Odată cu lansarea funcției de căutare neuronală pentru Serviciul Amazon OpenSearch în OpenSearch 2.9, este acum fără efort să se integreze cu modelele AI/ML pentru a alimenta căutarea semantică și alte cazuri de utilizare. Serviciul OpenSearch a acceptat atât căutarea lexicală, cât și cea vectorială de la introducerea caracteristicii k-nearest neighbor (k-NN) în 2020; cu toate acestea, configurarea căutării semantice a necesitat construirea unui cadru care să integreze modele de învățare automată (ML) pentru a le asimila și a căuta. Caracteristica de căutare neuronală facilitează transformarea text în vector în timpul ingerării și căutării. Când utilizați o interogare neuronală în timpul căutării, interogarea este tradusă într-o încorporare vectorială și k-NN este folosit pentru a returna cele mai apropiate înglobări vectoriale din corpus.
Pentru a utiliza căutarea neuronală, trebuie să configurați un model ML. Vă recomandăm să configurați conectorii AI/ML la serviciile AWS AI și ML (cum ar fi Amazon SageMaker or Amazon Bedrock) sau alternative terțe. Începând cu versiunea 2.9 a Serviciului OpenSearch, conectorii AI/ML se integrează cu căutarea neuronală pentru a simplifica și operaționaliza traducerea corpusului de date și a interogărilor în înglobări vectoriale, eliminând astfel o mare parte din complexitatea hidratării și a căutării vectorilor.
În această postare, demonstrăm cum să configurați conectorii AI/ML la modele externe prin consola OpenSearch Service.
