Imagine de autor
Scufundându-vă în lumea științei datelor și a învățării automate, una dintre abilitățile fundamentale pe care le veți întâlni este arta de a citi datele. Dacă aveți deja ceva experiență cu el, probabil că sunteți familiarizat cu JSON (JavaScript Object Notation) – un format popular atât pentru stocarea, cât și pentru schimbul de date.
Gândiți-vă la modul în care bazele de date NoSQL precum MongoDB adoră să stocheze date în JSON sau la modul în care API-urile REST răspund adesea în același format.
Cu toate acestea, JSON, deși perfect pentru stocare și schimb, nu este destul de pregătit pentru o analiză aprofundată în forma sa brută. Aici îl transformăm în ceva mai prietenos din punct de vedere analitic – un format tabelar.
Așadar, indiferent dacă aveți de-a face cu un singur obiect JSON sau cu o serie încântătoare a acestora, în termenii lui Python, vă ocupați în esență de un dict sau o listă de dict.
Să explorăm împreună cum se desfășoară această transformare, făcând datele noastre coapte pentru analiză ????
Astăzi voi explica o comandă magică care ne permite să analizăm cu ușurință orice JSON într-un format tabelar în câteva secunde.
Și este... pd.json_normalize()
Deci, să vedem cum funcționează cu diferite tipuri de JSON.
Primul tip de JSON cu care putem lucra sunt JSON-urile cu un singur nivel, cu câteva chei și valori. Definim primele noastre JSON simple după cum urmează:
Cod de autor
Deci, să simulăm necesitatea de a lucra cu aceste JSON. Știm cu toții că nu sunt multe de făcut în formatul lor JSON. Trebuie să transformăm aceste JSON într-un format care poate fi citit și modificabil... ceea ce înseamnă Pandas DataFrames!
1.1 Gestionarea structurilor JSON simple
Mai întâi, trebuie să importam biblioteca panda și apoi putem folosi comanda pd.json_normalize(), după cum urmează:
import pandas as pd
pd.json_normalize(json_string)
Aplicând această comandă unui JSON cu o singură înregistrare, obținem cel mai simplu tabel. Cu toate acestea, atunci când datele noastre sunt puțin mai complexe și prezintă o listă de JSON, putem folosi în continuare aceeași comandă fără alte complicații, iar rezultatul va corespunde unui tabel cu mai multe înregistrări.

Imagine de autor
Ușor... nu?
Următoarea întrebare naturală este ce se întâmplă atunci când unele dintre valori lipsesc.
1.2 Tratarea valorilor nule
Imaginați-vă că unele dintre valori nu sunt informate, cum ar fi, de exemplu, înregistrarea veniturilor pentru David lipsește. Când ne transformăm JSON într-un cadru de date simplu panda, valoarea corespunzătoare va apărea ca NaN.
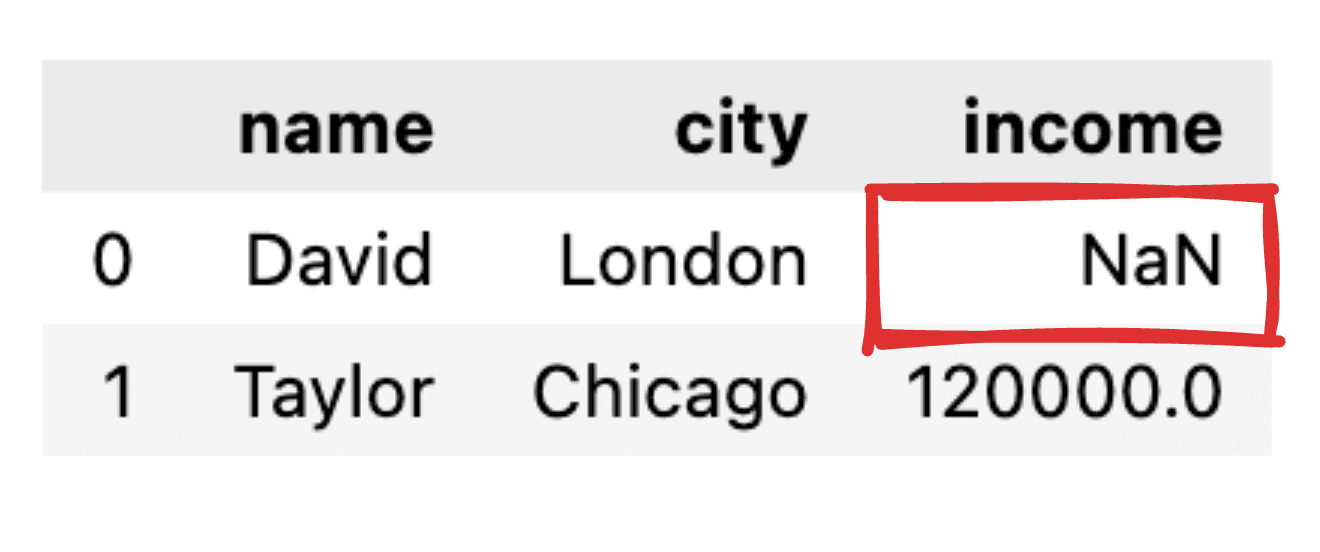
Imagine de autor
Și ce zici dacă vreau să iau doar câteva dintre câmpuri?
