Această postare este scrisă împreună cu Preshen Goobiah și Johan Olivier de la Capitec.
Apache Spark este un sistem de procesare distribuită cu sursă deschisă folosit pe scară largă, renumit pentru gestionarea sarcinilor de lucru de date la scară largă. Găsește aplicații frecvente printre dezvoltatorii Spark care lucrează Amazon EMR, Amazon SageMaker, AWS Adeziv și aplicații Spark personalizate.
Amazon RedShift oferă o integrare perfectă cu Apache Spark, permițându-vă să accesați cu ușurință datele Redshift atât pe clusterele furnizate de Amazon Redshift, cât și Amazon Redshift fără server. Această integrare extinde posibilitățile pentru soluțiile AWS de analiză și învățare automată (ML), făcând depozitul de date accesibil pentru o gamă mai largă de aplicații.
Cu Integrare Amazon Redshift pentru Apache Spark, puteți începe rapid și puteți dezvolta fără efort aplicații Spark folosind limbaje populare precum Java, Scala, Python, SQL și R. Aplicațiile dvs. pot citi și scrie fără probleme din depozitul dvs. de date Amazon Redshift, menținând în același timp performanța optimă și consistența tranzacțională. În plus, veți beneficia de îmbunătățiri ale performanței prin optimizări pushdown, sporind și mai mult eficiența operațiunilor dumneavoastră.
Capitec, cea mai mare bancă de retail din Africa de Sud, cu peste 21 de milioane de clienți de servicii bancare cu amănuntul, își propune să ofere servicii financiare simple, accesibile și accesibile pentru a-i ajuta pe sud-africanii să investească mai bine, astfel încât să poată trăi mai bine. În această postare, discutăm despre integrarea cu succes a conectorului Amazon Redshift open source de către echipa de servicii partajate Feature Platform a Capitec. Ca urmare a utilizării integrării Amazon Redshift pentru Apache Spark, productivitatea dezvoltatorilor a crescut cu un factor de 10, conductele de generare de caracteristici au fost simplificate, iar duplicarea datelor a fost redusă la zero.
Oportunitatea de afaceri
Există 19 modele predictive pentru utilizarea a 93 de funcții construite cu AWS Glue în diviziile Capitec Retail Credit. Înregistrările caracteristicilor sunt îmbogățite cu fapte și dimensiuni stocate în Amazon Redshift. Apache PySpark a fost selectat pentru a crea funcții, deoarece oferă un mecanism rapid, descentralizat și scalabil pentru a dispută date din diverse surse.
Aceste caracteristici de producție joacă un rol crucial în a permite aplicații de împrumut pe termen fix în timp real, aplicații pentru carduri de credit, monitorizarea comportamentului de credit lunar și identificarea salariului zilnic în cadrul companiei.
Problema sursei de date
Pentru a asigura fiabilitatea conductelor de date PySpark, este esențial să aveți date consistente la nivel de înregistrare din tabelele dimensionale și de fapt stocate în Enterprise Data Warehouse (EDW). Aceste tabele sunt apoi unite cu tabele din Enterprise Data Lake (EDL) în timpul execuției.
În timpul dezvoltării caracteristicilor, inginerii de date necesită o interfață perfectă pentru EDW. Această interfață le permite să acceseze și să integreze datele necesare din EDW în conductele de date, permițând dezvoltarea și testarea eficientă a caracteristicilor.
Procesul de rezolvare anterior
În soluția anterioară, inginerii de date din echipa de produs au petrecut 30 de minute pe rulare pentru a expune manual datele Redshift la Spark. Pașii au inclus următorii:
- Construiți o interogare predicată în Python.
- Trimiteți un mesaj DESCĂRCA interogare prin intermediul Amazon Redshift Data API.
- Datele de catalog în AWS Glue Data Catalog prin intermediul AWS SDK for Pandas folosind eșantionarea.
Această abordare a pus probleme pentru seturi mari de date, a necesitat întreținere recurentă din partea echipei platformei și a fost complex de automatizat.