Prezentare generală a soluției
Mai exact, această postare vă ghidează prin conectarea la un model în SageMaker. Apoi vă ghidăm prin utilizarea conectorului pentru a configura căutarea semantică pe Serviciul OpenSearch ca exemplu de caz de utilizare care este acceptat prin conexiunea la un model ML. Integrările Amazon Bedrock și SageMaker sunt acceptate în prezent pe interfața de utilizare a consolei OpenSearch Service, iar lista de integrări primare și terțe acceptate de UI va continua să crească.
Pentru toate modelele care nu sunt acceptate prin interfața de utilizare, le puteți configura folosind API-urile disponibile și Planuri ML. Pentru mai multe informații, consultați Introducere în modelele OpenSearch. Puteți găsi planuri pentru fiecare conector în Depozitul GitHub ML Commons.
Cerințe preliminare
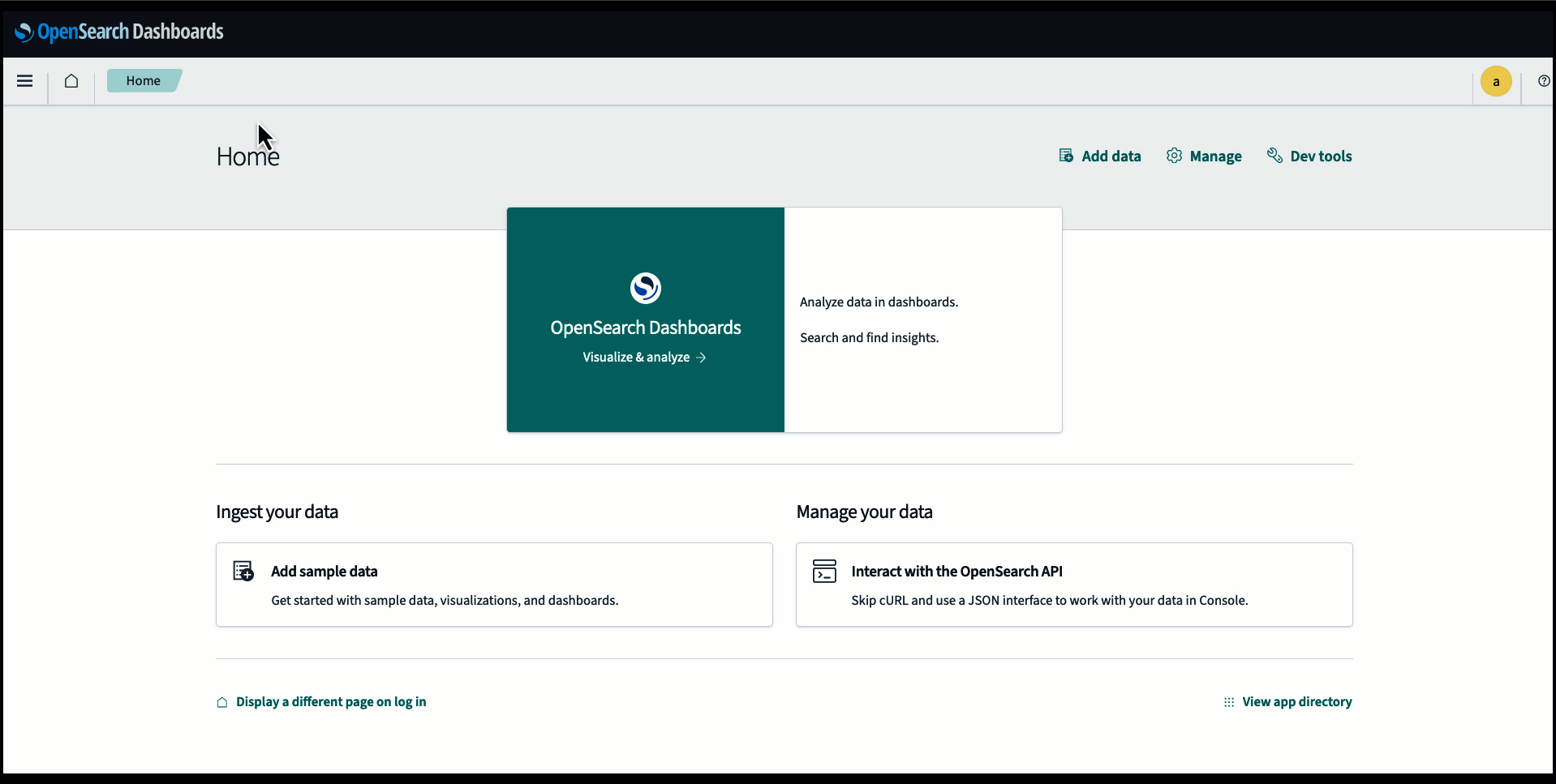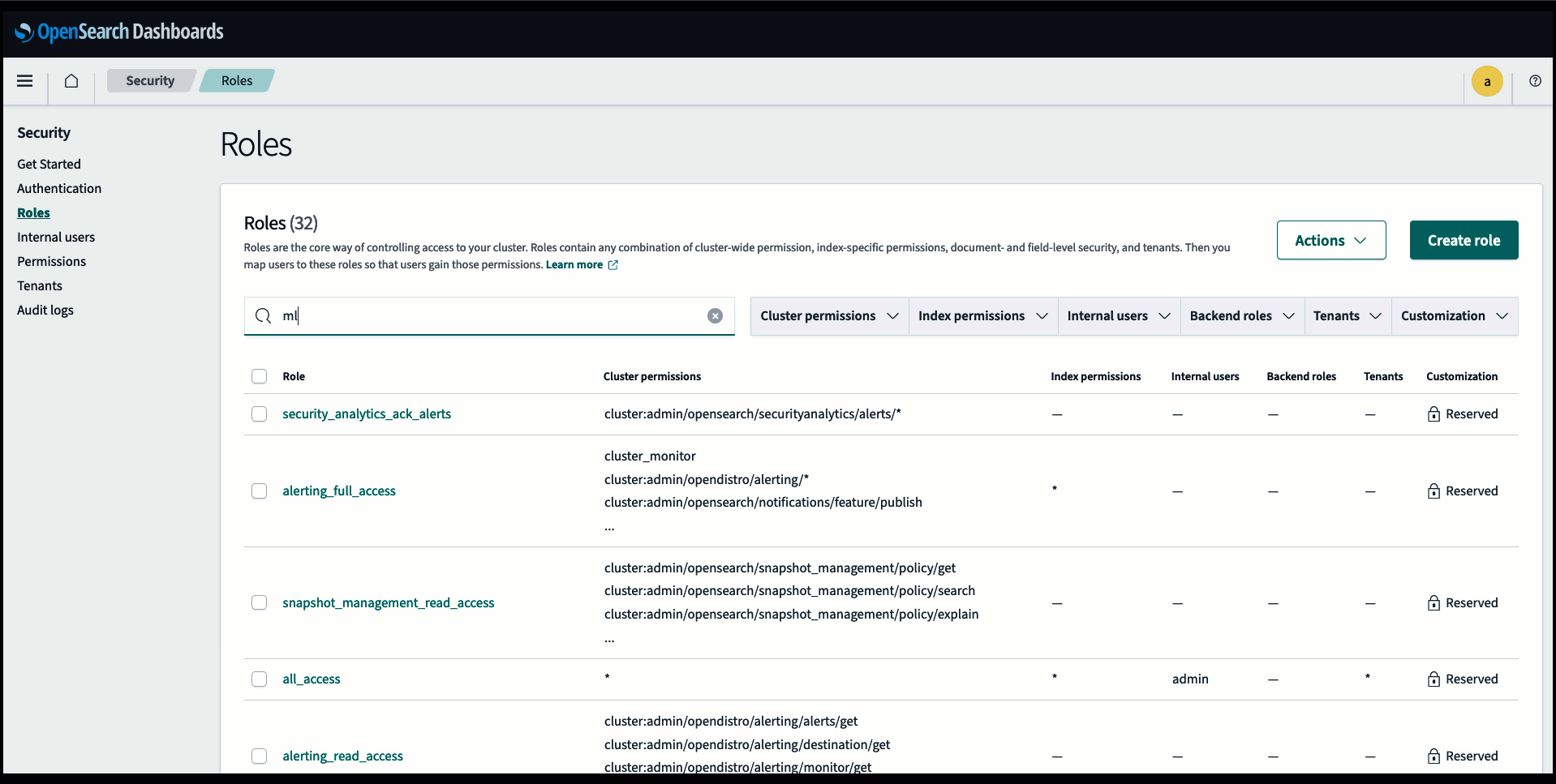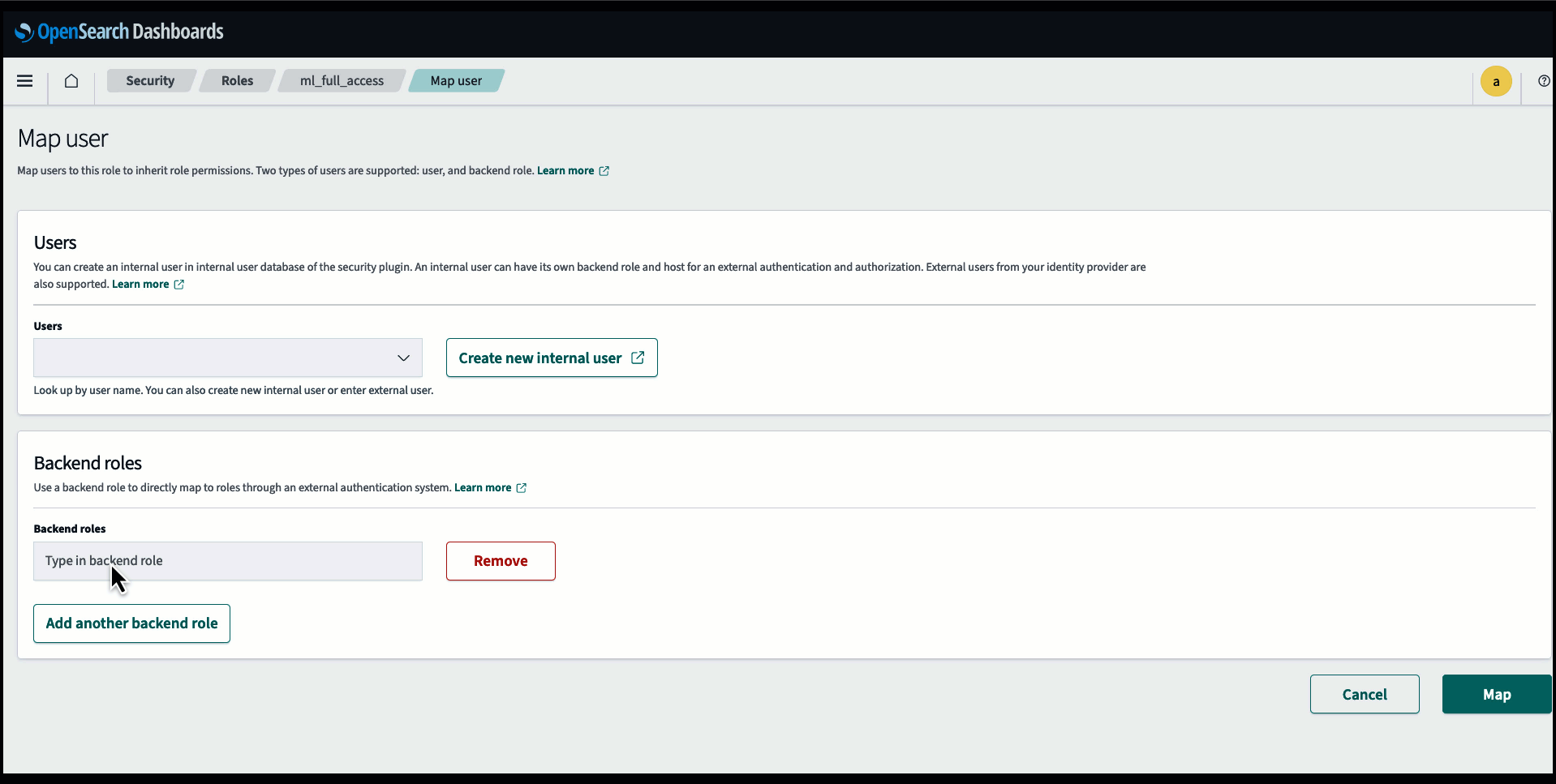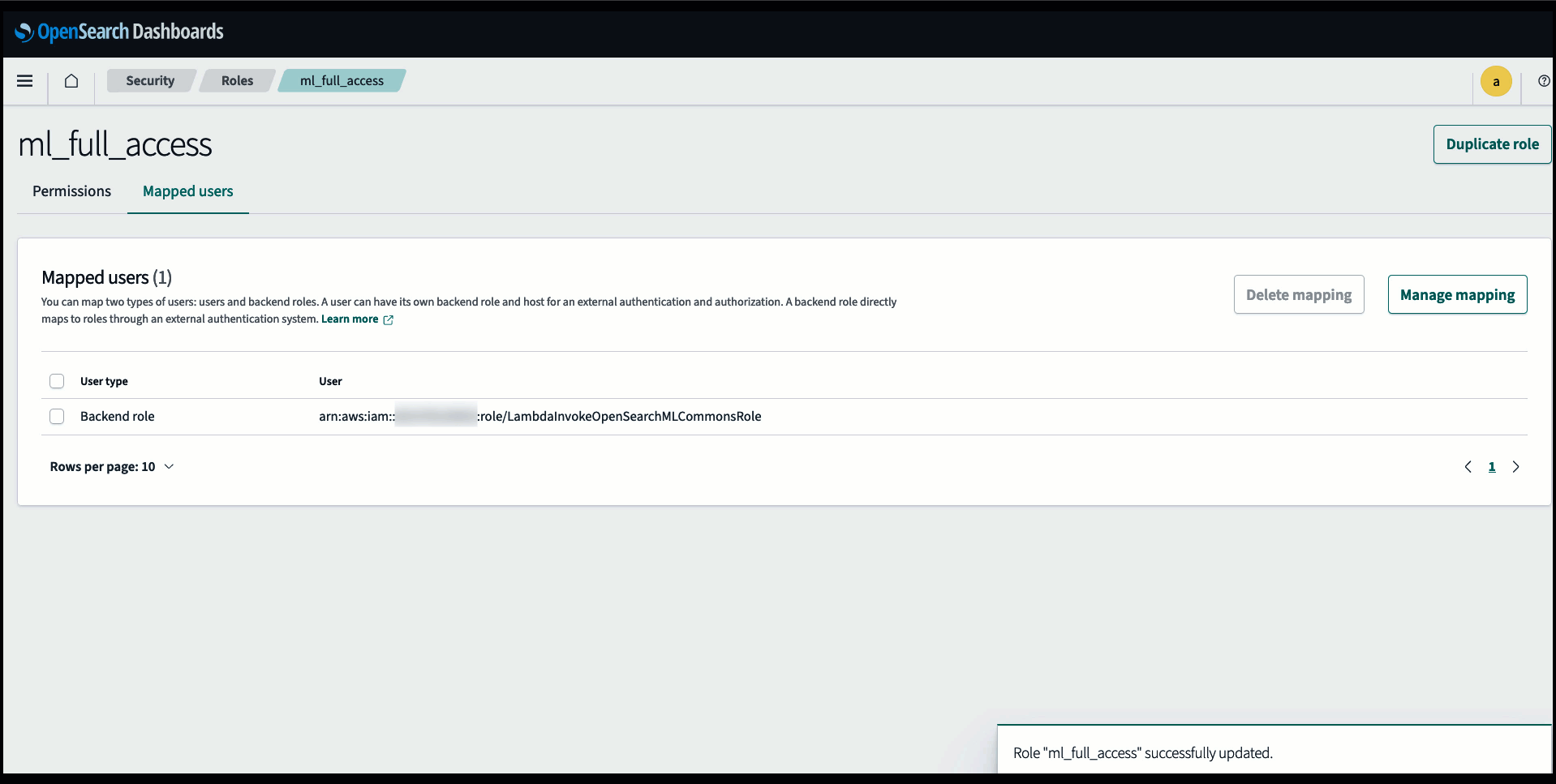
Înainte de a conecta modelul prin consola OpenSearch Service, creați un domeniu OpenSearch Service. Harta an Gestionarea identității și accesului AWS (IAM) rol după nume LambdaInvokeOpenSearchMLCommonsRole ca rol de backend pe ml_full_access rol folosind pluginul de securitate pe tablourile de bord OpenSearch, așa cum se arată în videoclipul următor. Fluxul de lucru pentru integrarea serviciului OpenSearch este pre-completat