Acreditamos que a IA generativa tem o potencial, ao longo do tempo, de transformar praticamente todas as experiências do cliente que conhecemos. O número de empresas que lançam aplicações generativas de IA na AWS é substancial e está crescendo rapidamente, incluindo adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy e LexisNexis Legal & Professional, para citar apenas algumas. Startups inovadoras como a Perplexity AI estão apostando tudo na AWS para IA generativa. Empresas líderes de IA como a Anthropic selecionaram a AWS como seu principal provedor de nuvem para cargas de trabalho de missão crítica e o local para treinar seus modelos futuros. E fornecedores globais de serviços e soluções como a Accenture estão colhendo os benefícios de aplicações personalizadas de IA generativa à medida que capacitam seus desenvolvedores internos com Sussurrador de Código da Amazon.
Esses clientes estão escolhendo a AWS porque estamos focados em fazer o que sempre fizemos: pegar tecnologia complexa e cara que pode transformar as experiências dos clientes e os negócios e democratizá-la para clientes de todos os tamanhos e capacidades técnicas. Para fazer isso, estamos investindo e inovando rapidamente para fornecer o conjunto mais abrangente de recursos nas três camadas da pilha de IA generativa. A camada inferior é a infraestrutura para treinar Large Language Models (LLMs) e outros Foundation Models (FMs) e produzir inferências ou previsões. A camada intermediária oferece acesso fácil a todos os modelos e ferramentas de que os clientes precisam para criar e dimensionar aplicativos generativos de IA com a mesma segurança, controle de acesso e outros recursos que os clientes esperam de um serviço da AWS. E na camada superior, temos investido em aplicações revolucionárias em áreas-chave, como codificação generativa baseada em IA. Além de oferecer-lhes opções e, como esperam de nós, amplitude e profundidade de recursos em todas as camadas, os clientes também nos dizem que apreciam nossa abordagem que prioriza os dados e confiam que construímos tudo desde o início com base em dados corporativos. grau de segurança e privacidade.
Esta semana demos um grande passo em frente, anunciando muitas novas capacidades significativas em todas as três camadas da pilha para tornar mais fácil e prático para os nossos clientes a utilização generalizada da IA generativa nos seus negócios.

Camada inferior da pilha: AWS Trainium2 é a mais recente adição a fornecer a infraestrutura de nuvem mais avançada para IA generativa
A camada inferior da pilha é a infraestrutura – computação, redes, estruturas, serviços – necessária para treinar e executar LLMs e outros FMs. A AWS inova para oferecer a infraestrutura mais avançada para ML. Por meio de nossa colaboração de longa data com a NVIDIA, a AWS foi a primeira a trazer GPUs para a nuvem há mais de 12 anos e, mais recentemente, fomos o primeiro grande provedor de nuvem a disponibilizar GPUs NVIDIA H100 com nossas instâncias P5. Continuamos investindo em inovações exclusivas que tornam a AWS a melhor nuvem para executar GPUs, incluindo os benefícios de custo-desempenho do sistema de virtualização mais avançado (AWS Nitro), rede poderosa em escala de petabit com Elastic Fabric Adapter (EFA) e hiper- dimensione clustering com Amazon EC2 UltraClusters (milhares de instâncias aceleradas co-localizadas em uma zona de disponibilidade e interconectadas em uma rede sem bloqueio que pode fornecer até 3,200 Gbps para treinamento de ML em grande escala). Também estamos facilitando para qualquer cliente o acesso à tão procurada capacidade computacional de GPU para IA generativa com os blocos de capacidade do Amazon EC2 para ML, o primeiro e único modelo de consumo do setor que permite aos clientes reservar GPUs para uso futuro (até 500 implantado em EC2 UltraClusters) para cargas de trabalho de ML de curta duração.
Há vários anos, percebemos que, para continuar inovando no desempenho de preços, precisaríamos inovar até o silício e começamos a investir em nossos próprios chips. Especificamente para ML, começamos com o AWS Inferentia, nosso chip de inferência desenvolvido especificamente. Hoje, estamos em nossa segunda geração do AWS Inferentia com instâncias Inf2 do Amazon EC2 otimizadas especificamente para aplicações de IA generativa em larga escala com modelos contendo centenas de bilhões de parâmetros. As instâncias Inf2 oferecem o menor custo para inferência na nuvem, ao mesmo tempo que oferecem uma taxa de transferência até quatro vezes maior e uma latência até dez vezes menor em comparação com as instâncias Inf1. Alimentadas por até 12 chips Inferentia2, as Inf2 são as únicas instâncias EC2 otimizadas para inferência que possuem conectividade de alta velocidade entre aceleradores para que os clientes possam executar inferências com mais rapidez e eficiência (a um custo menor) sem sacrificar o desempenho ou a latência, distribuindo modelos ultragrandes em vários aceleradores. Clientes como Adobe, Deutsche Telekom e Leonardo.ai obtiveram ótimos resultados iniciais e estão entusiasmados para implantar seus modelos em escala no Inf2.
No lado do treinamento, as instâncias Trn1 — alimentadas pelo chip de treinamento de ML desenvolvido especificamente pela AWS, o AWS Trainium — são otimizadas para distribuir treinamento em vários servidores conectados à rede EFA. Clientes como a Ricoh treinaram um LLM japonês com bilhões de parâmetros em poucos dias. A Databricks está obtendo desempenho de preço até 40% melhor com instâncias baseadas em Trainium para treinar modelos de aprendizagem profunda em larga escala. Mas com modelos novos e mais capazes sendo lançados praticamente todas as semanas, continuamos a ampliar os limites de desempenho e escala, e temos o prazer de anunciar AWS Trainium2, projetado para oferecer desempenho de preço ainda melhor para modelos de treinamento com centenas de bilhões a trilhões de parâmetros. O Trainium2 deve oferecer desempenho de treinamento até quatro vezes mais rápido que o Trainium de primeira geração e, quando usado em EC2 UltraClusters, deve fornecer até 65 exaflops de computação agregada. Isso significa que os clientes poderão treinar um LLM de 300 bilhões de parâmetros em semanas, em vez de meses. O desempenho, a escala e a eficiência energética do Trainium2 são algumas das razões pelas quais a Anthropic optou por treinar seus modelos na AWS e usará o Trainium2 em seus modelos futuros. E estamos colaborando com a Anthropic na inovação contínua com Trainium e Inferentia. Esperamos que nossas primeiras instâncias Trainium2 estejam disponíveis aos clientes em 2024.
Também estamos dobrando a cadeia de ferramentas de software para nosso silício de ML, especificamente no avanço do AWS Neuron, o kit de desenvolvimento de software (SDK) que ajuda os clientes a obter o desempenho máximo do Trainium e do Inferentia. Desde a introdução do Neuron em 2019, fizemos investimentos substanciais em tecnologias de compilador e estrutura, e hoje o Neuron oferece suporte a muitos dos modelos mais populares disponíveis publicamente, incluindo Llama 2 da Meta, MPT da Databricks e Stable Diffusion da Stability AI, bem como 93 dos 100 principais modelos do popular repositório de modelos Hugging Face. O Neuron se conecta a estruturas de ML populares, como PyTorch e TensorFlow, e o suporte para JAX chegará no início do próximo ano. Os clientes estão nos dizendo que a Neuron facilitou a migração de seus pipelines de treinamento e inferência de modelo existentes para Trainium e Inferentia com apenas algumas linhas de código.
Ninguém mais oferece a mesma combinação de escolha dos melhores chips de ML, rede super-rápida, virtualização e clusters de hiperescala. E assim, não é surpreendente que algumas das startups de IA generativa mais conhecidas, como AI21 Labs, Anthropic, Hugging Face, Perplexity AI, Runway e Stability AI, sejam executadas na AWS. Mas você ainda precisa das ferramentas certas para aproveitar efetivamente essa computação para construir, treinar e executar LLMs e outros FMs de maneira eficiente e econômica. E para muitas dessas startups, Amazon Sage Maker é a resposta. Seja construindo e treinando um novo modelo proprietário do zero ou começando com um dos muitos modelos populares disponíveis publicamente, o treinamento é uma tarefa complexa e cara. Também não é fácil executar esses modelos de maneira econômica. Os clientes devem adquirir grandes quantidades de dados e prepará-los. Isso normalmente envolve muito trabalho manual de limpeza de dados, remoção de duplicatas, enriquecimento e transformação. Em seguida, eles precisam criar e manter grandes clusters de GPUs/aceleradores, escrever código para distribuir com eficiência o treinamento do modelo entre clusters, verificar, pausar, inspecionar e otimizar o modelo com frequência e intervir manualmente e corrigir problemas de hardware no cluster. Muitos desses desafios não são novos, são alguns dos motivos pelos quais lançamos o SageMaker há seis anos – para quebrar as muitas barreiras envolvidas no treinamento e implantação de modelos e oferecer aos desenvolvedores um caminho muito mais fácil. Dezenas de milhares de clientes usam o Amazon SageMaker, e um número crescente deles, como LG AI Research, Perplexity AI, AI21, Hugging Face e Stability AI, estão treinando LLMs e outros FMs no SageMaker. Recentemente, o Technology Innovation Institute (criador dos populares Falcon LLMs) treinou o maior modelo disponível publicamente – Falcon 180B – no SageMaker. À medida que o tamanho e a complexidade dos modelos aumentaram, também aumentou o escopo do SageMaker.
