Automated Data Analytics (ADA) on AWS is an AWS solution that enables you to derive meaningful insights from data in a matter of minutes through a simple and intuitive user interface. ADA offers an AWS-native data analytics platform that is ready to use out of the box by data analysts for a variety of use cases. With ADA, teams can ingest, transform, govern, and query diverse datasets from a range of data sources without requiring specialist technical skills. ADA provides a set of conectori prefabricați to ingest data from a wide range of sources including Serviciul Amazon de stocare simplă (Amazon S3), Fluxuri de date Amazon Kinesis, Amazon CloudWatch, Amazon CloudTrail, și Amazon DynamoDB precum și mulți alții.
ADA provides a foundational platform that can be used by data analysts in a diverse set of use cases including IT, finance, marketing, sales, and security. ADA’s out-of-the-box CloudWatch data connector allows data ingestion from CloudWatch logs in the same AWS account in which ADA has been deployed, or from a different AWS account.
In this post, we demonstrate how an application developer or application tester is able to use ADA to derive operational insights of applications running in AWS. We also demonstrate how you can use the ADA solution to connect to different data sources in AWS. We first deploy the ADA solution into an AWS account and set up the ADA solution prin crearea produse de date using data connectors. We then use the ADA Query Workbench to join the separate datasets and query the correlated data, using familiar Structured Query Language (SQL), to gain insights. We also demonstrate how ADA can be integrated with business intelligence (BI) tools such as Tableau to visualize the data and to build reports.
Prezentare generală a soluțiilor
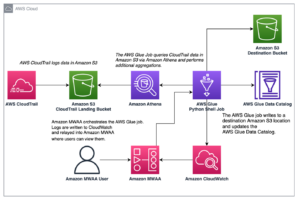
In this section, we present the solution architecture for the demo and explain the workflow. For the purposes of demonstration, the bespoke application is simulated using an AWS Lambdas function that emits logs in Format jurnal Apache at a preset interval using Amazon EventBridge. This standard format can be produced by many different web servers and be read by many log analysis programs. The application (Lambda function) logs are sent to a CloudWatch log group. The historical application logs are stored in an S3 bucket for reference and for querying purposes. A lookup table with a list of Codurile de stare HTTP along with the descriptions is stored in a DynamoDB table. These three serve as sources from which data is ingested into ADA for correlation, query, and analysis. We deploy the ADA solution into an AWS account and set up ADA. We then create the produse de date within ADA for the Grup de jurnal CloudWatch, Găleată S3, și DynamoDB. As the data products are configured, ADA provisions data pipelines to ingest the data from the sources. With the ADA Query Workbench, you can query the ingested data using plain SQL for application troubleshooting or issue diagnosis.
The following diagram provides an overview of the architecture and workflow of using ADA to gain insights into application logs.
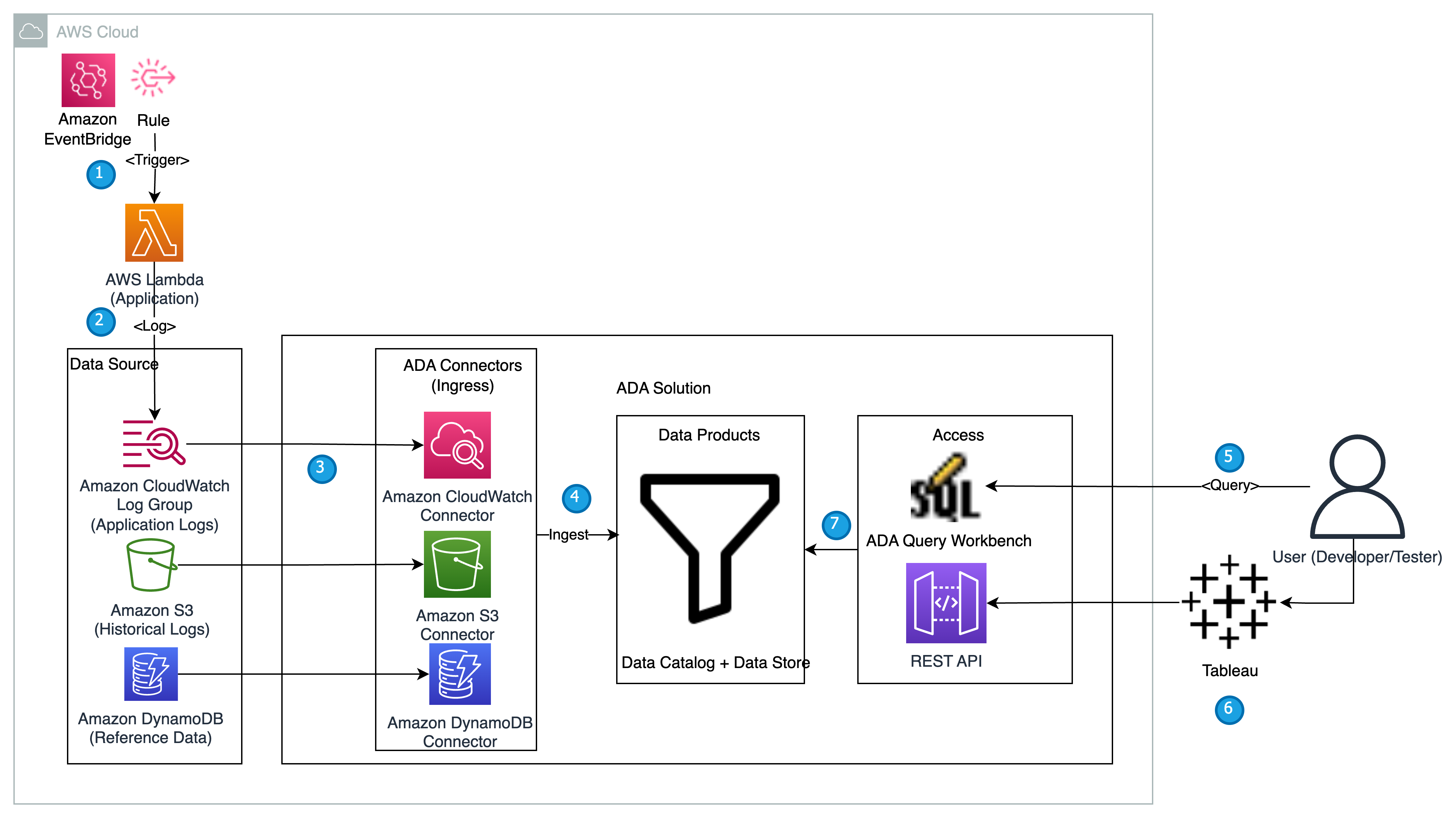
Fluxul de lucru include următorii pași:
- A Lambda function is scheduled to be triggered at 2-minute intervals using EventBridge.
- The Lambda function emits logs that are stored at a specified CloudWatch log group under
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. The application logs are generated using the Apache Log Format schema but stored in the CloudWatch log group in JSON format. - The data products for CloudWatch, Amazon S3, and DynamoDB are created in ADA. The CloudWatch data product connects to the CloudWatch log group where the application (Lambda function) logs are stored. The Amazon S3 connector connects to an S3 bucket folder where the historical logs are stored. The DynamoDB connector connects to a DynamoDB table where the status codes that are referred by the application and historical logs are stored.
- For each of the data products, ADA deploys the data pipeline infrastructure to ingest data from the sources. When the data ingestion is complete, you can write queries using SQL via the ADA Query Workbench.
- You can log in to the ADA portal and compose SQL queries from the Query Workbench to gain insights in to the application logs. You can optionally save the query and share the query with other ADA users in the same domain. The ADA query feature is powered by Amazon Atena, which is a serverless, interactive analytics service that provides a simplified, flexible way to analyze petabytes of data.
- Tableau is configured to access the ADA data products via ADA egress endpoints. You then create a dashboard with two charts. The first chart is a heat map that shows the prevalence of HTTP error codes correlated with the application API endpoints. The second chart is a bar chart that shows the top 10 application APIs with a total count of HTTP error codes from the historical data.
Cerințe preliminare
For this post, you need to complete the following prerequisites:
- instalaţi Interfața liniei de comandă AWS (AWS CLI), Kit AWS Cloud Development (AWS CDK) premise, TypeScript-specific premise, și merge.
- Lansa the ADA solution in your AWS account in the
us-east-1Regiune.- Provide an admin email while launching the ADA Formarea AWS Cloud stack. This is needed for ADA to send the root user password. An admin phone number is required to receive a one-time password message if multi-factor authentication (MFA) is enabled. For this demo, MFA is not enabled.
- Build and deploy the sample application (available on the GitHub repo) solution so that the following resources can be provisioned in your account in the
us-east-1Regiune:- A Lambda function that simulates the logging application and an EventBridge rule that invokes the application function at 2-minute intervals.
- An S3 bucket with the relevant bucket policies and a CSV file that contains the historical application logs.
- A DynamoDB table with the lookup data.
- relevant Gestionarea identității și accesului AWS (IAM) roles and permissions required for the services.
- Optionally, install Table Desktop, a third-party BI provider. For this post, we use Tableau Desktop version 2021.2. There is a cost involved in using a licensed version of the Tableau Desktop application. For additional details, refer to the Tableau licensing informaţii.
Deploy and set up ADA
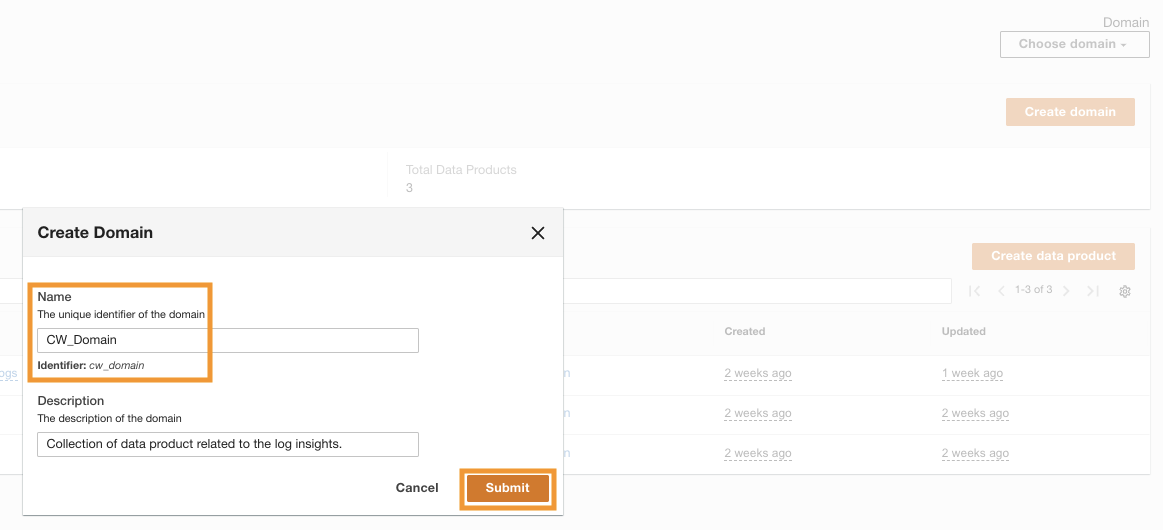
After ADA is deployed successfully, you can autentifici using the admin email provided during the installation. You then create a domeniu numit CW_Domain. A domain is a user-defined collection of data products. For example, a domain might be a team or a project. Domains provide a structured way for users to organize their data products and manage access permissions.
- On the ADA console, choose domenii în panoul de navigare.
- Alege Creați un domeniu.
- Introduceți un nume (
CW_Domain) and description, then choose Trimite mesaj.
Set up the sample application infrastructure using AWS CDK
The AWS CDK solution that deploys the demo application is hosted on GitHub. The steps to clone the repo and to set up the AWS CDK project are detailed in this section. Before you run these commands, be sure to configura your AWS credentials. Create a folder, open the terminal, and navigate to the folder where the AWS CDK solution needs to be installed. Run the following code:
These steps perform the following actions:
- Install the library dependencies
- Construiește proiectul
- Generate a valid CloudFormation template
- Deploy the stack using AWS CloudFormation in your AWS account
The deployment takes about 1–2 minutes and creates the DynamoDB lookup table, Lambda function, and S3 bucket containing the historical log files as outputs. Copy these values to a text editing application, such as Notepad.
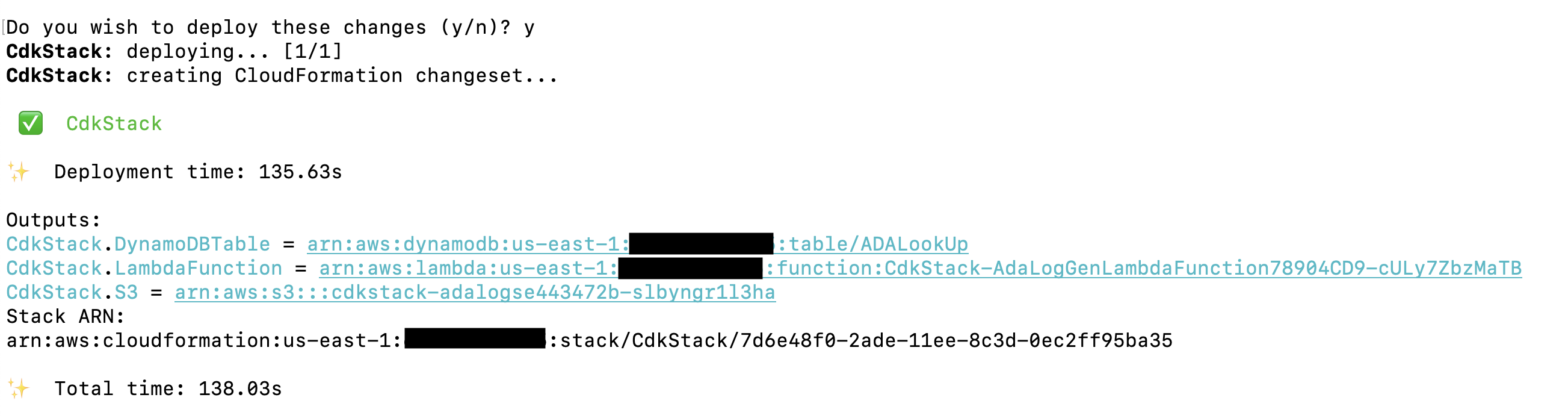
Create ADA data products
We create three different data products for this demo, one for each data source that you’ll be querying to gain operational insights. A data product is a dataset (a collection of data such as a table or a CSV file) that has been successfully imported into ADA and that can be queried.
Create a CloudWatch data product
First, we create a data product for the application logs by setting up ADA to ingest the CloudWatch log group for the sample application (Lambda function). Use the CdkStack.LambdaFunction output to get the Lambda function ARN and locate the corresponding CloudWatch log group ARN on the CloudWatch console.