pentru a utiliza LambdaInvokeOpenSearchMLCommonsRole Rolul IAM în mod implicit pentru a crea conectorul între domeniul OpenSearch Service și modelul implementat pe SageMaker. Dacă utilizați un rol personalizat IAM în integrările consolei OpenSearch Service, asigurați-vă că rolul personalizat este mapat ca rol backend cu ml_full_access permisiunile înainte de implementarea șablonului.
Implementați modelul folosind AWS CloudFormation
Următorul videoclip demonstrează pașii pentru a utiliza consola OpenSearch Service pentru a implementa un model în câteva minute pe Amazon SageMaker și pentru a genera ID-ul modelului prin conectorii AI. Primul pas este să alegi Integrations în panoul de navigare din consola OpenSearch Service AWS, care direcționează către o listă de integrări disponibile. Integrarea este configurată printr-o interfață de utilizare, care vă va solicita intrările necesare.
Pentru a configura integrarea, trebuie doar să furnizați punctul final al domeniului OpenSearch Service și să furnizați un nume de model pentru a identifica în mod unic conexiunea modelului. În mod implicit, șablonul implementează modelul de transformatori de propoziții Hugging Face, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
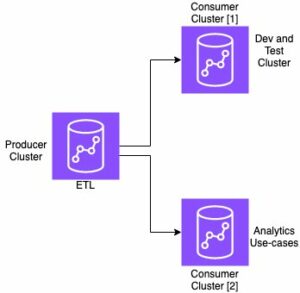
Când alegi Creați Stack, sunteți direcționat către Formarea AWS Cloud consolă. Șablonul CloudFormation implementează arhitectura detaliată în diagrama următoare.

