Serviciul Amazon OpenSearch recent introdus Multi-AZ cu Standby, o opțiune de implementare concepută pentru a oferi companiilor o disponibilitate îmbunătățită și o performanță constantă pentru sarcinile de lucru critice. Cu această caracteristică, clusterele gestionate pot atinge o disponibilitate de 99.99%, rămânând în același timp rezistente la defecțiunile infrastructurii zonale.
În această postare, explorăm modul în care funcționează căutarea și indexarea cu Multi-AZ cu Standby și analizăm mecanismele de bază care contribuie la fiabilitatea, simplitatea și toleranța la erori.
Context
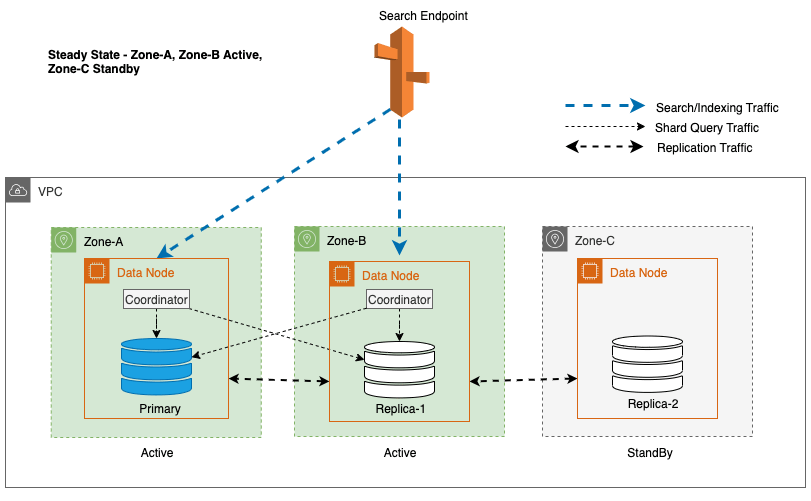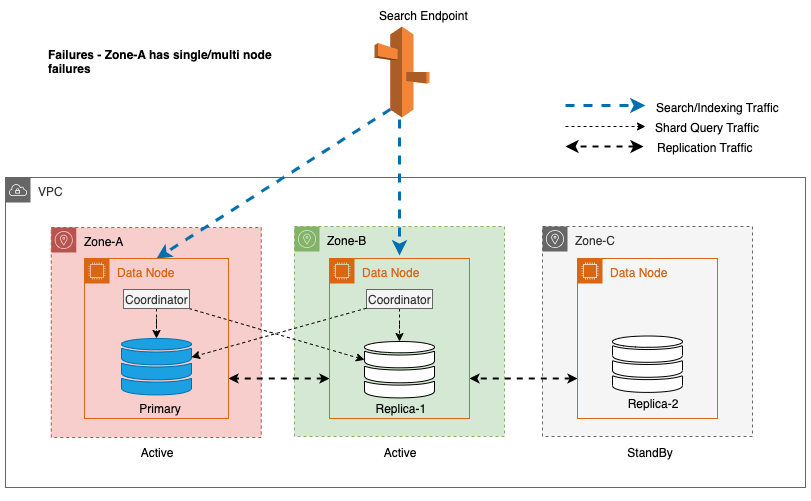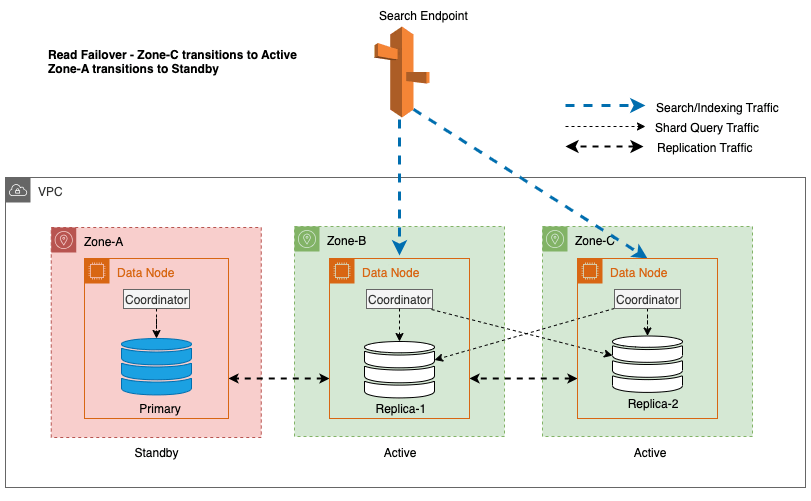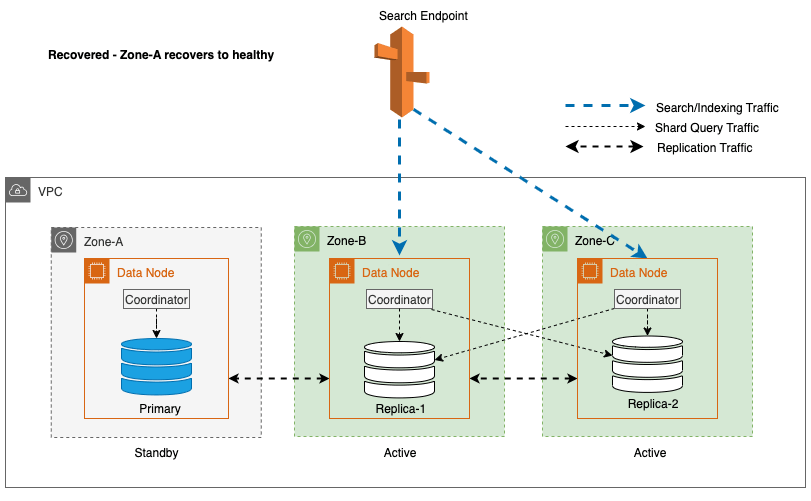
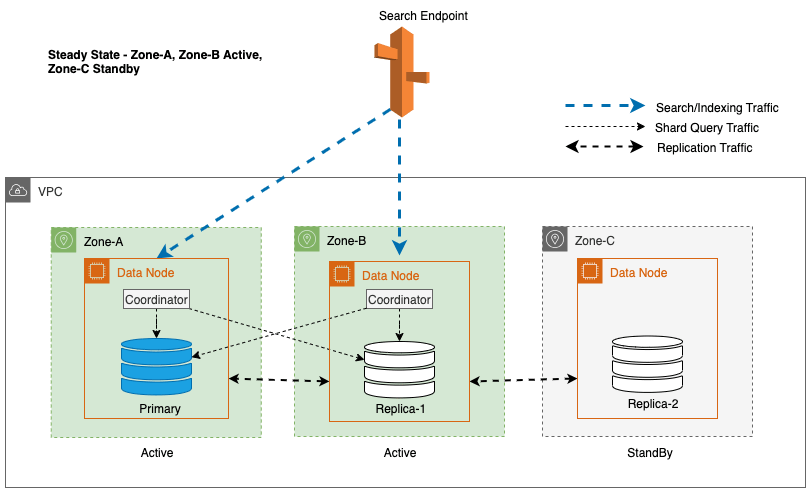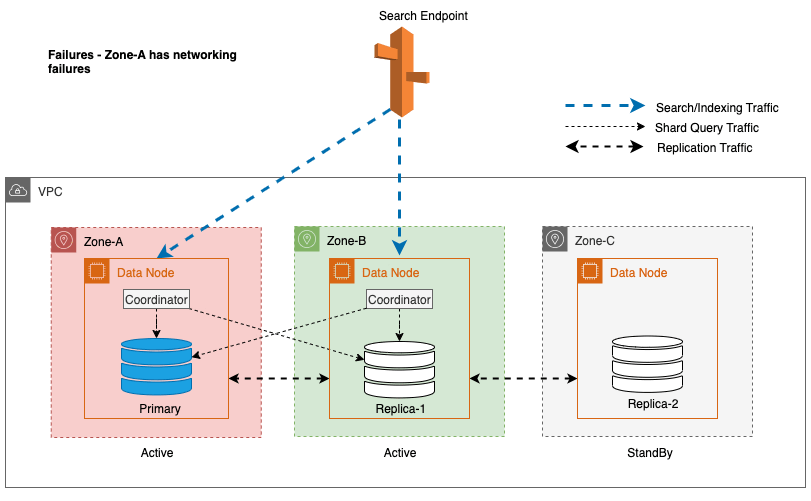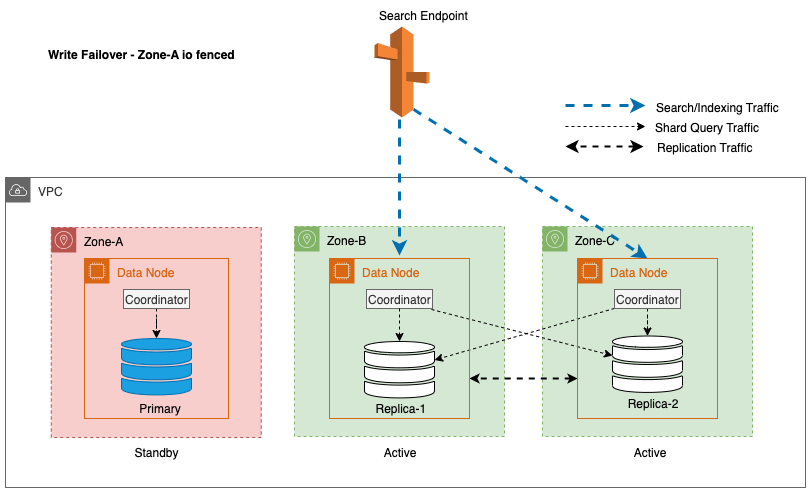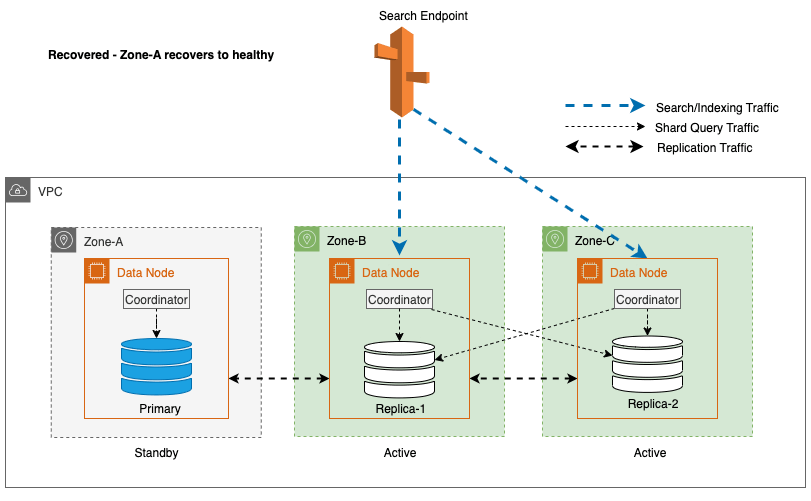
Multi-AZ cu Standby implementează instanțe de domeniu OpenSearch Service în trei Zone de Disponibilitate, cu două zone desemnate ca active și una ca standby. Această configurație asigură performanțe consistente, chiar și în