În era informațională de astăzi, volumele mari de date găzduite în nenumărate documente reprezintă atât o provocare, cât și o oportunitate pentru afaceri. Metodele tradiționale de procesare a documentelor sunt adesea insuficiente în ceea ce privește eficiența și acuratețea, lăsând loc pentru inovație, eficiență a costurilor și optimizări. Procesarea documentelor a cunoscut progrese semnificative odată cu apariția procesării inteligente a documentelor (IDP). Cu IDP, companiile pot transforma datele nestructurate din diferite tipuri de documente în perspective structurate, acționabile, sporind dramatic eficiența și reducând eforturile manuale. Cu toate acestea, potențialul nu se termină aici. Prin integrarea inteligenței artificiale generative (AI) în proces, putem îmbunătăți și mai mult capacitățile IDP. Inteligența artificială generativă nu numai că introduce capacități îmbunătățite în procesarea documentelor, ci introduce și o adaptabilitate dinamică la modelele de date în schimbare. Această postare vă duce prin sinergia IDP și AI generativă, dezvăluind modul în care acestea reprezintă următoarea frontieră în procesarea documentelor.
Discutăm în detaliu despre IDP în seria noastră Procesarea inteligentă a documentelor cu serviciile AWS AI (Partea 1 și Partea 2). În această postare, discutăm cum să extindem o arhitectură IDP nouă sau existentă cu modele de limbaj mari (LLM). Mai precis, discutăm despre cum ne putem integra Text Amazon cu LangChain ca încărcător de documente și Amazon Bedrock pentru a extrage date din documente și pentru a utiliza capabilități generative AI în cadrul diferitelor faze ale IDP.
Amazon Textract este un serviciu de învățare automată (ML) care extrage automat text, scris de mână și date din documentele scanate. Amazon Bedrock este un serviciu complet gestionat care oferă o gamă de modele de fundație (FM) de înaltă performanță prin intermediul API-urilor ușor de utilizat.
Următoarea diagramă este o arhitectură de referință la nivel înalt care explică modul în care puteți îmbunătăți și mai mult un flux de lucru IDP cu modele de bază. Puteți utiliza LLM-urile în una sau în toate fazele IDP, în funcție de cazul de utilizare și de rezultatul dorit.
În secțiunile următoare, ne aprofundăm modul în care Amazon Texttract este integrat în fluxurile de lucru AI generative folosind LangChain pentru a procesa documente pentru fiecare dintre aceste sarcini specifice. Blocurile de cod furnizate aici au fost tăiate pentru concizie. Consultați-vă GitHub depozit pentru caiete Python detaliate și o prezentare pas cu pas.
Extragerea textului din documente este un aspect crucial atunci când vine vorba de procesarea documentelor cu LLM. Puteți utiliza Amazon Texttract pentru a extrage text brut nestructurat din documente și pentru a păstra obiectele originale semistructurate sau structurate, cum ar fi perechile cheie-valoare și tabelele prezente în document. Pachetele de documente, cum ar fi cererile de asistență medicală și de asigurări sau creditele ipotecare, constau în formulare complexe care conțin o mulțime de informații în formate structurate, semi-structurate și nestructurate. Extragerea documentelor este un pas important aici, deoarece LLM-urile beneficiază de conținutul bogat pentru a genera răspunsuri mai precise și mai relevante, care altfel ar putea afecta calitatea rezultatelor LLM-urilor.
LangChain este un cadru puternic open-source pentru integrarea cu LLMs. LLM-urile în general sunt versatile, dar se pot lupta cu sarcini specifice domeniului în care sunt necesare un context mai profund și răspunsuri nuanțate. LangChain dă putere dezvoltatorilor în astfel de scenarii să construiască agenți care pot descompune sarcinile complexe în sub-sarcini mai mici. Sub-sarcinile pot introduce apoi context și memorie în LLM-uri prin conectarea și înlănțuirea solicitărilor LLM.
Oferte LangChain încărcătoare de documente care poate încărca și transforma date din documente. Le puteți folosi pentru a structura documente în formatele preferate care pot fi procesate de către LLM. The AmazonTextractPDFLoader este un tip de încărcător de servicii de încărcare de documente care oferă o modalitate rapidă de automatizare a procesării documentelor prin utilizarea Amazon Texttract în combinație cu LangChain. Pentru mai multe detalii despre AmazonTextractPDFLoader, se referă la LangChain documentație. Pentru a utiliza încărcătorul de documente Amazon Texttract, începeți prin a-l importa din biblioteca LangChain:
from langchain.document_loaders import AmazonTextractPDFLoaderhttps_loader = AmazonTextractPDFLoader("https://sample-website.com/sample-doc.pdf")
https_document = https_loader.load() s3_loader = AmazonTextractPDFLoader("s3://sample-bucket/sample-doc.pdf")
s3_document = s3_loader.load()De asemenea, puteți stoca documente în Amazon S3 și vă puteți referi la ele folosind modelul URL s3://, așa cum este explicat în Accesarea unei găleți folosind S3://și transmiteți această cale S3 către încărcătorul PDF Amazon Texttract:
import boto3
textract_client = boto3.client('textract', region_name='us-east-2') file_path = "s3://amazon-textract-public-content/langchain/layout-parser-paper.pdf"
loader = AmazonTextractPDFLoader(file_path, client=textract_client)
documents = loader.load()Un document cu mai multe pagini va conține mai multe pagini de text, care pot fi apoi accesate prin intermediul obiectului documente, care este o listă de pagini. Următorul cod parcurge paginile din obiectul documente și tipărește textul documentului, care este disponibil prin intermediul page_content atribut:
print(len(documents)) for document in documents: print(document.page_content)Amazon Comprehend și LLM-urile pot fi utilizate eficient pentru clasificarea documentelor. Amazon Comprehend este un serviciu de procesare a limbajului natural (NLP) care utilizează ML pentru a extrage informații din text. Amazon Comprehend acceptă, de asemenea, instruirea modelelor de clasificare personalizate cu cunoașterea aspectului documentelor precum PDF-uri, Word și formate de imagine. Pentru mai multe informații despre utilizarea clasificatorului de documente Amazon Comprehend, consultați Clasificatorul de documente Amazon Comprehend adaugă suport pentru aspect pentru o precizie mai mare.
