Organizațiile din toate industriile au cerințe complexe de procesare a datelor pentru cazurile lor de utilizare analitică în diferite sisteme de analiză, cum ar fi lacuri de date pe AWS, depozite de date (Amazon RedShift), căutare (Serviciul Amazon OpenSearch), NoSQL (Amazon DynamoDB), învățare automată (Amazon SageMaker), și altele. Profesioniștii în analiză au sarcina de a obține valoare din datele stocate în aceste sisteme distribuite pentru a crea experiențe mai bune, sigure și optimizate din punct de vedere al costurilor pentru clienții lor. De exemplu, companiile media digitale caută să combine și să proceseze seturi de date în baze de date interne și externe pentru a construi vederi unificate ale profilurilor clienților lor, pentru a stimula idei pentru funcții inovatoare și pentru a crește implicarea platformei.
În aceste scenarii, clienții care caută o ofertă de integrare a datelor fără server folosesc AWS Adeziv ca o componentă de bază pentru prelucrarea și catalogarea datelor. AWS Glue este bine integrat cu serviciile AWS și cu produsele partenerilor și oferă opțiuni de extragere, transformare și încărcare (ETL) cu coduri reduse/fără cod pentru a permite fluxurile de lucru analitice, învățarea automată (ML) sau dezvoltarea aplicațiilor. Lucrările AWS Glue ETL pot fi o componentă dintr-o conductă mai complexă. Orchestrarea rulării și gestionarea dependențelor dintre aceste componente este o capacitate cheie într-o strategie de date. Fluxuri de lucru gestionate de Amazon pentru fluxurile de aer Apache (Amazon MWAA) orchestrează conducte de date folosind tehnologii distribuite, inclusiv resurse on-premise, servicii AWS și componente terțe.
În această postare, arătăm cum să simplificăm monitorizarea unei sarcini AWS Glue orchestrate de Airflow folosind cele mai recente caracteristici ale Amazon MWAA.
Prezentare generală a soluției
Această postare discută următoarele:
- Cum să actualizați un mediu Amazon MWAA la versiunea 2.4.3.
- Cum să orchestrați o lucrare AWS Glue dintr-un flux de aer Grafic Acyclic direcționat (DAG).
- Îmbunătățirile de observabilitate ale pachetului furnizorului Airflow Amazon în Amazon MWAA. Acum puteți consolida jurnalele de rulare ale lucrărilor AWS Glue pe consola Airflow pentru a simplifica depanarea conductelor de date. Consola Amazon MWAA devine o singură referință pentru a monitoriza și analiza rulările de joburi AWS Glue. Anterior, echipele de asistență trebuiau să acceseze Consola de administrare AWS și luați pași manuali pentru această vizibilitate. Această caracteristică este disponibilă implicit din Amazon MWAA versiunea 2.4.3.
