Pe măsură ce Roblox a crescut în ultimii 16+ ani, la fel a crescut și amploarea și complexitatea infrastructurii tehnice care acceptă milioane de experiențe 3D captivante. Numărul de mașini pe care le susținem s-a triplat în ultimii doi ani, de la aproximativ 36,000 la 30 iunie 2021 la aproape 145,000 în prezent. Sprijinirea acestor experiențe mereu active pentru oameni din întreaga lume necesită mai mult de 1,000 de servicii interne. Pentru a ne ajuta să controlăm costurile și latența rețelei, implementăm și gestionăm aceste mașini ca parte a unei infrastructuri de cloud private hibride personalizate, care rulează în principal la sediul.
Infrastructura noastră acceptă în prezent peste 70 de milioane de utilizatori activi zilnic din întreaga lume, inclusiv creatorii care se bazează pe Roblox. economie pentru afacerile lor. Toate aceste milioane de oameni se așteaptă la un nivel foarte ridicat de fiabilitate. Având în vedere natura captivantă a experiențelor noastre, există o toleranță extrem de scăzută pentru întârzieri sau latență, ca să nu mai vorbim de întreruperi. Roblox este o platformă de comunicare și conexiune, în care oamenii se reunesc în experiențe 3D captivante. Când oamenii comunică ca avatarurile lor într-un spațiu captivant, chiar și întârzierile minore sau erorile sunt mai vizibile decât într-un fir de text sau într-un apel conferință.
În octombrie 2021, am avut o întrerupere la nivel de sistem. A început mic, cu o problemă într-o singură componentă într-un singur centru de date. Dar s-a răspândit rapid pe măsură ce investigam și a dus, în cele din urmă, la o întrerupere de 73 de ore. La acea vreme, le împărtășeam pe amândouă detalii despre ceea ce s-a întâmplat și unele dintre învățăturile noastre timpurii din această problemă. De atunci, am studiat acele învățăminte și am lucrat pentru a crește rezistența infrastructurii noastre la tipurile de defecțiuni care apar în toate sistemele la scară largă din cauza unor factori precum vârfuri extreme de trafic, vreme, defecțiuni hardware, erori software sau doar oamenii fac greseli. Când apar aceste defecțiuni, cum ne asigurăm că o problemă dintr-o singură componentă sau un grup de componente nu se răspândește la întregul sistem? Această întrebare s-a concentrat în ultimii doi ani și, în timp ce munca este în desfășurare, ceea ce am făcut până acum dă roade. De exemplu, în prima jumătate a anului 2023, am economisit 125 de milioane de ore de implicare pe lună, comparativ cu prima jumătate a anului 2022. Astăzi, împărtășim munca pe care am făcut-o deja, precum și viziunea noastră pe termen lung pentru construirea un sistem de infrastructură mai rezistent.
Construirea unui backstop
În cadrul sistemelor de infrastructură la scară largă, defecțiunile la scară mică apar de multe ori pe zi. Dacă o mașină are o problemă și trebuie scoasă din funcțiune, acest lucru este ușor de gestionat, deoarece majoritatea companiilor mențin mai multe instanțe ale serviciilor lor back-end. Deci, atunci când o singură instanță eșuează, alții preiau volumul de lucru. Pentru a rezolva aceste eșecuri frecvente, solicitările sunt în general setate să reîncerce automat dacă primesc o eroare.
Acest lucru devine o provocare atunci când un sistem sau o persoană reîncearcă prea agresiv, ceea ce poate deveni o modalitate prin care acele eșecuri la scară mică se propagă în întreaga infrastructură la alte servicii și sisteme. Dacă rețeaua sau un utilizator reîncearcă suficient de persistent, va supraîncărca în cele din urmă fiecare instanță a serviciului respectiv și, eventual, alte sisteme, la nivel global. Întreruperea noastră din 2021 a fost rezultatul a ceva destul de comun în sistemele la scară largă: o defecțiune începe mic, apoi se propagă prin sistem, devenind atât de rapid încât este greu de rezolvat înainte ca totul să se defecteze.
