În Prima parte din această serie de trei părți, am prezentat o soluție care demonstrează modul în care puteți automatiza detectarea falsificării documentelor și a fraudei la scară utilizând serviciile AWS AI și de învățare automată (ML) pentru un caz de utilizare de subscriere ipotecară.
În această postare, prezentăm o abordare pentru dezvoltarea unui model de viziune computerizată bazat pe învățarea profundă pentru a detecta și evidenția imagini falsificate în subscrierea de credite ipotecare. Oferim îndrumări privind construirea, instruirea și implementarea rețelelor de învățare profundă Amazon SageMaker.
În partea 3, demonstrăm cum să implementăm soluția pe Detector de fraude Amazon.
Prezentare generală a soluțiilor
Pentru a îndeplini obiectivul de detectare a falsificării documentelor în subscrierea de credite ipotecare, folosim un model de viziune computerizată găzduit pe SageMaker pentru soluția noastră de detectare a falsurilor de imagine. Acest model primește o imagine de testare ca intrare și generează o predicție a probabilității falsificării ca rezultat. Arhitectura rețelei este cea prezentată în diagrama următoare.
Falsificarea imaginilor implică în principal patru tehnici: îmbinare, copiere-mutare, îndepărtare și îmbunătățire. În funcție de caracteristicile falsului, diferite indicii pot fi folosite ca bază pentru detectarea și localizarea. Aceste indicii includ artefacte de compresie JPEG, inconsecvențe de margine, modele de zgomot, consistența culorilor, similitudinea vizuală, consistența EXIF și modelul camerei.
Având în vedere domeniul expansiv al detectării falsurilor de imagine, folosim algoritmul de analiza a nivelului de erori (ELA) ca metodă ilustrativă pentru detectarea falsurilor. Am selectat tehnica ELA pentru această postare din următoarele motive:
- Este mai rapid de implementat și poate detecta cu ușurință modificarea imaginilor.
- Funcționează prin analiza nivelurilor de compresie ale diferitelor părți ale unei imagini. Acest lucru îi permite să detecteze inconsecvențele care pot indica modificarea — de exemplu, dacă o zonă a fost copiată și lipită dintr-o altă imagine care a fost salvată la un nivel de compresie diferit.
- Este bun la detectarea unor modificări mai subtile sau fără întreruperi, care pot fi greu de observat cu ochiul liber. Chiar și modificările mici ale unei imagini pot introduce anomalii de compresie detectabile.
- Nu se bazează pe a avea imaginea originală nemodificată pentru comparație. ELA poate identifica semnele de falsificare numai în cadrul imaginii puse sub semnul întrebării. Alte tehnici necesită adesea originalul nemodificat pentru comparare.
- Este o tehnică ușoară care se bazează doar pe analiza artefactelor de compresie din datele imaginii digitale. Nu depinde de hardware specializat sau expertiză criminalistică. Acest lucru face ca ELA să fie accesibilă ca instrument de analiză de primă trecere.
- Imaginea ELA de ieșire poate evidenția clar diferențele de niveluri de compresie, făcând vizibil evidente zonele modificate. Acest lucru permite chiar și unui neexpert să recunoască semnele unei posibile manipulări.
- Funcționează pe multe tipuri de imagini (cum ar fi JPEG, PNG și GIF) și necesită doar imaginea în sine pentru a fi analizată. Alte tehnici criminalistice pot fi mai restrânse în ceea ce privește formatele sau cerințele de imagine originale.
Cu toate acestea, în scenariile din lumea reală în care este posibil să aveți o combinație de documente de intrare (JPEG, PNG, GIF, TIFF, PDF), vă recomandăm să utilizați ELA împreună cu diverse alte metode, cum ar fi detectarea inconsecvențelor în margini, modele de zgomot, uniformitatea culorii, Consecvența datelor EXIF, identificarea modelului camerei, și uniformitatea fontului. Ne propunem să actualizăm codul pentru această postare cu tehnici suplimentare de detectare a falsurilor.
Premisa de bază a ELA presupune că imaginile de intrare sunt în format JPEG, cunoscut pentru compresia cu pierderi. Cu toate acestea, metoda poate fi în continuare eficientă chiar dacă imaginile de intrare au fost inițial într-un format fără pierderi (cum ar fi PNG, GIF sau BMP) și ulterior convertite în JPEG în timpul procesului de modificare. Când ELA este aplicat la formatele originale fără pierderi, indică de obicei o calitate constantă a imaginii fără nicio deteriorare, ceea ce face dificilă identificarea zonelor modificate. În imaginile JPEG, norma așteptată este ca întreaga imagine să prezinte niveluri de compresie similare. Cu toate acestea, dacă o anumită secțiune din imagine afișează un nivel de eroare semnificativ diferit, deseori sugerează că a fost făcută o modificare digitală.
ELA evidențiază diferențele în rata de compresie JPEG. Regiunile cu colorare uniformă vor avea probabil un rezultat ELA mai scăzut (de exemplu, o culoare mai închisă în comparație cu marginile cu contrast ridicat). Lucrurile de căutat pentru a identifica falsificarea sau modificarea includ următoarele:
- Marginile similare ar trebui să aibă luminozitate similară în rezultatul ELA. Toate marginile cu contrast ridicat ar trebui să arate similare între ele, iar toate marginile cu contrast scăzut ar trebui să arate similare. Cu o fotografie originală, marginile cu contrast scăzut ar trebui să fie aproape la fel de luminoase ca marginile cu contrast ridicat.
- Texturi similare ar trebui să aibă o colorare similară sub ELA. Zonele cu mai multe detalii de suprafață, cum ar fi un prim plan al unei mingi de baschet, vor avea probabil un rezultat ELA mai mare decât o suprafață netedă.
- Indiferent de culoarea reală a suprafeței, toate suprafețele plane ar trebui să aibă aproximativ aceeași colorare sub ELA.
