Imagine de autor
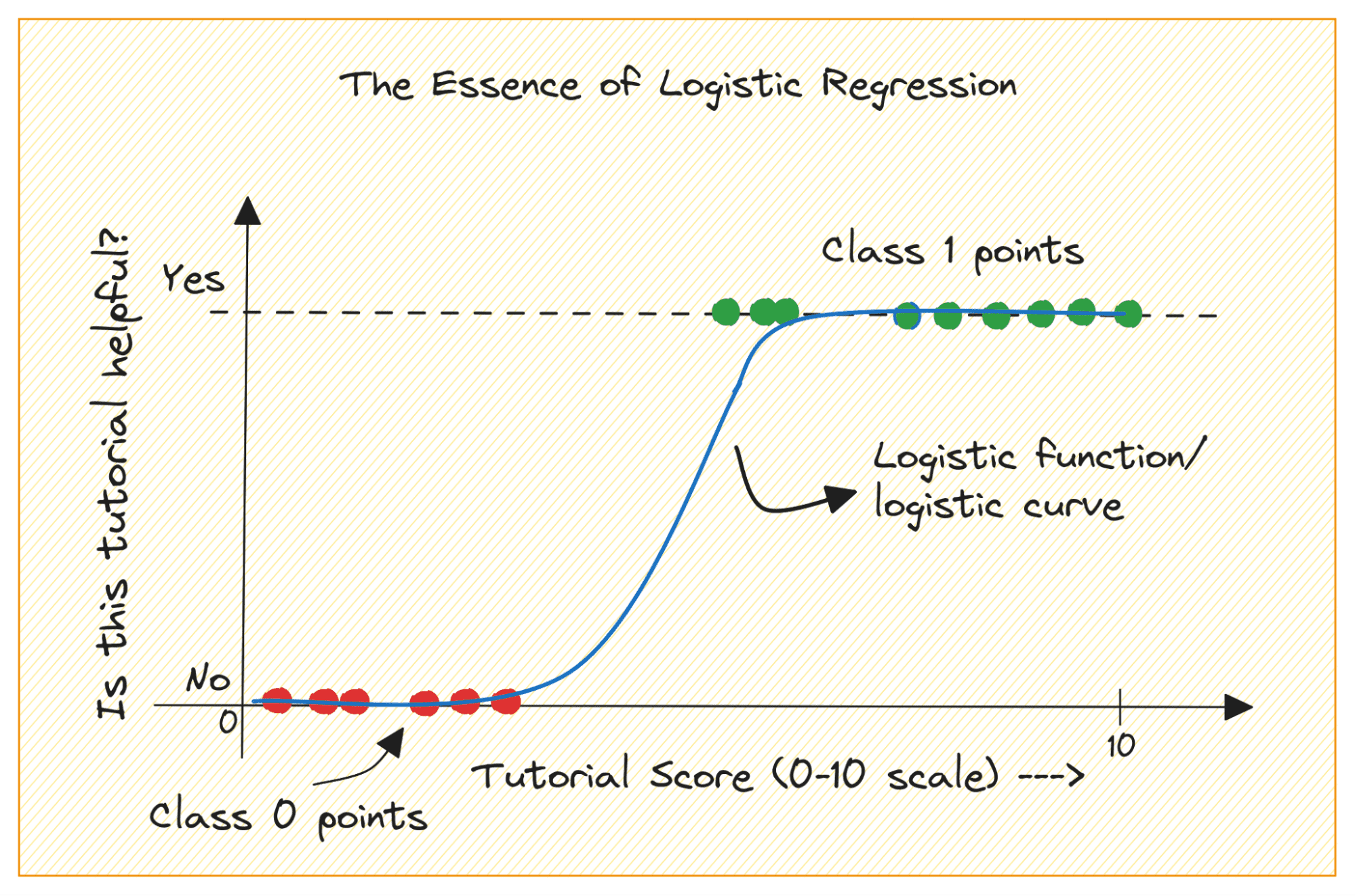
Când începeți cu învățarea automată, regresia logistică este unul dintre primii algoritmi pe care îi veți adăuga în cutia de instrumente. Este un algoritm simplu și robust, folosit în mod obișnuit pentru sarcini de clasificare binară.
Luați în considerare o problemă de clasificare binară cu clasele 0 și 1. Regresia logistică potrivește o funcție logistică sau sigmoidă la datele de intrare și prezice probabilitatea ca un punct de date de interogare să aparțină clasei 1. Interesant, da?