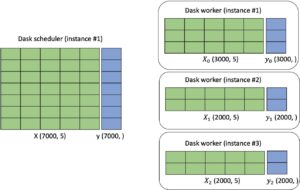
Ao longo dos anos, adicionamos mais de 380 recursos e capacidades revolucionários ao Amazon SageMaker, como ajuste automático de modelo, treinamento distribuído, opções flexíveis de implantação de modelo, ferramentas para OPs de ML, ferramentas para preparação de dados, armazenamentos de recursos, notebooks, integração perfeita com avaliações humanas em todo o ciclo de vida do ML e recursos integrados para IA responsável. Continuamos inovando rapidamente para garantir que os clientes do SageMaker possam continuar construindo, treinando e executando inferências para todos os modelos, incluindo LLMs e outros FMs. E estamos tornando ainda mais fácil e econômico para os clientes treinar e implantar modelos grandes com dois novos recursos. Primeiro, para simplificar o treinamento, estamos introduzindo HyperPod do Amazon SageMaker que automatiza mais processos necessários para treinamento distribuído tolerante a falhas em alta escala (por exemplo, configurar bibliotecas de treinamento distribuídas, dimensionar cargas de trabalho de treinamento em milhares de aceleradores, detectar e reparar instâncias defeituosas), acelerando o treinamento em até 40%. Como resultado, clientes como Perplexity AI, Hugging Face, Stability, Hippocratic, Alkaid e outros estão usando o SageMaker HyperPod para construir, treinar ou evoluir modelos. Segundo, estamos introduzindo novos recursos para tornar a inferência mais econômica e, ao mesmo tempo, reduzir a latência. O SageMaker agora ajuda os clientes a implantar vários modelos na mesma instância para que possam compartilhar recursos de computação, reduzindo o custo de inferência em 50% (em média). O SageMaker também monitora ativamente instâncias que processam solicitações de inferência e roteia solicitações de maneira inteligente com base nas instâncias disponíveis, alcançando uma latência de inferência 20% menor (em média). Conjecture, Salesforce e Slack já estão usando SageMaker para hospedar modelos devido a essas otimizações de inferência.
Camada intermediária da pilha: o Amazon Bedrock adiciona novos modelos e uma onda de novos recursos que tornam ainda mais fácil para os clientes criar e dimensionar com segurança aplicações generativas de IA
Embora vários clientes construam seus próprios LLMs e outros FMs, ou desenvolvam qualquer uma das opções disponíveis publicamente, muitos não vão querer gastar recursos e tempo para fazer isso. Para eles, a camada intermediária da pilha oferece esses modelos como um serviço. Nossa solução aqui, Rocha Amazônica, permite que os clientes escolham entre modelos líderes do setor, como Anthropic, Stability AI, Meta, Cohere, AI21 e Amazon, personalizem-nos com seus próprios dados e aproveitem todos os mesmos recursos líderes de segurança, controles de acesso e recursos aos quais estão acostumados. na AWS, tudo por meio de um serviço gerenciado. Disponibilizamos o Amazon Bedrock no final de setembro e a resposta dos clientes tem sido extremamente positiva. Clientes de todo o mundo e de praticamente todos os setores estão entusiasmados em usar o Amazon Bedrock. A adidas está permitindo que os desenvolvedores obtenham respostas rápidas sobre tudo, desde informações de “primeiros passos” até questões técnicas mais profundas. A Booking.com pretende usar IA generativa para escrever recomendações de viagem personalizadas para cada cliente. A Bridgewater Associates está desenvolvendo um Assistente de Analista de Investimentos com tecnologia LLM para ajudar a gerar gráficos, calcular indicadores financeiros e resumir resultados. A Carrier está disponibilizando análises e insights de energia mais precisos aos clientes para que eles reduzam o consumo de energia e reduzam as emissões de carbono. A Clariant está capacitando os membros de sua equipe com um chatbot interno de IA generativo para acelerar processos de P&D, apoiar equipes de vendas na preparação de reuniões e automatizar e-mails de clientes. A GoDaddy está ajudando os clientes a configurar facilmente seus negócios on-line usando IA generativa para criar seus sites, encontrar fornecedores, conectar-se com clientes e muito mais. Lexis Nexis Legal & Professional está transformando o trabalho jurídico para advogados e aumentando sua produtividade com pesquisa conversacional, resumo e recursos de elaboração e análise de documentos Lexis+ AI. A Nasdaq está ajudando a automatizar fluxos de trabalho investigativos sobre transações suspeitas e a fortalecer suas capacidades anti-crime financeiro e de vigilância. Todos esses — e muitos mais — aplicativos de IA generativos estão em execução na AWS.

Estamos entusiasmados com o impulso do Amazon Bedrock, mas ainda é o começo. O que vimos ao trabalharmos com os clientes é que todos estão se movendo rapidamente, mas a evolução da IA generativa continua em ritmo acelerado, com novas opções e inovações acontecendo praticamente diariamente. Os clientes estão descobrindo que existem modelos diferentes que funcionam melhor para diferentes casos de uso ou em diferentes conjuntos de dados. Alguns modelos são ótimos para resumo, outros são ótimos para raciocínio e integração e outros ainda têm um suporte linguístico realmente incrível. E há também a geração de imagens, casos de uso de pesquisa e muito mais – todos provenientes de modelos proprietários e de modelos que estão disponíveis publicamente para qualquer pessoa. E em tempos em que há tanta coisa incognoscível, a capacidade de adaptação é sem dúvida a ferramenta mais valiosa de todas. Não haverá um modelo para governar todos eles. E certamente não apenas uma empresa de tecnologia fornecendo os modelos que todos usam. Os clientes precisam experimentar modelos diferentes. Eles precisam ser capazes de alternar entre eles ou combiná-los no mesmo caso de uso. Isto significa que necessitam de uma escolha real de fornecedores modelo (o que os acontecimentos dos últimos 10 dias tornaram ainda mais claro). É por isso que inventamos o Amazon Bedrock, por que ele ressoa tão profundamente com os clientes e por que continuamos a inovar e iterar rapidamente para tornar a construção (e a movimentação entre) uma variedade de modelos tão fácil quanto uma chamada de API, colocando as técnicas mais recentes para personalização do modelo nas mãos de todos os desenvolvedores e manter os clientes seguros e seus dados privados. Estamos entusiasmados em apresentar vários novos recursos que tornarão ainda mais fácil para os clientes criar e dimensionar aplicativos generativos de IA:
- Expandindo a escolha do modelo com Anthropic Claude 2.1, Meta Llama 2 70B e adições à família Amazon Titan. Atualmente, os clientes ainda estão aprendendo e experimentando diferentes modelos para determinar quais desejam usar para diversos fins. Eles desejam poder experimentar facilmente os modelos mais recentes e também testar para ver quais capacidades e recursos lhes darão os melhores resultados e características de custo para seus casos de uso. Com o Amazon Bedrock, os clientes estão a apenas uma chamada de API de um novo modelo. Alguns dos resultados mais impressionantes que os clientes obtiveram nos últimos meses vêm de LLMs como Modelo Claude da Antrópico, que se destaca em uma ampla gama de tarefas, desde diálogos sofisticados e geração de conteúdo até raciocínios complexos, mantendo um alto grau de confiabilidade e previsibilidade. Os clientes relatam que Claude tem muito menos probabilidade de produzir resultados prejudiciais, é mais fácil de conversar e mais orientável em comparação com outros FMs, para que os desenvolvedores possam obter os resultados desejados com menos esforço. O modelo de última geração da Antrópico, Claude 2, pontua acima do percentil 90 nos exames de leitura e redação GRE e, de forma semelhante, no raciocínio quantitativo. E agora, o modelo Claude 2.1 recém-lançado está disponível no Amazon Bedrock. O Claude 2.1 oferece recursos importantes para empresas, como uma janela de contexto de token de 200 mil líder do setor (duas vezes o contexto do Claude 2), taxas reduzidas de alucinação e melhorias significativas na precisão, mesmo em comprimentos de contexto muito longos. O Claude 2.0 também inclui prompts de sistema aprimorados – que são instruções modelo que proporcionam uma melhor experiência para os usuários finais – ao mesmo tempo que reduz o custo de prompts e conclusões em 2.1%.
