În lumea de astăzi, clienții gestionează cantități mari de date în propria lor Serviciul Amazon de stocare simplă (Amazon S3), lacuri de date, care necesită conducte de date complicate pentru a înțelege continuu modificările în aspectul datelor și pentru a le face disponibile sistemelor consumatoare. AWS Adeziv crawlerele oferă o modalitate simplă de catalogare a datelor în AWS Glue Data Catalog, care elimină greutățile atunci când vine vorba de gestionarea schemelor și clasificarea datelor. Crawlerele AWS Glue extrag schema de date și partițiile din Amazon S3 pentru a popula automat catalogul de date, păstrând metadatele la zi.
Dar, odată cu creșterea exponențială a datelor în timp, numărul de partiții dintr-un anumit tabel poate crește semnificativ. Pentru că serviciile de analiză ca Amazon Atena interogați un tabel care conține milioane de partiții, timpul necesar pentru a prelua partiția crește și poate determina creșterea duratei de rulare a interogării.
Astăzi, suportul pentru crawler AWS Glue a fost extins pentru a adăuga automat indecși de partiții pentru tabelele nou descoperite pentru a optimiza procesarea interogărilor pe setul de date partiționat. Acum, când crawler-ul creează un nou tabel Data Catalog în timpul rulării crawler-ului, creează și un index de partiție în mod implicit, cu cea mai mare permutare a tuturor coloanelor de partiții numerice și de tip șir ca chei. Catalogul de date creează apoi un index care poate fi căutat pe baza acestor chei, reducând timpul necesar pentru a prelua și filtra metadatele partițiilor pe tabele cu milioane de partiții. Crearea de indici de partiții aduce beneficii sarcinilor de lucru de analiză care rulează pe Athena, Amazon EMR, Amazon Redshift Spectrumși AWS Glue.
În această postare, descriem cum să creați indici de partiție cu un crawler AWS Glue și să comparăm îmbunătățirea performanței interogărilor atunci când accesați datele accesate cu crawlere cu și fără un index de partiție de la Athena.
Prezentare generală a soluțiilor
Folosim un Formarea AWS Cloud șablon pentru a crea resursele noastre de soluții. În următorii pași, demonstrăm cum să configurați crawler-ul AWS Glue pentru a crea un index de partiție folosind fie consola AWS Glue, fie Interfața liniei de comandă AWS (AWS CLI). Apoi comparăm îmbunătățirile performanței interogărilor folosind Athena.
Cerințe preliminare
Pentru a urma această postare, trebuie să aveți acces la un Gestionarea identității și accesului AWS (IAM) rol de administrator pentru a crea resurse folosind AWS CloudFormation.
Configurați resursele soluției dvs
Șablonul CloudFormation generează următoarele resurse:
- Roluri și politici IAM
- O bază de date AWS Glue pentru a păstra schema
- Un crawler AWS Glue care indică un set de date foarte partiționat
- Un grup de lucru Athena și un compartiment pentru a stoca rezultatele interogărilor
Parcurgeți următorii pași pentru a configura resursele soluției:
- Conectați-vă la Consola de administrare AWS ca administrator IAM.