Atunci când este asociată cu LLM, clasificarea documentelor devine o abordare puternică pentru gestionarea unor volume mari de documente. LLM-urile sunt utile în clasificarea documentelor, deoarece pot analiza textul, modelele și elementele contextuale din document folosind înțelegerea limbajului natural. De asemenea, le puteți regla fin pentru anumite clase de documente. Când un nou tip de document introdus în conducta IDP necesită clasificare, LLM poate procesa text și clasifica documentul în funcție de un set de clase. Următorul este un exemplu de cod care utilizează încărcătorul de documente LangChain alimentat de Amazon Texttract pentru a extrage textul din document și a-l utiliza pentru clasificarea documentului. Noi folosim Claude antropic v2 model prin Amazon Bedrock pentru a efectua clasificarea.
În exemplul următor, extragem mai întâi text dintr-un raport de externare a pacientului și folosim un LLM pentru a-l clasifica având în vedere o listă de trei tipuri de documente diferite—DISCHARGE_SUMMARY, RECEIPT, și PRESCRIPTION. Următoarea captură de ecran arată raportul nostru.
from langchain.document_loaders import AmazonTextractPDFLoader
from langchain.llms import Bedrock
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain loader = AmazonTextractPDFLoader("./samples/document.png")
document = loader.load() template = """ Given a list of classes, classify the document into one of these classes. Skip any preamble text and just give the class name. <classes>DISCHARGE_SUMMARY, RECEIPT, PRESCRIPTION</classes>
<document>{doc_text}<document>
<classification>""" prompt = PromptTemplate(template=template, input_variables=["doc_text"])
bedrock_llm = Bedrock(client=bedrock, model_id="anthropic.claude-v2") llm_chain = LLMChain(prompt=prompt, llm=bedrock_llm)
class_name = llm_chain.run(document[0].page_content) print(f"The provided document is = {class_name}")
Rezumarea implică condensarea unui anumit text sau document într-o versiune mai scurtă, păstrând în același timp informațiile cheie. Această tehnică este benefică pentru recuperarea eficientă a informațiilor, ceea ce permite utilizatorilor să înțeleagă rapid punctele cheie ale unui document fără a citi întregul conținut. Deși Amazon Texttract nu realizează în mod direct rezumarea textului, oferă capabilitățile fundamentale de extragere a întregului text din documente. Acest text extras servește ca intrare la modelul nostru LLM pentru efectuarea sarcinilor de rezumare a textului.
Folosind același eșantion de raport de descărcare, folosim AmazonTextractPDFLoader pentru a extrage text din acest document. Ca și înainte, folosim modelul Claude v2 prin Amazon Bedrock și îl inițializam cu un prompt care conține instrucțiunile despre ce să facem cu textul (în acest caz, rezumat). În cele din urmă, rulăm lanțul LLM prin trecerea textului extras din încărcătorul de documente. Aceasta rulează o acțiune de inferență asupra LLM cu promptul care constă în instrucțiunile de rezumat și textul documentului marcat de Document. Consultați următorul cod:
Codul generează rezumatul unui raport rezumat de externare a pacientului:
Exemplul precedent a folosit un document cu o singură pagină pentru a efectua rezumatul. Cu toate acestea, probabil că veți avea de-a face cu documente care conțin mai multe pagini care necesită rezumat. O modalitate obișnuită de a realiza rezumatul pe mai multe pagini este să generați mai întâi rezumate pe bucăți mai mici de text și apoi să combinați rezumatele mai mici pentru a obține un rezumat final al documentului. Rețineți că această metodă necesită apeluri multiple către LLM. Logica pentru aceasta poate fi creată cu ușurință; cu toate acestea, LangChain oferă un lanț de rezumate încorporat care poate rezuma texte mari (din documente cu mai multe pagini). Rezumarea poate avea loc fie prin map_reduce sau cu stuff opțiuni, care sunt disponibile ca opțiuni pentru a gestiona apelurile multiple către LLM. În exemplul următor, folosim map_reduce pentru a rezuma un document cu mai multe pagini. Figura următoare ilustrează fluxul nostru de lucru.
