Especialistas à mesa: Engenharia de semicondutores sentou-se para falar sobre o caminho a seguir para a memória em sistemas cada vez mais heterogêneos, com Frank Ferro, diretor do grupo, gerenciamento de produtos da Cadência; Steven Woo, colega e ilustre inventor da Rambus; Jongsin Yun, tecnólogo de memória da Siemens EDA; Randy White, gerente de programa de soluções de memória da Keysight; e Frank Schirrmeister, vice-presidente de soluções e desenvolvimento de negócios da Arteris. O que se segue são trechos dessa conversa. A primeira parte desta discussão pode ser encontrada SUA PARTICIPAÇÃO FAZ A DIFERENÇA.
![[Da esquerda para a direita]: Frank Ferro, Cadence; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, da Keysight; e Frank Schirrmeister, Arteris.](https://platoaistream.com/wp-content/uploads/2024/01/rethinking-memory.png)
[Da esquerda para a direita]: Frank Ferro, Cadence; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, da Keysight; e Frank Schirrmeister, Arteris
SE: À medida que lutamos com IA/ML e demandas de energia, quais configurações precisam ser repensadas? Veremos uma mudança na arquitetura de Von Neumann?
Uau: Em termos de arquiteturas de sistemas, há uma bifurcação acontecendo na indústria. Os aplicativos tradicionais que são os cavalos de batalha dominantes, executados na nuvem em servidores baseados em x86, não irão desaparecer. Há décadas de software que foi construído e evoluiu e que dependerá dessa arquitetura para ter um bom desempenho. Por outro lado, AI/ML é uma nova classe. As pessoas repensaram as arquiteturas e construíram processadores muito específicos para cada domínio. Estamos vendo que cerca de dois terços da energia são gastos apenas na movimentação de dados entre um processador e um dispositivo HBM, enquanto apenas cerca de um terço é gasto no acesso real aos bits nos núcleos DRAM. A movimentação de dados é agora muito mais desafiadora e cara. Não vamos nos livrar da memória. Precisamos disso porque os conjuntos de dados estão ficando maiores. Portanto, a questão é: ‘Qual é o caminho certo a seguir?’ Tem havido muita discussão sobre empilhamento. Se pegássemos essa memória e a colocássemos diretamente em cima do processador, isso faria duas coisas por você. Primeiro, a largura de banda hoje é limitada pela costa ou pelo perímetro do chip. É para lá que vão as E/S. Mas se você empilhá-lo diretamente em cima do processador, agora você pode usar toda a área do chip para interconexões distribuídas, e você pode obter mais largura de banda na própria memória, e ela pode alimentar diretamente para dentro. o processador. Os links ficam muito mais curtos e a eficiência energética provavelmente aumenta na ordem de 5X a 6X. Em segundo lugar, a quantidade de largura de banda que você pode obter devido a mais interconexão de matriz de área com a memória também aumenta em vários fatores inteiros. Fazer essas duas coisas juntas pode fornecer mais largura de banda e torná-la mais eficiente em termos de energia. A indústria evolui de acordo com as necessidades, e essa é definitivamente uma maneira pela qual veremos os sistemas de memória começarem a evoluir no futuro para se tornarem mais eficientes em termos de energia e fornecerem mais largura de banda.