- Alege Lansați Stack pentru a implementa șablonul CloudFormation:

- Pentru Numele bazei de date, păstrați valoarea implicită
blog_partition_index_crawlerdb.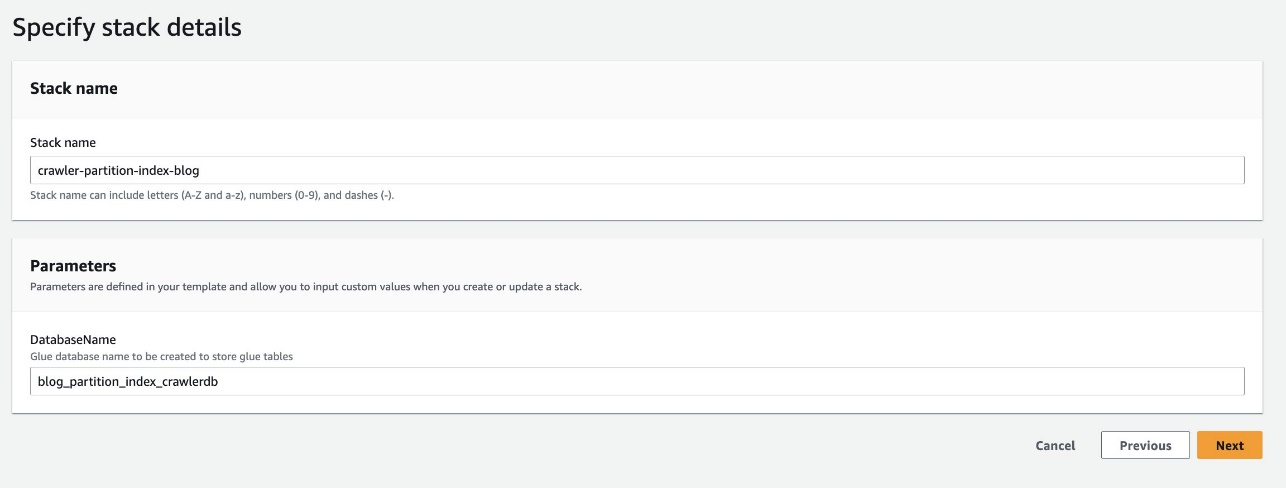
- Alege Pagina Următoare →.
- Consultați detaliile de pe pagina finală și selectați Recunosc că AWS CloudFormation ar putea crea resurse IAM.
- Alege Creați stivă.
- Când stiva este completă, pe consola AWS CloudFormation, navigați la ieşiri fila stivei.
- Notați valorile de
DatabaseNameșiGlueCrawlerName.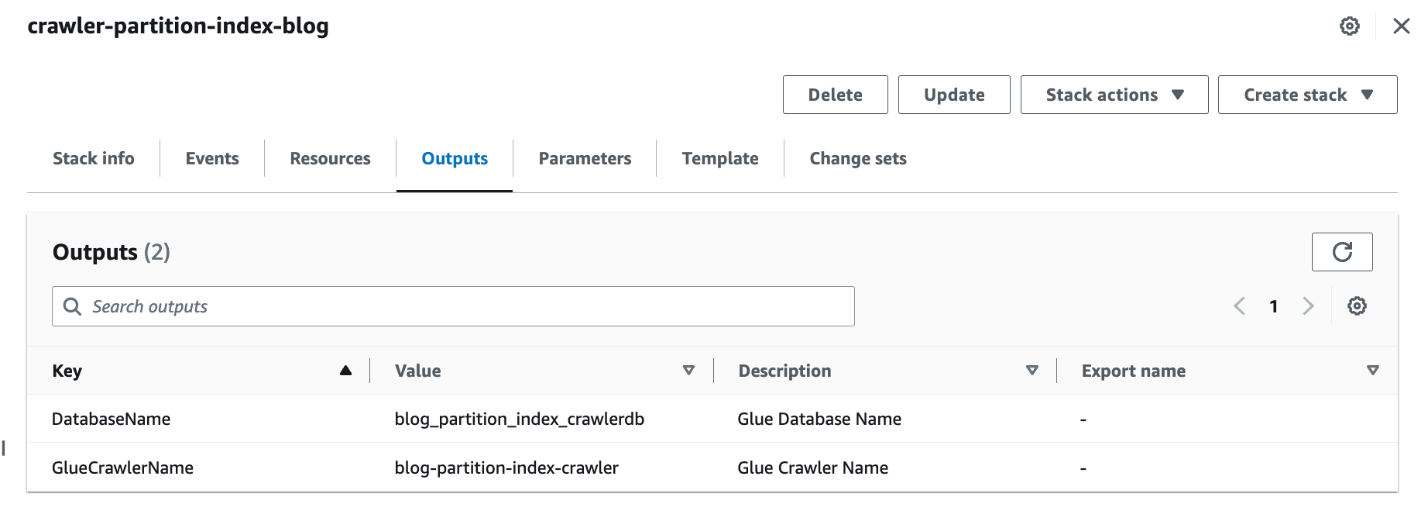
Unele dintre resursele pe care această stivă le implementează implică costuri atunci când sunt utilizate.
