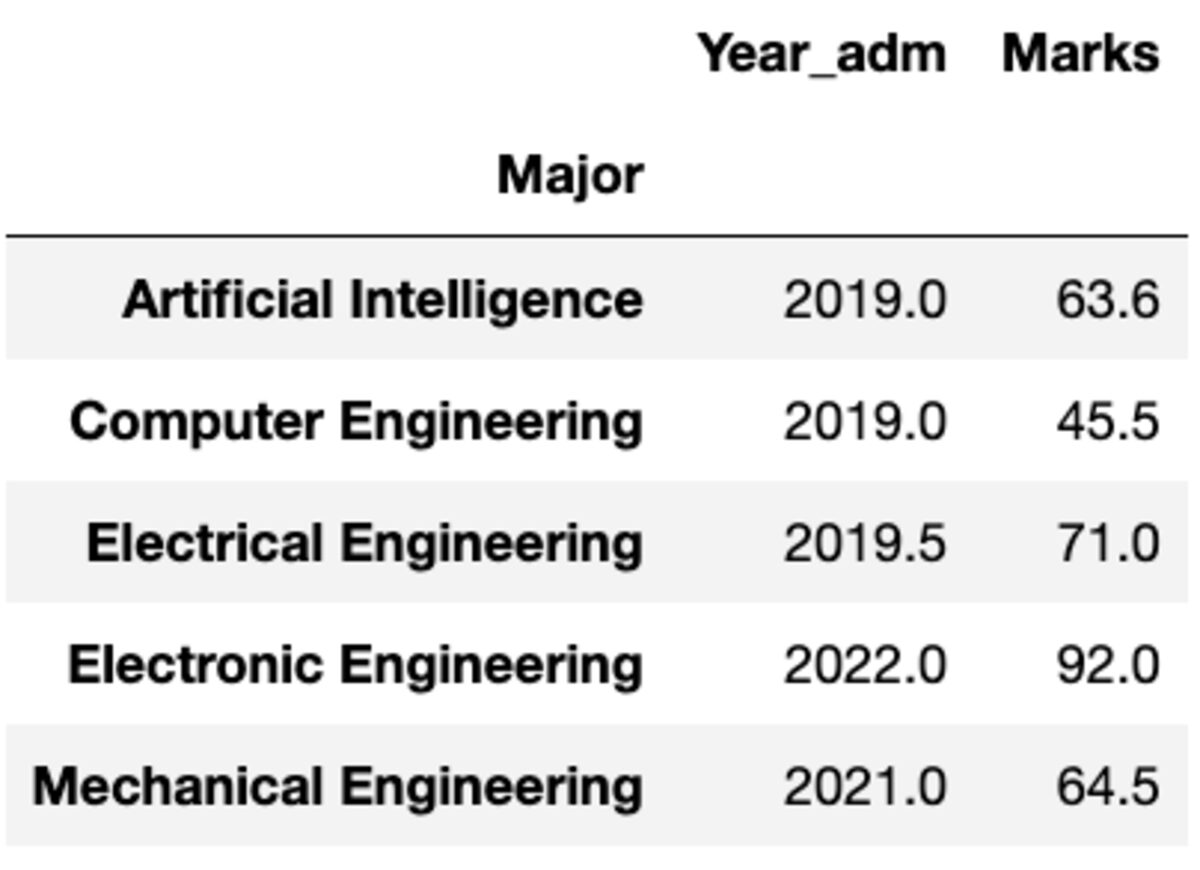
Dar ce se întâmplă dacă trebuie să aplicați o funcție diferită unei alte coloane. Nu vă faceți griji. Puteți face acest lucru și trecând perechea {coloană: funcție}.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
transformări
Este posibil să fie nevoie să efectuați transformări personalizate într-o anumită coloană, care pot fi realizate