Apoi parcurgeți următorii pași:
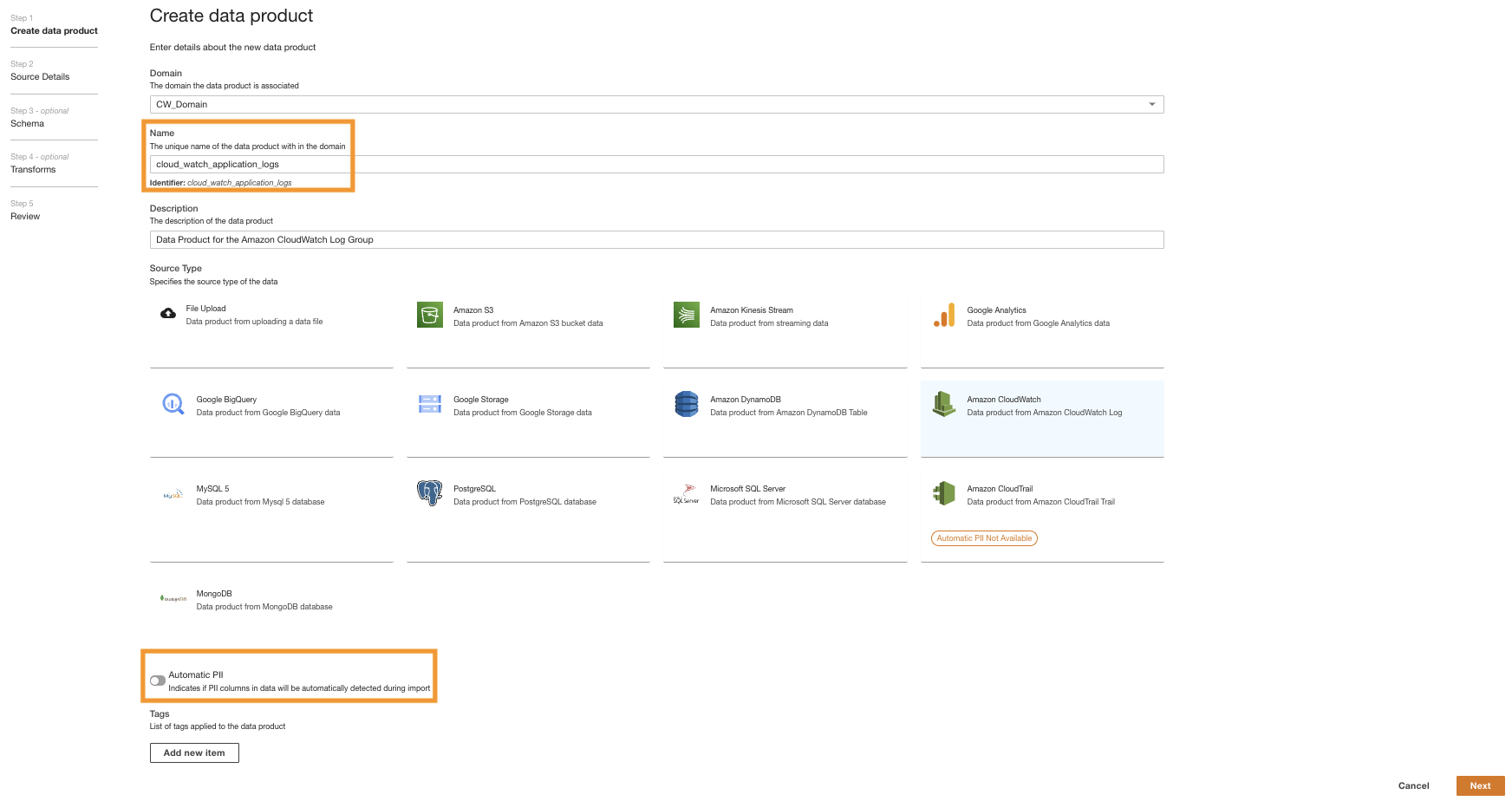
- On the ADA console, navigate to the ADA domain and create a CloudWatch data product.
- Pentru Nume si Prenume¸ introduceți un nume.
- Pentru Source type, alege Amazon CloudWatch.
- Dezactivați Automatic PII.
ADA has a feature that automatically detects personally identifiable information (PII) data during import that is enabled by default. For this demo, we disable this option for the data product because the discovery of PII data is not in the scope of this demo.
- Alege Pagina Următoare →.
- Search for and choose the CloudWatch log group ARN copied from the previous step.

- Copy the log group ARN.
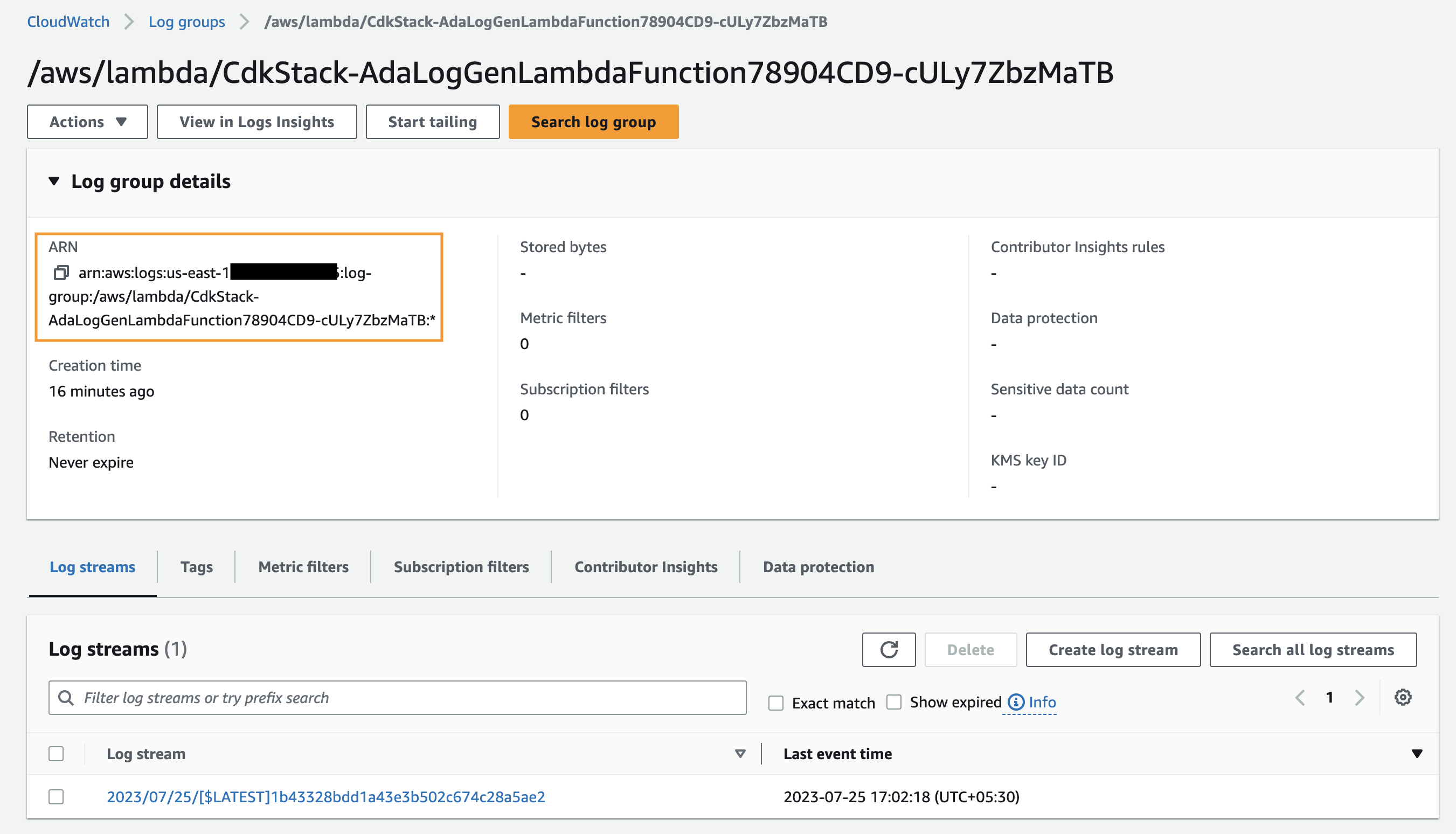
- On the data product page, enter the log group ARN.
- Pentru CloudWatch Query, enter a query that you want ADA to get from the log group.
In this demo, we query the @message field because we’re interested in getting the application logs from the log group.
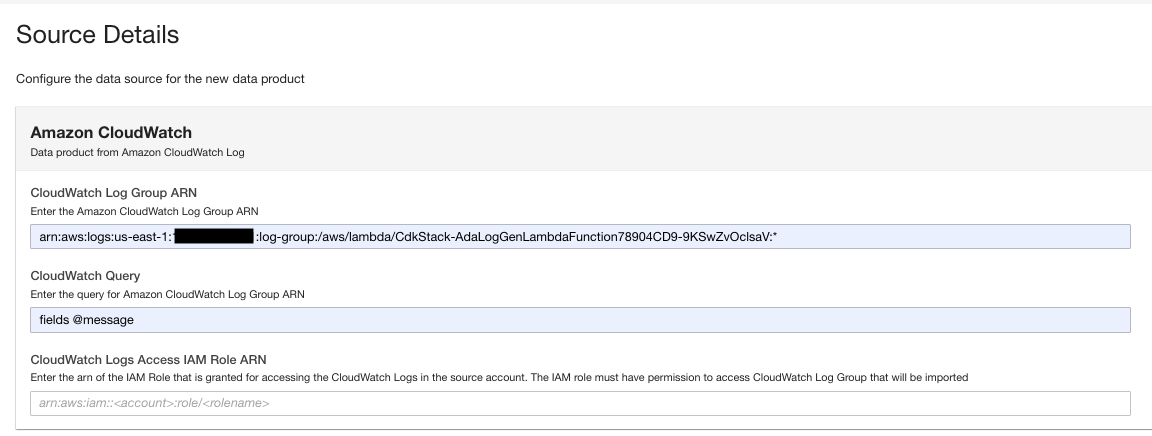
- Select how the data updates are triggered after initial import.
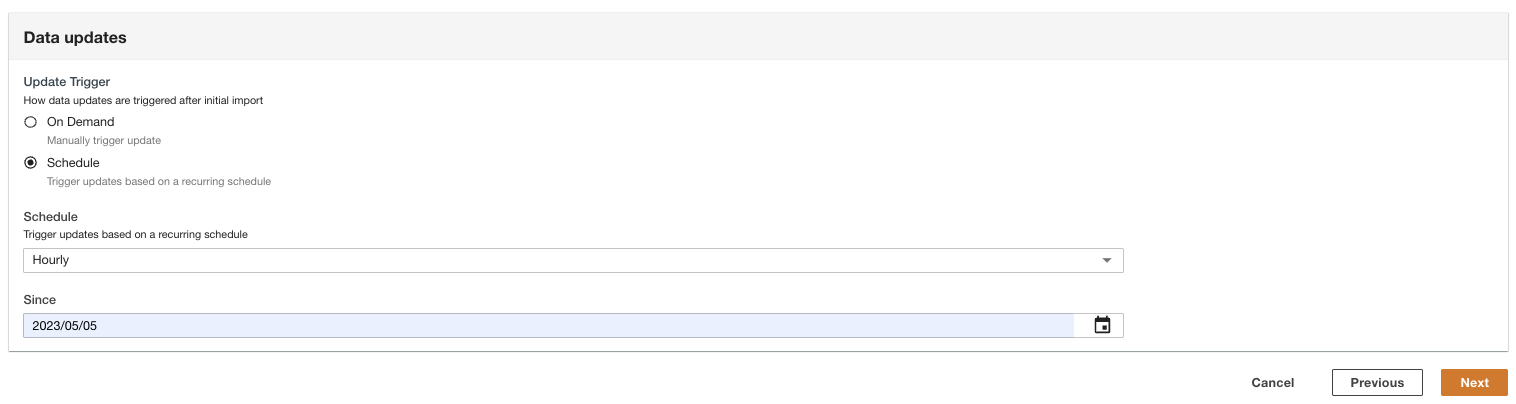
ADA can be configured to ingest the data from the source at flexible intervals (up to 15 minutes or later) or on demand. For the demo, we set the data updates to run hourly.
- Alege Pagina Următoare →.
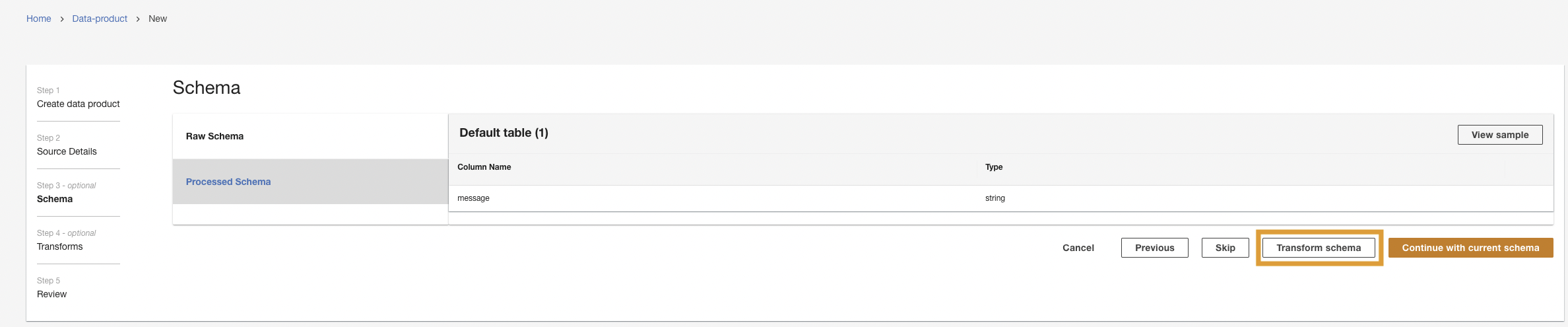
Next, ADA will connect to the log group and query the schema. Because the logs are in Apache Log Format, we transform the logs into separate fields so that we can run queries on the specific log fields. ADA provides four lipsă transformations and supports custom transformation through a Python script. In this demo, we run a custom Python script to transform the JSON message field into Apache Log Format fields.
- Alege Transform schema.
- Alege Create new transform.
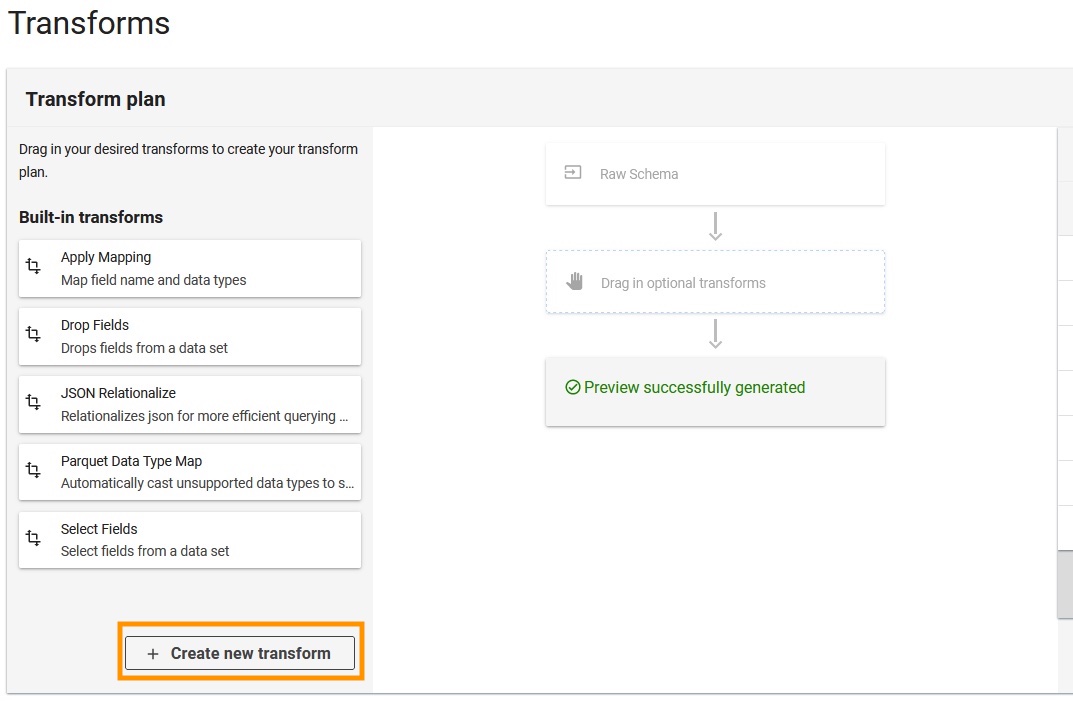
- Încărcați
apache-log-extractor-transform.pyscript from the/asset/transform_logs/dosar. - Alege Trimite mesaj.