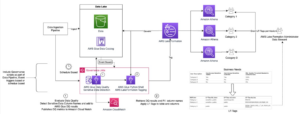
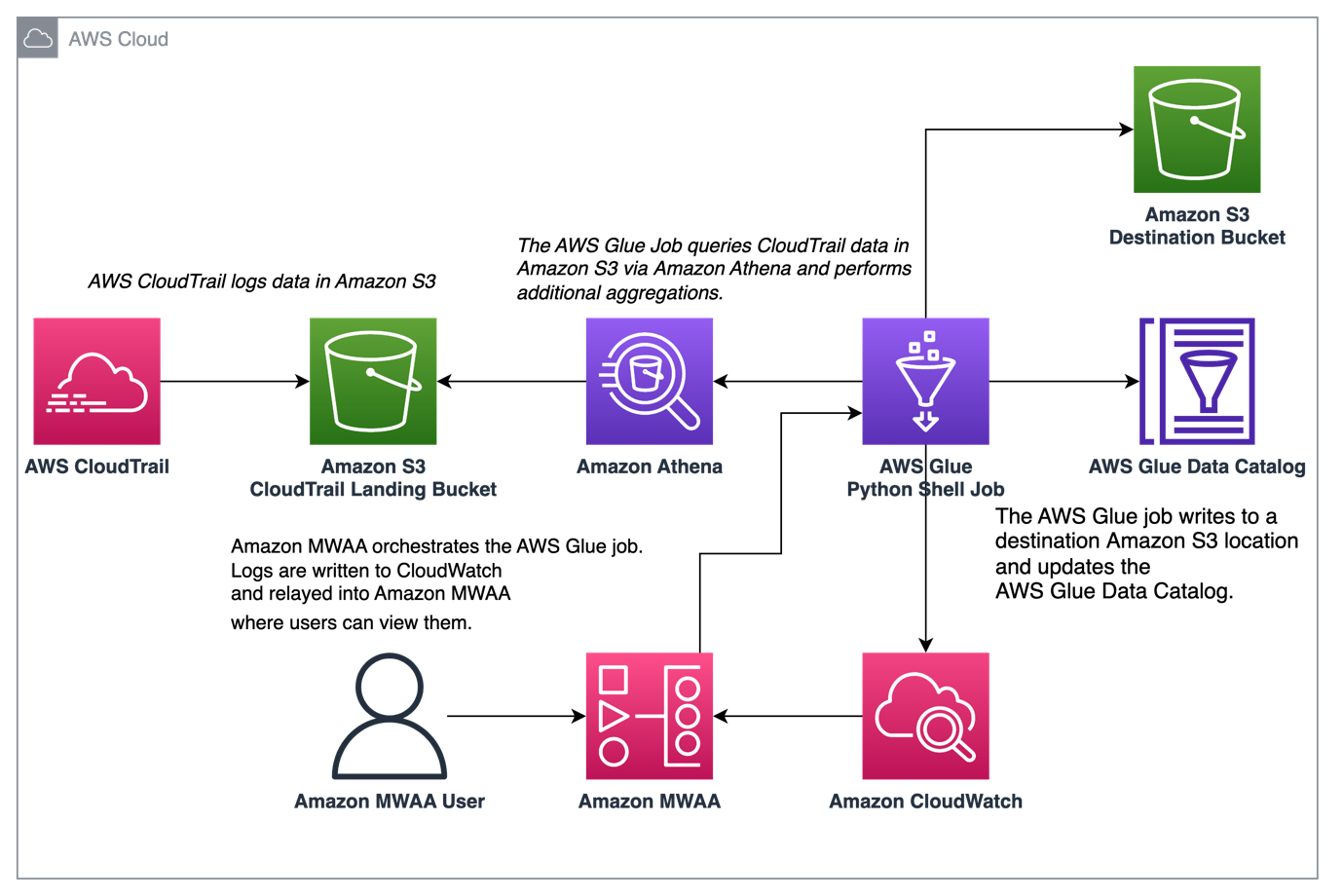
Următoarea diagramă ilustrează arhitectura soluției noastre.
Cerințe preliminare
Aveți nevoie de următoarele condiții preliminare:
Configurați mediul Amazon MWAA
Pentru instrucțiuni despre crearea mediului, consultați Creați un mediu Amazon MWAA. Pentru utilizatorii existenți, vă recomandăm să faceți upgrade la versiunea 2.4.3 pentru a profita de îmbunătățirile de observabilitate prezentate în această postare.
Pașii pentru actualizarea Amazon MWAA la versiunea 2.4.3 diferă în funcție de faptul că versiunea curentă este 1.10.12 sau 2.2.2. Discutăm ambele opțiuni în această postare.
Cerințe preliminare pentru configurarea unui mediu Amazon MWAA
Trebuie să îndepliniți următoarele cerințe preliminare:
Actualizați de la versiunea 1.10.12 la 2.4.3
Dacă utilizați versiunea Amazon MWAA 1.10.12, a se referi la Migrarea la un nou mediu Amazon MWAA pentru a face upgrade la 2.4.3.
