Principais lições
- A Propagação de Pensamento (TP) é um novo método que aprimora as habilidades complexas de raciocínio de Grandes Modelos de Linguagem (LLMs).
- O TP aproveita problemas análogos e suas soluções para melhorar o raciocínio, em vez de fazer os LLMs raciocinarem do zero.
- Experimentos em diversas tarefas mostram que o TP supera substancialmente os métodos de referência, com melhorias que variam de 12% a 15%.
O TP primeiro solicita aos LLMs que proponham e resolvam um conjunto de problemas análogos relacionados ao problema de entrada. Em seguida, o TP reutiliza os resultados de problemas análogos para produzir diretamente uma nova solução ou derivar um plano de execução intensivo em conhecimento para alterar a solução inicial obtida do zero.
A versatilidade e o poder computacional dos Large Language Models (LLMs) são inegáveis, mas não são ilimitados. Um dos desafios mais significativos e consistentes para os LLMs é a sua abordagem geral à resolução de problemas, que consiste no raciocínio a partir dos primeiros princípios para cada nova tarefa encontrada. Isto é problemático, pois permite um elevado grau de adaptabilidade, mas também aumenta a probabilidade de erros, particularmente em tarefas que requerem raciocínio em vários passos.
O desafio de “raciocinar do zero” é especialmente pronunciado em tarefas complexas que exigem múltiplas etapas de lógica e inferência. Por exemplo, se for pedido a um LLM que encontre o caminho mais curto numa rede de pontos interligados, normalmente não aproveitará o conhecimento prévio ou problemas análogos para encontrar uma solução. Em vez disso, tentaria resolver o problema isoladamente, o que pode levar a resultados abaixo do ideal ou mesmo a erros flagrantes. Digitar Propagação de Pensamento (TP), um método projetado para aumentar as capacidades de raciocínio dos LLMs. O TP visa superar as limitações inerentes aos LLMs, permitindo-lhes extrair de um reservatório de problemas análogos e suas soluções correspondentes. Esta abordagem inovadora não apenas melhora a precisão das soluções geradas pelo LLM, mas também aumenta significativamente sua capacidade de lidar com tarefas de raciocínio complexas e em várias etapas. Ao aproveitar o poder da analogia, o TP fornece uma estrutura que amplifica as capacidades de raciocínio inatas dos LLMs, aproximando-nos um passo da realização de sistemas artificiais verdadeiramente inteligentes.
A propagação do pensamento envolve duas etapas principais:
- Primeiro, o LLM é solicitado a propor e resolver um conjunto de problemas análogos relacionados ao problema de entrada
- Em seguida, as soluções para estes problemas análogos são usadas para produzir diretamente uma nova solução ou para alterar a solução inicial.
O processo de identificação de problemas análogos permite ao LLM reutilizar estratégias e soluções de resolução de problemas, melhorando assim as suas capacidades de raciocínio. O TP é compatível com os métodos de prompt existentes, fornecendo uma solução generalizável que pode ser incorporada em diversas tarefas sem necessidade de engenharia específica significativa.
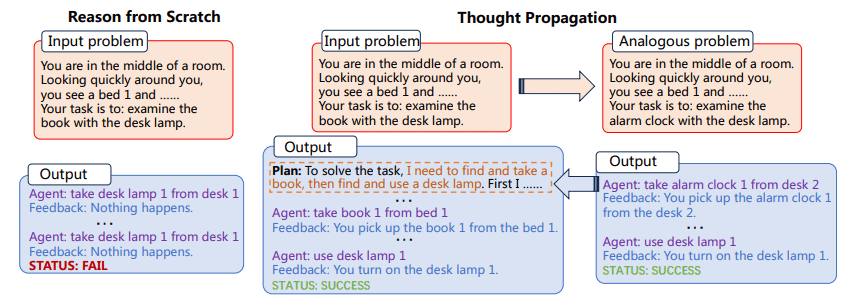
Figura 1: O processo de propagação do pensamento (imagem do papel)
Além disso, a adaptabilidade do PT não deve ser subestimada. Sua compatibilidade com os métodos de solicitação existentes o torna uma ferramenta altamente versátil. Isto significa que o TP não está limitado a nenhum tipo específico de domínio de resolução de problemas. Isso abre caminhos interessantes para o ajuste fino e a otimização de tarefas específicas, elevando assim a utilidade e a eficácia dos LLMs em um amplo espectro de aplicações.
