Construirea modelelor de fundație (FM) necesită construirea, întreținerea și optimizarea clusterelor mari pentru a antrena modele cu zeci până la sute de miliarde de parametri pe cantități mari de date. Crearea unui mediu rezistent care poate face față eșecurilor și schimbărilor de mediu fără a pierde zile sau săptămâni de progres în formarea modelului este o provocare operațională care necesită să implementați scalarea clusterului, monitorizarea proactivă a sănătății, verificarea locurilor de muncă și capabilități de reluare automată a instruirii în cazul în care apar eșecuri sau probleme. .
Suntem încântați să împărtășim asta Amazon SageMaker HyperPod este acum disponibilă în general pentru a permite modele de bază de antrenament cu mii de acceleratoare cu până la 40% mai rapide, oferind un mediu de antrenament foarte rezistent, eliminând în același timp ridicarea grele nediferențiată implicată în operarea clusterelor de antrenament la scară largă. Cu SageMaker HyperPod, practicienii de învățare automată (ML) pot antrena FM săptămâni și luni fără întreruperi și fără a fi nevoiți să se ocupe de problemele de defecțiune hardware.
Clienți precum Stability AI folosesc SageMaker HyperPod pentru a-și antrena modelele de fundație, inclusiv Stable Diffusion.
„În calitate de companie lider de IA generativă open source, obiectivul nostru este de a maximiza accesibilitatea IA modernă. Construim modele de fundație cu zeci de miliarde de parametri, care necesită infrastructura pentru a scala în mod optim performanța antrenamentului. Cu infrastructura gestionată și bibliotecile de optimizare ale SageMaker HyperPod, putem reduce timpul și costurile de antrenament cu peste 50%. Face antrenamentul nostru model mai rezistent și mai performant pentru a construi mai rapid modele de ultimă generație.”
– Emad Mostaque, fondator și CEO Stability AI.
Pentru a face ca întregul ciclu de dezvoltare a FM să fie rezistent la defecțiuni hardware, SageMaker HyperPod vă ajută să creați clustere, să monitorizați starea clusterului, să reparați și să înlocuiți nodurile defecte din mers, să salvați puncte de control frecvente și să reluați automat antrenamentul fără a pierde progresul. În plus, SageMaker HyperPod este preconfigurat cu Amazon SageMaker biblioteci de instruire distribuite, inclusiv Biblioteca de paralelism de date SageMaker (SMDDP) și Biblioteca de paralelism model SageMaker (SMP), pentru a îmbunătăți performanța de antrenament FM, simplificând împărțirea datelor și modelelor de antrenament în bucăți mai mici și procesându-le în paralel în nodurile clusterului, utilizând în același timp pe deplin infrastructura de calcul și rețea a clusterului. SageMaker HyperPod integrează Slurm Workload Manager pentru orchestrarea grupurilor și a joburilor de instruire.
Prezentare generală a Slurm Workload Manager
slurm, cunoscut anterior sub numele de Utilitar Linux simplu pentru gestionarea resurselor, este un planificator de joburi pentru rularea joburilor pe un cluster de calcul distribuit. De asemenea, oferă un cadru pentru rularea joburilor paralele folosind Biblioteca de comunicații colective NVIDIA (NCCL) or Interfață de transmitere a mesajelor (MPI) standardele. Slurm este un sistem de gestionare a resurselor de cluster cu sursă deschisă popular, utilizat pe scară largă de calculul de înaltă performanță (HPC) și sarcinile de lucru generative de instruire AI și FM. SageMaker HyperPod oferă o modalitate simplă de a porni în funcțiune cu un cluster Slurm în câteva minute.
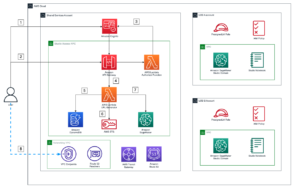
Următoarea este o diagramă arhitecturală la nivel înalt a modului în care utilizatorii interacționează cu SageMaker HyperPod și modul în care diferitele componente ale clusterului interacționează între ele și cu alte servicii AWS, cum ar fi Amazon FSx pentru Luster și Serviciul Amazon de stocare simplă (Amazon S3).