Prezentare generală a soluției actuale
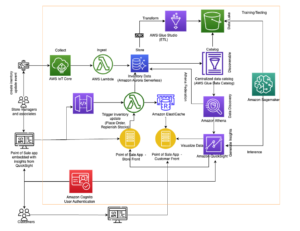
Capitec a reușit să rezolve aceste probleme cu integrarea Amazon Redshift pentru Apache Spark în conductele de generare de caracteristici. Arhitectura este definită în diagrama următoare.

Fluxul de lucru include următorii pași:
- Bibliotecile interne sunt instalate în jobul AWS Glue PySpark prin AWS CodeArtifact.
- Un job AWS Glue preia acreditările de cluster Redshift de la Manager de secrete AWS și configurează conexiunea Amazon Redshift (injectează acreditările de cluster, locații de descărcare, formate de fișiere) prin biblioteca internă partajată. Integrarea Amazon Redshift pentru Apache Spark acceptă și utilizarea Gestionarea identității și accesului AWS (IAM) la recuperați acreditările și conectați-vă la Amazon Redshift.
- Interogarea Spark este tradusă într-o interogare optimizată Amazon Redshift și trimisă la EDW. Acest lucru este realizat prin integrarea Amazon Redshift pentru Apache Spark.
- Setul de date EDW este descărcat într-un prefix temporar într-un Serviciul Amazon de stocare simplă Găleată (Amazon S3)
- Setul de date EDW din compartimentul S3 este încărcat în executanții Spark prin integrarea Amazon Redshift pentru Apache Spark.
- Setul de date EDL este încărcat în executanții Spark prin AWS Glue Data Catalog.
Aceste componente lucrează împreună pentru a se asigura că inginerii de date și conductele de date de producție au instrumentele necesare pentru a implementa integrarea Amazon Redshift pentru Apache Spark, pentru a rula interogări și pentru a facilita descărcarea datelor din Amazon Redshift în EDL.
Utilizarea integrării Amazon Redshift pentru Apache Spark în AWS Glue 4.0
În această secțiune, demonstrăm utilitatea integrării Amazon Redshift pentru Apache Spark prin îmbogățirea unui tabel de cereri de împrumut care se află în lacul de date S3 cu informații despre clienți din depozitul de date Redshift din PySpark.
dimclient tabelul din Amazon Redshift conține următoarele coloane:
- ClientKey – INT8
- ClientAltKey – VARCHAR50
- PartyIdentifierNumber – VARCHAR20
- ClientCreateDate - DATA
- Este anulat – INT2
- RowIsCurrent – INT2
loanapplication tabelul din Catalogul de date AWS Glue conține următoarele coloane:
- RecordID – MARE
- LogDate - TIMESTAMP-UL
- PartyIdentifierNumber – STRING
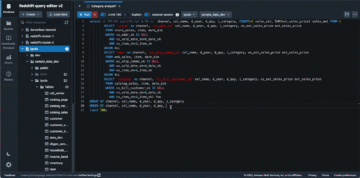
Tabelul Redshift este citit prin integrarea Amazon Redshift pentru Apache Spark și stocat în cache. Vezi următorul cod:
Înregistrările cererii de împrumut sunt citite din lacul de date S3 și îmbogățite cu dimclient tabel cu informații despre Amazon Redshift:
Ca urmare, înregistrarea cererii de împrumut (din lacul de date S3) este îmbogățită cu ClientCreateDate coloană (de la Amazon Redshift).

Cum rezolvă integrarea Amazon Redshift pentru Apache Spark problema aprovizionării datelor
Integrarea Amazon Redshift pentru Apache Spark abordează eficient problema aprovizionării datelor prin următoarele mecanisme:
- Lectură la timp – Integrarea Amazon Redshift pentru conectorul Apache Spark citește tabelele Redshift într-o manieră la timp, asigurând consistența datelor și a schemei. Acest lucru este deosebit de valoros pentru Dimensiunea tip 2 care se schimbă lent (SCD) și intervalul de timp acumulând fapte instantanee. Prin combinarea acestor tabele Redshift cu tabelele AWS Glue Data Catalog din sistemul sursă din EDL în conductele de producție PySpark, conectorul permite integrarea perfectă a datelor din mai multe surse, menținând în același timp integritatea datelor.
