Datele geospațiale sunt date despre anumite locații de pe suprafața pământului. Poate reprezenta o zonă geografică în ansamblu sau poate reprezenta un eveniment asociat unei zone geografice. Analiza datelor geospațiale este căutată în câteva industrii. Implica înțelegerea unde există datele dintr-o perspectivă spațială și de ce există acolo.
Există două tipuri de date geospațiale: date vectoriale și date raster. Datele raster sunt o matrice de celule reprezentate ca o grilă, reprezentând în mare parte fotografii și imagini din satelit. În această postare, ne concentrăm pe datele vectoriale, care sunt reprezentate ca coordonate geografice de latitudine și longitudine, precum și linii și poligoane (zone) care le conectează sau le cuprind. Datele vectoriale au o multitudine de cazuri de utilizare pentru a obține informații despre mobilitate. Datele mobile ale utilizatorilor sunt una dintre aceste componente și sunt derivate în principal din poziția geografică a dispozitivelor mobile care folosesc GPS sau editori de aplicații care folosesc SDK-uri sau integrări similare. În scopul acestei postări, ne referim la aceste date ca date de mobilitate.
Aceasta este o serie în două părți. În această primă postare, prezentăm datele de mobilitate, sursele acestora și o schemă tipică a acestor date. Apoi, discutăm despre diferitele cazuri de utilizare și explorăm modul în care puteți utiliza serviciile AWS pentru a curăța datele, modul în care învățarea automată (ML) poate ajuta în acest efort și cum puteți utiliza datele în mod etic pentru a genera imagini și perspective. Al doilea post va fi de natură mai tehnică și va acoperi acești pași în detaliu alături de exemplu de cod. Această postare nu are un set de date eșantion sau un cod exemplu, mai degrabă acoperă modul de utilizare a datelor după ce sunt achiziționate de la un agregator de date.
Poți să folosești Capacitățile geospațiale Amazon SageMaker pentru a suprapune datele de mobilitate pe o hartă de bază și pentru a oferi vizualizare stratificată pentru a facilita colaborarea. Vizualizatorul interactiv alimentat de GPU și notebook-urile Python oferă o modalitate simplă de a explora milioane de puncte de date într-o singură fereastră și de a partaja informații și rezultate.
Surse și schemă
Există puține surse de date despre mobilitate. În afară de ping-urile GPS și editorii de aplicații, pentru a spori setul de date sunt folosite și alte surse, cum ar fi punctele de acces Wi-Fi, datele privind fluxul de sume licitate obținute prin difuzarea de anunțuri pe dispozitive mobile și anumite transmițătoare hardware plasate de companii (de exemplu, în magazinele fizice). ). Este adesea dificil pentru companii să colecteze singure aceste date, așa că le pot cumpăra de la agregatorii de date. Agregatorii de date colectează date de mobilitate din diverse surse, le curăță, adaugă zgomot și fac datele disponibile zilnic pentru anumite regiuni geografice. Datorită naturii datelor în sine și deoarece este dificil de obținut, acuratețea și calitatea acestor date pot varia considerabil, iar companiile trebuie să evalueze și să verifice acest lucru utilizând valori precum utilizatorii activi zilnici, numărul total de ping-uri zilnice, și ping-uri medii zilnice pe dispozitiv. Următorul tabel arată cum poate arăta o schemă tipică a unui flux de date zilnic trimis de agregatorii de date.
| Atribut | Descriere |
| Id sau menajeră | ID de publicitate mobilă (MAID) al dispozitivului (hashing) |
| lat | Latitudinea dispozitivului |
| lng | Longitudinea dispozitivului |
| geohash | Locația geohash a dispozitivului |
| tip de dispozitiv | Sistemul de operare al dispozitivului = IDFA sau GAID |
| acuratețe_orizontală | Precizia coordonatelor GPS orizontale (în metri) |
| timestamp-ul | Marca temporală a evenimentului |
| ip | Adresa IP |
| vechi | Altitudinea dispozitivului (în metri) |
| viteză | Viteza dispozitivului (în metri/secundă) |
| ţară | Cod ISO din două cifre pentru țara de origine |
| de stat | Codurile reprezentând statul |
| oraș | Codurile reprezentând orașul |
| cod poștal | Codul poștal unde este văzut ID-ul dispozitivului |
| purtător | Purtatorul dispozitivului |
| device_manufacturer | Producatorul aparatului |
Cazuri de utilizare
Datele de mobilitate au aplicații pe scară largă în diverse industrii. Următoarele sunt câteva dintre cele mai frecvente cazuri de utilizare:
- Măsuri de densitate – Analiza traficului pietonal poate fi combinată cu densitatea populației pentru a observa activități și vizite la punctele de interes (POI). Aceste valori prezintă o imagine a câte dispozitive sau utilizatori se opresc în mod activ și se interacționează cu o afacere, care poate fi folosită în continuare pentru selectarea site-ului sau chiar pentru analizarea tiparelor de mișcare în jurul unui eveniment (de exemplu, persoane care călătoresc pentru o zi de joc). Pentru a obține astfel de informații, datele brute primite trec printr-un proces de extragere, transformare și încărcare (ETL) pentru a identifica activitățile sau angajamentele din fluxul continuu de ping-uri privind locația dispozitivului. Putem analiza activitățile prin identificarea opririlor efectuate de utilizator sau de dispozitivul mobil prin gruparea ping-urilor folosind modele ML în Amazon SageMaker.
- Călătorii și traiectorii – Fluxul zilnic de locație al unui dispozitiv poate fi exprimat ca o colecție de activități (opriri) și călătorii (mișcare). O pereche de activități poate reprezenta o călătorie între ele, iar urmărirea călătoriei de către dispozitivul în mișcare în spațiul geografic poate duce la cartografierea traiectoriei reale. Modelele de traiectorie ale mișcărilor utilizatorilor pot duce la perspective interesante, cum ar fi modelele de trafic, consumul de combustibil, planificarea orașului și multe altele. De asemenea, poate furniza date pentru a analiza traseul parcurs de la punctele de publicitate, cum ar fi un panou publicitar, pentru a identifica cele mai eficiente rute de livrare pentru a optimiza operațiunile lanțului de aprovizionare sau pentru a analiza rutele de evacuare în caz de dezastre naturale (de exemplu, evacuarea uraganelor).