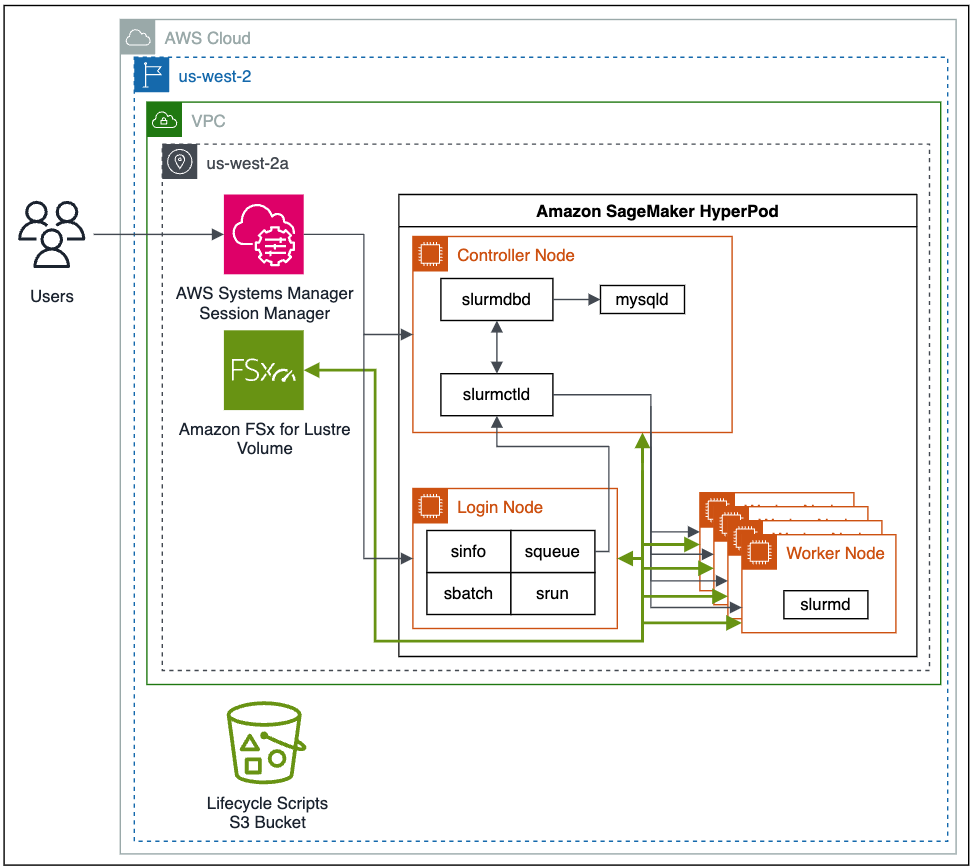
Joburile Slurm sunt trimise prin comenzi pe linia de comandă. Comenzile pentru a rula joburi Slurm sunt srun și sbatch. srun comanda rulează jobul de antrenament în modul interactiv și de blocare și sbatch rulează în procesare batch și în modul fără blocare. srun este folosit mai ales pentru a rula joburi imediate, în timp ce sbatch poate fi folosit pentru rulări ulterioare de joburi.
Pentru informații despre comenzi și configurații suplimentare Slurm, consultați Documentația Slurm Workload Manager.
Auto-reluare și capabilități de vindecare
Una dintre noile caracteristici ale SageMaker HyperPod este abilitatea de a avea reluare automată a lucrărilor dvs. Anterior, atunci când un nod lucrător a eșuat în timpul unei executări de instruire sau de reglare fină, utilizatorul era la latitudinea utilizatorului să verifice starea jobului, să repornească jobul de la cel mai recent punct de control și să continue să monitorizeze jobul pe toată durata executării. Cu lucrările de instruire sau lucrările de reglare fină care trebuie să ruleze zile, săptămâni sau chiar luni la un moment dat, acest lucru devine costisitor din cauza cheltuielilor administrative suplimentare ale utilizatorului care trebuie să petreacă cicluri pentru a monitoriza și întreține lucrarea în cazul în care un blocările nodurilor, precum și costul timpului inactiv al instanțelor de calcul accelerate scumpe.