În acest tutorial, vom învăța despre regresia logistică de la sol în sus:
- Funcția logistică (sau sigmoidă).
- Cum trecem de la regresia liniară la regresia logistică
- Cum funcționează regresia logistică
În cele din urmă, vom construi un model simplu de regresie logistică clasifică returnările RADAR din ionosferă.
Înainte de a afla mai multe despre regresia logistică, să analizăm cum funcționează funcția logistică. Funcția logistică (sau sigmoidă) este dată de:

Când grafici funcția sigmoid, va arăta astfel:
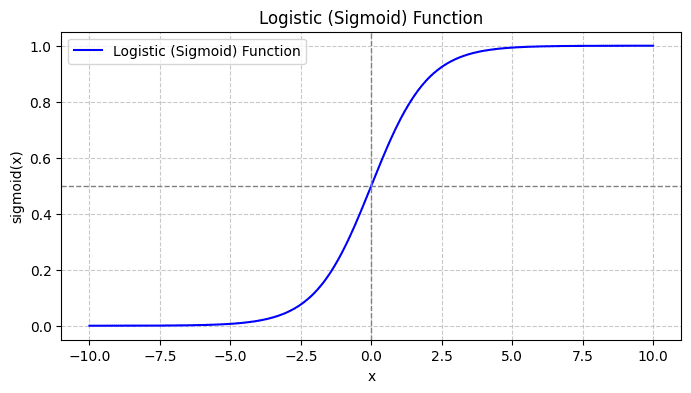
Din intrigă, vedem că:
- Când x = 0, σ(x) ia o valoare de 0.5.
- Când x se apropie de +∞, σ(x) se apropie de 1.
- Când x se apropie de -∞, σ(x) se apropie de 0.
Așadar, pentru toate intrările reale, funcția sigmoidă le comprimă pentru a prelua valori în intervalul [0, 1].
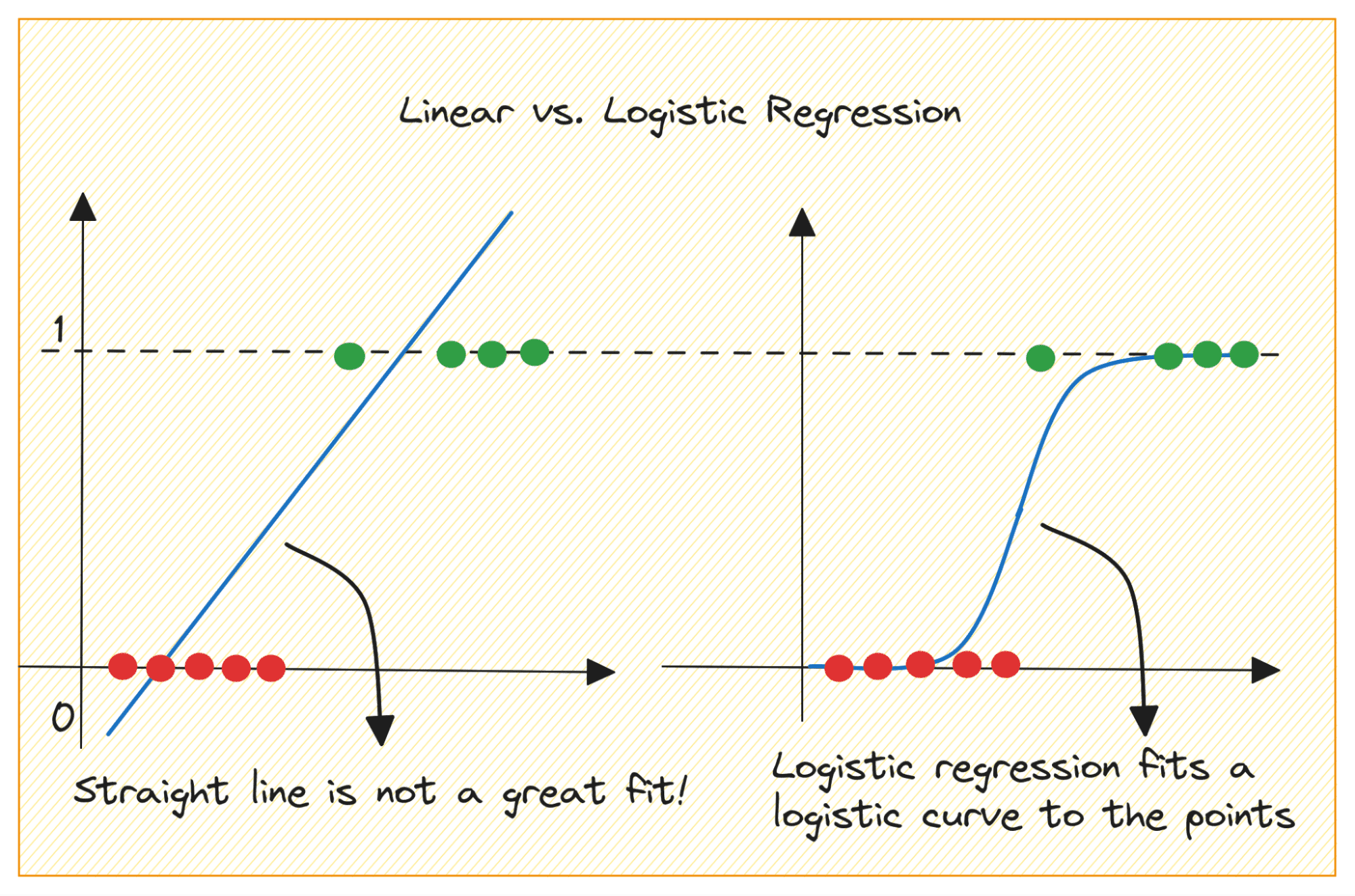
Să discutăm mai întâi de ce nu putem folosi regresia liniară pentru o problemă de clasificare binară.
Într-o problemă de clasificare binară, rezultatul este o etichetă categorială (0 sau 1). Deoarece regresia liniară prezice rezultate cu valori continue care pot fi mai mici de 0 sau mai mari decât 1, nu are sens pentru problema în cauză.