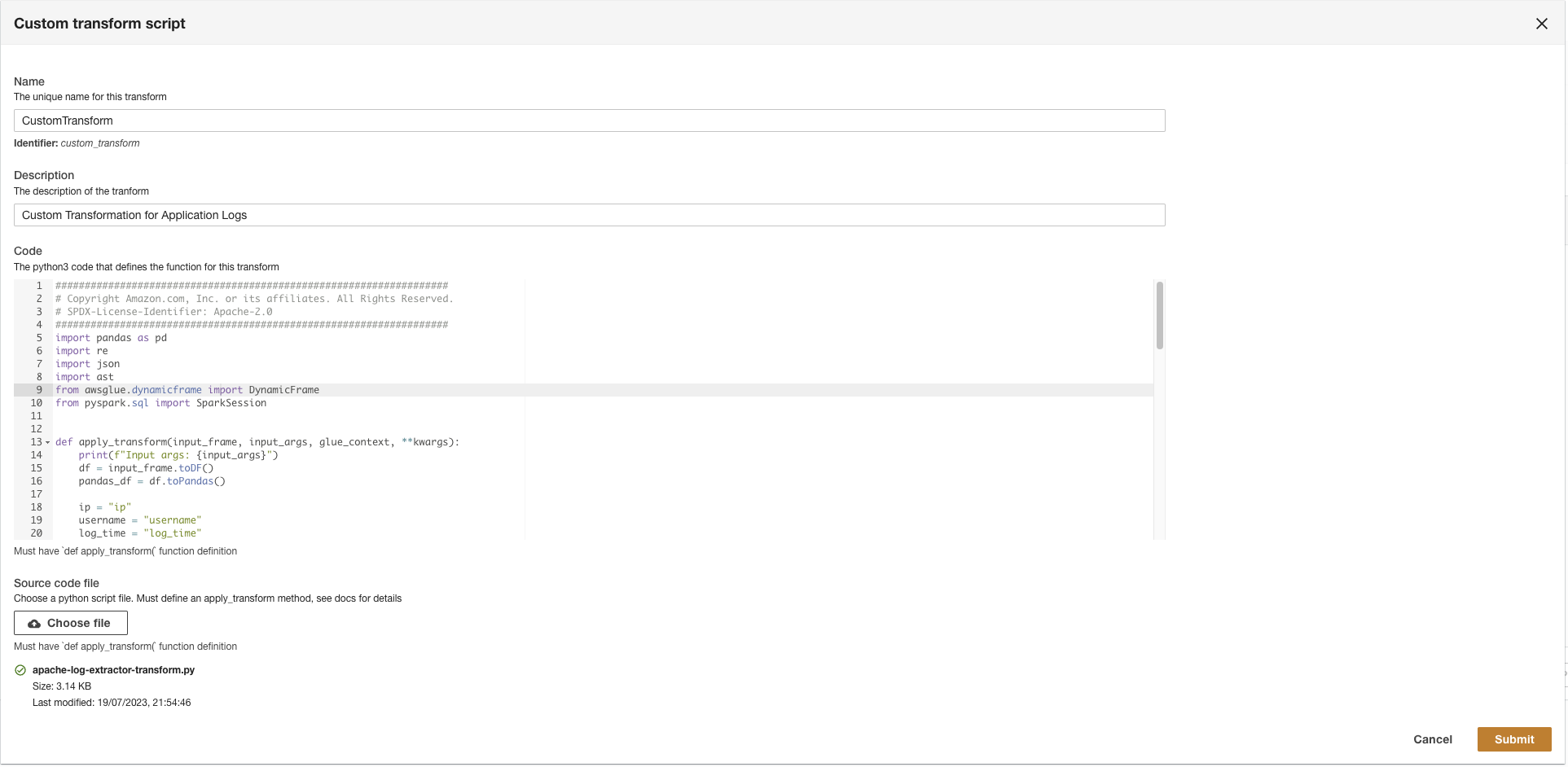
ADA will transform the CloudWatch logs using the script and present the processed schema.
- Alege Pagina Următoare →.
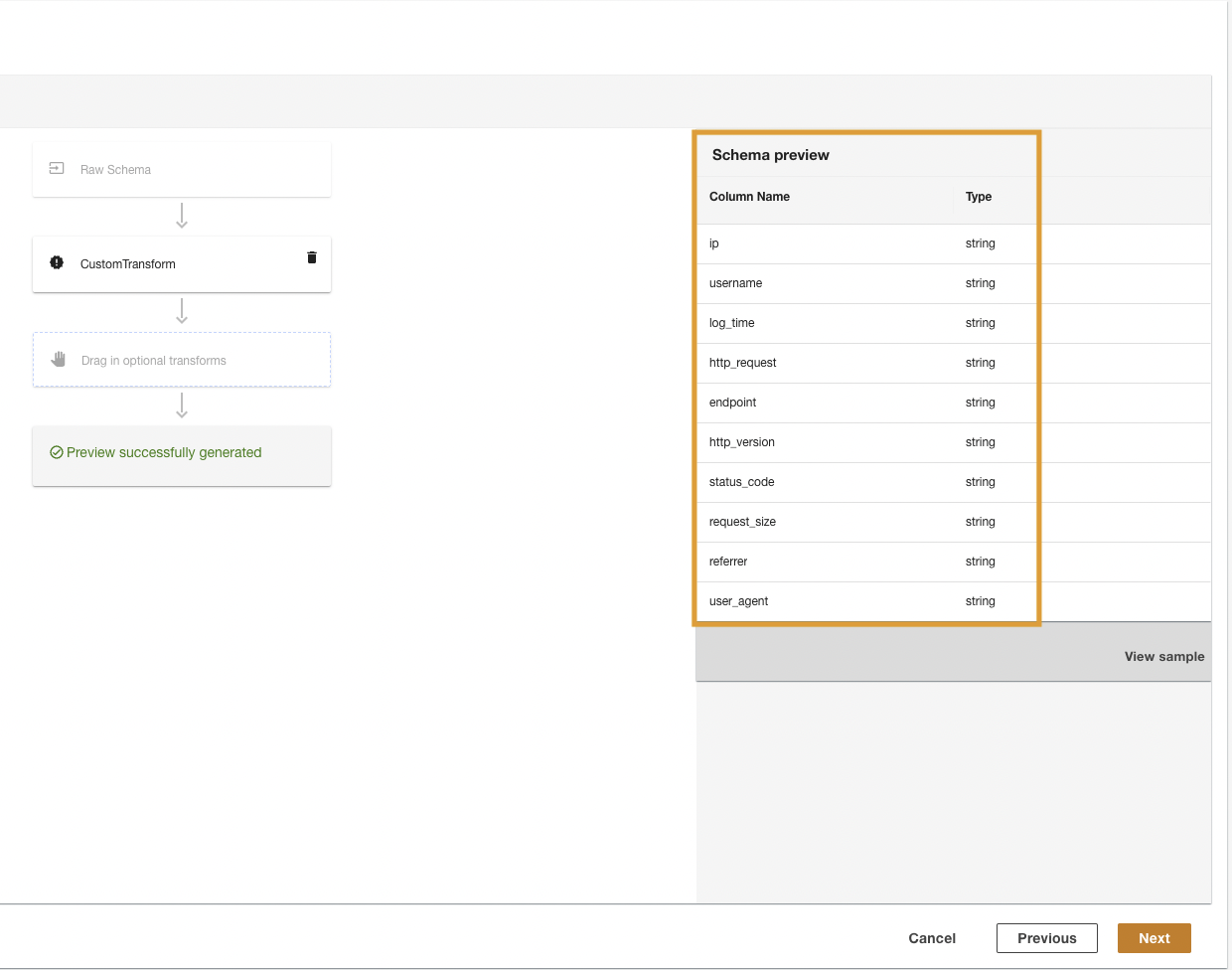
- In the last step, review the steps and choose Trimite mesaj.
ADA will start the data processing, create the data pipelines, and prepare the CloudWatch log groups to be queried from the Query Workbench. This process will take a few minutes to complete and will be shown on the ADA console under Produse de date.
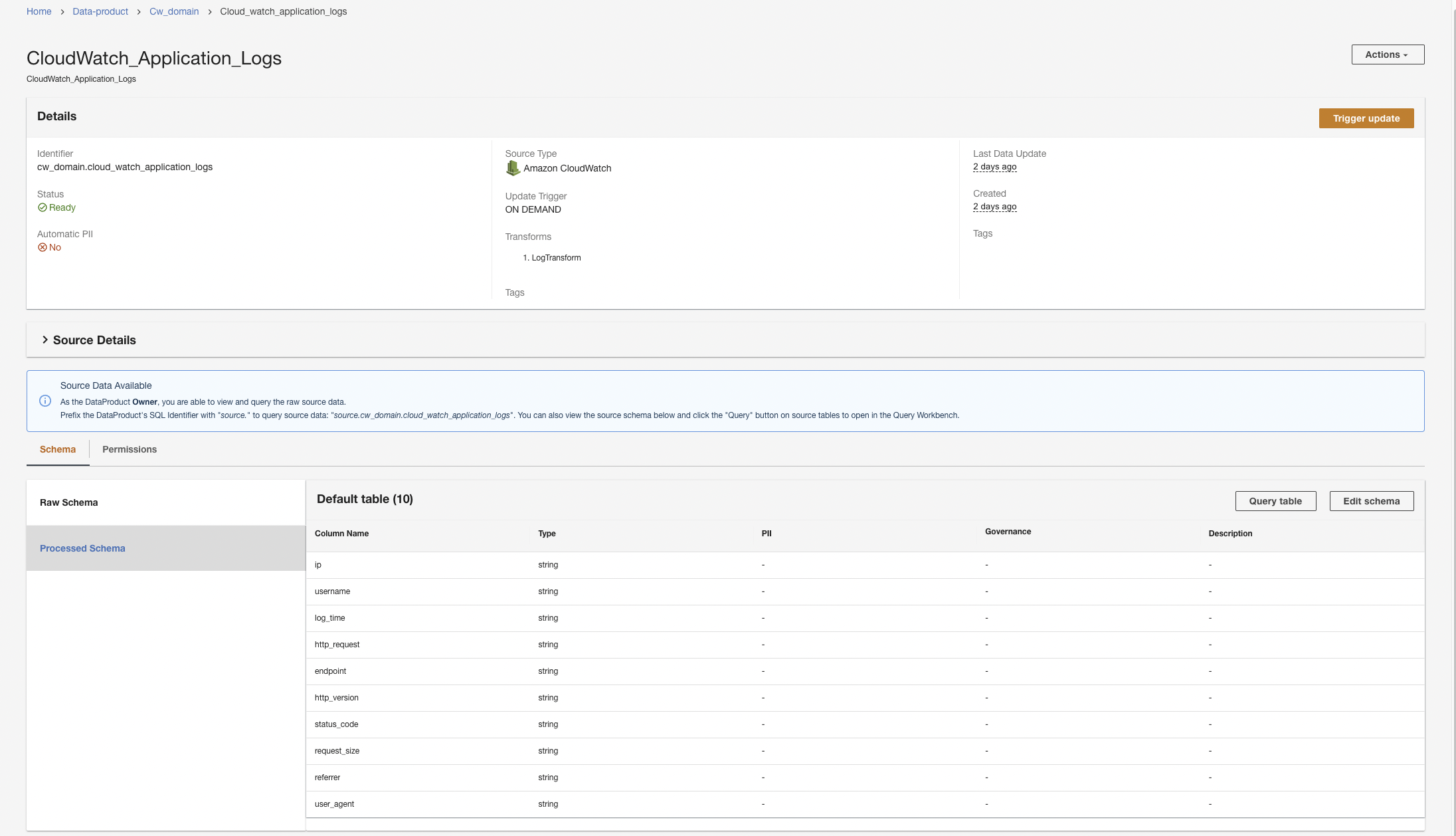
Create an Amazon S3 data product
We repeat the steps to add the historical logs from the Amazon S3 data source and look up reference data from the DynamoDB table. For these two data sources, we don’t create custom transforms because the data formats are in CSV (for historical logs) and key attributes (for reference lookup data).
- On the ADA console, create a new data product.
- Introduceți un nume (
hist_logs) și alegeți Amazon S3.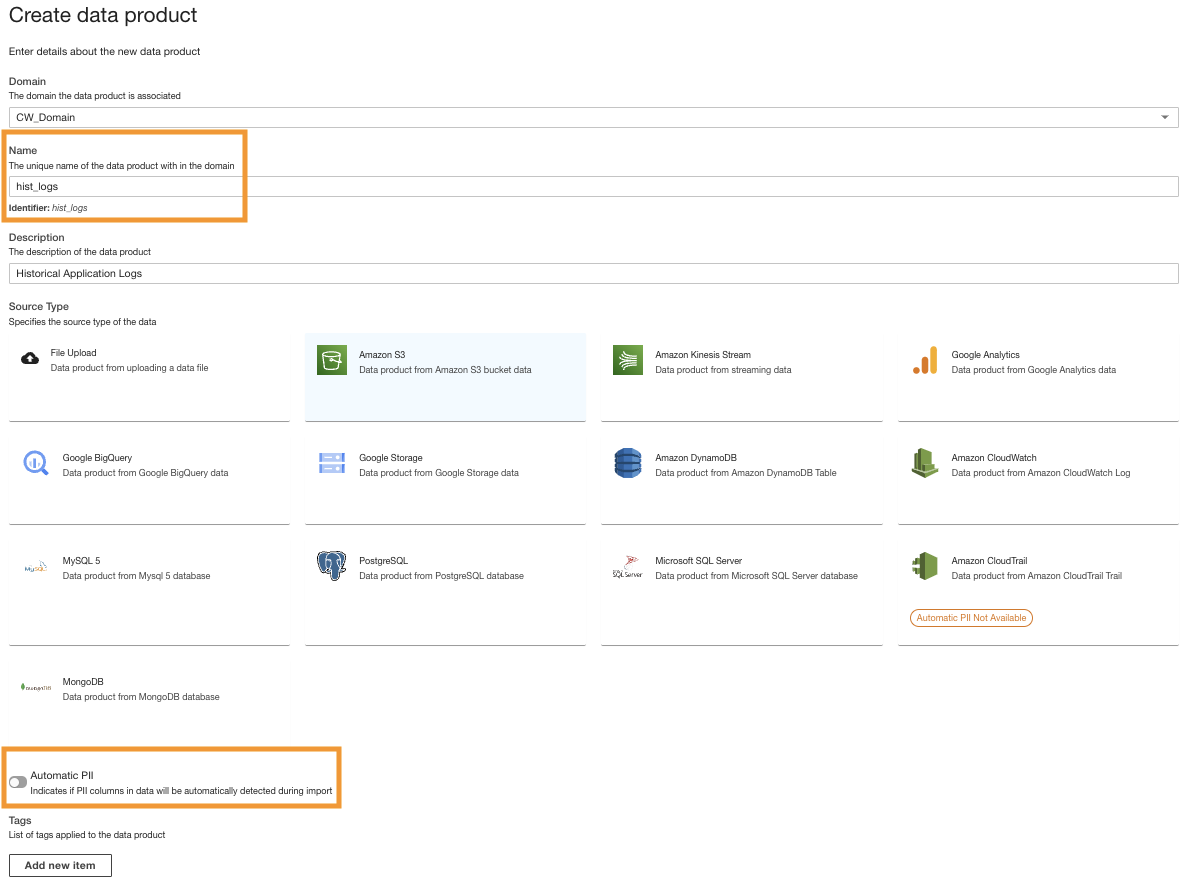
- Copy the Amazon S3 URI (the text after
arn:aws:s3:::) de laCdkStack.S3output variable and navigate to the Amazon S3 console. - In the search box, enter the copied text, open the S3 bucket, select the
/logsfolder, and choose Copy S3 URI.
