Com o lançamento do recurso de busca neural para Serviço Amazon OpenSearch no OpenSearch 2.9, agora é fácil integrar-se a modelos de IA/ML para potencializar a pesquisa semântica e outros casos de uso. O OpenSearch Service oferece suporte à pesquisa lexical e vetorial desde a introdução de seu recurso k-vizinho mais próximo (k-NN) em 2020; no entanto, a configuração da pesquisa semântica exigiu a construção de uma estrutura para integrar modelos de aprendizado de máquina (ML) para ingestão e pesquisa. O recurso de pesquisa neural facilita a transformação de texto em vetor durante a ingestão e a pesquisa. Quando você usa uma consulta neural durante a pesquisa, a consulta é traduzida em uma incorporação de vetor e k-NN é usado para retornar as incorporações de vetor mais próximas do corpus.
Para usar a pesquisa neural, você deve configurar um modelo de ML. Recomendamos configurar conectores de IA/ML para serviços de IA e ML da AWS (como Amazon Sage Maker or Rocha Amazônica) ou alternativas de terceiros. A partir da versão 2.9 no OpenSearch Service, os conectores AI/ML integram-se à pesquisa neural para simplificar e operacionalizar a tradução do seu corpus de dados e consultas para incorporações de vetores, removendo assim grande parte da complexidade da hidratação e pesquisa de vetores.
