Imagine de autor
Alăturați-vă KDnuggets cu calea noastră Înapoi la elementele de bază pentru a vă ajuta să începeți o nouă carieră sau să vă perfecționați abilitățile de știință a datelor. Calea Înapoi la principii este împărțită în 4 săptămâni, cu o săptămână bonus. Sperăm că puteți folosi aceste bloguri ca ghid de curs.
Dacă nu ați făcut-o deja, aruncați o privire la:
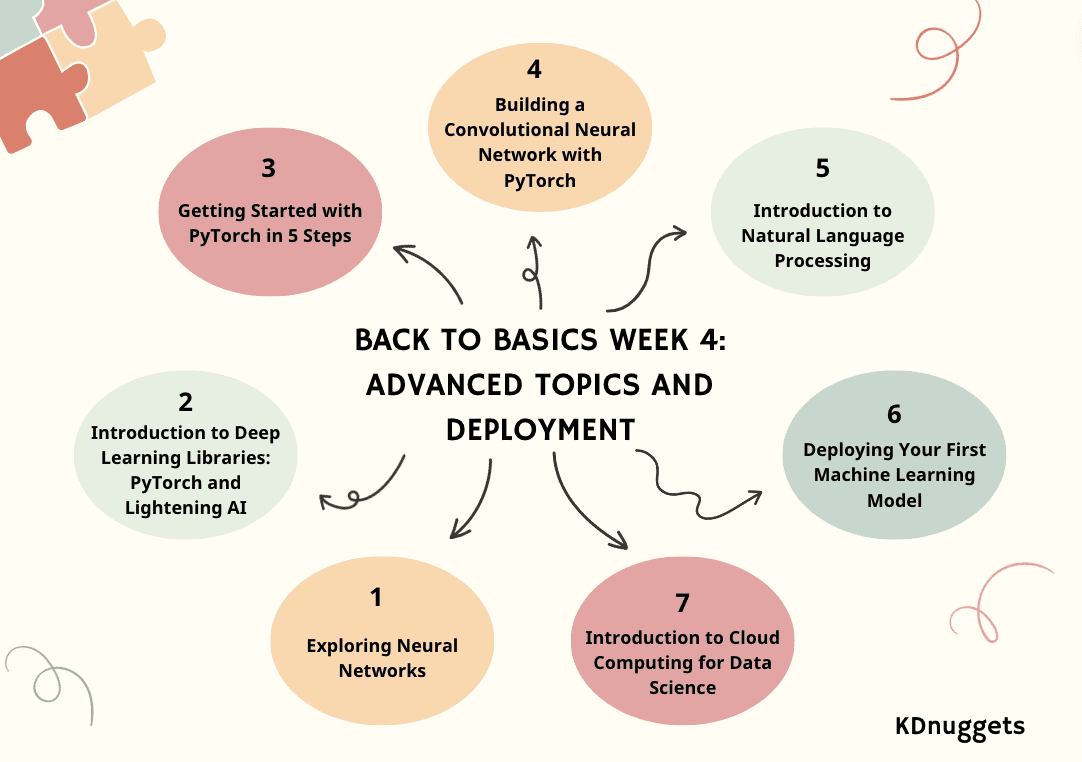
Trecând la a treia săptămână, ne vom scufunda în subiecte avansate și implementare.
- Ziua 1: Explorarea rețelelor neuronale
- Ziua 2: Introducere în bibliotecile Deep Learning: PyTorch și Lightening AI
- Ziua 3: Începeți cu PyTorch în 5 pași
- Ziua 4: Construirea unei rețele neuronale convoluționale cu PyTorch
- Ziua 5: Introducere în procesarea limbajului natural
- Ziua 6: Implementarea primului model de învățare automată
- Ziua 7: Introducere în Cloud Computing pentru Data Science
Săptămâna 4 – Partea 1: Explorarea rețelelor neuronale
Deblocarea puterii AI: un ghid pentru rețelele neuronale și aplicațiile acestora.
Imaginați-vă o mașină care gândește, învață și se adaptează ca creierul uman și descoperă tipare ascunse în date.
Această tehnologie, rețelele neuronale (NN), algoritmii imită cogniția. Vom explora mai târziu ce sunt NN-urile și cum funcționează.
În acest articol, vă voi explica aspectele fundamentale ale rețelelor neuronale (NN) – structură, tipuri, aplicații din viața reală și termeni cheie care definesc funcționarea.
Săptămâna 4 – Partea 2: Introducere în bibliotecile Deep Learning: PyTorch și Lightning AI
O explicație simplă a PyTorch și Lightning AI.