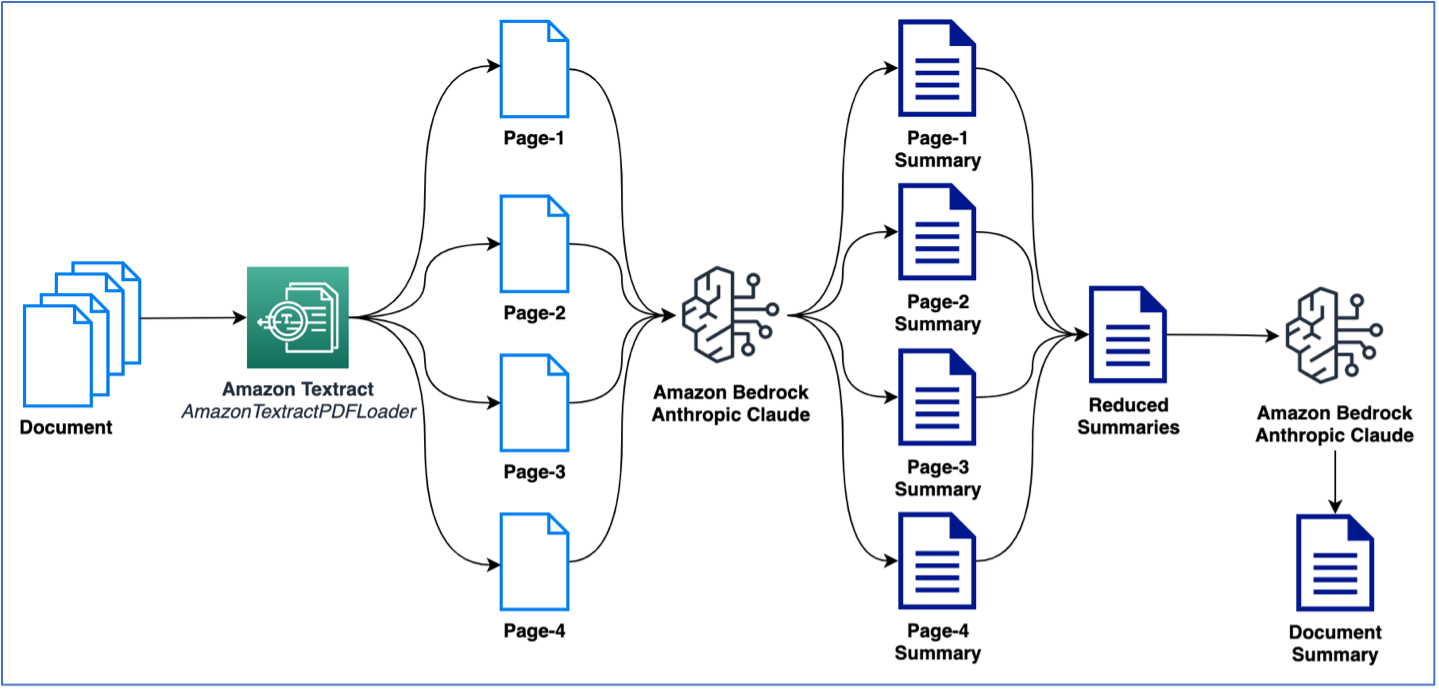
Să începem prin extragerea documentului și să vedem numărul total de simboluri pe pagină și numărul total de pagini:
În continuare, folosim sistemul încorporat LangChain load_summarize_chain pentru a rezuma întregul document:
from langchain.chains.summarize import load_summarize_chain summary_chain = load_summarize_chain(llm=bedrock_llm, chain_type='map_reduce')
output = summary_chain.run(document)
print(output.strip())Standardizare și întrebări și răspunsuri
În această secțiune, discutăm despre standardizare și sarcini de întrebări și răspunsuri.
Standardizare
Standardizarea ieșirii este o sarcină de generare de text în care LLM-urile sunt folosite pentru a oferi o formatare consecventă a textului de ieșire. Această sarcină este deosebit de utilă pentru automatizarea extragerii entităților cheie care necesită ca rezultatul să fie aliniat cu formatele dorite. De exemplu, putem urma cele mai bune practici de inginerie promptă pentru a regla fin un LLM pentru a formata datele în format LL/ZZ/AAAA, care poate fi compatibil cu o coloană DATE a bazei de date. Următorul bloc de cod arată un exemplu despre cum se face acest lucru folosind un LLM și inginerie promptă. Nu numai că standardizăm formatul de ieșire pentru valorile datei, dar solicităm și modelului să genereze rezultatul final într-un format JSON, astfel încât să fie ușor de consumat în aplicațiile noastre din aval. Folosim Limbajul de expresie LangChain (LCEL) a înlănțui două acțiuni. Prima acțiune solicită LLM să genereze o ieșire în format JSON doar cu datele din document. A doua acțiune preia ieșirea JSON și standardizează formatul datei. Rețineți că această acțiune în doi pași poate fi efectuată și într-un singur pas cu o inginerie promptă adecvată, așa cum vom vedea în normalizare și șabloane.
Ieșirea eșantionului de cod precedent este o structură JSON cu date 07/09/2020 și 08/09/2020, care sunt în formatul ZZ/LL/AAAA și sunt data de internare și respectiv externare a pacientului din spital, conform la raportul de sinteză de descărcare de gestiune.