- Interogări optimizate Redshift – Integrarea Amazon Redshift pentru Apache Spark joacă un rol crucial în transformarea planului de interogare Spark într-o interogare optimizată Redshift. Acest proces de conversie simplifică experiența de dezvoltare pentru echipa de produs prin aderarea la principiul localității datelor. Interogările optimizate utilizează capacitățile și optimizările de performanță ale Amazon Redshift, asigurând preluarea și procesarea eficientă a datelor de la Amazon Redshift pentru conductele PySpark. Acest lucru ajută la eficientizarea procesului de dezvoltare, îmbunătățind în același timp performanța generală a operațiunilor de aprovizionare a datelor.
Obține cele mai bune performanțe
Integrarea Amazon Redshift pentru Apache Spark aplică automat predicate și interogări pushdown pentru a optimiza performanța. Puteți obține îmbunătățiri de performanță utilizând formatul implicit Parquet utilizat pentru descărcare cu această integrare.
Pentru detalii suplimentare și exemple de cod, consultați Nou – Integrarea Amazon Redshift cu Apache Spark.
Beneficiile soluției
Adoptarea integrării a adus mai multe beneficii semnificative pentru echipă:
- Productivitate îmbunătățită a dezvoltatorilor – Interfața PySpark oferită de integrare a sporit productivitatea dezvoltatorului cu un factor de 10, permițând o interacțiune mai fluidă cu Amazon Redshift.
- Eliminarea dublării datelor – Tabelele Redshift duplicate și catalogate AWS Glue din lacul de date au fost eliminate, rezultând un mediu de date mai raționalizat.
- Sarcină EDW redusă – Integrarea a facilitat descărcarea selectivă a datelor, minimizând încărcarea EDW prin extragerea doar a datelor necesare.
Utilizând integrarea Amazon Redshift pentru Apache Spark, Capitec a deschis calea pentru o procesare îmbunătățită a datelor, o productivitate crescută și un ecosistem de inginerie a funcțiilor mai eficient.
Concluzie
În această postare, am discutat despre modul în care echipa Capitec a implementat cu succes integrarea Apache Spark Amazon Redshift pentru Apache Spark pentru a-și simplifica fluxurile de lucru de calcul al caracteristicilor. Aceștia au subliniat importanța utilizării conductelor de date PySpark descentralizate și modulare pentru crearea caracteristicilor modelului predictiv.
În prezent, integrarea Amazon Redshift pentru Apache Spark este utilizată de 7 conducte de date de producție și 20 de conducte de dezvoltare, arătându-și eficacitatea în mediul Capitec.
Mergând mai departe, echipa de servicii partajate Feature Platform de la Capitec intenționează să extindă adoptarea integrării Amazon Redshift pentru Apache Spark în diferite domenii de afaceri, cu scopul de a îmbunătăți și mai mult capabilitățile de procesare a datelor și de a promova practici eficiente de inginerie a caracteristicilor.
Pentru informații suplimentare despre utilizarea integrării Amazon Redshift pentru Apache Spark, consultați următoarele resurse:
Despre Autori
 Preshen Goobiah este inginer principal de învățare automată pentru platforma de caracteristici la Capitec. El se concentrează pe proiectarea și construirea de componente Feature Store pentru uzul întreprinderilor. În timpul liber, îi place să citească și să călătorească.
Preshen Goobiah este inginer principal de învățare automată pentru platforma de caracteristici la Capitec. El se concentrează pe proiectarea și construirea de componente Feature Store pentru uzul întreprinderilor. În timpul liber, îi place să citească și să călătorească.
 Johan Olivier este inginer senior de învățare automată pentru platforma de modele Capitec. Este un antreprenor și pasionat de rezolvare a problemelor. Îi place muzica și socializarea în timpul liber.
Johan Olivier este inginer senior de învățare automată pentru platforma de modele Capitec. Este un antreprenor și pasionat de rezolvare a problemelor. Îi place muzica și socializarea în timpul liber.
 Sudipta Bagchi este arhitect de soluții de specialitate senior la Amazon Web Services. Are peste 12 ani de experiență în date și analiză și îi ajută pe clienți să proiecteze și să construiască soluții de analiză scalabile și de înaltă performanță. În afara serviciului, îi place să alerge, să călătorească și să joace cricket. Conectează-te cu el LinkedIn.