cazul defecțiunilor zonale, prin menținerea aceleiași capacități în toate zonele. Important este că această zonă de așteptare urmează a design stabil static, eliminând nevoia de furnizare a capacității sau de mișcare a datelor în timpul defecțiunilor.
În timpul operațiunilor obișnuite, zona activă gestionează traficul coordonatorului atât pentru solicitările de citire, cât și de scriere, precum și pentru traficul de interogări shard. Zona de așteptare, pe de altă parte, primește doar trafic de replicare. OpenSearch Service utilizează un protocol de replicare sincron pentru cererile de scriere. Acest lucru permite serviciului să promoveze cu promptitudine o zonă de așteptare la starea activă în cazul unei defecțiuni (timpul mediu până la failover <= 1 minut), cunoscut sub numele de failover zonal. Zona activă anterior este apoi retrogradată în modul de așteptare, iar operațiunile de recuperare încep pentru a-și restabili starea sănătoasă.
Căutați rutarea traficului și failover-ul pentru a garanta disponibilitate ridicată
Într-un domeniu OpenSearch Service, a coordonator este orice nod care gestionează solicitările HTTP(S), în special cererile de indexare și căutare. Într-un domeniu Multi-AZ cu Standby, nodurile de date din zona activă acționează ca coordonatori pentru cererile de căutare.
În timpul fazei de interogare a unei cereri de căutare, coordonatorul determină fragmentele care urmează să fie interogate și trimite o solicitare nodului de date care găzduiește copia fragmentului. Interogarea este rulată local pe fiecare fragment și documentele potrivite sunt returnate la nodul coordonator. Nodul coordonator, care este responsabil pentru trimiterea cererii către nodurile care conțin copii shard, rulează procesul în doi pași. În primul rând, creează un iterator care definește ordinea în care nodurile trebuie să fie interogate pentru o copie shard, astfel încât traficul să fie distribuit uniform între copiile shard. Ulterior, cererea este trimisă la nodurile relevante.
Pentru a crea o listă ordonată de noduri pentru a fi interogate pentru o copie shard, nodul coordonator utilizează diverși algoritmi. Acești algoritmi includ selecția round-robin, selecția adaptivă a replicilor, rutarea fragmentelor bazată pe preferințe și round-robin ponderat.