Imaginile JPEG folosesc un sistem de compresie cu pierderi. Fiecare recodificare (resalvare) a imaginii adaugă mai multă pierdere de calitate imaginii. Mai exact, algoritmul JPEG operează pe o grilă de 8×8 pixeli. Fiecare pătrat de 8×8 este comprimat independent. Dacă imaginea este complet nemodificată, atunci toate pătratele 8×8 ar trebui să aibă potențiale de eroare similare. Dacă imaginea este nemodificată și resalvată, atunci fiecare pătrat ar trebui să se degradeze aproximativ la aceeași rată.
ELA salvează imaginea la un nivel de calitate JPEG specificat. Această resalvare introduce o cantitate cunoscută de erori în întreaga imagine. Imaginea resalvată este apoi comparată cu imaginea originală. Dacă o imagine este modificată, atunci fiecare pătrat de 8×8 care a fost atins de modificare ar trebui să aibă un potențial de eroare mai mare decât restul imaginii.
Rezultatele de la ELA depind direct de calitatea imaginii. Poate doriți să știți dacă a fost adăugat ceva, dar dacă imaginea este copiată de mai multe ori, atunci ELA poate permite doar detectarea resalvarilor. Încercați să găsiți versiunea de cea mai bună calitate a imaginii.
Cu antrenament și practică, ELA poate, de asemenea, să învețe să identifice transformările de scalare, calitate, decupare și salvare a imaginii. De exemplu, dacă o imagine non-JPEG conține linii de grilă vizibile (1 pixel lățime în 8×8 pătrate), atunci înseamnă că imaginea a început ca JPEG și a fost convertită în format non-JPEG (cum ar fi PNG). Dacă unele zone ale imaginii nu au linii de grilă sau liniile de grilă se deplasează, atunci aceasta denotă o îmbinare sau o porțiune desenată în imaginea non-JPEG.
În secțiunile următoare, demonstrăm pașii pentru configurarea, antrenamentul și implementarea modelului de computer vision.
Cerințe preliminare
Pentru a urma această postare, completați următoarele cerințe preliminare:
- Aveți un cont AWS.
- Configurarea Amazon SageMaker Studio. Puteți iniția rapid SageMaker Studio folosind setările prestabilite implicite, facilitând o lansare rapidă. Pentru mai multe informații, consultați Amazon SageMaker simplifică configurarea Amazon SageMaker Studio pentru utilizatorii individuali.
- Deschideți SageMaker Studio și lansați un terminal de sistem.
- Rulați următoarea comandă în terminal:
git clone https://github.com/aws-samples/document-tampering-detection.git - Costul total al rulării SageMaker Studio pentru un utilizator și configurațiile mediului notebook este de 7.314 USD pe oră.
Configurați caietul de antrenament model
Parcurgeți următorii pași pentru a vă configura caietul de antrenament:
- Deschideți
tampering_detection_training.ipynbfișier din directorul document-tampering-detection. - Configurați mediul notebook cu imaginea TensorFlow 2.6 Python 3.8 CPU sau GPU Optimized.
Este posibil să vă confruntați cu o disponibilitate insuficientă sau să atingeți limita cotei pentru instanțe GPU din contul dvs. AWS atunci când selectați instanțe optimizate pentru GPU. Pentru a crește cota, vizitați consola Cote de servicii și creșteți limita de serviciu pentru tipul de instanță specific de care aveți nevoie. De asemenea, puteți utiliza un mediu de notebook optimizat pentru CPU în astfel de cazuri. - Pentru Nucleu, alege Python3.
- Pentru Tipul instanței, alege ml.m5d.24xlarge sau orice alt exemplu mare.
Am selectat un tip de instanță mai mare pentru a reduce timpul de antrenament al modelului. Cu un mediu de notebook ml.m5d.24xlarge, costul pe oră este de 7.258 USD pe oră.
Rulați caietul de antrenament
Rulați fiecare celulă din blocnotes tampering_detection_training.ipynb în ordine. Discutăm câteva celule mai detaliat în secțiunile următoare.
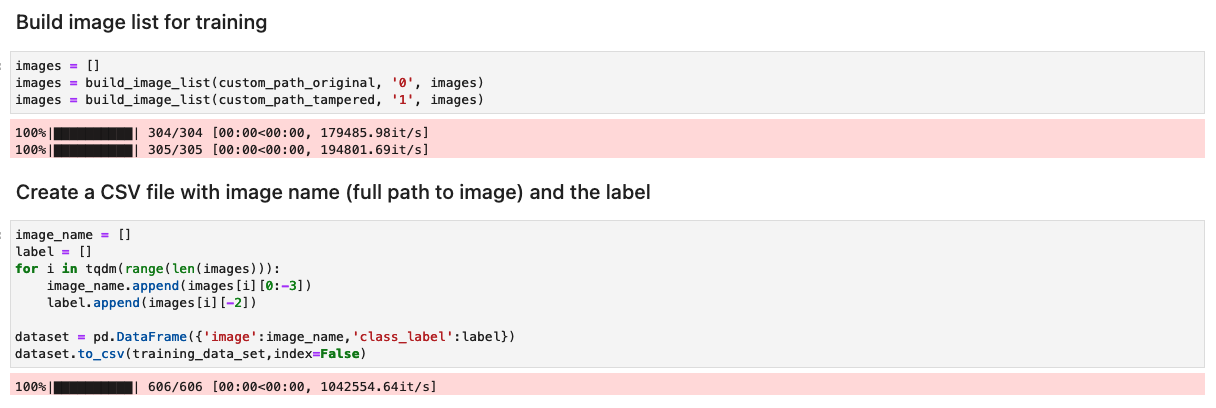
Pregătiți setul de date cu o listă de imagini originale și modificate
Înainte de a rula următoarea celulă în blocnotes, pregătiți un set de date de documente originale și modificate pe baza cerințelor dvs. specifice de afaceri. Pentru această postare, folosim un exemplu de set de date de talonoane de plată modificate și extrase de cont. Setul de date este disponibil în directorul de imagini al GitHub depozit.

Caietul citește imaginile originale și modificate din images/training director.
