Modelele de limbaj mari (LLM) prezintă o provocare unică atunci când vine vorba de evaluarea performanței. Spre deosebire de învățarea automată tradițională, unde rezultatele sunt adesea binare, rezultatele LLM locuiesc într-un spectru de corectitudine. De asemenea, deși modelul dvs. de bază poate excela în valori ample, performanța generală nu garantează performanța optimă pentru cazurile dvs. de utilizare specifice.
Prin urmare, o abordare holistică a evaluării LLM-urilor trebuie să utilizeze o varietate de abordări, cum ar fi utilizarea LLM-urilor pentru a evalua LLM-urile (adică autoevaluarea) și utilizarea abordărilor hibride om-LLM. Acest articol analizează pașii specifici ai diferitelor metode, acoperind cum să creați seturi de evaluare personalizate adaptate aplicației dvs., să identificați valorile relevante și să implementați metode riguroase de evaluare – atât pentru selectarea modelelor, cât și pentru monitorizarea performanței continue în producție.
Creați seturi de evaluare țintite pentru cazurile dvs. de utilizare
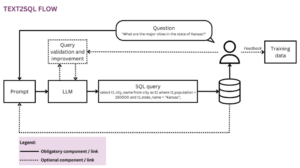
Pentru a evalua performanța unui LLM într-un anumit caz de utilizare, trebuie să testați modelul pe un set de exemple care sunt reprezentative pentru cazurile de utilizare țintă. Acest lucru necesită construirea unui set de evaluare personalizat.
- Începe mici. Pentru a testa performanța LLM în cazul dvs. de utilizare, puteți începe cu doar 10 exemple. Fiecare dintre aceste exemple poate fi rulat de mai multe ori pentru a evalua consistența și fiabilitatea modelului.
- Alege exemple provocatoare. Exemplele pe care le alegeți nu ar trebui să fie simple. Ar trebui să fie provocatoare, concepute pentru a testa capacitatea modelului la maximum. Aceasta ar putea include solicitări cu intrări neașteptate, interogări care ar putea induce părtiniri sau întrebări care necesită o înțelegere profundă a subiectului. Nu este vorba despre păcălirea modelului, ci mai degrabă să ne asigurăm că este pregătit pentru natura imprevizibilă a aplicațiilor din lumea reală.
- Luați în considerare valorificarea LLM-urilor pentru construirea unui set de evaluare. În mod interesant, este o practică obișnuită să folosiți modele lingvistice pentru a construi seturi de evaluare pentru a evalua fie el însuși, fie alte modele lingvistice. De exemplu, un LLM poate genera un set de perechi întrebări și răspunsuri pe baza unui text de intrare, pe care îl puteți utiliza ca prim lot de mostre pentru aplicația dvs. de răspunsuri la întrebări.
- Includeți feedback-ul utilizatorilor. Indiferent dacă provin de la testarea echipelor interne sau de la o implementare mai largă, feedbackul utilizatorilor dezvăluie adesea provocări neprevăzute și scenarii din lumea reală. Un astfel de feedback poate fi integrat ca noi exemple provocatoare în seturile dvs. de evaluare.
În esență, construirea unui set de evaluare personalizat este un proces dinamic, care se adaptează și se dezvoltă în tandem cu ciclul de viață al proiectului LLM. Această metodologie iterativă asigură că modelul dumneavoastră rămâne în acord cu provocările actuale și relevante.
Combinați valorile, comparațiile și evaluarea bazată pe criterii
Numai valorile sunt de obicei insuficiente pentru a evalua LLM. LLM-urile operează într-un domeniu în care nu există întotdeauna un răspuns „corect” singular. În plus, utilizarea valorilor agregate poate induce în eroare. Un model s-ar putea să exceleze într-un domeniu și să se clatine într-un altul, dar totuși să înregistreze un scor mediu impresionant.
Criteriile dvs. de evaluare vor depinde de atributele distincte ale unui anumit sistem LLM. În timp ce acuratețea și imparțialitatea sunt obiective comune, alte criterii ar putea fi primordiale în scenarii specifice. De exemplu, un chatbot medical poate acorda prioritate inofensiunii răspunsurilor, un bot de asistență pentru clienți ar putea accentua menținerea unui ton prietenos consecvent sau o aplicație de dezvoltare web ar putea necesita rezultate într-un format specific.