SageMaker HyperPod abordează rezistența muncii prin utilizarea verificărilor automate de sănătate, înlocuirea nodurilor și recuperarea jobului. Lucrările Slurm în SageMaker HyperPod sunt monitorizate folosind un plugin Slurm personalizat SageMaker folosind cadru SPANK. Când un job de antrenament eșuează, SageMaker HyperPod va inspecta starea clusterului printr-o suită de verificări de sănătate. Dacă se găsește un nod defect în cluster, SageMaker HyperPod va elimina automat nodul din cluster, îl va înlocui cu un nod sănătos și va reporni munca de antrenament. Când utilizați puncte de control în joburile de antrenament, orice lucrare întreruptă sau eșuată poate fi reluată de la cel mai recent punct de control.
Prezentare generală a soluțiilor
Pentru a vă implementa SageMaker HyperPod, mai întâi vă pregătiți mediul configurându-vă Cloud virtual virtual Amazon (Amazon VPC) și grupuri de securitate, implementând servicii de asistență, cum ar fi FSx pentru Luster, în VPC-ul dvs. și publicând scripturile ciclului de viață Slurm într-un compartiment S3. Apoi, implementați și configurați SageMaker HyperPod și vă conectați la nodul principal pentru a începe lucrările de antrenament.
Cerințe preliminare
Înainte de a vă crea SageMaker HyperPod, trebuie mai întâi să vă configurați VPC-ul, să creați un sistem de fișiere FSx pentru Luster și să stabiliți un compartiment S3 cu scripturile ciclului de viață ale clusterului dorite. De asemenea, aveți nevoie de cea mai recentă versiune a Interfața liniei de comandă AWS (AWS CLI) și pluginul CLI instalat pentru Manager de sesiune AWS, o capacitate de Manager sistem AWS.
SageMaker HyperPod este complet integrat cu VPC-ul dumneavoastră. Pentru informații despre crearea unui nou VPC, consultați Creați un VPC implicit or Creați un VPC. Pentru a permite o conexiune perfectă cu cea mai înaltă performanță între resurse, ar trebui să vă creați toate resursele în aceeași regiune și zonă de disponibilitate, precum și să vă asigurați că regulile grupului de securitate asociate permit conectarea între resursele clusterului.
Următorul tu creați un sistem de fișiere FSx pentru Luster. Acesta va servi drept sistem de fișiere de înaltă performanță pentru utilizare pe parcursul antrenamentului nostru de model. Asigurați-vă că FSx pentru Luster și grupurile de securitate ale clusterului permit comunicarea de intrare și de ieșire între resursele clusterului și sistemul de fișiere FSx pentru Luster.
Pentru a configura scripturile ciclului de viață al cluster-ului, care sunt rulate atunci când apar evenimente precum o nouă instanță de cluster, creați o găleată S3 și apoi copiați și, opțional, personalizați scripturile implicite ciclului de viață. Pentru acest exemplu, stocăm toate scripturile ciclului de viață într-un prefix de găleată de lifecycle-scripts.
Mai întâi, descărcați exemplele de scripturi ciclului de viață din GitHub repo. Ar trebui să le personalizați pentru a se potrivi cu comportamentele de cluster dorite.
Apoi, creați o găleată S3 pentru a stoca scripturile personalizate ale ciclului de viață.
Apoi, copiați scripturile implicite ale ciclului de viață din directorul local în compartimentul și prefixul dorit aws s3 sync:
În cele din urmă, pentru a configura clientul pentru o conexiune simplificată la nodul principal al clusterului, ar trebui instalați sau actualizați AWS CLI și instalați fișierul Plugin AWS Session Manager CLI pentru a permite conexiunilor terminale interactive să administreze clusterul și să ruleze joburi de instruire.
Puteți crea un cluster SageMaker HyperPod fie cu resurse disponibile la cerere, fie prin solicitarea unei rezervări de capacitate la SageMaker. Pentru a crea o rezervare de capacitate, creați o solicitare de creștere a cotei pentru a rezerva anumite tipuri de instanțe de calcul și alocarea capacității în tabloul de bord Cote de servicii.