Ferro: Quando comecei a trabalhar na HBM, por volta de 2016, alguns dos clientes mais avançados perguntaram se ela poderia ser empilhada. Eles estão procurando como empilhar a DRAM há algum tempo porque há vantagens claras. Da camada física, o PHY torna-se basicamente insignificante, o que economiza muita energia e eficiência. Mas agora você tem um processador de vários 100 W com memória. A memória não aguenta o calor. É provavelmente o elo mais fraco da cadeia de calor, o que cria outro desafio. Há benefícios, mas eles ainda precisam descobrir como lidar com as térmicas. Há mais incentivos agora para avançar com esse tipo de arquitetura, porque isso realmente economiza em termos de desempenho e potência, além de melhorar a eficiência da computação. Mas existem alguns desafios de design físico que precisam ser enfrentados. Como Steve estava dizendo, vemos todos os tipos de arquiteturas sendo lançadas. Concordo totalmente que as arquiteturas GPU/CPU não vão a lugar nenhum, elas ainda serão dominantes. Ao mesmo tempo, todas as empresas do planeta estão tentando criar uma ratoeira melhor para fazer sua IA. Vemos SRAM no chip e combinações de memória de alta largura de banda. O LPDDR tem se levantado bastante atualmente em termos de como aproveitar as vantagens do LPDDR no data center por causa do poder. Vimos até mesmo GDDR sendo usado em alguns aplicativos de inferência de IA, bem como em todos os sistemas de memória antigos. Eles agora estão tentando espremer o máximo possível de DDR5s em uma área ocupada. Já vi todas as arquiteturas que você possa imaginar, seja DDR, HBM, GDDR ou outras. Depende do núcleo do seu processador em termos de qual é o seu valor agregado geral e como você pode romper sua arquitetura específica. O sistema de memória que o acompanha, para que você possa esculpir sua CPU e sua arquitetura de memória, dependendo do que estiver disponível.
E um: Outra questão é a não volatilidade. Se a IA tiver que lidar com o intervalo de energia entre a execução de uma IA baseada em IoT, por exemplo, então precisaremos de muita energia ligada e desligada, e todas essas informações para o treinamento de IA terão que ser alternadas continuamente. Se tivermos algum tipo de solução onde possamos armazenar esses pesos no chip para que não tenhamos que ir e voltar sempre para obter o mesmo peso, então haverá muita economia de energia, especialmente para IA baseada em IoT. Haverá outra solução para ajudar essas demandas de energia.
Schirrmeister: O que acho fascinante, do ponto de vista NoC, é onde você tem que otimizar esses caminhos de um processador passando por um NoC, acessando uma interface de memória com um controlador potencialmente passando por UCIe para passar um chiplet para outro chiplet, que então tem memória em isto. Não é que as arquiteturas de Von Neumann estejam mortas. Mas existem muitas variações agora, dependendo da carga de trabalho que você deseja calcular. Eles precisam ser considerados no contexto da memória, e a memória é apenas um aspecto. Onde você obtém os dados da localidade de dados, como eles são organizados nesta DRAM? Estamos trabalhando em todas essas coisas, como análise de desempenho de memórias e, em seguida, otimização da arquitetura do sistema. Está estimulando muita inovação para novas arquiteturas, nas quais nunca pensei quando estava na universidade aprendendo sobre Von Neumann. No outro extremo, você tem coisas como malhas. Há muito mais arquiteturas agora a serem consideradas, e isso é impulsionado pela largura de banda da memória, recursos de computação e assim por diante, não crescendo na mesma taxa.
Branco: Há uma tendência envolvendo computação desagregada ou distribuída, o que significa que o arquiteto precisa ter mais ferramentas à sua disposição. A hierarquia de memória se expandiu. Estão incluídas semânticas, assim como CXL e diversas memórias híbridas, que estão disponíveis para flash e em DRAM. Uma aplicação paralela ao data center é a automotiva. O setor automotivo sempre teve esse sensor computado com ECUs (unidades de controle eletrônico). Estou fascinado em como isso evoluiu para o data center. Avançando rapidamente, hoje temos nós de computação distribuídos, chamados controladores de domínio. É a mesma coisa. Ele está tentando resolver que talvez a energia não seja um grande problema porque a escala dos computadores não é tão grande, mas a latência é certamente um grande problema no setor automotivo. ADAS precisa de largura de banda superalta e você tem diferentes compensações. E então você tem mais sensores mecânicos, mas restrições semelhantes em um data center. Você tem armazenamento frio que não precisa ter baixa latência e outros aplicativos de alta largura de banda. É fascinante ver o quanto as ferramentas e as opções do arquiteto evoluíram. A indústria tem feito um ótimo trabalho de resposta e todos nós fornecemos várias soluções que alimentam o mercado.
SE: Como as ferramentas de design de memória evoluíram?