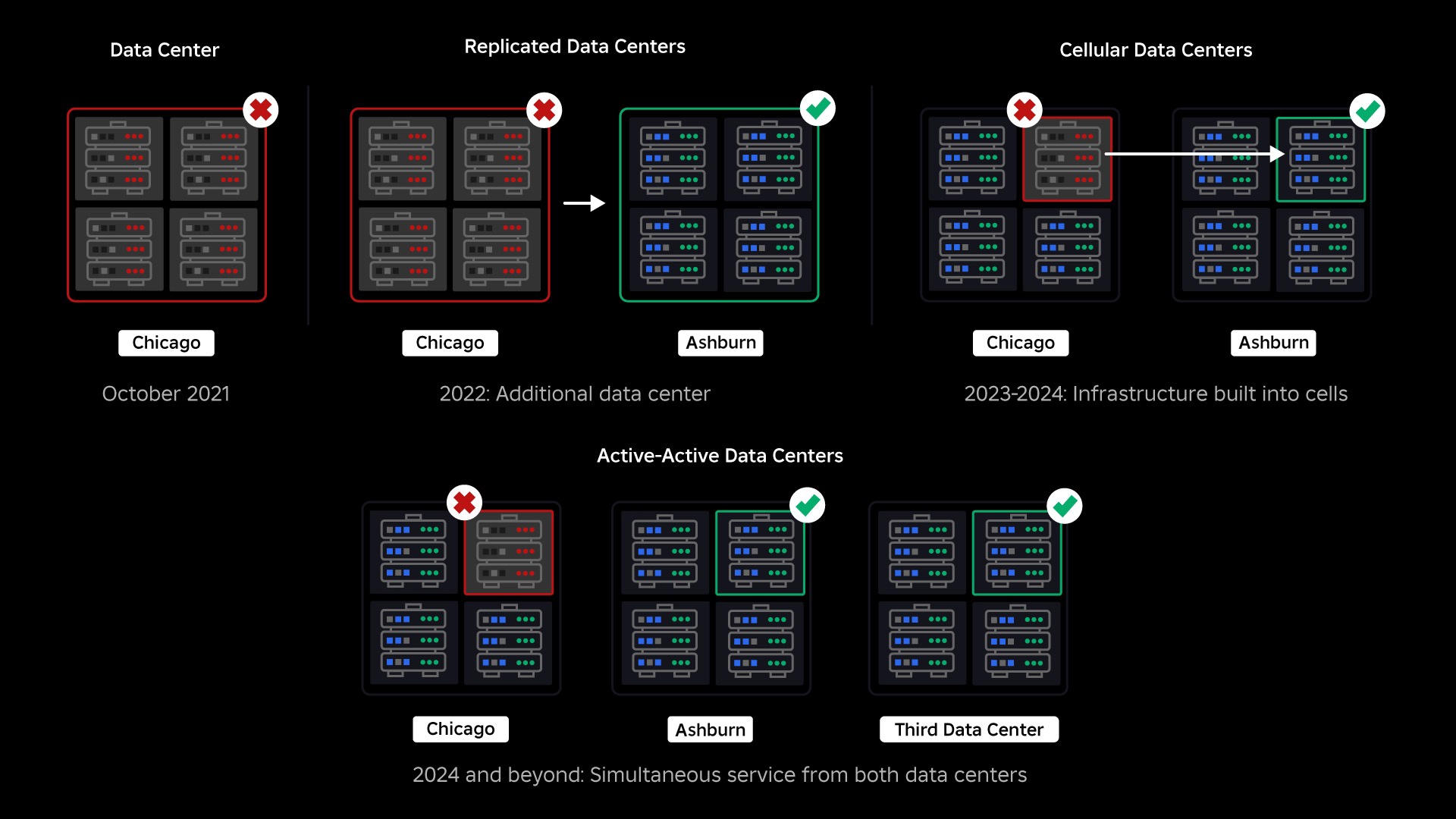
La momentul întreruperii noastre, aveam un centru de date activ (cu componentele din acesta acționând ca rezervă). Aveam nevoie de capacitatea de a trece manual la un nou centru de date atunci când o problemă îl distruge pe cel existent. Prima noastră prioritate a fost să ne asigurăm că avem o implementare de rezervă a Roblox, așa că am construit acel backup într-un nou centru de date, situat într-o regiune geografică diferită. Aceasta a adăugat protecție pentru cel mai rău caz: o întrerupere care se răspândește la suficiente componente dintr-un centru de date încât devine complet inoperabil. Avem acum un centru de date care gestionează sarcinile de lucru (activ) și unul în standby, care servește ca rezervă (pasiv). Scopul nostru pe termen lung este să trecem de la această configurație activ-pasivă la o configurație activ-activ, în care ambele centre de date gestionează sarcinile de lucru, cu un echilibrator de încărcare care distribuie cererile între ele în funcție de latență, capacitate