Configurați-vă clusterul de antrenament
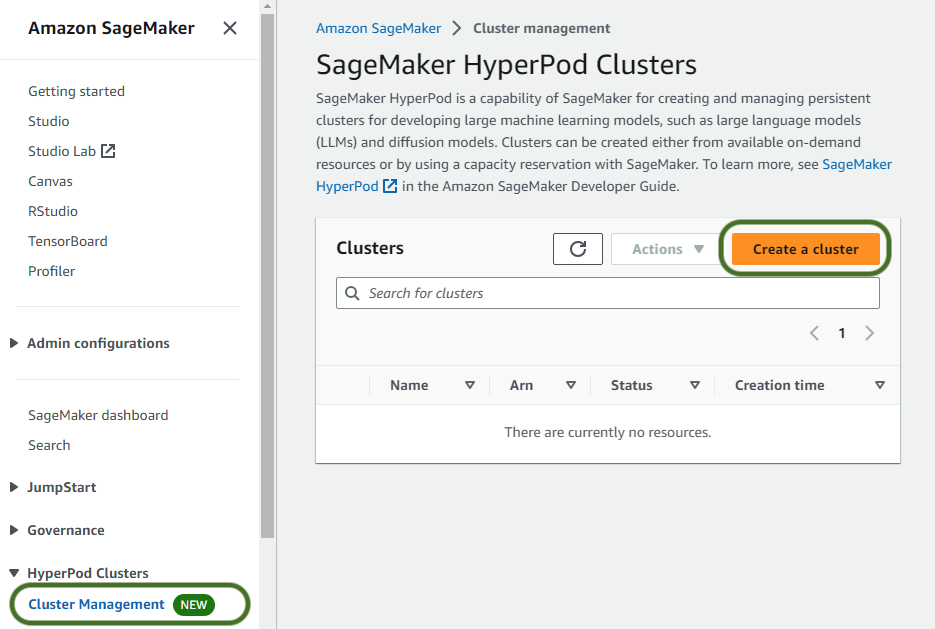
Pentru a vă crea clusterul SageMaker HyperPod, parcurgeți următorii pași:
- Pe consola SageMaker, alegeți Managementul clusterelor în Clustere HyperPod în panoul de navigare.
- Alege Creați un cluster.
- Furnizați un nume de cluster și, opțional, orice etichete de aplicat resurselor clusterului, apoi alegeți Pagina Următoare →.
- Selectați Creați grup de instanțe și specificați numele grupului de instanțe, tipul de instanță necesar, cantitatea de instanțe dorită și calea prefixului S3 în care ați copiat anterior scripturile ciclului de viață al clusterului.
Este recomandat să aveți grupuri de instanțe diferite pentru nodurile de controler utilizate pentru a administra clusterul și trimite joburi și nodurile de lucru utilizate pentru a rula joburi de instruire folosind instanțe de calcul accelerate. Opțional, puteți configura un grup de instanțe suplimentar pentru nodurile de conectare.
- Mai întâi creați grupul de instanțe controler, care va include nodul principal de cluster.
- Pentru acest grup de instanță Gestionarea identității și accesului AWS (IAM) rol, alege Creați un nou rol și specificați orice compartiment S3 la care doriți să aibă acces instanțele cluster din grupul de instanțe.
Rolului generat i se va acorda acces numai în citire la compartimentele specificate în mod implicit.
- Alege Creare rol.
- Introduceți numele scriptului care urmează să fie rulat la fiecare creare a instanței în promptul de creare a scriptului. În acest exemplu, scriptul la creare este numit
on_create.sh.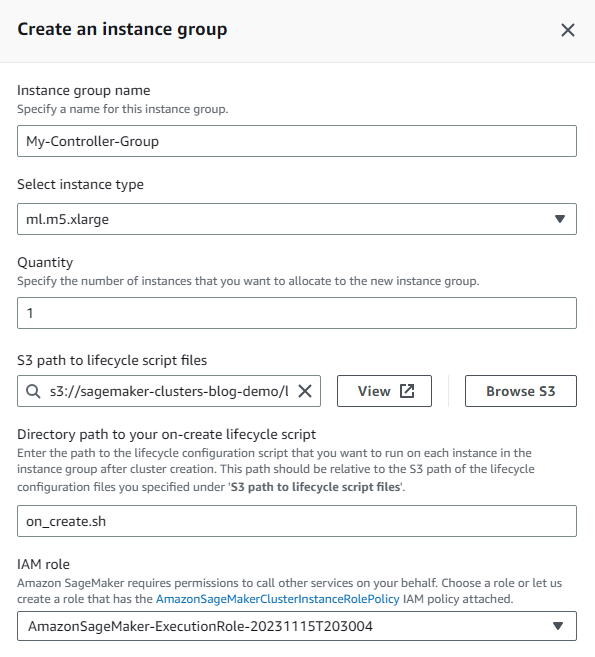
- Alege Economisiți.