Setul de date pentru antrenament este creat folosind un fișier CSV cu două coloane: calea către fișierul imagine și eticheta pentru imagine (0 pentru imaginea originală și 1 pentru imaginea manipulată).
Procesați setul de date prin generarea rezultatelor ELA ale fiecărei imagini de antrenament
În acest pas, generăm rezultatul ELA (la o calitate de 90%) al imaginii de antrenament de intrare. Functia convert_to_ela_image ia doi parametri: calea, care este calea către un fișier imagine, și calitatea, reprezentând parametrul de calitate pentru compresia JPEG. Funcția efectuează următorii pași:
- Convertiți imaginea în format RGB și salvați din nou imaginea ca fișier JPEG cu calitatea specificată sub numele tempresaved.jpg.
- Calculați diferența dintre imaginea originală și imaginea JPEG resalvată (ELA) pentru a determina diferența maximă în valorile pixelilor dintre imaginile originale și cele resalvate.
- Calculați un factor de scară pe baza diferenței maxime pentru a regla luminozitatea imaginii ELA.
- Îmbunătățiți luminozitatea imaginii ELA utilizând factorul de scară calculat.
- Redimensionați rezultatul ELA la 128x128x3, unde 3 reprezintă numărul de canale pentru a reduce dimensiunea de intrare pentru antrenament.
- Returnați imaginea ELA.
În formatele de imagine cu pierderi, cum ar fi JPEG, procesul inițial de salvare duce la pierderi considerabile de culoare. Cu toate acestea, atunci când imaginea este încărcată și, ulterior, re-codificată în același format cu pierderi, există în general mai puțină degradare a culorii. Rezultatele ELA subliniază zonele de imagine cele mai susceptibile la degradarea culorii la resalvare. În general, modificările apar proeminent în regiunile care prezintă un potențial mai mare de degradare în comparație cu restul imaginii.
Apoi, imaginile sunt procesate într-o matrice NumPy pentru antrenament. Apoi împărțim aleatoriu setul de date de intrare în date de antrenament și de testare sau validare (80/20). Puteți ignora orice avertismente atunci când rulați aceste celule.
În funcție de dimensiunea setului de date, rularea acestor celule poate dura timp. Pentru setul de date eșantion pe care l-am furnizat în acest depozit, ar putea dura 5-10 minute.
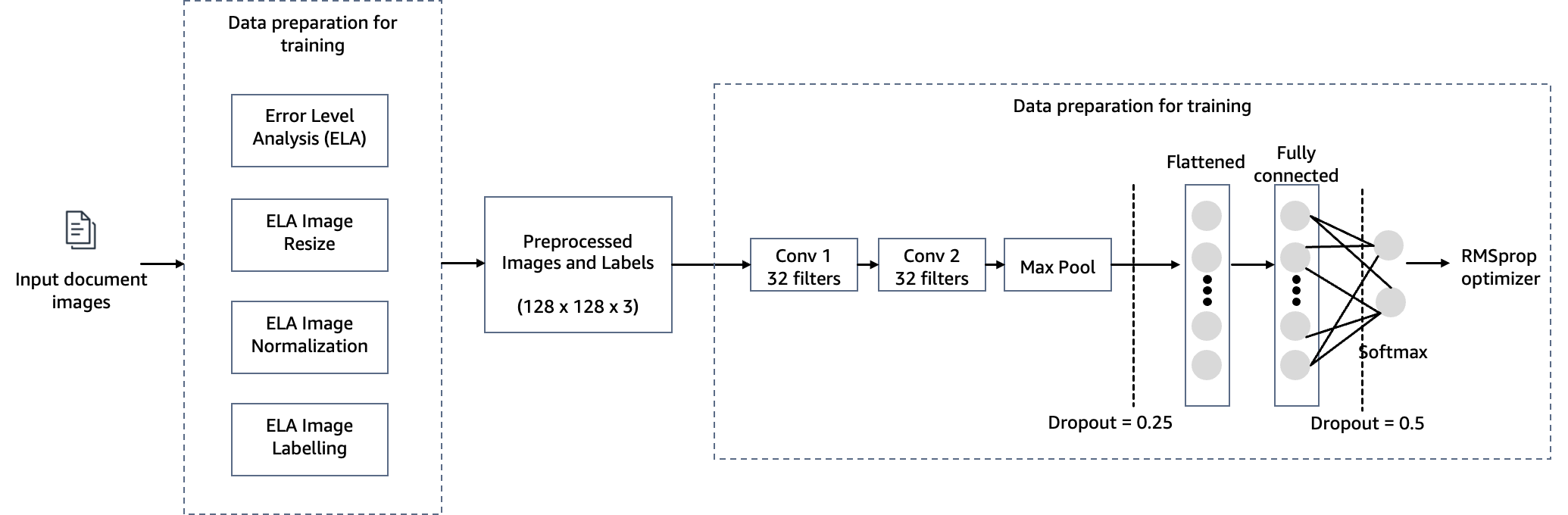
Configurați modelul CNN
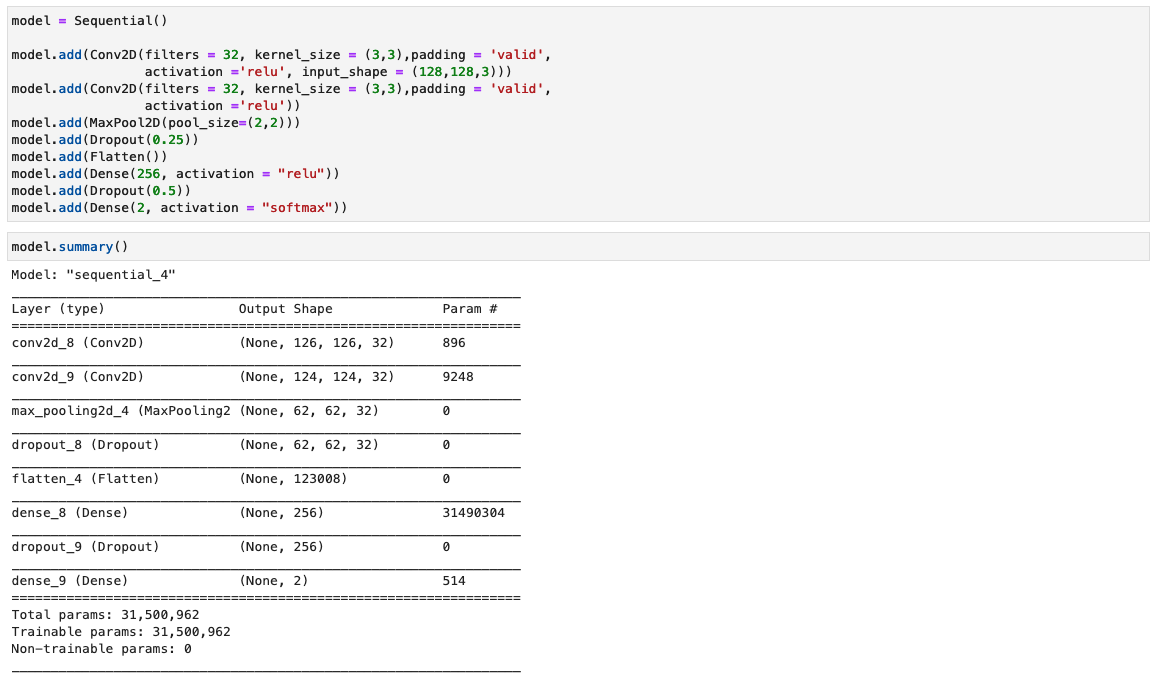
În acest pas, construim o versiune minimă a rețelei VGG cu filtre convoluționale mici. VGG-16 este format din 13 straturi convoluționale și trei straturi complet conectate. Următoarea captură de ecran ilustrează arhitectura modelului nostru de rețea neuronală convoluțională (CNN).
Rețineți următoarele configurații:
- Intrare – Modelul acceptă o dimensiune de intrare a imaginii de 128x128x3.
- Straturi convoluționale – Straturile convoluționale folosesc un câmp receptiv minim (3×3), cea mai mică dimensiune posibilă care încă surprinde sus/jos și stânga/dreapta. Aceasta este urmată de o funcție de activare a unității lineare rectificate (ReLU) care reduce timpul de antrenament. Aceasta este o funcție liniară care va scoate intrarea dacă este pozitivă; în caz contrar, ieșirea este zero. Pasul de convoluție este fixat la valoarea implicită (1 pixel) pentru a păstra rezoluția spațială după convoluție (pasul este numărul de deplasări de pixeli peste matricea de intrare).