- Analiza bazinului hidrografic - A arie de captare se referă la locurile din care o anumită zonă își atrage vizitatorii, care pot fi clienți sau potențiali clienți. Companiile de vânzare cu amănuntul pot folosi aceste informații pentru a determina locația optimă pentru a deschide un nou magazin sau pentru a determina dacă două locații de magazine sunt prea aproape una de cealaltă, cu zone de captare suprapuse și își împiedică activitatea reciprocă. De asemenea, ei pot afla de unde provin clienții reali, pot identifica clienții potențiali care trec prin zonă, călătoresc la serviciu sau acasă, pot analiza valori similare privind vizitele pentru concurenți și multe altele. Companiile de Marketing Tech (MarTech) și Advertisement Tech (AdTech) pot folosi, de asemenea, această analiză pentru a optimiza campaniile de marketing prin identificarea publicului apropiat de magazinul unei mărci sau pentru a clasifica magazinele după performanță pentru publicitatea în afara casei.
Există câteva alte cazuri de utilizare, inclusiv generarea de informații despre locație pentru proprietăți imobiliare comerciale, creșterea datelor de imagini din satelit cu numere de trafic, identificarea centrelor de livrare pentru restaurante, determinarea probabilității de evacuare a cartierului, descoperirea tiparelor de mișcare a oamenilor în timpul unei pandemii și multe altele.
Provocări și utilizare etică
Utilizarea etică a datelor de mobilitate poate duce la multe perspective interesante care pot ajuta organizațiile să-și îmbunătățească operațiunile, să efectueze un marketing eficient sau chiar să obțină un avantaj competitiv. Pentru a utiliza aceste date în mod etic, trebuie urmați câțiva pași.
Începe cu colectarea datelor în sine. Deși majoritatea datelor de mobilitate rămân fără informații de identificare personală (PII), cum ar fi numele și adresa, colectorii și agregatorii de date trebuie să aibă consimțământul utilizatorului pentru a colecta, utiliza, stoca și partaja datele lor. Legile privind confidențialitatea datelor, cum ar fi GDPR și CCPA, trebuie respectate, deoarece permit utilizatorilor să determine modul în care companiile își pot folosi datele. Acest prim pas este o mișcare substanțială către utilizarea etică și responsabilă a datelor de mobilitate, dar se poate face mai mult.
Fiecărui dispozitiv i se atribuie un ID de publicitate mobilă (MAID), care este utilizat pentru ancorarea ping-urilor individuale. Acest lucru poate fi înfundat și mai mult prin utilizarea Amazon Macie, Amazon S3 Object Lambda, Amazon Comprehend, sau chiar AWS Glue Studio Detectează transformarea PII. Pentru mai multe informații, consultați Tehnici obișnuite pentru detectarea datelor PHI și PII folosind AWS Services.
În afară de PII, ar trebui luate în considerare mascarea locației de acasă a utilizatorului, precum și a altor locații sensibile, cum ar fi bazele militare sau lăcașurile de cult.
Pasul final pentru utilizarea etică este de a deriva și exporta numai valori agregate din Amazon SageMaker. Aceasta înseamnă obținerea unor valori precum numărul mediu sau numărul total de vizitatori, spre deosebire de tiparele individuale de călătorie; obținerea de tendințe zilnice, săptămânale, lunare sau anuale; sau indexarea modelelor de mobilitate asupra datelor disponibile public, cum ar fi datele recensământului.
Prezentare generală a soluțiilor
După cum am menționat mai devreme, serviciile AWS pe care le puteți utiliza pentru analiza datelor de mobilitate sunt Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend și Amazon SageMaker. Capacitățile geospațiale Amazon SageMaker le facilitează oamenilor de știință de date și inginerilor ML să construiască, să antreneze și să implementeze modele folosind date geospațiale. Puteți transforma sau îmbogăți eficient seturi de date geospațiale la scară largă, puteți accelera construirea modelelor cu modele ML pregătite în prealabil și puteți explora predicțiile modelului și datele geospațiale pe o hartă interactivă folosind grafică accelerată 3D și instrumente de vizualizare încorporate.
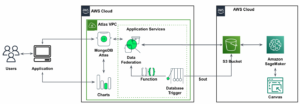
Următoarea arhitectură de referință descrie un flux de lucru care utilizează ML cu date geospațiale.
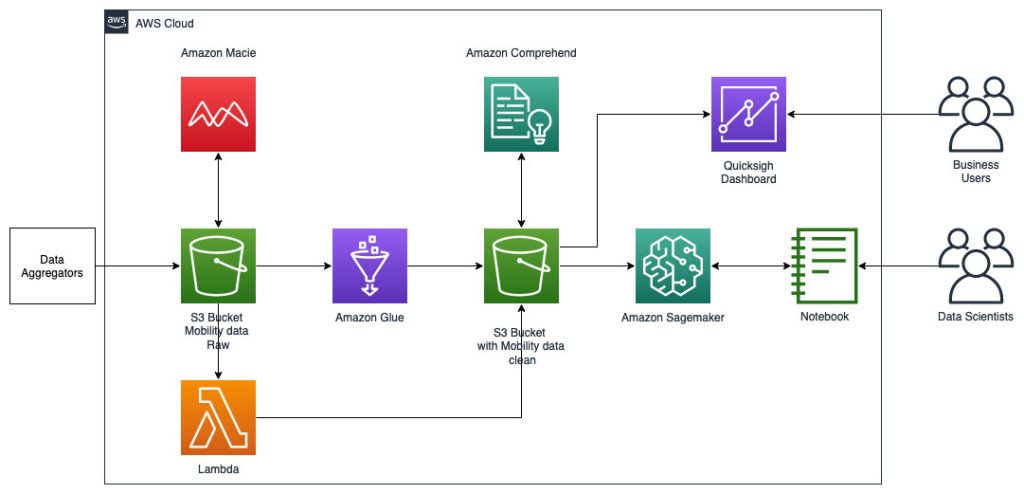
În acest flux de lucru, datele brute sunt agregate din diverse surse de date și stocate într-un Serviciul Amazon de stocare simplă (S3) găleată. Amazon Macie este folosit pe această găleată S3 pentru a identifica și redacta și PII. AWS Glue este apoi folosit pentru a curăța și transforma datele brute în formatul necesar, apoi datele modificate și curățate sunt stocate într-o găleată S3 separată. Pentru acele transformări de date care nu sunt posibile prin AWS Glue, utilizați AWS Lambdas pentru a modifica și curăța datele brute. Când datele sunt curățate, puteți utiliza Amazon SageMaker pentru a construi, antrena și implementa modele ML pe datele geospațiale pregătite. De asemenea, puteți utiliza joburi de procesare geospațială caracteristică a capabilităților geospațiale Amazon SageMaker pentru a preprocesa datele, de exemplu, folosind o funcție Python și instrucțiuni SQL pentru a identifica activitățile din datele brute de mobilitate. Oamenii de știință de date pot realiza acest proces conectându-se prin intermediul notebook-urilor Amazon SageMaker. De asemenea, puteți utiliza Amazon QuickSight pentru a vizualiza rezultatele afacerii și alte valori importante din date.