Faceți upgrade de la versiunea 2.0.2 sau 2.2.2 la 2.4.3
Dacă utilizați mediul Amazon MWAA versiunea 2.2.2 sau anterioară, parcurgeți următorii pași:
- Crearea unei requirements.txt pentru orice dependențe personalizate cu versiuni specifice necesare pentru DAG-urile dvs.
- Încărcați fișierul pe Amazon S3 în locația corespunzătoare unde mediul Amazon MWAA indică cerințele.txt pentru instalarea dependențelor.
- Urmați pașii din Migrarea la un nou mediu Amazon MWAA și selectați versiunea 2.4.3.
Actualizați-vă DAG-urile
Clienții care au făcut upgrade dintr-un mediu Amazon MWAA mai vechi ar putea avea nevoie să facă actualizări la DAG-urile existente. În versiunea Airflow 2.4.3, mediul Airflow va folosi în mod implicit versiunea 6.0.0 a pachetului furnizorului Amazon. Acest pachet poate include unele modificări potențial, cum ar fi modificări ale numelor operatorilor. De exemplu, cel AWSGlueJobOperator a fost depreciat și înlocuit cu GlueJobOperator. Pentru a menține compatibilitatea, actualizați DAG-urile Airflow prin înlocuirea tuturor operatorilor depreciați sau neacceptați din versiunile anterioare cu cei noi. Parcurgeți următorii pași:
- Navigheaza catre Operatorii Amazon AWS.
- Selectați versiunea corespunzătoare instalată în instanța dvs. Amazon MWAA (6.0.0. în mod implicit) pentru a găsi o listă de operatori Airflow acceptați.
- Faceți modificările necesare în codul DAG existent și încărcați fișierele modificate în locația DAG din Amazon S3.
Orchestrați lucrarea AWS Glue din Airflow
Această secțiune acoperă detaliile orchestrării unei sarcini AWS Glue în cadrul DAG-urilor Airflow. Airflow ușurează dezvoltarea conductelor de date cu dependențe între sisteme eterogene, cum ar fi procese locale, dependențe externe, alte servicii AWS și multe altele.
Orchestrați agregarea jurnalelor CloudTrail cu AWS Glue și Amazon MWAA
În acest exemplu, parcurgem un caz de utilizare al utilizării Amazon MWAA pentru a orchestra o lucrare AWS Glue Python Shell care persistă valorile agregate bazate pe jurnalele CloudTrail.
CloudTrail permite vizibilitatea apelurilor AWS API care sunt efectuate în contul dvs. AWS. Un caz de utilizare obișnuit al acestor date ar fi acela de a culege valori de utilizare privind directorii care acționează pe resursele contului dvs. pentru audit și nevoi de reglementare.
Pe măsură ce evenimentele CloudTrail sunt înregistrate, acestea sunt livrate ca fișiere JSON în Amazon S3, care nu sunt ideale pentru interogări analitice. Dorim să cumulăm aceste date și să le păstrăm ca fișiere Parquet pentru a permite performanța optimă a interogărilor. Ca pas inițial, putem folosi Athena pentru a efectua interogarea inițială a datelor înainte de a face agregări suplimentare în munca noastră AWS Glue. Pentru mai multe informații despre crearea unui tabel AWS Glue Data Catalog, consultați Crearea tabelului pentru jurnalele CloudTrail în Athena folosind proiecția partiției date. După ce am explorat datele prin Athena și am decis ce valori dorim să reținem în tabelele agregate, putem crea un job AWS Glue.
Creați un tabel CloudTrail în Athena
În primul rând, trebuie să creăm un tabel în Catalogul nostru de date care să permită interogarea datelor CloudTrail prin Athena. Următorul exemplu de interogare creează un tabel cu două partiții pe Regiune și dată (numită snapshot_date). Asigurați-vă că înlocuiți substituenții pentru compartimentul CloudTrail, ID-ul contului AWS și numele tabelului CloudTrail:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Rulați interogarea anterioară pe consola Athena și notați numele tabelului și baza de date AWS Glue Data Catalog unde a fost creat. Folosim aceste valori mai târziu în codul Airflow DAG.