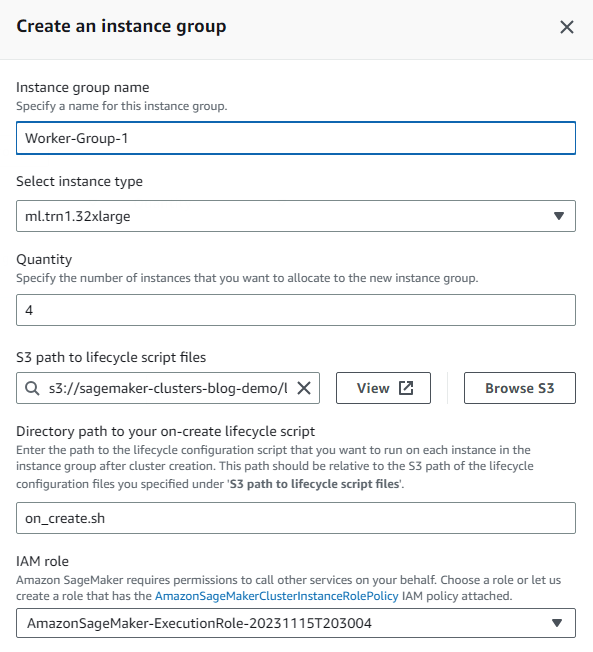
- Alege Creați grup de instanțe pentru a crea grupul de instanțe de lucrător.
- Furnizați toate detaliile solicitate, inclusiv tipul de instanță și cantitatea dorită.
Acest exemplu folosește patru instanțe accelerate ml.trn1.32xl pentru a realiza munca noastră de instruire. Puteți utiliza același rol IAM ca înainte sau puteți personaliza rolul pentru instanțele de lucru. În mod similar, puteți utiliza diferite scripturi de ciclu de viață la creare pentru acest grup de instanțe de lucru decât grupul de instanțe anterior.
- Alege Pagina Următoare → a continua.
- Alegeți VPC-ul, subrețeaua și grupurile de securitate dorite pentru instanțele dvs. de cluster.
Găzduim instanțele clusterului într-o singură zonă de disponibilitate și subrețea pentru a asigura o latență scăzută.
Rețineți că, dacă veți accesa frecvent datele S3, este recomandat să creați un punct final VPC care este asociat cu tabelul de rutare al subrețelei private pentru a reduce costurile potențiale de transfer de date.
- Alege Pagina Următoare →.

- Examinați rezumatul detaliilor clusterului, apoi alegeți Trimite mesaj.
Ca alternativă, pentru a vă crea SageMaker HyperPod utilizând AWS CLI, mai întâi personalizați parametrii JSON folosiți pentru a crea cluster-ul:
Apoi utilizați următoarea comandă pentru a crea cluster-ul folosind intrările furnizate:
Rulați-vă primul job de antrenament cu Llama 2
Rețineți că utilizarea modelului Llama 2 este guvernată de licența Meta. Pentru a descărca modelul de greutăți și tokenizer, vizitați și acceptați licența înainte de a solicita acces Site-ul Meta’s Hugging Face.
După ce clusterul rulează, conectați-vă cu Session Manager folosind id-ul clusterului, numele grupului de instanțe și id-ul instanței. Utilizați următoarea comandă pentru a vizualiza detaliile clusterului dvs.:
Notați ID-ul clusterului inclus în ARN-ul clusterului în răspuns.
Utilizați următoarea comandă pentru a prelua numele grupului de instanțe și ID-ul instanței necesare pentru a vă conecta la cluster.
Luați notă de InstanceGroupName si InstanceId în răspuns, deoarece acestea vor fi folosite pentru a se conecta la instanță cu Managerul de sesiune.
Acum utilizați Managerul de sesiune pentru a vă conecta la nodul principal sau la unul dintre nodurile de conectare și pentru a vă executa munca de antrenament:
În continuare, vom pregăti mediul și vom descărca Llama 2 și setul de date RedPjama. Pentru codul complet și o prezentare pas cu pas a acestuia, urmați instrucțiunile de pe AWSome Training distribuit Repo GitHub.