Capacitățile geospațiale Amazon SageMaker și joburile de procesare geospațială
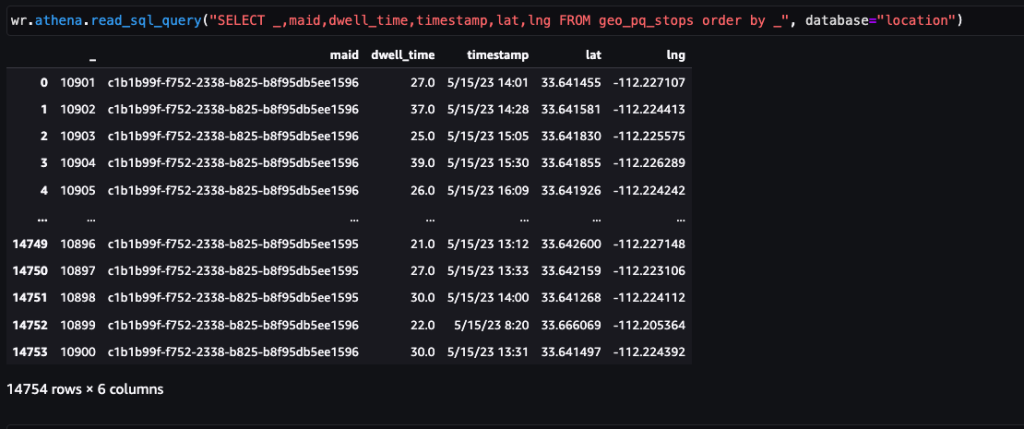
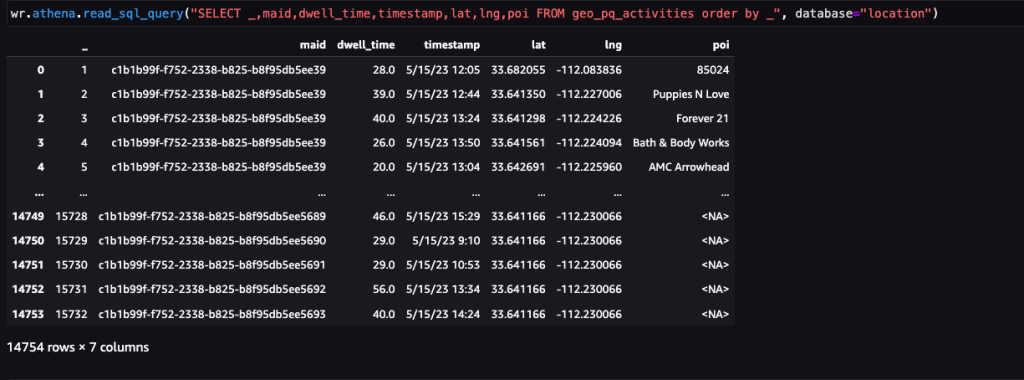
După ce datele sunt obținute și introduse în Amazon S3 cu un flux zilnic și curățate pentru orice date sensibile, acestea pot fi importate în Amazon SageMaker folosind un Amazon SageMaker Studio caiet cu o imagine geospațială. Următoarea captură de ecran arată un eșantion de ping-uri zilnice de dispozitiv încărcate în Amazon S3 ca fișier CSV și apoi încărcate într-un cadru de date panda. Notebook-ul Amazon SageMaker Studio cu imagine geospațială vine preîncărcat cu biblioteci geospațiale precum GDAL, GeoPandas, Fiona și Shapely și simplifică procesarea și analiza acestor date.
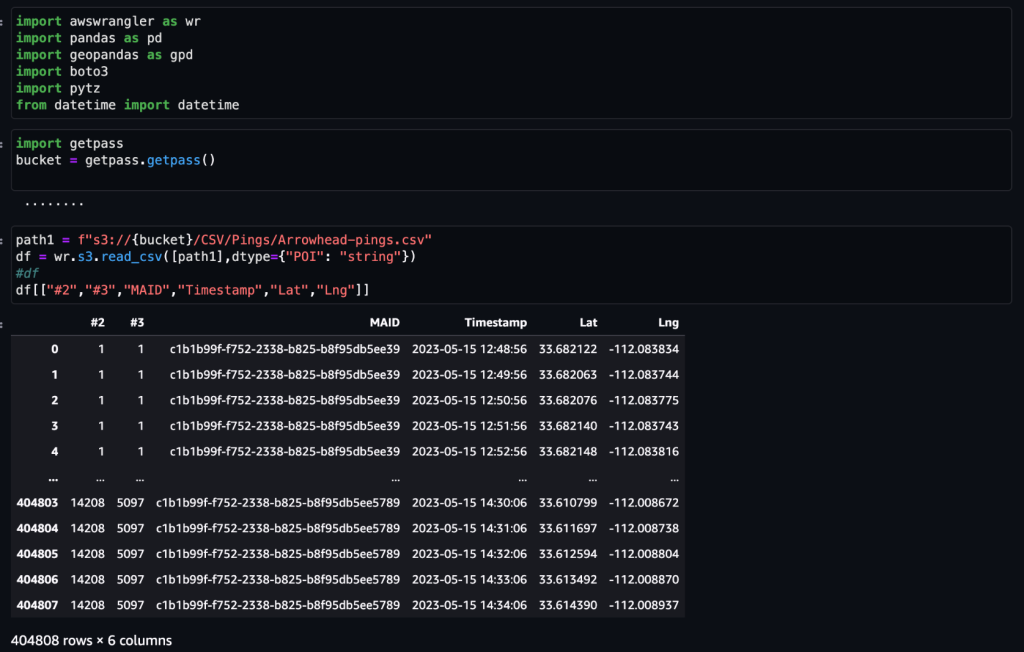
Acest exemplu de set de date conține aproximativ 400,000 de ping-uri zilnice de la 5,000 de dispozitive din 14,000 de locuri unice înregistrate de la utilizatorii care vizitează Arrowhead Mall, un complex de mall popular din Phoenix, Arizona, pe 15 mai 2023. Captura de ecran anterioară arată un subset de coloane din schema de date. The MAID coloana reprezintă ID-ul dispozitivului, iar fiecare MAID generează ping-uri în fiecare minut care transmit latitudinea și longitudinea dispozitivului, înregistrate în fișierul eșantion ca Lat și Lng coloane.