cu ușurință folosind groupby(). Să definim un scalar standard similar cu cel disponibil în modulul de preprocesare al lui sklearn. Puteți transforma toate coloanele apelând metoda transform și trecând funcția personalizată.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
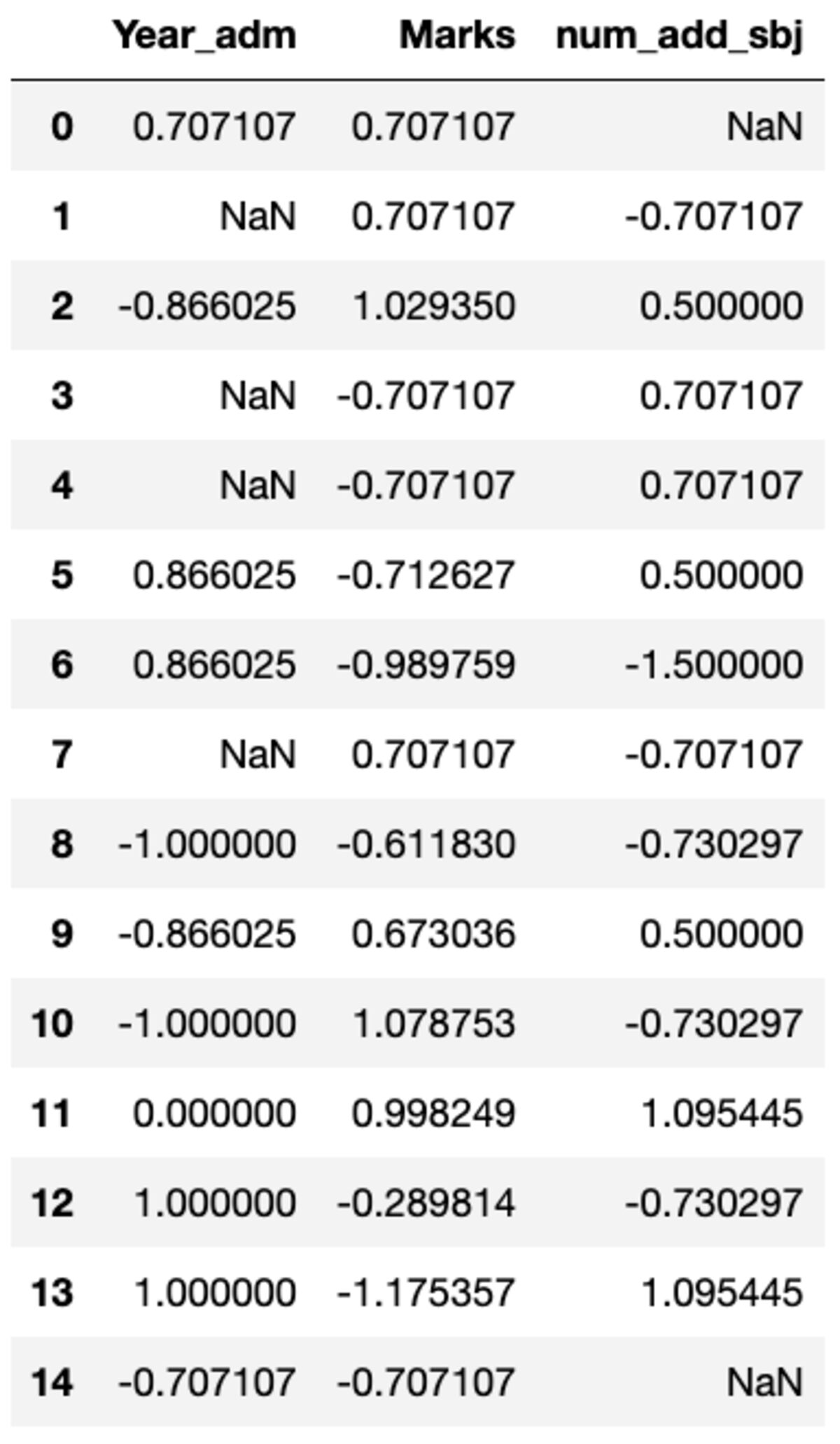
Rețineți că „NaN” reprezintă grupuri cu abatere standard zero.