Urmați pașii detaliați în 2.test_cases/8.neuronx-nemo-megatron/README.md fişier. După ce ați urmat pașii pentru pregătirea mediului, pregătirea modelului, descărcarea și tokenizarea setului de date și pre-compilarea modelului, ar trebui să editați 6.pretrain-model.sh script și sbatch comanda de trimitere a jobului pentru a include un parametru care vă va permite să profitați de caracteristica de reluare automată a SageMaker HyperPod.
Editați sbatch linia să arate astfel:
După depunerea jobului, veți primi un JobID pe care îl puteți folosi pentru a verifica starea jobului folosind următorul cod:
În plus, puteți monitoriza jobul urmând jurnalul de ieșire a jobului folosind următorul cod:
A curăța
Pentru a șterge clusterul SageMaker HyperPod, fie utilizați consola SageMaker, fie următoarea comandă AWS CLI:
Concluzie
Această postare v-a arătat cum să vă pregătiți mediul AWS, să implementați primul dvs. cluster SageMaker HyperPod și să antrenezi un model Llama 7 cu 2 miliarde de parametri. SageMaker HyperPod este disponibil în general astăzi în regiunile Americi (N. Virginia, Ohio și Oregon), Asia Pacific (Singapore, Sydney și Tokyo) și Europa (Frankfurt, Irlanda și Stockholm). Acestea pot fi implementate prin consola SageMaker, AWS CLI și SDK-urile AWS și acceptă familiile de instanțe p4d, p4de, p5, trn1, inf2, g5, c5, c5n, m5 și t3.
Pentru a afla mai multe despre SageMaker HyperPod, vizitați Amazon SageMaker HyperPod.
Despre autori
 Brad Doran este Senior Technical Account Manager la Amazon Web Services, concentrat pe AI generativă. El este responsabil pentru rezolvarea provocărilor de inginerie pentru clienții generativi de inteligență artificială din segmentul de piață digital nativ de afaceri. El provine dintr-un mediu de dezvoltare a infrastructurii și software-ului și în prezent urmează studii doctorale și cercetări în inteligența artificială și învățarea automată.
Brad Doran este Senior Technical Account Manager la Amazon Web Services, concentrat pe AI generativă. El este responsabil pentru rezolvarea provocărilor de inginerie pentru clienții generativi de inteligență artificială din segmentul de piață digital nativ de afaceri. El provine dintr-un mediu de dezvoltare a infrastructurii și software-ului și în prezent urmează studii doctorale și cercetări în inteligența artificială și învățarea automată.
 Keita Watanabe este Senior GenAI Specialist Solutions Architect la Amazon Web Services, unde ajută la dezvoltarea de soluții de învățare automată folosind proiecte OSS precum Slurm și Kubernetes. Studiul său este în cercetarea și dezvoltarea învățării automate. Înainte de a se alătura AWS, Keita a lucrat în industria comerțului electronic ca cercetător care a dezvoltat sisteme de recuperare a imaginilor pentru căutarea de produse. Keita deține un doctorat în știință la Universitatea din Tokyo.
Keita Watanabe este Senior GenAI Specialist Solutions Architect la Amazon Web Services, unde ajută la dezvoltarea de soluții de învățare automată folosind proiecte OSS precum Slurm și Kubernetes. Studiul său este în cercetarea și dezvoltarea învățării automate. Înainte de a se alătura AWS, Keita a lucrat în industria comerțului electronic ca cercetător care a dezvoltat sisteme de recuperare a imaginilor pentru căutarea de produse. Keita deține un doctorat în știință la Universitatea din Tokyo.
 Justin Pirtle este arhitect principal de soluții la Amazon Web Services. El consiliază în mod regulat clienții AI generativi în proiectarea, implementarea și scalarea infrastructurii lor. Este un vorbitor regulat la conferințele AWS, inclusiv re:Invent, precum și la alte evenimente AWS. Justin deține o diplomă de licență în Sisteme Informaționale de Management de la Universitatea Texas din Austin și o diplomă de master în Inginerie Software de la Universitatea Seattle.