Întrebări și răspunsuri cu Retrieval Augmented Generation
LLM-urile sunt cunoscute pentru a reține informații faptice, adesea denumite cunoștințele lor despre lume sau viziunea asupra lumii. Când sunt reglate fin, pot produce rezultate de ultimă generație. Cu toate acestea, există constrângeri în ceea ce privește cât de eficient un LLM poate accesa și manipula aceste cunoștințe. Ca urmare, în sarcinile care se bazează în mare măsură pe cunoștințe specifice, performanța lor ar putea să nu fie optimă pentru anumite cazuri de utilizare. De exemplu, în scenariile de întrebări și răspunsuri, este esențial ca modelul să respecte strict contextul furnizat în document, fără a se baza doar pe cunoștințele sale mondiale. Abaterea de la aceasta poate duce la denaturari, inexactități sau chiar răspunsuri incorecte. Metoda cea mai frecvent utilizată pentru a rezolva această problemă este cunoscută ca Recuperare Augmented Generation (CÂRPĂ). Această abordare sinergizează punctele forte atât ale modelelor de recuperare, cât și ale modelelor de limbaj, sporind precizia și calitatea răspunsurilor generate.
LLM-urile pot impune, de asemenea, limitări de simboluri din cauza constrângerilor lor de memorie și a limitărilor hardware-ului pe care rulează. Pentru a gestiona această problemă, tehnici precum chunking sunt folosite pentru a împărți documentele mari în porțiuni mai mici care se încadrează în limitele token-urilor LLM. Pe de altă parte, înglobările sunt folosite în NLP în primul rând pentru a surprinde semnificația semantică a cuvintelor și relațiile lor cu alte cuvinte într-un spațiu dimensional înalt. Aceste înglobări transformă cuvintele în vectori, permițând modelelor să proceseze și să înțeleagă eficient datele textuale. Prin înțelegerea nuanțelor semantice dintre cuvinte și expresii, înglobările permit LLM-urilor să genereze rezultate coerente și relevante din punct de vedere contextual. Rețineți următorii termeni cheie:
- chunking – Acest proces descompune cantități mari de text din documente în bucăți mai mici și semnificative de text.
- Încorporări – Acestea sunt transformări vectoriale cu dimensiuni fixe ale fiecărei bucăți care rețin informația semantică din bucăți. Aceste înglobări sunt ulterior încărcate într-o bază de date vectorială.
- Baza de date vectorială – Aceasta este o bază de date de înglobare de cuvinte sau vectori care reprezintă contextul cuvintelor. Acționează ca o sursă de cunoștințe care ajută sarcinile NLP în conductele de procesare a documentelor. Avantajul bazei de date vectoriale aici este că permite doar contextul necesar să fie furnizat LLM-urilor în timpul generării textului, așa cum explicăm în secțiunea următoare.
RAG folosește puterea înglobărilor pentru a înțelege și a prelua segmentele relevante de document în timpul fazei de recuperare. Procedând astfel, RAG poate funcționa în limitele token-urilor LLM, asigurându-se că cele mai relevante informații sunt selectate pentru generare, rezultând rezultate mai precise și mai relevante din punct de vedere contextual.
Următoarea diagramă ilustrează integrarea acestor tehnici pentru a crea contribuția la LLM, îmbunătățind înțelegerea contextuală a acestora și permițând răspunsuri mai relevante în context. O abordare implică căutarea de similaritate, utilizând atât o bază de date vectorială, cât și fragmentarea. Baza de date vectorială stochează înglobări reprezentând informații semantice, iar fragmentarea împarte textul în secțiuni gestionabile. Folosind acest context din căutarea de similaritate, LLM-urile pot rula sarcini precum răspunsul la întrebări și operațiuni specifice domeniului, cum ar fi clasificarea și îmbogățirea.

Pentru această postare, folosim o abordare bazată pe RAG pentru a efectua întrebări și răspunsuri în context cu documente. În următorul exemplu de cod, extragem text dintr-un document și apoi împărțim documentul în bucăți mai mici de text. Îmbunătățirea este necesară deoarece este posibil să avem documente mari cu mai multe pagini și LLM-urile noastre pot avea limite de simboluri. Aceste bucăți sunt apoi încărcate în baza de date vectorială pentru a efectua căutarea de similaritate în pașii următori. În exemplul următor, folosim modelul Amazon Titan Embed Text v1, care realizează încorporarea vectorială a fragmentelor de document:
Codul creează un context relevant pentru LLM folosind bucățile de text care sunt returnate de acțiunea de căutare a similarității din baza de date vectorială. Pentru acest exemplu, folosim o sursă deschisă Magazin de vectori FAISS ca o bază de date vectorială eșantion pentru a stoca înglobări vectoriale ale fiecărei bucăți de text. Apoi definim baza de date vectorială ca a LangChain retriever, care este trecut în RetrievalQA lanţ. Aceasta rulează intern o interogare de căutare de similaritate în baza de date vectorială care returnează primele n (unde n=3 în exemplul nostru) bucăți de text care sunt relevante pentru întrebare. În cele din urmă, lanțul LLM este rulat cu contextul relevant (un grup de bucăți relevante de text) și cu întrebarea la care să răspundă LLM. Pentru o prezentare pas cu pas a codului de întrebări și răspunsuri cu RAG, consultați blocnotesul Python de pe GitHub.
Ca alternativă la FAISS, puteți utiliza și Capacitățile bazei de date vectoriale Amazon OpenSearch Service, Amazon Relational Database Service (Amazon RDS) pentru PostgreSQL cu pgvector extensie ca baze de date vectoriale sau baza de date Chroma open-source.