De asemenea, o linie dreaptă poate să nu fie cea mai potrivită atunci când etichetele de ieșire aparțin uneia dintre cele două categorii.
Imagine de autor
Deci, cum trecem de la regresia liniară la regresia logistică? În regresia liniară rezultatul estimat este dat de:
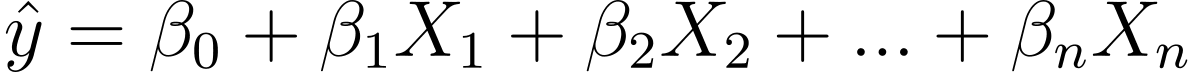
Unde βs sunt coeficienții și X_is sunt predictorii (sau caracteristicile).
Fără pierderea generalității, să presupunem X_0 = 1:

Deci putem avea o expresie mai concisă:
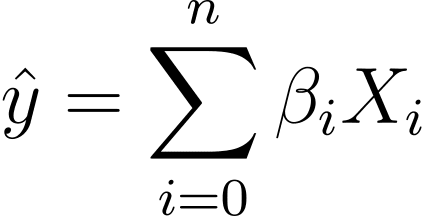
În regresia logistică, avem nevoie de probabilitatea prezisă p_i în intervalul [0,1]. Știm că funcția logistică comprimă intrările astfel încât acestea să ia valori în intervalul [0,1].
Deci, introducând această expresie în funcția logistică, avem probabilitatea prezisă ca:
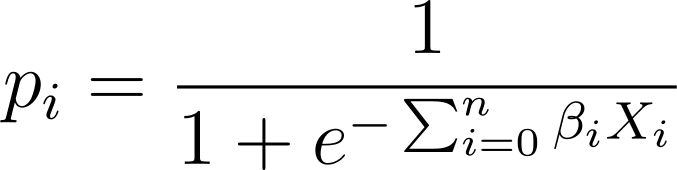
Deci, cum găsim curba logistică cea mai potrivită pentru setul de date dat? Pentru a răspunde la aceasta, să înțelegem estimarea probabilității maxime.
Estimarea probabilității maxime (MLE) este utilizat pentru a estima parametrii modelului de regresie logistică prin maximizarea funcției de probabilitate. Să descompunem procesul de MLE în regresia logistică și modul în care funcția de cost este formulată pentru optimizare folosind coborârea gradientului.