Para um número crescente de clientes que desejam usar uma versão gerenciada do modelo Llama 2 disponível publicamente da Meta, o Amazon Bedrock oferece o Llama 2 13B, e estamos adicionando Llama 2 70B. O Llama 2 70B é adequado para tarefas de grande escala, como modelagem de linguagem, geração de texto e sistemas de diálogo. Os modelos Llama disponíveis publicamente foram baixados mais de 30 milhões de vezes, e os clientes adoram que a Amazon Bedrock os ofereça como parte de um serviço gerenciado onde eles não precisam se preocupar com infraestrutura ou ter profundo conhecimento em ML em suas equipes. Além disso, para geração de imagens, o Stability AI oferece um conjunto de modelos populares de texto para imagem. Stable Diffusion XL 1.0 (SDXL 1.0) é o mais avançado deles e agora está disponível no Amazon Bedrock. A última edição deste popular modelo de imagem aumentou a precisão, melhor fotorrealismo e maior resolução.
Os clientes também estão usando Titã Amazona modelos, que são criados e pré-treinados pela AWS para oferecer recursos poderosos com grande economia para uma variedade de casos de uso. A Amazon tem um histórico de 25 anos em ML e IA – tecnologia que usamos em nossos negócios – e aprendemos muito sobre a construção e implantação de modelos. Escolhemos cuidadosamente como treinamos nossos modelos e os dados que usamos para fazer isso. Indenizamos os clientes contra alegações de que nossos modelos ou seus resultados infringem os direitos autorais de alguém. Apresentamos nossos primeiros modelos Titan em abril deste ano. Texto Titã Lite—agora disponível para o público geral—é um modelo sucinto e econômico para casos de uso como chatbots, resumo de texto ou redação, e também é atraente para ajustes. Titan Text Express – agora também disponível para o público geral—é mais expansivo e pode ser usado para uma ampla gama de tarefas baseadas em texto, como geração de texto aberto e bate-papo conversacional. Oferecemos essas opções de modelo de texto para oferecer aos clientes a capacidade de otimizar a precisão, o desempenho e o custo, dependendo do caso de uso e dos requisitos de negócios. Clientes como Nexxiot, PGA Tour e Ryanair estão usando nossos dois modelos Titan Text. Também temos um modelo de embeddings, Titan Text Embeddings, para casos de uso de pesquisa e personalização. Clientes como a Nasdaq estão obtendo ótimos resultados usando Titan Text Embeddings para aprimorar os recursos do Nasdaq IR Insight para gerar insights de mais de 9,000 documentos de empresas globais para equipes de sustentabilidade, jurídicas e contábeis. E continuaremos a adicionar mais modelos à família Titan ao longo do tempo. Estamos apresentando um novo modelo de embeddings, Titan Multimodal Embeddings, para potencializar experiências multimodais de pesquisa e recomendação para usuários usando imagens e texto (ou uma combinação de ambos) como entradas. E nós somos apresentando um novo modelo de texto para imagem, Amazon Titan Image Generator. Com o Titan Image Generator, clientes de setores como publicidade, comércio eletrônico e mídia e entretenimento podem usar uma entrada de texto para gerar imagens realistas com qualidade de estúdio em grandes volumes e com baixo custo. Estamos entusiasmados com a forma como os clientes estão respondendo aos modelos Titan e você pode esperar que continuaremos a inovar aqui.
- Novos recursos para personalizar seu aplicativo generativo de IA de forma segura com seus dados proprietários: um dos recursos mais importantes do Amazon Bedrock é a facilidade de personalizar um modelo. Isso se torna realmente interessante para os clientes porque é onde a IA generativa encontra seu principal diferencial: seus dados. No entanto, é realmente importante que os seus dados permaneçam seguros, que eles tenham controle sobre eles ao longo do caminho e que as melhorias no modelo sejam privadas para eles. Existem algumas maneiras de fazer isso, e o Amazon Bedrock oferece a mais ampla seleção de opções de personalização em vários modelos). O primeiro é o ajuste fino. Ajustar um modelo no Amazon Bedrock é fácil. Você simplesmente seleciona o modelo e o Amazon Bedrock faz uma cópia dele. Em seguida, você aponta para alguns exemplos rotulados (por exemplo, uma série de bons pares de perguntas e respostas) que você armazena no Amazon Simple Storage Service (Amazon S3) e o Amazon Bedrock “treina incrementalmente” (aumenta o modelo copiado com as novas informações). baseando-se nesses exemplos, e o resultado é um modelo privado, mais preciso e ajustado, que fornece respostas mais relevantes e personalizadas. Temos o prazer de anunciar que o ajuste fino está disponível para Cohere Command, Meta Llama 2, Amazon Titan Text (Lite e Express), Amazon Titan Multimodal Embeddings e em versão prévia para Amazon Titan Image Generator. E, por meio de nossa colaboração com a Anthropic, em breve forneceremos aos clientes da AWS acesso antecipado a recursos exclusivos para personalização de modelos e ajuste fino de seu modelo de última geração, Claude.
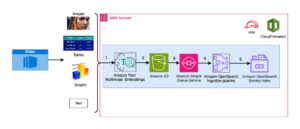
Uma segunda técnica para personalizar LLMs e outros FMs para o seu negócio é a geração aumentada de recuperação (RAG), que permite personalizar as respostas de um modelo aumentando seus prompts com dados de diversas fontes, incluindo repositórios de documentos, bancos de dados e APIs. Em setembro, introduzimos um recurso RAG, Knowledge Bases for Amazon Bedrock, que conecta modelos com segurança às suas fontes de dados proprietárias para complementar seus prompts com mais informações para que seus aplicativos forneçam respostas mais relevantes, contextuais e precisas. Bases de Conhecimento agora está disponível com uma API que executa todo o fluxo de trabalho RAG desde a busca do texto necessário para aumentar um prompt, até o envio do prompt ao modelo e o retorno da resposta. As bases de conhecimento oferecem suporte a bancos de dados com recursos vetoriais que armazenam representações numéricas de seus dados (incorporações) que os modelos usam para acessar esses dados para RAG, incluindo Amazon OpenSearch Service e outros bancos de dados populares como Pinecone e Redis Enterprise Cloud (suporte vetorial Amazon Aurora e MongoDB em breve breve).
A terceira maneira de personalizar modelos no Amazon Bedrock é com pré-treinamento contínuo. Com este método, o modelo baseia-se no seu pré-treinamento original para compreensão geral da linguagem para aprender linguagem e terminologia específicas do domínio. Essa abordagem é para clientes que possuem grandes quantidades de informações não rotuladas e específicas de domínio e desejam permitir que seus LLMs entendam a linguagem, as frases, as abreviações, os conceitos, as definições e o jargão exclusivos de seu mundo (e de negócios). Ao contrário do ajuste fino, que utiliza uma quantidade relativamente pequena de dados, o pré-treinamento contínuo é realizado em grandes conjuntos de dados (por exemplo, milhares de documentos de texto). Agora, os recursos de pré-treinamento estão disponíveis no Amazon Bedrock para Titan Text Lite e Titan Text Express.
- Disponibilidade geral de Agentes da Amazon Bedrock para ajudar a executar tarefas de várias etapas usando sistemas, fontes de dados e conhecimento da empresa. LLMs são ótimos para conversar e gerar conteúdo, mas os clientes desejam que seus aplicativos sejam capazes de do ainda mais, como tomar medidas, resolver problemas e interagir com uma variedade de sistemas para concluir tarefas de várias etapas, como reservar viagens, registrar reclamações de seguros ou solicitar peças de reposição. E a Amazon Bedrock pode ajudar nesse desafio. Com os agentes, os desenvolvedores selecionam um modelo, escrevem algumas instruções básicas como “você é um agente de atendimento ao cliente alegre” e “verifica a disponibilidade do produto no sistema de estoque”, apontam o modelo selecionado para as fontes de dados e sistemas empresariais corretos (por exemplo, CRM). ou aplicativos ERP) e escrever algumas funções AWS Lambda para executar as APIs (por exemplo, verificar a disponibilidade de um item no inventário ERP). O Amazon Bedrock analisa automaticamente a solicitação e a divide em uma sequência lógica usando os recursos de raciocínio do modelo selecionado para determinar quais informações são necessárias, quais APIs chamar e quando chamá-las para concluir uma etapa ou resolver uma tarefa. Agora com disponibilidade geral, os agentes podem planejar e executar a maioria das tarefas de negócios, desde responder às perguntas dos clientes sobre a disponibilidade do produto até receber seus pedidos, e os desenvolvedores não precisam estar familiarizados com aprendizado de máquina, solicitações de engenheiros, treinar modelos ou conectar sistemas manualmente. E a Bedrock faz tudo isso de forma segura e privada, e clientes como Druva e Athene já os estão usando para melhorar a precisão e a velocidade de desenvolvimento de seus aplicativos generativos de IA.