Pentru Multi-AZ cu Standby, algoritmul ponderat round-robin este utilizat pentru selectarea copiei fragmente. În această abordare, zonelor active li se atribuie o pondere de 1, iar zonei de așteptare i se atribuie o pondere de 0. Acest lucru asigură că niciun trafic de citire nu este trimis către nodurile de date din Zona de disponibilitate de așteptare.
Greutățile sunt stocate în metadatele stării clusterului ca obiect JSON:
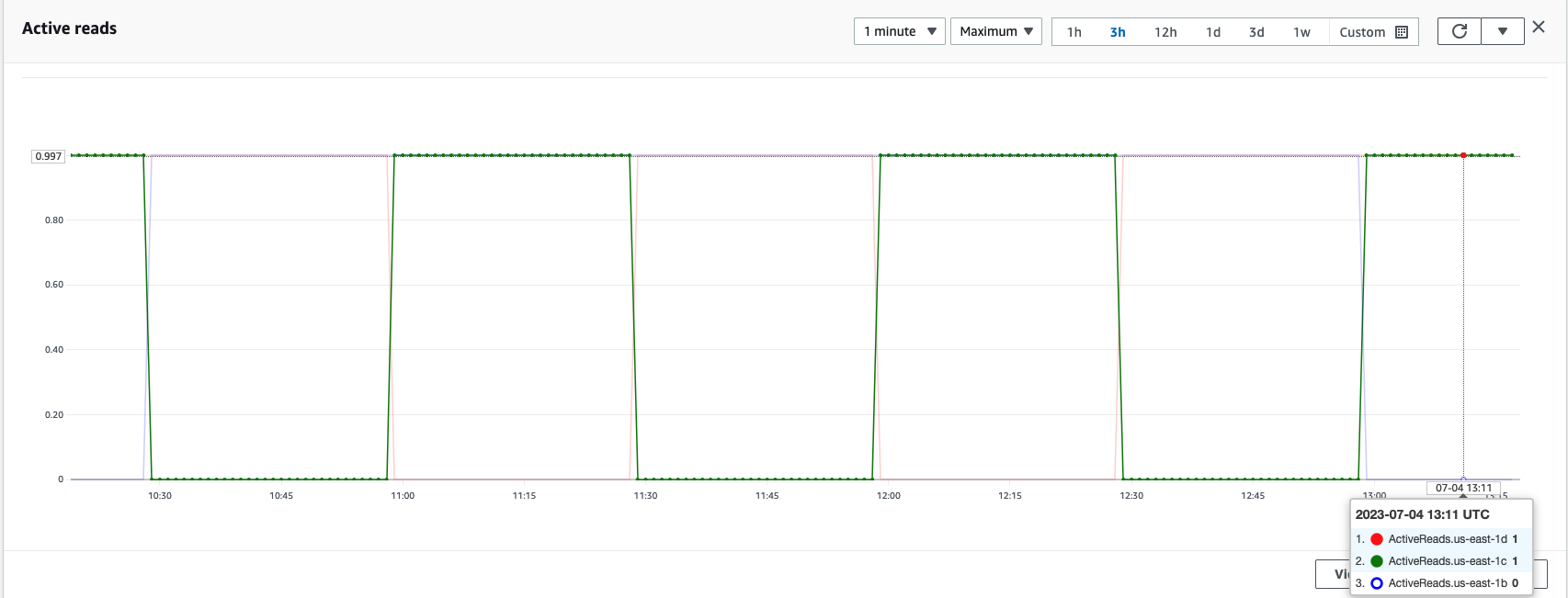
După cum se arată în următoarea captură de ecran, us-east-1b Regiunea are statutul de zonă ca StandBy, indicând faptul că nodurile de date din această zonă de disponibilitate sunt în stare de așteptare și nu primesc solicitări de căutare sau de indexare de la echilibratorul de încărcare.

Pentru a menține operațiunile la starea de echilibru, zona de disponibilitate de așteptare este rotită la fiecare 30 de minute, asigurându-se că toate părțile rețelei sunt acoperite în zonele de disponibilitate. Această abordare proactivă verifică disponibilitatea căilor de citire, sporind și mai mult rezistența sistemului în timpul potențialelor defecțiuni. Următoarea diagramă ilustrează această arhitectură.