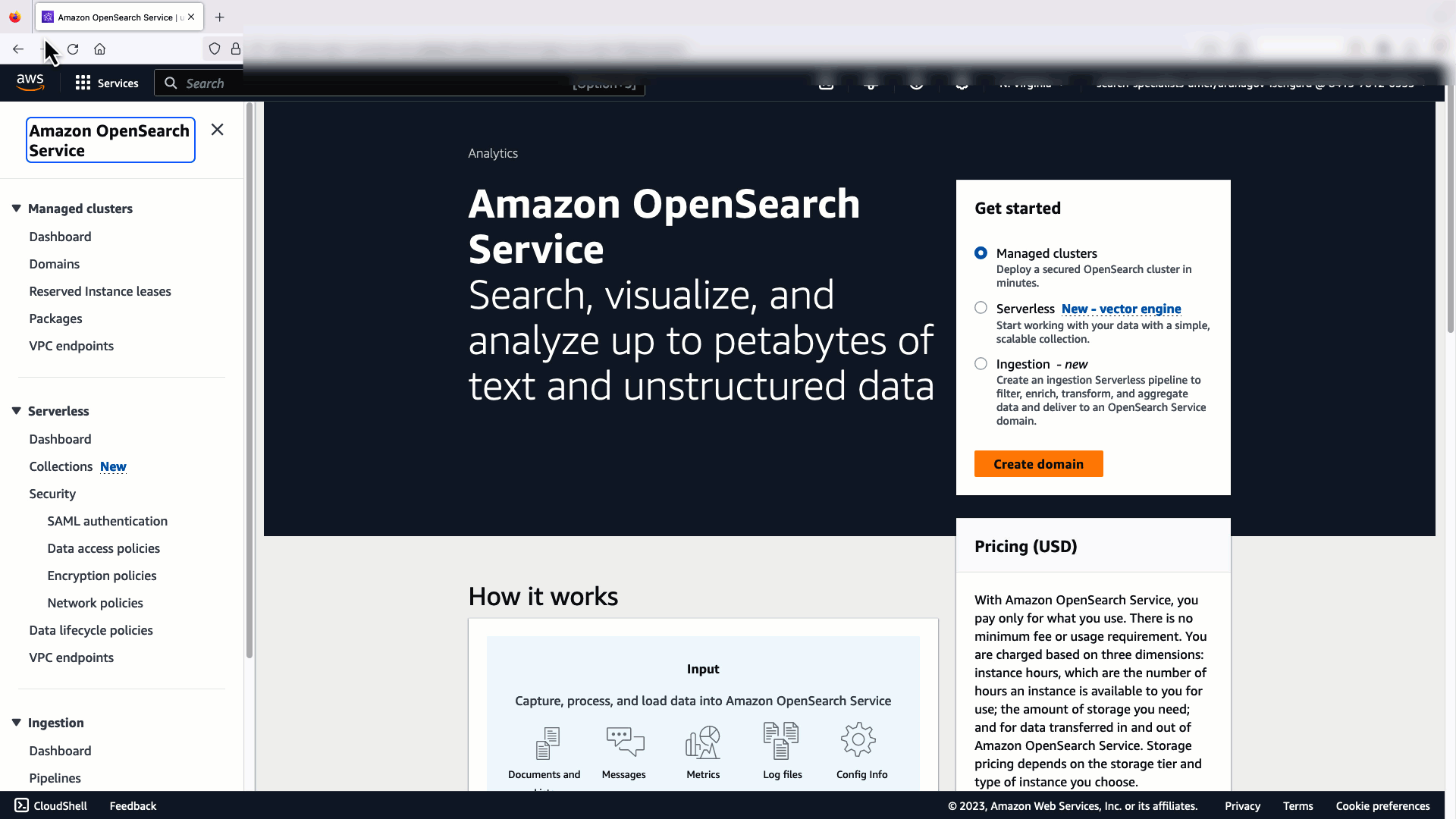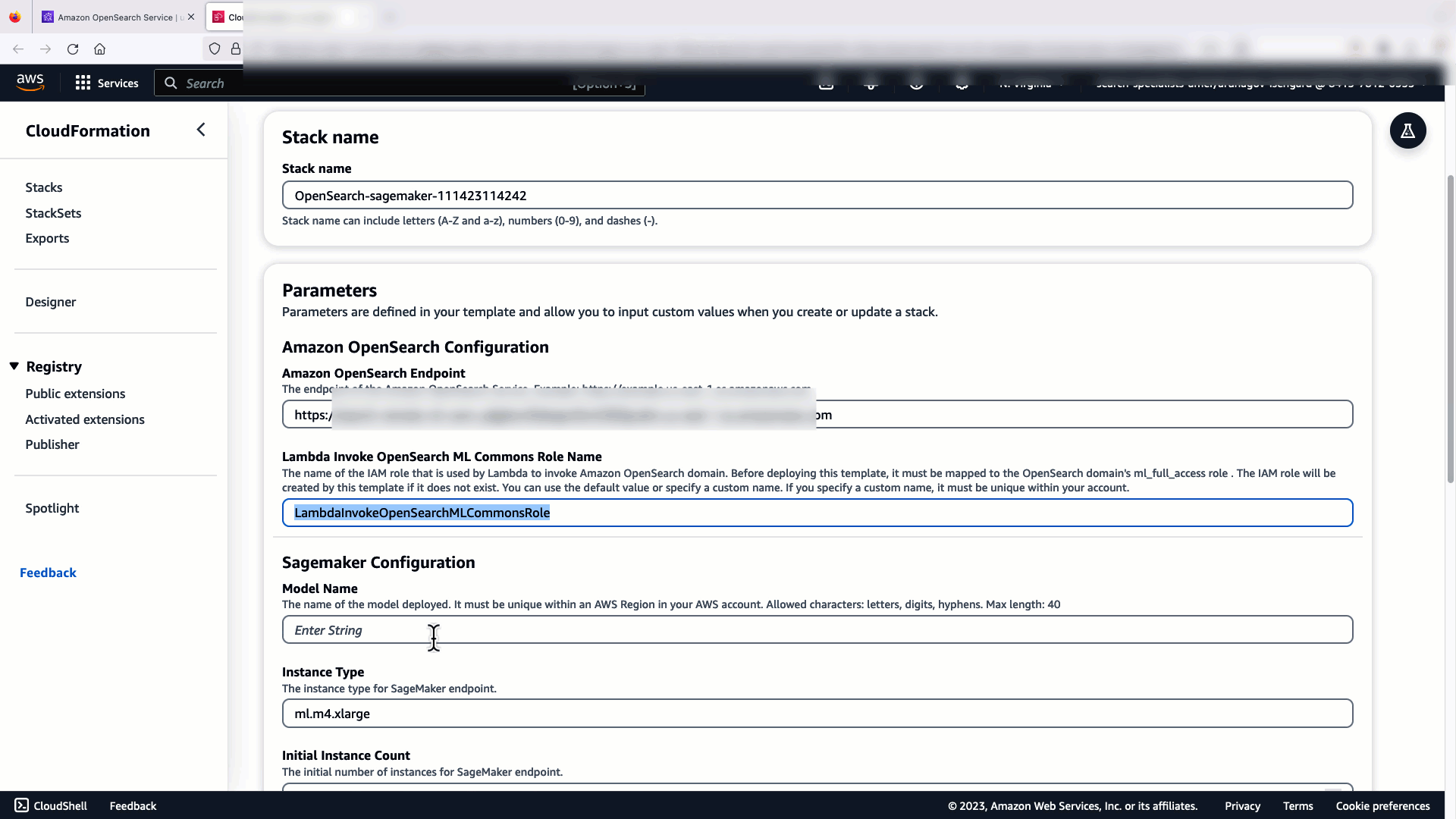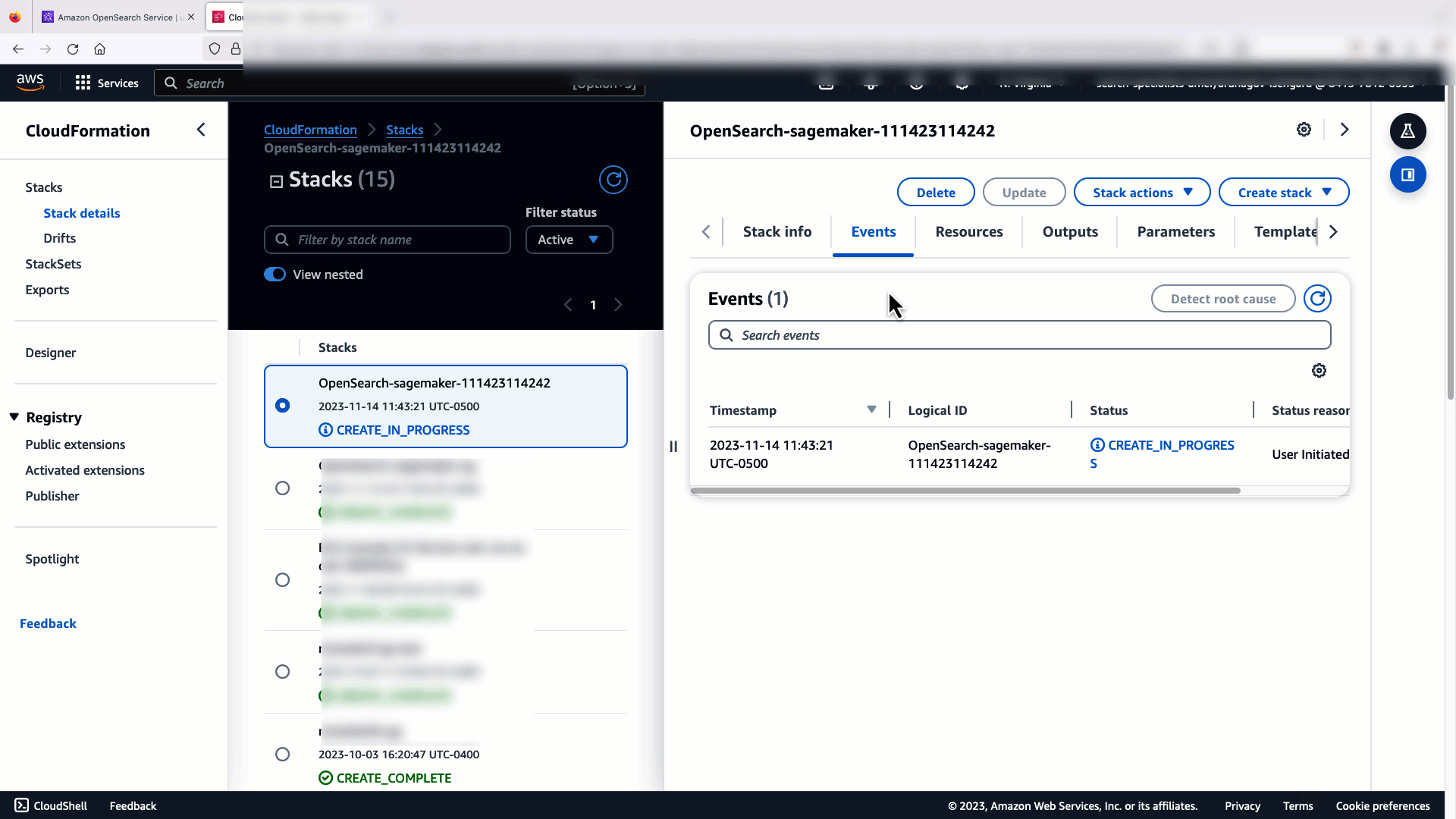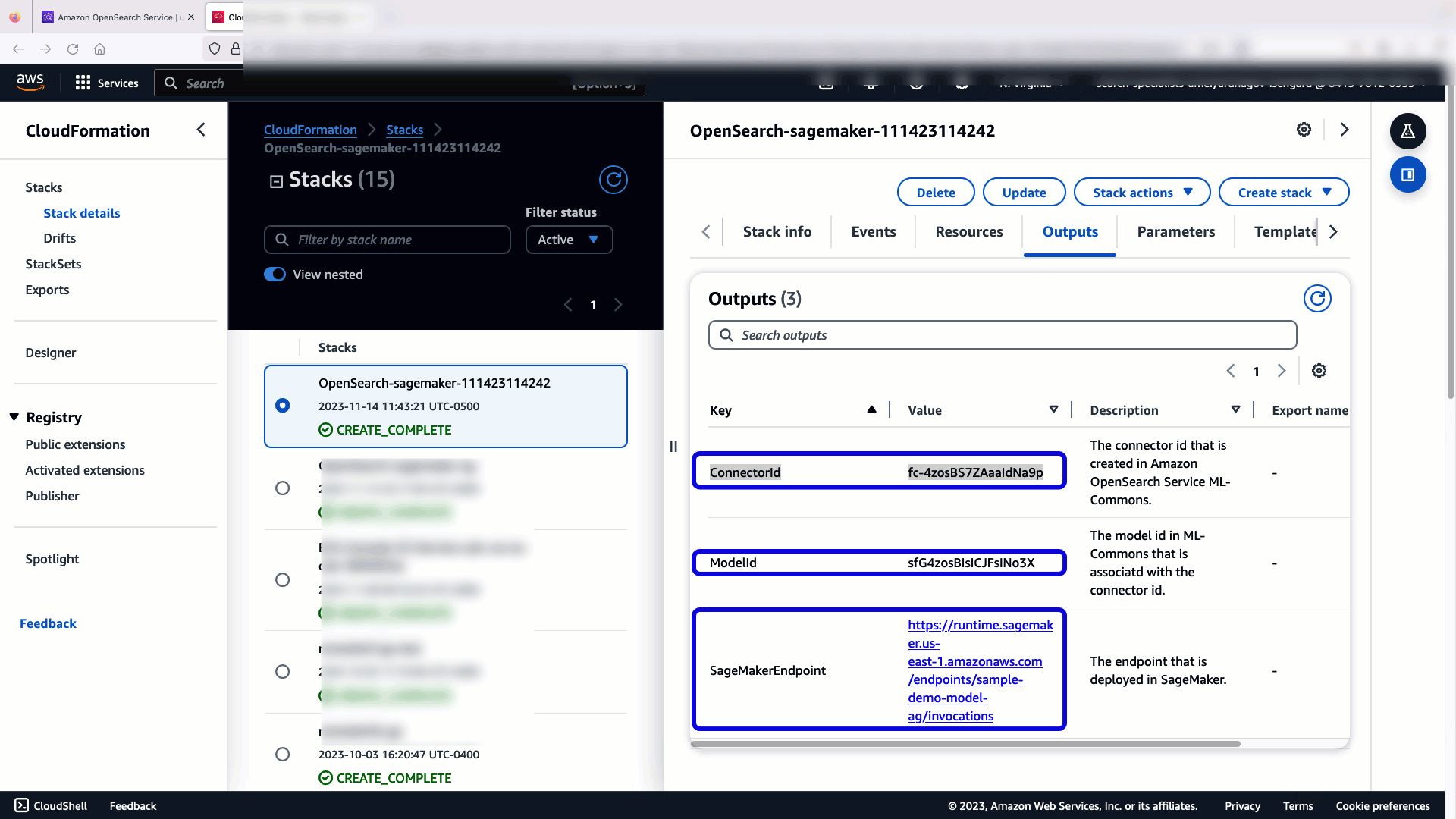
Stiva CloudFormation creează un AWS Lambdas aplicație care implementează un model din Serviciul Amazon de stocare simplă (Amazon S3), creează conectorul și generează ID-ul modelului în ieșire. Apoi puteți utiliza acest ID de model pentru a crea un index semantic.