Schirrmeister: Quando comecei com meus primeiros chips nos anos 90, a ferramenta de sistema mais usada era o Excel. Desde então, sempre esperei que isso pudesse quebrar em algum ponto devido às coisas que fazemos no nível do sistema, memória, análise de largura de banda e assim por diante. Isso impactou bastante minhas equipes. Na época, era uma coisa muito avançada. Mas, na opinião de Randy, agora certas coisas complexas precisam ser simuladas com um nível de fidelidade que antes não era possível sem a computação. Para dar um exemplo, assumir uma certa latência para um acesso DRAM pode levar a más decisões de arquitetura e ao projeto potencialmente incorreto de arquiteturas de transporte de dados no chip. O outro lado também é verdade. Se você sempre assumir o pior caso, você projetará demais a arquitetura. Ter ferramentas que executam a DRAM e a análise de desempenho, e ter os modelos adequados disponíveis para os controladores, permite que um arquiteto simule tudo isso, é um ambiente fascinante para se estar. Minha esperança, desde os anos 90, de que o Excel pudesse, em algum momento, quebrar como um A ferramenta de nível de sistema pode realmente se tornar realidade, porque alguns dos efeitos dinâmicos que você não pode mais fazer no Excel porque precisa simulá-los - especialmente quando você adiciona uma interface morre-a-morte com características PHY e, em seguida, vincula a camada características como verificar se tudo estava correto e potencialmente reenviar dados. Não realizar essas simulações resultará em uma arquitetura abaixo do ideal.
Ferro: O primeiro passo na maioria das avaliações que fazemos é fornecer a eles o testbench de memória para começar a observar a eficiência da DRAM. Esse é um grande passo, mesmo fazendo coisas tão simples como executar ferramentas locais para fazer simulação de DRAM, mas depois passar para simulações completas. Vemos mais clientes solicitando esse tipo de simulação. Garantir que a eficiência da sua DRAM esteja na casa dos 90 é um primeiro passo muito importante em qualquer avaliação.
Uau: Parte do motivo pelo qual você vê o surgimento de ferramentas completas de simulação de sistema é que as DRAMs se tornaram muito mais complicadas. É muito difícil agora estar no controle de algumas dessas cargas de trabalho complexas usando ferramentas simples como o Excel. Se você olhar a folha de dados da DRAM nos anos 90, verá que essas folhas de dados tinham cerca de 40 páginas. Agora são centenas de páginas. Isso apenas fala da complexidade do dispositivo para obter altas larguras de banda. Você associa isso ao fato de que a memória é um grande fator no custo do sistema, bem como na largura de banda e na latência relacionadas ao desempenho do processador. É também um grande impulsionador de potência, então você precisa simular em um nível muito mais detalhado agora. Em termos de fluxo de ferramentas, os arquitetos de sistemas entendem que a memória é um grande impulsionador. Portanto, as ferramentas precisam ser mais sofisticadas e interagir muito bem com outras ferramentas para que o arquiteto do sistema obtenha a melhor visão global do que está acontecendo – especialmente sobre como a memória está impactando o sistema.
E um: À medida que avançamos para a era da IA, muitos sistemas multi-core são usados, mas não sabemos quais dados vão para onde. Também está indo mais paralelo ao chip. O tamanho da memória é muito maior. Se usarmos o tipo de IA ChatGPT, o tratamento de dados para os modelos requer cerca de 350 MB de dados, o que é uma enorme quantidade de dados apenas para pesar, e a entrada/saída real é muito maior. Esse aumento na quantidade de dados necessários significa que há muitos efeitos probabilísticos que nunca vimos antes. É um teste extremamente desafiador ver todos os erros relacionados a essa grande quantidade de memória. E o ECC é usado em todos os lugares, até mesmo na SRAM, que tradicionalmente não usava ECC, mas agora é muito comum nos maiores sistemas. Testar tudo isso é muito desafiador e precisa ser apoiado por soluções EDA para testar todas essas diferentes condições.
SE: Que desafios as equipes de engenharia enfrentam no dia a dia?