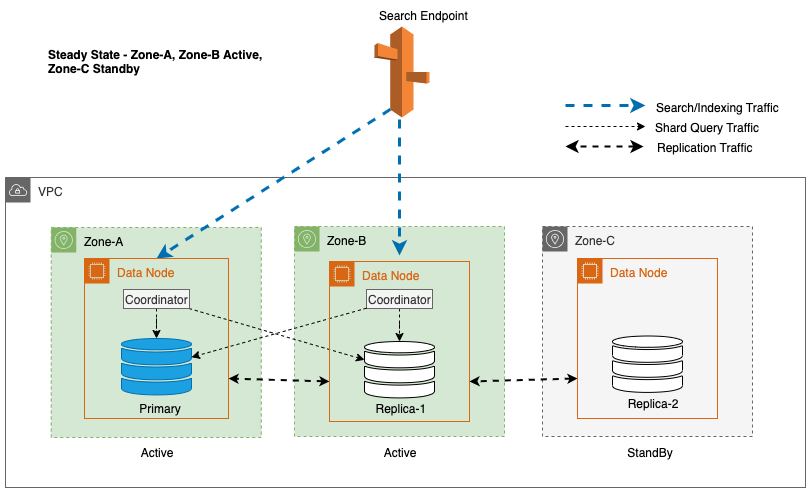
În diagrama precedentă, Zona-C are o greutate ponderată round-robin setată la zero. Acest lucru asigură că nodurile de date din zona de așteptare nu primesc niciun trafic de indexare sau de căutare. Când coordonatorul interogează nodurile de date pentru copii shard, folosește o greutate round-robin ponderată pentru a decide ordinea în care nodurile vor fi interogate. Deoarece greutatea este zero pentru Zona de Disponibilitate de așteptare, solicitările coordonatorului nu sunt trimise.
Într-un cluster OpenSearch Service, zonele active și de așteptare pot fi verificate în orice moment utilizând valorile de rotație a zonei de disponibilitate, așa cum se arată în următoarea captură de ecran.
În timpul întreruperilor zonale, zona de disponibilitate de așteptare comută fără probleme în modul de deschidere eșuată pentru solicitările de căutare. Aceasta înseamnă că traficul de interogări shard este direcționat către toate zonele de disponibilitate, chiar și către cele din standby, atunci când o copie shard nu este disponibilă în zona de disponibilitate activă. Această abordare care nu poate fi deschisă protejează cererile de căutare de întreruperi în timpul defecțiunilor, asigurând un serviciu continuu. Următoarea diagramă ilustrează această arhitectură.
În diagrama precedentă, în timpul stării de echilibru, traficul de interogare shard este trimis către nodul de date din Zonele de Disponibilitate active (Zona-A și Zona-B). Din cauza defecțiunilor nodurilor din Zona-A, zona de disponibilitate de așteptare (Zona-C) nu se deschide pentru a prelua traficul de interogări shard, astfel încât să nu aibă niciun impact asupra solicitărilor de căutare. În cele din urmă, Zona-A este detectată ca nesănătoasă, iar reluarea la citire comută starea de așteptare la Zona-A.
Modul în care failover-ul asigură disponibilitate ridicată în timpul deficienței de scriere
Modelul de replicare OpenSearch Service urmează un model de backup primar, caracterizat prin natura sa sincronă, în care este necesară confirmarea de la toate copiile fragmente înainte ca o solicitare de scriere să poată fi confirmată utilizatorului. Un dezavantaj notabil al acestui model de replicare este susceptibilitatea acestuia la încetiniri în cazul oricărei deteriorări în calea de scriere. Aceste sisteme se bazează pe un nod lider activ pentru a identifica defecțiunile sau întârzierile și apoi difuzează aceste informații către toate nodurile. Durata necesară pentru a detecta aceste probleme (timpul mediu de detectare) și ulterior rezolvarea acestora (timpul mediu de reparare) determină în mare măsură cât timp va funcționa sistemul într-o stare defectuoasă. În plus, orice eveniment de rețea care afectează comunicațiile între zone poate împiedica în mod semnificativ cererile de scriere datorită naturii sincrone a replicării.
Serviciul OpenSearch utilizează un protocol intern de comunicare nod la nod pentru replicarea traficului de scriere și coordonarea actualizărilor metadatelor prin intermediul unui lider ales. În consecință, punerea în standby a zonei care se confruntă cu stres nu ar rezolva în mod eficient problema deficienței de scriere.
Transferarea la scriere zonală: întreruperea traficului de replicare între zone
Pentru Multi-AZ cu Standby, pentru a atenua potențialele probleme de performanță cauzate în timpul evenimentelor neprevăzute, cum ar fi eșecurile zonale și evenimentele de rețea, transferarea la scriere zonală este o abordare eficientă. Această abordare implică eliminarea grațioasă a nodurilor din zona afectată din cluster, întrerupând efectiv traficul de intrare și ieșire între zone. Prin întreruperea traficului de replicare inter-zonă, impactul defecțiunilor zonale poate fi conținut în zona afectată. Acest lucru oferă clienților o experiență mai previzibilă și asigură că sistemul continuă să funcționeze în mod fiabil.