- Straturi complet conectate – Rețeaua are două straturi complet conectate. Primul strat dens folosește activarea ReLU, iar al doilea folosește softmax pentru a clasifica imaginea ca originală sau manipulată.
Puteți ignora orice avertismente atunci când rulați aceste celule.
Salvați artefactele modelului
Salvați modelul antrenat cu un nume de fișier unic, de exemplu, pe baza datei și orei curente, într-un director numit model.

Modelul este salvat în format Keras cu extensia .keras. De asemenea, salvăm artefactele modelului într-un director numit 1, care conține semnături seriate și starea necesară pentru a le rula, inclusiv valori variabile și vocabulare pentru a le implementa într-un timp de execuție SageMaker (despre care discutăm mai târziu în această postare).
Măsurați performanța modelului
Următoarea curbă de pierdere arată evoluția pierderii modelului pe epocile de antrenament (iterații).
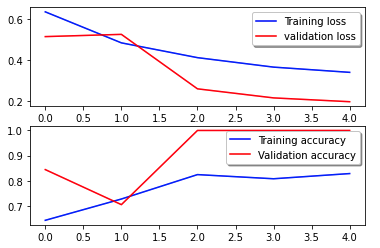
Funcția de pierdere măsoară cât de bine se potrivesc predicțiile modelului cu țintele reale. Valorile mai mici indică o mai bună aliniere între predicții și valorile adevărate. Scăderea pierderilor de-a lungul epocilor înseamnă că modelul se îmbunătățește. Curba de precizie ilustrează acuratețea modelului în epocile de antrenament. Precizia este raportul dintre predicțiile corecte și numărul total de predicții. O precizie mai mare indică un model mai performant. De obicei, precizia crește în timpul antrenamentului pe măsură ce modelul învață tipare și își îmbunătățește capacitatea de predicție. Acestea vă vor ajuta să determinați dacă modelul este supraadaptat (performanță bună la datele de antrenament, dar slab la datele nevăzute) sau subadaptare (nu învață suficient din datele de antrenament).
Următoarea matrice de confuzie reprezintă vizual cât de bine modelul distinge cu exactitate între clasele pozitive (imagine falsificată, reprezentată ca valoare 1) și negative (imagine nemodificată, reprezentată ca valoare 0).
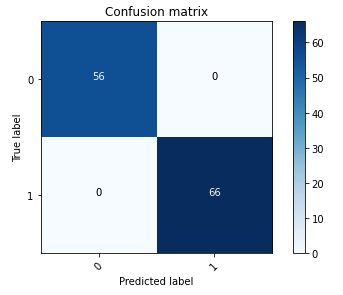
În urma pregătirii modelului, următorul nostru pas implică implementarea modelului de viziune computerizată ca API. Acest API va fi integrat în aplicațiile de afaceri ca o componentă a fluxului de lucru de subscriere. Pentru a realiza acest lucru, folosim Amazon SageMaker Inference, un serviciu complet gestionat. Acest serviciu se integrează perfect cu instrumentele MLOps, permițând implementarea modelelor scalabile, inferența eficientă din punct de vedere al costurilor, managementul îmbunătățit al modelului în producție și complexitatea operațională redusă. În această postare, implementăm modelul ca punct final de inferență în timp real. Cu toate acestea, este important să rețineți că, în funcție de fluxul de lucru al aplicațiilor dvs. de afaceri, implementarea modelului poate fi, de asemenea, adaptată ca procesare în lot, manipulare asincronă sau printr-o arhitectură de implementare fără server.