The historical logs are stored in this path.
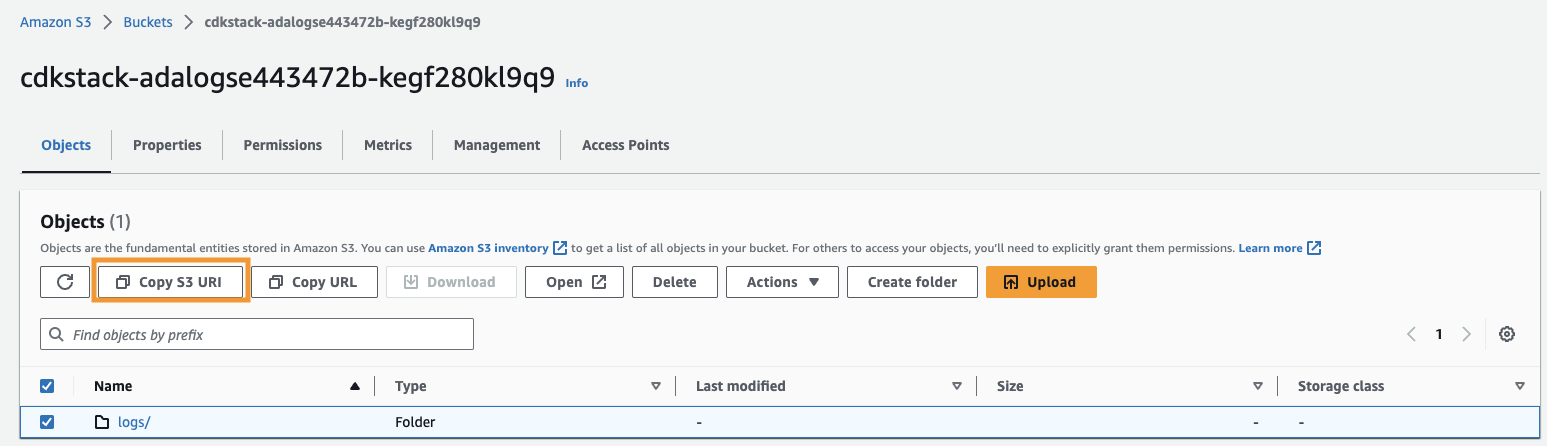
- Navigate back to the ADA console and enter the copied S3 URI for Locația S3.
- Pentru Actualizați Trigger, Selectați La cerere because the historical logs are updated at an unspecified frequency.
- Pentru Actualizați politica, Selectați Adăuga to append newly imported data to the existing data.
- Alege Pagina Următoare →.
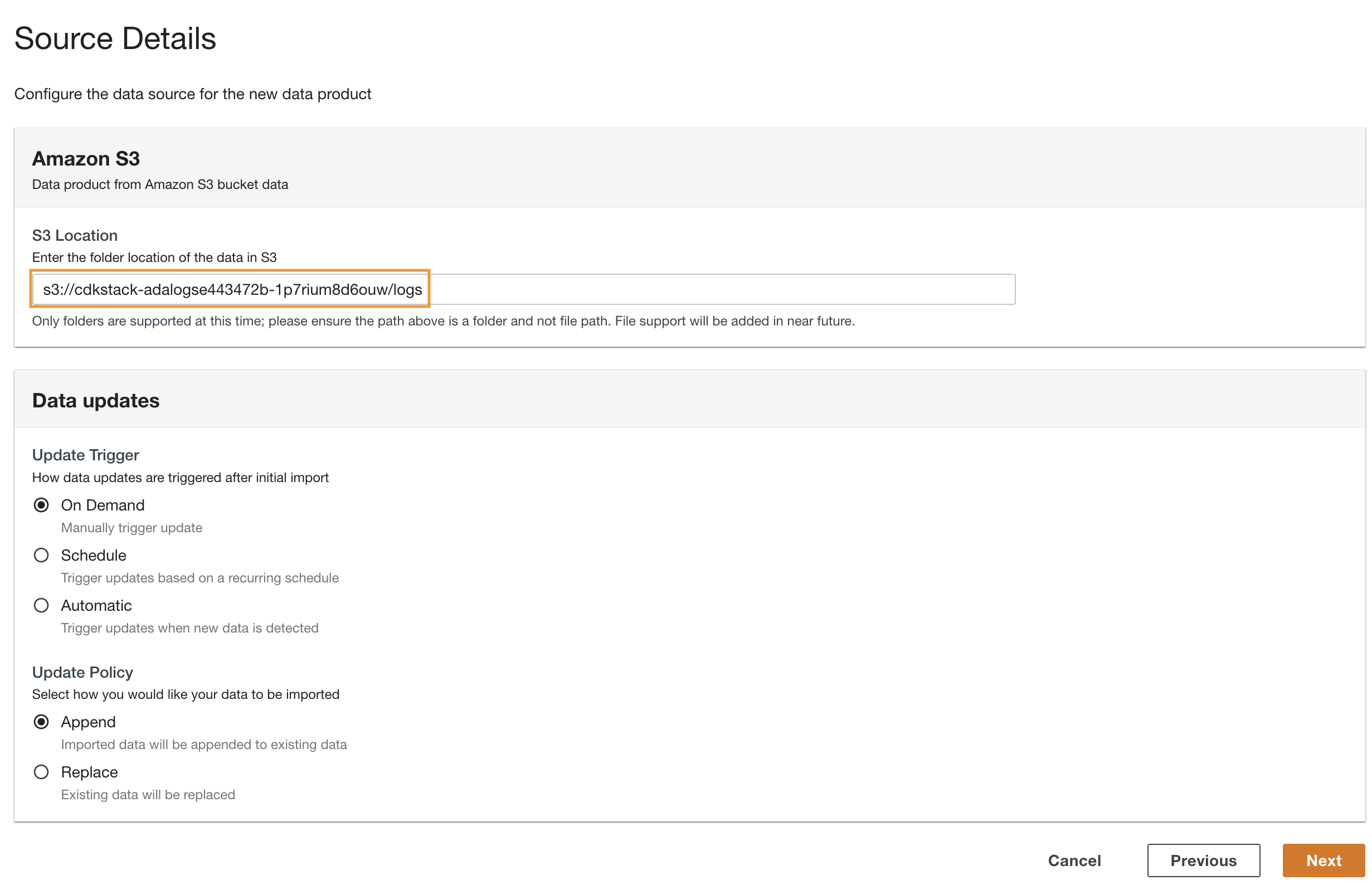
ADA processes the schema for the files in the selected folder path. Because the logs are in CSV format, ADA is able to read the column names without requiring additional transformations. However, the columns status_code și request_size are inferred as long type by ADA. We want to keep the column data types consistent among the data products so that we can join the data tables and query the data. The column status_code will be used to create joins across the data tables.
- Alege Transform schema to change the data types of the two columns to string data type.
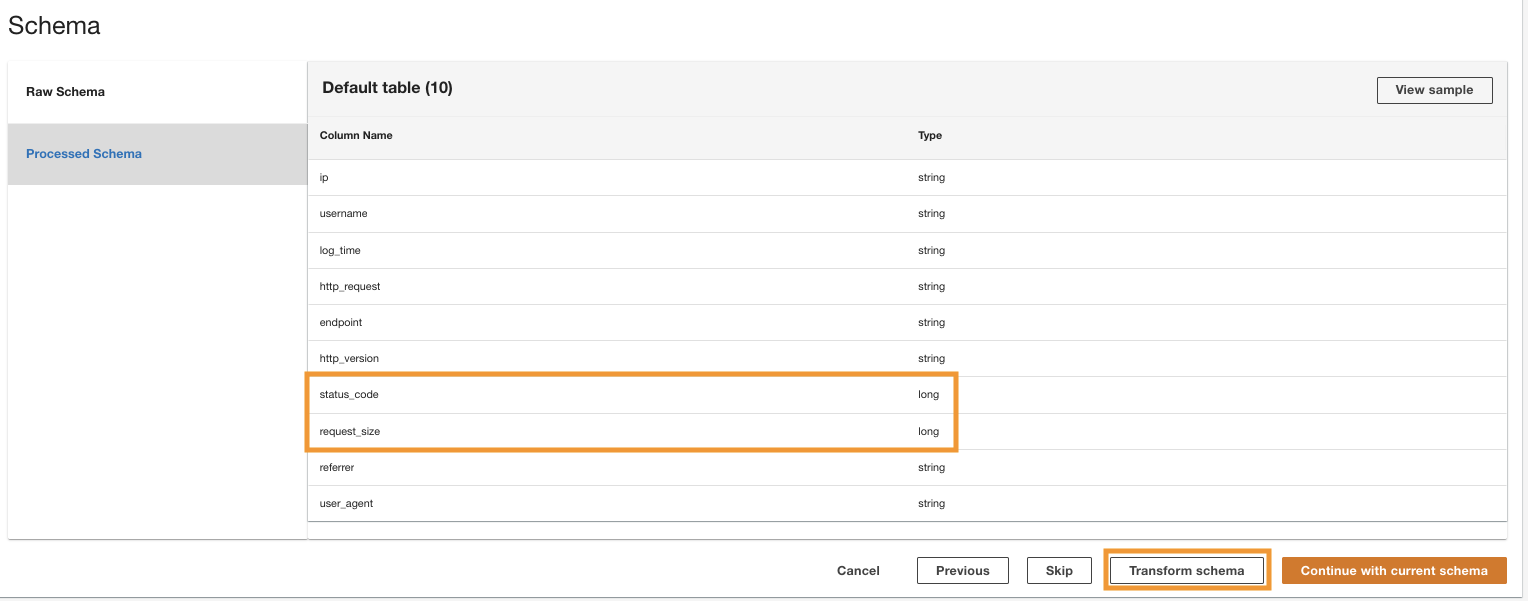
Note the highlighted column names in the Schema preview pane prior to applying the data type transformations.
- În Transform plan panou, sub Built-in transforms, alege Apply Mapping.
This option allows you to change the data type from one type to another.
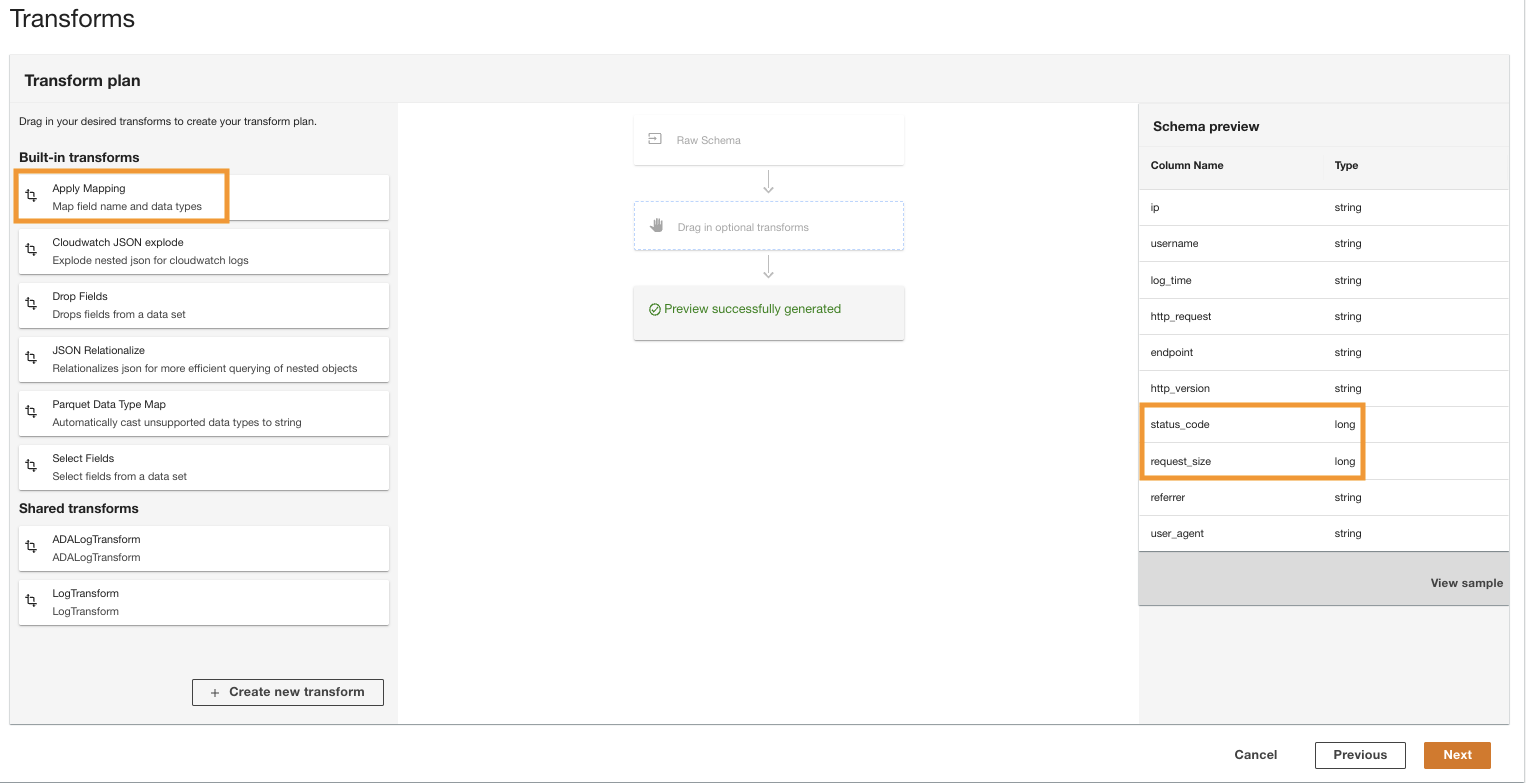
- În Apply Mapping section, deselect Drop other fields.
If this option is not disabled, only the transformed columns will be preserved and all other columns will be dropped. Because we want to retain all the columns, we disable this option.