Eșec la scriere grațioasă
Orchestrarea unui failover de scriere în cadrul Serviciului OpenSearch este realizată de nodul lider ales printr-un mecanism bine definit. Acest mecanism implică un protocol de consens pentru publicarea stării clusterului, asigurând acordul unanim între toate nodurile pentru a desemna o singură zonă (în orice moment) pentru dezafectare. Este important că metadatele legate de zona afectată sunt replicate în toate nodurile pentru a asigura persistența acesteia, chiar și în timpul unei reporniri complete în cazul unei întreruperi.
În plus, nodul lider asigură o tranziție lină și grațioasă prin plasarea inițială a nodurilor din zonele afectate în standby pentru o durată de 5 minute înainte de a iniția gardul I/O. Această abordare deliberată împiedică orice trafic de coordonator nou sau trafic de interogare shard să fie direcționat către nodurile din zona afectată. Acest lucru, la rândul său, le permite acestor noduri să-și îndeplinească sarcinile în desfășurare cu grație și să gestioneze treptat orice solicitare în zbor înainte de a fi scoase din funcțiune. Următoarea diagramă ilustrează această arhitectură.
În procesul de implementare a unui failover de scriere pentru un nod lider, OpenSearch Service urmează acești pași cheie:
- Abdicarea liderului – Dacă nodul lider se întâmplă să fie situat într-o zonă programată pentru trecerea la scriere a erorilor, sistemul asigură că nodul lider renunță voluntar din rolul său de conducere. Această abdicare se realizează într-o manieră controlată, iar întregul proces este predat altui nod eligibil, care se ocupă apoi de acțiunile necesare.
- Preveniți realegerea liderului care urmează să fie dezafectat – Pentru a preveni realegerea unui lider dintr-o zonă marcată pentru trecerea la scriere, atunci când nodul lider eligibil inițiază acțiunea de transfer în scriere, ia măsuri pentru a se asigura că nodurile lider care urmează să fie dezafectate nu participă la alte alegeri. Acest lucru se realizează prin excluderea nodului lider care urmează să fie dezafectat din configurația de vot, împiedicându-l efectiv să voteze în orice fază critică a funcționării clusterului.
Metadatele legate de zona de failover de scriere sunt stocate în starea clusterului, iar aceste informații sunt publicate la toate nodurile din clusterul distribuit OpenSearch Service, după cum urmează:
Următoarea captură de ecran ilustrează faptul că, în timpul unei încetiniri a rețelei într-o zonă, trecerea la scriere a erorilor ajută la recuperarea disponibilității.
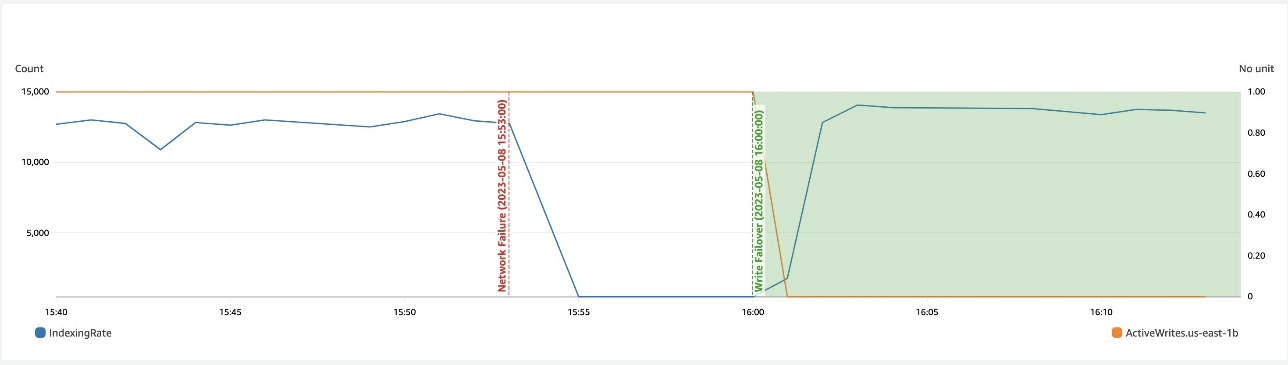
Recuperare zonală după failover-ul de scriere
Procesul de repunere în funcțiune zonală joacă un rol esențial în faza de recuperare în urma unui failover de scriere zonală. După ce zona afectată a fost restaurată și este considerată stabilă, nodurile care au fost dezafectate anterior se vor alătura clusterului. Această repunere în funcțiune are loc de obicei într-un interval de timp de 2 minute după ce zona a fost repunerea în funcțiune.