Filtru
Poate doriți să verificați care „Major” are performanțe slabe, adică cel în care „Notele” medii ale elevilor sunt mai mici de 60. Este necesar să aplicați o metodă de filtrare pentru grupurile cu o funcție în interiorul acesteia. Codul de mai jos folosește a funcția lambda pentru a obține rezultatele filtrate.
groups.filter(lambda x: x['Marks'].mean() 60)

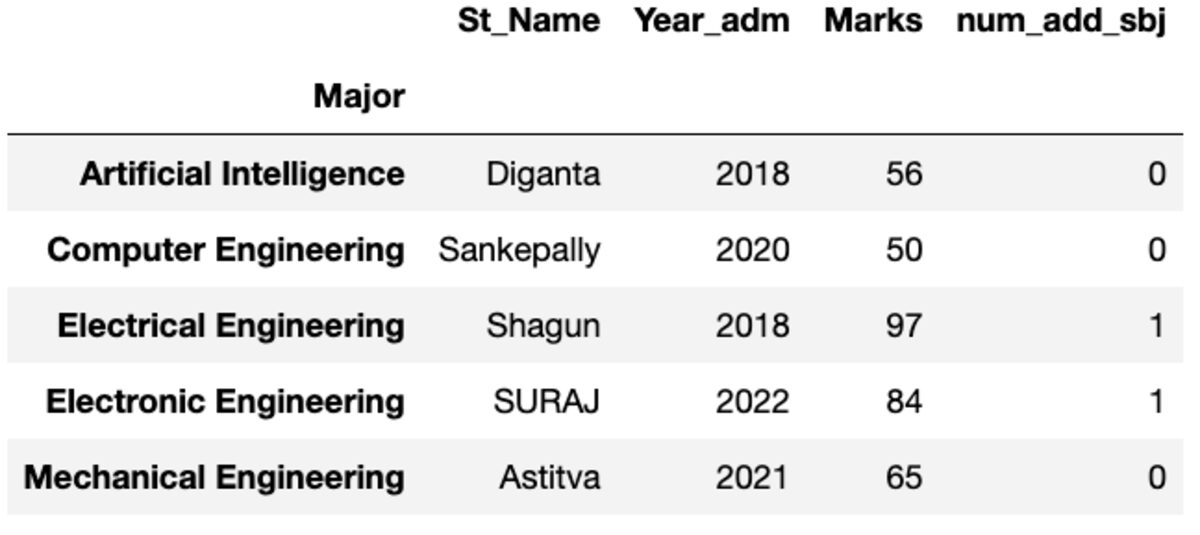
First
Vă oferă prima sa instanță sortată după index.
groups.first()
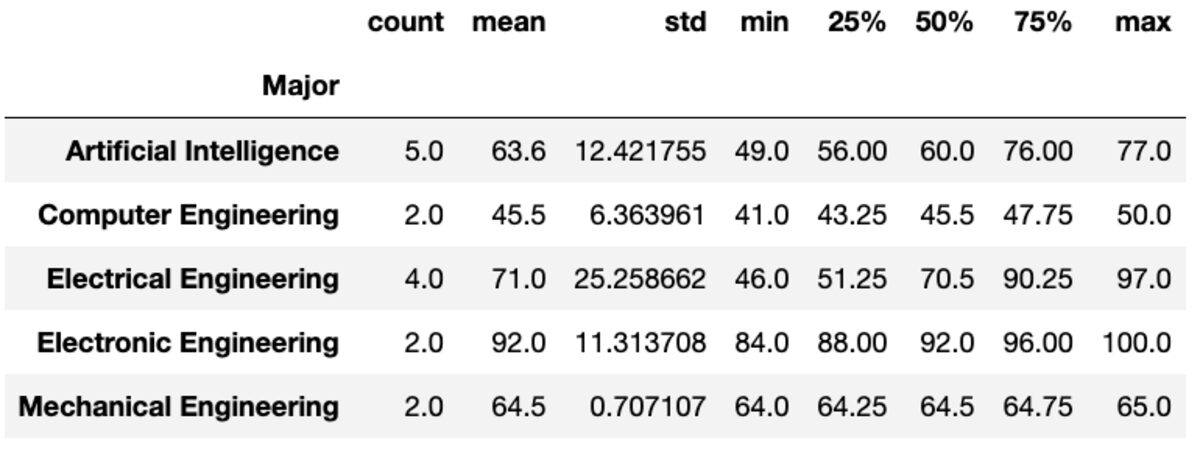
Descrie
Metoda „descrie” returnează statistici de bază, cum ar fi count, mean, std, min, max etc. pentru coloanele date.