Configurați blocnotesul de implementare a modelului
Parcurgeți următorii pași pentru a configura blocnotesul dvs. de implementare a modelului:
- Deschideți
tampering_detection_model_deploy.ipynbfișier din directorul document-tampering-detection. - Configurați mediul notebook cu imaginea Data Science 3.0.
- Pentru Nucleu, alege Python3.
- Pentru Tipul instanței, alege ml.t3.mediu.
Cu un mediu de notebook ml.t3.medium, costul pe oră este de 0.056 USD.
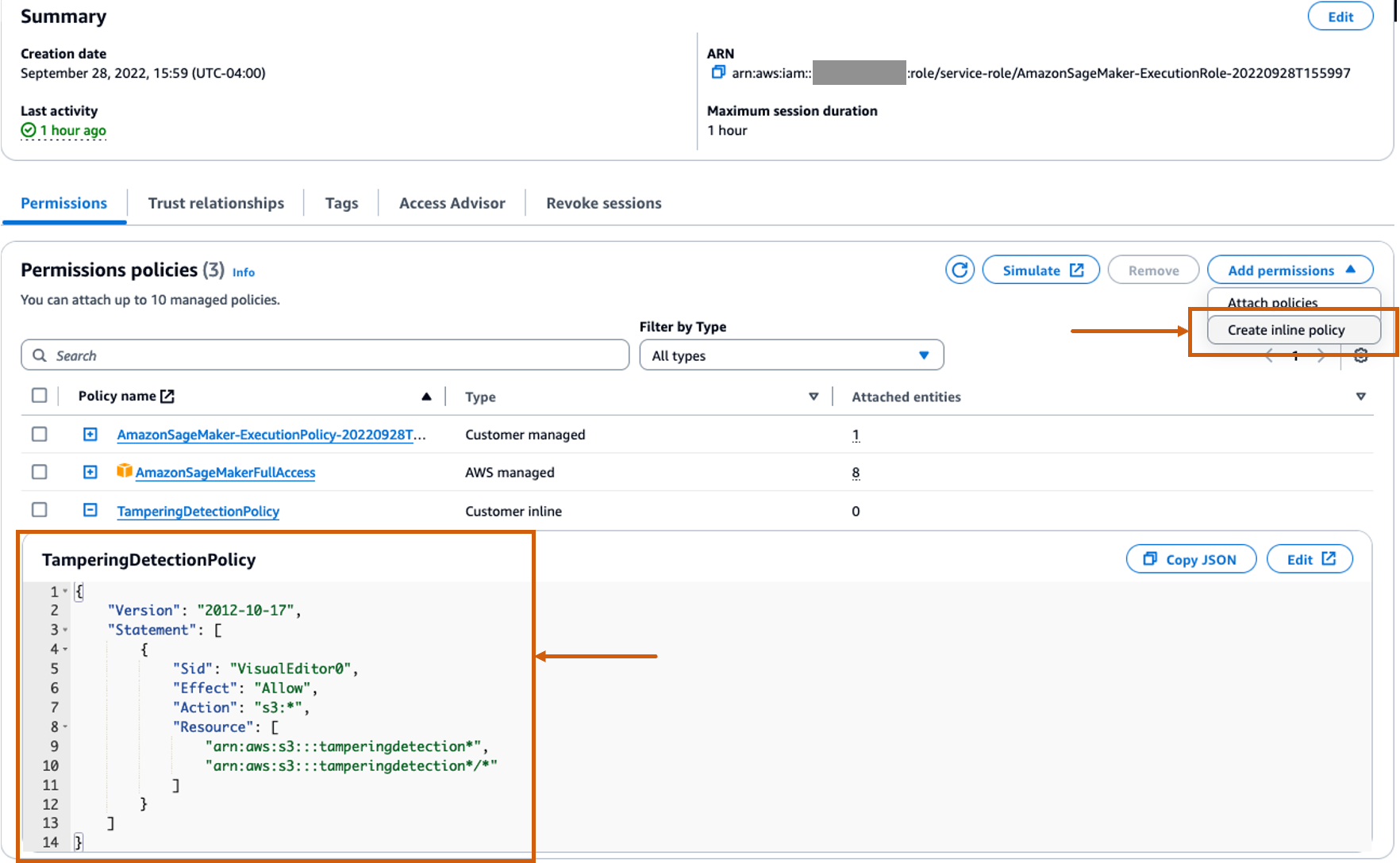
Creați o politică inline personalizată pentru rolul SageMaker pentru a permite toate acțiunile Amazon S3
Gestionarea identității și accesului AWS Rolul (IAM) pentru SageMaker va fi în format AmazonSageMaker- ExecutionRole-<random numbers>. Asigurați-vă că utilizați rolul corect. Numele rolului poate fi găsit sub detaliile utilizatorului din configurările domeniului SageMaker.

Actualizați rolul IAM pentru a include o politică integrată pentru a permite tuturor Serviciul Amazon de stocare simplă (Amazon S3) acțiuni. Acest lucru va fi necesar pentru a automatiza crearea și ștergerea compartimentelor S3 care vor stoca artefactele modelului. Puteți limita accesul la anumite compartimente S3. Rețineți că am folosit un wildcard pentru numele compartimentului S3 în politica IAM (tamperingdetection*).
Rulați blocnotesul de implementare
Rulați fiecare celulă din blocnotes tampering_detection_model_deploy.ipynb în ordine. Discutăm câteva celule mai detaliat în secțiunile următoare.
Creați o găleată S3
Rulați celula pentru a crea o găleată S3. Găleata va fi numită tamperingdetection<current date time> și în aceeași regiune AWS ca mediul dvs. SageMaker Studio.