Acest lucru le permite să se sincronizeze cu nodurile lor egale și inițiază procesul de recuperare pentru fragmentele replica, restabilind eficient clusterul la starea dorită.
Concluzie
Introducerea Serviciului OpenSearch Multi-AZ cu Standby oferă companiilor o soluție puternică pentru a obține o disponibilitate ridicată și o performanță constantă pentru sarcinile de lucru critice. Cu această opțiune de implementare, companiile își pot îmbunătăți reziliența infrastructurii, pot simplifica configurarea și gestionarea clusterului și pot aplica cele mai bune practici. Cu funcții cum ar fi selecția ponderată a exemplarelor round-robin, mecanisme proactive de failover și zone de disponibilitate în așteptare cu deschidere eșuată, OpenSearch Service Multi-AZ cu standby asigură o experiență de căutare fiabilă și eficientă pentru mediile de întreprindere solicitante.
Pentru mai multe informații despre Multi-AZ cu Standby, consultați Serviciul Amazon OpenSearch Under the Hood: Multi-AZ cu standby.
Despre autor
 Anshu Agarwal este un inginer software senior care lucrează pe AWS OpenSearch la Amazon Web Services. Este pasionată de rezolvarea problemelor legate de construirea de sisteme scalabile și foarte fiabile.
Anshu Agarwal este un inginer software senior care lucrează pe AWS OpenSearch la Amazon Web Services. Este pasionată de rezolvarea problemelor legate de construirea de sisteme scalabile și foarte fiabile.
 Rishab Nahata este un inginer software care lucrează la OpenSearch la Amazon Web Services. Este fascinat de rezolvarea problemelor din sistemele distribuite. El este un colaborator activ la OpenSearch.
Rishab Nahata este un inginer software care lucrează la OpenSearch la Amazon Web Services. Este fascinat de rezolvarea problemelor din sistemele distribuite. El este un colaborator activ la OpenSearch.
 Bukhtawar Khan este inginer principal care lucrează pe Amazon OpenSearch Service. Este interesat de sistemele distribuite și autonome. El este un colaborator activ la OpenSearch.
Bukhtawar Khan este inginer principal care lucrează pe Amazon OpenSearch Service. Este interesat de sistemele distribuite și autonome. El este un colaborator activ la OpenSearch.
 Ranjith Ramachandra este un manager de inginerie care lucrează la Amazon OpenSearch Service la Amazon Web Services.
Ranjith Ramachandra este un manager de inginerie care lucrează la Amazon OpenSearch Service la Amazon Web Services.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/achieve-high-availability-in-amazon-opensearch-multi-az-with-standby-enabled-domains-a-deep-dive-into-failovers/
- :are
- :este
- :nu
- :Unde
- 1
- 10
- 100
- 12
- 30
- 501
- a
- Despre Noi
- Obține
- realizat
- recunoscut
- peste
- act
- Acțiune
- acțiuni
- activ
- adaptivă
- În plus,
- adresa
- afectat
- După
- Acord
- Algoritmul
- algoritmi
- TOATE
- permite
- Amazon
- Amazon Web Services
- printre
- an
- și
- O alta
- Orice
- abordare
- arhitectură
- SUNT
- AS
- alocate
- At
- autonom
- sisteme autonome
- disponibilitate
- gradului de conştientizare
- AWS
- Backup
- echilibrist
- BE
- deoarece
- fost
- înainte
- fiind
- CEL MAI BUN
- Cele mai bune practici
- între
- atât
- difuza
- Clădire
- întreprinderi
- by
- CAN
- Capacitate
- transportate
- cauzată
- caracterizat
- taxă
- verificat
- Grup
- Comunicare
- Comunicații
- Completă
- Configuraţie
- Consens
- prin urmare
- luate în considerare
- consistent
- Consoleze
- conținute
- continuă
- continuu
- a contribui
- contribuabil
- controlată
- coordonator
- Coordonator
- coordonatori
- copii
- acoperit
- crea
- creează
- critic
- crucial
- clienţii care
- tăiere
- de date
- decide
- adânc
- scufundare adâncă
- defineste
- întârzieri
- se îngropa
- cerând
- desfășurarea
- implementează
- desemnat
- proiectat
- dorit
- detecta
- detectat
- determină
- dirijat
- Ruptură
- distribuite
- sisteme distribuite
- scufunda
- do
- documente
- domeniu
- domenii
- Dont
- jos
- două
- durată
- în timpul
- fiecare
- Eficace
- în mod eficient
- eficient
- ales
- Alegeri
- eligibil
- eliminarea
- activat
- permite
- aplica
- inginer
- Inginerie
- spori
- sporită
- consolidarea
- asigura
- asigură
- asigurare
- Afacere
- Întreg
- medii
- mai ales
- Eter (ETH)
- Chiar
- eveniment
- evenimente
- în cele din urmă
- Fiecare
- F? r?