Sudipta Bagchi este arhitect de soluții de specialitate senior la Amazon Web Services. Are peste 12 ani de experiență în date și analiză și îi ajută pe clienți să proiecteze și să construiască soluții de analiză scalabile și de înaltă performanță. În afara serviciului, îi place să alerge, să călătorească și să joace cricket. Conectează-te cu el LinkedIn.
 Syed Humair este arhitect de soluții Senior Analytics Specialist la Amazon Web Services (AWS). Are peste 17 ani de experiență în arhitectura întreprinderii, concentrându-se pe date și AI/ML, ajutând clienții AWS la nivel global să-și abordeze cerințele tehnice și de afaceri. Te poți conecta cu el pe LinkedIn.
Syed Humair este arhitect de soluții Senior Analytics Specialist la Amazon Web Services (AWS). Are peste 17 ani de experiență în arhitectura întreprinderii, concentrându-se pe date și AI/ML, ajutând clienții AWS la nivel global să-și abordeze cerințele tehnice și de afaceri. Te poți conecta cu el pe LinkedIn.
 Vuyisa Maswana este arhitect senior de soluții la AWS, cu sediul în Cape Town. Vuyisa se concentrează puternic pe a ajuta clienții să construiască soluții tehnice pentru a rezolva problemele de afaceri. El a sprijinit Capitec în călătoria lor AWS din 2019.
Vuyisa Maswana este arhitect senior de soluții la AWS, cu sediul în Cape Town. Vuyisa se concentrează puternic pe a ajuta clienții să construiască soluții tehnice pentru a rezolva problemele de afaceri. El a sprijinit Capitec în călătoria lor AWS din 2019.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/simplifying-data-processing-at-capitec-with-amazon-redshift-integration-for-apache-spark/
- :are
- :este
- $UP
- 06
- 1
- 10
- 100
- 12
- 16
- 17
- 19
- 20
- 2019
- 30
- 7
- a
- Capabil
- acces
- accesibil
- realizat
- peste
- Suplimentar
- informatii suplimentare
- În plus,
- adresa
- adrese
- aderare
- Adoptare
- accesibil
- AI / ML
- Urmarind
- isi propune
- Permiterea
- permite
- de asemenea
- Amazon
- Amazon Web Services
- Amazon Web Services (AWS)
- printre
- an
- Google Analytics
- și
- Apache
- Apache Spark
- aplicație
- aplicatii
- se aplică
- abordare
- arhitectură
- SUNT
- domenii
- AS
- At
- automatizarea
- în mod automat
- AWS
- AWS Adeziv
- Bancă
- Bancar
- bazat
- deoarece
- comportament
- beneficia
- Beneficiile
- CEL MAI BUN
- Mai bine
- între
- Cea mai mare
- amplificat
- atât
- mai larg
- construi
- Clădire
- construit
- afaceri
- by
- CAN
- capacități
- pelerină
- card
- catalog
- schimbarea
- client
- clientii
- Grup
- CO
- cod
- Coloană
- Coloane
- combinând
- complex
- componente
- calcul
- Conectați
- conexiune
- consistent
- conține
- context
- Convertire
- de conversie a
- crea
- Crearea
- scrisori de acreditare
- credit
- card de credit
- crichet
- crucial
- personalizat
- clienţii care
- zilnic
- de date
- Lacul de date
- de prelucrare a datelor
- depozit de date
- seturi de date
- descentralizată
- Mod implicit
- definit
- demonstra
- Amenajări
- proiect
- detalii
- dezvolta
- Dezvoltator
- Dezvoltatorii
- Dezvoltare
- diferit
- Dimensiune
- Dimensiuni
- discuta
- discutat
- distribuite
- diferit
- cu ușurință
- ecosistem
- în mod eficient
- eficacitate
- eficiență
- eficient
- efort
- eliminat
- accentuat
- permite
- permițând
- inginer