Creați arhiva de artefacte model și încărcați pe Amazon S3
Creați un fișier tar.gz din artefactele modelului. Am salvat artefactele modelului într-un director numit 1, care conține semnături seriate și starea necesară pentru a le rula, inclusiv valori variabile și vocabulare pentru a le implementa în timpul de execuție SageMaker. De asemenea, puteți include un fișier de inferență personalizat numit inference.py în folderul de cod din artefactul model. Inferența personalizată poate fi utilizată pentru preprocesarea și postprocesarea imaginii de intrare.
![]()
Creați un punct final de inferență SageMaker
Celula pentru crearea unui punct final de inferență SageMaker poate dura câteva minute.
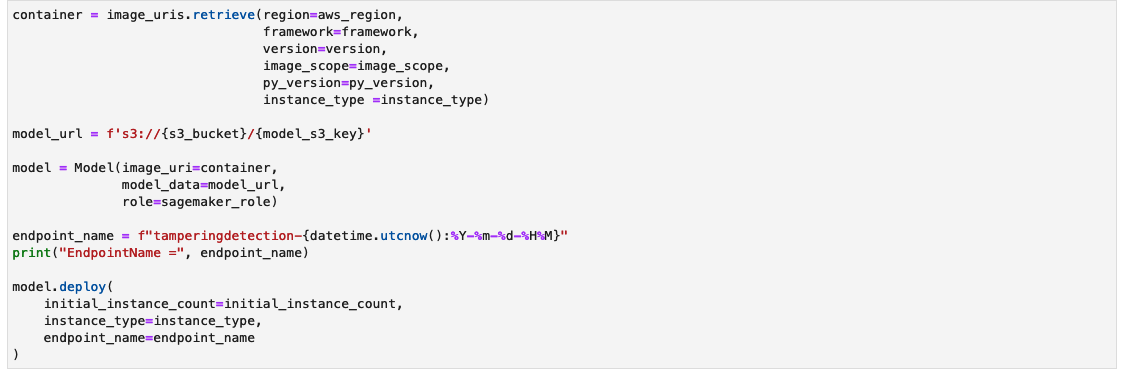
Testați punctul final de inferență
Funcția check_image preprocesează o imagine ca imagine ELA, o trimite la un punct final SageMaker pentru inferență, preia și procesează predicțiile modelului și tipărește rezultatele. Modelul preia o matrice NumPy a imaginii de intrare ca imagine ELA pentru a oferi predicții. Predicțiile sunt scoase ca 0, reprezentând o imagine nemodificată și 1, reprezentând o imagine falsificată.

Să invocăm modelul cu o imagine nemodificată a talonului de plată și să verificăm rezultatul.

Modelul emite clasificarea ca 0, reprezentând o imagine nemodificată.
Acum să invocăm modelul cu o imagine manipulată a talonului de plată și să verificăm rezultatul.

Modelul emite clasificarea ca 1, reprezentând o imagine falsificată.
Limitări
Deși ELA este un instrument excelent pentru a ajuta la detectarea modificărilor, există o serie de limitări, cum ar fi următoarele:
- Este posibil ca o singură modificare a pixelului sau o ajustare minoră a culorii să nu genereze o schimbare vizibilă în ELA, deoarece JPEG funcționează pe o grilă.
- ELA identifică doar ce regiuni au niveluri de compresie diferite. Dacă o imagine de calitate inferioară este îmbinată într-o imagine de calitate superioară, atunci imaginea de calitate inferioară poate apărea ca o regiune mai întunecată.
- Scalare, recolorare sau adăugare de zgomot la o imagine va modifica întreaga imagine, creând un potențial de nivel de eroare mai mare.
- Dacă o imagine este resalvată de mai multe ori, atunci aceasta poate fi în întregime la un nivel minim de eroare, unde mai multe resalvări nu modifică imaginea. În acest caz, ELA va returna o imagine neagră și nu pot fi identificate modificări folosind acest algoritm.
- Cu Photoshop, simplul act de salvare a imaginii poate ascuți automat texturile și marginile, creând un potențial de nivel de eroare mai mare. Acest artefact nu identifică modificarea intenționată; identifică faptul că a fost utilizat un produs Adobe. Din punct de vedere tehnic, ELA apare ca o modificare deoarece Adobe a efectuat automat o modificare, dar modificarea nu a fost neapărat intenționată de către utilizator.
Vă recomandăm să utilizați ELA alături de alte tehnici discutate anterior în blog pentru a detecta o gamă mai mare de cazuri de manipulare a imaginii. ELA poate servi, de asemenea, ca un instrument independent pentru examinarea vizuală a disparităților de imagine, mai ales atunci când formarea unui model bazat pe CNN devine o provocare.
A curăța
Pentru a elimina resursele pe care le-ați creat ca parte a acestei soluții, parcurgeți următorii pași:
- Rulați celulele notebook-ului sub A curăța secțiune. Aceasta va șterge următoarele:
- Punct final de inferență SageMaker – Numele punctului final de inferență va fi
tamperingdetection-<datetime>. - Obiecte din găleata S3 și găleata S3 în sine – Numele găleții va fi
tamperingdetection<datetime>.
- Punct final de inferență SageMaker – Numele punctului final de inferență va fi
- Închide resursele notebook-ului SageMaker Studio.
Concluzie
În această postare, am prezentat o soluție end-to-end pentru detectarea falsificării documentelor și a fraudei folosind deep learning și SageMaker. Am folosit ELA pentru a preprocesa imaginile și pentru a identifica discrepanțe în nivelurile de compresie care pot indica manipulare. Apoi am antrenat un model CNN pe acest set de date procesate pentru a clasifica imaginile ca originale sau modificate.
Modelul poate atinge performanțe puternice, cu o acuratețe de peste 95% cu un set de date (falsificat și original) potrivit pentru cerințele dvs. de afaceri. Acest lucru indică faptul că poate detecta în mod fiabil documente falsificate, cum ar fi talonele de plată și extrasele bancare. Modelul antrenat este implementat la un punct final SageMaker pentru a permite inferența cu latență scăzută la scară. Prin integrarea acestei soluții în fluxurile de lucru ipotecare, instituțiile pot semnala automat documentele suspecte pentru investigarea ulterioară a fraudelor.