A implementação da Propagação de Pensamento pode ser integrada ao fluxo de trabalho dos LLMs existentes. Por exemplo, em uma tarefa de raciocínio de caminho mais curto, TP poderia primeiro resolver um conjunto de problemas análogos mais simples para compreender vários caminhos possíveis. Usaria então esses insights para resolver o problema complexo, aumentando assim a probabilidade de encontrar a solução ideal.
Exemplo 1
- Tarefa: Raciocínio do caminho mais curto
- Problemas análogos: Caminho mais curto entre o ponto A e B, Caminho mais curto entre o ponto B e C
- Solução final: Caminho ótimo do ponto A ao C considerando as soluções de problemas análogos
Exemplo 2
- Tarefa: Escrita criativa
- Problemas análogos: Escreva um conto sobre amizade, Escreva um conto sobre confiança
- Solução final: Escreva um conto complexo que integre temas de amizade e confiança
O processo envolve primeiro resolver esses problemas análogos e depois usar os insights obtidos para enfrentar a tarefa complexa em questão. Este método demonstrou sua eficácia em diversas tarefas, apresentando melhorias substanciais nas métricas de desempenho.
As implicações da Propagação de Pensamento vão além da mera melhoria das métricas existentes. Esta técnica de estímulo tem o potencial de alterar a forma como entendemos e implantamos LLMs. A metodologia sublinha uma mudança da resolução de problemas isolada e atómica para uma abordagem mais holística e interligada. Isso nos leva a considerar como os LLMs podem aprender não apenas com os dados, mas com o próprio processo de resolução de problemas. Ao atualizar continuamente a sua compreensão através de soluções para problemas análogos, os LLMs equipados com TP estão mais bem preparados para enfrentar desafios imprevistos, tornando-os mais resilientes e adaptáveis em ambientes em rápida evolução.
A Propagação de Pensamento é uma adição promissora à caixa de ferramentas de métodos de estímulo destinados a aprimorar as capacidades dos LLMs. Ao permitir que os LLMs aproveitem problemas análogos e suas soluções, o TP fornece um método de raciocínio mais matizado e eficaz. As experiências confirmam a sua eficácia, tornando-o uma estratégia candidata para melhorar o desempenho dos LLMs numa variedade de tarefas. O TP pode, em última análise, representar um avanço significativo na procura de sistemas de IA mais capazes.
Mateus Mayo (@mattmayo13) possui mestrado em ciência da computação e pós-graduação em mineração de dados. Como editor-chefe do KDnuggets, Matthew pretende tornar acessíveis conceitos complexos de ciência de dados. Seus interesses profissionais incluem processamento de linguagem natural, algoritmos de aprendizado de máquina e exploração de IA emergente. Ele é movido pela missão de democratizar o conhecimento na comunidade de ciência de dados. Matthew codifica desde os 6 anos de idade.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.kdnuggets.com/thought-propagation-an-analogical-approach-to-complex-reasoning-with-large-language-models?utm_source=rss&utm_medium=rss&utm_campaign=thought-propagation-an-analogical-approach-to-complex-reasoning-with-large-language-models
- :tem
- :é
- :não
- $UP
- 15%
- 8
- a
- habilidades
- habilidade
- Sobre
- acessível
- precisão
- em
- Adição
- AI
- Sistemas de IA
- Destinado
- visa
- algoritmos
- Permitindo
- permite
- tb
- amplifica
- an
- e
- qualquer
- aplicações
- abordagem
- SOMOS
- artificial
- AS
- At
- tentativa
- aumentar
- avenidas
- b
- Linha de Base
- BE
- sido
- Melhor