și sănătate. Odată ce aceasta este pusă în aplicare, ne așteptăm să avem o fiabilitate și mai mare pentru toate Roblox și să putem reuși aproape instantaneu, mai degrabă decât peste câteva ore. 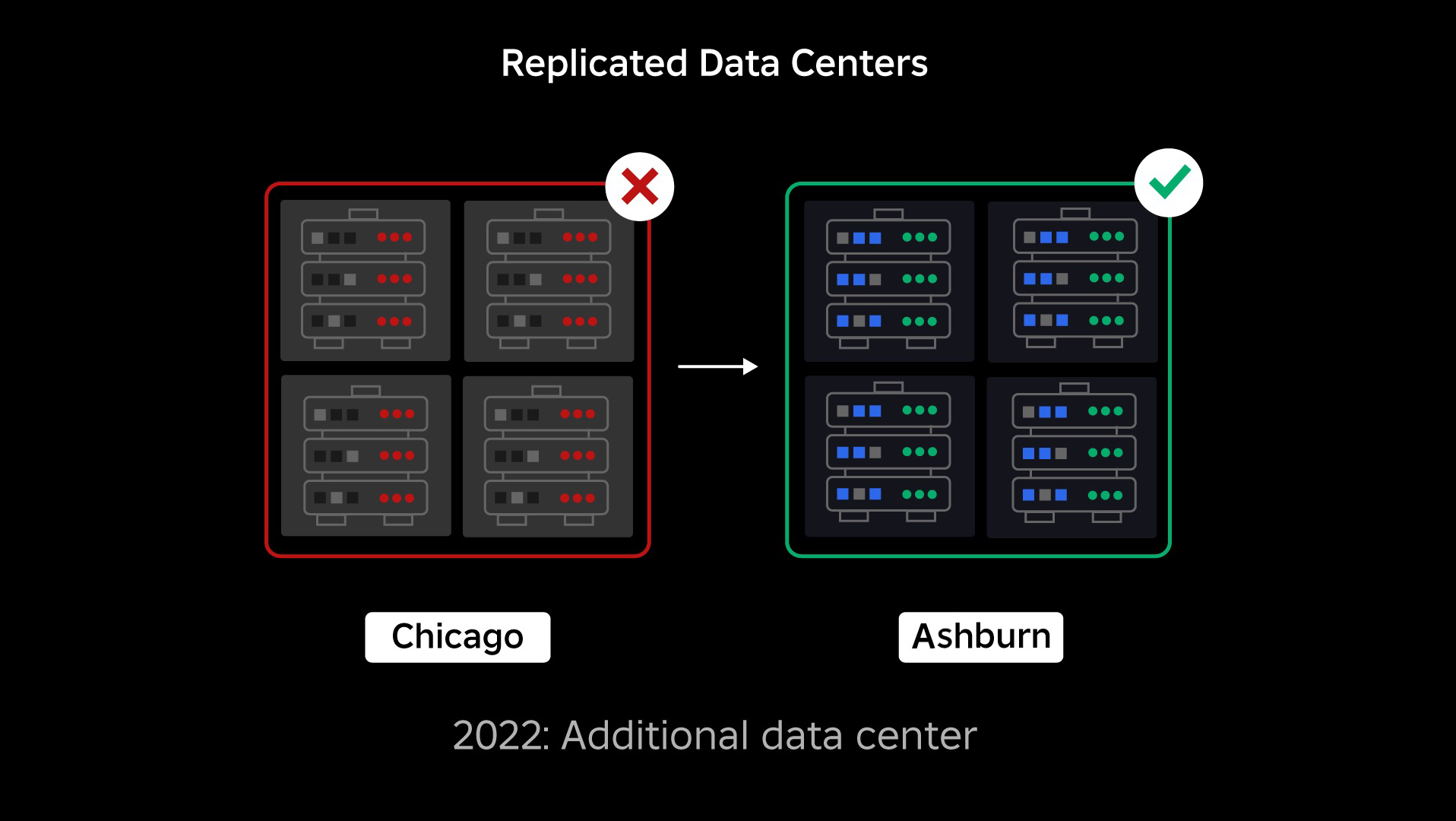
Trecerea la o infrastructură celulară
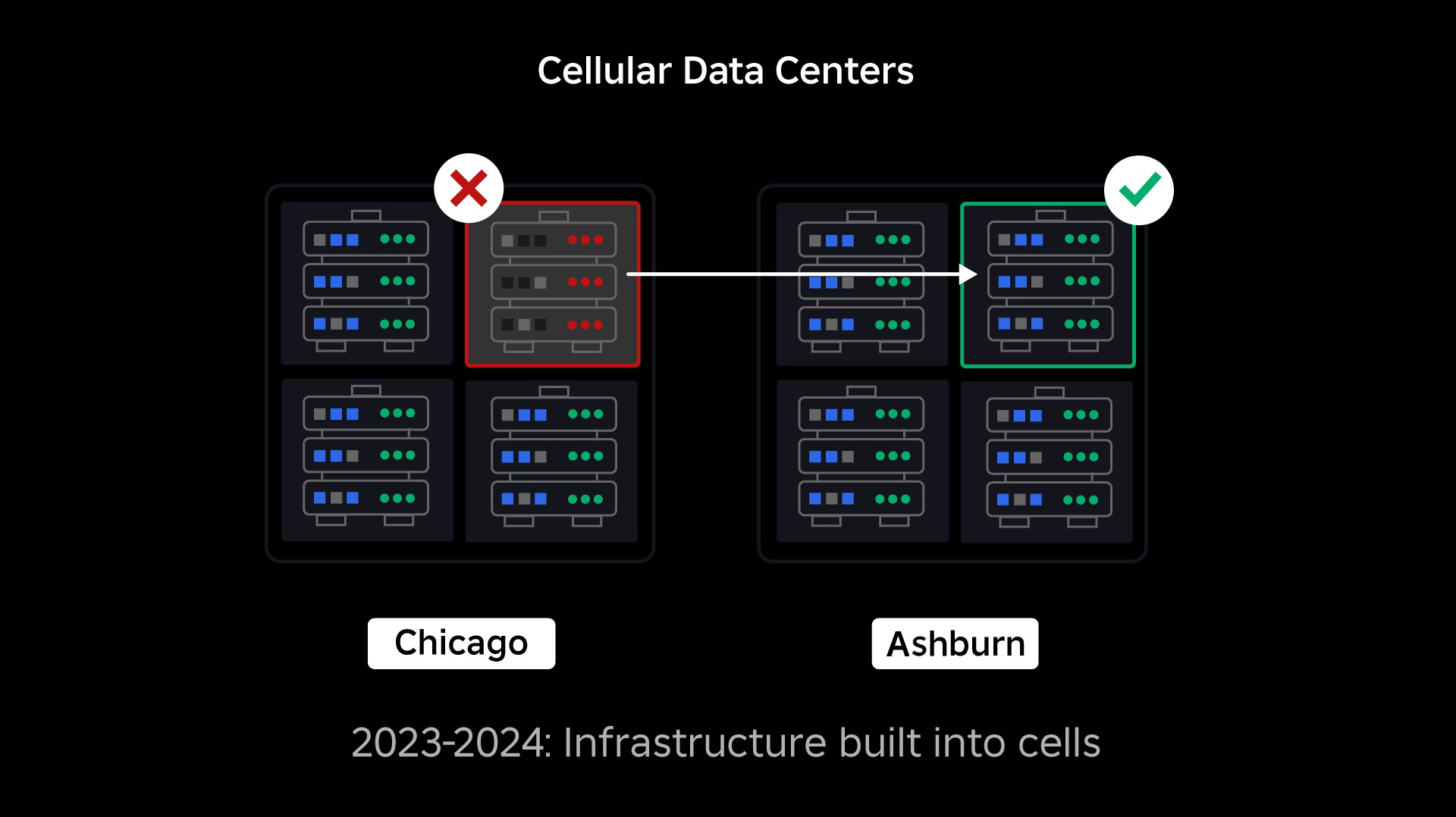
Următoarea noastră prioritate a fost să creăm ziduri puternice de explozie în interiorul fiecărui centru de date pentru a reduce posibilitatea ca un întreg centru de date să eșueze. Celulele (unele companii le numesc clustere) sunt în esență un set de mașini și sunt modul în care creăm acești pereți. Replicăm serviciile atât în interiorul celulelor, cât și între celule, pentru o redundanță suplimentară. În cele din urmă, dorim ca toate serviciile de la Roblox să ruleze în celule, astfel încât să poată beneficia atât de pereții puternici de explozie, cât și de redundanță. Dacă o celulă nu mai este funcțională, poate fi dezactivată în siguranță. Replicarea între celule permite serviciului să continue să ruleze în timp ce celula este reparată. În unele cazuri, repararea celulei poate însemna o reprovizionare completă a celulei. În industrie, ștergerea și reprovisionarea unei mașini individuale sau a unui set mic de mașini este destul de comună, dar a face acest lucru pentru o celulă întreagă, care conține ~ 1,400 de mașini, nu este.
Pentru ca acest lucru să funcționeze, aceste celule trebuie să fie în mare măsură uniforme, astfel încât să putem muta rapid și eficient sarcinile de lucru de la o celulă la alta. Am stabilit anumite cerințe pe care serviciile trebuie să le îndeplinească înainte de a rula într-o celulă. De exemplu, serviciile trebuie să fie containerizate, ceea ce le face mult mai portabile și împiedică pe oricine să facă modificări de configurare la nivelul sistemului de operare. Am adoptat o filozofie a infrastructurii ca cod pentru celule: în depozitul nostru de cod sursă, includem definiția a tot ceea ce se află într-o celulă, astfel încât să o putem reconstrui rapid de la zero folosind instrumente automate.