Învățarea profundă este o ramură a modelului de învățare automată bazată pe rețele neuronale. În celălalt model de mașină, prelucrarea datelor pentru a găsi caracteristicile semnificative se face adesea manual sau bazându-se pe expertiza domeniului; cu toate acestea, învățarea profundă poate imita creierul uman pentru a descoperi caracteristicile esențiale, crescând performanța modelului.
Există multe aplicații pentru modele de învățare profundă, inclusiv recunoașterea facială, detectarea fraudei, vorbire în text, generare de text și multe altele. Învățarea profundă a devenit o abordare standard în multe aplicații avansate de învățare automată și nu avem nimic de pierdut dacă aflăm despre ele.
Pentru a dezvolta acest model de învățare profundă, există diverse cadre de bibliotecă pe care ne putem baza, mai degrabă decât să lucrăm de la zero. În acest articol, vom discuta două biblioteci diferite pe care le putem folosi pentru a dezvolta modele de învățare profundă: PyTorch și Lighting AI.
Săptămâna 4 – Partea 3: Noțiuni introductive cu PyTorch în 5 pași
Acest tutorial oferă o introducere aprofundată în învățarea automată folosind PyTorch și învelișul său de nivel înalt, PyTorch Lightning. Articolul acoperă pașii esențiali de la instalare la subiecte avansate, oferind o abordare practică a construirii și antrenării rețelelor neuronale și subliniind beneficiile utilizării Lightning.
PyTorch este un cadru de învățare automată cu sursă deschisă popular, bazat pe Python și optimizat pentru calcularea accelerată de GPU. Dezvoltat inițial de Meta AI în 2016 și acum parte a Fundației Linux, PyTorch a devenit rapid unul dintre cele mai utilizate cadre pentru cercetarea și aplicațiile de deep learning.
PyTorch Lightning este un înveliș ușor construit pe PyTorch, care simplifică și mai mult procesul de flux de lucru al cercetătorilor și de dezvoltare a modelului. Cu Lightning, oamenii de știință de date se pot concentra mai mult pe proiectarea modelelor decât pe codul standard.
Săptămâna 4 – Partea 4: Construirea unei rețele neuronale convoluționale cu PyTorch
Această postare de blog oferă un tutorial despre construirea unei rețele neuronale convoluționale pentru clasificarea imaginilor în PyTorch, valorificând straturi convoluționale și de grupare pentru extragerea caracteristicilor, precum și straturi complet conectate pentru predicție.
O rețea neuronală convoluțională (CNN sau ConvNet) este un algoritm de învățare profundă conceput special pentru sarcini în care recunoașterea obiectelor este crucială - cum ar fi clasificarea, detectarea și segmentarea imaginilor. CNN-urile sunt capabile să obțină acuratețe de ultimă generație în sarcini de viziune complexe, alimentând multe aplicații din viața reală, cum ar fi sistemele de supraveghere, managementul depozitelor și multe altele.
Ca oameni, putem recunoaște cu ușurință obiectele din imagini analizând modele, forme și culori. CNN-urile pot fi antrenate să efectueze și această recunoaștere, învățând care modele sunt importante pentru diferențiere. De exemplu, când încercăm să facem distincția între o fotografie a unei pisici și a unui câine, creierul nostru se concentrează asupra formei, texturilor și trăsăturilor faciale unice. Un CNN învață să înțeleagă aceleași tipuri de caracteristici distinctive. Chiar și pentru sarcinile de clasificare foarte fine, CNN-urile sunt capabile să învețe reprezentări complexe de caracteristici direct din pixeli.
Săptămâna 4 – Partea 5: Introducere în procesarea limbajului natural
O prezentare generală a procesării limbajului natural (NLP) și a aplicațiilor sale.
Învățăm multe despre ChatGPT și modelele de limbaj mari (LLM). Procesarea limbajului natural a fost un subiect interesant, un subiect care ia cu asalt lumea AI și a tehnologiei. Da, LLM-urile precum ChatGPT le-au ajutat la creșterea lor, dar nu ar fi bine să înțelegem de unde vine totul? Deci, să revenim la elementele de bază – NLP.
NLP este un subdomeniu al inteligenței artificiale și este capacitatea unui computer de a detecta și înțelege limbajul uman, prin vorbire și text, așa cum putem noi oamenii. NLP ajută modelele să proceseze, să înțeleagă și să producă limbajul uman.
Scopul NLP este de a reduce decalajul de comunicare dintre oameni și computere. Modelele NLP sunt de obicei instruite pe sarcini precum predicția cuvântului următor, care le permit să construiască dependențe contextuale și apoi să poată genera rezultate relevante.
Săptămâna 4 – Partea 6: Implementarea primului model de învățare automată
Cu doar 3 pași simpli, puteți construi și implementa un model de clasificare a sticlei mai repede decât puteți spune... model de clasificare a sticlei!