- În Mapări de câmppentru Numele vechi și Nume nou, introduce
status_codesi pentru Tip nou, introducestring.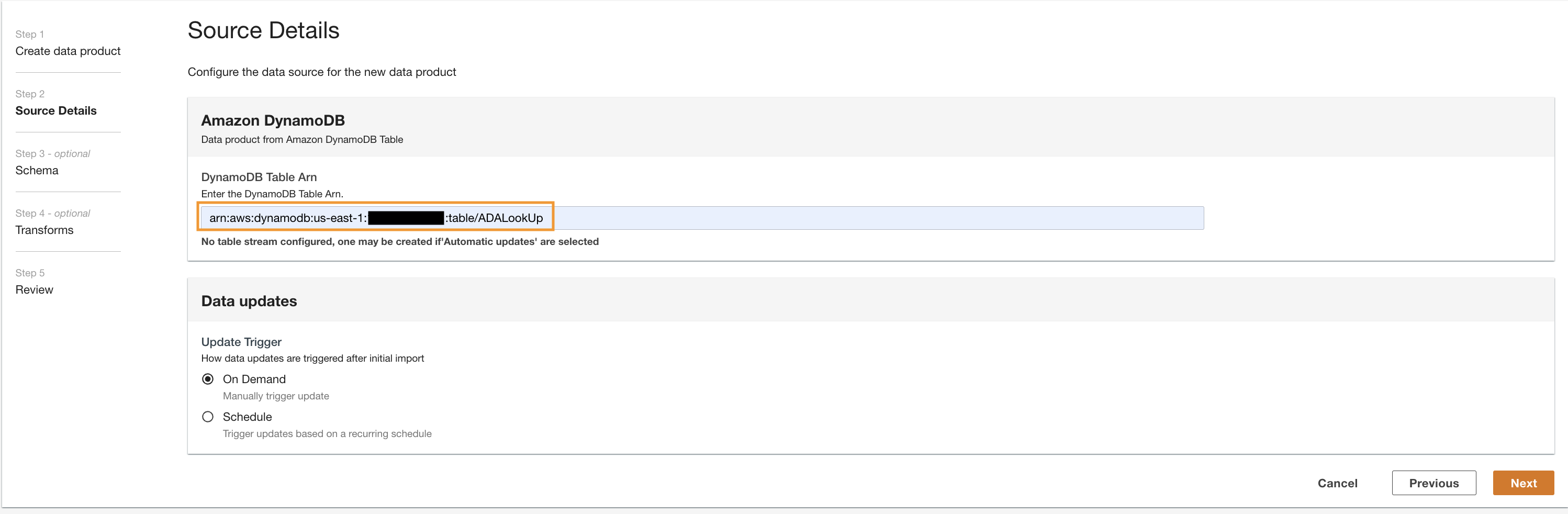
- Alege Adaugare element.
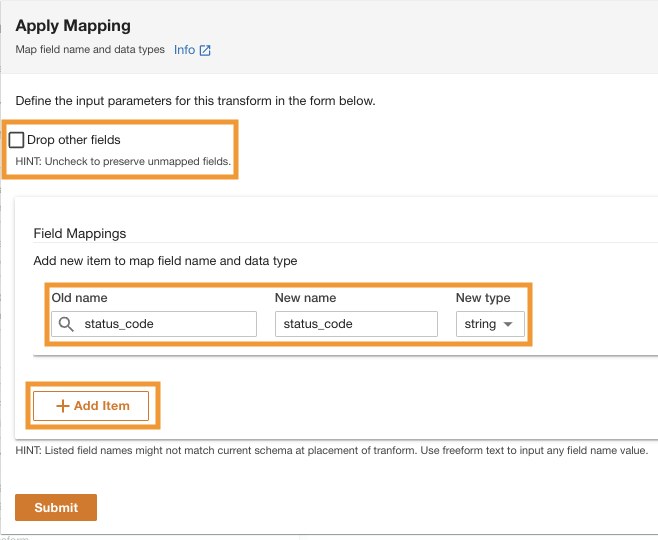
- Pentru Numele vechi și Nume nou¸ enter request_size and for New data type, enter string.
- Alege Trimite mesaj.
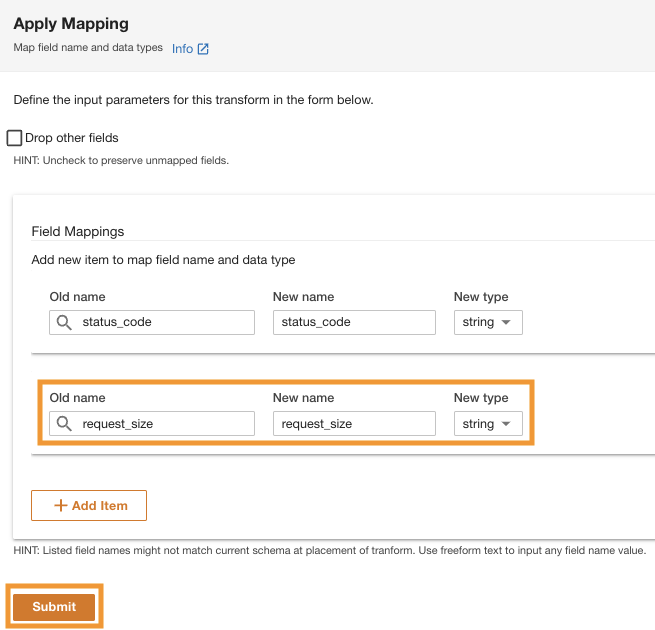
ADA will apply the mapping transformation on the Amazon S3 data source. Note the column types in the Schema preview panoul.
- Alege View sample to preview the data with the transformation applied.
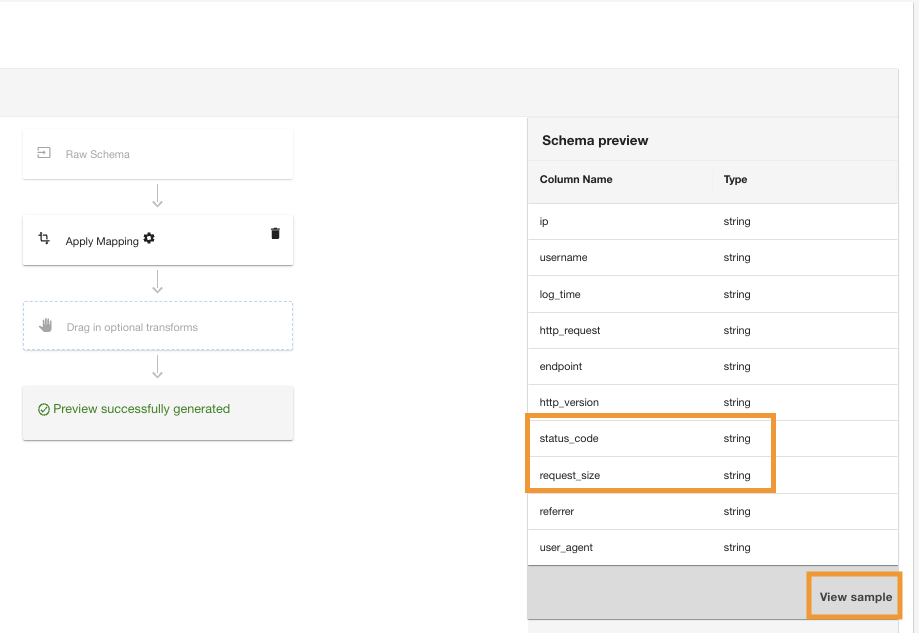
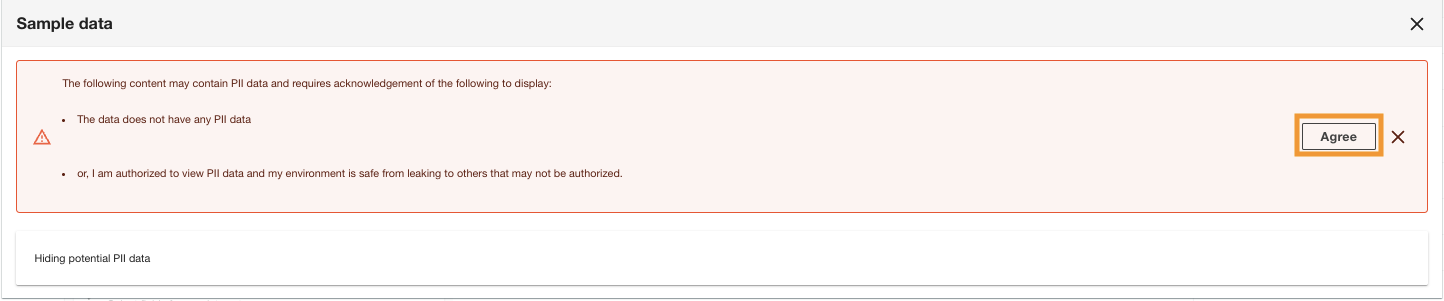
ADA will display the PII data acknowledgement to ensure that either only authorized users can view the data or that the dataset doesn’t contain any PII data.
- Alege Conveni to continue to view the sample data.
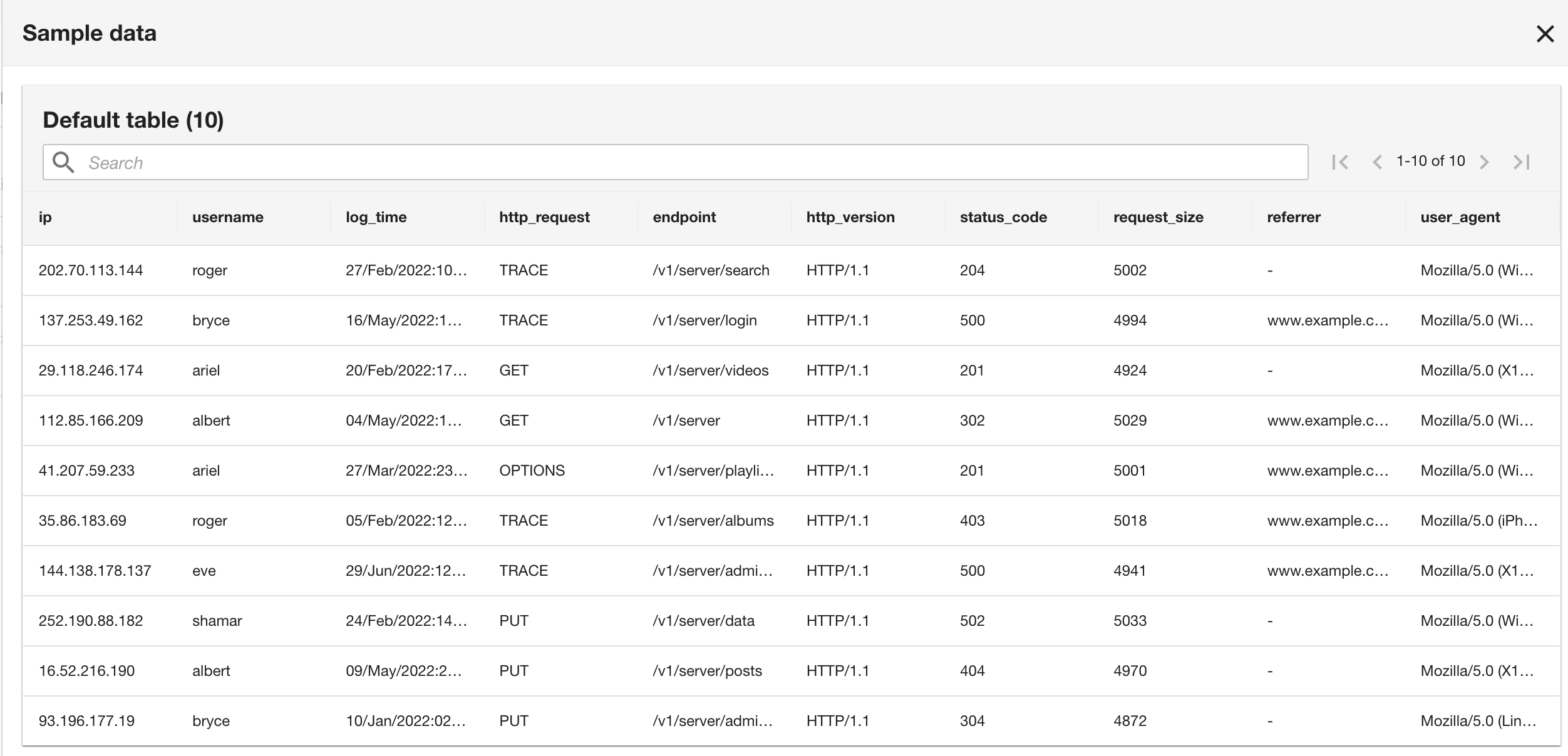
Note that the schema is identical to the CloudWatch log group schema because both the current application and historical application logs are in Apache Log Format.
- In the final step, review the configuration and choose Trimite mesaj.
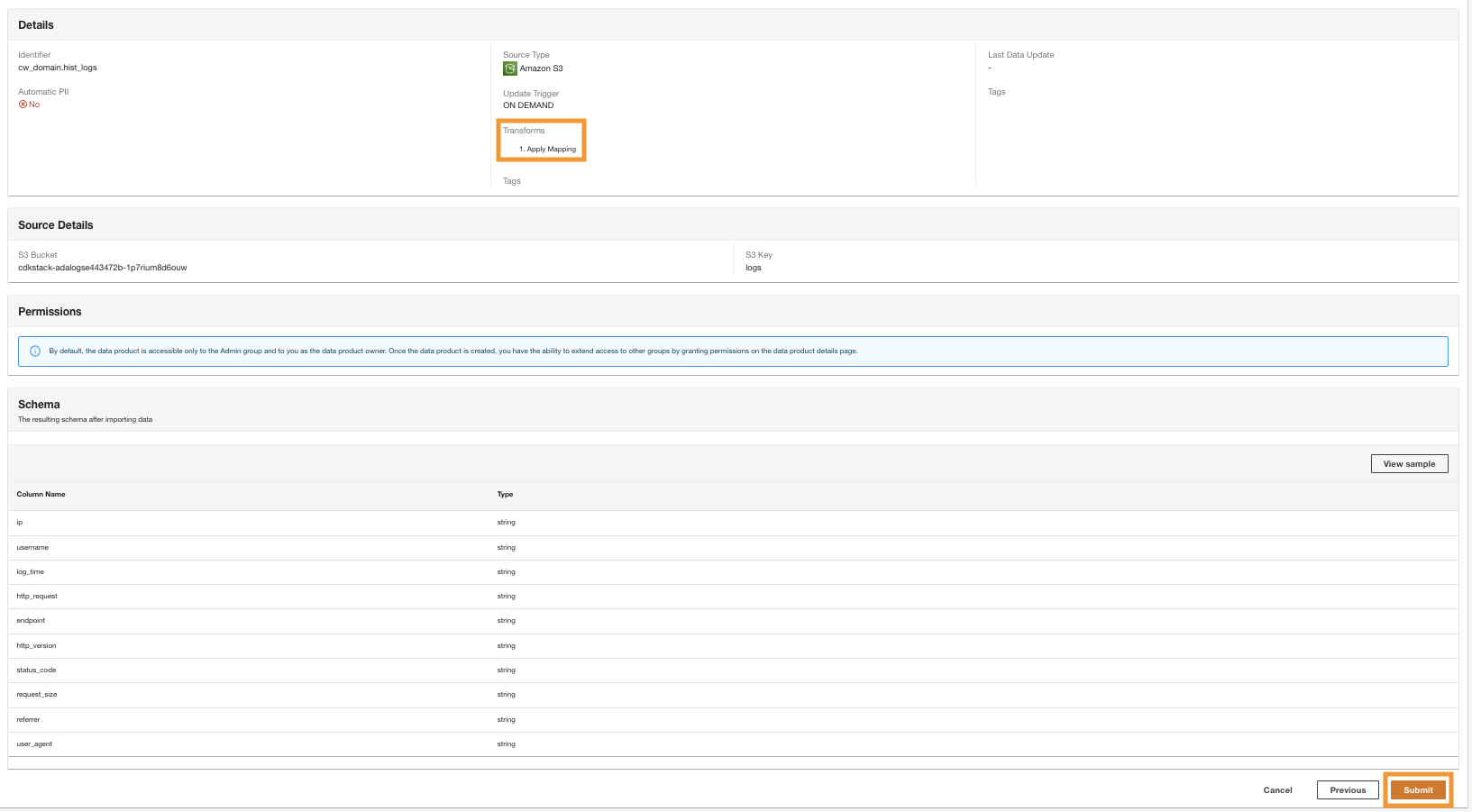
ADA starts processing the data from the Amazon S3 source, creates the backend infrastructure, and prepares the data product. This process takes a few minutes depending upon the size of the data.