- Apresentando... Guarda-corpos para Amazon Bedrock para que você possa aplicar proteções com base nos requisitos do seu caso de uso e nas políticas de IA responsáveis. Os clientes desejam ter certeza de que as interações com seus aplicativos de IA sejam seguras, evitem linguagem tóxica ou ofensiva, permaneçam relevantes para seus negócios e estejam alinhadas com suas políticas responsáveis de IA. Com as proteções, os clientes podem especificar tópicos a serem evitados, e o Amazon Bedrock fornecerá aos usuários apenas respostas aprovadas para perguntas que se enquadrem nessas categorias restritas. Por exemplo, uma aplicação bancária online pode ser configurada para evitar fornecer aconselhamento de investimento e remover conteúdo impróprio (como discurso de ódio e violência). No início de 2024, os clientes também poderão redigir informações de identificação pessoal (PII) nas respostas do modelo. Por exemplo, depois que um cliente interage com um agente de call center, a conversa de atendimento ao cliente costuma ser resumida para manutenção de registros, e as proteções podem remover PII desses resumos. Guardrails podem ser usados em modelos no Amazon Bedrock (incluindo modelos ajustados) e com agentes para Amazon Bedrock para que os clientes possam trazer um nível consistente de proteção para todas as suas aplicações generativas de IA.
Camada superior da pilha: a inovação contínua torna a IA generativa acessível a mais usuários
Na camada superior da pilha estão os aplicativos que aproveitam LLMs e outros FMs para que você possa aproveitar as vantagens da IA generativa no trabalho. Uma área onde a IA generativa já está mudando o jogo é a codificação. No ano passado, lançamos o Amazon CodeWhisperer, que ajuda você a criar aplicativos com mais rapidez e segurança, gerando sugestões e recomendações de código quase em tempo real. Clientes como Accenture, Boeing, Bundesliga, The Cigna Group, Kone e Warner Music Group estão usando o CodeWhisperer para aumentar a produtividade dos desenvolvedores – e a Accenture está capacitando até 50,000 de seus desenvolvedores de software e profissionais de TI com o Amazon CodeWhisperer. Queremos que o maior número possível de desenvolvedores consiga obter os benefícios de produtividade da IA generativa, e é por isso que o CodeWhisperer oferece recomendações gratuitamente para todos os indivíduos.
No entanto, embora as ferramentas de codificação de IA façam muito para facilitar a vida dos desenvolvedores, seus benefícios de produtividade são limitados pela falta de conhecimento de bases de código internas, APIs internas, bibliotecas, pacotes e classes. Uma maneira de pensar sobre isso é que se você contratar um novo desenvolvedor, mesmo que seja de classe mundial, ele não será tão produtivo em sua empresa até que entenda suas práticas recomendadas e seu código. As ferramentas de codificação baseadas em IA de hoje são como aquele desenvolvedor recém-contratado. Para ajudar com isso, recentemente visualizamos um novo capacidade de personalização no Amazon CodeWhisperer que aproveita com segurança a base de código interna de um cliente para fornecer recomendações de código mais relevantes e úteis. Com esse recurso, CodeWhisperer é especialista em os código e fornece recomendações mais relevantes para economizar ainda mais tempo. Em um estudo que fizemos com a Persistent, uma empresa global de engenharia digital e modernização empresarial, descobrimos que as personalizações ajudam os desenvolvedores a concluir tarefas até 28% mais rápido do que com os recursos gerais do CodeWhisperer. Agora, um desenvolvedor de uma empresa de tecnologia de saúde pode pedir ao CodeWhisperer para “importar imagens de ressonância magnética associadas ao ID do cliente e executá-las no classificador de imagens” para detectar anomalias. Como o CodeWhisperer tem acesso à base de código, ele pode fornecer sugestões muito mais relevantes que incluem os locais de importação das imagens de ressonância magnética e IDs de clientes. O CodeWhisperer mantém as personalizações totalmente privadas e o FM subjacente não as utiliza para treinamento, protegendo a valiosa propriedade intelectual dos clientes. A AWS é o único grande provedor de nuvem que oferece recursos como esse para todos.
Apresentando... Amazon Q, o assistente generativo com tecnologia de IA feito sob medida para o trabalho
Os desenvolvedores certamente não são os únicos que estão experimentando a IA generativa – milhões de pessoas estão usando aplicativos de bate-papo com IA generativa. O que os primeiros fornecedores fizeram neste espaço é emocionante e super útil para os consumidores, mas em muitos aspectos eles não “funcionam” no trabalho. Seus conhecimentos e capacidades gerais são excelentes, mas eles não conhecem sua empresa, seus dados, seus clientes, suas operações ou seus negócios. Isso limita o quanto eles podem ajudá-lo. Eles também não sabem muito sobre o seu papel – que trabalho você faz, com quem trabalha, que informações você usa e a que você tem acesso. Essas limitações são compreensíveis porque esses assistentes não têm acesso às informações privadas da sua empresa e não foram projetados para atender aos requisitos de privacidade e segurança de dados que as empresas precisam para lhes conceder esse acesso. É difícil garantir a segurança após o fato e esperar que funcione bem. Acreditamos que temos uma maneira melhor, que permitirá que todas as pessoas em todas as organizações utilizem a IA generativa com segurança no seu trabalho diário.
Westamos entusiasmados em apresentar Amazon Q, um novo tipo de assistente generativo com tecnologia de IA especificamente para o trabalho e que pode ser adaptado ao seu negócio. Q pode ajudá-lo a obter respostas rápidas e relevantes para perguntas urgentes, resolver problemas, gerar conteúdo e tomar ações usando os dados e a experiência encontrados nos repositórios de informações, códigos e sistemas corporativos da sua empresa. Quando você conversa com o Amazon Q, ele fornece informações e conselhos imediatos e relevantes para ajudar a agilizar tarefas, acelerar a tomada de decisões e ajudar a estimular a criatividade e a inovação no trabalho. Construímos o Amazon Q para ser seguro e privado, e ele pode compreender e respeitar suas identidades, funções e permissões existentes e usar essas informações para personalizar suas interações. Se um usuário não tiver permissão para acessar determinados dados sem Q, ele também não poderá acessá-los usando Q. Projetamos o Amazon Q para atender aos rigorosos requisitos dos clientes empresariais desde o primeiro dia: nenhum conteúdo é usado para melhorar os modelos subjacentes.

Amazon Q é seu assistente especialista para construir na AWS: treinamos o Amazon Q com 17 anos de conhecimento e experiência em AWS para que ele possa transformar a maneira como você cria, implanta e opera aplicativos e cargas de trabalho na AWS. O Amazon Q tem uma interface de chat no AWS Management Console e documentação, seu IDE (via CodeWhisperer) e salas de chat de sua equipe no Slack ou em outros aplicativos de chat. O Amazon Q pode ajudá-lo a explorar novos recursos da AWS, começar a usar mais rapidamente, aprender tecnologias desconhecidas, arquitetar soluções, solucionar problemas, atualizar e muito mais. Ele é especialista em padrões bem arquitetados da AWS, práticas recomendadas, documentação e implementações de soluções. Aqui estão alguns exemplos do que você pode fazer com seu novo assistente especialista da AWS:
- Obtenha respostas precisas e orientações sobre recursos, serviços e soluções da AWS: Peça ao Amazon Q para “Conte-me sobre os agentes do Amazon Bedrock” e Q fornecerá uma descrição do recurso, além de links para materiais relevantes. Você também pode fazer ao Amazon Q praticamente qualquer pergunta sobre como funciona um serviço AWS (por exemplo, “Quais são os limites de escalabilidade em uma tabela DynamoDB?” “O que é armazenamento gerenciado Redshift?”) ou como arquitetar melhor qualquer número de soluções ( “Quais são as melhores práticas para construir arquiteturas orientadas a eventos?”). E o Amazon Q reunirá respostas sucintas e sempre citará (e vinculará) suas fontes.