Următoarele sunt capturi de ecran din instrumentul de vizualizare a hărților al capabilităților geospațiale Amazon SageMaker, oferit de Foursquare Studio, care ilustrează aspectul ping-urilor de pe dispozitivele care vizitează mall-ul între 7:00 AM și 6:00 PM.
Următoarea captură de ecran arată ping-uri din mall și din zonele învecinate.

Următoarele arată ping-uri din interiorul diferitelor magazine din mall.
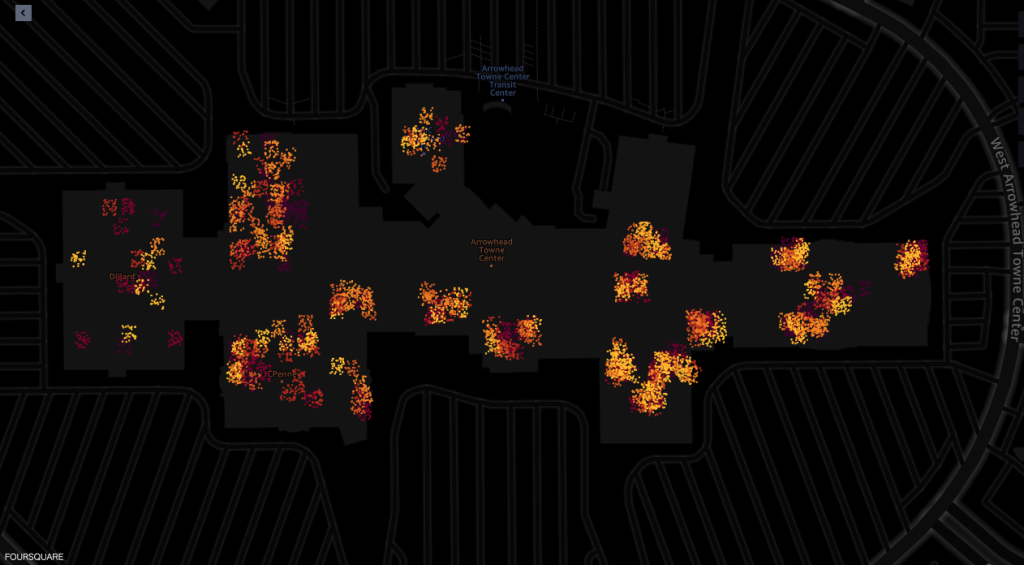
Fiecare punct din capturi de ecran descrie un ping de la un dispozitiv dat la un moment dat. Un grup de ping-uri reprezintă locuri populare în care dispozitivele s-au adunat sau s-au oprit, cum ar fi magazinele sau restaurantele.
Ca parte a ETL inițial, aceste date brute pot fi încărcate pe tabele folosind AWS Glue. Puteți crea un crawler AWS Glue pentru a identifica schema datelor și a tabelelor de formulare, indicând locația datelor brute din Amazon S3 ca sursă de date.

După cum sa menționat mai sus, datele brute (pingurile zilnice ale dispozitivului), chiar și după ETL inițial, vor reprezenta un flux continuu de ping-uri GPS care indică locațiile dispozitivului. Pentru a extrage informații utile din aceste date, trebuie să identificăm opriri și călătorii (traiectorii). Acest lucru poate fi realizat folosind joburi de procesare geospațială caracteristică a capabilităților geospațiale SageMaker. Procesare Amazon SageMaker folosește o experiență simplificată și gestionată pe SageMaker pentru a rula sarcini de lucru de procesare a datelor cu containerul geospațial special creat. Infrastructura de bază pentru o lucrare de procesare SageMaker este gestionată integral de SageMaker. Această caracteristică permite rularea codului personalizat pe datele geospațiale stocate pe Amazon S3 prin rularea unui container ML geospatial pe o lucrare de procesare SageMaker. Puteți rula operațiuni personalizate pe date geospațiale deschise sau private, scriind cod personalizat cu biblioteci open source și rulați operația la scară utilizând joburi de procesare SageMaker. Abordarea bazată pe container rezolvă nevoile legate de standardizarea mediului de dezvoltare cu biblioteci open source utilizate în mod obișnuit.
Pentru a rula astfel de sarcini de lucru la scară mare, aveți nevoie de un cluster de calcul flexibil care se poate scala de la zeci de instanțe pentru a procesa un bloc până la mii de instanțe pentru procesarea la scară planetară. Gestionarea manuală a unui cluster de calcul DIY este lentă și costisitoare. Această caracteristică este deosebit de utilă atunci când setul de date de mobilitate implică mai mult de câteva orașe în mai multe state sau chiar țări și poate fi utilizată pentru a rula o abordare ML în doi pași.
Primul pas este să folosiți algoritmul de clustering spațial bazat pe densitate a aplicațiilor cu zgomot (DBSCAN) pentru a opri opririle de la ping-uri. Următorul pas este să utilizați metoda mașinilor vector de suport (SVM) pentru a îmbunătăți în continuare precizia opririlor identificate și, de asemenea, pentru a distinge opririle cu angajamente cu un POI față de opririle fără unul (cum ar fi acasă sau serviciu). De asemenea, puteți utiliza jobul de procesare SageMaker pentru a genera călătorii și traiectorii din ping-urile zilnice ale dispozitivului, identificând opriri consecutive și cartând calea dintre opririle sursă și destinație.
După procesarea datelor brute (ping-uri zilnice ale dispozitivului) la scară cu joburi de procesare geospațială, noul set de date numit stops ar trebui să aibă următoarea schemă.
| Atribut | Descriere |
| Id sau menajeră | ID-ul de publicitate mobil al dispozitivului (hashed) |
| lat | Latitudinea centroidului clusterului de oprire |
| lng | Longitudinea centroidului clusterului de oprire |
| geohash | Locația Geohash a POI |
| tip de dispozitiv | Sistemul de operare al dispozitivului (IDFA sau GAID) |
| timestamp-ul | Ora de începere a opririi |
| timp_de_locuire | Timpul de oprire (în secunde) |
| ip | Adresa IP |
| vechi | Altitudinea dispozitivului (în metri) |
| ţară | Cod ISO din două cifre pentru țara de origine |
| de stat | Codurile reprezentând statul |
| oraș | Codurile reprezentând orașul |
| cod poștal | Codul poștal unde este văzut ID-ul dispozitivului |
| purtător | Purtatorul dispozitivului |
| device_manufacturer | Producatorul aparatului |
Opririle sunt consolidate prin gruparea ping-urilor pe dispozitiv. Agruparea bazată pe densitate este combinată cu parametri precum pragul de oprire fiind de 300 de secunde și distanța minimă dintre opriri fiind de 50 de metri. Acești parametri pot fi ajustați în funcție de cazul dvs. de utilizare.