- Inginerie
- inginerii
- spori
- consolidarea
- îmbogățit
- îmbogățitor
- asigura
- asigurare
- Afacere
- entuziast
- Antreprenor
- Mediu inconjurator
- esenţial
- Eter (ETH)
- existent
- Extinde
- se extinde
- experienţă
- facilita
- facilitat
- fapt
- factor
- fapte
- FAST
- Caracteristică
- DESCRIERE
- Fișier
- financiar
- Servicii financiare
- descoperiri
- Concentra
- concentrat
- concentrându-se
- următor
- Pentru
- format
- Înainte
- frecvent
- din
- funcții
- mai mult
- Câştig
- generaţie
- obține
- GitHub
- La nivel global
- Manipularea
- Avea
- he
- ajutor
- ajutor
- ajută
- -l
- lui
- Cum
- HTML
- http
- HTTPS
- IAM
- Identificare
- Identitate
- punerea în aplicare a
- implementat
- import
- importanță
- îmbunătățit
- îmbunătățiri
- in
- inclus
- include
- a crescut
- informații
- integra
- integrare
- integritate
- interacţiune
- interfaţă
- intern
- în
- probleme de
- IT
- ESTE
- Java
- Loc de munca
- alătura
- alăturat
- călătorie
- lac
- Limbă
- mare
- pe scară largă
- conduce
- învăţare
- stânga
- biblioteci
- Bibliotecă
- ca
- trăi
- încărca
- împrumut
- Locații
- iubeste
- maşină
- masina de învățare
- mentine
- întreținere
- Efectuarea
- manieră
- manual
- mecanism
- mecanisme
- milion
- minimizând
- minute
- ML
- model
- Modele
- modular
- Monitorizarea
- lunar
- mai mult
- mai eficient
- multiplu
- Muzică
- necesar
- of
- promoții
- Măslin
- on
- afară
- deschide
- open-source
- Operațiuni
- optimă
- Optimizați
- optimizate
- comandă
- exterior
- peste
- global
- panda
- în special
- Parolă
- pentru
- performanță
- plan
- Planurile
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- Joaca
- joc
- joacă
- Popular
- pozat
- posibilităţile de
- Post
- practicile
- predictivă
- precedent
- principiu
- Problemă
- de rezolvare a problemelor
- probleme
- proces
- prelucrare
- Produs
- producere
- productivitate
- promova
- furniza
- prevăzut
- Piton
- interogări
- repede
- R
- gamă
- Citeste
- Citind
- în timp real
- record
- înregistrări
- recurente
- Redus
- trimite
- încredere
- Renumit
- necesita
- necesar
- Cerinţe
- rezolvă
- Resurse
- rezultat
- rezultând
- cu amănuntul
- Bancare cu amănuntul
- Rol
- Alerga
- funcţionare
- salariu
- SC
- Scala
- scalabil
- domeniu
- sdk
- fără sudură
- perfect
- secrete
- Secțiune
- vedea
- selectate
- selectarea
- selectiv
- senior
- Servicii
- Seturi
- câteva
- comun
- simbolizeazã
- semnificativ
- simplu
- simplifica
- simplificarea
- întrucât
- Încet
- mai lin
- Instantaneu
- So
- socializare
- soluţie
- soluţii
- REZOLVAREA
- rezolvă
- Sursă
- Surse
- Sourcing
- Sud
- Scânteie
- specialist
- uzat
- SQL
- început
- paşi
- depozitare
- stocate
- simplifica
- raționalizate
- Şir
- puternic
- prezentat
- de succes
- Reușit
- Suportat
- Sprijină
- sistem
- tabel
- echipă
- Tehnic
- temporar
- Testarea
- acea
- Sursa
- lor
- Lor
- apoi
- Acestea
- ei
- acest
- Prin
- timp
- la
- împreună
- Unelte
- oraş
- tranzacțional
- Traveling
- URL-ul
- utilizare
- utilizat
- folosind
- utilitate
- utilizate
- Utilizand
- Valoros
- de
- Depozit
- a fost
- Cale..
- we
- web
- servicii web
- au fost
- în timp ce
- cu
- în
- Apartamente
- lucram impreuna
- flux de lucru
- fluxuri de lucru
- de lucru
- scrie
- ani
- a cedat
- tu
- Ta
- zephyrnet
- zero