Editați și rulați crawler-ul AWS Glue
Pentru a configura și rula crawler-ul AWS Glue, parcurgeți următorii pași:
- Pe consola AWS Glue, alegeți crawlere în panoul de navigare.
- Localizați
crawler blog-partition-index-crawlerȘi alegeți Editati.
- În Setați ieșirea și programarea secțiune, sub Opţiuni avansate, Selectați Creați automat indexuri de partiții.
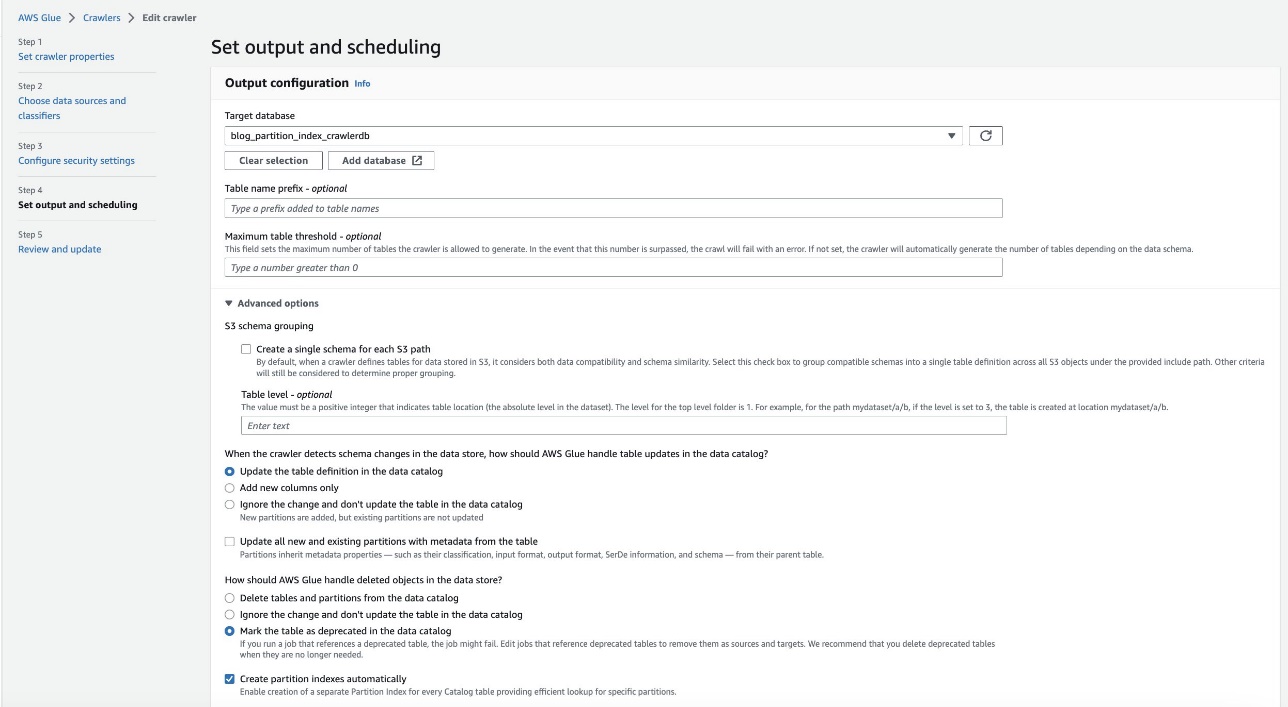
- Examinați și actualizați setările crawlerului.