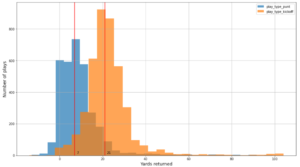
Următoarea captură de ecran arată aproximativ 15,000 de opriri identificate din 400,000 de ping-uri. Un subset al schemei precedente este prezent, de asemenea, unde coloana Dwell Time reprezintă durata opririi, iar Lat și Lng coloanele reprezintă latitudinea și longitudinea centroizilor grupului de opriri per dispozitiv și locație.
După ETL, datele sunt stocate în format de fișier Parquet, care este un format de stocare în coloană care facilitează procesarea unor cantități mari de date.
Următoarea captură de ecran arată opririle consolidate din ping-uri pe dispozitiv în interiorul mall-ului și în zonele învecinate.

După identificarea opririlor, acest set de date poate fi alăturat cu date POI disponibile public sau cu date POI personalizate specifice cazului de utilizare pentru a identifica activități, cum ar fi implicarea cu mărcile.
Următoarea captură de ecran arată opririle identificate la principalele puncte de interes (magazine și mărci) din interiorul Arrowhead Mall.
Codurile poștale de acasă au fost folosite pentru a masca locația de acasă a fiecărui vizitator pentru a menține confidențialitatea în cazul în care aceasta face parte din călătoria lor în setul de date. Latitudinea și longitudinea în astfel de cazuri sunt coordonatele respective ale centroidului codului poștal.
Următoarea captură de ecran este o reprezentare vizuală a unor astfel de activități. Imaginea din stânga mapează opririle către magazine, iar imaginea din dreapta oferă o idee despre aspectul mall-ului în sine.

Acest set de date rezultat poate fi vizualizat în mai multe moduri, despre care le vom discuta în secțiunile următoare.
Măsuri de densitate
Putem calcula și vizualiza densitatea activităților și vizitelor.
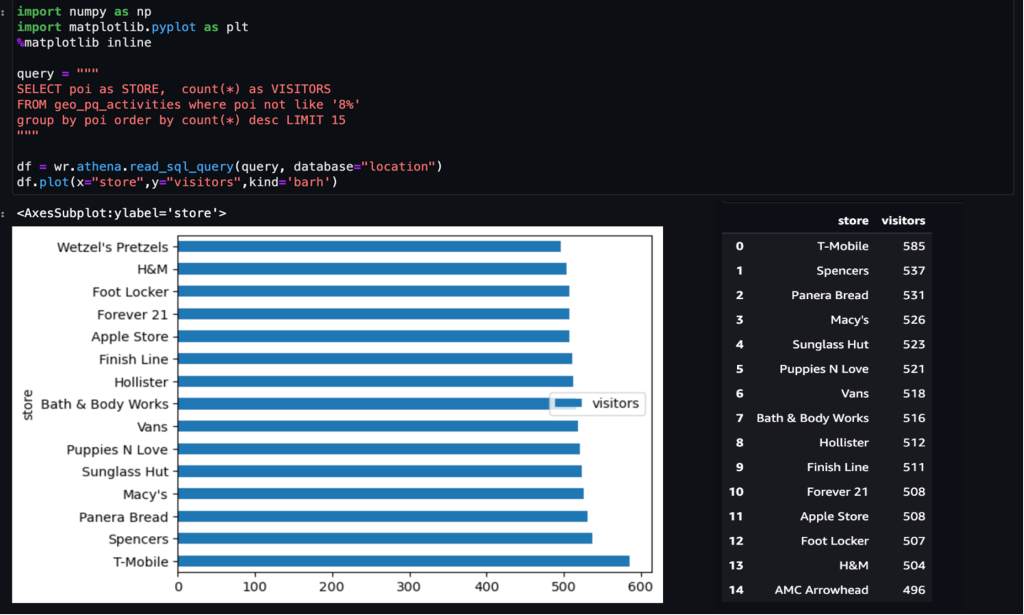
Exemplu 1 – Următoarea captură de ecran arată primele 15 magazine vizitate din mall.
Exemplu 2 – Următoarea captură de ecran arată numărul de vizite la Apple Store la fiecare oră.

Călătorii și traiectorii
După cum am menționat mai devreme, o pereche de activități consecutive reprezintă o călătorie. Putem folosi următoarea abordare pentru a deriva călătorii din datele activităților. Aici, funcțiile ferestrei sunt utilizate cu SQL pentru a genera trips tabel, așa cum se arată în captura de ecran.

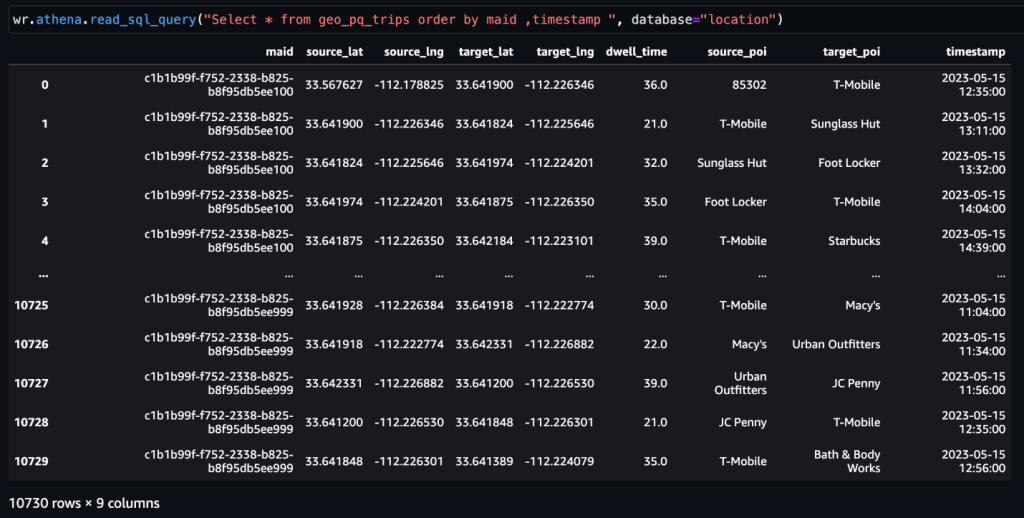
După trips tabelul este generat, pot fi determinate călătorii către un POI.