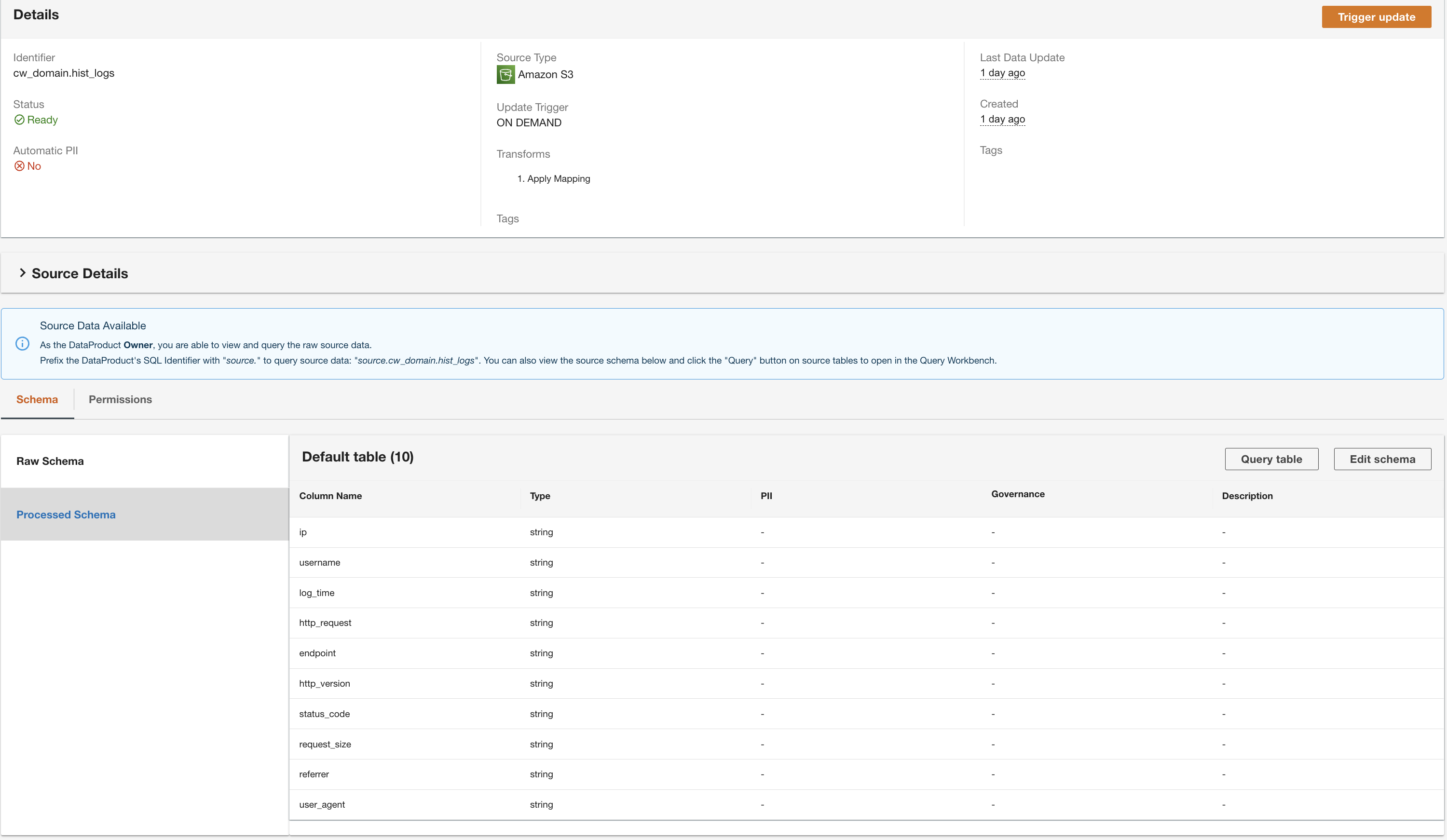
Create a DynamoDB data product
Lastly, we create a DynamoDB data product. Complete the following steps:
- On the ADA console, create a new data product.
- Introduceți un nume (
lookup) și alegeți Amazon DynamoDB.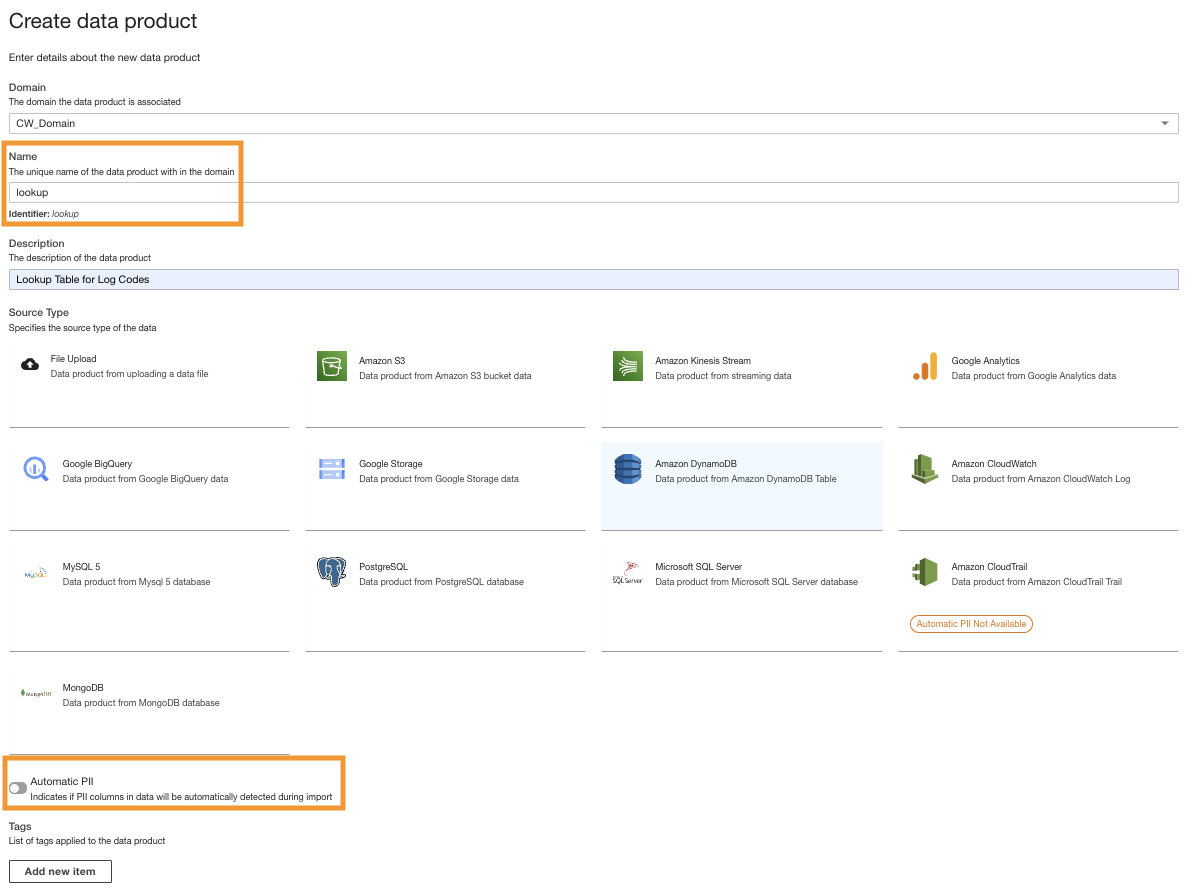
- Introduceţi
Cdk.DynamoDBTableoutput variable for DynamoDB Table ARN.
This table contains key attributes that will be used as a lookup table in this demo. For the lookup data, we are using the HTTP codes and long and short descriptions of the codes. You can also use PostgreSQL, MySQL, or a CSV file source as an alternative.
- Pentru Actualizați Trigger, Selectați La cerere.
The updates will be on demand because the lookup is mostly for reference purpose while querying and any updates to the lookup data can be updated in ADA using on-demand triggers.
- Alege Pagina Următoare →.
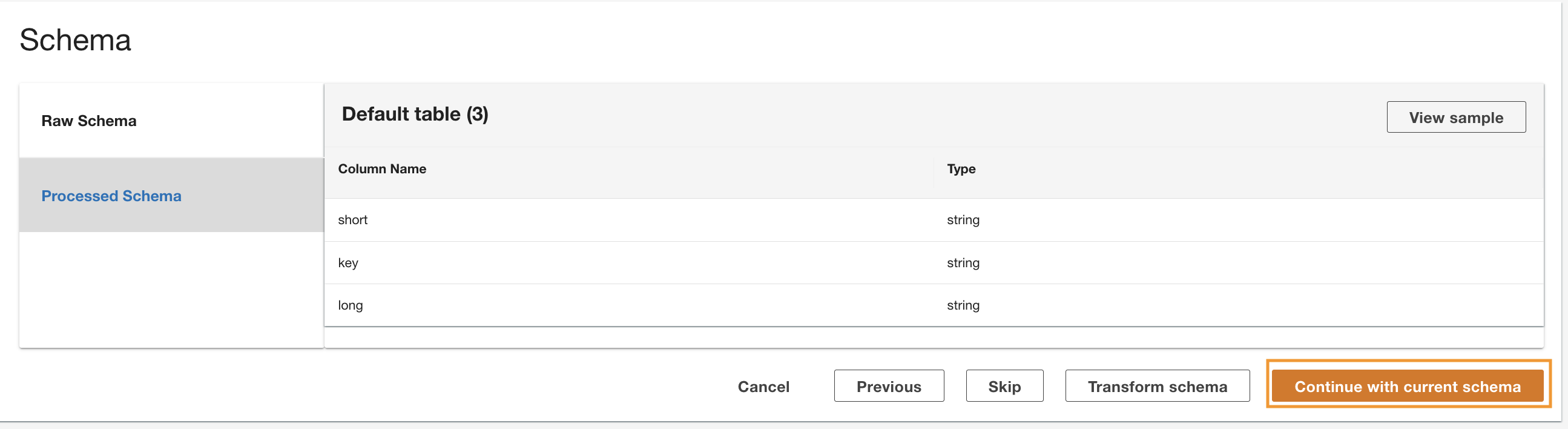
ADA reads the schema from the underlying DynamoDB schema and presents the column name and type for optional transformation. We will proceed with the default schema selection because the column types are consistent with the types from the CloudWatch log group and Amazon S3 CSV data source. Having data types that are consistent across the data sources allows us to write queries to fetch records by joining the tables using the column fields. For example, the column key in the DynamoDB schema corresponds to the status_code in the Amazon S3 and CloudWatch data products. We can write queries that can join the three tables using the column name key. An example is shown in the next section.
- Alege Continue with current schema.
- Examinați configurația și alegeți Trimite mesaj.
ADA will process the data from the DynamoDB table data source and prepare the data product. Depending upon the size of the data, this process takes a few minutes.
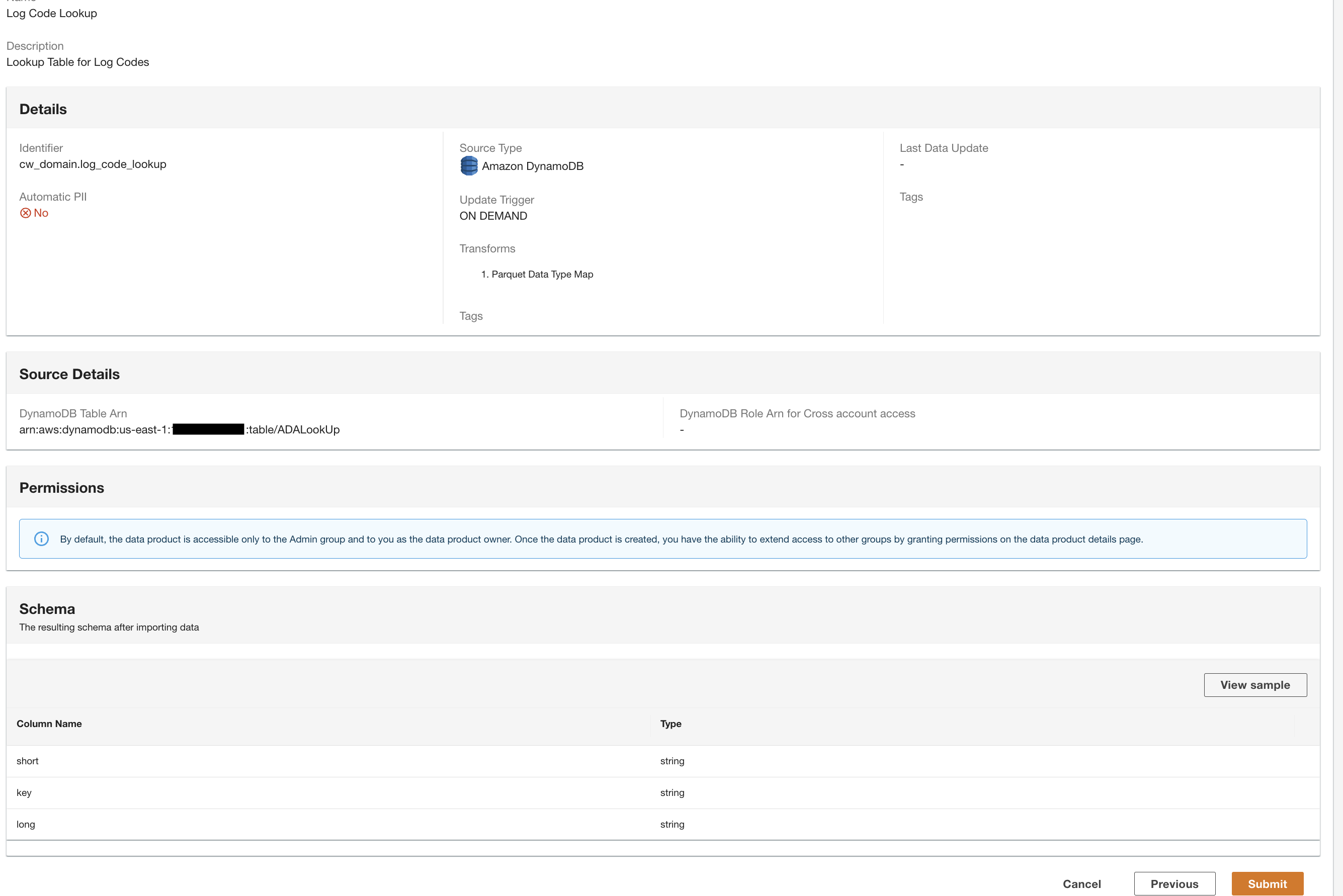
Now we have all the three data products processed by ADA and available for you to run queries.