Întrebări și răspunsuri cu date tabelare
Datele tabelare din documente pot fi dificil de prelucrat pentru LLM din cauza complexității sale structurale. Amazon Texttract poate fi mărit cu LLM-uri, deoarece permite extragerea tabelelor din documente într-un format imbricat de elemente, cum ar fi pagină, tabel și celule. Efectuarea întrebărilor și răspunsurilor cu date tabelare este un proces în mai mulți pași și poate fi realizat prin intermediul autointerogare. Mai jos este o prezentare generală a pașilor:
- Extrageți tabele din documente utilizând Amazon Texttract. Cu Amazon Texttract, structura tabulară (rânduri, coloane, anteturi) poate fi extrasă dintr-un document.
- Stocați datele tabulare într-o bază de date vectorială împreună cu informații despre metadate, cum ar fi numele antetului și descrierea fiecărui antet.
- Utilizați promptul pentru a construi o interogare structurată, folosind un LLM, pentru a obține datele din tabel.
- Utilizați interogarea pentru a extrage datele relevante din tabel din baza de date vectorială.
De exemplu, într-un extras de cont bancar, având în vedere mesajul „Care sunt tranzacțiile cu depozite mai mari de 1000 USD”, LLM va parcurge următorii pași:
- Creați o interogare, cum ar fi
“Query: transactions” , “filter: greater than (Deposit$)”. - Convertiți interogarea într-o interogare structurată.
- Aplicați interogarea structurată la baza de date vectorială în care sunt stocate datele din tabelul nostru.
Pentru o prezentare pas cu pas a unui exemplu de cod de întrebări și răspunsuri cu tabel, consultați blocnotesul Python în GitHub.
Șabloane și normalizări
În această secțiune, ne uităm la modul de utilizare a tehnicilor de inginerie prompte și a mecanismului încorporat LangChain pentru a genera o ieșire cu extrageri dintr-un document într-o schemă specificată. De asemenea, efectuăm o anumită standardizare a datelor extrase, folosind tehnicile discutate anterior. Începem prin a defini un șablon pentru rezultatul dorit. Aceasta va servi ca o schemă și va încapsula detaliile despre fiecare entitate pe care dorim să o extragem din textul documentului.
Rețineți că pentru fiecare dintre entități, folosim descrierea pentru a explica ce este acea entitate pentru a ajuta LLM să extragă valoarea din textul documentului. În următorul exemplu de cod, folosim acest șablon pentru a crea solicitarea noastră pentru LLM împreună cu textul extras din document folosind AmazonTextractPDFLoader și ulterior efectuați inferența cu modelul:
Dupa cum se poate vedea, {keys} o parte a promptului sunt cheile din șablonul nostru și {details} sunt cheile împreună cu descrierea lor. În acest caz, nu solicităm modelului în mod explicit formatul de ieșire, în afară de specificarea în instrucțiune pentru a genera ieșirea în format JSON. Acest lucru funcționează în cea mai mare parte; totuși, deoarece rezultatul din LLM este generarea de text nedeterministă, dorim să specificăm formatul în mod explicit ca parte a instrucțiunii din prompt. Pentru a rezolva acest lucru, putem folosi LangChain analizator structurat de ieșire modul pentru a profita de inginerie automată de promptare care ajută la convertirea șablonului nostru într-un prompt de instrucțiuni de format. Folosim șablonul definit mai devreme pentru a genera promptul de instrucțiuni de format, după cum urmează:
Apoi folosim această variabilă în promptul nostru original ca instrucțiune pentru LLM, astfel încât să extragă și să formateze rezultatul în schema dorită, făcând o mică modificare la promptul nostru:
Până acum, am extras doar datele din document într-o schemă dorită. Cu toate acestea, mai trebuie să realizăm o anumită standardizare. De exemplu, dorim ca data admiterii pacientului și data externarii să fie extrase în format ZZ/LL/AAAA. În acest caz, creștem description a tastei cu instrucțiunile de formatare:
Consultați caietul Python în GitHub pentru o prezentare completă pas cu pas și o explicație.
Verificări și corecții ortografice
LLM-urile au demonstrat abilități remarcabile în înțelegerea și generarea de text asemănător omului. Una dintre aplicațiile mai puțin discutate, dar extrem de utile ale LLM-urilor este potențialul lor în verificările gramaticale și corectarea propozițiilor în documente. Spre deosebire de verificatoarele gramaticale tradiționale care se bazează pe un set de reguli predefinite, LLM-urile folosesc modele pe care le-au identificat din cantități mari de date text pentru a determina ce înseamnă limbaj corect sau fluent. Aceasta înseamnă că pot detecta nuanțe, context și subtilități pe care sistemele bazate pe reguli le-ar putea pierde.
Imaginați-vă textul extras dintr-un rezumat al externarii pacientului care spune „Pacientul Jon Doe, care a fost internat cu pneumonie severă, a prezentat o îmbunătățire semnificativă și poate fi externat în siguranță. Urmăriri sunt programate pentru săptămâna viitoare.” Un verificator ortografic tradițional ar putea recunoaște „admittd”, „pneumonie”, „îmbunătățire” și „nex” drept erori. Cu toate acestea, contextul acestor erori ar putea duce la noi greșeli sau sugestii generice. Un LLM, dotat cu pregătirea sa extinsă, ar putea sugera: „Pacientul John Doe, care a fost internat cu pneumonie severă, a prezentat o îmbunătățire semnificativă și poate fi externat în siguranță. Urmăriri sunt programate pentru săptămâna viitoare.”