În acest tutorial, vom învăța cum să construim un model simplu de clasificare multiplă folosind Clasificarea sticlei set de date. Scopul nostru este să dezvoltăm și să implementăm o aplicație web care poate prezice diferite tipuri de sticlă, cum ar fi:
- Clădire Windows Float Processed
- Construire Windows Non-Float Processed
- Geamuri plutitoare ale vehiculului procesate
- Geamurile vehiculului nu au fost procesate (lipsesc din setul de date)
- Containere
- Tacâmuri
- Reglabile
Mai mult, vom afla despre:
- Skops: Partajați modelele bazate pe scikit-learn și puneți-le în producție.
- Grad: cadru de aplicații web ML.
- HuggingFace Spaces: model gratuit de învățare automată și platformă de găzduire a aplicațiilor.
Până la sfârșitul acestui tutorial, veți avea experiență practică în construirea, instruirea și implementarea unui model de bază de învățare automată ca aplicație web.
Săptămâna 4 – Partea 7: Introducere în cloud computing pentru știința datelor
Și Power Duo of Modern Tech.
În lumea de astăzi, două forțe principale au apărut ca schimbări de joc: Data Science și Cloud Computing.
Imaginați-vă o lume în care cantități colosale de date sunt generate în fiecare secundă. Ei bine... nu trebuie să-ți imaginezi... Este lumea noastră!
De la interacțiunile cu rețelele sociale la tranzacțiile financiare, de la înregistrările medicale la preferințele de comerț electronic, datele sunt peste tot.
Dar ce folos au aceste date dacă nu putem obține valoare? Exact asta face Data Science.
Și unde stocăm, procesăm și analizăm aceste date? Acolo strălucește Cloud Computing.
Să pornim într-o călătorie pentru a înțelege relația împletită dintre aceste două minuni tehnologice. Să (încercăm) să descoperim totul împreună!
Felicitări pentru finalizarea săptămânii 4!!
Echipa KDnuggets speră că calea Back to Basics a oferit cititorilor o abordare cuprinzătoare și structurată pentru a stăpâni fundamentele științei datelor.
Săptămâna bonus va fi postată săptămâna viitoare luni – rămâneți pe fază!
Nisha Arya este un Data Scientist și un scriitor tehnic independent. Ea este interesată în special să ofere sfaturi în carieră în domeniul științei datelor sau tutoriale și cunoștințe bazate pe teorie în jurul științei datelor. Ea dorește, de asemenea, să exploreze diferitele moduri în care Inteligența Artificială este/poate aduce beneficii longevității vieții umane. O învățătoare pasionată, care încearcă să-și extindă cunoștințele tehnice și abilitățile de scriere, în timp ce îi ajută să-i ghideze pe alții.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.kdnuggets.com/back-to-basics-week-4-advanced-topics-and-deployment?utm_source=rss&utm_medium=rss&utm_campaign=back-to-basics-week-4-advanced-topics-and-deployment
- :are
- :este
- :nu
- :Unde
- $UP
- 1
- 2016
- 7
- a
- capacitate
- Capabil
- Despre Noi
- precizie
- Obține
- avansat
- sfat
- AI
- Algoritmul
- algoritmi
- TOATE
- permite
- deja
- de asemenea
- Sume
- an
- analiza
- analiza
- și
- aplicație
- aplicatii
- abordare
- SUNT
- în jurul
- articol
- artificial
- inteligență artificială
- AS
- aspecte
- At
- înapoi
- bazat
- de bază
- Noțiuni de bază
- BE
- deveni
- fost
- beneficia
- Beneficiile
- între
- Blog
- bloguri
- Primă
- Creier
- Branch firma
- POD
- extinde
- construi
- Clădire
- construit
- dar
- by
- CAN
- Carieră
- CAT
- Caracteristici
- Chat GPT
- clasificare
- Cloud
- cloud computing
- CNN
- cod
- cunoaștere
- vine
- Comunicare
- completarea
- complex
- cuprinzător
- calculator
- Calculatoare
- tehnica de calcul
- legat
- construirea
- contextual
- rețea neuronală convoluțională
- înscrie-te la cursul
- acoperă
- crucial
- În prezent
- de date
- de prelucrare a datelor
- știința datelor
- om de știință de date
- adânc
- învățare profundă
- definire
- dependențe
- implementa
- Implementarea
- desfășurarea
- proiectat
- proiect
- detecta