Exemplu de cod de lucru AWS Glue
Următorul cod este un exemplu Lucrare AWS Glue Python Shell care face următoarele:
- Preia argumente (pe care le transmitem de la Amazon MWAA DAG) cu privire la datele din ziua de procesat
- Folosește AWS SDK pentru Pandas pentru a rula o interogare Athena pentru a face filtrarea inițială a datelor JSON CloudTrail în afara AWS Glue
- Utilizează Pandas pentru a face agregări simple pe datele filtrate
- Emite datele agregate în AWS Glue Data Catalog într-un tabel
- Utilizează înregistrarea în jurnal în timpul procesării, care va fi vizibilă în Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
Următoarele sunt câteva avantaje cheie în această lucrare AWS Glue:
- Folosim o interogare Athena pentru a ne asigura că filtrarea inițială se face în afara sarcinii noastre AWS Glue. Ca atare, un job Python Shell cu calcul minim este încă suficient pentru agregarea unui set de date CloudTrail mare.
- Asiguram opțiunea set de biblioteci de analiză este activat la crearea lucrării noastre AWS Glue pentru a utiliza biblioteca AWS SDK pentru Pandas.
Creați o lucrare AWS Glue
Parcurgeți următorii pași pentru a vă crea jobul AWS Glue:
- Copiați scriptul din secțiunea precedentă și salvați-l într-un fișier local. Pentru această postare, fișierul este numit
script.py. - Pe consola AWS Glue, alegeți Locuri de muncă ETL în panoul de navigare.
- Creați un nou loc de muncă și selectați Editor de script Python Shell.
- Selectați Încărcați și editați un script existent și încărcați fișierul pe care l-ați salvat local.
- Alege Crea.

- Pe Detaliile postului fila, introduceți un nume pentru jobul dvs. AWS Glue.
- Pentru Rolul IAM, alegeți un rol existent sau creați un rol nou care are permisiunile necesare pentru Amazon S3, AWS Glue și Athena. Rolul trebuie să interogheze tabelul CloudTrail pe care l-ați creat mai devreme și să scrie într-o locație de ieșire.
Puteți utiliza următorul exemplu de cod de politică. Înlocuiți substituenții cu compartimentul dvs. de jurnalele CloudTrail, numele tabelului de ieșire, baza de date AWS Glue de ieșire, compartimentul S3 de ieșire, numele tabelului CloudTrail, baza de date AWS Glue care conține tabelul CloudTrail și ID-ul contului dvs. AWS.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Pentru Versiunea Python, alege Python 3.9.
- Selectați Încărcați biblioteci de analiză comune.
- Pentru Unități de prelucrare a datelor, alege 1 DPU.
- Lăsați celelalte opțiuni ca implicite sau ajustați după cum este necesar.

- Alege Economisiți pentru a salva configurația jobului.
Configurați un Amazon MWAA DAG pentru a orchestra lucrarea AWS Glue
Următorul cod este pentru un DAG care poate orchestra jobul AWS Glue pe care l-am creat. Profităm de următoarele caracteristici cheie în acest DAG:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Creșteți observabilitatea joburilor AWS Glue în Amazon MWAA
Joburile AWS Glue scriu jurnalele în Amazon CloudWatch. Odată cu îmbunătățirile recente de observabilitate aduse pachetului de furnizori Amazon de la Airflow, aceste jurnale sunt acum integrate cu jurnalele de activități Airflow. Această consolidare oferă utilizatorilor Airflow vizibilitate de la capăt la capăt direct în interfața de utilizare Airflow, eliminând nevoia de a căuta în CloudWatch sau consola AWS Glue.