1.3 Selectarea numai a acelor coloane de interes
În cazul în care dorim doar să transformăm anumite câmpuri într-un DataFrame tabelar pandas, comanda json_normalize() nu ne permite să alegem ce câmpuri să transformăm.
Prin urmare, ar trebui efectuată o mică preprocesare a JSON în care filtrăm doar acele coloane de interes.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Deci, să trecem la o structură JSON mai avansată.
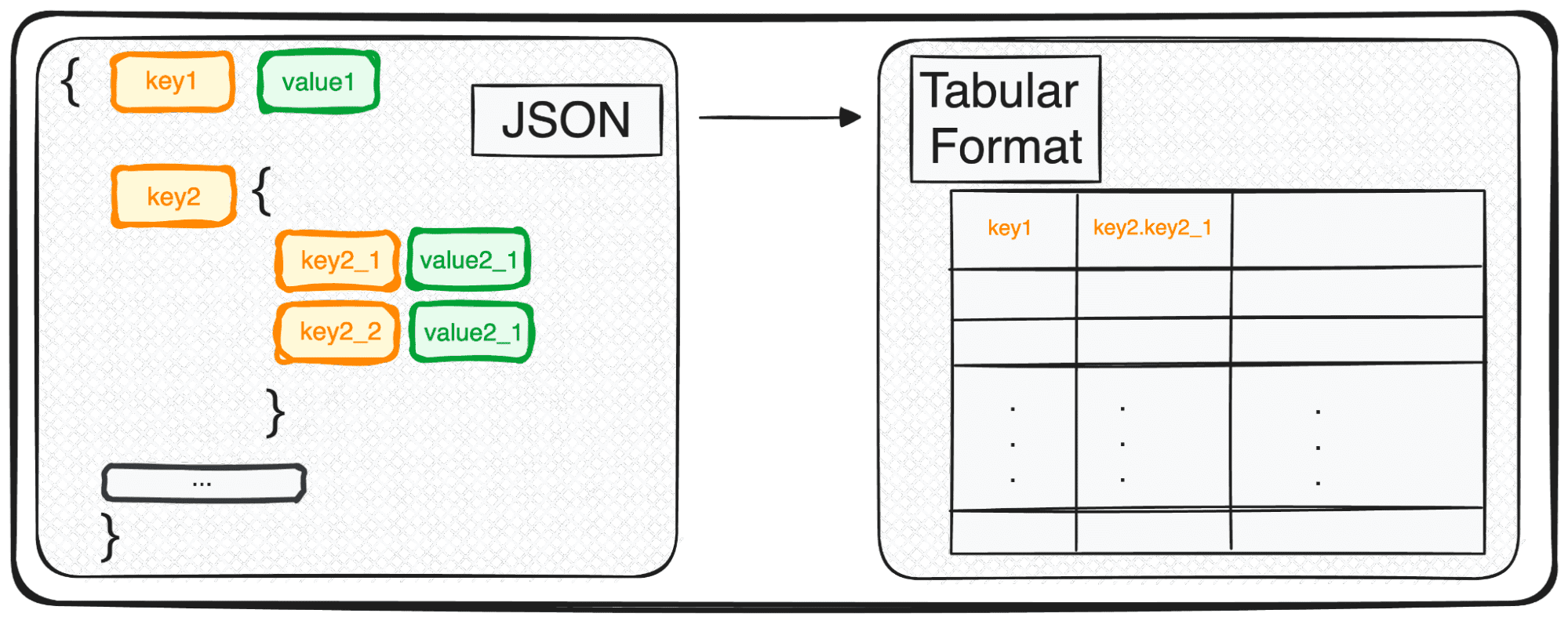
Când avem de-a face cu JSON-uri cu mai multe niveluri, ne aflăm cu JSON-uri imbricate în diferite niveluri. Procedura este aceeași ca înainte, dar în acest caz, putem alege câte niveluri vrem să transformăm. În mod implicit, comanda va extinde întotdeauna toate nivelurile și va genera coloane noi care conțin numele concatenat al tuturor nivelurilor imbricate.
Deci, dacă normalizăm următoarele JSON-uri.