groups['Marks'].describe()
Mărimea
Dimensiunea, după cum sugerează și numele, returnează dimensiunea fiecărui grup în ceea ce privește numărul de înregistrări.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
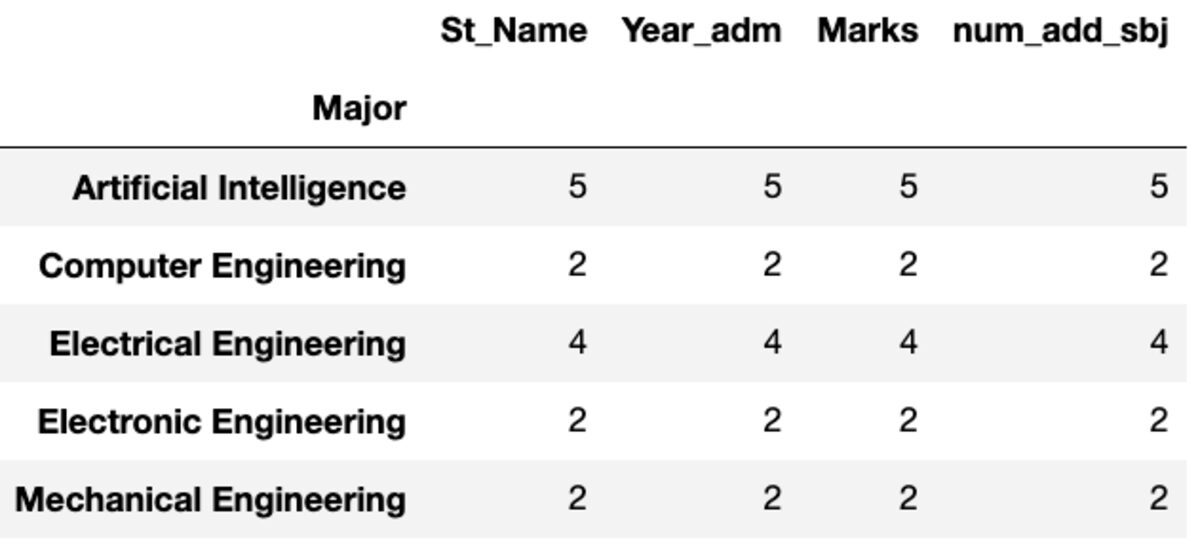
dtype: int64Contele și Nuique
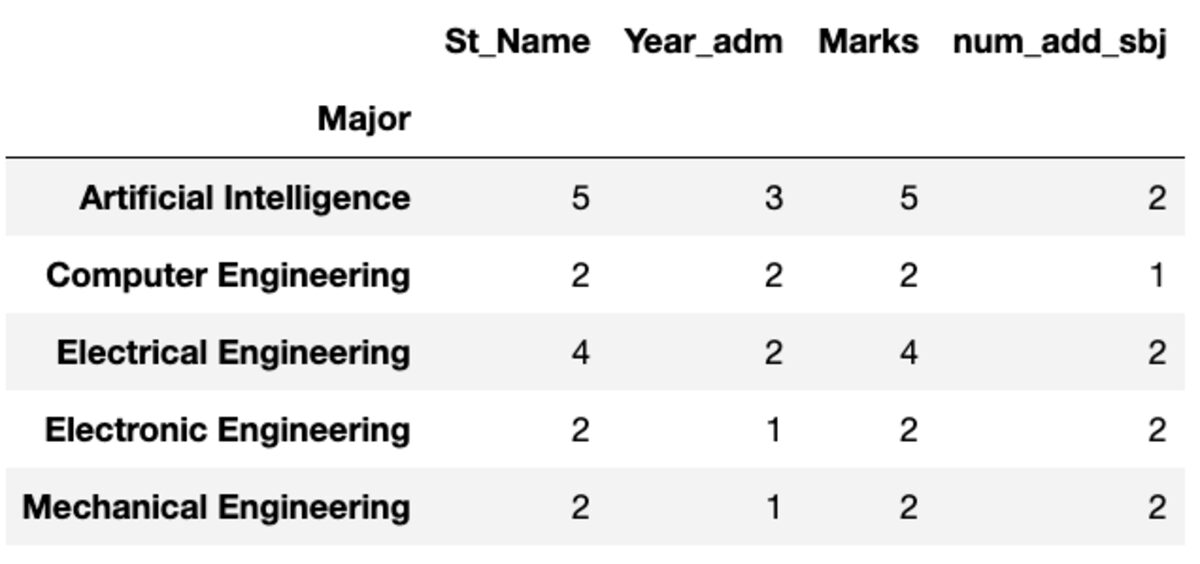
„Count” returnează toate valorile, în timp ce „Nunique” returnează numai valorile unice din acel grup.