Pentru a utiliza această caracteristică, asigurați-vă că rolul IAM atașat mediului Amazon MWAA are următoarele permisiuni pentru a prelua și scrie jurnalele necesare:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Dacă verbose=true, jurnalele de rulare a lucrărilor AWS Glue sunt afișate în jurnalele de activități Airflow. Valoarea implicită este false. Pentru mai multe informații, consultați parametrii.
Când sunt activate, DAG-urile citesc din fluxul de jurnal CloudWatch al jobului AWS Glue și le transmit la jurnalele pasilor jobului Airflow DAG AWS Glue. Aceasta oferă informații detaliate despre rularea unei lucrări AWS Glue în timp real prin intermediul jurnalelor DAG. Rețineți că lucrările AWS Glue generează un grup de jurnal CloudWatch de ieșire și de eroare bazat pe STDOUT și, respectiv, STDERR ale jobului. Toate jurnalele din grupul de jurnal de ieșire și jurnalele de excepții sau erori din grupul de jurnal de erori sunt transmise în Amazon MWAA.
Administratorii AWS pot limita acum accesul unei echipe de asistență doar la Airflow, făcând din Amazon MWAA singurul panou de sticlă pentru orchestrarea locurilor de muncă și gestionarea sănătății locurilor de muncă. Anterior, utilizatorii trebuiau să verifice starea executării jobului AWS Glue în pașii DAG Airflow și să preia identificatorul de rulare a jobului. Apoi au trebuit să acceseze consola AWS Glue pentru a găsi istoricul rulării jobului, să caute jobul de interes folosind identificatorul și, în cele din urmă, să navigheze la jurnalele CloudWatch ale jobului pentru a depana.
Creați DAG
Pentru a crea DAG, parcurgeți următorii pași:
- Salvați codul DAG precedent într-un fișier .py local, înlocuind substituenții indicați.
Valorile pentru ID-ul contului dvs. AWS, numele jobului AWS Glue, baza de date AWS Glue cu tabelul CloudTrail și numele tabelului CloudTrail ar trebui să fie deja cunoscute. Puteți ajusta găleata S3 de ieșire, baza de date AWS Glue de ieșire și numele tabelului de ieșire după cum este necesar, dar asigurați-vă că rolul IAM al jobului AWS Glue pe care l-ați folosit mai devreme este configurat corespunzător.
- Pe consola Amazon MWAA, navigați la mediul dvs. pentru a vedea unde este stocat codul DAG.
Dosarul DAG-uri este prefixul din compartimentul S3 în care ar trebui să fie plasat fișierul DAG.
- Încărcați fișierul editat acolo.

- Deschideți consola Amazon MWAA pentru a confirma că DAG apare în tabel.

Rulați DAG
Pentru a rula DAG, parcurgeți următorii pași:
- Alegeți dintre următoarele opțiuni:
- Declanșează DAG – Acest lucru face ca datele de ieri să fie folosite ca date de prelucrat
- Trigger DAG cu config – Cu această opțiune, puteți trece o dată diferită, eventual pentru umpleri, care este recuperată folosind
dag_run.confîn codul DAG și apoi trecut în jobul AWS Glue ca parametru

Următoarea captură de ecran arată opțiunile suplimentare de configurare dacă alegeți Trigger DAG cu config.

- Monitorizați DAG-ul în timp ce rulează.
- Când DAG este complet, deschideți detaliile cursei.
În panoul din dreapta, puteți vizualiza jurnalele sau puteți alege Detalii de instanță de activitate pentru o vedere completă.

- Vizualizați jurnalele de ieșire a lucrărilor AWS Glue în Amazon MWAA fără a utiliza consola AWS Glue datorită
GlueJobOperatorsteag verborizat.

Lucrarea AWS Glue va avea rezultate scrise în tabelul de ieșire pe care l-ați specificat.