Cod de autor
Am obține următorul tabel cu 3 coloane sub competențele de teren:
- aptitudini.python
- aptitudini.SQL
- aptitudini.GCP
și 4 coloane sub rolurile de câmp
- roluri.şef de proiect
- roluri.inginer de date
- roluri.scientist de date
- roluri.analist de date

Imagine de autor
Cu toate acestea, imaginați-vă că vrem doar să ne transformăm nivelul superior. Putem face acest lucru definind în mod specific parametrul max_level la 0 (max_level pe care dorim să-l extindem).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
Valorile în așteptare vor fi menținute în JSON-uri din cadrul nostru de date Pandas.
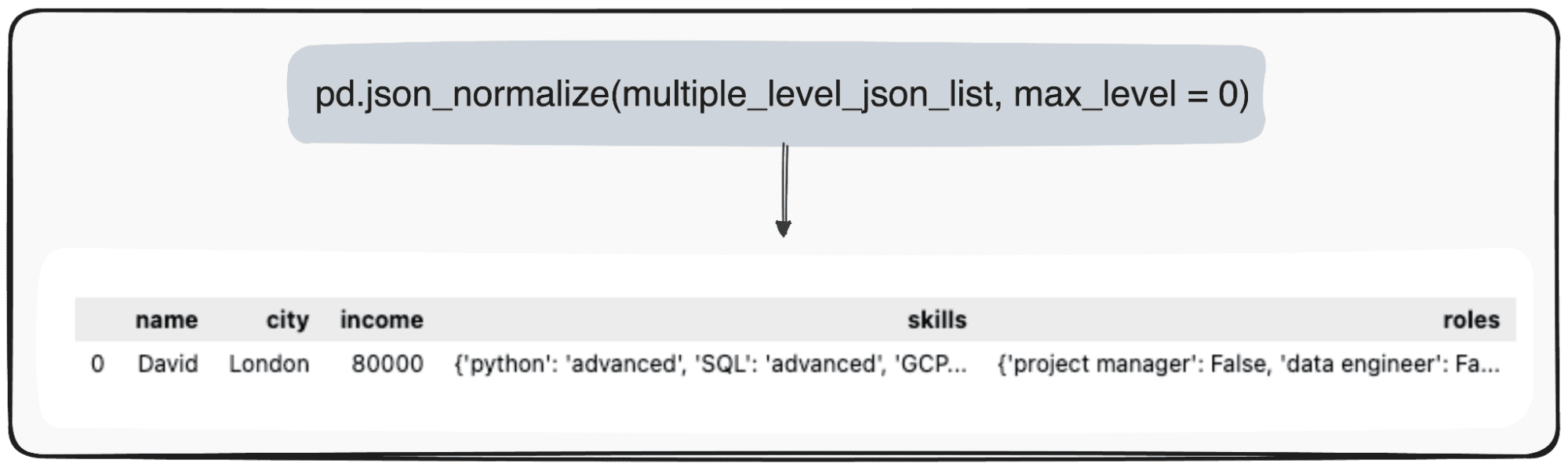
Imagine de autor
Ultimul caz pe care îl putem găsi este acela de a avea o listă imbricată într-un câmp JSON. Deci, definim mai întâi JSON-urile noastre de utilizat.
Cod de autor
Putem gestiona eficient aceste date folosind Pandas în Python. Funcția pd.json_normalize() este deosebit de utilă în acest context. Poate aplatiza datele JSON, inclusiv lista imbricată, într-un format structurat adecvat pentru analiză. Când această funcție este aplicată datelor noastre JSON, produce un tabel normalizat care încorporează lista imbricată ca parte a câmpurilor sale.
Mai mult, Pandas oferă capacitatea de a perfecționa și mai mult acest proces. Utilizând parametrul record_path din pd.json_normalize(), putem direcționa funcția pentru a normaliza în mod specific lista imbricată.
Această acțiune are ca rezultat un tabel dedicat exclusiv conținutului listei. În mod implicit, acest proces va desfășura doar elementele din listă. Cu toate acestea, pentru a îmbogăți acest tabel cu context suplimentar, cum ar fi păstrarea unui ID asociat pentru fiecare înregistrare, putem folosi meta parametrul.

Imagine de autor
În rezumat, transformarea datelor JSON în fișiere CSV folosind biblioteca Pandas de la Python este ușoară și eficientă.
JSON este încă cel mai comun format în stocarea și schimbul de date modern, în special în bazele de date NoSQL și API-urile REST. Cu toate acestea, prezintă câteva provocări analitice importante atunci când se ocupă de date în format brut.
Rolul esențial al pd.json_normalize() al lui Pandas apare ca o modalitate excelentă de a gestiona astfel de formate și de a converti datele noastre în Pandas DataFrame.