groups.count()
groups.nunique()
Redenumiți
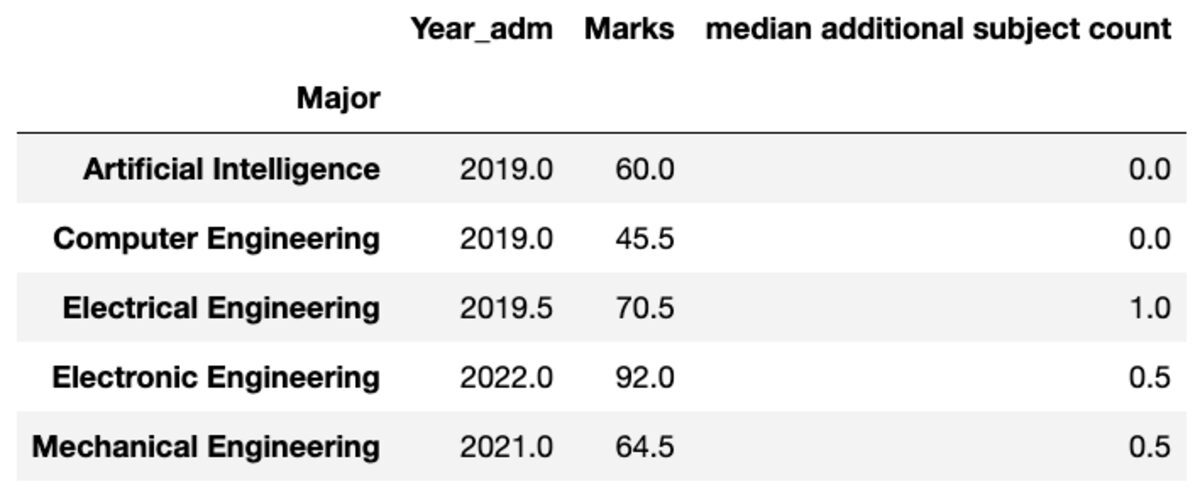
De asemenea, puteți redenumi numele coloanelor agregate în funcție de preferințele dvs.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- Fiți clar cu privire la scopul grupării: Încercați să grupați datele pe o coloană pentru a obține media altei coloane? Sau încercați să grupați datele pe mai multe coloane pentru a obține numărul rândurilor din fiecare grup?
- Înțelegeți indexarea cadrului de date: Funcția groupby folosește indexul pentru a grupa datele. Dacă doriți să grupați datele după o coloană, asigurați-vă că coloana este setată ca index sau puteți utiliza .set_index()
- Utilizați funcția de agregare corespunzătoare: Poate fi folosit cu diverse funcții de agregare precum mean(), sum(), count(), min(), max()
- Utilizați parametrul as_index: Când este setat la Fals, acest parametru le spune pandalor să folosească coloanele grupate ca coloane obișnuite în loc de index.