Nu toate serviciile îndeplinesc în prezent aceste cerințe, așa că ne-am străduit pentru a ajuta proprietarii de servicii să le îndeplinească acolo unde este posibil și am creat noi instrumente pentru a facilita migrarea serviciilor în celule atunci când sunt gata. De exemplu, noul nostru instrument de implementare „face” automat implementarea unui serviciu în celule, astfel încât proprietarii de servicii să nu fie nevoiți să se gândească la strategia de replicare. Acest nivel de rigoare face ca procesul de migrare să fie mult mai dificil și mai consumator de timp, dar rezultatul pe termen lung va fi un sistem în care:
- Este mult mai ușor să stăpânești o defecțiune și să previi răspândirea lui la alte celule;
- Inginerii noștri de infrastructură pot fi mai eficienți și se pot mișca mai repede; și
- Inginerii care construiesc serviciile la nivel de produs care sunt implementate în cele din urmă în celule nu trebuie să știe sau să își facă griji cu privire la celulele în care rulează serviciile lor.
Rezolvarea provocărilor mai mari
Similar cu modul în care ușile de incendiu sunt folosite pentru a ține flăcările, celulele acționează ca pereți puternici de explozie în cadrul infrastructurii noastre pentru a ajuta la limitarea oricărei probleme care declanșează o defecțiune într-o singură celulă. În cele din urmă, toate serviciile care compun Roblox vor fi implementate redundant în interiorul și între celule. Odată ce această lucrare este finalizată, problemele s-ar putea propaga suficient de larg pentru a face o celulă întreagă inoperabilă, dar ar fi extrem de dificil ca o problemă să se propagă dincolo de acea celulă. Și dacă reușim să facem celulele interschimbabile, recuperarea va fi semnificativ mai rapidă pentru că vom putea trece la o altă celulă și vom împiedica problema să afecteze utilizatorii finali.
Acolo unde acest lucru devine dificil este separarea acestor celule suficient pentru a reduce oportunitatea de a propaga erori, păstrând în același timp lucrurile performante și funcționale. Într-un sistem de infrastructură complex, serviciile trebuie să comunice între ele pentru a partaja interogări, informații, sarcini de lucru etc. Pe măsură ce replicăm aceste servicii în celule, trebuie să fim atenți la modul în care gestionăm comunicarea încrucișată. Într-o lume ideală, redirecționăm traficul de la o celulă nesănătoasă la alte celule sănătoase. Dar cum gestionăm o „interogare a morții” – una asta provocând o celulă să fie nesănătoasă? Dacă redirecționăm acea interogare către o altă celulă, aceasta poate provoca ca celula să devină nesănătoasă, exact așa cum încercăm să o evităm. Trebuie să găsim mecanisme pentru a deplasa traficul „bun” de la celulele nesănătoase în timp ce detectăm și reducem traficul care determină celulele să devină nesănătoase.
Pe termen scurt, am implementat copii ale serviciilor de calcul în fiecare celulă de calcul, astfel încât majoritatea solicitărilor către centrul de date să poată fi servite de o singură celulă. De asemenea, echilibrăm traficul dintre celule. Privind mai departe, am început să construim un proces de descoperire a serviciilor de ultimă generație, care va fi valorificat de o rețea de servicii, pe care sperăm să o finalizăm în 2024. Acest lucru ne va permite să implementăm politici sofisticate care vor permite comunicarea între celule numai atunci când nu va afecta negativ celulele de failover. De asemenea, în 2024 va fi o metodă de direcționare a cererilor dependente către o versiune de serviciu în aceeași celulă, care va minimiza traficul între celule și, prin urmare, va reduce riscul de propagare între celule a eșecurilor.
La vârf, peste 70% din traficul nostru de servicii back-end este deservit din celule și am învățat multe despre cum să creăm celule, dar anticipăm mai multe cercetări și teste pe măsură ce continuăm să migrăm serviciile noastre până în 2024 și dincolo. Pe măsură ce progresăm, acești pereți de explozie vor deveni din ce în ce mai puternici.
Migrarea unei infrastructuri mereu activate
Roblox este o platformă globală care sprijină utilizatorii din întreaga lume, așa că nu putem muta serviciile în afara orelor de vârf sau „în perioadele de întrerupere”, ceea ce complică și mai mult procesul de migrare a tuturor mașinilor noastre în celule și serviciile noastre să ruleze în acele celule. . Avem milioane de experiențe mereu activate care trebuie să fie susținute în continuare, chiar dacă mutăm mașinile pe care rulează și serviciile care le susțin. Când am început acest proces, nu aveam zeci de mii de mașini neutilizate și disponibile pentru a migra aceste sarcini de lucru.