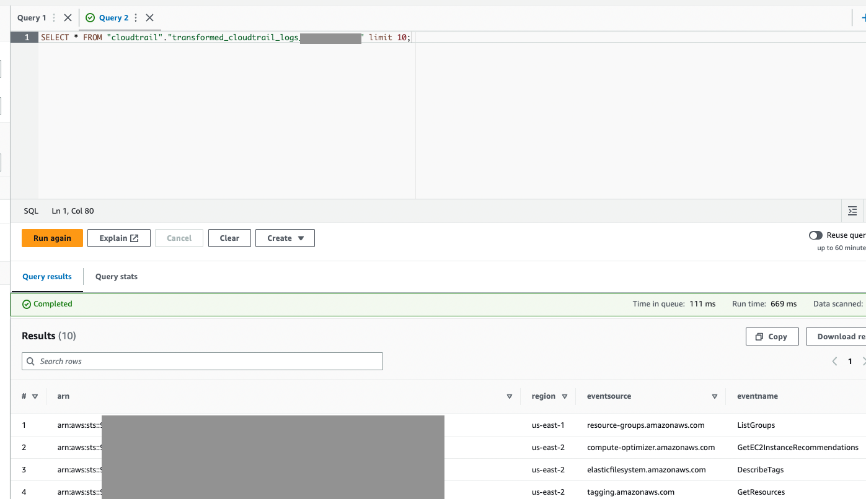
- Interogați acest tabel prin Athena pentru a confirma că a avut succes.
Rezumat
Amazon MWAA oferă acum un singur loc pentru a urmări starea lucrării AWS Glue și vă permite să utilizați consola Airflow ca un singur panou de sticlă pentru orchestrarea lucrărilor și gestionarea sănătății. În această postare, am parcurs pașii pentru a orchestra lucrările AWS Glue prin utilizarea Airflow GlueJobOperator. Cu noile îmbunătățiri de observabilitate, puteți depana fără probleme lucrările AWS Glue într-o experiență unificată. De asemenea, am demonstrat cum să actualizați mediul dvs. Amazon MWAA la o versiune compatibilă, să actualizați dependențele și să schimbați politica rolului IAM în consecință.
Pentru mai multe informații despre pașii obișnuiți de depanare, consultați Depanare: crearea și actualizarea unui mediu Amazon MWAA. Pentru detalii aprofundate despre migrarea către un mediu Amazon MWAA, consultați Actualizare de la 1.10 la 2. Pentru a afla despre modificările codului open-source pentru o observabilitate sporită a joburilor AWS Glue din pachetul Airflow Amazon furnizor, consultați retransmiteți jurnalele de la lucrările AWS Glue.
În cele din urmă, vă recomandăm să vizitați Blogul AWS Big Data pentru alte materiale despre analiză, ML și guvernanța datelor pe AWS.
Despre Autori
 Rushabh Lokhande este inginer de date și ML cu practica AWS Professional Services Analytics. El îi ajută pe clienți să implementeze soluții de big data, machine learning și analiză. În afara serviciului, îi place să petreacă timpul cu familia, lectură, alergare și golf.
Rushabh Lokhande este inginer de date și ML cu practica AWS Professional Services Analytics. El îi ajută pe clienți să implementeze soluții de big data, machine learning și analiză. În afara serviciului, îi place să petreacă timpul cu familia, lectură, alergare și golf.
 Ryan Gomes este inginer de date și ML cu practica AWS Professional Services Analytics. Este pasionat de a ajuta clienții să obțină rezultate mai bune prin soluții de analiză și învățare automată în cloud. În afara serviciului, îi place fitness, gătit și petrece timp de calitate cu prietenii și familia.
Ryan Gomes este inginer de date și ML cu practica AWS Professional Services Analytics. Este pasionat de a ajuta clienții să obțină rezultate mai bune prin soluții de analiză și învățare automată în cloud. În afara serviciului, îi place fitness, gătit și petrece timp de calitate cu prietenii și familia.