Alternativ, vă puteți configura crawler-ul utilizând AWS CLI (furnizați rolul dvs. IAM și regiunea):
- Acum rulați crawler-ul și verificați dacă rularea crawler-ului este completă.
Acesta este un set de date foarte partiționat și va dura aproximativ 90 de minute.
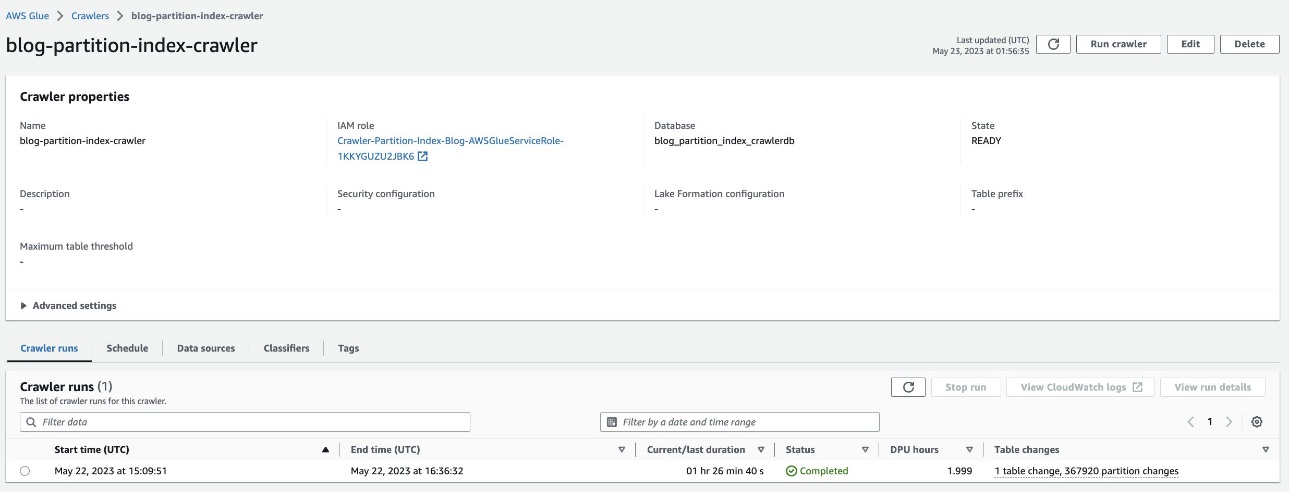
Verificați tabelul partiționat
În baza de date AWS Glue blog_partition_index_crawlerdb, verificați dacă tabelul highly_partitioned_table este creat.
În mod implicit, crawler-ul determină un index bazat pe cea mai mare permutare a coloanelor de partiții ale tipurilor de coloane valide în aceeași ordine a coloanelor de partiții, care sunt fie numerice, fie șir. Pentru tabelul creat de crawler (highly_partitioned_table), avem coloane de partiție year (şir), month (şir), day (șir), și hour (şir).
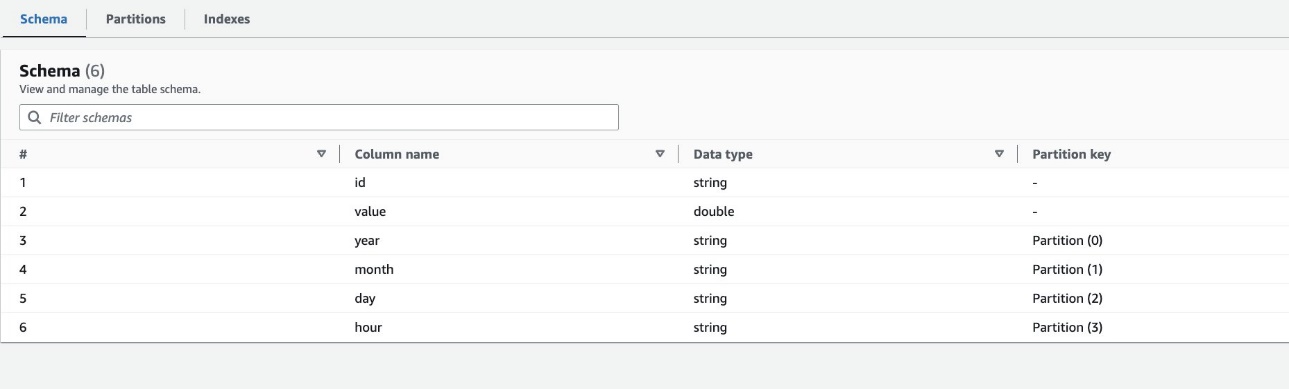
Pe baza acestei definiții, crawler-ul a creat un index privind permutarea anului, lunii, zilei și orei. Crawler-ul a creat indecșii prefixați cu crawler_ pe orice index de partiție creat implicit.