Pentru a eficientiza procesul, mai multe criterii de evaluare pot fi integrate într-un singur funcția de feedback. Va lua ca intrare textul generat de un LLM și unele metadate, apoi va scoate un scor care indică calitatea textului.
Astfel, evaluarea holistică a performanței LLM implică de obicei cel puțin 3 abordări diferite:
- Măsuri cantitative: Când există răspunsuri corecte definitive, puteți utiliza implicit metodele tradiționale de evaluare ML folosind abordări cantitative.
- Comparații de referință: Pentru cazurile fără un răspuns clar clar, dar cu o referință disponibilă a răspunsurilor acceptabile, răspunsul modelului poate fi comparat și comparat cu exemplele preexistente.
- Evaluare bazată pe criterii: În absența unei referințe, accentul se mută către măsurarea rezultatelor modelului în funcție de criteriile predefinite.
Atât comparațiile de referință, cât și evaluările bazate pe criterii pot fi executate fie de către evaluatori umani, fie prin procese automate. În continuare, vom analiza avantajele și dezavantajele acestor abordări distincte de evaluare.
Abordări umane, autoevaluare și hibride
Evaluarea umană este adesea privită ca standardul de aur pentru evaluarea aplicațiilor de învățare automată, inclusiv sistemele bazate pe LLM, dar nu este întotdeauna fezabilă din cauza constrângerilor temporale sau tehnice. Autoevaluarea și abordările hibride sunt adesea folosite în setările întreprinderii pentru a scala evaluarea performanței LLM.
Evaluarea umană
Supravegherea umană asupra rezultatelor aplicațiilor bazate pe LLM este esențială pentru a asigura acuratețea și fiabilitatea acestor sisteme. Cu toate acestea, bazarea exclusiv pe această abordare pentru a evalua LLM poate să nu fie ideală din cauza următoarelor limitări cheie:
- Preocupări de calitate: În mod surprinzător, modelele avansate precum GPT-4 produc adesea evaluări de calitate superioară în comparație cu rezultatele medii de la muncitorii angajați prin Mechanical Turk. Evaluatorii umani, cu excepția cazului în care sunt ghidați de proiecte experimentale meticuloase, s-ar putea să nu se concentreze pe calitățile de bază care contează cel mai mult. Există o tendință de a fi prins în elemente superficiale; de exemplu, ei ar putea favoriza un răspuns bine formatat, dar eronat, în detrimentul unui răspuns precis, dar clar prezentat.
- Implicații ale costurilor: Obținerea evaluărilor umane de top este costisitoare. Cu cât este mai mare calitatea evaluării pe care o căutați, cu atât costurile asociate sunt mai mari.
- Constrângeri de timp: Colectarea evaluărilor umane necesită timp. În lumea rapidă a dezvoltării sistemelor bazate pe LLM, unde implementările pot avea loc în doar câteva zile sau săptămâni, dezvoltatorii nu își pot permite întotdeauna să întrerupă și să aștepte feedback.
Aceste constrângeri subliniază importanța completării evaluărilor umane cu tehnici de evaluare mai eficiente.
Auto-evaluare
Modelele lingvistice mari s-au dovedit capabile să evalueze performanța omologilor lor. În special, un LLM mai avansat sau mai mare poate fi utilizat pentru a evalua performanța modelelor mai mici. De asemenea, este obișnuit să utilizați un LLM pentru a-și evalua propria rezultate. Având în vedere mecanica LLM-urilor, un model ar putea oferi inițial un răspuns incorect. Cu toate acestea, furnizând aceluiași model o solicitare creată strategic care solicită o evaluare a răspunsului său inițial, modelul are efectiv oportunitatea de a „reflecta” sau „regândi”. Această procedură crește substanțial probabilitatea ca modelul să identifice orice erori.