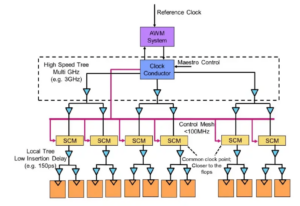
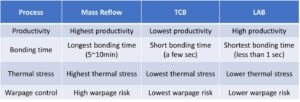
Branco: Em qualquer dia, você me encontrará no laboratório. Arregacei as mangas e fiquei com as mãos sujas, cutucando fios, soldando e tudo mais. Penso muito na validação pós-silício. Conversamos sobre as primeiras simulações e ferramentas na matriz – BiST e coisas assim. No final das contas, antes de enviarmos, queremos fazer alguma forma de validação do sistema ou testes no nível do dispositivo. Conversamos sobre como superar o muro da memória. Colocamos memória, HBM, coisas assim. Se olharmos para a evolução da tecnologia de embalagens, começamos com embalagens com chumbo. Eles não eram muito bons para a integridade do sinal. Décadas depois, passamos para uma integridade de sinal otimizada, como ball grid arrays (BGAs). Não conseguimos acessar isso, o que significava que você não poderia testá-lo. Então, criamos esse conceito chamado interposer de dispositivo – um interposer BGA – e isso nos permitiu colocar um acessório especial que roteava os sinais. Então poderíamos conectá-lo ao equipamento de teste. Avançando até hoje, agora temos HBM e chips. Como faço para colocar meu acessório no intermediário de silício? Não podemos, e essa é a luta. É um desafio que me mantém acordado à noite. Como realizamos análises de falhas em campo com um OEM ou cliente de sistema, onde eles não estão obtendo eficiência de 90%. Há mais erros no link, eles não conseguem inicializar corretamente e o treinamento não está funcionando. É um problema de integridade do sistema?
Schirrmeister: Você não preferiria fazer isso em casa com uma interface virtual do que caminhar até o laboratório? A resposta não é mais análises que você incorpora no chip? Com os chips, integramos tudo ainda mais. Colocar seu ferro de soldar lá não é realmente uma opção, então é preciso haver uma maneira de análise no chip. Temos o mesmo problema para a NoC. As pessoas olham para a NoC, você envia os dados e eles desaparecem. Precisamos que a análise seja implementada para que as pessoas possam fazer a depuração, e isso se estende ao nível de fabricação, para que você finalmente possa trabalhar em casa e fazer tudo com base na análise do chip.
Ferro: Especialmente com memória de alta largura de banda, você não consegue entrar fisicamente lá. Quando licenciamos o PHY, também temos um produto que o acompanha, para que você possa ver cada um desses 1,024 bits. Você pode começar a ler e gravar DRAM a partir da ferramenta para não precisar entrar lá fisicamente. Gosto da ideia do intermediário. Retiramos alguns pinos do intermediário durante o teste, o que você não pode fazer no sistema. É realmente um desafio entrar nesses sistemas 3D. Mesmo do ponto de vista do fluxo de ferramentas de design, parece que a maioria das empresas faz seu próprio fluxo individual em muitas dessas ferramentas 2.5D. Estamos começando a montar uma forma mais padronizada de construir um sistema 2.5D, desde a integridade do sinal, potência, todo o fluxo.
Branco: À medida que as coisas avançam, espero que ainda possamos manter o mesmo nível de precisão. Estou no grupo de conformidade do fator de forma UCIe. Estou procurando como caracterizar um dado conhecido como bom, um dado dourado. Eventualmente, isso levará muito mais tempo, mas encontraremos um meio termo entre o desempenho e a precisão dos testes de que precisamos e a flexibilidade incorporada.
Schirrmeister: Se eu analisar os chips e sua adoção em um ambiente de produção mais aberto, os testes são um dos maiores desafios para fazê-los funcionar corretamente. Se sou uma grande empresa e controlo todos os seus lados, posso restringir as coisas de forma adequada para que os testes e assim por diante se tornem viáveis. Se eu quiser seguir o slogan da UCIe de que a UCI está a apenas uma letra do PCI, e imagino um futuro onde a montagem da UCIe se tornará, do ponto de vista da fabricação, como os slots PCI em um PC hoje, então os aspectos de teste para isso são realmente desafiante. Precisamos encontrar uma solução. Há muito trabalho a fazer.