Verificați același lucru navigând la tabel highly_partitioned_table pe consola AWS Glue și alegând Indexuri tab.
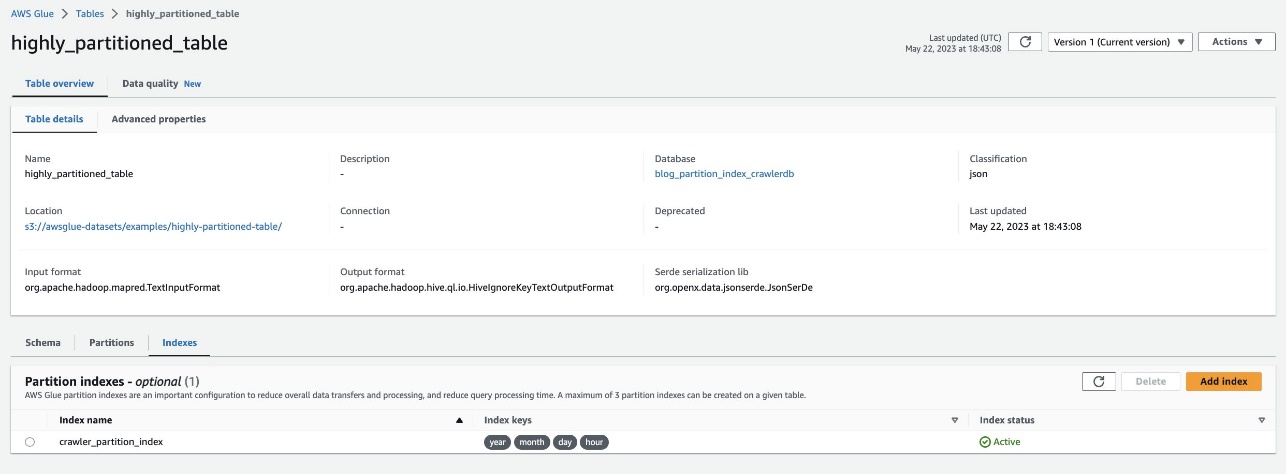
Crawler-ul a reușit să acceseze cu crawlere sursa de date S3 și să completeze cu succes indecșii de partiții pentru tabel.
Comparați îmbunătățirile performanței interogărilor folosind Athena
Mai întâi, interogăm tabelul din Athena fără a folosi indexul de partiție. Pentru a verifica tabelele folosind Athena, parcurgeți următorii pași:
- Pe consola Athena, alegeți
crawler-primary-workgroupca grup de lucru Athena și alegeți recunoaște.