Cu toate acestea, am avut un număr mic de mașini suplimentare care au fost achiziționate în așteptarea creșterii viitoare. Pentru început, am construit celule noi folosind acele mașini, apoi am migrat sarcinile de lucru către ele. Apreciem eficiența, precum și fiabilitatea, așa că, în loc să ieșim și să cumpărăm mai multe mașini odată ce am rămas fără mașini „de rezervă”, am construit mai multe celule ștergând și reprovisionând mașinile de pe care am migrat. Apoi am migrat sarcinile de lucru pe acele mașini reprovisionate și am început procesul din nou. Acest proces este complex – deoarece mașinile sunt înlocuite și eliberate pentru a fi integrate în celule, ele nu se eliberează într-un mod ideal, ordonat. Acestea sunt fragmentate fizic în sălile de date, lăsându-ne să le furnizăm în mod fragmentat, ceea ce necesită un proces de defragmentare la nivel hardware pentru a menține locațiile hardware aliniate cu domeniile de defecțiuni fizice la scară largă.
O parte a echipei noastre de inginerie de infrastructură se concentrează pe migrarea încărcăturilor de lucru existente din mediul nostru moștenit sau „pre-celulă” în celule. Această activitate va continua până când vom migra mii de servicii de infrastructură diferite și mii de servicii back-end în celule nou construite. Ne așteptăm ca acest lucru să dureze tot anul viitor și, eventual, până în 2025, din cauza unor factori complicati. În primul rând, această lucrare necesită unelte robuste pentru a fi construite. De exemplu, avem nevoie de instrumente pentru a reechilibra automat un număr mare de servicii atunci când implementăm o nouă celulă, fără a afecta utilizatorii noștri. Am văzut, de asemenea, servicii care au fost construite cu ipoteze despre infrastructura noastră. Trebuie să revizuim aceste servicii, astfel încât să nu depindă de lucruri care s-ar putea schimba în viitor pe măsură ce ne mutăm în celule. De asemenea, am implementat atât o modalitate de a căuta modele de design cunoscute care nu vor funcționa bine cu arhitectura celulară, cât și un proces metodic de testare pentru fiecare serviciu care este migrat. Aceste procese ne ajută să evităm orice problemă cu care se confruntă utilizatorii cauzate de incompatibilitatea unui serviciu cu celulele.
Astăzi, aproape 30,000 de mașini sunt gestionate de celule. Este doar o fracțiune din flota noastră totală, dar a fost o tranziție foarte ușoară până acum, fără impact negativ asupra jucătorilor. Scopul nostru final este ca sistemele noastre să atingă un timp de funcționare de 99.99% a utilizatorilor în fiecare lună, ceea ce înseamnă că nu vom întrerupe mai mult de 0.01% din orele de implicare. La nivelul întregii industrie, timpul de nefuncționare nu poate fi eliminat complet, dar scopul nostru este să reducem orice timp de nefuncționare Roblox într-o măsură în care să fie aproape de neobservat.
Pregătire pentru viitor pe măsură ce creștem
În timp ce eforturile noastre timpurii se dovedesc a fi de succes, munca noastră asupra celulelor este departe de a fi încheiată. Pe măsură ce Roblox continuă să se extindă, vom continua să lucrăm pentru a îmbunătăți eficiența și rezistența sistemelor noastre prin această și alte tehnologii. Pe măsură ce mergem, platforma va deveni din ce în ce mai rezistentă la probleme și orice probleme care apar ar trebui să devină din ce în ce mai puțin vizibile și perturbatoare pentru oamenii de pe platforma noastră.
Pe scurt, până în prezent, avem:
- Am construit un al doilea centru de date și am atins cu succes starea activă/pasivă.
- Am creat celule în centrele noastre de date active și pasive și am migrat cu succes peste 70% din traficul nostru de servicii back-end către aceste celule.
- Stabiliți cerințele și cele mai bune practici pe care va trebui să le respectăm pentru a menține toate celulele uniforme pe măsură ce continuăm să migrăm restul infrastructurii noastre.
- A început un proces continuu de construire a „pereților de explozie” mai puternici între celule.
Pe măsură ce aceste celule devin mai interschimbabile, va exista mai puțină diafonie între celule. Acest lucru deblochează câteva oportunități foarte interesante pentru noi în ceea ce privește creșterea automatizării în ceea ce privește monitorizarea, depanarea și chiar schimbarea automată a sarcinilor de lucru.
În septembrie, am început, de asemenea, să rulăm experimente active/active în centrele noastre de date. Acesta este un alt mecanism pe care îl testăm pentru a îmbunătăți fiabilitatea și a minimiza timpii de trecere la eroare. Aceste experimente au ajutat la identificarea unui număr de modele de proiectare a sistemului, în mare parte în jurul accesului la date, pe care trebuie să le reluăm pe măsură ce ne străduim să devenim complet activ-activ. În general, experimentul a avut un succes suficient pentru a-l lăsa în funcțiune pentru traficul de la un număr limitat de utilizatori.