- experienţă
- confruntă
- explora
- eșuează
- Eșec
- eşecuri
- Caracteristică
- DESCRIERE
- scrimă
- First
- următor
- urmează
- Pentru
- FRAME
- din
- Complet
- mai mult
- gif
- Graţios
- treptat
- garanta
- mână
- manipula
- Mânere
- se întâmplă
- he
- sănătos
- ajută
- Înalt
- extrem de
- capotă
- găzduire
- Cum
- http
- HTTPS
- identifica
- if
- ilustrează
- Impactul
- afectate
- deteriorare
- Punere în aplicare a
- important
- in
- include
- indicând
- informații
- Infrastructură
- inițial
- Initiaza
- inițierea
- cazuri
- interesat
- intern
- în
- introdus
- Introducere
- implică
- problema
- probleme de
- IT
- ESTE
- jpg
- JSON
- Cheie
- cunoscut
- în mare măsură
- lider
- Conducere
- ca
- Listă
- încărca
- la nivel local
- situat
- Lung
- menține
- mentine
- gestionate
- administrare
- manager
- manieră
- marcat
- potrivire
- însemna
- mijloace
- măsuri
- mecanism
- mecanisme
- Metadata
- Metrici
- minut
- minute
- diminua
- mod
- model
- mai mult
- mişcare
- Natură
- necesar
- Nevoie
- reţea
- rețele
- Nou
- Nu.
- nod
- noduri
- notabil
- obiect
- of
- de pe
- on
- ONE
- în curs de desfășurare
- afară
- deschide
- funcionar
- operaţie
- Operațiuni
- Opțiune
- or
- orchestrație
- comandă
- Altele
- afară
- pană
- Întreruperile
- peste
- participa
- piese
- pasionat
- cale
- căi
- egal
- performanță
- persistență
- fază
- plasare
- Plato
- Informații despre date Platon
- PlatoData
- joacă
- Post
- potenţial
- puternic
- practicile
- precedent
- predictibil
- împiedica
- prevenirea
- previne
- în prealabil
- primar
- Principal
- Proactivă
- probleme
- proces
- promova
- protocol
- furniza
- furnizează
- Publicare
- publicat
- Punând
- interogări
- Citeste
- a primi
- primește
- recent
- Recupera
- recuperare
- recuperare
- trimite
- regiune
- regulat
- legate de
- încredere
- de încredere
- se bazează
- rămas
- îndepărtare
- repara
- răspunde
- replicat
- replică
- solicita
- cereri de
- necesar
- elasticitate
- elastic
- rezolvă
- responsabil
- restabili
- restaurat
- restabilirea
- Rol
- rutare
- Alerga
- ruleaza
- s
- garanții
- acelaşi
- scalabil
- programată
- perfect
- Caută
- selecţie
- trimitere
- trimite
- senior
- trimis
- serviciu
- Servicii
- set
- ea
- indicat
- semnificativ
- simplitate
- simplifica
- singur
- Incetineste
- încetiniri
- netezi
- So
- Software
- Inginer Software
- soluţie
- Rezolvarea
- stabil
- Stat
- Stare
- constant
- paşi
- stocate
- stres
- Ulterior
- de succes
- susceptibil
- sistem
- sisteme
- Lua
- luate
- ia
- sarcini
- acea
- lor
- Lor
- apoi
- Acolo.
- Acestea
- acest
- aceste
- trei
- Prin
- timp
- ori
- la
- toleranță
- trafic
- tranziţie
- ÎNTORCĂ
- Două
- tipic
- în
- care stau la baza
- neprevăzut
- actualizări
- utilizat
- Utilizator
- utilizări
- folosind
- utilizează
- diverse
- de bunăvoie
- Vot
- we
- web
- servicii web
- greutate
- BINE
- bine definit
- au fost
- cand
- care
- în timp ce
- voi
- cu
- în
- de lucru
- fabrică
- scrie
- zephyrnet
- zero
- zone