Justin Pirtle este arhitect principal de soluții la Amazon Web Services. El consiliază în mod regulat clienții AI generativi în proiectarea, implementarea și scalarea infrastructurii lor. Este un vorbitor regulat la conferințele AWS, inclusiv re:Invent, precum și la alte evenimente AWS. Justin deține o diplomă de licență în Sisteme Informaționale de Management de la Universitatea Texas din Austin și o diplomă de master în Inginerie Software de la Universitatea Seattle.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/introducing-amazon-sagemaker-hyperpod-to-train-foundation-models-at-scale/
- :este
- :Unde
- $UP
- 1
- 100
- 12
- 14
- 24
- 7
- a
- capacitate
- Despre Noi
- accelerat
- acceleratoare
- Accept
- acces
- accesibilitate
- accesarea
- Cont
- peste
- plus
- Suplimentar
- adrese
- administra
- administrativ
- Avantaj
- După
- AI
- TOATE
- alocare
- permite
- permite
- de asemenea
- Amazon
- Amazon SageMaker
- Amazon Web Services
- Americi
- Sume
- an
- și
- Orice
- Aplică
- arhitectural
- SUNT
- apărea
- artificial
- inteligență artificială
- Inteligența artificială și învățarea în mașină
- AS
- Asia
- Asia Pacific
- asociate
- At
- Austin
- Automata
- în mod automat
- disponibilitate
- disponibil
- AWS
- fundal
- BE
- devine
- înainte
- între
- miliarde
- blocarea
- construi
- Clădire
- afaceri
- by
- denumit
- CAN
- capacități
- capacitate
- Capacitate
- CEO
- contesta
- provocări
- Modificări
- verifica
- Verificări
- Alege
- client
- Grup
- cod
- Colectiv
- vine
- Comunicare
- Comunicații
- companie
- Completă
- componente
- Calcula
- tehnica de calcul
- conferințe
- Configuraţie
- configurarea
- Conectați
- conexiune
- Conexiuni
- Consoleze
- continua
- controlor
- A costat
- costisitor
- Cheltuieli
- crea
- Crearea
- creaţie
- În prezent
- personalizat
- clienţii care
- personaliza
- personalizate
- ciclu
- cicluri
- tablou de bord
- de date
- Zi
- afacere
- Mod implicit
- Grad
- implementa
- dislocate
- Implementarea
- proiect
- dorit
- detaliat
- detalii
- dezvolta
- în curs de dezvoltare
- Dezvoltare
- diferit
- difuziune
- digital
- Ruptură
- distribuite
- calcul distribuit
- instruire distribuită
- Descarca
- două
- în timpul
- fiecare
- E-commerce
- oricare
- eliminarea
- permite
- Punct final
- Inginerie
- asigura
- Întreg
- Mediu inconjurator
- de mediu
- stabili
- Eter (ETH)
- Europa
- Chiar
- eveniment
- evenimente
- exemplu
- excitat
- scump
- suplimentar
- Față
- A eșuat
- eșuează
- Eșec
- eşecuri
- familii
- mai repede
- defect
- Caracteristică
- DESCRIERE
- Fișier
- First
- concentrat
- urma
- următor
- Pentru
- anterior
- găsit
- Fundație
- fondator
- Fondator și CEO
- patru
- Cadru
- frankfurt
- frecvent
- frecvent
- din
- Complet
- complet
- în general
- generată
- generativ
- AI generativă
- obține
- GitHub
- scop
- merge
- guvernată
- acordate
- grup
- Grupului
- manipula
- Piese metalice
- Avea
- având în
- he
- cap
- vindecare
- Sănătate
- sănătos
- greu
- ridicare de greutati
- ajută
- Înalt
- High Performance Computing
- la nivel înalt
- performanta ridicata
- cea mai mare
- extrem de
- lui
- deține
- gazdă
- Cum
- Cum Pentru a
- hpc
- HTML
- http
- HTTPS
- sute
- IAM
- ID
- Identitate
- Idle
- if
- imagine
- imediat
- punerea în aplicare a
- îmbunătăţi
- in
- include
- inclus
- Inclusiv
- Crește
- industrie
- informații
- Sisteme de informare