Dacă modelul implicit, complet MiniLM-L6-v2, nu vă servește scopului, puteți implementa orice model de încorporare de text la alegere pe gazda modelului aleasă (SageMaker sau Amazon Bedrock) furnizând artefactele modelului dvs. ca obiect S3 accesibil. Alternativ, puteți selecta una dintre următoarele modele de limbaj preinstruit și implementați-l în SageMaker. Pentru instrucțiuni de configurare a terminalului și a modelelor, consultați Imagini disponibile Amazon SageMaker.
SageMaker este un serviciu complet gestionat care reunește un set larg de instrumente pentru a permite ML de înaltă performanță și la costuri reduse pentru orice caz de utilizare, oferind beneficii cheie, cum ar fi monitorizarea modelelor, găzduirea fără server și automatizarea fluxului de lucru pentru instruire și implementare continuă. SageMaker vă permite să găzduiți și să gestionați ciclul de viață al modelelor de încorporare a textului și să le utilizați pentru a alimenta interogări de căutare semantică în Serviciul OpenSearch. Când este conectat, SageMaker găzduiește modelele dvs. și Serviciul OpenSearch este utilizat pentru a interoga pe baza rezultatelor de inferență de la SageMaker.
Vizualizați modelul implementat prin OpenSearch Dashboards
Pentru a verifica că șablonul CloudFormation a implementat cu succes modelul pe domeniul OpenSearch Service și pentru a obține ID-ul modelului, puteți utiliza API-ul ML Commons REST GET prin OpenSearch Dashboards Dev Tools.
GET _plugins REST API oferă acum API-uri suplimentare pentru a vedea și starea modelului. Următoarea comandă vă permite să vedeți starea unui model de la distanță:
După cum se arată în următoarea captură de ecran, a DEPLOYED starea din răspuns indică că modelul este implementat cu succes pe clusterul OpenSearch Service.

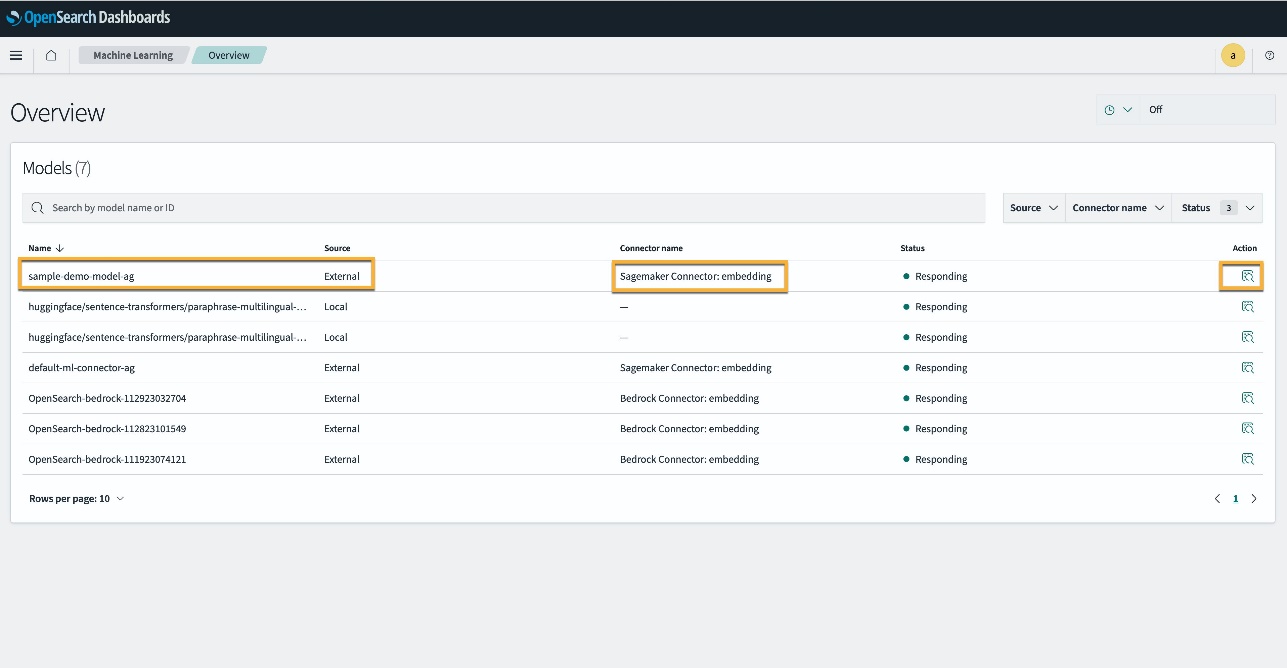
Alternativ, puteți vizualiza modelul implementat pe domeniul dvs. OpenSearch Service folosind Invatare mecanica pagina de tablouri de bord OpenSearch.

Această pagină listează informațiile despre model și stările tuturor modelelor implementate.

Creați conducta neuronală folosind ID-ul modelului
Când starea modelului arată ca fie DEPLOYED în Dev Tools sau verde și Răspunsul în OpenSearch Dashboards, puteți utiliza ID-ul modelului pentru a vă construi conducta de asimilare neuronală. Următorul canal de asimilare este rulat în instrumentele de dezvoltare OpenSearch Dashboards ale domeniului dvs. Asigurați-vă că înlocuiți ID-ul modelului cu ID-ul unic generat pentru modelul implementat pe domeniul dvs.

Creați indexul de căutare semantică folosind conducta neuronală ca conductă implicită
Acum puteți defini maparea indexului cu conducta implicită configurată pentru a utiliza noua conductă neuronală pe care ați creat-o la pasul anterior. Asigurați-vă că câmpurile vectoriale sunt declarate ca knn_vector iar dimensiunile sunt adecvate modelului care este implementat pe SageMaker. Dacă ați păstrat configurația implicită pentru a implementa modelul all-MiniLM-L6-v2 pe SageMaker, păstrați următoarele setări așa cum sunt și rulați comanda în Dev Tools.

Ingerați documente mostre pentru a genera vectori
Pentru această demonstrație, puteți ingera fișierul eșantion de catalog de produse din magazinul cu amănuntul la nou semantic_demostore index. Înlocuiți numele de utilizator, parola și punctul final al domeniului cu informațiile de domeniu și ingerați date brute în Serviciul OpenSearch:

Validați noul index semantic_demostore
Acum că v-ați ingerat setul de date în domeniul OpenSearch Service, validați dacă vectorii necesari sunt generați folosind o căutare simplă pentru a prelua toate câmpurile. Validați dacă câmpurile definite ca knn_vectors au vectorii necesari.

Comparați căutarea lexicală și căutarea semantică alimentată de căutarea neuronală folosind instrumentul Comparați rezultatele căutării
Instrumentul de comparare a rezultatelor căutării pe OpenSearch Dashboards este disponibil pentru sarcinile de lucru de producție. Puteți naviga la Comparați rezultatele căutării pagina și comparați rezultatele interogării între căutarea lexicală și căutarea neuronală configurată pentru a utiliza ID-ul modelului generat mai devreme.