Artigos Relacionados
O futuro da memória (Parte 1 da rodada acima)
Das tentativas de resolver problemas térmicos e de energia até as funções do CXL e UCIe, o futuro reserva uma série de oportunidades para a memória.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://semiengineering.com/rethinking-memory/
- :tem
- :é
- :não
- :onde
- $UP
- 1
- 2016
- 3d
- 40
- a
- Sobre
- acima
- Acesso
- acessando
- precisão
- real
- ADA
- adicionar
- endereço
- Adoção
- avançado
- Vantagem
- vantagens
- novamente
- AI
- Treinamento de IA
- AI / ML
- Todos os Produtos
- permitidas
- permite
- tb
- sempre
- quantidade
- an
- análise
- analítica
- e
- Outro
- responder
- qualquer
- mais
- qualquer lugar
- Aplicação
- aplicações
- adequadamente
- arquitetos
- arquitetura
- SOMOS
- ÁREA
- por aí
- arranjado
- Ordem
- AS
- pergunta
- aspecto
- aspectos
- Montagem
- assumir
- At
- Tentativas
- automotivo
- disponível
- longe
- em caminho duplo
- Mau
- bola
- Largura de Banda
- Barra
- baseado
- Basicamente
- base
- BE
- Porque
- tornam-se
- torna-se
- sido
- antes
- ser
- Benefícios
- MELHOR
- Melhor
- entre
- Grande
- maior
- Pouco
- Break
- trazer
- construir
- construído
- negócio
- desenvolvimento de negócios
- mas a
- by
- Cadência
- chamado
- veio
- CAN
- Pode obter
- capacidades
- casas
- Centralização de
- certo
- certamente
- cadeia
- desafiar
- desafios
- desafiante
- características
- caracterizar
- a verificação
- lasca
- Chips
- classe
- remover filtragem
- Na nuvem
- frio
- Cold Storage
- combinações
- como
- vinda
- comum
- Empresas
- Empresa
- integrações
- complexidade
- compliance
- complicado
- Computar
- computadores
- computação
- conceito
- condições
- Contato
- considerado
- restrições
- contexto
- contraste
- ao controle
- controlador
- Conversa
- núcleo
- correta
- Custo
- poderia
- Casal
- CPU
- cria
- cliente
- Clientes
- dados,
- Data Center
- conjuntos de dados
- dia
- dia a dia
- dias
- morto
- acordo
- décadas
- decisões
- definitivamente
- demandas
- Dependendo
- depende
- Design
- concepção
- detalhado
- Desenvolvimento
- dispositivo
- morrem
- diferente
- difícil
- diretamente
- Diretor
- discussão
- disposição
- Distinto
- distribuído
- computação distribuída
- do
- parece
- Não faz
- fazer
- domínio
- dominante
- feito
- não
- down
- dirigido
- motorista
- durante
- dinâmico
- Cedo
- efeitos
- eficiência
- eficiente
- Eletrônico
- final
- energia
- Engenharia
- Todo
- Meio Ambiente
- equipamento
- Era
- erros
- especialmente
- Éter (ETH)
- avaliação
- avaliações
- Mesmo
- eventualmente
- Cada
- tudo
- em toda parte
- evolução
- evolui
- evoluiu
- evolui
- exemplo
- Excel
- expandido
- caro
- se estende
- extremo
- extremamente
- Olhos
- Rosto
- fato
- fator
- Falha
- fascinante
- RÁPIDO
- factível
- companheiro
- fidelidade
- campo
- Figura
- Finalmente
- Encontre
- Primeiro nome
- Flash
- Flexibilidade
- Giro
- fluxo
- segue
- Pegada
- Escolha
- formulário
- adiante
- para a frente
- encontrado
- franco
- da
- cheio
- mais distante
- futuro
- ter
- obtendo
- OFERTE
- dado
- Global
- Go
- vai
- vai
- Dourado
- ido
- Bom estado, com sinais de uso
- bom trabalho
- tem
- Grade
- Grupo
- Crescente
- tinha
- Manipulação
- mãos
- feliz
- Ter
- ter
- cabeça
- ajudar
- hierarquia
- Alta
- detém
- Início
- esperança
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- enorme
- Centenas
- HÍBRIDO
- i
- idéia
- if
- fotografia
- impactada
- impactando
- importante
- melhorar
- in
- Incentivo
- incluído
- incorretamente
- Crescimento
- cada vez mais
- Individual
- indústria
- INFORMAÇÕES
- Inovação
- dentro
- integrar
- integridade
- interliga
- Interface
- para dentro
- envolvendo
- emitem
- questões
- IT
- ESTÁ
- se
- Trabalho
- apenas por
- Saber
- conhecido
- laboratório
- grande
- Maior
- maior
- Latência
- mais tarde
- camada
- conduzir
- aprendizagem
- carta
- Nível
- Licença
- como
- Limitado
- LINK
- Links
- local
- olhar
- procurando
- lote
- grande quantidade
- Baixo
- a manter
- fazer
- Fazendo
- de grupos
- Gerente
- fabrica
- muitos
- mercado
- max-width
- talvez
- me
- significa
- significava
- mecânico
- média
- Memórias
- Memória
- poder
- modelos
- mais
- a maioria
- mover
- movido
- movimento
- em movimento
- muito
- my
- você merece...