- Escolha o melhor serviço AWS para seu caso de uso e comece rapidamente: Pergunte à Amazon Q “Quais são as maneiras de construir um aplicativo da Web na AWS? ”E fornecerá uma lista de serviços potenciais, como Amplificar AWS, AWS Lambda e Amazon EC2 com as vantagens de cada um. A partir daí você pode restringir as opções ajudando Q a entender seus requisitos, preferências e restrições (por exemplo, “Qual destes seria melhor se eu quiser usar contêineres?” ou “Devo usar um banco de dados relacional ou não relacional? ”). Termine com “Como posso começar?” e o Amazon Q descreverá algumas etapas básicas e indicará recursos adicionais.
- Otimize seus recursos computacionais: O Amazon Q pode ajudá-lo a selecionar instâncias do Amazon EC2. Se você pedir “Ajude-me a encontrar a instância EC2 certa para implantar uma carga de trabalho de codificação de vídeo para meu aplicativo de jogos com o mais alto desempenho”, Q fornecerá uma lista de famílias de instâncias com motivos para cada sugestão. E você pode fazer inúmeras perguntas de acompanhamento para ajudar a encontrar a melhor opção para sua carga de trabalho.
- Obtenha assistência para depurar, testar e otimizar seu código: Se você encontrar um erro ao codificar em seu IDE, peça ajuda ao Amazon Q dizendo: “Meu código tem um erro de E/S, você pode fornecer uma correção?” e Q irá gerar o código para você. Se gostar da sugestão, você pode pedir ao Amazon Q para adicionar a correção ao seu aplicativo. Como o Amazon Q está no seu IDE, ele entende o código em que você está trabalhando e sabe onde inserir a correção. O Amazon Q também pode criar testes de unidade (“Escrever testes de unidade para a função selecionada”) que podem ser inseridos em seu código e você pode executar. Por fim, o Amazon Q pode indicar maneiras de otimizar seu código para obter melhor desempenho. Peça a Q para “Otimizar minha consulta selecionada do DynamoDB” e ele usará a compreensão do seu código para fornecer uma sugestão em linguagem natural sobre o que corrigir junto com o código que o acompanha que você pode implementar com um clique.
- Diagnosticar e solucionar problemas: Se você encontrar problemas no AWS Management Console, como erros de permissão EC2 ou erros de configuração do Amazon S3, basta pressionar o botão “Solucionar problemas com Amazon Q” e ele usará sua compreensão do tipo de erro e do serviço onde o erro está localizado para lhe dar sugestões de solução. Você pode até pedir ao Amazon Q para solucionar problemas de sua rede (por exemplo, “Por que não consigo me conectar à minha instância EC2 usando SSH?”) e Q analisará sua configuração ponta a ponta e fornecerá um diagnóstico (por exemplo, “Esta instância parece estar em uma sub-rede privada, então a acessibilidade pública pode precisar ser estabelecida”).
- Crie uma nova base de código rapidamente: Quando você conversa com o Amazon Q em seu IDE, ele combina sua experiência na criação de software com a compreensão do seu código – uma combinação poderosa! Anteriormente, se você assumisse um projeto de outra pessoa ou fosse novo na equipe, talvez precisasse passar horas revisando manualmente o código e a documentação para entender como funciona e o que faz. Agora, como o Amazon Q entende o código em seu IDE, você pode simplesmente pedir ao Amazon Q para explicar o código (“Forneça-me uma descrição do que este aplicativo faz e como funciona”) e Q fornecerá detalhes como quais serviços o o código usa e o que diferentes funções fazem (por exemplo, Q pode responder algo como: “Este aplicativo está construindo um sistema básico de tickets de suporte usando Python Flask e AWS Lambda” e continuar descrevendo cada um de seus principais recursos, como eles são implementados, e muito mais).
- Limpe seu backlog de recursos mais rapidamente: Você pode até mesmo pedir ao Amazon Q para orientá-lo e automatizar grande parte do processo completo de adição de um recurso ao seu aplicativo em Amazon CodeCatalyst, nosso serviço unificado de desenvolvimento de software para equipes. Para fazer isso, basta atribuir a Q uma tarefa de backlog de sua lista de problemas – assim como faria com um colega de equipe – e Q gera um plano passo a passo sobre como construirá e implementará o recurso. Depois de aprovar o plano, Q escreverá o código e apresentará as alterações sugeridas como uma revisão do código. Você pode solicitar retrabalho (se necessário), aprovar e/ou implantar!
- Atualize seu código em uma fração do tempo: A maioria dos desenvolvedores gasta apenas uma fração do seu tempo escrevendo novos códigos e construindo novos aplicativos. Eles gastam muito mais de seus ciclos em áreas dolorosas e lentas, como manutenção e atualizações. Faça atualizações de versão de idioma. Um grande número de clientes continua usando versões mais antigas do Java porque levará meses — até mesmo anos — e milhares de horas de tempo de desenvolvedor para atualizar. Adiar isso tem custos e riscos reais: você perde melhorias de desempenho e fica vulnerável a problemas de segurança. Acreditamos que o Amazon Q pode ser uma virada de jogo aqui e estamos entusiasmados com Transformação do código Q da Amazon, um recurso que pode remover grande parte desse trabalho pesado e reduzir o tempo necessário para atualizar aplicativos de dias para minutos. Basta abrir o código que deseja atualizar em seu IDE e pedir ao Amazon Q para “/transformar” seu código. O Amazon Q analisará todo o código-fonte do aplicativo, gerará o código na linguagem e versão de destino e executará testes, ajudando você a obter melhorias de segurança e desempenho das versões de linguagem mais recentes. Recentemente, uma equipe muito pequena de desenvolvedores da Amazon usou o Amazon Q Code Transformation para atualizar 1,000 aplicativos de produção do Java 8 para o Java 17 em apenas dois dias. O tempo médio por aplicação foi inferior a 10 minutos. Hoje, o Amazon Q Code Transformation realiza atualizações da linguagem Java de Java 8 ou Java 11 para Java 17. A seguir (e em breve) está a capacidade de transformar o .NET Framework em .NET multiplataforma (com ainda mais transformações no futuro). .
Amazon Q é o seu especialista em negócios: você pode conectar o Amazon Q aos dados, informações e sistemas do seu negócio para que ele possa sintetizar tudo e fornecer assistência personalizada para ajudar as pessoas a resolver problemas, gerar conteúdo e realizar ações relevantes para o seu negócio. Trazer o Amazon Q para o seu negócio é fácil. Possui mais de 40 conectores integrados para sistemas empresariais populares, como Amazon S3, Microsoft 365, Salesforce, ServiceNow, Slack, Atlassian, Gmail, Google Drive e Zendesk. Ele também pode se conectar à sua intranet interna, wikis e livros de execução e, com o Amazon Q SDK, você pode criar uma conexão com qualquer aplicativo interno que desejar. Aponte o Amazon Q para esses repositórios e ele “aumentará” o seu negócio, capturando e compreendendo as informações semânticas que tornam sua empresa única. Em seguida, você obtém seu próprio aplicativo Web Amazon Q simples e amigável para que os funcionários de sua empresa possam interagir com a interface de conversação. O Amazon Q também se conecta ao seu provedor de identidade para entender um usuário, sua função e quais sistemas ele tem permissão para acessar, para que os usuários possam fazer perguntas detalhadas e diferenciadas e obter resultados personalizados que incluem apenas as informações que estão autorizados a ver. O Amazon Q gera respostas e insights precisos e fiéis ao material e ao conhecimento que você fornece, e você pode restringir tópicos delicados, bloquear palavras-chave ou filtrar perguntas e respostas inadequadas. Aqui estão alguns exemplos do que você pode fazer com o novo assistente especializado da sua empresa:
- Obtenha respostas nítidas e super relevantes com base nos dados e informações do seu negócio: Os funcionários podem perguntar ao Amazon Q sobre qualquer coisa que tenham pesquisado anteriormente em todos os tipos de fontes. Pergunte “Quais são as diretrizes mais recentes para uso de logotipo?” ou “Como posso solicitar um cartão de crédito corporativo?”, e o Amazon Q sintetizará todo o conteúdo relevante que encontrar e retornará com respostas rápidas, além de links para os conteúdos relevantes. fontes (por exemplo, portais de marcas e repositórios de logotipos, políticas de T&E da empresa e solicitações de cartão).