- entre
- Pós
- Trazendo
- amplo
- mas a
- by
- CAN
- candidato
- capacidades
- capaz
- desafiar
- desafios
- mais próximo
- Codificação
- comunidade
- compatibilidade
- compatível
- integrações
- computacional
- poder computacional
- computador
- Ciência da Computação
- conceitos
- Confirmar
- Considerar
- considerando
- consistente
- Consistindo
- continuamente
- Correspondente
- poderia
- Criatividade
- dados,
- mineração de dados
- ciência de dados
- Grau
- Demanda
- democratizar
- demonstraram
- implantar
- projetado
- diretamente
- domínio
- desenhar
- dirigido
- editor-chefe
- Eficaz
- eficácia
- eficácia
- ou
- Elevando
- emergente
- Engenharia
- Melhora
- aprimorando
- Entrar
- ambientes
- equipado
- erros
- especialmente
- Mesmo
- Cada
- evolução
- exemplo
- emocionante
- execução
- existente
- experimentos
- Explorando
- Encontre
- descoberta
- Primeiro nome
- Escolha
- para a frente
- Quadro
- Amizade
- da
- ganhou
- Geral
- Go
- pós-graduação
- mão
- he
- Alta
- altamente
- sua
- detém
- holística
- Como funciona o dobrador de carta de canal
- HTTPS
- identificar
- if
- imagem
- implementação
- implicações
- melhorar
- melhorias
- melhora
- melhorar
- in
- incluir
- Incorporado
- Aumenta
- aumentando
- inerente
- do estado inicial,
- inato
- inovadores
- entrada
- insights
- em vez disso
- integrado
- Integra-se
- Inteligente
- interconectado
- interesses
- para dentro
- envolve
- isolado
- isolamento
- IT
- ESTÁ
- se
- jpg
- apenas por
- KDnuggetsGenericName
- Tipo
- Conhecimento
- língua
- grande
- conduzir
- APRENDER
- aprendizagem
- Alavancagem
- aproveita as
- aproveitando
- probabilidade
- LIMITE
- limitações
- Limitado
- lógica
- máquina
- aprendizado de máquina
- a Principal
- fazer
- FAZ
- Fazendo
- dominar
- Mateus
- Posso..
- significa
- apenas
- método
- Metodologia
- métodos
- Métrica
- Mineração
- Missão
- modelos
- mais
- a maioria
- múltiplo
- natural
- Linguagem Natural
- Processamento de linguagem natural
- rede
- Novo
- nova solução
- romance
- obtido
- of
- Velho
- on
- ONE
- só
- abre
- ideal
- otimização
- or
- Supera o desempenho
- abertamente
- Superar
- Papel
- particularmente
- caminho
- atuação
- plano
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- pontos
- possível
- potencial
- poder
- preparado
- princípios
- Prévio
- Problema
- Solução de problemas
- problemas
- processo
- em processamento
- profissional
- promissor
- pronunciado
- propagação
- oferece
- fornece
- fornecendo
- variando
- rapidamente
- em vez
- realização
- razão
- relacionado
- representação
- representar
- requerer
- resiliente
- Resultados
- reutilizar
- s
- Ciência
- arranhar
- Pesquisar
- conjunto
- mudança
- Baixo
- rede de apoio social
- mostrar
- apresentando
- periodo
- de forma considerável
- desde
- solução
- Soluções
- RESOLVER
- Resolvendo
- específico
- Espectro
- Passo
- Passos
- História
- estratégias
- Estratégia
- substancial
- substancialmente
- sistemas
- equipamento
- Tarefa
- tarefas
- técnica
- do que
- que
- A
- deles
- Eles
- temas
- então
- assim
- Este
- deles
- isto
- pensamento
- Através da
- para
- ferramenta
- Caixa de ferramentas
- para
- tp
- verdadeiramente
- Confiança
- dois
- tipicamente
- Em última análise
- inegável
- sublinhados
- compreender
- compreensão
- imprevisto
- atualização
- us
- usar
- usava
- utilização
- utilidade
- variedade
- vário
- versátil
- versatilidade
- foi
- we
- qual
- de
- sem
- de gestão de documentos
- seria
- escrever
- escrita
- anos
- ainda
- Produção
- zefirnet