Următorul este un exemplu de document scris de mână cu același text ca explicat anterior.

Extragem documentul cu un încărcător de documente Amazon Texttract și apoi instruim LLM, prin inginerie promptă, să rectifice textul extras pentru a corecta orice greșeli de ortografie și/sau gramaticale:
Ieșirea codului precedent arată textul original extras de încărcătorul de documente, urmat de textul corectat generat de LLM:
Țineți minte că, oricât de puternice sunt LLM-urile, este esențial să vedeți sugestiile lor ca doar atât - sugestii. Deși surprind impresionant de bine complexitățile limbajului, nu sunt infailibili. Unele sugestii ar putea schimba sensul sau tonul dorit al textului original. Prin urmare, este esențial ca recenzenții umani să folosească corecțiile generate de LLM ca ghid, nu absolut. Colaborarea intuiției umane cu capacitățile LLM promite un viitor în care comunicarea noastră scrisă nu este doar lipsită de erori, ci și mai bogată și mai nuanțată.
Concluzie
Inteligența artificială generativă schimbă modul în care puteți procesa documentele cu IDP pentru a obține informații. În postare Îmbunătățirea procesării inteligente a documentelor AWS cu inteligență artificială generativă, am discutat despre diferitele etape ale conductei și despre modul în care clientul AWS Ricoh își îmbunătățește conducta IDP cu LLM-uri. În această postare, am discutat despre diferite mecanisme de creștere a fluxului de lucru IDP cu LLM-uri prin Amazon Bedrock, Amazon Texttract și popularul cadru LangChain. Puteți începe cu noul încărcător de documente Amazon Texttract cu LangChain astăzi, folosind exemplele de caiete disponibile în GitHub depozit. Pentru mai multe informații despre lucrul cu AI generativă pe AWS, consultați Anunțăm noi instrumente pentru construirea cu IA generativă pe AWS.
Despre Autori
 Sonali Sahu conduce procesarea inteligentă a documentelor cu echipa de servicii AI/ML din AWS. Ea este autoare, lider de gândire și tehnolog pasionat. Domeniul ei de interes principal este AI și ML și vorbește frecvent la conferințe și întâlniri AI și ML din întreaga lume. Ea are atât o experiență vastă, cât și profundă în tehnologie și industria tehnologiei, cu expertiză în industrie în domeniul sănătății, sectorul financiar și asigurări.
Sonali Sahu conduce procesarea inteligentă a documentelor cu echipa de servicii AI/ML din AWS. Ea este autoare, lider de gândire și tehnolog pasionat. Domeniul ei de interes principal este AI și ML și vorbește frecvent la conferințe și întâlniri AI și ML din întreaga lume. Ea are atât o experiență vastă, cât și profundă în tehnologie și industria tehnologiei, cu expertiză în industrie în domeniul sănătății, sectorul financiar și asigurări.
 Anjan Biswas este un arhitect senior de soluții de servicii AI, cu accent pe AI/ML și Data Analytics. Anjan face parte din echipa de servicii AI la nivel mondial și lucrează cu clienții pentru a-i ajuta să înțeleagă și să dezvolte soluții la problemele de afaceri cu AI și ML. Anjan are peste 14 ani de experiență de lucru cu lanțul global de aprovizionare, producție și organizații de vânzare cu amănuntul și ajută în mod activ clienții să înceapă și să se extindă pe serviciile AWS AI.
Anjan Biswas este un arhitect senior de soluții de servicii AI, cu accent pe AI/ML și Data Analytics. Anjan face parte din echipa de servicii AI la nivel mondial și lucrează cu clienții pentru a-i ajuta să înțeleagă și să dezvolte soluții la problemele de afaceri cu AI și ML. Anjan are peste 14 ani de experiență de lucru cu lanțul global de aprovizionare, producție și organizații de vânzare cu amănuntul și ajută în mod activ clienții să înceapă și să se extindă pe serviciile AWS AI.
 Chinmayee Rane este arhitect specializat în soluții AI/ML la Amazon Web Services. Este pasionată de matematică aplicată și învățare automată. Ea se concentrează pe proiectarea de soluții inteligente de procesare a documentelor și AI generativă pentru clienții AWS. În afara serviciului, îi place dansul salsa și bachata.