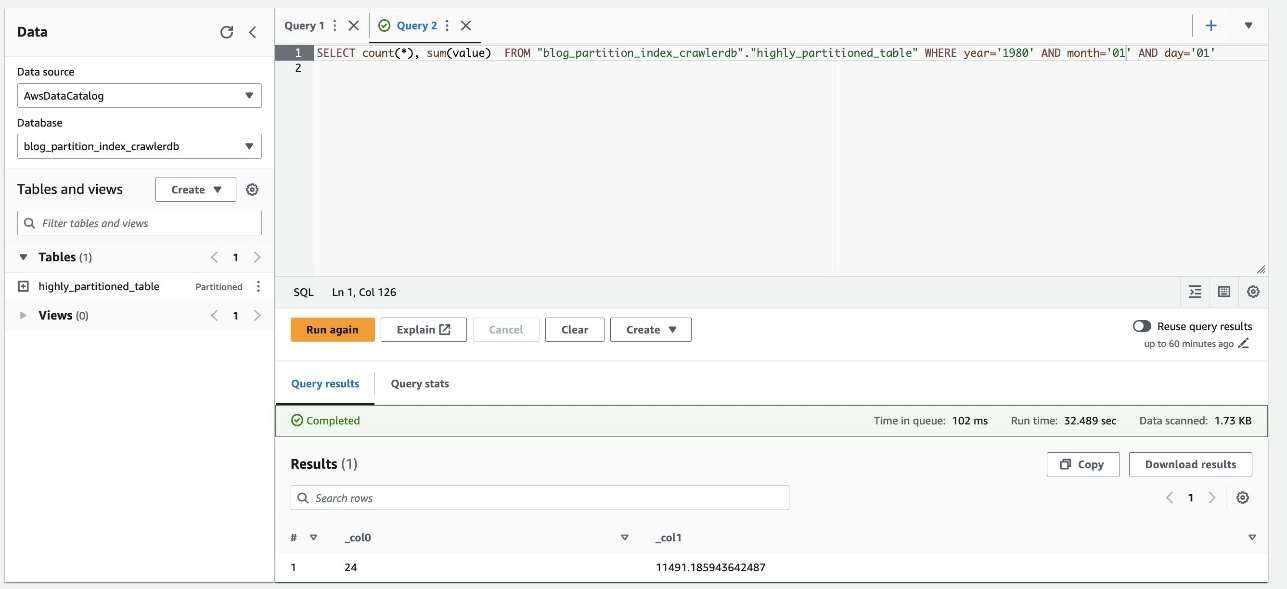
- Rulați următoarea interogare:
Următoarea captură de ecran arată că interogarea a durat aproximativ 32 de secunde fără ca filtrarea să fie activată folosind indexul de partiție.
- Acum activăm indexul de partiție pe interogarea Athena:
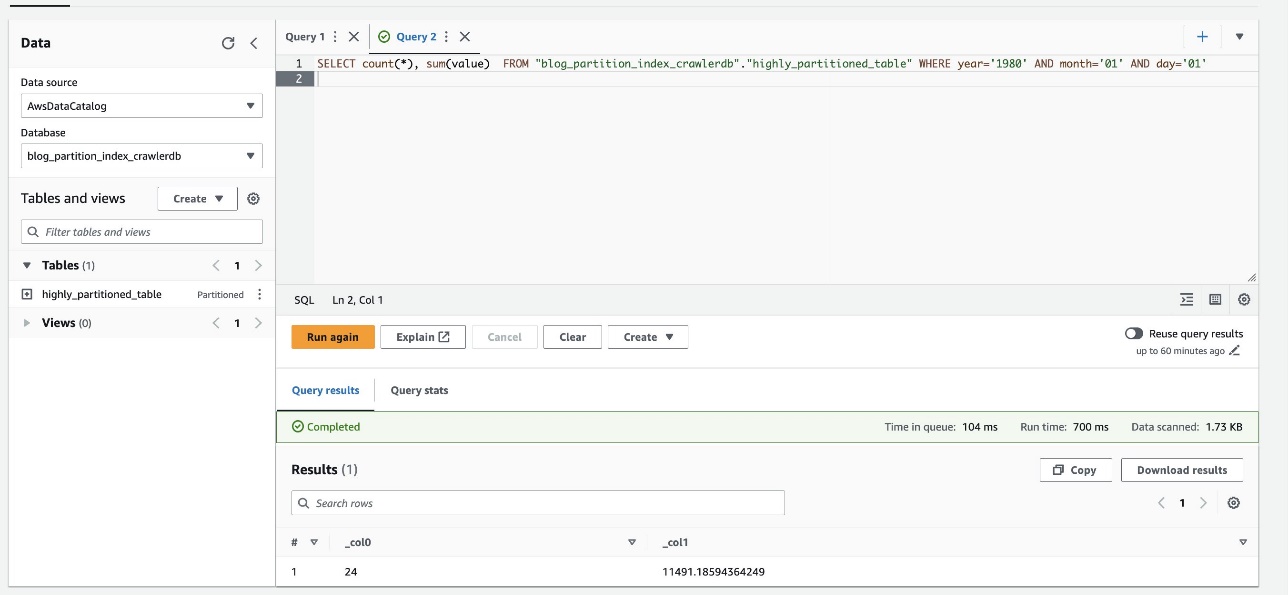
- Rulați din nou următoarea interogare și notați timpul de execuție:
Următoarea captură de ecran arată că interogarea a durat doar 700 de milisecunde, ceea ce este mult mai rapid cu filtrarea activată folosind indexul de partiție.
A curăța
Pentru a evita taxele nedorite către contul dvs. AWS, puteți șterge resursele AWS:
- Conectați-vă la consola CloudFormation ca administrator IAM utilizat pentru crearea stivei CloudFormation.
- Ștergeți stiva CloudFormation pe care ați creat-o.
Concluzie
În această postare, am explicat cum să configurați un crawler AWS pentru a crea indecși de partiție și am comparat performanța interogărilor la accesarea datelor cu indici de la Athena.
Dacă nu sunt prezenți indici de partiții pe tabel, AWS Glue încarcă toate partițiile tabelului și apoi filtrează partițiile încărcate, ceea ce duce la o recuperare ineficientă a metadatelor. Serviciile de analiză precum Redshift Spectrum, Amazon EMR și AWS Glue ETL Spark DataFrames pot utiliza acum indici pentru preluarea partițiilor, rezultând performanțe semnificative de interogare.
