În marșul către sisteme mai capabile, mai rapide, mai mici și cu putere mai mică, Legea lui Moore a oferit software-ului o călătorie gratuită timp de peste 30 de ani, doar pe evoluția proceselor semiconductoare. Hardware-ul de calcul a oferit valori îmbunătățite de performanță/zonă/putere în fiecare an, permițând software-ului să se extindă în complexitate și să ofere mai multe capacități fără dezavantaje. Apoi victoriile ușoare au devenit mai puțin ușoare. Procesele mai avansate au continuat să ofere un număr mai mare de porți pe unitate de suprafață, dar câștigurile în performanță și putere au început să se aplatizeze. Deoarece așteptările noastre pentru inovație nu s-au oprit, progresele arhitecturii hardware au devenit mai importante pentru a recupera slăbirea.

Drivere pentru creșterea numărului de nuclee
Un pas timpuriu în această direcție a folosit procesoare cu mai multe nuclee pentru a accelera debitul total prin împrumutarea sau virtualizarea unui amestec de sarcini concurente între nuclee, reducând puterea după cum este necesar prin oprirea sau oprirea nucleelor inactive. Multi-core este standard astăzi și o tendință în mai multe nuclee (chiar mai multe procesoare pe un cip) este deja evidentă în opțiunile de instanță de server disponibile în platformele cloud de la AWS, Azure, Alibaba și altele.
Arhitecturile cu mai multe/mai multe nuclee sunt un pas înainte, dar paralelismul prin clusterele CPU este grosier și are propriile limite de performanță și putere, datorită legii lui Amdahl. Arhitecturile au devenit mai eterogene, adăugând acceleratoare pentru imagine, audio și alte nevoi specializate. Acceleratoarele AI au impulsionat, de asemenea, paralelismul cu granulație fină, trecând la matrice sistolice și alte tehnici specifice domeniului. Ceea ce a funcționat destul de bine până când a apărut ChatGPT cu 175 de miliarde de parametri, GPT-3 evoluând în GPT-4 cu 100 de trilioane de parametri – ordine de mărime mai complexe decât sistemele AI de astăzi – forțând funcții de accelerare și mai specializate în cadrul acceleratoarelor AI.
Pe un alt front, sistemele multi-senzor din aplicațiile auto se integrează acum în SoC-uri unice pentru o mai bună cunoaștere a mediului și un PPA îmbunătățit. Aici, noile niveluri de autonomie în domeniul auto depind de fuzionarea intrărilor de la mai multe tipuri de senzori într-un singur dispozitiv, în subsisteme replicate de 2X, 4X sau 8X.
Potrivit lui Michał Siwinski (CMO la Arteris), eșantionarea a peste o lună de discuții cu mai multe echipe de proiectare dintr-o gamă largă de aplicații sugerează că acele echipe se îndreaptă în mod activ către un număr mai mare de nuclee pentru a îndeplini obiectivele de capacitate, performanță și putere. Îmi spune că și ei văd această tendință în creștere. Progresele proceselor ajută în continuare la numărarea porților SoC, dar responsabilitatea pentru îndeplinirea obiectivelor de performanță și putere este acum ferm în mâinile arhitecților.
Mai multe nuclee, mai multe interconectari
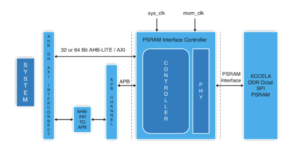
Mai multe nuclee pe un cip implică mai multe conexiuni de date între acele nuclee. În cadrul unui accelerator între elementele de procesare învecinate, la cache-ul local, la acceleratoare pentru matrice rară și alte manipulări specializate. Adăugați conectivitate ierarhică între plăcile de accelerație și magistralele la nivel de sistem. Adăugați conectivitate pentru stocarea greutății pe cip, decompresie, difuzare, colectare și recomprimare. Adăugați conectivitate HBM pentru cache-ul funcțional. Adăugați un motor de fuziune dacă este necesar.
Clusterul de control bazat pe CPU trebuie să se conecteze la fiecare dintre acele subsisteme replicate și la toate funcțiile obișnuite – codecuri, managementul memoriei, insulă de siguranță și rădăcină de încredere, dacă este cazul, UCIe dacă este o implementare multi-chiplet, PCIe pentru I/O cu lățime de bandă mare. , și Ethernet sau fibră pentru rețea.
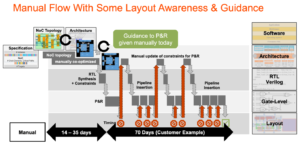
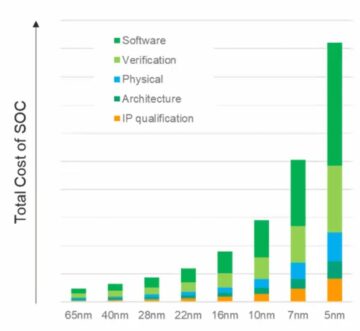
Este multă interconexiune, cu consecințe directe pentru comercializarea produsului. În procesele sub 16 nm, infrastructura NoC contribuie acum cu 10-12% în zonă. Și mai important, ca autostradă de comunicație între nuclee, poate avea un impact semnificativ asupra performanței și puterii. Există pericolul real ca o implementare suboptimă să irosească performanța așteptată a arhitecturii și câștigurile de putere sau, mai rău, să ducă la convergerea numeroaselor bucle de reproiectare. Cu toate acestea, găsirea unei implementări bune într-un plan complex SoC depinde încă de optimizări lente de încercare și eroare în programe de proiectare deja strânse. Trebuie să facem saltul la designul NoC conștient din punct de vedere fizic, pentru a garanta performanță deplină și suport de putere din ierarhiile complexe NoC și trebuie să facem aceste optimizări mai rapide.