Chinmayee Rane este arhitect specializat în soluții AI/ML la Amazon Web Services. Este pasionată de matematică aplicată și învățare automată. Ea se concentrează pe proiectarea de soluții inteligente de procesare a documentelor și AI generativă pentru clienții AWS. În afara serviciului, îi place dansul salsa și bachata.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/intelligent-document-processing-with-amazon-textract-amazon-bedrock-and-langchain/
- :are
- :este
- :nu
- :Unde
- .anex
- $1000
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 14
- 15%
- 16
- 22
- 23
- 33
- 35%
- 7
- 9
- a
- abilități
- Despre Noi
- Absolut
- acces
- accesate
- Conform
- precizie
- precis
- realizat
- peste
- Acțiune
- acțiuni
- activ
- activitate
- Acte
- Ad
- adresa
- Adaugă
- adera
- admite
- admise
- progresele
- Avantaj
- venire
- vârstă
- agenţi
- AI
- Servicii AI
- AI / ML
- aliniat
- TOATE
- Permiterea
- permite
- de-a lungul
- de asemenea
- alternativă
- Cu toate ca
- Amazon
- Amazon Comprehend
- Amazon RDS
- Text Amazon
- Amazon Web Services
- Sume
- an
- Google Analytics
- analiza
- și
- răspunde
- Antropică
- antibiotice
- Orice
- API-uri
- aplicatii
- aplicat
- numiri
- abordare
- arhitectură
- SUNT
- ZONĂ
- în jurul
- Artă
- artificial
- inteligență artificială
- Inteligența artificială (AI)
- AS
- aspect
- ajuta
- Asistent
- At
- spori
- augmented
- autor
- automatizarea
- Automata
- în mod automat
- Automatizare
- disponibil
- gradului de conştientizare
- AWS
- Client AWS
- Bancă
- BE
- deoarece
- devine
- fost
- înainte
- benefică
- beneficia
- CEL MAI BUN
- Cele mai bune practici
- între
- Bloca
- Blocuri
- atât
- lăţime
- Pauză
- pauze
- construi
- Clădire
- construit-in
- afaceri
- întreprinderi
- dar
- by
- apeluri
- CAN
- Poate obține
- capacități
- captura
- caz
- cazuri
- Celule
- sigur
- lanţ
- lanţuri
- contesta
- provocare
- Schimbare
- Modificări
- schimbarea
- Verificări
- alegere
- creanțe
- clasă
- clase
- clasificare
- Clasifica
- cod
- COERENT
- colaborare
- Coloană
- Coloane
- combinaţie
- combina
- vine
- Comun
- în mod obișnuit
- Comunicare
- compatibil
- Completă
- complex
- complexitate
- înţelege
- concis
- conferințe
- Conectarea
- consistent
- constă
- constrângeri
- construi
- conţine
- conținute
- conține
- conţinut
- context
- contextual
- converti
- Nucleu
- corecta
- corectat
- Corectarea
- ar putea
- ambarcaţiunilor
- fabricat
- creează
- crucial
- personalizat
- client
- clienţii care
- Dans
- de date
- Analiza datelor
- Baza de date
- baze de date
- Data
- Date
- afacere
- adânc
- Mai adânc
- defini
- definit
- definire
- demonstrat
- În funcție
- depozite
- adâncime
- descris
- descriere
- proiect
- dorit
- detaliu
- detaliat
- detalii
- detecta
- Determina
- dezvolta
- Dezvoltatorii
- Dietă
- diferit
- direct
- discuta
- discutat
- scufunda
- împărţi
- diviziunilor
- do
- Doctor
- document
- documentaţie
- documente
- CĂPRIOARĂ
- Nu
- face
- don
- făcut
- Dont
- jos
- dramatic
- două
- în timpul
- dinamic
- e
- fiecare
- Mai devreme
- cu ușurință
- ușor de folosit
- în mod eficient
- eficiență
- eficient
- eficient
- Eforturile
- oricare
- element
- încastra
- angajat
- imputerniceste
- permite
- permite
- permițând
- capăt
- Inginerie
- spori
- sporită
- consolidarea
- asigura
- asigurare
- Întreg
- entități
- entitate
- echipat
- Erori
- esenţial
- Eter (ETH)
- Chiar
- exemplu
- Cu excepția
- excepție
- existent
- experienţă
- expertiză
- Explica
- a explicat
- explică
- explicație
- explicit
- expresie
- extinde
- extensie
- extensiv
- extrage
- extracţie
- extracte
- faptic
- Cădea
- fals
- departe
- oboseală
- Domenii
- Figura
- final
- În cele din urmă
- financiar
- Sector Financial
- First
- potrivi
- Concentra
- se concentrează
- urma
- a urmat
- următor
- urmează
- Pentru
- format
- formulare
- găsit
- Fundație
- Cadru
- Gratuit
- frecvent
- din
- Frontieră
- Complet
- complet
- mai mult
- viitor
- General
- genera
- generată
- generează
- generator
- generaţie
- generativ
- AI generativă
- obține
- Da
- dat
- Caritate
- Gramatică
- înţelege
- mai mare
- grup
- ghida
- mână
- manipula
- întâmpla
- lucru
- Piese metalice
- Avea
- anteturile
- de asistență medicală
- puternic
- ajutor
- util
- ajutor
- ajută
- ei
- aici
- la nivel înalt
- performanta inalta
- superior
- deține
- Spital
- Cum
- Cum Pentru a
- Totuși
- HTML
- HTTPS
- uman
- i
- ID
- identificat
- if
- ilustrează
- imagine
- imens
- Impactul
- import
- important
- importatoare
- a impune
- îmbunătățire
- in
- Inclusiv
- index
- industrie
- informații
- Informații despre vârstă
- Inovaţie
- intrare
- perspective
- instanță
- instrucțiuni
- asigurare
- integra
- integrate
- integrarea
- integrare
- Inteligență
- Inteligent
- Procesarea inteligentă a documentelor
- destinate
- intern
- în
- complexități
- introduce
- introdus
- Prezintă
- intuiţie
- implică
- IT
- ESTE
- Jackson
- Ioan
- JOHN DOE
- jon
- jpg
- JSON
- doar
- Cheie
- chei
- Cunoaște
- cunoştinţe
- cunoscut
- limbă
- mare
- Aspect
- conduce
- lider
- conducere
- învăţare
- lăsând
- Bibliotecă
- ca
- Probabil
- limitări
- Limitele
- Listă
- încărca
- încărcător
- logică
- Uite
- Lot
- maşină
- masina de învățare
- Efectuarea
- administra
- gestionate
- de conducere
- manual
- de fabricaţie
- marcat
- matematică
- Mai..