- Simplifique as comunicações do dia a dia: Basta perguntar e o Amazon Q pode gerar conteúdo (“Criar uma postagem no blog e três manchetes de mídia social anunciando o produto descrito nesta documentação”), criar resumos executivos (“Escrever um resumo da transcrição da nossa reunião com uma lista com marcadores de itens de ação” ), fornecer atualizações por e-mail (“Elabore um e-mail destacando nossos programas de treinamento do terceiro trimestre para clientes na Índia”) e ajude a estruturar reuniões (“Criar uma agenda de reunião para falar sobre o último relatório de satisfação do cliente”).
- Tarefas completas: O Amazon Q pode ajudar a concluir determinadas tarefas, reduzindo a quantidade de tempo que os funcionários gastam em trabalhos repetitivos, como preencher tíquetes. Peça ao Amazon Q para “Resumir o feedback do cliente sobre a nova oferta de preços no Slack” e, em seguida, solicite que Q pegue essas informações e abra um ticket no Jira para atualizar a equipe de marketing. Você pode pedir a Q para “Resumir a transcrição desta chamada” e, em seguida, “Abrir um novo caso para o Cliente A no Salesforce”. O Amazon Q oferece suporte a outras ferramentas populares de automação de trabalho, como Zendesk e Service Now.
Amazon Q está no Amazon QuickSight: Com o Amazon Q no QuickSight, serviço de business intelligence da AWS, os usuários podem fazer perguntas aos seus painéis como “Por que o número de pedidos aumentou no mês passado?” e obtenha visualizações e explicações dos fatores que influenciaram o aumento. E os analistas podem usar o Amazon Q para reduzir o tempo que levam para criar painéis de dias para minutos com um prompt simples como “Mostre-me as vendas por região por mês como um gráfico de barras empilhadas”. Q volta com esse diagrama, e você pode adicioná-lo facilmente a um painel ou conversar mais com Q para refinar a visualização (por exemplo, “Alterar o gráfico de barras em um diagrama de Sankey” ou “Mostrar países em vez de regiões”). O Amazon Q no QuickSight também facilita o uso de painéis existentes para informar as partes interessadas da empresa, extrair insights importantes e simplificar a tomada de decisões usando histórias de dados. Por exemplo, os usuários podem solicitar ao Amazon Q que “construa uma história sobre como o negócio mudou no último mês para uma análise de negócios com a liderança sênior” e, em segundos, o Amazon Q fornece uma história baseada em dados que é visualmente atraente e é completamente personalizável. Essas histórias podem ser compartilhadas com segurança em toda a organização para ajudar a alinhar as partes interessadas e tomar melhores decisões.
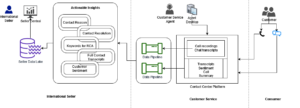
Amazon Q está no Amazon Connect: No Amazon Connect, nosso serviço de contact center, o Amazon Q ajuda seus agentes de atendimento ao cliente a fornecer um melhor atendimento ao cliente. O Amazon Q aproveita os repositórios de conhecimento que seus agentes normalmente usam para obter informações para os clientes e, então, os agentes podem conversar com o Amazon Q diretamente no Connect para obter respostas que os ajudem a responder mais rapidamente às solicitações dos clientes, sem precisar pesquisar eles próprios a documentação. E, embora seja ótimo conversar com o Amazon Q para obter respostas super rápidas, no atendimento ao cliente não existe rapidez demais. É por isso Amazon Q In Connect transforma uma conversa ao vivo do cliente com um agente em um prompt e fornece automaticamente ao agente possíveis respostas, ações sugeridas e links para recursos. Por exemplo, o Amazon Q pode detectar que um cliente está entrando em contato com uma locadora de veículos para alterar sua reserva, gerar uma resposta para o agente comunicar rapidamente como as políticas de taxas de alteração da empresa se aplicam e orientar o agente nas etapas necessárias para atualizar a reserva. reserva.
Amazon Q está na cadeia de suprimentos da AWS (em breve): No AWS Supply Chain, nosso serviço de insights da cadeia de suprimentos, o Amazon Q ajuda planejadores de oferta e demanda, gerentes de estoque e parceiros comerciais a otimizar sua cadeia de suprimentos, resumindo e destacando possíveis riscos de falta ou excesso de estoque e visualizando cenários para resolver o problema. Os usuários podem fazer perguntas “o quê”, “por que” e “e se” ao Amazon Q sobre os dados da cadeia de suprimentos e conversar sobre cenários complexos e as compensações entre as diferentes decisões da cadeia de suprimentos. Por exemplo, um cliente pode perguntar: “O que está causando o atraso nas minhas remessas e como posso acelerar as coisas?” ao que a Amazon Q pode responder: “90% dos seus pedidos estão na costa leste, e uma grande tempestade no Sudeste está causando um atraso de 24 horas. Se você enviar para o porto de Nova York em vez de Miami, você agilizará as entregas e reduzirá os custos em 50%.”
Nossos clientes estão adotando a IA generativa rapidamente: eles estão treinando modelos inovadores na AWS, desenvolvendo aplicativos de IA generativos em velocidade recorde usando o Amazon Bedrock e implantando aplicativos revolucionários em suas organizações, como o Amazon Q. Com nossos anúncios mais recentes, a AWS está trazendo aos clientes ainda mais desempenho, opções e inovação em todas as camadas da pilha. O impacto combinado de todos os recursos que oferecemos na re:Invent representa um marco importante no cumprimento de uma meta interessante e significativa: estamos tornando a IA generativa acessível a clientes de todos os tamanhos e habilidades técnicas para que eles possam reinventar e transformar o que é possível.
Recursos
Sobre o autor
 Swami Sivasubramanian é vice-presidente de dados e aprendizado de máquina da AWS. Nessa função, Swami supervisiona todos os serviços de banco de dados, análise e IA e machine learning da AWS. A missão de sua equipe é ajudar as organizações a colocar seus dados para funcionar com uma solução de dados completa e de ponta a ponta para armazenar, acessar, analisar, visualizar e prever.
Swami Sivasubramanian é vice-presidente de dados e aprendizado de máquina da AWS. Nessa função, Swami supervisiona todos os serviços de banco de dados, análise e IA e machine learning da AWS. A missão de sua equipe é ajudar as organizações a colocar seus dados para funcionar com uma solução de dados completa e de ponta a ponta para armazenar, acessar, analisar, visualizar e prever.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/welcome-to-a-new-era-of-building-in-the-cloud-with-generative-ai-on-aws/
- :tem
- :é
- :não
- :onde
- $UP
- 000
- 1
- 10
- 100
- 11
- 12
- 17
- 200
- 2019
- 2024
- 25
- 30
- 300
- 35%
- 40
- 50
- 500
- 65
- 8
- 9
- a
- habilidades
- habilidade
- Capaz
- Sobre
- acima
- acelerar
- acelerado
- aceleradores
- Accenture
- Acesso
- acessibilidade
- acessível
- Contabilidade
- precisão
- preciso
- adquirir
- em
- Açao Social
- ações
- ativamente
- adaptar
- adicionar
- adicionado
- acrescentando
- Adição
- Adicional
- Adicionalmente
- Adicionais
- Adiciona
- Adidas
- adobe
- Adotando
- avançado
- Avançando
- Vantagem
- vantagens
- Publicidade
- conselho
- Depois de
- contra
- agenda
- Agente
- agentes
- agregar
- atrás
- AI
- IA e aprendizado de máquina
- Chatbot AI
- ai pesquisa
- Alimentado por AI
- alinhar
- Todos os Produtos
- permitir
- permite
- juntamente
- já
- tb
- sempre
- Amazon
- Sussurrador de Código da Amazon
- Amazon EC2
- AmazonQuickSight
- Amazon Sage Maker
- Amazon Web Services
- quantidade
- quantidades
- an
- análise
- analista
- Analistas
- analítica
- analisar
- análises
- e
- Anunciar
- Anúncios
- Anunciando
- responder
- respostas
- Antrópico
- qualquer
- qualquer um
- nada
- api
- APIs
- app
- aparece
- Aplicação
- aplicações
- Aplicar
- apreciar
- abordagem
- aprovar
- aprovou
- Aplicativos
- Abril
- SOMOS
- ÁREA
- áreas
- indiscutivelmente
- por aí
- AS
- perguntar
- Assistência
- Assistente
- assistentes
- associado
- associados
- At
- Atlassian
- aumentar
- aumentado
- aumentos
- aurora
- autorizado
- automatizar
- automatiza
- Automático
- automaticamente
- Automação
- automotivo
- disponibilidade
- disponível
- média
- evitar
- longe
- AWS
- Inferência da AWS
- AWS Lambda
- Console de gerenciamento da AWS
- em caminho duplo
- Bancário
- Barra
- barreiras
- base
- baseado
- basic
- BE
- Porque
- torna-se
- sido
- começou
- Acreditar
- Benefícios
- MELHOR
- melhores práticas
- Melhor
- entre
- Grande
- bilhão
- bilhões
- Bloquear
- Blocos
- Blog
- Boeing
- parafuso
- reserva
- Booking.com
- Livros
- ambos
- Inferior
- limites
- interesse?