- Detectare
- dezvolta
- dezvoltat
- Dezvoltare
- diferit
- direct
- descoperi
- descoperirea
- discuta
- distinge
- scufunda
- do
- face
- Câine
- domeniu
- făcut
- duo
- e-commerce
- cu ușurință
- Îmbarce
- a apărut
- subliniind
- capăt
- esenţial
- Eter (ETH)
- Chiar
- Fiecare
- pretutindeni
- exact
- exemplu
- experienţă
- expertiză
- Explica
- explicație
- explora
- Explorarea
- extracţie
- facial
- recunoastere faciala
- mai repede
- Caracteristică
- DESCRIERE
- financiar
- Găsi
- First
- pluti
- Concentra
- se concentrează
- Pentru
- Forțele
- Fundație
- Cadru
- cadre
- fraudă
- detectarea fraudei
- Gratuit
- independent
- din
- complet
- funcţie
- fundamental
- Fundamentele
- mai mult
- decalaj
- genera
- generată
- generaţie
- obține
- obtinerea
- de sticlă
- Go
- scop
- bine
- Creștere
- ghida
- hands-on
- Avea
- de asistență medicală
- a ajutat
- ajutor
- ajută
- ei
- Ascuns
- la nivel înalt
- speranţă
- găzduire
- Cum
- Cum Pentru a
- Totuși
- HTTPS
- uman
- Oamenii
- i
- if
- imagine
- Clasificarea imaginilor
- imagini
- important
- in
- în profunzime
- Inclusiv
- crescând
- instalare
- Inteligență
- interacţiuni
- interesat
- interesant
- impletesc
- în
- Introducere
- IT
- ESTE
- călătorie
- doar
- KDnuggets
- pasionat
- Cheie
- conținutului în
- cunoştinţe
- limbă
- mare
- mai tarziu
- straturi
- AFLAȚI
- elev
- învăţare
- efectului de pârghie
- biblioteci
- Bibliotecă
- Viaţă
- trasnet
- Iluminat
- fulger
- categorie ușoară
- ca
- linux
- fundația linux
- ll
- longevitate
- Uite
- pierde
- Lot
- maşină
- masina de învățare
- Principal
- administrare
- manual
- multe
- Stăpânirea
- semnificativ
- Mass-media
- meta
- dispărut
- ML
- model
- Modele
- Modern
- luni
- mai mult
- cele mai multe
- Natural
- Limbajul natural
- Procesarea limbajului natural
- reţea
- rețele
- neural
- rețele neuronale
- rețele neuronale
- Nou
- următor
- saptamana viitoare
- nlp
- nimic
- acum
- obiect
- obiecte
- of
- oferind
- de multe ori
- on
- ONE
- open-source
- operaţie
- optimizate
- or
- iniţial
- Altele
- Altele
- al nostru
- producție
- iesiri
- Prezentare generală
- parte
- în special
- cărare
- modele
- efectua
- performanță
- alege
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- Popular
- Post
- postat
- putere
- Alimentarea
- prezice
- prezicere
- preferinţele
- proces
- prelucrate
- prelucrare
- producere
- prevăzut
- furnizează
- furnizarea
- pune
- Piton
- pirtorh
- repede
- mai degraba
- cititori
- recunoaştere
- recunoaște
- înregistrări
- relaţie
- se bazează
- bazându-se
- cercetare
- cercetător
- acelaşi
- Spune
- Ştiinţă
- Om de stiinta
- oamenii de stiinta
- scikit-learn
- zgâria
- Al doilea
- caută
- segmentarea
- Modela
- forme
- Distribuie
- ea
- strălucește
- simplu
- Simplifică
- aptitudini
- So
- Social
- social media
- spații
- specific
- discurs
- vorbire-text
- împărţi
- standard
- început
- de ultimă oră
- şedere
- paşi
- stoca
- Furtună
- structura
- structurat
- astfel de
- supraveghere
- sisteme
- luare
- sarcini
- echipă
- tech
- Tehnic
- tehnologic
- Tehnologia
- termeni
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- generarea textului
- decât
- acea
- Noțiuni de bază
- lor
- Lor
- apoi
- teorie
- Acolo.
- Acestea
- ei
- Gândire
- Al treilea
- acest
- Prin
- la
- azi
- de asemenea
- top
- subiect
- subiecte
- dresat
- Pregătire
- Tranzacții
- încerca
- încercat
- tutorial
- tutoriale
- Două
- Tipuri
- tipic
- înţelege
- unic
- pe
- utilizare
- utilizat
- folosind
- valoare
- diverse
- Impotriva
- foarte
- viziune
- Depozit
- managementul depozitului
- Cale..
- modalități de
- we
- web
- aplicatie web
- aplicații web
- săptămână
- săptămâni
- BINE
- Ce
- cand
- care
- În timp ce
- pe larg
- Wikipedia
- voi
- ferestre
- dorește
- cu
- în
- Cuvânt
- flux de lucru
- de lucru
- lume
- scriitor
- scris
- da
- tu
- Ta
- zephyrnet