 Vishwa Gupta este arhitect senior de date cu practica AWS Professional Services Analytics. El îi ajută pe clienți să implementeze soluții de big data și de analiză. În afara serviciului, îi place să petreacă timpul cu familia, să călătorească și să încerce mâncare nouă.
Vishwa Gupta este arhitect senior de date cu practica AWS Professional Services Analytics. El îi ajută pe clienți să implementeze soluții de big data și de analiză. În afara serviciului, îi place să petreacă timpul cu familia, să călătorească și să încerce mâncare nouă.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoAiStream. Web3 Data Intelligence. Cunoștințe amplificate. Accesați Aici.
- Mintând viitorul cu Adryenn Ashley. Accesați Aici.
- Cumpărați și vindeți acțiuni în companii PRE-IPO cu PREIPO®. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :are
- :este
- :nu
- :Unde
- $UP
- 1
- 10
- 100
- 12
- 8
- a
- Despre Noi
- acces
- în consecință
- Cont
- Obține
- peste
- Acțiune
- aciclic
- Suplimentar
- Avantaj
- Avantajele
- După
- agregare
- TOATE
- permite
- permite
- deja
- de asemenea
- Amazon
- Amazon Web Services
- an
- Analitic
- Google Analytics
- analiza
- și
- Orice
- Apache
- api
- aplicație
- Dezvoltare de Aplicații
- adecvat
- arhitectură
- SUNT
- argument
- argumente
- AS
- At
- atribute
- audit
- disponibil
- AWS
- AWS Adeziv
- Servicii profesionale AWS
- bazat
- BE
- devine
- fost
- înainte
- fiind
- Mai bine
- între
- Mare
- Datele mari
- atât
- Breaking
- construi
- dar
- by
- denumit
- apeluri
- CAN
- caz
- cazuri
- catalog
- cauze
- Schimbare
- Modificări
- verifica
- Alege
- Cloud
- cod
- COM
- combina
- comentariu
- Comun
- Companii
- compatibilitate
- compatibil
- Completă
- complex
- component
- componente
- Calcula
- Configuraţie
- Confirma
- Consoleze
- consolida
- consolidare
- gătit
- Nucleu
- acoperă
- crea
- a creat
- creează
- Crearea
- Curent
- personalizat
- client
- clienţii care
- DAG
- de date
- integrarea datelor
- de prelucrare a datelor
- strategie de date
- depozite de date
- Baza de date
- baze de date
- seturi de date
- Data
- Date
- datetime
- Zi
- hotărât
- Mod implicit
- livrate
- demonstrat
- În funcție
- depreciată
- detaliat
- detalii
- Dezvoltare
- diferi
- diferit
- digital
- Suport digital
- direct
- discuta
- distribuite
- sisteme distribuite
- do
- face
- face
- făcut
- în timpul
- e
- Mai devreme
- faciliteaza
- efect
- eliminarea
- altfel
- permite
- activat
- permite
- un capăt la altul
- angajament
- inginer
- îmbunătățiri
- asigura
- Intrați
- Mediu inconjurator
- eroare
- Eter (ETH)
- evenimente
- exemplu
- Cu excepția
- excepție
- exista
- existent
- există
- experienţă
- Experiențe
- explorat
- expresie
- extern
- extrage
- A eșuat
- fals
- familie
- Caracteristică
- Recomandate
- DESCRIERE
- Fișier
- Fişiere
- filtrare
- În cele din urmă
- Găsi
- fitness
- următor
- alimente
- Pentru
- format
- Prietenii lui
- din
- Complet
- aduna
- genera
- de sticlă
- Go
- golf
- guvernare
- grup
- Hadoop
- Avea
- he
- Sănătate
- ajutor
- ajută
- istorie
- Stup
- Cum
- Cum Pentru a
- HTML
- http
- HTTPS
- IAM
- ID
- ideal
- idei
- identificator
- if
- ilustrează
- punerea în aplicare a
- import
- in
- în profunzime
- include
- Inclusiv
- Crește
- a crescut
- indicată
- industrii
- info
- informații
- inițială
- inovatoare
- perspective
- Instalarea
- instanță
- instrucțiuni
- integrate
- integrare
- interes
- intern
- în
- IT
- Loc de munca
- Locuri de munca
- jpg
- JSON
- Cheie
- cunoscut
- mare
- mai tarziu
- Ultimele
- AFLAȚI
- învăţare
- Bibliotecă
- LIMITĂ
- Listă
- încărca
- local
- la nivel local
- locaţie
- log
- autentificat
- logare
- cautati
- maşină
- masina de învățare
- făcut
- menține
- face
- Efectuarea
- gestionate
- administrare
- de conducere
- manual
- material
- Mai..