Pentru mai multe informații despre indicii de partiție și performanța interogărilor în diferite motoare analitice, consultați Îmbunătățiți performanța interogărilor Amazon Athena folosind indecșii de partiții AWS Glue Data Catalog și Îmbunătățiți performanța interogărilor folosind indecșii de partiții AWS Glue.
Mulțumiri speciale tuturor celor care au contribuit la lansarea acestei funcții crawler: Yuhang Chen, Kyle Duong și Mita Gavade.
Despre autori
 Srividya Parthasarathy este arhitect senior Big Data în echipa AWS Lake Formation. Îi place să construiască soluții de rețea de date și să le partajeze comunității.
Srividya Parthasarathy este arhitect senior Big Data în echipa AWS Lake Formation. Îi place să construiască soluții de rețea de date și să le partajeze comunității.
 Sandeep Adwankar este Senior Technical Product Manager la AWS. Cu sediul în California Bay Area, el lucrează cu clienți din întreaga lume pentru a traduce cerințele de afaceri și tehnice în produse care le permit clienților să îmbunătățească modul în care gestionează, securizează și accesează datele.
Sandeep Adwankar este Senior Technical Product Manager la AWS. Cu sediul în California Bay Area, el lucrează cu clienți din întreaga lume pentru a traduce cerințele de afaceri și tehnice în produse care le permit clienților să îmbunătățească modul în care gestionează, securizează și accesează datele.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- EVM Finance. Interfață unificată pentru finanțare descentralizată. Accesați Aici.
- Grupul Quantum Media. IR/PR amplificat. Accesați Aici.