- Cria
- nunca
- Novo
- noite
- nós
- agora
- número
- of
- WOW!
- Velho
- on
- ONE
- só
- aberto
- oportunidades
- Otimize
- otimizado
- otimizando
- Opção
- Opções
- or
- ordem
- Outros
- Outros
- Fora
- global
- Superar
- próprio
- pacotes
- acondicionamento
- páginas
- Paralelo
- parte
- particular
- passar
- caminho
- caminhos
- PC
- Pessoas
- realizar
- atuação
- perspectiva
- físico
- Fisicamente
- pins
- avião
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- possível
- potencialmente
- poder
- presidente
- anteriormente
- provavelmente
- Problema
- Subcontratante
- processadores
- Produto
- gestão de produtos
- Produção
- Agenda
- adequado
- devidamente
- fornecer
- colocar
- questão
- bastante
- elevando
- Taxa
- em vez
- Leitura
- clientes
- relacionado
- depender
- requeridos
- exige
- resolver
- responder
- resultar
- Livrar
- certo
- Subir
- papéis
- Rolo
- Execute
- corrida
- mesmo
- Salvar
- Poupança
- dizendo
- Escala
- Segundo
- Vejo
- visto
- parece
- visto
- semântica
- Semicondutor
- enviar
- sensor
- sensor
- Servidores
- vários
- folhas
- mudança
- navio
- lado
- Sides
- Siemens
- Signal
- sinais
- Silício
- semelhante
- simples
- simulação
- simulações
- desde
- solteiro
- Tamanho
- caça-níqueis
- So
- Software
- solução
- Soluções
- alguns
- sofisticado
- fala
- especial
- gasto
- Squeeze
- pilha
- empilhado
- empilhamento
- padronizado
- ponto de vista
- começo
- começado
- Comece
- Passo
- Steve
- steven
- Ainda
- armazenamento
- loja
- Lutar
- tal
- Suportado
- certo
- .
- sistemas
- mesa
- Tire
- Converse
- equipes
- tecnólogo
- Tecnologia
- condições
- teste
- ensaio
- testes
- do que
- que
- A
- O Futuro
- deles
- Eles
- então
- Lá.
- térmico
- Este
- deles
- coisa
- coisas
- think
- Terceiro
- isto
- aqueles
- pensamento
- Através da
- tempo
- para
- hoje
- juntos
- ferramenta
- ferramentas
- topo
- TOTALMENTE
- compensações
- tradicional
- tradicionalmente
- Training
- transporte
- Trend
- verdadeiro
- tentando
- dois
- dois terços
- tipo
- compreender
- unidades
- universidade
- us
- usar
- usava
- utilização
- validação
- valor
- variações
- vário
- muito
- vício
- Vice-Presidente
- Ver
- Virtual
- de
- caminhada
- parede
- queremos
- foi
- Caminho..
- we
- peso
- BEM
- foram
- O Quê
- o que quer
- quando
- se
- qual
- enquanto
- branco
- inteiro
- porque
- precisarão
- de
- sem
- cortejar
- Atividades:
- trabalho a partir de casa
- trabalhar
- o pior
- escrita
- Você
- investimentos
- zefirnet