Use the Query Workbench to query the data
ADA allows you to run queries against the data products while abstracting the data source and making it accessible using SQL (Structured Query Language). You can write queries and join the tables just as you would query against tables in a relational database. We demonstrate ADA’s querying capability via two user scenarios. In both the scenarios, we join an application log dataset to the error codes lookup table. In the first use case, we query the current application logs to identify the top 10 most accessed application endpoints along with the corresponding HTTP status codes:
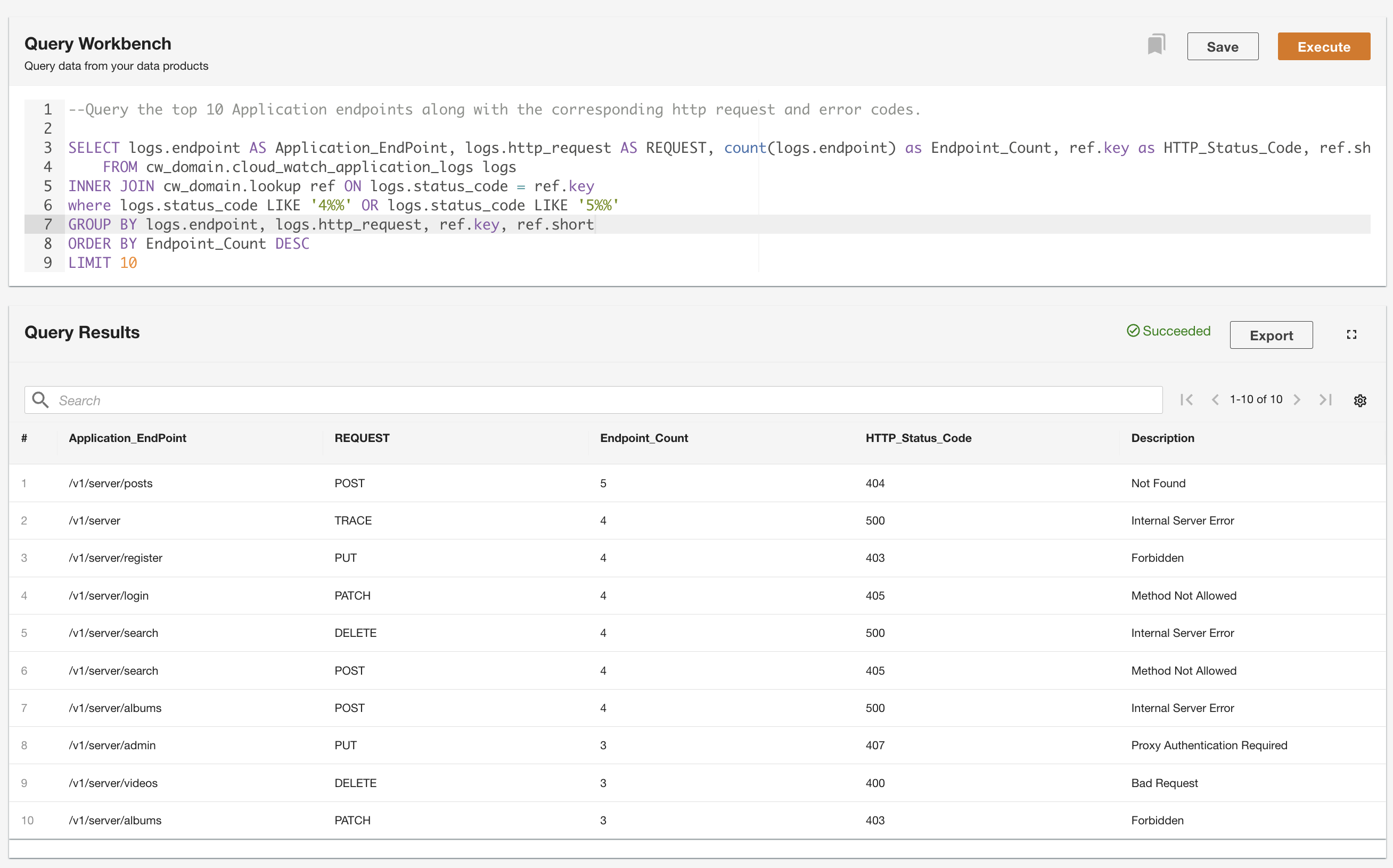
In the second example, we query the historical logs table to get the top 10 application endpoints with the most errors to understand the endpoint call pattern:
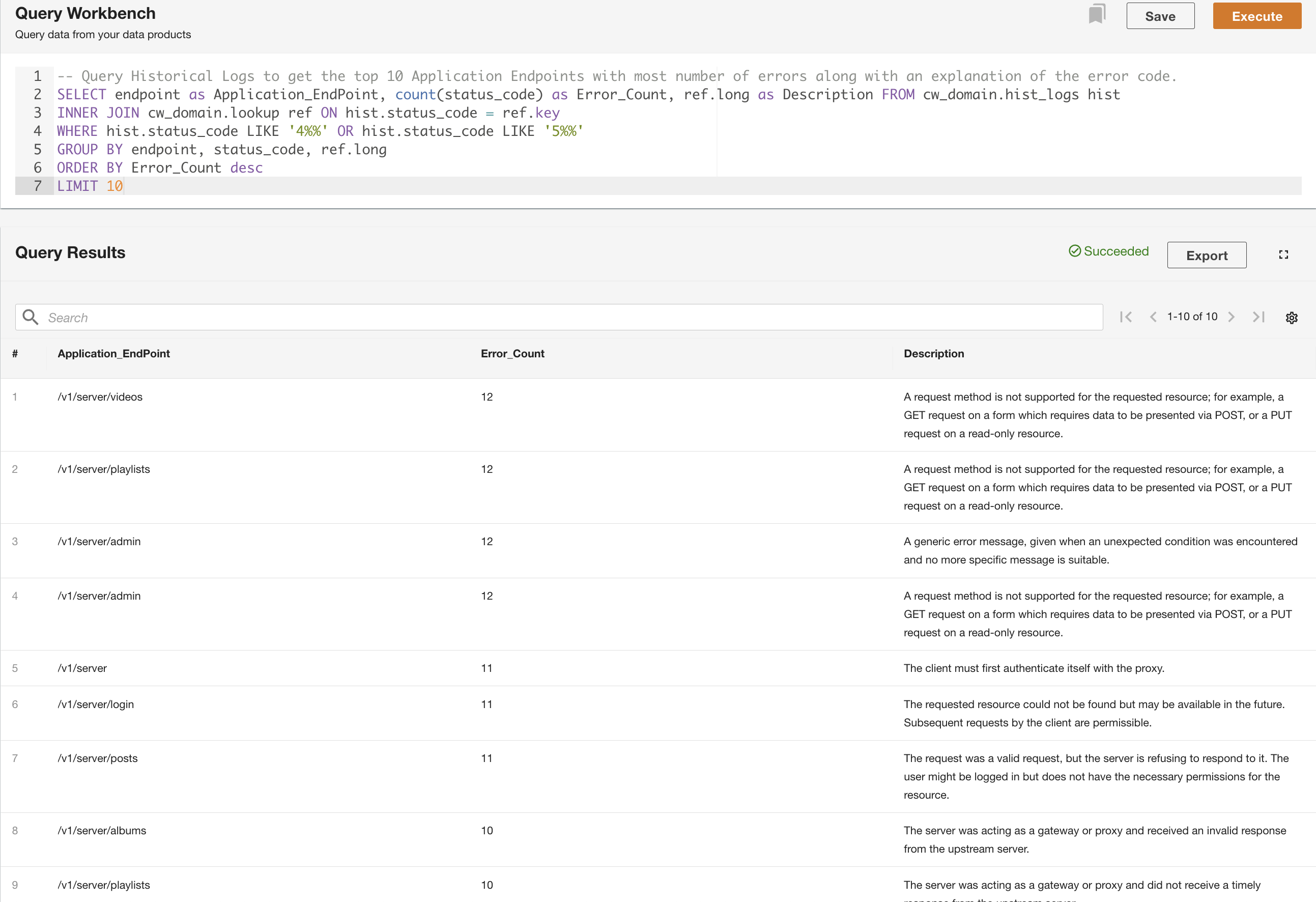
In addition to querying, you can optionally save the query and share the saved query with other users in the same domain. The shared queries are accessible directly from the Query Workbench. The query results can also be exported to CSV format.
Visualize ADA data products in Tableau
ADA offers the ability to conectaţi to third-party BI tools to visualize data and create reports from the ADA data products. In this demo, we use ADA’s native integration with Tableau to visualize the data from the three data products we configured earlier. Using Tableau’s Athena connector and following the steps in Tableau configuration, you can configure ADA as a data source in Tableau. After a successful connection has been established between Tableau and ADA, Tableau will populate the three data products under the Tableau catalog cw_domain.
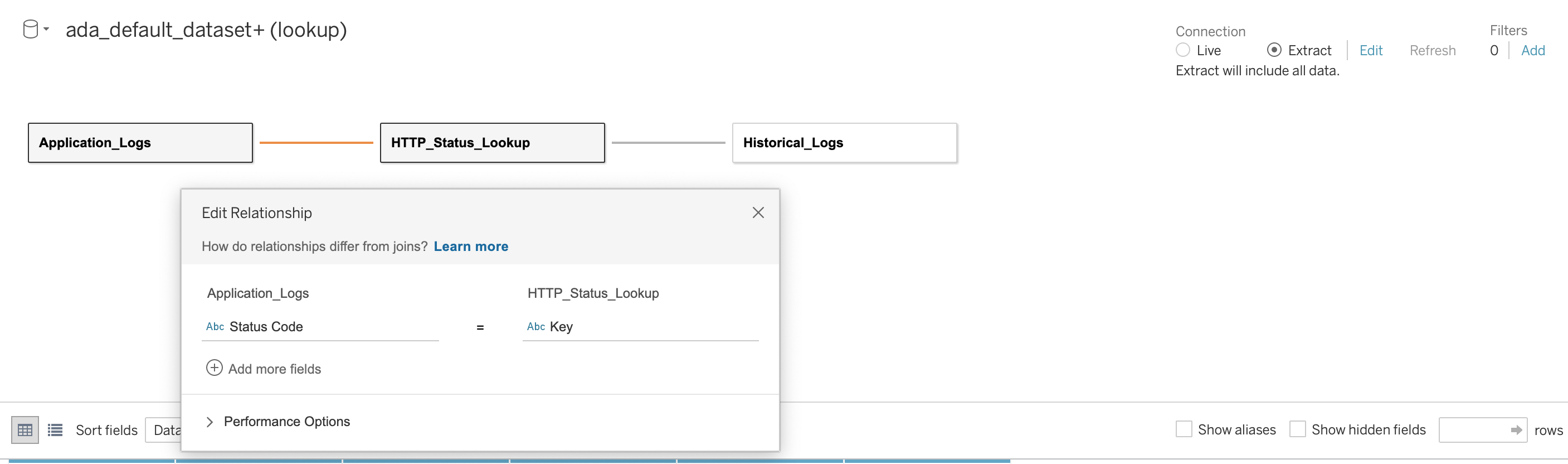
We then establish a relationship across the three databases using the HTTP status code as the joining column, as shown in the following screenshot. Tableau allows us to work in online and offline mode with the data sources. In online mode, Tableau will connect to ADA and query the data products live. In offline mode, we can use the Extrage option to extract the data from ADA and import the data in to Tableau. In this demo, we import the data in to Tableau to make the querying more responsive. We then save the Tableau workbook. We can inspect the data from the data sources by choosing the database and Actualizează acum.
With the data source configurations in place in Tableau, we can create custom reports, charts, and visualizations on the ADA data products. Let’s consider two use cases for visualizations.
As shown in the following figure, we visualized the frequency of the HTTP errors by application endpoints using Tableau’s built-in harta termografica chart. We filtered out the HTTP status codes to only include error codes in the 4xx and 5xx range.
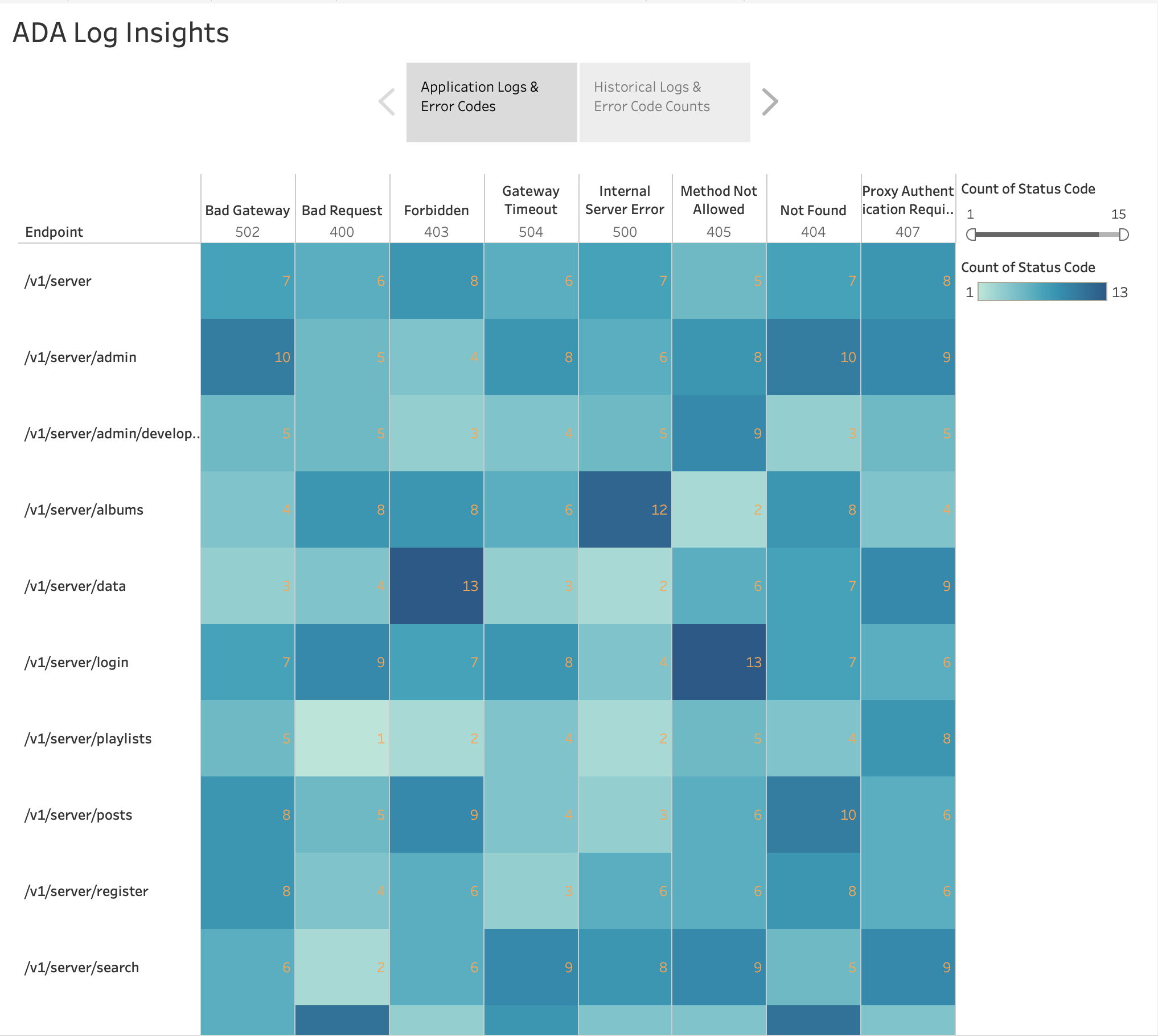
We also created a bar chart to depict the application endpoints from the historical logs ordered by the count of HTTP error codes. In this chart, we can see that the /v1/server/admin endpoint has generated the most HTTP error status codes.