De asemenea, puteți utiliza groupby() împreună cu alte funcții Pandas, cum ar fi pivot_table(), crosstab() și cut() pentru a extrage mai multe informații din datele dvs.
O funcție de grupare este un instrument puternic pentru analiza și manipularea datelor, deoarece vă permite să grupați rânduri de date pe una sau mai multe coloane și apoi să efectuați calcule agregate pe grupuri. Tutorialul a demonstrat diverse moduri de utilizare a funcției groupby cu ajutorul exemplelor de cod. Sper că vă oferă o înțelegere a diferitelor opțiuni care vin cu acesta și, de asemenea, modul în care acestea ajută la analiza datelor.
Vidhi Chugh este un strateg AI și un lider în transformarea digitală care lucrează la intersecția dintre produs, științe și inginerie pentru a construi sisteme scalabile de învățare automată. Ea este un lider în inovare premiat, o autoare și un vorbitor internațional. Ea are misiunea de a democratiza învățarea automată și de a rupe jargonul pentru ca toată lumea să facă parte din această transformare.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- capacitate
- Capabil
- Obține
- realizat
- Suplimentar
- În plus,
- agregare
- AI
- TOATE
- permite
- analiză
- analiza
- și
- O alta
- aplicat
- Aplică
- Aplicarea
- adecvat
- artificial
- inteligență artificială
- autor
- disponibil
- in medie
- premiat
- bazat
- de bază
- de mai jos
- biotehnologie
- Pauză
- construi
- calcula
- apel
- caz
- verifica
- clar
- cod
- Coloană
- Coloane
- cum
- complex
- calculator
- Inginerie calculator
- crea
- Crearea
- personalizat
- de date
- analiza datelor
- seturi de date
- democratiza
- demonstrat
- deviere
- diferit
- digital
- Transformarea digitală
- direcționa
- Dont
- fiecare
- cu ușurință
- în mod eficient
- Inginerie Electrică
- Electronic
- Inginerie
- etc
- toată lumea
- exemplu
- exemple
- extrage
- Cădea
- DESCRIERE
- umple
- filtru
- Găsi
- First
- Concentra
- următor
- FRAME
- din
- funcţie
- funcții
- genera
- obține
- dat
- oferă
- merge
- grup
- Grupului
- hands-on
- ajutor
- speranţă
- Cum
- Cum Pentru a
- HTML
- HTTPS
- import
- in
- incredibil
- index
- Inovaţie
- perspective
- instanță
- in schimb
- Inteligență
- Internațional
- intersecție
- IT
- jargon
- KDnuggets
- Cheie
- mare
- lider
- AFLAȚI
- învăţare
- biblioteci
- Bibliotecă
- Listă
- Se pare
- maşină
- masina de învățare
- major
- face
- Manipulare
- multe
- Meci
- max
- mecanic
- Inginerie Mecanică
- mediu
- metodă
- Misiune
- modul
- mai mult
- multiplu
- nume
- nume
- Nevoie
- următor
- număr
- ONE
- open-source
- Operațiuni
- Opţiuni
- Altele
- panda
- parametru
- parte
- special
- Care trece
- efectua
- Locuri
- Plato
- Informații despre date Platon
- PlatoData
- puternic
- Produs
- furnizează
- scop
- Piton
- repede
- aleator
- recomandat
- înregistrări
- regulat
- rămas
- reprezintă
- Necesită
- REST
- rezultat
- REZULTATE
- reveni
- Returnează
- Richard
- rotund
- funcţionare
- acelaşi
- scalabil
- ȘTIINȚE
- set
- să
- indicat
- asemănător
- singur
- Mărimea
- unele
- Vorbitor
- specific
- standard
- statistică
- Pas
- Strateg
- student
- Elevi
- subiect
- sugerează
- rezuma
- sisteme
- Sarcină
- sarcini
- spune
- termeni
- sfat
- la
- instrument
- Transforma
- Transformare
- transformări
- tutorial
- Tipuri
- înţelegere
- unic
- utilizare
- Valori
- diverse
- modalități de
- Ce
- care
- voi
- de lucru
- ar
- X
- an
- Ta
- zephyrnet
- zero