Utilizarea LLM-urilor pentru a evalua alte LLM-uri oferă o alternativă rapidă și rentabilă la angajarea evaluatorilor umani. Cu toate acestea, această metodă are capcane critice pe care liderii de afaceri și tehnologia trebuie să fie pregătiți să le abordeze:
- Atunci când au sarcina de a evalua un răspuns pe o scară de la 1 la 5, LLM-urile ar putea prezintă o părtinire consecventă spre o anumită evaluare, indiferent de calitatea reală a răspunsului.
- Când își compară propria producție cu cea a altor modele, un LLM în general manifestă o preferință pentru propriul răspuns.
- Secvențierea candidaților de răspuns poate ocazional influențează evaluarea, cum ar fi, de exemplu, demonstrarea unei preferințe pentru primul răspuns candidat afișat.
- LLM-urile tind să favorizează răspunsuri mai lungi, chiar dacă conțin erori de fapt sau sunt mai greu de înțeles și de utilizat de către utilizatorii umani.
Având în vedere imperfecțiunile inerente evaluărilor LLM, încorporarea strategică a supravegherii manuale de către evaluatorii umani rămâne un pas recomandabil și nu trebuie omis din procesul dumneavoastră de dezvoltare a aplicației LLM.
Abordare hibridă
Abordarea predominantă este ca dezvoltatorii să se bazeze foarte mult pe evaluările automate facilitate de LLM. Acest lucru le echipează cu un mecanism de feedback imediat, permițând selecția rapidă a modelului, reglarea fină și experimentarea cu solicitări variate ale sistemului. Scopul este realizarea unui sistem performant bazat pe aceste evaluari automate. Odată ce faza de evaluare automată este finalizată, următorul pas implică de obicei o scufundare mai profundă cu evaluatori umani de înaltă calitate pentru a valida fiabilitatea autoevaluării.
Asigurarea unor evaluări umane de înaltă calitate poate fi un efort costisitor. Deși nu este pragmatic să se recurgă la acest nivel de control după fiecare rafinare minoră a sistemului, evaluarea umană este o fază indispensabilă înainte de tranziția unui sistem LLM într-un mediu de producție. După cum sa menționat mai devreme, evaluările de la LLM-uri pot manifesta părtiniri și nu pot fi de încredere.
După implementare, este esențial să colectăm feedback autentic de la utilizatorii finali ai aplicațiilor noastre bazate pe LLM. Feedback-ul poate fi la fel de simplu ca ai face utilizatorii să evalueze un răspuns ca fiind util (degetul în sus) sau neutil (degetul în jos), dar în mod ideal ar trebui să fie însoțit de comentarii detaliate care evidențiază punctele forte și deficiențele răspunsurilor modelului.
Actualizările de bază ale modelului sau schimbările în interogările utilizatorilor pot degrada din greșeală performanța aplicației dvs. sau pot expune punctele slabe latente. Monitorizarea continuă a performanței aplicației LLM în raport cu criteriile noastre definite rămâne critică pe tot parcursul vieții sale operaționale, astfel încât să puteți identifica și aborda rapid deficiențele emergente. .
Intrebari cu cheie
Evaluarea performanței sistemelor bazate pe LLM prezintă provocări unice, deosebind sarcina de evaluările convenționale de învățare automată. În procesul de evaluare a unui sistem LLM, trebuie luate în considerare următoarele considerații critice pentru a vă informa metodologia:
- Seturi de evaluare personalizate: Pentru a obține informații utile, este imperativ să construiți seturi de evaluare robuste, centrate pe aplicații. Aceste seturi nu trebuie neapărat să fie mari, dar ar trebui să cuprindă o gamă largă de mostre provocatoare.
- Extinderea dinamică a provocărilor de evaluare: Pe măsură ce primiți feedback de la utilizatori, este esențial să extindeți și să rafinați în mod iterativ setul de evaluare pentru a surprinde provocările și nuanțele în evoluție.
- Metrici cantitative și criterii calitative: Natura complicată a LLM-urilor eludează adesea valorile cantitative simple. Este esențial să stabiliți un set de criterii adaptate cazului dumneavoastră de utilizare specific, permițând o evaluare mai nuanțată a performanței modelului.
- Funcția de feedback unificat: Pentru a simplifica procesul de evaluare, luați în considerare combinarea mai multor criterii într-o funcție de feedback unică și coerentă.