Exemplul 1 – Următoarea captură de ecran arată primele 10 magazine care direcționează traficul pietonal către Apple Store.

Exemplu 2 – Următoarea captură de ecran arată toate călătoriile la Arrowhead Mall.

Exemplu 3 – Următorul videoclip arată modelele de mișcare în interiorul mall-ului.

Exemplu 4 – Următorul videoclip arată modelele de mișcare în afara mall-ului.
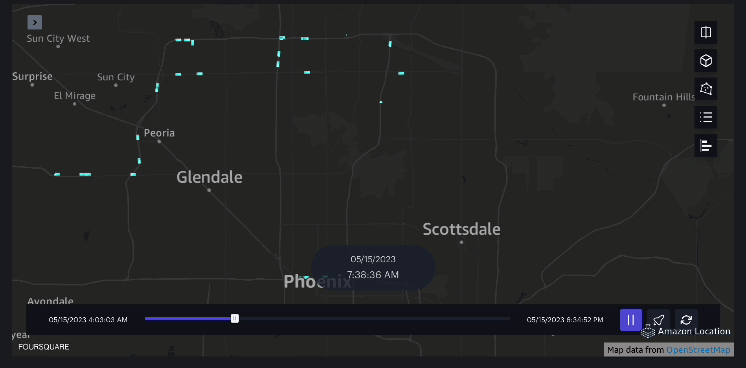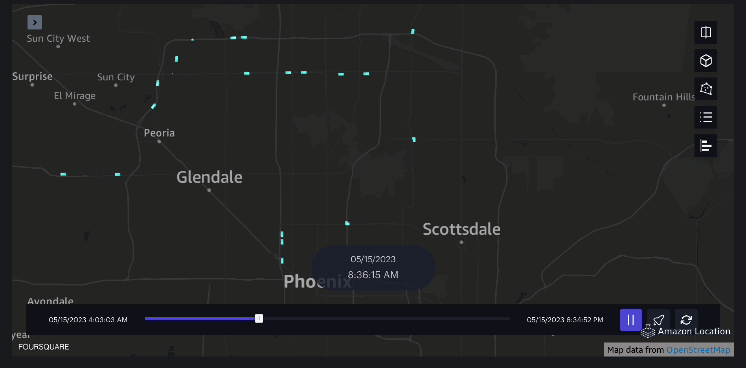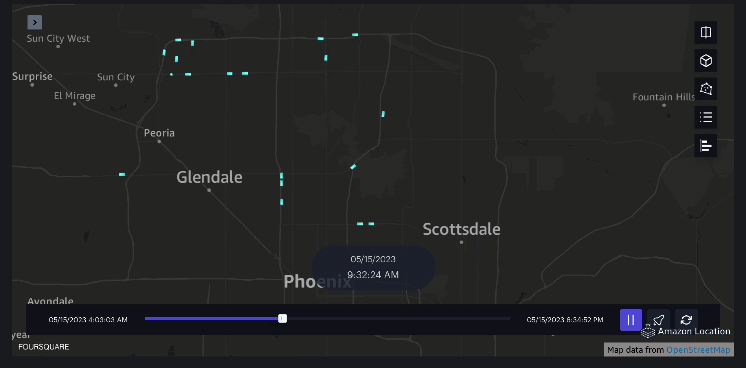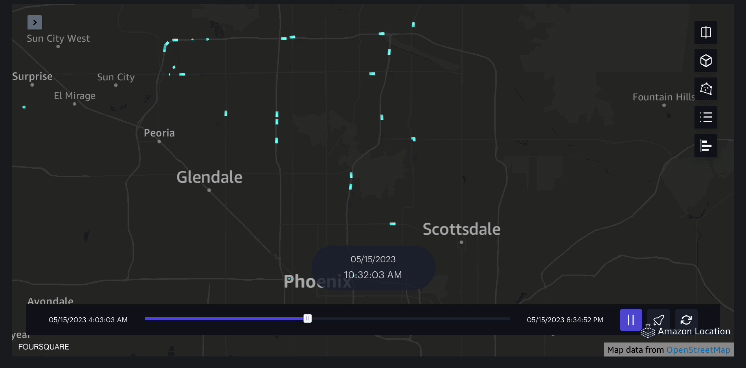
Analiza bazinului hidrografic
Putem analiza toate vizitele la un POI și putem determina zona de captare.
Exemplul 1 – Următoarea captură de ecran arată toate vizitele la magazinul Macy’s.

Exemplu 2 – Următoarea captură de ecran arată primele 10 coduri poștale ale zonei de domiciliu (limitele evidențiate) de unde au avut loc vizitele.

Verificarea calității datelor
Putem verifica calitatea fluxului de date zilnic primit și putem detecta anomalii folosind tablourile de bord și analizele de date QuickSight. Următoarea captură de ecran arată un exemplu de tablou de bord.

Concluzie
Datele de mobilitate și analiza lor pentru obținerea de informații despre clienți și obținerea unui avantaj competitiv rămâne un domeniu de nișă, deoarece este dificil să obțineți un set de date consistent și precis. Cu toate acestea, aceste date pot ajuta organizațiile să adauge context analizelor existente și chiar să producă noi perspective despre modelele de mișcare a clienților. Capacitățile geospațiale Amazon SageMaker și joburile de procesare geospatială pot ajuta la implementarea acestor cazuri de utilizare și la obținerea de informații într-un mod intuitiv și accesibil.
În această postare, am demonstrat cum să folosim serviciile AWS pentru a curăța datele de mobilitate și apoi să folosim capabilitățile geospațiale Amazon SageMaker pentru a genera seturi de date derivate, cum ar fi opriri, activități și călătorii folosind modele ML. Apoi am folosit seturile de date derivate pentru a vizualiza modelele de mișcare și pentru a genera perspective.
Puteți începe cu capabilitățile geospațiale Amazon SageMaker în două moduri:
Pentru a afla mai multe, vizitați Capacitățile geospațiale Amazon SageMaker și Noțiuni introductive cu Amazon SageMaker geospatial. De asemenea, vizitați-ne GitHub repo, care are câteva exemple de notebook-uri despre capabilitățile geospațiale Amazon SageMaker.