Defalcarea estimării probabilității maxime
După cum sa discutat, modelăm probabilitatea ca un rezultat binar să apară în funcție de una sau mai multe variabile (sau caracteristici) predictoare:
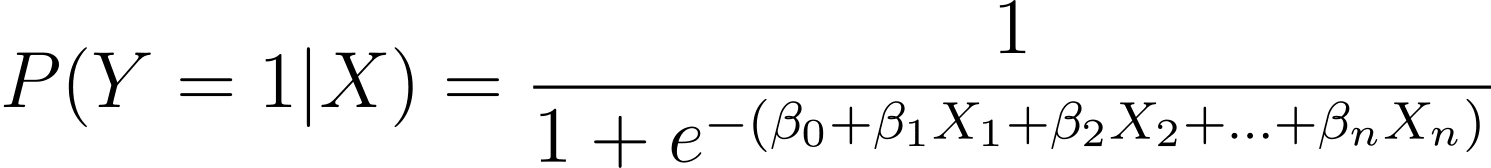
Aici, β sunt parametrii sau coeficienții modelului. X_1, X_2,…, X_n sunt variabilele predictoare.
MLE își propune să găsească valorile lui β care maximizează probabilitatea datelor observate. Funcția de probabilitate, notată cu L(β), reprezintă probabilitatea de a observa rezultatele date pentru valorile predictorilor date în cadrul modelului de regresie logistică.
Formularea funcției de log-probabilitate
Pentru a simplifica procesul de optimizare, este obișnuit să lucrați cu funcția de log-probabilitate. Pentru că transformă produse ale probabilităților în sume ale probabilităților log.
Funcția de log-probabilitate pentru regresia logistică este dată de:
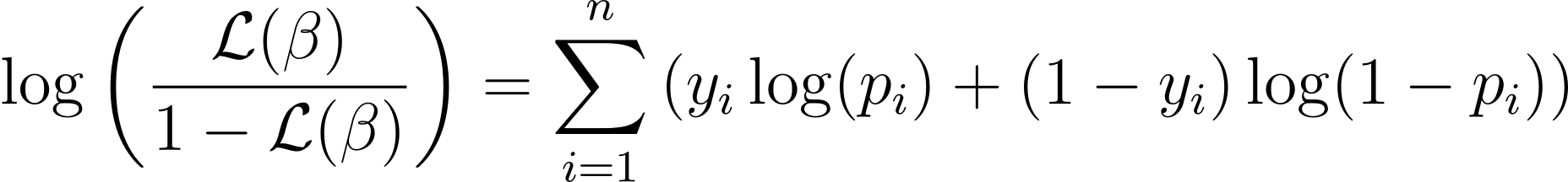
Acum că cunoaștem esența log-probabilității, să trecem la formularea funcției de cost pentru regresia logistică și, ulterior, coborârea gradientului pentru găsirea celor mai buni parametri de model.
Funcția de cost pentru regresia logistică
Pentru a optimiza modelul de regresie logistică, trebuie să maximizăm log-probabilitatea. Deci putem folosi probabilitatea log-negativă ca funcție de cost pentru a minimiza în timpul antrenamentului. Log-probabilitatea negativă, denumită adesea pierdere logistică, este definită ca:
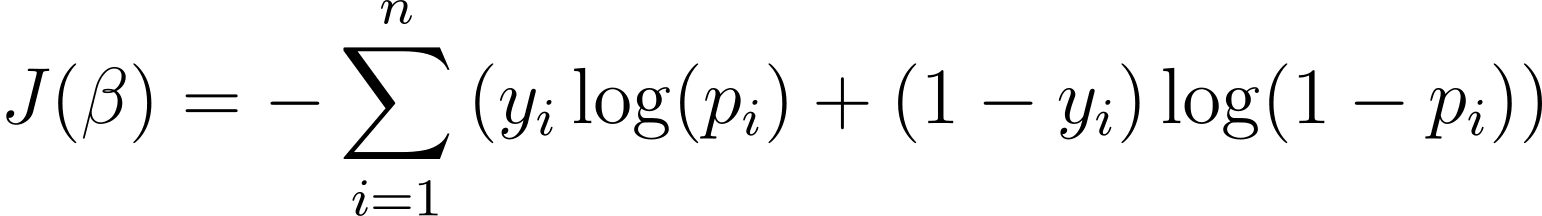
Prin urmare, scopul algoritmului de învățare este de a găsi valorile lui ? care minimizează această funcție de cost. Coborârea gradientului este un algoritm de optimizare utilizat în mod obișnuit pentru găsirea minimului acestei funcții de cost.