Suntem încântați să continuăm să promovăm această activitate pentru a aduce o mai mare eficiență și rezistență platformei. Această activitate asupra celulelor și infrastructurii activ-activ, împreună cu celelalte eforturi ale noastre, ne va face posibil să creștem într-o utilitate fiabilă și performantă pentru milioane de oameni și să continuăm să ne extindem pe măsură ce lucrăm pentru a conecta un miliard de oameni în mod real. timp.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- :are
- :este
- :nu
- :Unde
- $UP
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- capacitate
- Capabil
- Despre Noi
- acces
- Obține
- realizat
- peste
- act
- actorie
- activ
- adăugat
- Suplimentar
- adresa
- adoptată
- din nou
- agresiv
- aliniat
- TOATE
- permite
- singur
- de-a lungul
- deja
- de asemenea
- an
- și
- O alta
- anticipa
- anticipare
- Orice
- oricine
- aproximativ
- arhitectură
- SUNT
- în jurul
- AS
- ipoteze
- At
- Automata
- în mod automat
- Automatizare
- disponibil
- Avatare
- evita
- Back-end
- Backup
- echilibrist
- de echilibrare
- bazat
- BE
- deoarece
- deveni
- devine
- devenire
- fost
- înainte
- început
- fiind
- beneficia
- CEL MAI BUN
- Cele mai bune practici
- între
- Dincolo de
- Mare
- mai mare
- Miliard
- Blog
- atât
- aduce
- adus
- gandaci
- construi
- Clădire
- construit
- întreprinderi
- dar
- Cumpărare
- by
- apel
- CAN
- nu poti
- Capacitate
- cazuri
- Provoca
- cauzată
- provocând
- celulă
- Celule
- celular
- Centru
- Centre
- sigur
- provocare
- Schimbare
- Modificări
- Închide
- Cloud
- infrastructura cloud
- cod
- cum
- venire
- Comun
- comunica
- comunicarea
- Comunicare
- Companii
- comparație
- Completă
- complet
- complex
- complexitate
- component
- componente
- Calcula
- tehnica de calcul
- Conferință
- Configuraţie
- Conectați
- conexiune
- conţine
- conține
- continua
- continuă
- continuu
- Control
- copii
- Cheltuieli
- ar putea
- crea
- Crearea
- Creatorii
- În prezent
- Personalizat-a construit
- zilnic
- de date
- accesul la date
- Data Center
- centre de date
- Data
- zi
- definiție
- Grad
- întârzieri
- depinde
- Dependent/ă
- implementa
- dislocate
- desfășurarea
- Amenajări
- modele de design
- FĂCUT
- diferit
- dificil
- călăuzitor
- descoperire
- distruge
- brizant
- distribuire
- do
- face
- face
- domenii
- făcut
- Dont
- Uși
- jos
- nefuncționare
- conducere
- două
- în timpul
- fiecare
- Devreme
- mai ușor
- uşor
- eficiență
- eficient
- eficient
- Eforturile
- eliminat
- permite
- capăt
- angajament
- Inginerie
- inginerii
- suficient de
- asigura
- Întreg
- în întregime
- Mediu inconjurator
- eroare
- Erori
- În esență,
- etc
- Chiar
- în cele din urmă
- Fiecare
- tot
- exemplu
- excitat
- existent
- aștepta
- cu experienţă
- Experiențe
- experiment
- experimente
- extremă
- extrem
- factori
- FAIL
- în lipsa
- eșuează
- Eșec
- eşecuri
- destul de
- departe
- Modă
- mai repede
- Găsi
- Incendiu
- First
- FLOTA
- Concentra
- concentrat
- urma
- Pentru
- Înainte
- fracțiune
- fragmentată
- Gratuit
- frecvent
- din
- Complet
- complet
- funcțional
- mai mult
- viitor
- creșterea viitoare
- în general
- geografic
- obține
- obtinerea
- dat
- Caritate
- La nivel global
- Go
- scop
- Merge
- merge
- mai mare
- grup
- Crește
- crescut
- Creștere
- HAD
- Jumătate
- manipula
- Manipularea
- întâmpla
- Greu
- Piese metalice
- Avea
- cap
- Sănătate
- sănătos
- ajutor
- a ajutat
- Înalt
- superior
- speranţă
- ORE
- Cum
- Cum Pentru a
- Totuși
- HTTPS
- Oamenii
- Hibrid
- ideal
- identifica
- if
- captivantă
- Impactul
- impact
- punerea în aplicare a
- implementat
- îmbunătăţi
- in
- include
- Inclusiv
- incompatibil
- Crește
- crescând
- tot mai mult
- individ
- industrie
- informații
- Infrastructură
- în interiorul
- instanță
- cazuri
- instantaneu
- interesant
- intern
- în
- problema
- probleme de
- IT
- iunie
- doar
- A pastra
- păstrare
- Cunoaște
- cunoscut
- mare
- pe scară largă
- în mare măsură
- Latență
- învățat
- Părăsi
- lăsând
- Moştenire
- mai puțin
- lăsa
- Nivel
- efectul de levier
- ca
- Limitat
- încărca
- situat
- Locații
- pe termen lung
- mai lung
- cautati
- Lot
- Jos
- maşină
- Masini
- menține
- face
- FACE
- Efectuarea
- administra
- gestionate
- manual
- multe
- max-width
- însemna
- sens
- mecanism
- mecanisme
- Întâlni
- ochiurilor de plasă
- metodă
- metodic
- ar putea
- migra
- migrată
- Migrarea
- migrațiune
- milion
- milioane
- minimaliza
- minor
- greşeli
- Monitorizarea
- Lună
- mai mult
- mai eficient
- cele mai multe
- muta
- mult
- multiplu
- trebuie sa
- Natură
- aproape
- Nevoie
- necesar
- negativ
- negativ
- reţea
- Nou
- recent
- următor
- generație următoare
- Nu.