Proiectele NoC conștiente din punct de vedere fizic mențin legea lui Moore pe drumul cel bun
Legea lui Moore poate să nu fie moartă, dar progresele în performanță și putere astăzi provin din arhitectură și interconectarea NoC, mai degrabă decât din proces. Arhitectura împinge mai multe nuclee de accelerator, mai multe acceleratoare în cadrul acceleratoarelor și mai multă replicare a subsistemului pe cip. Toate cresc complexitatea interconectării pe cip. Pe măsură ce proiectele cresc numărul de nuclee și trec la geometriile procesului la 16 nm și mai jos, numeroasele interconexiuni NoC care se întind pe SoC și subsistemele sale pot sprijini întregul potențial al acestor proiecte complexe numai dacă sunt implementate în mod optim împotriva constrângerilor fizice și de sincronizare - prin intermediul unei rețele conștiente din punct de vedere fizic. pe designul cipului.
Dacă vă faceți griji și în legătură cu aceste tendințe, poate doriți să aflați mai multe despre tehnologia Arteris FlexNoC 5 IP AICI.
Distribuie această postare prin:
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://semiwiki.com/artificial-intelligence/326727-interconnect-under-the-spotlight-as-core-counts-accelerate/
- :este
- $UP
- 100
- a
- Despre Noi
- accelera
- accelerarea
- accelerare
- accelerator
- acceleratoare
- peste
- activ
- avansat
- avans
- împotriva
- AI
- Sisteme AI
- Alibaba
- TOATE
- Permiterea
- deja
- și
- a apărut
- aplicatii
- adecvat
- arhitectură
- SUNT
- ZONĂ
- AS
- At
- audio
- auto
- disponibil
- gradului de conştientizare
- AWS
- Azuriu
- Lățime de bandă
- BE
- deveni
- de mai jos
- între
- Miliard
- difuza
- Autobuze
- by
- cache
- CAN
- capabil
- Chat GPT
- cip
- Cloud
- Grup
- OCP
- cum
- Comunicare
- complex
- complexitate
- Calcula
- concurent
- Conectați
- Conexiuni
- Suport conectare
- Consecințele
- constrângeri
- a continuat
- Control
- converg
- Nucleu
- Procesor
- PERICOL
- de date
- mort
- livra
- livrate
- depinde de
- Amenajări
- modele
- dispozitiv
- diferit
- direcționa
- direcţie
- discuții
- jos
- dezavantaje
- fiecare
- Devreme
- element
- Motor
- Mediu inconjurator
- Chiar
- Fiecare
- evoluţie
- evoluție
- Extinde
- aşteptări
- de aşteptat
- mai repede
- DESCRIERE
- descoperire
- cu fermitate
- Pentru
- Înainte
- Gratuit
- din
- faţă
- Complet
- funcții
- fuziune
- câștig
- Goluri
- bine
- garanta
- Manipularea
- mâini
- Piese metalice
- Avea
- ajutor
- aici
- Înalt
- superior
- Şosea
- HTTPS
- imagine
- Impactul
- implementarea
- implementat
- important
- îmbunătățit
- in
- inactiv
- Crește
- crescând
- Infrastructură
- Inovaţie
- instanță
- integrarea
- IP
- insulă
- IT
- ESTE
- a sari
- Drept
- AFLAȚI
- Nivel
- nivelurile de
- Limitele
- local
- Lot
- face
- administrare
- Martie
- Matrice
- max-width
- Întâlni
- Reuniunea
- Memorie
- Metrici
- ar putea
- Lună
- mai mult
- muta
- în mişcare
- multiplu
- Nevoie
- necesar
- nevoilor
- reţea
- rețele
- Nou
- numeroși
- of
- on
- Opţiuni
- comenzilor
- Altele
- Altele
- propriu
- parametrii
- performanță
- fizic
- Fizic
- Platforme
- Plato
- Informații despre date Platon
- PlatoData
- Post
- potenţial
- putere
- Alimentarea
- destul de
- proces
- procese
- prelucrare
- Produs
- pur
- împins
- împingerea
- gamă
- mai degraba
- real
- reducerea
- replicat
- replică
- responsabilitate
- rezultat
- Călări
- rădăcină
- Siguranţă
- semiconductor
- semnificativ
- întrucât
- singur
- moale
- încetini
- mai mici
- So
- Software
- matrice rară
- de specialitate
- Reflector
- standard
- început
- Pas
- Încă
- Stop
- depozitare
- sugerează
- a sustine
- sistem
- sisteme
- sarcini
- echipe
- tehnici de
- Tehnologia
- spune
- acea
- Acestea
- Prin
- debit
- sincronizare
- la
- astăzi
- azi
- Total
- tendință
- Tendinţe
- Trilion
- Încredere
- Cotitură
- Tipuri
- în
- unitate
- de
- greutate
- BINE
- care
- larg
- Gamă largă
- voi
- Victorii
- cu
- în
- de lucru
- an
- ani
- zephyrnet