Sper că acest ghid a fost util, iar data viitoare când aveți de-a face cu JSON, o puteți face într-un mod mai eficient.
Puteți verifica notebook-ul Jupyter corespunzător în urmând depozitul GitHub.
Josep Ferrer este inginer analitic din Barcelona. A absolvit inginerie fizică și lucrează în prezent în domeniul Data Science aplicat mobilității umane. El este un creator de conținut part-time axat pe știința și tehnologia datelor. Îl poți contacta pe LinkedIn, Twitter or Mediu.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :este
- :nu
- :Unde
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- Despre Noi
- Acțiune
- Suplimentar
- avansat
- TOATE
- permite
- permite
- deja
- mereu
- an
- analiză
- analist
- analitic
- Google Analytics
- și
- Orice
- API-uri
- apărea
- aplicat
- Aplicarea
- SUNT
- Mulțime
- Artă
- AS
- asociate
- Barcelona
- de bază
- BE
- înainte
- Pic
- atât
- dar
- by
- CAN
- capacitate
- caz
- provocări
- verifica
- Alege
- Oraș
- Coloane
- Comun
- complex
- complicații
- contactați-ne
- conţinut
- conținut
- context
- converti
- de conversie a
- corespund
- Corespunzător
- creator
- În prezent
- de date
- analist de date
- inginer de date
- știința datelor
- om de știință de date
- stocare a datelor
- baze de date
- David
- abuzive
- dedicat
- Mod implicit
- defini
- definire
- încântător
- DICT
- diferit
- direcționa
- do
- face
- fiecare
- cu ușurință
- uşor
- Eficace
- în mod eficient
- element
- apare
- întâlni
- inginer
- Inginerie
- îmbogăți
- În esență,
- schimb
- schimbând
- exclusiv
- Extinde
- experienţă
- explicând
- explora
- familiar
- puțini
- camp
- Domenii
- Fişiere
- filtru
- Găsi
- First
- concentrat
- următor
- urmează
- Pentru
- formă
- format
- prietenos
- din
- funcţie
- fundamental
- mai mult
- BPSC
- genera
- obține
- GitHub
- Go
- mare
- ghida
- manipula
- Manipularea
- se întâmplă
- Avea
- având în
- he
- -l
- speranţă
- Cum
- Totuși
- HTTPS
- uman
- i
- BOLNAV
- ID
- if
- imagina
- import
- important
- in
- în profunzime
- include
- Inclusiv
- Venituri
- încorporează
- informat
- instanță
- interes
- în
- ISN
- IT
- ESTE
- JavaScript
- JSON
- Jupiter Notebook
- doar
- KDnuggets
- Cheie
- chei
- Cunoaște
- Nume
- învăţare
- Nivel
- nivelurile de
- Bibliotecă
- ca
- Listă
- mic
- ll
- dragoste
- maşină
- masina de învățare
- magie
- menținut
- Efectuarea
- administra
- manager
- multe
- mijloace
- meta
- dispărut
- mobilitate
- Modern
- MongoDB
- mai mult
- cele mai multe
- muta
- mult
- multiplu
- nume
- Natural
- Nevoie
- cuibărit
- Nou
- următor
- Nu.
- în special
- caiet
- obiect
- obține
- of
- promoții
- de multe ori
- on
- ONE
- afară
- or
- al nostru
- ne
- producție
- panda
- parametru
- parte
- în special
- în așteptarea
- Perfect
- efectuată
- Fizică
- pivot
- Plato
- Informații despre date Platon
- PlatoData
- Popular
- cadouri
- probabil
- procedură
- proces
- produce
- proiect
- Piton
- întrebare
- cu totul
- Crud
- RE
- Citind
- gata
- record
- înregistrări
- rafina
- Răspunde
- REST
- REZULTATE
- reținere
- dreapta
- Rol
- s
- acelaşi
- Ştiinţă
- Ştiinţă şi Tehnologie
- Om de stiinta
- secunde
- vedea
- selectarea
- să
- simplu
- simula
- singur
- aptitudini
- mic
- So
- unele
- ceva
- specific
- specific
- SQL
- Încă
- depozitare
- stoca
- structura
- structurat
- astfel de
- potrivit
- REZUMAT
- T
- tabel
- Tehnologia
- termeni
- acea
- lumea
- lor
- Lor
- apoi
- Acestea
- acest
- aceste
- timp
- la
- împreună
- top
- Transforma
- Transformare
- transformare
- tip
- Tipuri
- în
- us
- utilizare
- util
- folosind
- Utilizand
- valoare
- Valori
- vrea
- a fost
- Cale..
- we
- Ce
- cand
- dacă
- care
- în timp ce
- voi
- cu
- în
- Apartamente
- de lucru
- fabrică
- lume
- ar
- tu
- zephyrnet