- Break
- quebra
- trazer
- Trazendo
- construir
- Prédio
- Constrói
- construído
- construídas em
- negócio
- inteligência de negócios
- negócios
- mas a
- botão
- by
- chamada
- call center
- CAN
- Pode obter
- capacidades
- capacidade
- capaz
- Capacidade
- Capturar
- carro
- carbono
- as emissões de carbono
- cartão
- cuidadosamente
- casas
- casos
- Categorias
- causando
- Centralização de
- certo
- certamente
- cadeia
- desafiar
- desafios
- alterar
- mudado
- Changer
- Alterações
- mudança
- características
- de cores
- charts
- salas de chat
- chatbot
- chatbots
- conversando
- verificar
- lasca
- Chips
- escolha
- Escolha
- escolha
- escolhido
- reivindicações
- aulas
- Limpeza
- remover filtragem
- clique
- Na nuvem
- infraestrutura de nuvem
- Agrupar
- agrupamento
- Costa
- código
- base de código
- Revisão de código
- Codificação
- colaborando
- colaboração
- COM
- combinação
- combinar
- combinado
- combina
- como
- vem
- vinda
- Em Breve
- comunicar
- Comunicações
- Empresas
- Empresa
- Empresa
- comparado
- atraente
- completar
- completamente
- integrações
- complexidade
- compreensivo
- Computar
- conceitos
- Configuração
- configurando
- conjetura
- Contato
- conectado
- da conexão
- Conectividade
- conecta
- consistente
- cônsul
- restrições
- Consumidores
- consumo
- Contacto
- contact center
- Containers
- conteúdo
- contexto
- contextual
- continuar
- continuou
- continua
- continuar
- ao controle
- controles
- Conversa
- conversação
- conversas
- direitos autorais
- copywriting
- núcleo
- Custo
- relação custo-benefício
- custos
- países
- Cox
- crio
- criado
- criatividade
- criadores
- crédito
- cartão de crédito
- Crime
- CRISP
- CRM
- multi-plataforma
- cliente
- experiência do cliente
- A satisfação do cliente
- Atendimento ao Cliente
- Clientes
- personalizável
- personalização
- personalizar
- personalizado
- Cortar
- ciclos
- diariamente
- painel de instrumentos
- painéis
- dados,
- Preparação de dados
- privacidade de dados
- Privacidade e segurança de dados
- conjuntos de dados
- orientado por dados
- banco de dados
- bases de dados
- Bancos de dados
- dia
- dia a dia
- dias
- Tomada de Decisão
- decisões
- profundo
- deep learning
- mais profunda
- definições
- Grau
- atraso
- entregar
- Entregas
- entregando
- entrega
- Demanda
- Democratizando
- Dependendo
- implantar
- implantado
- Implantação
- desenvolvimento
- profundidade
- descreve
- descrito
- descrição
- projetado
- desejado
- detalhado
- detalhes
- descobrir
- Determinar
- DEUTSCHE TELECOM
- Developer
- desenvolvedores
- em desenvolvimento
- Desenvolvimento
- diagnóstico
- diálogo
- Diálogo
- DID
- diferente
- Distribuição
- digital
- diretamente
- distribuir
- distribuído
- treinamento distribuído
- distribuindo
- do
- documento
- documentação
- INSTITUCIONAIS
- parece
- Não faz
- fazer
- feito
- não
- duplicação
- down
- distância
- dois
- duplicatas
- duração
- e
- e-commerce,
- cada
- Cedo
- mais fácil
- facilmente
- Leste
- Costa leste
- fácil
- Economia
- edição
- efetivamente
- eficiência
- eficientemente
- esforço
- ou
- outro
- e-mails
- emissões
- colaboradores
- autorizar
- capacitação
- permitir
- permitindo
- codificação
- encontro
- final
- end-to-end
- energia
- Consumo de energia
- eficiência energética
- engenheiro
- Engenharia
- aumentar
- Melhorias
- enriquecedor
- Empreendimento
- de nível empresarial
- empresas
- Entretenimento
- Todo
- envelope
- Era
- ERP
- erro
- erros
- Éter (ETH)
- avaliações
- Mesmo
- eventos
- SEMPRE
- Cada
- todos
- tudo
- evolução
- evolui
- exemplo
- exemplos
- animado
- emocionante
- executar
- executivo
- existente
- expansivo
- esperar
- a acelerar
- caro
- vasta experiência
- experiente
- Experiências
- especialista
- experiência
- Explicação
- explorar
- expresso
- tecidos
- Rosto
- fato
- fatores
- bastante
- fiel
- falcão
- Cair
- familiar
- famílias
- família
- RÁPIDO
- mais rápido
- defeituoso
- Característica
- Funcionalidades
- taxa
- retornos
- poucos
- Arquivamento
- filtro
- Finalmente
- financeiro
- Encontre
- descoberta
- encontra
- final
- acabamento
- Primeiro nome
- Fixar
- flexível
- focado
- seguir
- Escolha
- Para os consumidores
- para a frente
- encontrado
- Foundation
- quatro
- fração
- Quadro
- enquadramentos
- Gratuito
- freqüentemente
- amigável
- da
- funções
- mais distante
- futuro
- jogo
- jogador desafiante
- jogos
- Geral
- geralmente
- gerar
- gera
- gerando
- geração
- generativo
- IA generativa
- gerador
- ter
- obtendo
- OFERTE
- Global
- digital global
- gmail
- Go
- meta
- vai
- Bom estado, com sinais de uso
- GPU
- GPUs
- ótimo
- Solo
- inovador
- Grupo
- Crescente
- crescido
- orientações
- guia
- orientações
- tinha
- mãos
- Acontecimento
- Queijos duros
- Hardware
- prejudicial
- odiar
- discurso de ódio
- Ter
- ter
- headlines
- saúde
- pesado
- levantamento pesado
- ajudar
- ajuda
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Alta
- superior
- mais
- Destacando
- altamente
- contratar
- sua
- hospedagem
- HORÁRIO
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTTPS
- Centenas
- i
- ID
- identidades
- Identidade
- ids
- if
- imagem
- geração de imagem
- imagens
- Imediato
- Impacto
- executar
- implementações
- implementado
- importar
- importante
- impressionante
- melhorar
- melhorado
- melhorias
- in
- incluir
- inclui
- Incluindo
- Crescimento
- aumentou
- aumentando
- indicadores
- indivíduos
- indústrias
- indústria
- líder da indústria
- influenciado
- info
- informar
- INFORMAÇÕES
- Infraestrutura
- inovar
- inovando
- Inovação
- e inovações
- inovadores
- entrada
- inputs
- introspecção
- insights
- instância
- instâncias
- em vez disso
- Instituto
- instruções
- com seguro
- integração
- intelectual
- propriedade intelectual
- Inteligência
- pretende
- interagir
- interações
- interage
- interconectado
- Interface
- interno
- intervir
- para dentro
- introduzir
- introduzido
- introduzindo
- Inventado
- inventário
- Investir
- investigativo
- investir
- investimento
- Investimentos
- envolvido
- envolve
- questões
- IT
- Profissionais de TI
- ESTÁ
- Japonês
- jargão
- Java
- jpg
- apenas por
- apenas um
- Guarda
- manutenção
- Chave
- Áreas-chave
- palavras-chave
- de emergência
- Conjunto (SDK)
- Saber
- Conhecimento
- sabe
- Laboratório
- Falta
- língua
- grande
- em grande escala
- maior
- Sobrenome
- Ano passado
- Atrasado
- Latência
- mais recente
- lançado
- de lançamento
- Advogados
- camada
- camadas
- Liderança
- principal
- APRENDER
- aprendido
- aprendizagem
- Legal
- menos
- Permite
- Nível
- Alavancagem
- aproveita as
- LexisNexis
- LG
- bibliotecas
- wifecycwe
- facelift
- como
- Provável
- limitações
- Limitado
- limites
- linhas
- LINK
- Links
- Lista
- viver
- Vidas
- lhama
- localizado
- locais
- lógico
- logotipo
- longo
- de longa data
- lote
- gosta,
- Baixo
- diminuir
- menor
- máquina
- aprendizado de máquina
- moldadas
- a manter
- manutenção
- manutenção
- principal
- fazer
- FAZ
- Fazendo
- gerenciados
- de grupos
- Gerentes
- manual
- trabalho manual
- manualmente
- muitos
- Marketing
- material
- materiais
- máximo
- Posso..