- acum
- număr
- numere
- avea loc
- octombrie
- of
- de pe
- on
- dată
- ONE
- în curs de desfășurare
- afară
- Oportunităţi
- Oportunitate
- or
- OS
- Altele
- Altele
- al nostru
- afară
- pană
- Întreruperile
- peste
- global
- Proprietarii
- parte
- pasiv
- trecut
- modele
- de plată
- Vârf
- oameni
- pentru
- la sută
- efectuarea
- persistent
- persoană
- filozofie
- fizic
- Fizic
- alege
- Loc
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- player
- Politicile
- portabil
- porţiune
- posibilitate
- posibil
- eventual
- potenţial
- practicile
- împiedica
- previne
- în primul rând
- prioritate
- privat
- proces
- procese
- Progres
- progresiv
- propagare
- protecţie
- dovedind
- dispoziţie
- cumparate
- Împinge
- interogări
- întrebare
- repede
- mai degraba
- gata
- real
- în timp real
- reechilibreze
- recuperare
- redirecționa
- reduce
- regiune
- încredere
- de încredere
- se bazează
- repara
- înlocuiește
- replică
- depozit
- cereri de
- Cerinţe
- Necesită
- cercetare
- elasticitate
- elastic
- rezolvă
- REST
- rezultat
- a rezultat
- revizui
- Risc
- Roblox
- robust
- Alerga
- funcţionare
- ruleaza
- în siguranță
- acelaşi
- salvate
- Scară
- scenariu
- zgâria
- Caută
- Al doilea
- văzut
- separând
- Septembrie
- servit
- serviciu
- Servicii
- servire
- set
- câteva
- Distribuie
- comun
- partajarea
- schimbare
- SCHIMBARE
- Pantaloni scurți
- să
- semnificativ
- întrucât
- singur
- Ședință
- mic
- netezi
- So
- până acum
- Software
- unele
- ceva
- sofisticat
- Sursă
- cod sursă
- Spaţiu
- piroane
- răspândire
- răspândire
- Începe
- început
- începe
- Stare
- Încă
- Strategie
- puternic
- puternic
- Studiu
- reuși
- de succes
- Reușit
- REZUMAT
- a sustine
- Suportat
- De sprijin
- Sprijină
- sistem
- sisteme
- Lua
- luate
- echipă
- Tehnic
- Tehnologii
- zeci
- durată
- termeni
- Testarea
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- decât
- acea
- Viitorul
- lumea
- lor
- Lor
- apoi
- Acolo.
- astfel
- Acestea
- ei
- lucruri
- crede
- acest
- aceste
- mii
- Prin
- de-a lungul
- timp
- ori
- la
- astăzi
- împreună
- toleranță
- de asemenea
- instrument
- Unelte
- Total
- spre
- trafic
- tranziţie
- declanșând
- încercat
- Două
- Tipuri
- final
- în cele din urmă
- deblochează
- până la
- nefolosit
- pe
- uptime
- us
- utilizat
- Utilizator
- utilizatorii
- folosind
- utilitate
- valoare
- versiune
- foarte
- vizibil
- viziune
- vrea
- a fost
- Cale..
- we
- Vreme
- BINE
- au fost
- Ce
- indiferent de
- cand
- care
- în timp ce
- OMS
- larg
- voi
- șters
- cu
- în
- Apartamente
- a lucrat
- de lucru
- lume
- face griji
- ar
- an
- ani
- zephyrnet