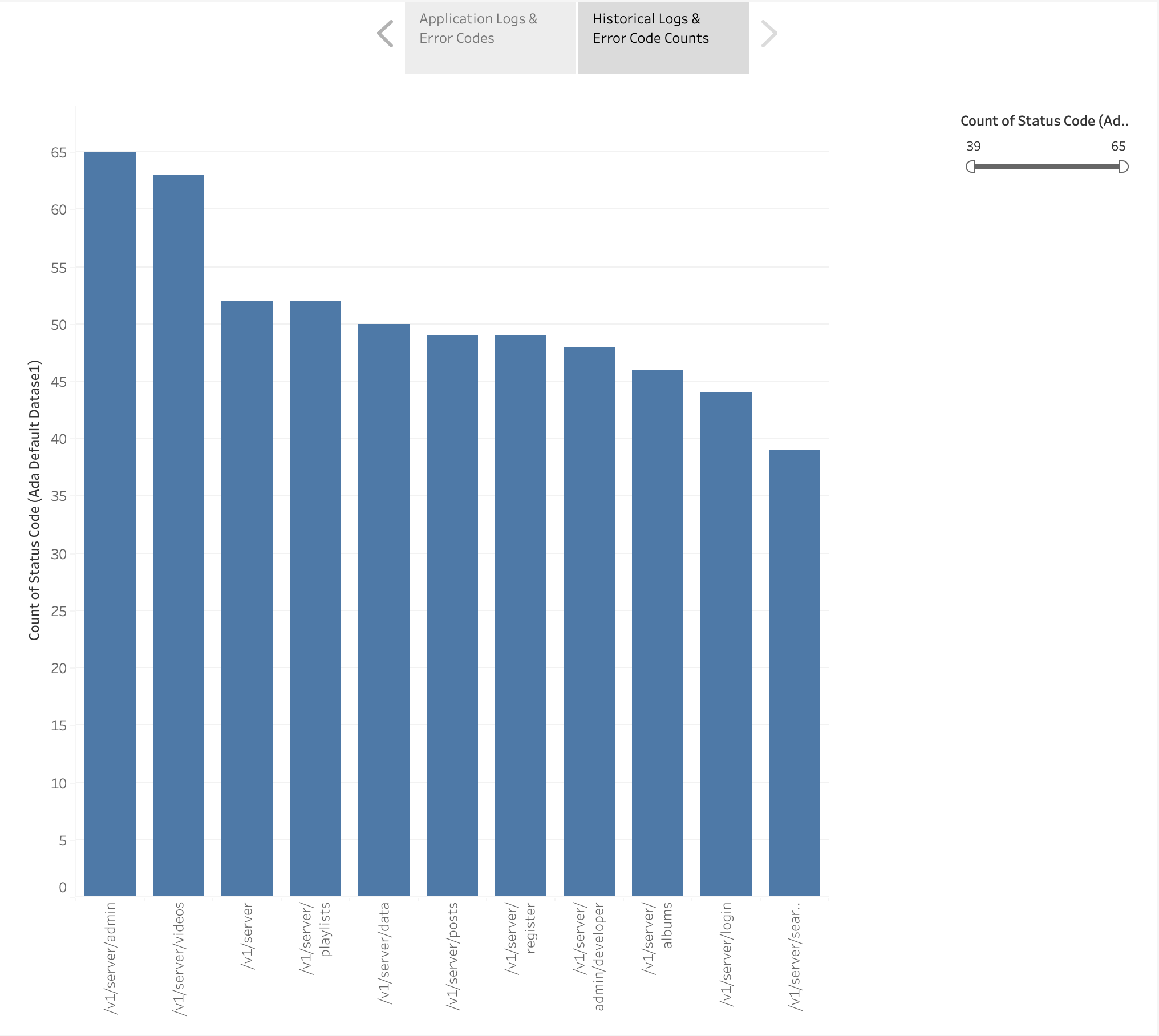
A curăța
Cleaning up the sample application infrastructure is a two-step process. First, to remove the infrastructure provisioned for the purposes of this demo, run the following command in the terminal:
For the following question, enter y and AWS CDK will delete the resources deployed for the demo:
Alternatively, you can remove the resources via the AWS CloudFormation console by navigating to the CdkStack stack and choosing Șterge.
The second step is to uninstall ADA. For instructions, refer to Dezinstalează soluția.
Concluzie
In this post, we demonstrated how to use the ADA solution to derive insights from application logs stored across two different data sources. We demonstrated how to install ADA on an AWS account and deploy the demo components using AWS CDK. We created data products in ADA and configured the data products with the respective data sources using the ADA’s built-in data connectors. We demonstrated how to query the data products using standard SQL queries and generate insights on the log data. We also connected the Tableau Desktop client, a third-party BI product, to ADA and demonstrated how to build visualizations against the data products.
ADA automates the process of ingesting, transforming, governing, and querying diverse datasets and simplifying the lifecycle management of data. ADA’s pre-built connectors allow you to ingest data from diverse data sources. Software teams with basic knowledge of AWS products and services will be able to set up an operational data analytics platform in a few hours and provide secure access to the data. The data can then be easily and quickly queried using an intuitive and standalone web user interface.
Try out ADA today to easily manage and gain insights from data.
Despre autori
 Aparajithan Vaidyanathan este arhitect principal de soluții pentru întreprinderi la AWS. El sprijină clienții întreprinderi care migrează și își modernizează sarcinile de lucru pe cloud AWS. Este un arhitect cloud cu peste 23 de ani de experiență în proiectarea și dezvoltarea de sisteme software pentru întreprinderi, la scară largă și distribuite. El este specializat în Machine Learning și Data Analytics, cu accent pe domeniul Data și Feature Engineering. Este un aspirant la maraton, iar hobby-urile sale includ drumeții, plimbări cu bicicleta și petrecerea timpului cu soția și cei doi băieți.
Aparajithan Vaidyanathan este arhitect principal de soluții pentru întreprinderi la AWS. El sprijină clienții întreprinderi care migrează și își modernizează sarcinile de lucru pe cloud AWS. Este un arhitect cloud cu peste 23 de ani de experiență în proiectarea și dezvoltarea de sisteme software pentru întreprinderi, la scară largă și distribuite. El este specializat în Machine Learning și Data Analytics, cu accent pe domeniul Data și Feature Engineering. Este un aspirant la maraton, iar hobby-urile sale includ drumeții, plimbări cu bicicleta și petrecerea timpului cu soția și cei doi băieți.
 Rashim Rahman is a Software Developer based out of Sydney, Australia with 10+ years of experience in software development and architecture. He works primarily on building large scale open-source AWS solutions for common customer use cases and business problems. In his spare time, he enjoys sports and spending time with friends and family.
Rashim Rahman is a Software Developer based out of Sydney, Australia with 10+ years of experience in software development and architecture. He works primarily on building large scale open-source AWS solutions for common customer use cases and business problems. In his spare time, he enjoys sports and spending time with friends and family.
 Hafiz Saadullah is a Principal Technical Product Manager at Amazon Web Services. Hafiz focuses on AWS Solutions, designed to help customers by addressing common business problems and use cases.
Hafiz Saadullah is a Principal Technical Product Manager at Amazon Web Services. Hafiz focuses on AWS Solutions, designed to help customers by addressing common business problems and use cases.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. Automobile/VE-uri, carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- ChartPrime. Crește-ți jocul de tranzacționare cu ChartPrime. Accesați Aici.
- BlockOffsets. Modernizarea proprietății de compensare a mediului. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- :are
- :este
- :nu
- :Unde
- $UP
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- capacitate
- Capabil
- Despre Noi
- acces
- accesate
- accesibil
- Cont
- peste
- acțiuni
- ADA
- adăuga
- plus
- Suplimentar
- adresare
- admin
- După
- împotriva
- TOATE
- permite
- permite
- de-a lungul
- de asemenea
- alternativă
- Amazon
- Amazon Web Services
- printre
- an
- analiză
- analiști
- Google Analytics
- analiza
- și
- O alta
- Orice
- Apache
- api
- API-uri
- aplicație
- aplicatii
- aplicat
- Aplică
- Aplicarea
- arhitectură
- SUNT
- AS
- aspirant
- At
- atribute
- Australia
- Autentificare
- autorizat
- Automata
- automate
- în mod automat
- disponibil
- AWS
- Formarea AWS Cloud
- înapoi
- Backend
- bar
- bazat
- de bază
- BE
- deoarece
- fost
- înainte
- bespoke
- între
- atât
- Cutie
- construi
- Clădire
- construit-in
- afaceri
- business intelligence
- dar
- by
- apel
- CAN
- capacitate
- caz
- cazuri
- catalog
- CD
- Schimbare
- Diagramă
- Grafice
- Alege
- alegere
- client
- Cloud
- cod
- Coduri
- colectare
- Coloană
- Coloane
- Comun
- Completă
- componente
- Configuraţie
- configurat
- Conectați
- legat
- conexiune
- Connects
- Lua în considerare
- consistent
- Consoleze
- conține
- continua
- corelat
- Corelație
- Corespunzător
- corespunde
- A costat
- crea
- a creat
- creează
- Crearea
- scrisori de acreditare
- Curent
- personalizat
- client
- clienţii care
- tablou de bord
- de date
- Analiza datelor
- de prelucrare a datelor
- Baza de date
- baze de date
- seturi de date
- Mod implicit
- Cerere
- Demo
- demonstra
- demonstrat
- În funcție
- implementa
- dislocate
- desfășurarea
- implementează
- descriere
- proiectat
- proiect
- desktop
- detaliat
- detalii
- Dezvoltator
- în curs de dezvoltare
- Dezvoltare
- diagnostic
- diferit
- direct
- invalid
- descoperire
- Afişa
- distribuite
- diferit
- Nu
- domeniu
- domenii
- Dont
- scăzut
- în timpul
- fiecare
- Mai devreme
- cu ușurință
- editare
- oricare
- activat
- permite
- Punct final
- Obiective
- Inginerie
- asigura
- Intrați
- Afacere
- clienții întreprinderii
- Soluții pentru întreprinderi
- eroare
- Erori
- stabili
- stabilit
- Eter (ETH)
- exemplu
- existent
- experienţă
- Explica
- explicație
- extrage
- extrageți datele
- familiar
- familie
- Caracteristică
- puțini
- camp
- Domenii
- Figura
- Fișier
- Fişiere
- final
- finanţa
- First
- flexibil
- Concentra
- se concentrează
- următor
- Pentru
- format
- patru
- Frecvență
- Prietenii lui
- din
- funcţie
- Câştig
- genera
- generată
- obține
- obtinerea
- guvernare
- grup
- Grupului
- Avea
- având în
- he
- ajutor
- Evidențiat
- drumeții
- lui
- istoric
- hobby-uri
- găzduit
- ORE
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- IAM
- identic
- identifica
- Identitate
- if
- import
- in
- include
- include
- Inclusiv
- informații
- Infrastructură
- inițială
- perspective
- instala
- instalare
- instrucțiuni
- integrate
- integrare
- Inteligență
- interactiv
- interesat
- interfaţă
- în
- intuitiv
- invocă
- implicat
- problema
- IT
- alătura
- aderarea
- Se alătură
- jpg
- JSON
- doar
- A pastra
- Cheie
- cunoştinţe
- limbă
- mare
- pe scară largă
- Nume
- mai tarziu
- lansare
- învăţare
- Bibliotecă
- Autorizat
- ciclu de viață
- ca
- LIMITĂ
- Linie
- Listă
- trăi
- log
- logare
- Lung
- Uite
- căutare
- maşină
- masina de învățare
- face
- Efectuarea
- administra
- administrare
- manager
- multe
- Hartă
- cartografiere
- Maraton
- Marketing
- materie
- semnificativ
- mesaj
- AMF
- ar putea
- migra
- minute
- mod
- moderniza
- mai mult
- cele mai multe
- Mai ales
- Mozilla
- autentificare multi-factor
- MySQL
- nume
- Numit
- nume
- nativ
- Navigaţi
- navigând
- Navigare
- Nevoie
- necesar
- nevoilor
- Nou
- recent
- următor
- număr
- of
- promoții
- Offline
- Vechi
- on
- La cerere
- ONE
- on-line
- afară
- deschide
- open-source
- operațional
- Opțiune
- or
- comandă
- Altele
- Altele
- afară
- producție
- Prezentare generală
- pagină
- pâine
- Parolă
- cale
- Model
- efectua
- permisiuni
- Personal
- telefon
- PII
- conducte
- Loc
- Simplu
- plan
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- Politicile
- Portal
- Post
- postgresql
- alimentat
- Pregăti
- Se pregătește
- premise
- prezenta
- cadouri
- Anunţ
- precedent
- în primul rând
- Principal
- anterior
- probleme
- continua
- proces
- prelucrate
- procese
- prelucrare
- Produs
- Produs
- manager de produs
- Produse
- Produse si Servicii
- Programe
- proiect
- furniza
- prevăzut
- furnizorul
- furnizează
- scop
- scopuri
- Piton
- interogări
- întrebare
- repede
- gamă
- Citeste
- gata
- a primi
- înregistrări
- menționat
- regiune
- relaţie
- scoate
- repeta
- Rapoarte
- solicita
- necesar
- Resurse
- respectiv
- sensibil
- REZULTATE
- reține
- revizuiască
- călărie
- rolurile
- rădăcină
- Regula
- Alerga
- alergător
- funcţionare
- de vânzări
- acelaşi
- Economisiți
- Scară
- scenarii
- programată
- domeniu
- Caută
- Al doilea
- Secțiune
- sigur
- securitate
- vedea
- selectate
- selecţie
- trimite
- trimis
- distinct
- servi
- serverless
- serviciu
- Servicii
- set
- instalare
- Distribuie
- comun
- Pantaloni scurți
- indicat
- Emisiuni
- simplu
- simplificată
- simplificarea
- Mărimea
- aptitudini
- So
- Software
- de dezvoltare de software
- soluţie
- soluţii
- Sursă
- Surse
- specialist
- specializată
- specific
- specificată
- Cheltuire
- Sportul
- SQL
- stivui
- standalone
- standard
- Începe
- începe
- Stare
- Pas
- paşi
- depozitare
- stocate
- Şir
- structurat
- de succes
- Reușit
- astfel de
- Sprijină
- sigur
- sydney
- sisteme
- tabel
- Tablou
- Lua
- ia
- echipă
- echipe
- Tehnic
- abilitati tehnice
- Terminal
- acea
- Sursa
- lor
- apoi
- Acolo.
- Acestea
- terț
- acest
- trei
- Prin
- timp
- la
- astăzi
- Unelte
- top
- Top 10
- Total
- Transforma
- Transformare
- transformări
- transformat
- transformare
- transformatele
- a declanșat
- Două
- tip
- Tipuri
- în
- care stau la baza
- înţelege
- actualizat
- actualizări
- pe
- URI
- us
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- User Interface
- utilizatorii
- folosind
- Valori
- variabil
- varietate
- versiune
- de
- Vizualizare
- vrea
- Cale..
- we
- web
- servicii web
- BINE
- cand
- care
- în timp ce
- larg
- Gamă largă
- soţie
- voi
- cu
- în
- fără
- Apartamente
- flux de lucru
- fabrică
- ar
- scrie
- ani
- tu
- Ta
- zephyrnet