- me
- significativo
- significa
- Mídia
- Conheça
- reunião
- reuniões
- atende
- Membros
- mers
- Meta
- método
- Miami
- Microsoft
- Microsoft 365
- Coração
- poder
- marco miliário
- minutos
- perder
- Missão
- ML
- modelo
- modelagem
- modelos
- modernização
- Ímpeto
- MongoDB
- monitores
- Mês
- mês
- mais
- a maioria
- Mais populares
- em movimento
- MRI
- muito
- múltiplo
- Música
- devo
- my
- nome
- Nasdaq
- natural
- Linguagem Natural
- Perto
- necessário
- você merece...
- necessário
- necessitando
- líquido
- rede
- networking
- Novo
- New York
- recentemente
- Próximo
- Nitro
- não
- laptops
- agora
- número
- Nvidia
- of
- WOW!
- ofensivo
- oferecer
- oferecendo treinamento para distância
- Oferece
- frequentemente
- mais velho
- on
- uma vez
- ONE
- queridos
- online
- serviços bancários online
- só
- aberto
- operar
- Operações
- Otimize
- otimizado
- otimizando
- Opções
- or
- ordens
- organização
- organizações
- original
- Outros
- Outros
- A Nossa
- Fora
- esboço
- saída
- outputs
- Acima de
- estoque excessivo
- esmagadoramente
- próprio
- Paz
- pacotes
- doloroso
- pares
- parâmetro
- parâmetros
- parte
- Parceiros
- peças
- passado
- padrões
- pausa
- Pessoas
- para
- realizar
- atuação
- realizada
- executa
- permissão
- permissões
- pessoa
- Personalização
- Personalizar
- Pessoalmente
- PGA Tour
- Frases
- Pii
- Lugar
- plano
- platão
- Inteligência de Dados Platão
- PlatãoData
- mais
- ponto
- políticas
- Popular
- positivo
- possível
- Publique
- potencial
- poder
- alimentado
- poderoso
- Prática
- praticamente
- práticas
- preciso
- predizer
- Previsões
- preferências
- preparação
- Preparar
- presente
- presidente
- imprensa
- premente
- visualização
- anteriormente
- preço
- preços
- primário
- política de privacidade
- Privacidade e segurança
- privado
- informação privada
- Problema
- problemas
- processo
- processos
- em processamento
- produzir
- Produto
- Produção
- produtivo
- produtividade
- profissional
- Programas
- projeto
- solicita
- propriedade
- proprietário
- proteger
- proteção
- fornecer
- provedor
- fornecedores
- fornece
- fornecendo
- público
- publicamente
- fins
- Empurrar
- Empurrando
- colocar
- Colocar
- Python
- pytorch
- Q3
- quantitativo
- questão
- Frequentes
- Links
- rapidamente
- bastante
- R & D
- alcance
- rápido
- rapidamente
- Preços
- RE
- Leitura
- reais
- em tempo real
- realista
- perceber
- realizado
- clientes
- colhendo
- razões
- recentemente
- Recomendação
- recomendações
- registro
- reduzir
- Reduzido
- redução
- refinar
- região
- liberado
- relevante
- confiabilidade
- permanece
- remover
- removendo
- reparação
- repetitivo
- substituição
- resposta
- Denunciar
- repositório
- solicitar
- pedidos
- requeridos
- Requisitos
- pesquisa
- reserva
- Reservar
- Resolução
- Ressoa
- Recursos
- respeito
- Responder
- responder
- resposta
- respostas
- responsável
- restringir
- restringido
- resultar
- Resultados
- voltar
- rever
- revendo
- certo
- riscos
- Tipo
- papéis
- Quartos
- rotas
- Regra
- Execute
- corrida
- pista
- sacrificando
- seguro
- proteções
- seguramente
- sábio
- vendas
- Salesforce
- mesmo
- satisfação
- Salvar
- dizendo
- Escala
- dimensionamento
- cenários
- escopo
- pontuações
- arranhar
- Sdk
- desatado
- Pesquisar
- Segundo
- Segunda geração
- segundo
- seguro
- firmemente
- segurança
- Vejo
- visto
- visto
- selecionar
- selecionado
- doadores,
- envio
- senior
- liderança sênior
- sensível
- Setembro
- Seqüência
- Série
- Servidores
- serviço
- ServiceNow
- Serviços
- conjunto
- Conjuntos
- vários
- Partilhar
- compartilhado
- navio
- Baixo
- rede de apoio social
- lado
- periodo
- Silício
- Similarmente
- simples
- simplificar
- simplesmente
- desde
- SIX
- tamanhos
- folga
- pequeno
- So
- Redes Sociais
- meios de comunicação social
- Software
- Desenvolvedores de software
- desenvolvimento de software
- kit de desenvolvimento de software
- solução
- Soluções
- RESOLVER
- alguns
- Alguém
- algo
- Em breve
- sofisticado
- fonte
- código fonte
- Fontes
- sudeste
- Espaço
- Faísca
- especificamente
- discurso
- velocidade
- gastar
- Estabilidade
- estável
- pilha
- empilhado
- partes interessadas
- começado
- Comece
- Startups
- estado-da-arte
- ficar
- Passo
- Passos
- Ainda
- armazenamento
- loja
- lojas
- Histórias
- Storm
- História
- simplificar
- Fortalecer
- rigoroso
- estrutura
- Estudo
- sub-rede
- substancial
- tal
- adequado
- suíte
- resumir
- RESUMO
- super
- completar
- fornecedores
- supply
- Oferta e procura
- cadeia de suprimentos
- ajuda
- suportes
- certo
- surpreendente
- vigilância
- suspeito
- Sustentabilidade
- Interruptor
- sintetizar
- .
- sistemas
- mesa
- adaptados
- Tire
- toma
- tomar
- Converse
- Target
- Tarefa
- tarefas
- Profissionais
- Membros do time
- equipes
- Dados Técnicos:
- técnica
- técnicas
- Tecnologias
- Tecnologia
- inovação tecnológica
- dizer
- dizendo
- dez
- dezenas
- fluxo tensor
- terminologia
- teste
- ensaio
- testes
- texto
- geração de texto
- do que
- que
- A
- O Futuro
- o mundo
- deles
- Eles
- si mesmos
- então
- Lá.
- Este
- deles
- coisa
- coisas
- think
- Terceiro
- isto
- este ano
- aqueles
- milhares
- três
- Através da
- todo
- Taxa de transferência
- bilhete
- bilhetes
- tempo
- vezes
- titã
- para
- hoje
- hoje
- juntos
- token
- também
- levou
- ferramenta
- ferramentas
- topo
- Temas
- excursão
- para
- para
- pista
- Trading
- Trem
- treinado
- Training
- Transações
- Cópia
- Transformar
- Transformação
- transformações
- transformando
- viagens
- trilhões
- viagem
- verdadeiramente
- Confiança
- tentar
- tentando
- voltas
- dois
- tipo
- tipicamente
- subjacente
- compreender
- compreensível
- compreensão
- entende
- desconhecido
- unificado
- único
- características únicas
- unidade
- ao contrário
- até
- Atualizar
- Atualizações
- atualização
- atualizações
- us
- Uso
- usar
- caso de uso
- usava
- Utilizador
- usuários
- usos
- utilização
- Valioso
- variedade
- vário
- versão
- Contra
- muito
- via
- vício
- Vice-Presidente
- Vídeo
- praticamente
- visualização
- visualizar
- visualmente
- volumes
- Vulnerável
- queremos
- Warner
- Warner Music Group
- foi
- Onda
- Caminho..
- maneiras
- we
- web
- Aplicativo da Web
- serviços web
- sites
- semana
- semanas
- boas-vindas
- BEM
- bem conhecido
- foram
- O Quê
- O que é a
- quando
- se
- qual
- enquanto
- QUEM
- porque
- Largo
- Ampla variedade
- mais largo
- precisarão
- janela
- de
- dentro
- sem
- Atividades:
- trabalhou
- fluxos de trabalho
- trabalhar
- trabalho
- mundo
- classe mundial
- preocupar-se
- Equivalente há
- seria
- escrever
- escrever código
- escrita
- ano
- anos
- Iorque
- Você
- investimentos
- Zendesk
- zefirnet