Despre Autori
 Jimy Matthews este un arhitect de soluții AWS, cu experiență în tehnologia AI/ML. Jimy are sediul în Boston și lucrează cu clienții întreprinderilor pe măsură ce își transformă afacerea adoptând cloud-ul și îi ajută să construiască soluții eficiente și durabile. Este pasionat de familia lui, de mașini și de artele marțiale mixte.
Jimy Matthews este un arhitect de soluții AWS, cu experiență în tehnologia AI/ML. Jimy are sediul în Boston și lucrează cu clienții întreprinderilor pe măsură ce își transformă afacerea adoptând cloud-ul și îi ajută să construiască soluții eficiente și durabile. Este pasionat de familia lui, de mașini și de artele marțiale mixte.
 Girish Keshav este arhitect de soluții la AWS, ajutând clienții în călătoria lor de migrare în cloud să modernizeze și să ruleze sarcinile de lucru în mod sigur și eficient. El lucrează cu liderii echipelor tehnologice pentru a-i ghida în ceea ce privește securitatea aplicațiilor, învățarea automată, optimizarea costurilor și sustenabilitatea. Are sediul în San Francisco și îi place să călătorească, să facă drumeții, să urmărească sporturi și să exploreze fabricile de bere artizanale.
Girish Keshav este arhitect de soluții la AWS, ajutând clienții în călătoria lor de migrare în cloud să modernizeze și să ruleze sarcinile de lucru în mod sigur și eficient. El lucrează cu liderii echipelor tehnologice pentru a-i ghida în ceea ce privește securitatea aplicațiilor, învățarea automată, optimizarea costurilor și sustenabilitatea. Are sediul în San Francisco și îi place să călătorească, să facă drumeții, să urmărească sporturi și să exploreze fabricile de bere artizanale.
 Debarcaderul Ramesh este un lider senior al Arhitecturii de soluții, axat pe a ajuta clienții întreprinderilor AWS să-și monetizeze activele de date. El îi sfătuiește pe directori și ingineri să proiecteze și să construiască soluții cloud extrem de scalabile, fiabile și rentabile, axate în special pe învățarea automată, date și analiză. În timpul liber, se bucură de aer liber, ciclism și drumeții cu familia.
Debarcaderul Ramesh este un lider senior al Arhitecturii de soluții, axat pe a ajuta clienții întreprinderilor AWS să-și monetizeze activele de date. El îi sfătuiește pe directori și ingineri să proiecteze și să construiască soluții cloud extrem de scalabile, fiabile și rentabile, axate în special pe învățarea automată, date și analiză. În timpul liber, se bucură de aer liber, ciclism și drumeții cu familia.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/use-mobility-data-to-derive-insights-using-amazon-sagemaker-geospatial-capabilities/
- :are
- :este
- :nu
- :Unde
- $UP
- 000
- 1
- 10
- 100
- 14
- 15%
- 2023
- 300
- 361
- 3d
- 400
- 50
- 7
- 9
- a
- Despre Noi
- mai sus
- accelera
- accelerat
- acces
- accesibil
- realiza
- precizie
- precis
- realizat
- activ
- activ
- activităţi de
- curent
- adăuga
- adresa
- aderat
- Ajustat
- Adoptarea
- Anunţuri
- Avantaj
- publicitate
- Promovare
- După
- Agregator
- Agregatoare
- AI / ML
- Ajutorul
- Algoritmul
- TOATE
- pe langa
- de asemenea
- Cu toate ca
- am
- Amazon
- Amazon Comprehend
- Amazon SageMaker
- Amazon SageMaker geospatial
- Amazon SageMaker Studio
- Amazon Web Services
- Sume
- an
- analize
- analiză
- Google Analytics
- analiza
- analiza
- Ancoră
- și
- Orice
- separat
- aplicaţia
- Apple
- aplicație
- securitatea aplicațiilor
- aplicatii
- abordare
- aproximativ
- arhitectură
- SUNT
- ZONĂ
- domenii
- Arizona
- în jurul
- Arte
- AS
- Bunuri
- alocate
- asociate
- At
- atinge
- audiență
- spori
- disponibil
- in medie
- AWS
- AWS Adeziv
- de bază
- bazat
- bază
- BE
- deoarece
- fost
- fiind
- între
- ofertă
- Bloca
- boston
- limitele
- marci
- construi
- Clădire
- construit-in
- afaceri
- întreprinderi
- dar
- by
- calcula
- denumit
- Campanii
- CAN
- Poate obține
- capacități
- masini
- caz
- cazuri
- CJAP
- Celule
- recensământ
- date de recensământ
- lanţ
- verifica
- Oraşe
- Oraș
- curat
- Închide
- Cloud
- Grup
- clustering
- cod
- Coduri
- colaborare
- colecta
- colectare
- colectori
- Coloană
- Coloane
- combinate
- vine
- venire
- comercial
- proprietate comerciala
- Comun
- în mod obișnuit
- Companii
- competitiv
- concurenți
- complex
- component
- înţelege
- Calcula
- Conectarea
- consecutiv
- consimţământ
- Considerații
- consistent
- consum
- Recipient
- conține
- context
- continuu
- A costat
- țări
- ţară
- acoperi
- acoperă
- ambarcaţiunilor
- tractor pe şenile
- crea
- personalizat
- client
- clienţii care
- zilnic
- tablou de bord
- tablouri de bord
- de date
- puncte de date
- confidențialitatea datelor
- de prelucrare a datelor
- seturi de date
- zi
- livrare
- demonstrat
- densitate
- ilustrând
- implementa
- derivat
- deriva
- Derivat
- Amenajări
- destinații
- detaliu
- detecta
- Determina
- determinat
- determinarea
- Dezvoltare
- dispozitiv
- Dispozitive
- dificil
- direcționa
- dezastre
- descoperirea
- discuta
- distanţă
- distinge
- diy
- face
- făcut
- DOT
- atrage
- două
- durată
- în timpul
- fiecare
- Mai devreme
- mai ușor
- uşor
- Eficace
- eficient
- eficient
- efort
- împuternici
- permite
- care să cuprindă
- angajament
- angajamente
- captivant
- inginerii
- îmbogăți
- Afacere
- clienții întreprinderii
- Mediu inconjurator
- mai ales
- bunuri
- Eter (ETH)
- etic
- Chiar
- eveniment
- Fiecare
- exemplu
- directori
- existent
- există
- scump
- experienţă
- expertiză
- explora
- Explorarea
- exporturile
- și-a exprimat
- extrage
- familie
- Caracteristică
- fed-
- puțini
- Fișier
- final
- Găsi
- fiona
- First
- flexibil
- Concentra
- concentrat
- a urmat
- următor
- Picior
- Pentru
- formă
- format
- Pătrat
- FRAME
- Francisco
- Gratuit
- din
- Combustibil
- complet
- funcţie
- funcții
- mai mult
- câștigă
- joc
- s-au adunat
- GDPR
- genera
- generată
- generează
- generator
- geografic
- geografice
- ML geospațial
- obține
- obtinerea
- gif
- dat
- oferă
- Merge
- gps
- grafică
- mare
- Mare în aer liber
- Grilă
- ghida
- Piese metalice
- hash
- Avea
- he
- ajutor
- util
- ajutor
- ajută
- aici
- Evidențiat
- extrem de
- drumeții
- lui
- Acasă
- Orizontală
- oră
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- huburi
- uragan
- ID
- idee
- identificat
- identifica
- identificarea
- IDFA
- if
- imagine
- punerea în aplicare a
- important
- îmbunătăţi
- in
- Inclusiv
- Intrare
- indicând
- individ
- industrii
- informații
- Infrastructură
- inițială
- în interiorul
- perspective
- cazuri
- integrările
- Inteligență
- interactiv
- interes
- interesant
- în
- introduce
- intuitiv
- implică
- IT
- ESTE
- în sine
- Loc de munca
- Locuri de munca
- alăturat
- călătorie
- jpg
- mare
- pe scară largă
- latitudine
- legii
- stratificat
- Aspect
- conduce
- lider
- Liderii
- AFLAȚI
- învăţare
- stânga
- biblioteci
- ca
- probabilitate
- linii
- încărca
- locaţie
- Locații
- Uite
- arată ca
- iubeste
- maşină
- masina de învățare
- Masini
- făcut
- menține
- major
- face
- FACE
- gestionate
- de conducere
- manual
- multe
- Hartă
- cartografiere
- Harta
- Marketing
- Campanii de marketing
- tehnologie de marketing
- Marter
- marţial
- masca
- Matrice
- Mai..