Coborâre gradient în regresie logistică
Coborâre în gradient este un algoritm de optimizare iterativ care actualizează parametrii modelului β în direcția opusă gradientului funcției de cost în raport cu β. Regula de actualizare la pasul t+1 pentru regresia logistică folosind coborârea gradientului este următoarea:
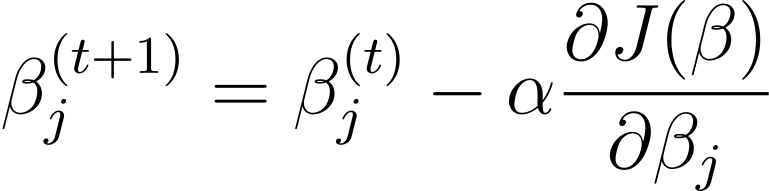
Unde α este rata de învățare.
Derivatele parțiale pot fi calculate folosind regula lanțului. Coborârea gradientului actualizează iterativ parametrii – până la convergență – cu scopul de a minimiza pierderea logistică. Pe măsură ce converge, găsește valorile optime ale lui β care maximizează probabilitatea datelor observate.
Acum că știți cum funcționează regresia logistică, să construim un model predictiv folosind biblioteca scikit-learn.
Vom folosi setul de date ionosferă din depozitul de învățare automată UCI pentru acest tutorial. Setul de date cuprinde 34 de caracteristici numerice. Ieșirea este binară, una dintre „bun” sau „rău” (notat cu „g” sau „b”). Eticheta de ieșire „bună” se referă la returnările RADAR care au detectat o anumită structură în ionosferă.
Pasul 1 - Încărcarea setului de date
Mai întâi, descărcați setul de date și citiți-l într-un cadru de date Pandas:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Pasul 2 – Explorarea setului de date
Să aruncăm o privire la primele câteva rânduri ale cadrului de date:
# Display the first few rows of the DataFrame
df.head()
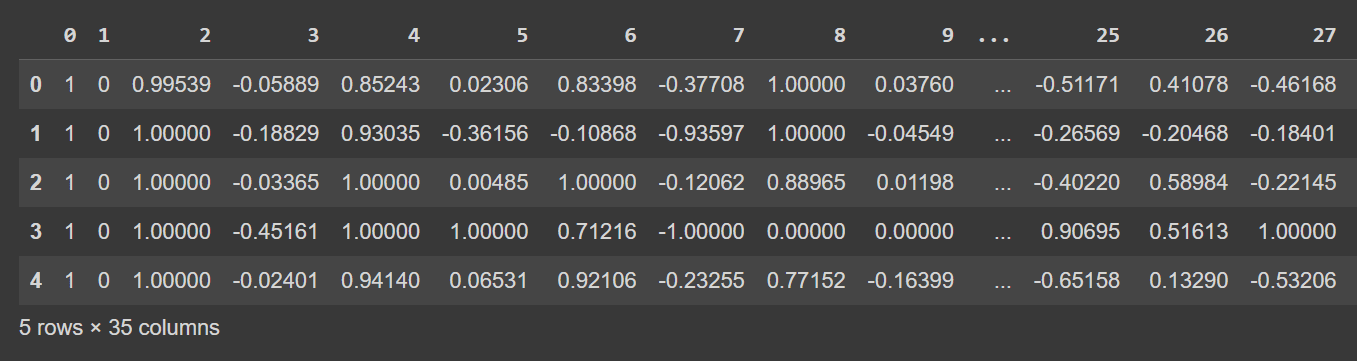
Ieșire trunchiată a df.head()
Să obținem câteva informații despre setul de date: numărul de valori non-nule și tipurile de date ale fiecărei coloane:
# Get information about the dataset
print(df.info())
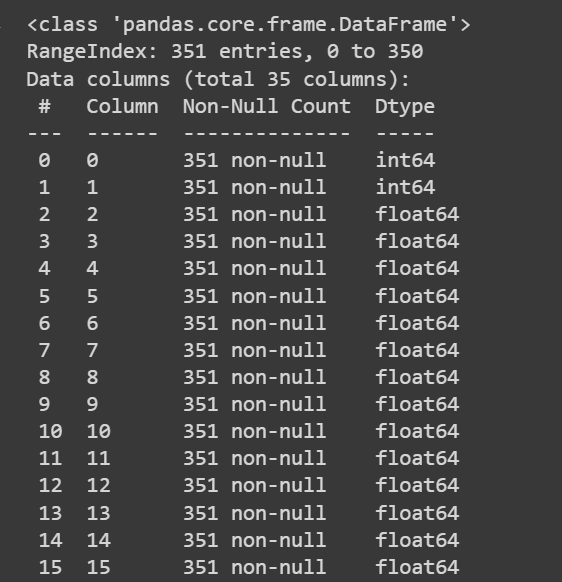 Ieșire trunchiată a df.info()
Ieșire trunchiată a df.info()
Deoarece avem toate caracteristicile numerice, putem obține și niște statistici descriptive folosind describe() metoda pe cadrul de date:
# Get descriptive statistics of the dataset
print(df.describe())
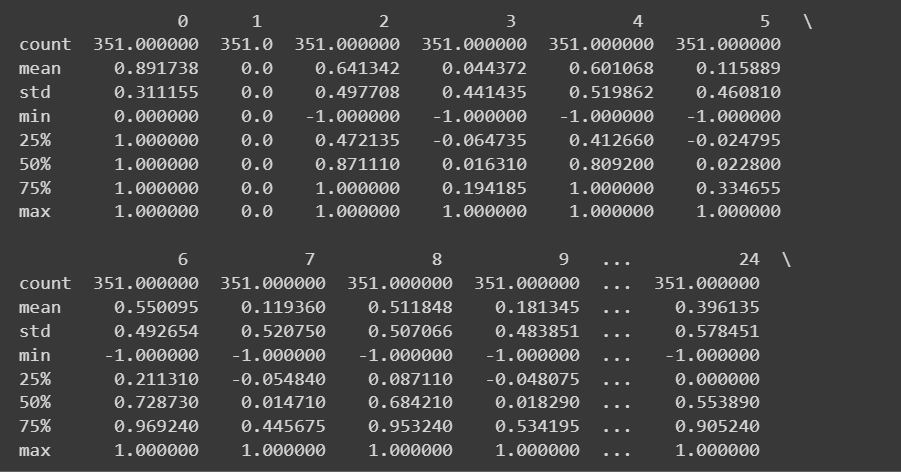
Ieșire trunchiată a df.describe()
Numele coloanelor sunt în prezent de la 0 la 34, inclusiv eticheta. Deoarece setul de date nu oferă nume descriptive pentru coloane, se referă doar la ele ca atribut_1 la atribut_34 dacă doriți să puteți redenumi coloanele cadrului de date așa cum se arată:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Notă: Acest pas este pur opțional. Puteți continua cu numele de coloane implicite, dacă preferați.
# Display the first few rows of the DataFrame
df.head()
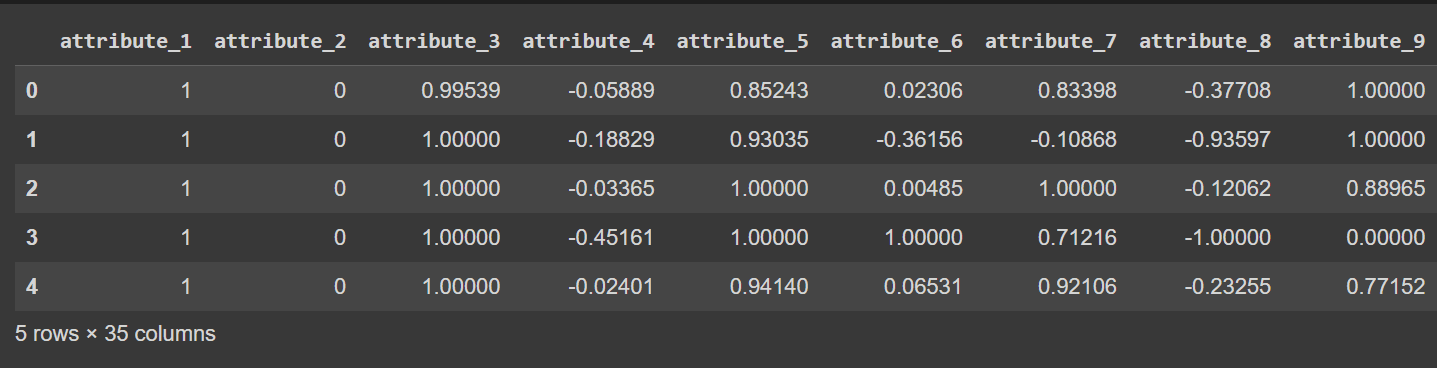
Ieșire trunchiată a df.head() [După redenumirea coloanelor]
Pasul 3 – Redenumirea etichetelor claselor și vizualizarea distribuției claselor
Deoarece etichetele clasei de ieșire sunt „g” și „b”, trebuie să le mapam la 1 și, respectiv, 0. O poți face folosind map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Să vizualizăm și distribuția etichetelor de clasă:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
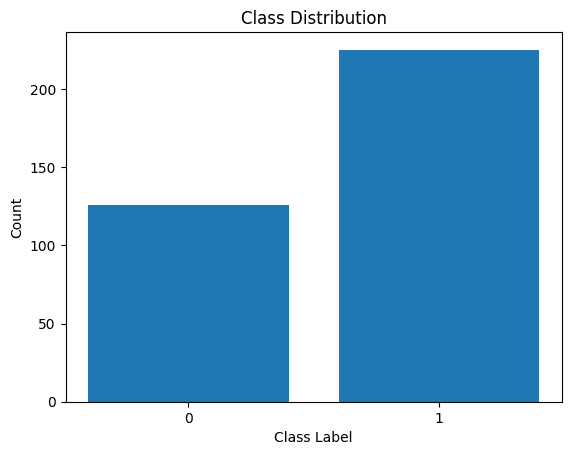
Distribuirea etichetelor de clasă
Vedem că există un dezechilibru în distribuție. Există mai multe înregistrări aparținând clasei 1 decât clasei 0. Vom gestiona acest dezechilibru de clasă atunci când construim modelul de regresie logistică.