- Mass-media
- Întâlni
- mesaj
- Metrici
- Migrarea
- minim
- ML
- modificată
- modul
- monitor
- Monitorizarea
- mai mult
- trebuie sa
- nume
- nume
- Navigaţi
- Navigare
- necesar
- Nevoie
- necesar
- nevoilor
- Nou
- nimic
- acum
- of
- oferind
- on
- ONE
- cele
- afară
- deschide
- open-source
- cod open-source
- operator
- Operatorii
- optimă
- Opțiune
- Opţiuni
- or
- orchestrat
- orchestrație
- Altele
- al nostru
- rezultate
- producție
- exterior
- pachet
- panda
- pâine
- parametrii
- partener
- trece
- Trecut
- pasionat
- performanță
- permisiuni
- persistă
- conducte
- Loc
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- puncte
- Politica
- Post
- potenţial
- practică
- premise
- precedent
- în prealabil
- proces
- procese
- prelucrare
- Produse
- profesional
- profesioniști
- Profiluri
- Proiectare
- furnizorul
- furnizori
- furnizează
- Piton
- calitate
- interogări
- ridica
- gamă
- Citeste
- Citind
- real
- în timp real
- recent
- recomanda
- regiune
- autoritățile de reglementare
- Releu
- înlocui
- înlocuiește
- necesar
- Cerinţe
- resursă
- Resurse
- respectiv
- răspuns
- REZULTATE
- reține
- dreapta
- Rol
- RÂND
- Alerga
- funcţionare
- s
- Economisiți
- scenarii
- sdk
- perfect
- Caută
- Secțiune
- sigur
- vedea
- Căuta
- senior
- serverless
- Servicii
- instalare
- configurarea
- Coajă
- să
- Arăta
- Emisiuni
- simplu
- simplifica
- întrucât
- singur
- Instantaneu
- soluţie
- soluţii
- unele
- specific
- specificată
- Cheltuire
- Declarație
- Stare
- Pas
- paşi
- Încă
- depozitare
- stocate
- Strategie
- curent
- Şir
- de succes
- astfel de
- suficient
- a sustine
- Suportat
- sisteme
- tabel
- Lua
- luare
- Sarcină
- echipe
- Tehnologii
- șablon
- Mulțumiri
- acea
- lor
- Lor
- apoi
- Acolo.
- Acestea
- ei
- terț
- acest
- Prin
- timp
- la
- urmări
- Transforma
- Traveling
- adevărat
- încerca
- marţi
- transformat
- Două
- tip
- ui
- unificat
- unitate
- Actualizează
- actualizări
- actualizarea
- upgrade-ul
- modernizate
- Se încarcă
- Folosire
- utilizare
- carcasa de utilizare
- utilizat
- utilizatorii
- folosind
- valoare
- Valori
- versiune
- de
- Vizualizare
- vizualizari
- vizibilitate
- vizibil
- umblat
- vrea
- a fost
- we
- web
- servicii web
- BINE
- Ce
- cand
- dacă
- care
- OMS
- voi
- cu
- în
- fără
- Apartamente
- fluxuri de lucru
- ar
- scrie
- scris
- tu
- Ta
- zephyrnet