- me
- sens
- semnificativ
- mijloace
- mecanism
- mecanisme
- meetups
- Memorie
- meta
- Metadata
- metodă
- Metode
- ar putea
- minte
- rata
- greşeli
- ML
- model
- Modele
- modul
- mai mult
- ipoteci
- cele mai multe
- multiplu
- nume
- nume
- Natural
- Limbajul natural
- Procesarea limbajului natural
- Înțelegerea limbajului natural
- necesar
- Nevoie
- necesar
- nevoilor
- Nou
- următor
- saptamana viitoare
- nlp
- nota
- caiet
- notebook-uri
- acum
- umbrire
- număr
- obiect
- obiecte
- of
- promoții
- de multe ori
- on
- ONE
- afară
- open-source
- Operațiuni
- Oportunitate
- optimă
- Opţiuni
- or
- organizații
- original
- Altele
- in caz contrar
- al nostru
- afară
- Rezultat
- producție
- iesiri
- exterior
- peste
- Prezentare generală
- ofertele
- pagină
- pagini
- Durere
- împerecheat
- perechi
- parte
- în special
- trece
- Trecut
- Care trece
- pasionat
- cale
- pacient
- Model
- modele
- pentru
- efectua
- performanță
- efectuată
- efectuarea
- efectuează
- fază
- PhD
- Expresii
- conducte
- plan
- Plato
- Informații despre date Platon
- PlatoData
- "vă rog"
- pneumonie
- puncte
- Popular
- posibil
- Post
- potenţial
- putere
- alimentat
- puternic
- practicile
- tocmai
- Precizie
- preferat
- prezenta
- în prealabil
- în primul rând
- printuri
- Problemă
- probleme
- proces
- prelucrate
- prelucrare
- produce
- Promisiuni
- adecvat
- furniza
- prevăzut
- furnizorul
- furnizează
- Piton
- Q & A
- calitate
- întrebare
- Rapid
- repede
- Crud
- Citind
- recunoaște
- reducerea
- trimite
- referință
- menționat
- Relaţii
- se bazează
- bazându-se
- remarcabil
- raportează
- reprezenta
- reprezentând
- necesar
- Necesită
- respectiv
- răspunsuri
- restricții
- rezultat
- rezultând
- REZULTATE
- cu amănuntul
- reține
- reținere
- Returnează
- Bogat
- Cameră
- norme
- Alerga
- ruleaza
- s
- în siguranță
- acelaşi
- Spune
- Scară
- scenarii
- programată
- Caută
- Al doilea
- Secțiune
- secțiuni
- sector
- vedea
- segmente
- selectate
- senior
- propoziție
- serie
- servi
- servește
- serviciu
- Servicii
- set
- sever
- ea
- Pantaloni scurți
- să
- indicat
- Emisiuni
- semnificativ
- singur
- mic
- mai mici
- fragment
- So
- Numai
- soluţii
- REZOLVAREA
- unele
- Sursă
- Spaţiu
- vorbeşte
- specialist
- specific
- specific
- specificată
- ortografie
- împărţi
- Stadiile
- standardizare
- Începe
- început
- de ultimă oră
- Declarație
- Pas
- paşi
- Încă
- stoca
- stocate
- magazine
- puncte forte
- Şir
- structural
- structura
- structurat
- Lupta
- ulterior
- Ulterior
- astfel de
- sugera
- rezuma
- REZUMAT
- livra
- lanțului de aprovizionare
- a sustine
- Sprijină
- sinergie
- sisteme
- T
- tabel
- Lua
- ia
- Sarcină
- sarcini
- echipă
- tehnică
- tehnici de
- tehnolog
- Tehnologia
- șablon
- termeni
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- generarea textului
- textual
- decât
- acea
- lumea
- lor
- Lor
- apoi
- Acolo.
- prin urmare
- Acestea
- ei
- acest
- gândit
- trei
- Prin
- gigant
- la
- astăzi
- azi
- împreună
- semn
- indicativele
- TONE
- Unelte
- top
- Total
- tradiţional
- Pregătire
- Tranzacții
- Transforma
- transformări
- adevărat
- încerca
- Două
- tip
- Tipuri
- înţelege
- înţelegere
- spre deosebire de
- dezvelire
- URL-ul
- utilizare
- carcasa de utilizare
- utilizat
- utilizatorii
- utilizări
- folosind
- utilizate
- Utilizand
- v1
- valoare
- Valori
- variabil
- diverse
- Fixă
- multilateral
- versiune
- de
- Vizualizare
- volume
- walkthrough
- vrea
- a fost
- Cale..
- we
- web
- servicii web
- săptămână
- BINE
- Ce
- cand
- care
- în timp ce
- OMS
- voi
- cu
- în
- fără
- asistat
- Cuvânt
- cuvinte
- Apartamente
- flux de lucru
- fluxuri de lucru
- de lucru
- fabrică
- lume
- ar
- scris
- X
- ani
- tu
- zephyrnet