Pasul 5 – Preprocesarea setului de date
Să colectăm caracteristicile și etichetele de ieșire astfel:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
După împărțirea setului de date în tren și seturi de testare, trebuie să preprocesăm setul de date.
Când există multe caracteristici numerice - fiecare la o scară potențial diferită - trebuie să preprocesăm caracteristicile numerice. O metodă comună este de a le transforma astfel încât să urmeze o distribuție cu medie zero și varianță unitară.
StandardScaler din modulul de preprocesare al lui scikit-learn ne ajută să realizăm acest lucru.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Pasul 6 – Construirea unui model de regresie logistică
Acum putem instanția un clasificator de regresie logistică. The LogisticRegression clasa face parte din modulul linear_model al scikit-learn.
Observați că am setat class_weight parametrul la „echilibrat”. Acest lucru ne va ajuta să ținem cont de dezechilibrul clasei. Prin atribuirea de ponderi fiecărei clase — invers proporțională cu numărul de înregistrări din clase.
După instanțierea clasei, putem potrivi modelul la setul de date de antrenament:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Pasul 7 – Evaluarea modelului de regresie logistică
Puteți apela la predict() metoda de a obține predicțiile modelului.
Pe lângă scorul de precizie, putem obține și un raport de clasificare cu valori precum precizia, rechemarea și scorul F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
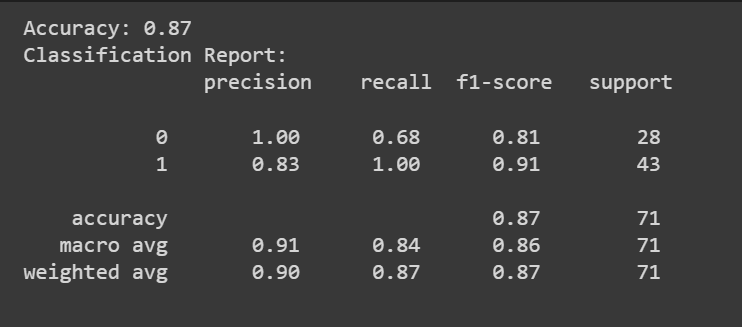
Felicitări, ați codificat primul model de regresie logistică!
În acest tutorial, am învățat despre regresia logistică în detaliu: de la teorie și matematică la codificarea unui clasificator de regresie logistică.
Ca pas următor, încercați să construiți un model de regresie logistică pentru un set de date potrivit la alegerea dvs.
Setul de date Ionosphere este licențiat sub a Creative Commons Atribuire 4.0 Internațional Licență (CC BY 4.0):
Sigillito, V., Wing, S., Hutton, L. și Baker, K.. (1989). ionosferă. Depozitul UCI Machine Learning. https://doi.org/10.24432/C5W01B.