- Abordarea de evaluare hibridă: Utilizarea atât a LLM-urilor, cât și a evaluatorilor umani de înaltă calitate în procesul dvs. de evaluare oferă o perspectivă mai cuprinzătoare și oferă cele mai fiabile și mai rentabile rezultate.
- Monitorizare continuă a lumii reale: Prin îmbinarea feedback-ului utilizatorului cu funcția de feedback unificat, puteți monitoriza și ajusta în permanență performanța LLM, asigurând alinierea consecventă la cerințele din lumea reală.
Bucurați-vă de acest articol? Înscrieți-vă pentru mai multe actualizări ale cercetării AI.
Vă vom anunța când vom lansa mai multe articole sumare ca acesta.
Legate de
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. Automobile/VE-uri, carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- ChartPrime. Crește-ți jocul de tranzacționare cu ChartPrime. Accesați Aici.
- BlockOffsets. Modernizarea proprietății de compensare a mediului. Accesați Aici.
- Sursa: https://www.topbots.com/llm-performance-evaluation/
- :are
- :este
- :nu
- :Unde
- $UP
- 1
- 10
- a
- Despre Noi
- acceptabil
- însoțit
- Cont
- precizie
- precis
- Obține
- dobândirea
- curent
- adresa
- avansat
- Avantajele
- După
- împotriva
- agregat
- AI
- cercetare ai
- Permiterea
- singur
- de asemenea
- alternativă
- mereu
- an
- și
- O alta
- răspunde
- răspunsuri
- Orice
- separat
- aplicație
- Dezvoltare de Aplicații
- aplicatii
- abordare
- abordari
- SUNT
- articol
- bunuri
- AS
- evalua
- evaluare
- asociate
- At
- atribute
- Automata
- Automat
- disponibil
- in medie
- astept
- de bază
- bazat
- BE
- înainte
- Dincolo de
- distorsiunilor
- rapeluri
- Bot
- atât
- larg
- Clădire
- afaceri
- dar
- by
- CAN
- candidat
- candidaţilor
- Capacitate
- captura
- caz
- cazuri
- prins
- contesta
- provocări
- provocare
- chatbot
- Alege
- COERENT
- Colectare
- combinând
- vine
- comentarii
- Comun
- comparație
- compararea
- Terminat
- cuprinzător
- Lua în considerare
- Considerații
- consistent
- constrângeri
- construi
- continuu
- convențional
- Nucleu
- corecta
- cost-eficiente
- costisitor
- Cheltuieli
- ar putea
- acoperire
- crea
- Criteriile de
- critic
- crucial
- Curent
- personalizat
- client
- Relații Clienți
- Zi
- adânc
- Mai adânc
- Mod implicit
- definit
- definitiv
- demonstrând
- desfășurarea
- implementări
- proiectat
- modele
- detaliat
- Dezvoltatorii
- Dezvoltare
- diferit
- afișat
- distinct
- Nu
- domeniu
- Dont
- jos
- dezavantaje
- două
- dinamic
- e
- fiecare
- Mai devreme
- în mod eficient
- eficient
- oricare
- element
- șmirghel
- scoate in evidenta
- permițând
- înconjura
- încerca
- asigură
- asigurare
- Afacere
- Mediu inconjurator
- Erori
- esenţă
- esenţial
- stabili
- Eter (ETH)
- evalua
- evaluarea
- evaluare
- evaluări
- Chiar
- Fiecare
- evoluție
- exemplu
- exemple
- Excel
- executat
- exista
- Extinde
- expansiune
- scump
- experimental
- facilitat
- faptic
- Falter
- ritm rapid
- favoriza
- realizabil
- feedback-ul
- puțini
- First
- Concentra
- următor
- Pentru
- format
- frecvent
- prietenos
- din
- funcţie
- În plus
- aduna
- General
- în general
- genera
- generată
- veritabil
- obține
- dat
- scop
- Aur
- Gold Standard
- În creştere
- garanta
- întâmpla
- Mai tare
- Cablaje
- Avea
- având în
- puternic
- de înaltă calitate
- superior
- subliniind
- holistică
- Cum
- Cum Pentru a
- Totuși
- HTTPS
- uman
- Hibrid
- i
- ideal
- ideal
- identifica
- identificarea
- if
- imediat
- imperativ
- punerea în aplicare a
- importanță
- impresionant
- in
- include
- inclus
- indică
- Informa
- inerent
- inițială
- inițial
- intrare
- intrări
- perspective
- instanță
- integrate
- intern
- în
- IT
- ESTE
- în sine
- jpg
- Cheie
- Cunoaște
- limbă
- mare
- mai mare
- Liderii
- învăţare
- cel mai puțin
- Nivel
- Pârghie
- efectului de pârghie
- Viaţă
- ciclu de viață
- ca
- probabilitate
- limitări
- LLP
- mai lung
- maşină
- masina de învățare
- mentine
- manual
- materie
- max-width
- Mai..