A curăța
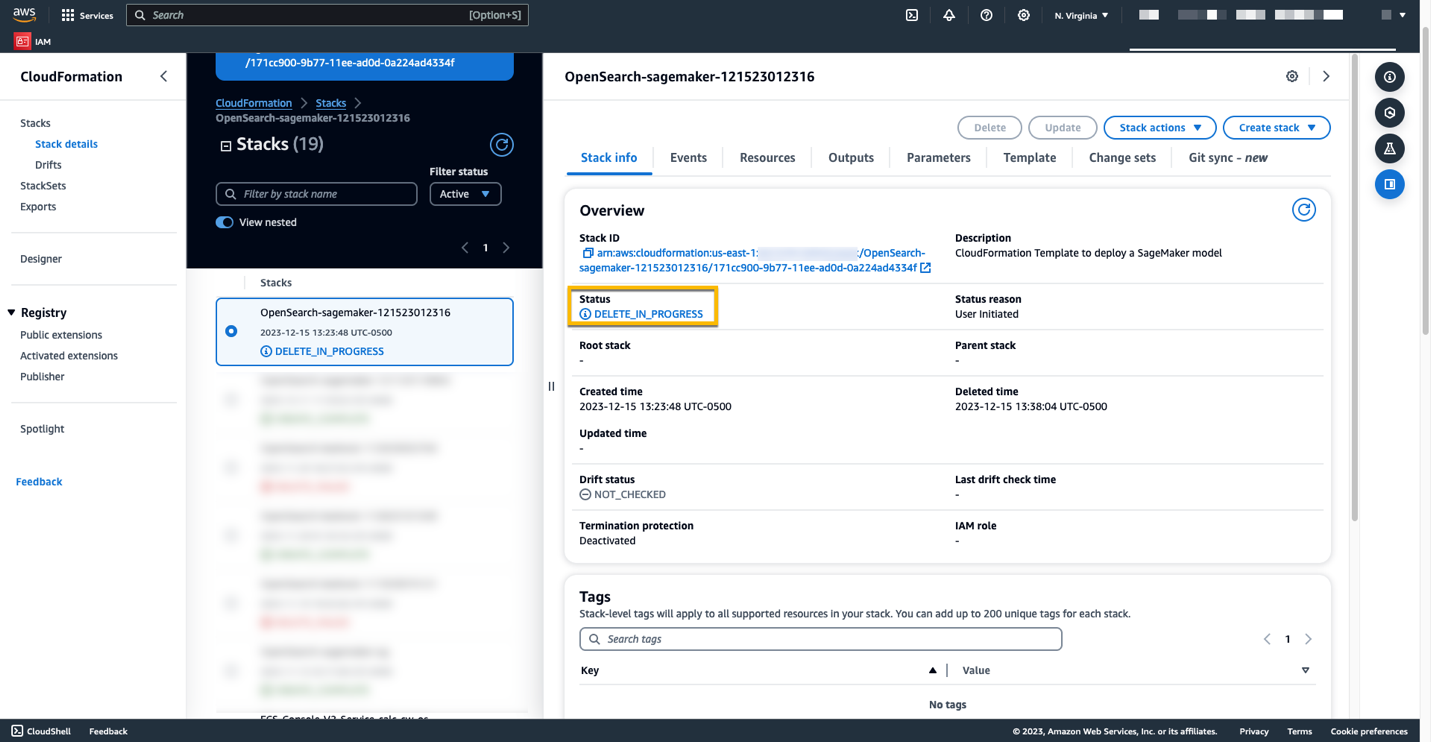
Puteți șterge resursele pe care le-ați creat urmând instrucțiunile din această postare, ștergând stiva CloudFormation. Aceasta va șterge resursele Lambda și compartimentul S3 care conțin modelul care a fost implementat în SageMaker. Parcurgeți următorii pași:
- În consola AWS CloudFormation, navigați la pagina cu detaliile stivei.
- Alege Șterge.

- Alege Șterge a confirma.

Puteți monitoriza progresul ștergerii stivei pe consola AWS CloudFormation.
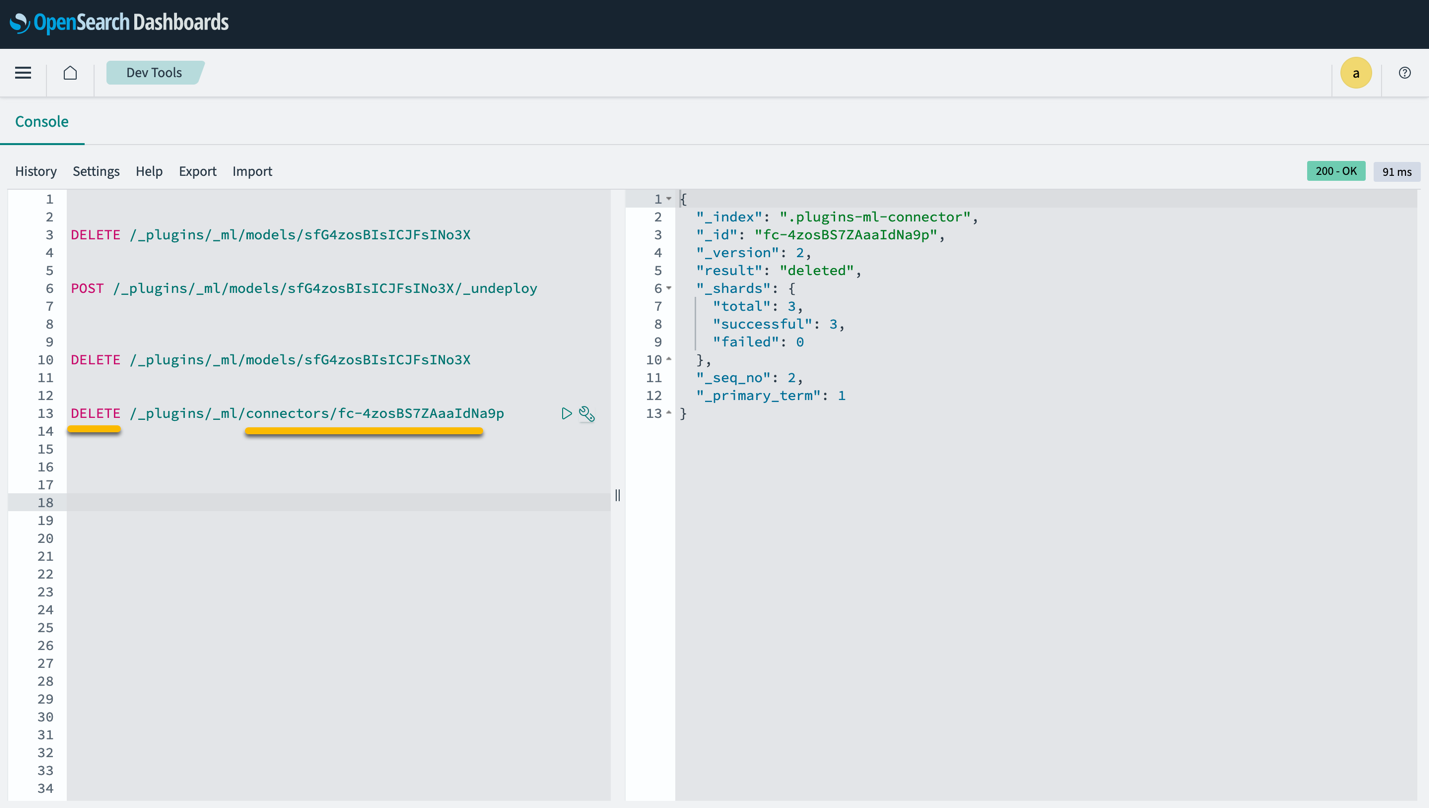
Rețineți că, ștergerea stivei CloudFormation nu șterge modelul implementat pe domeniul SageMaker și conectorul AI/ML creat. Acest lucru se datorează faptului că aceste modele și conectorul pot fi asociate cu mai mulți indici din domeniu. Pentru a șterge în mod specific un model și conectorul asociat acestuia, utilizați API-urile model așa cum se arată în capturile de ecran de mai jos.