Deși puternic, ELA are unele limitări în identificarea anumitor tipuri de manipulare mai subtilă. Ca următori pași, modelul ar putea fi îmbunătățit prin încorporarea unor tehnici criminalistice suplimentare în instruire și prin utilizarea unor seturi de date mai mari și mai diverse. În general, această soluție demonstrează modul în care puteți utiliza învățarea profundă și serviciile AWS pentru a construi soluții de impact care sporesc eficiența, reduc riscurile și previn frauda.
În partea 3, demonstrăm cum să implementăm soluția pe Amazon Fraud Detector.
Despre autori
 Anup Ravindranath este arhitect senior de soluții la Amazon Web Services (AWS) cu sediul în Toronto, Canada, lucrând cu organizații de servicii financiare. El îi ajută pe clienți să-și transforme afacerile și să inoveze pe cloud.
Anup Ravindranath este arhitect senior de soluții la Amazon Web Services (AWS) cu sediul în Toronto, Canada, lucrând cu organizații de servicii financiare. El îi ajută pe clienți să-și transforme afacerile și să inoveze pe cloud.
 Vinnie Saini este arhitect senior de soluții la Amazon Web Services (AWS) cu sediul în Toronto, Canada. Ea a ajutat clienții serviciilor financiare să se transforme pe cloud, cu soluții bazate pe inteligență artificială și ML așezate pe piloni de bază puternici ai excelenței arhitecturale.
Vinnie Saini este arhitect senior de soluții la Amazon Web Services (AWS) cu sediul în Toronto, Canada. Ea a ajutat clienții serviciilor financiare să se transforme pe cloud, cu soluții bazate pe inteligență artificială și ML așezate pe piloni de bază puternici ai excelenței arhitecturale.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/train-and-host-a-computer-vision-model-for-tampering-detection-on-amazon-sagemaker-part-2/
- :are
- :este
- :nu
- :Unde
- $UP
- 056
- 1
- 100
- 13
- 195
- 258
- 408
- 75
- 8
- 95%
- a
- capacitate
- Despre Noi
- acces
- accesibil
- Cont
- precizie
- precis
- Obține
- peste
- act
- acțiuni
- Activarea
- curent
- adăugat
- adăugare
- Suplimentar
- Adaugă
- regla
- Ajustare
- chirpici
- După
- împotriva
- AI
- urmări
- Algoritmul
- aliniere
- TOATE
- permite
- permite
- aproape
- de-a lungul
- pe langa
- de asemenea
- modificate
- Amazon
- Detector de fraude Amazon
- Amazon SageMaker
- Amazon SageMaker Studio
- Amazon Web Services
- Amazon Web Services (AWS)
- sumă
- an
- analiză
- analiza
- analiza
- și
- O alta
- Orice
- api
- apărea
- apare
- aplicatii
- aplicat
- abordare
- aproximativ
- arhitectural
- arhitectură
- arhivă
- SUNT
- ZONĂ
- domenii
- Mulțime
- AS
- presupune
- At
- automatizarea
- în mod automat
- disponibilitate
- disponibil
- AWS
- Bancă
- bazat
- Baschet
- BE
- deoarece
- devine
- fost
- CEL MAI BUN
- Mai bine
- între
- Negru
- Blog
- a stimula
- Luminos
- construi
- Clădire
- afaceri
- Aplicații pentru afaceri
- întreprinderi
- dar
- by
- calculată
- denumit
- aparat foto
- CAN
- Canada
- capturi
- caz
- cazuri
- Captură
- celulă
- Celule
- sigur
- provocare
- Schimbare
- Modificări
- canale
- Caracteristici
- verifica
- Alege
- clase
- clasificare
- Clasifica
- clar
- Cloud
- CNN
- cod
- culoare
- Coloane
- combinaţie
- comparaţie
- comparație
- comparație
- Completă
- complet
- complexitate
- component
- calculator
- Computer Vision
- configurarea
- confuzie
- conjuncție
- legat
- considerabil
- consistent
- constă
- Consoleze
- construi
- conține
- converti
- convertit
- rețea neuronală convoluțională
- corecta
- A costat
- ar putea
- Procesor
- crea
- a creat
- Crearea
- creaţie
- Curent
- curba
- personalizat
- clienţii care
- mai întunecat
- de date
- știința datelor
- seturi de date
- Data
- scădere
- adânc
- învățare profundă
- Mod implicit
- demonstra
- demonstrează
- denotă
- dens
- depinde
- Dependent/ă
- În funcție
- implementa
- dislocate
- Implementarea
- desfășurarea
- detaliu
- detalii
- detecta
- Detectare
- Determina
- dezvolta
- diagramă
- diferenţă
- diferenţele
- diferit
- digital
- direct
- discuta
- discutat
- afișează
- face distincția
- diferit
- do
- document
- documente
- Nu
- domeniu
- elaborate
- condus
- în timpul
- fiecare
- cu ușurință
- Margine
- Eficace
- eficiență
- scoate in evidenta
- angajarea
- permite
- permițând
- un capăt la altul
- Punct final
- sporită
- sporire
- suficient de
- Întreg
- în întregime
- Mediu inconjurator
- epoci
- eroare
- Erori
- mai ales
- Eter (ETH)
- Chiar
- Fiecare
- examinator
- exemplu
- Excelență
- excelent
- expune
- expozante
- expansiv
- de aşteptat
- expertiză
- extensie
- ochi
- facilitând
- factor
- puțini
- camp
- Fișier
- Filtre
- financiar
- Servicii financiare
- Găsi
- First
- fixată
- plat
- urma
- a urmat
- următor
- Pentru
- juridic
- criminalistica
- fals
- format
- găsit
- Fundație
- foundational
- patru
- fraudă
- din
- complet
- funcţie
- mai mult
- în general
- genera
- generează
- generator
- gif
- merge
- bine
- GPU
- mai mare
- Grilă
- îndrumare
- HAD
- Manipularea
- Greu
- Piese metalice
- Avea
- având în
- he
- ajutor
- ajutor
- ajută
- superior
- Evidențiați
- highlights-uri
- Lovit
- gazdă
- găzduit
- oră
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- IAM
- identificat
- identifică
- identifica
- identificarea
- Identitate
- IEEE
- if
- ignora
- ilustrează
- imagine
- imagini
- impactant
- punerea în aplicare a
- important
- îmbunătăţeşte
- îmbunătățirea
- in
- include
- Inclusiv
- incoerențe
- care încorporează
- Crește
- Creșteri
- independent
- independent
- indica
- indică
- individ
- informații
- inițială
- iniția
- inova
- intrare
- instanță
- cazuri
- instituții
- integrate
- integreaza
- integrarea
- Intenționat
- în
- introduce
- Prezintă
- investigaţie
- implică
- problema
- IT
- iterații
- ESTE
- în sine
- jpg
- A pastra
- keras
- Cunoaște
- cunoscut
- Etichetă
- lipsă
- mare
- mai mare
- mai tarziu
- lansa
- strat
- straturi
- Conduce
- AFLAȚI
- învăţare
- mai puțin
- Nivel
- nivelurile de
- categorie ușoară
- ca
- probabilitate
- Probabil
- LIMITĂ
- limitări
- liniar
- linii
- Listă
- Localizare
- Uite
- de pe
- LOWER
- maşină
- masina de învățare
- făcut
- mai ales
- face
- FACE
- Efectuarea
- gestionate
- administrare
- Manipulare
- multe
- Meci
- Matrice
- maxim
- Mai..