- mecanic
- mecanică
- mecanism
- medical
- Mers
- care fuzionează
- Metadata
- metodă
- Metodologie
- Metode
- meticulos
- Metrici
- ar putea
- minor
- derutant
- ML
- model
- Modele
- monitor
- Monitorizarea
- mai mult
- mai eficient
- cele mai multe
- multiplu
- trebuie sa
- Natură
- în mod necesar
- Nevoie
- Nou
- următor
- în special
- notat
- Obiectivele
- of
- promoții
- de multe ori
- on
- dată
- ONE
- în curs de desfășurare
- funcionar
- operațional
- Oportunitate
- optimă
- or
- Altele
- al nostru
- rezultate
- producție
- peste
- Supraveghere
- propriu
- perechi
- Suprem
- special
- pauză
- performanță
- efectuarea
- perspectivă
- fază
- Plato
- Informații despre date Platon
- PlatoData
- practică
- pragmatic
- pregătit
- prezenta
- prezentat
- cadouri
- Prioritizarea
- procedură
- proces
- procese
- produce
- producere
- Proiecte
- dovedit
- furniza
- Q & A
- calitativ
- calităţi
- calitate
- cantitativ
- interogări
- Întrebări
- repede
- gamă
- rată
- mai degraba
- evaluare
- lumea reală
- tărâm
- a primi
- rafina
- Fără deosebire
- Inregistreaza-te
- eliberaţi
- încredere
- de încredere
- bazându-se
- rămășițe
- reprezentant
- cereri de
- necesita
- Cerinţe
- Necesită
- cercetare
- Resort
- răspuns
- răspunsuri
- REZULTATE
- dezvaluie
- riguros
- robust
- Alerga
- acelaşi
- Scară
- scenarii
- scor
- control
- Căuta
- selectarea
- selecţie
- secvențiere
- set
- Seturi
- instalare
- setări
- Ture
- deficiențe
- să
- semna
- simplu
- simplifica
- singular
- mai mici
- So
- Numai
- unele
- specific
- Spectru
- standard
- Începe
- Pas
- paşi
- Încă
- simplu
- Strategic
- Strategic
- simplifica
- puncte forte
- subiect
- substanţial
- astfel de
- REZUMAT
- superior
- a sustine
- SWIFT
- sistem
- sisteme
- adaptate
- Lua
- luate
- Tandem
- Ţintă
- vizate
- Sarcină
- echipă
- Tehnic
- tehnici de
- Tehnologia
- test
- Testarea
- acea
- lor
- Lor
- apoi
- Acolo.
- Acestea
- ei
- acest
- Prin
- de-a lungul
- consumă timp
- ori
- la
- TONE
- TOPBOTS
- față de
- tradiţional
- tranziția
- tipic
- înţelege
- înţelegere
- Neașteptat
- neprevăzut
- unificat
- unic
- spre deosebire de
- imprevizibil
- actualizări
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizatorii
- folosind
- obișnuit
- folosi
- utilizate
- VALIDA
- varietate
- de
- vizualizate
- we
- web
- dezvoltare web
- săptămâni
- cand
- dacă
- care
- în timp ce
- mai larg
- voi
- cu
- în
- fără
- muncitorii
- lume
- încă
- randamentele
- tu
- Ta
- zephyrnet