- PlatoAiStream. Web3 Data Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :are
- :este
- :Unde
- $UP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- Capabil
- acces
- accesarea
- Cont
- recunoaște
- peste
- adăuga
- admin
- din nou
- TOATE
- de-a lungul
- de asemenea
- Amazon
- Amazon Atena
- Amazon EMR
- Amazon Web Services
- Sume
- an
- Analitic
- Google Analytics
- și
- Orice
- aproximativ
- SUNT
- ZONĂ
- în jurul
- AS
- At
- în mod automat
- disponibil
- evita
- AWS
- Formarea AWS Cloud
- AWS Adeziv
- Formația lacului AWS
- bazat
- Golf
- deoarece
- fost
- Beneficiile
- Mare
- Datele mari
- Clădire
- afaceri
- by
- California
- CAN
- catalog
- Provoca
- Modificări
- taxe
- chen
- Alege
- alegere
- clasificare
- Coloană
- Coloane
- vine
- comunitate
- comparaţie
- comparație
- Completă
- Consoleze
- continuu
- Contribuit
- Cheltuieli
- tractor pe şenile
- crea
- a creat
- creează
- Crearea
- creaţie
- Curent
- clienţii care
- de date
- accesul la date
- Lacul de date
- Baza de date
- zi
- Mod implicit
- demonstra
- implementa
- implementează
- descrie
- detalii
- determină
- a descoperit
- jos
- în timpul
- eficient
- oricare
- permite
- activat
- Motoare
- Eter (ETH)
- toată lumea
- extins
- a explicat
- exponențial
- extrage
- extrageți datele
- mai repede
- Caracteristică
- filtru
- filtrare
- Filtre
- final
- urma
- următor
- Pentru
- formare
- din
- generează
- dat
- glob
- Crește
- În creştere
- Avea
- he
- greu
- ridicare de greutati
- extrem de
- deţine
- oră
- Cum
- Cum Pentru a
- HTML
- http
- HTTPS
- IAM
- Identitate
- îmbunătăţi
- îmbunătățire
- îmbunătățiri
- in
- Crește
- Creșteri
- index
- indexurile
- ineficace
- informații
- în
- IT
- jpg
- A pastra
- păstrare
- chei
- lac
- cea mai mare
- lansa
- Aspect
- ridicare
- ca
- Linie
- loturile
- face
- administra
- administrare
- manager
- ochiurilor de plasă
- Metadata
- ar putea
- milioane
- minute
- Lună
- mai mult
- mult
- trebuie sa
- Navigaţi
- navigând
- Navigare
- necesar
- Nou
- recent
- Nu.
- acum
- număr
- of
- on
- afară
- Optimizați
- or
- comandă
- al nostru
- producție
- peste
- pagină
- pâine
- cale
- performanță
- Plato
- Informații despre date Platon
- PlatoData
- Post
- prezenta
- prelucrare
- Produs
- manager de produs
- Produse
- furniza
- reducerea
- regiune
- necesar
- Cerinţe
- Necesită
- Resurse
- rezultând
- REZULTATE
- Rol
- rolurile
- Alerga
- funcţionare
- acelaşi
- secunde
- Secțiune
- sigur
- senior
- Servicii
- set
- setări
- partajarea
- ea
- Emisiuni
- semnificativ
- semnificativ
- simplu
- soluţie
- soluţii
- Sursă
- Scânteie
- Spectru
- stivui
- paşi
- depozitare
- stoca
- simplu
- Şir
- Reușit
- a sustine
- sisteme
- tabel
- Lua
- echipă
- Tehnic
- șablon
- Mulțumiri
- acea
- lor
- Lor
- apoi
- Acestea
- ei
- acest
- timp
- la
- azi
- a luat
- Traduceți
- adevărat
- tip
- Tipuri
- în
- înţelege
- nedorit
- Actualizează
- utilizare
- utilizat
- folosind
- folosi
- valoare
- Valori
- diverse
- Fixă
- verifica
- versiune
- a fost
- Cale..
- we
- web
- servicii web
- cand
- care
- OMS
- voi
- cu
- fără
- Grup de lucru
- fabrică
- lume
- yaml
- an
- tu
- Ta
- zephyrnet