- Infrastructură
- intrări
- instala
- instanță
- cazuri
- instrucțiuni
- integrate
- integreaza
- Inteligență
- interacţiona
- interactiv
- interfaţă
- întrerupt
- în
- introducerea
- implicat
- Irlanda
- probleme de
- IT
- Loc de munca
- Locuri de munca
- aderarea
- jpg
- JSON
- Justin
- cunoscut
- Kubernetes
- mare
- pe scară largă
- Latență
- mai tarziu
- Ultimele
- conducere
- AFLAȚI
- învăţare
- biblioteci
- Bibliotecă
- Licență
- ciclu de viață
- ridicare
- ca
- Linie
- linux
- Lamă
- local
- log
- Logare
- Uite
- arată ca
- care pierde
- Jos
- maşină
- masina de învățare
- menține
- mentine
- face
- FACE
- Efectuarea
- gestionate
- administrare
- sistemul de management
- manager
- Piață
- studii de masterat
- materie
- Maximaliza
- meta
- minute
- ML
- mod
- model
- Modele
- Modern
- monitor
- monitorizate
- Monitorizarea
- luni
- mai mult
- Mai ales
- nume
- nativ
- Navigare
- Nevoie
- necesar
- au nevoie
- reţea
- Nou
- Funcții noi
- nod
- noduri
- nota
- acum
- Nvidia
- avea loc
- of
- Ohio
- on
- La cerere
- ONE
- deschide
- open-source
- de operare
- operațional
- optimizare
- optimizarea
- or
- orchestrație
- Oregon
- Ne
- Altele
- al nostru
- producție
- peste
- Pacific
- pâine
- Paralel
- parametru
- parametrii
- Care trece
- cale
- efectua
- performanță
- PhD
- Plato
- Informații despre date Platon
- PlatoData
- conecteaza
- Popular
- Post
- potenţial
- Pregăti
- precedent
- în prealabil
- Principal
- anterior
- privat
- Proactivă
- continua
- prelucrare
- Produs
- Progres
- Proiecte
- prevăzut
- furnizează
- furnizarea
- Editare
- urmărirea
- cantitate
- RE
- recomandat
- recuperare
- reduce
- trimite
- regiune
- regiuni
- regulat
- regulat
- scoate
- repara
- înlocui
- înlocuire
- solicita
- solicitat
- necesita
- Necesită
- cercetare
- cercetare și dezvoltare
- Rezervare
- Rezervă
- elastic
- resursă
- Resurse
- răspuns
- responsabil
- relua
- Rol
- rutare
- norme
- Alerga
- funcţionare
- ruleaza
- sagemaker
- acelaşi
- Economisiți
- Scară
- scalare
- Ştiinţă
- Om de stiinta
- scenariu
- script-uri
- sdks
- fără sudură
- Caută
- Seattle
- securitate
- vedea
- segment
- senior
- servi
- serviciu
- Servicii
- sesiune
- set
- Distribuie
- să
- a arătat
- asemănător
- simplu
- simplificată
- Singapore
- singur
- mai mici
- Software
- de dezvoltare de software
- Inginerie software
- soluţii
- Rezolvarea
- Sursă
- Vorbitor
- specialist
- specific
- specificată
- petrece
- împărţi
- Stabilitate
- stabil
- standarde
- Începe
- de ultimă oră
- Stare
- paşi
- depozitare
- stoca
- simplu
- studiu
- supunere
- prezenta
- prezentat
- subrețea
- astfel de
- Costum
- suită
- REZUMAT
- a sustine
- De sprijin
- sigur
- sydney
- sincronizare
- sistem
- sisteme
- tabel
- Lua
- Tehnic
- zeci
- Terminal
- Texas
- decât
- acea
- lor
- Lor
- apoi
- Acestea
- ei
- acest
- mii
- Prin
- de-a lungul
- timp
- la
- astăzi
- tokeniza
- Tokyo
- Tren
- Pregătire
- transfer
- tip
- Tipuri
- în
- universitate
- Universitatea din Tokyo
- Actualizează
- utilizare
- utilizat
- Utilizator
- utilizatorii
- utilizări
- folosind
- utilitate
- Utilizand
- diverse
- Fixă
- versiune
- de
- Vizualizare
- Virginia
- Virtual
- Vizita
- walkthrough
- a fost
- Cale..
- we
- web
- servicii web
- săptămâni
- BINE
- cand
- care
- în timp ce
- pe larg
- Wikipedia
- voi
- cu
- în
- fără
- a lucrat
- lucrător
- ar
- tu
- Ta
- zephyrnet