În primul rând, undeploy modelul din memoria domeniului OpenSearch Service:

Apoi puteți șterge modelul din indexul modelului:

În cele din urmă, ștergeți conectorul din indexul conectorului:
Concluzie
În această postare, ați învățat cum să implementați un model în SageMaker, să creați conectorul AI/ML folosind consola OpenSearch Service și să construiți indexul de căutare neuronală. Abilitatea de a configura conectori AI/ML în Serviciul OpenSearch simplifică procesul de hidratare a vectorului, făcând integrarea modelelor externe native. Puteți crea un index de căutare neuronală în câteva minute folosind conducta de ingestie neuronală și căutarea neuronală care utilizează ID-ul modelului pentru a genera încorporarea vectorului din mers în timpul ingerării și căutării.
Pentru a afla mai multe despre acești conectori AI/ML, consultați Conectori AI Amazon OpenSearch Service pentru serviciile AWS, Integrari de șabloane AWS CloudFormation pentru căutare semantică, și Crearea de conectori pentru platforme ML terțe.
Despre Autori
 Aruna Govindaraju este un Amazon OpenSearch Specialist Solutions Architect și a lucrat cu multe motoare de căutare comerciale și open source. Este pasionată de căutare, relevanță și experiența utilizatorului. Experiența ei în corelarea semnalelor utilizatorilor finali cu comportamentul motorului de căutare a ajutat mulți clienți să-și îmbunătățească experiența de căutare.
Aruna Govindaraju este un Amazon OpenSearch Specialist Solutions Architect și a lucrat cu multe motoare de căutare comerciale și open source. Este pasionată de căutare, relevanță și experiența utilizatorului. Experiența ei în corelarea semnalelor utilizatorilor finali cu comportamentul motorului de căutare a ajutat mulți clienți să-și îmbunătățească experiența de căutare.
 Dagney Braun este manager de produs principal la AWS, concentrat pe OpenSearch.
Dagney Braun este manager de produs principal la AWS, concentrat pe OpenSearch.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- :are
- :este
- :nu
- $UP
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- capacitate
- Despre Noi
- acces
- accesibil
- Suplimentar
- AI
- AI / ML
- TOATE
- permite
- de asemenea
- alternative
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- și
- Orice
- api
- API-uri
- aplicație
- adecvat
- arhitectură
- SUNT
- AS
- asociate
- At
- Automatizare
- disponibil
- AWS
- Formarea AWS Cloud
- Backend
- bazat
- BE
- deoarece
- comportament
- Beneficiile
- între
- atât
- Aduce
- larg
- construi
- Clădire
- by
- CAN
- caz
- cazuri
- catalog
- alegere
- Alege
- ales
- Grup
- comercial
- Commons
- comparaţie
- Completă
- complexitate
- Configuraţie
- configurat
- configurarea
- Confirma
- legat
- Conectarea
- conexiune
- Consoleze
- conţine
- continua
- continuu
- corelând
- crea
- a creat
- creează
- În prezent
- personalizat
- clienţii care
- tablouri de bord
- de date
- Mod implicit
- defini
- definit
- livrarea
- Demo
- demonstra
- demonstrează
- implementa
- dislocate
- Implementarea
- desfășurarea
- implementează
- descriere
- detaliat
- detalii
- dev
- Dimensiune
- Dimensiuni
- documente
- Nu
- domeniu
- în timpul
- fiecare
- Mai devreme
- fără efort
- oricare
- Încorporarea
- permite
- Punct final
- Motor
- Motoare
- asigura
- Eter (ETH)
- exemplu
- experienţă
- expertiză
- extern
- Față
- facilitează
- Caracteristică
- Domenii
- Găsi
- First
- concentrat
- următor
- Pentru
- Cadru
- din
- complet
- genera
- generată
- generează
- obține
- gif
- GitHub
- Verde
- Crește
- ghida
- Avea
- a ajutat
- ei
- performanta ridicata
- gazdă
- găzduire
- Gazdele
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- Față îmbrățișată
- hidratare
- IAM
- ID
- identifica
- Identitate
- if
- îmbunătăţi
- in
- index
- indexurile
- indică
- informații
- intrări
- in schimb
- instrucțiuni
- integra
- integrare
- integrările
- în
- Introducere
- IT
- ESTE
- jpg
- JSON
- A pastra
- Cheie
- limbă
- lansa
- AFLAȚI
- învățat
- învăţare
- ciclu de viață
- Listă
- liste
- low-cost
- maşină
- masina de învățare
- face
- Efectuarea
- administra
- gestionate
- manager
- multe
- Hartă
- cartografiere
- Memorie
- metodă
- minute
- ML
- model
- Modele
- monitor
- Monitorizarea
- mai mult
- mult
- multiplu
- trebuie sa
- nume
- nativ
- Navigaţi
- Navigare
- necesar
- Nevoie
- neural
- Nou
- acum
- obiect
- of
- on
- ONE
- afară
- deschide
- open-source
- or
- Altele
- producție
- pagină
- pâine
- pasionat
- Parolă
- permisiuni
- conducte
- Plato
- Informații despre date Platon
- PlatoData
- conecteaza
- Post
- putere
- alimentat
- precedent
- Principal
- anterior
- proces
- procesoare
- Produs
- manager de produs
- producere
- Progres
- proprietăţi
- furniza
- furnizează
- furnizarea
- scop
- interogări
- Crud
- date neprelucrate
- recomanda
- trimite
- la distanta
- eliminarea
- înlocui
- necesar
- Resurse
- răspuns
- REST
- REZULTATE
- cu amănuntul
- reținut
- reveni
- Rol
- rute
- Alerga
- sagemaker
- capturi de ecran
- Caută
- motor de cautare
- Motoare de cautare
- securitate
- vedea
- selecta
- servi
- serverless
- serviciu
- Servicii
- set
- setări
- ea
- indicat
- Emisiuni
- semnalele
- simplu
- Simplifică
- simplifica
- întrucât
- soluţii
- Sursă
- specialist
- specific
- stivui
- Pornire
- Stare
- Pas
- paşi
- depozitare
- Reușit
- astfel de
- Suportat
- sigur
- șablon
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- acea
- lor
- Lor
- apoi
- astfel
- Acestea
- terț
- acest
- Prin
- la
- împreună
- Unelte
- Pregătire
- Transformare
- Traducere
- adevărat
- tip
- ui
- unic
- unic
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- Experiența de utilizare
- folosind
- VALIDA
- verifica
- versiune
- de
- Video
- Vizualizare
- plimbări
- a fost
- we
- web
- servicii web
- cand
- care
- voi
- cu
- în
- a lucrat
- flux de lucru
- automatizarea fluxului de lucru
- tu
- Ta
- zephyrnet