- mijloace
- măsuri
- mediu
- Întâlni
- metodă
- Metode
- minim
- minim
- minor
- minute
- ML
- MLOps
- model
- modificările aduse
- modificată
- modifica
- mai mult
- Ipotecare
- cele mai multe
- multiplu
- nume
- Numit
- în mod necesar
- Nevoie
- necesar
- negativ
- reţea
- rețele
- neural
- rețele neuronale
- cu toate acestea
- următor
- Nu.
- Zgomot
- nota
- caiet
- număr
- NumPy
- obiectiv
- evident
- of
- de multe ori
- on
- ONE
- afară
- opereaza
- operațional
- optimizate
- or
- comandă
- organizații
- original
- iniţial
- Altele
- in caz contrar
- al nostru
- rezultate
- producție
- iesiri
- peste
- global
- parametru
- parametrii
- parte
- special
- piese
- cale
- modele
- pentru
- performanță
- efectuată
- efectuarea
- efectuează
- photoshop
- imagine
- piloni
- Pixel
- Plato
- Informații despre date Platon
- PlatoData
- intrigă
- Politica
- porţiune
- pozitiv
- posibil
- Post
- potenţial
- potențiale
- puternic
- practică
- prezicere
- Predictii
- predictivă
- Pregăti
- premise
- prezenta
- prezentat
- conservat
- împiedica
- în prealabil
- printuri
- proces
- prelucrate
- procese
- prelucrare
- Produs
- producere
- progresie
- furniza
- prevăzut
- Piton
- calitate
- Chestionat
- mai repede
- aleator
- gamă
- rapid
- rată
- raport
- lumea reală
- în timp real
- tărâm
- motive
- primește
- recunoaște
- recomanda
- rectificat
- reduce
- Redus
- reduce
- trimite
- regiune
- regiuni
- relu
- se bazează
- îndepărtare
- scoate
- tencuială
- depozit
- reprezentate
- reprezentând
- reprezintă
- necesita
- necesar
- Cerinţe
- Necesită
- Rezoluţie
- Resurse
- REST
- limitat
- rezultat
- REZULTATE
- reveni
- RGB
- Risc
- Rol
- Alerga
- funcţionare
- sagemaker
- SageMaker Inference
- acelaşi
- Exemplu de set de date
- Economisiți
- salvate
- economisire
- scalabil
- Scară
- scalare
- scenarii
- Ştiinţă
- fără sudură
- perfect
- Al doilea
- Secțiune
- secțiuni
- selectate
- selectarea
- trimite
- senior
- serie
- servi
- serverless
- serviciu
- Servicii
- set
- configurarea
- ea
- schimbare
- Ture
- să
- Emisiuni
- Semnături
- semnifică
- Semne
- asemănător
- simplu
- Simplifică
- singur
- Mărimea
- mic
- netezi
- soluţie
- soluţii
- unele
- ceva
- spațial
- de specialitate
- specific
- specific
- specificată
- împărţi
- Loc
- pătrat
- pătrate
- început
- Stat
- Declarații
- Pas
- paşi
- Încă
- depozitare
- stoca
- pas
- puternic
- studio
- Ulterior
- astfel de
- sugerează
- sigur
- Suprafață
- susceptibil
- suspicios
- rapid
- sistem
- adaptate
- Lua
- ia
- obiective
- tehnic
- tehnică
- tehnici de
- tensorflow
- Terminal
- test
- Testarea
- decât
- acea
- Statul
- lor
- Lor
- apoi
- Acolo.
- Acestea
- lucruri
- acest
- trei
- Prin
- timp
- ori
- la
- instrument
- Unelte
- Toronto
- Total
- atins
- Tren
- dresat
- Pregătire
- Transforma
- transformări
- adevărat
- încerca
- Două
- tip
- Tipuri
- tipic
- în
- care stau la baza
- subscriere
- unic
- unitate
- Actualizează
- pe
- USD
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizări
- folosind
- validare
- valoare
- Valori
- variabil
- diverse
- versiune
- vizibil
- viziune
- Vizita
- vizual
- vizual
- vrea
- a fost
- we
- web
- servicii web
- BINE
- au fost
- Ce
- cand
- care
- larg
- voi
- cu
- în
- fără
- flux de lucru
- fluxuri de lucru
- de lucru
- fabrică
- tu
- Ta
- zephyrnet
- zero