- mijloace
- menționat
- metodă
- Metrici
- migrațiune
- Militar
- milioane
- minim
- minut
- mixt
- ML
- Mobil
- dispozitiv mobil
- dispozitive mobile
- mobilitate
- model
- Modele
- moderniza
- modificată
- modifica
- genera bani
- lunar
- mai mult
- cele mai multe
- Mai ales
- muta
- mişcare
- mișcări
- în mişcare
- multiplu
- multitudine
- trebuie sa
- nume
- Natural
- Natură
- Nevoie
- nevoilor
- Nou
- următor
- nișă
- Zgomot
- caiet
- notebook-uri
- număr
- numere
- obiect
- observa
- obține
- obținut
- obținerea
- a avut loc
- of
- de multe ori
- on
- ONE
- afară
- deschide
- open-source
- operaţie
- Operațiuni
- opus
- optimă
- optimizare
- Optimizați
- or
- organizații
- Altele
- al nostru
- afară
- rezultate
- în aer liber
- exterior
- peste
- pereche
- panda
- pandemie
- parametrii
- parte
- în special
- trece
- pasionat
- cale
- modele
- oameni
- pentru
- efectua
- performanță
- Personal
- perspectivă
- fenix
- fotografii
- fizic
- imagine
- PII
- ping
- plasat
- Locuri
- planificare
- Plato
- Informații despre date Platon
- PlatoData
- pm
- Punct
- puncte
- Popular
- populație
- poziţie
- posibil
- Post
- potenţial
- potentiali clienti
- alimentat
- precedent
- Predictii
- prezenta
- intimitate
- legile de confidențialitate
- privat
- proces
- prelucrare
- produce
- furniza
- public
- editori
- cumpărare
- cumparate
- scop
- Piton
- calitate
- rank
- mai degraba
- Crud
- date neprelucrate
- real
- Imobiliare
- inregistrata
- trimite
- referință
- se referă
- regiuni
- de încredere
- rămășițe
- reprezenta
- reprezentare
- reprezentate
- reprezentând
- reprezintă
- necesar
- respectiv
- responsabil
- restaurante
- rezultând
- REZULTATE
- cu amănuntul
- dreapta
- Traseul
- rute
- Alerga
- funcţionare
- sagemaker
- Exemplu de set de date
- San
- San Francisco
- satelit
- Imagini din satelit
- scalabil
- Scară
- oamenii de stiinta
- capturi de ecran
- sdks
- fără sudură
- Al doilea
- secunde
- secțiuni
- în siguranță,
- securitate
- selecţie
- senior
- sensibil
- trimis
- distinct
- serie
- Servicii
- servire
- câteva
- Distribuie
- Cumpărături
- să
- indicat
- Emisiuni
- asemănător
- simplu
- simplificată
- singur
- teren
- încetini
- So
- soluţii
- rezolvă
- unele
- căutat
- Sursă
- Surse
- Spaţiu
- spațial
- specific
- Sportul
- pete
- SQL
- standardizare
- început
- începe
- Declarații
- Statele
- Pas
- paşi
- Stop
- oprit
- oprire
- opriri
- depozitare
- stoca
- stocate
- magazine
- simplu
- curent
- studio
- substanțial
- astfel de
- livra
- lanțului de aprovizionare
- a sustine
- Suprafață
- Înconjurător
- Durabilitate
- durabilă
- sistem
- tabel
- luate
- echipe
- tech
- Tehnic
- tehnici de
- Tehnologia
- zeci
- decât
- acea
- Zona
- Sursa
- lor
- Lor
- se
- apoi
- Acolo.
- Acestea
- ei
- acest
- aceste
- mii
- prag
- Prin
- timp
- la
- de asemenea
- instrument
- Unelte
- top
- Top 10
- Total
- față de
- calc
- trafic
- Tren
- traiectorie
- Transforma
- transformări
- emițătoare
- călătorie
- Traveling
- Tendinţe
- excursie
- Două
- Tipuri
- tipic
- care stau la baza
- înţelegere
- unic
- încărcat
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizatorii
- utilizări
- folosind
- folosi
- diverse
- verifica
- de
- Video
- Vizita
- vizitat
- vizitatori
- Vizite
- vizual
- vizualizare
- imagina
- vizuale
- vs
- vizionarea
- Cale..
- modalități de
- we
- web
- servicii web
- săptămânal
- BINE
- Ce
- cand
- care
- OMS
- întreg
- de ce
- Wi-fi
- pe scară largă
- voi
- fereastră
- cu
- fără
- Apartamente
- flux de lucru
- fabrică
- scris
- anual
- tu
- Ta
- zephyrnet
- Zip