Bala Priya C este un dezvoltator și scriitor tehnic din India. Îi place să lucreze la intersecția dintre matematică, programare, știința datelor și crearea de conținut. Domeniile ei de interes și expertiză includ DevOps, știința datelor și procesarea limbajului natural. Îi place să citească, să scrie, să codifice și să cafea! În prezent, ea lucrează la învățarea și la împărtășirea cunoștințelor sale cu comunitatea de dezvoltatori, creând tutoriale, ghiduri, articole de opinie și multe altele.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :este
- :nu
- $UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- Despre Noi
- Cont
- precizie
- Obține
- adăuga
- plus
- După
- isi propune
- Algoritmul
- algoritmi
- TOATE
- de asemenea
- an
- și
- răspunde
- abordari
- SUNT
- domenii
- AS
- asuma
- At
- autor
- b
- brutar
- Echilibrat
- bar
- BE
- deoarece
- apartenenta
- CEL MAI BUN
- Pauză
- construi
- Clădire
- by
- apel
- CAN
- nu poti
- categorii
- lanţ
- alegere
- clasă
- clase
- clasificare
- cifrat
- Codificare
- colecta
- Coloană
- Coloane
- Comun
- în mod obișnuit
- Commons
- comunitate
- cuprinde
- concis
- conţinut
- crearea de continut
- converti
- A costat
- acoperire
- crea
- creaţie
- În prezent
- curba
- de date
- puncte de date
- știința datelor
- set de date
- Mod implicit
- definit
- Instrumentele financiare derivate
- detaliu
- detectat
- Dezvoltator
- DevOps
- diferit
- direcţie
- discuta
- discutat
- Afişa
- distribuire
- do
- face
- jos
- Descarca
- în timpul
- fiecare
- esenţă
- estima
- evaluarea
- expertiză
- Explorarea
- expresie
- DESCRIERE
- puțini
- Găsi
- descoperire
- descoperiri
- First
- potrivi
- urma
- urmează
- Pentru
- FRAME
- din
- funcţie
- obține
- obtinerea
- dat
- Go
- scop
- mai mare
- Teren
- Ghiduri
- mână
- manipula
- Avea
- ajutor
- ajută
- ei
- Cum
- HTTPS
- ICS
- if
- dezechilibru
- import
- in
- include
- index
- India
- Indici
- informații
- intrare
- intrări
- interes
- interesant
- intersecție
- în
- IT
- doar
- KDnuggets
- Cunoaște
- cunoştinţe
- Etichetă
- etichete
- limbă
- AFLAȚI
- învățat
- învăţare
- mai puțin
- lăsa
- Bibliotecă
- Licență
- Autorizat
- ca
- probabilitate
- îi place
- Linie
- încărcare
- log
- Uite
- arată ca
- de pe
- maşină
- masina de învățare
- face
- multe
- Hartă
- matematica
- matplotlib
- Maximaliza
- maximizarea
- maxim
- Mai..
- însemna
- metodă
- Metrici
- minimaliza
- minim
- model
- Modele
- modul
- mai mult
- muta
- nume
- Natural
- Limbajul natural
- Procesarea limbajului natural
- Nevoie
- negativ
- următor
- număr
- observate
- of
- de multe ori
- on
- ONE
- Opinie
- opus
- optimă
- optimizare
- Optimizați
- or
- Rezultat
- rezultate
- producție
- iesiri
- panda
- parametru
- parametrii
- parte
- piese
- Plato
- Informații despre date Platon
- PlatoData
- Punct
- puncte
- potenţial
- Precizie
- a prezis
- Predictii
- predictivă
- Predictor
- prezice
- a prefera
- probabilitate
- Problemă
- continua
- proces
- prelucrare
- Produse
- Programare
- furniza
- pur
- Piton
- radar
- gamă
- rată
- Citeste
- Citind
- real
- înregistrări
- menționat
- se referă
- regres
- raportează
- depozit
- reprezintă
- solicita
- respect
- respectiv
- Returnează
- revizuiască
- robust
- Regula
- s
- Ştiinţă
- scikit-learn
- scor
- vedea
- sens
- set
- Seturi
- partajarea
- ea
- indicat
- simplu
- simplifica
- So
- unele
- împărţi
- început
- statistică
- Pas
- drept
- structura
- Ulterior
- astfel de
- potrivit
- sume
- Lua
- ia
- Ţintă
- sarcini
- Tehnic
- test
- Testarea
- decât
- acea
- Lor
- teorie
- Acolo.
- prin urmare
- ei
- acest
- Prin
- la
- Toolbox
- Tren
- dresat
- Pregătire
- Transforma
- transformatele
- încerca
- tutorial
- tutoriale
- Două
- Tipuri
- în
- înţelege
- unitate
- Actualizează
- actualizări
- URL-ul
- us
- cont SUA
- utilizare
- utilizat
- folosind
- valoare
- Valori
- imagina
- we
- cand
- care
- de ce
- Wikipedia
- voi
- aripă
- cu
- Apartamente
- de lucru
- fabrică
- ar
- scriitor
- scris
- X
- da
- tu
- Ta
- zephyrnet
- zero