Nesta postagem, demonstramos como configurar conectores AI/ML para modelos externos por meio do console do OpenSearch Service.
Visão geral da solução
Especificamente, esta postagem orienta você na conexão com um modelo no SageMaker. Em seguida, orientamos você no uso do conector para configurar a pesquisa semântica no OpenSearch Service como um exemplo de caso de uso compatível por meio da conexão a um modelo de ML. Atualmente, as integrações do Amazon Bedrock e do SageMaker são compatíveis com a IU do console do OpenSearch Service, e a lista de integrações próprias e de terceiros com suporte da IU continuará a crescer.
Para quaisquer modelos não suportados pela UI, você pode configurá-los usando as APIs disponíveis e o Projetos de ML. Para obter mais informações, consulte Introdução aos modelos OpenSearch. Você pode encontrar projetos para cada conector no Repositório GitHub do ML Commons.
Pré-requisitos
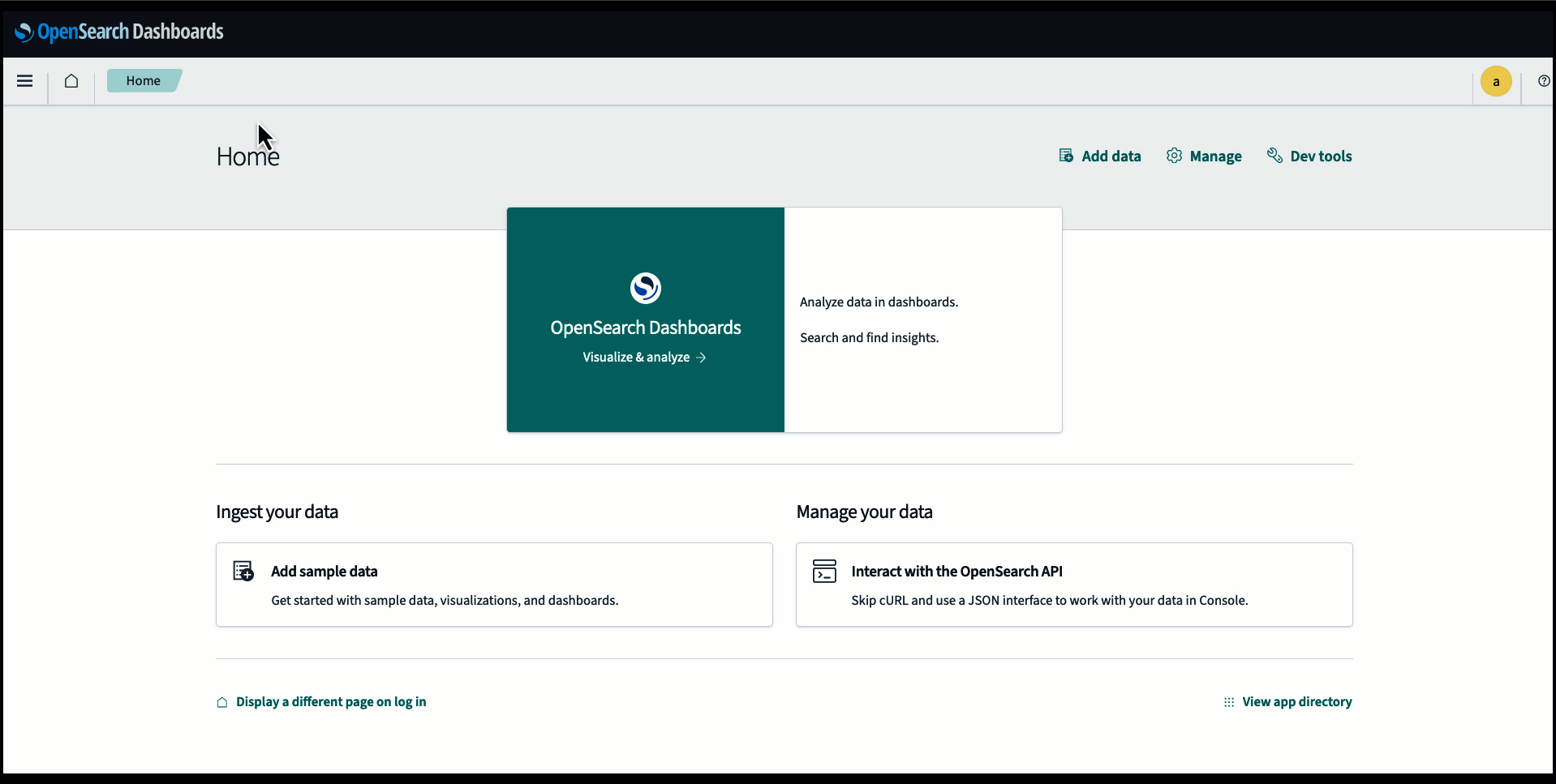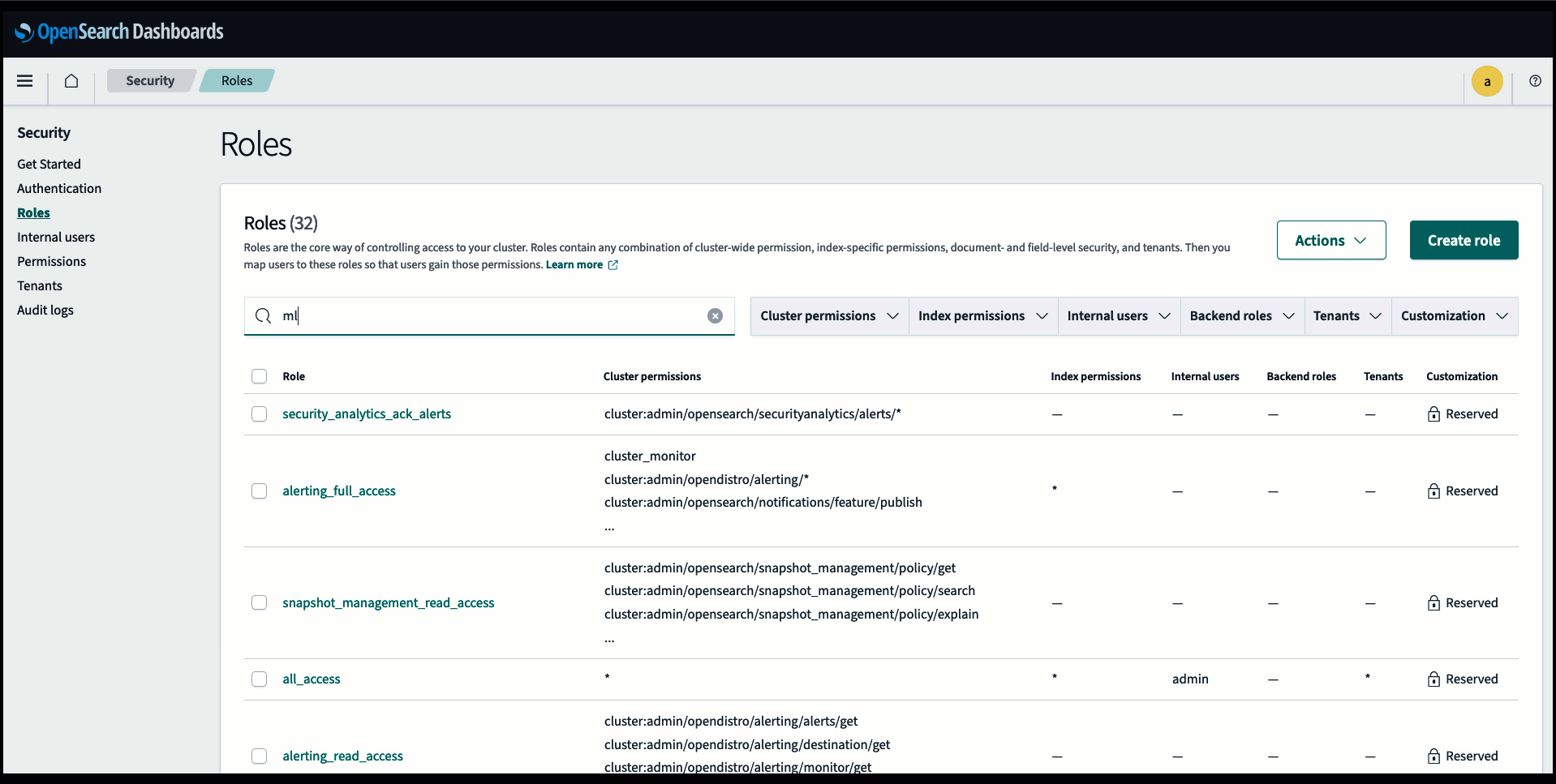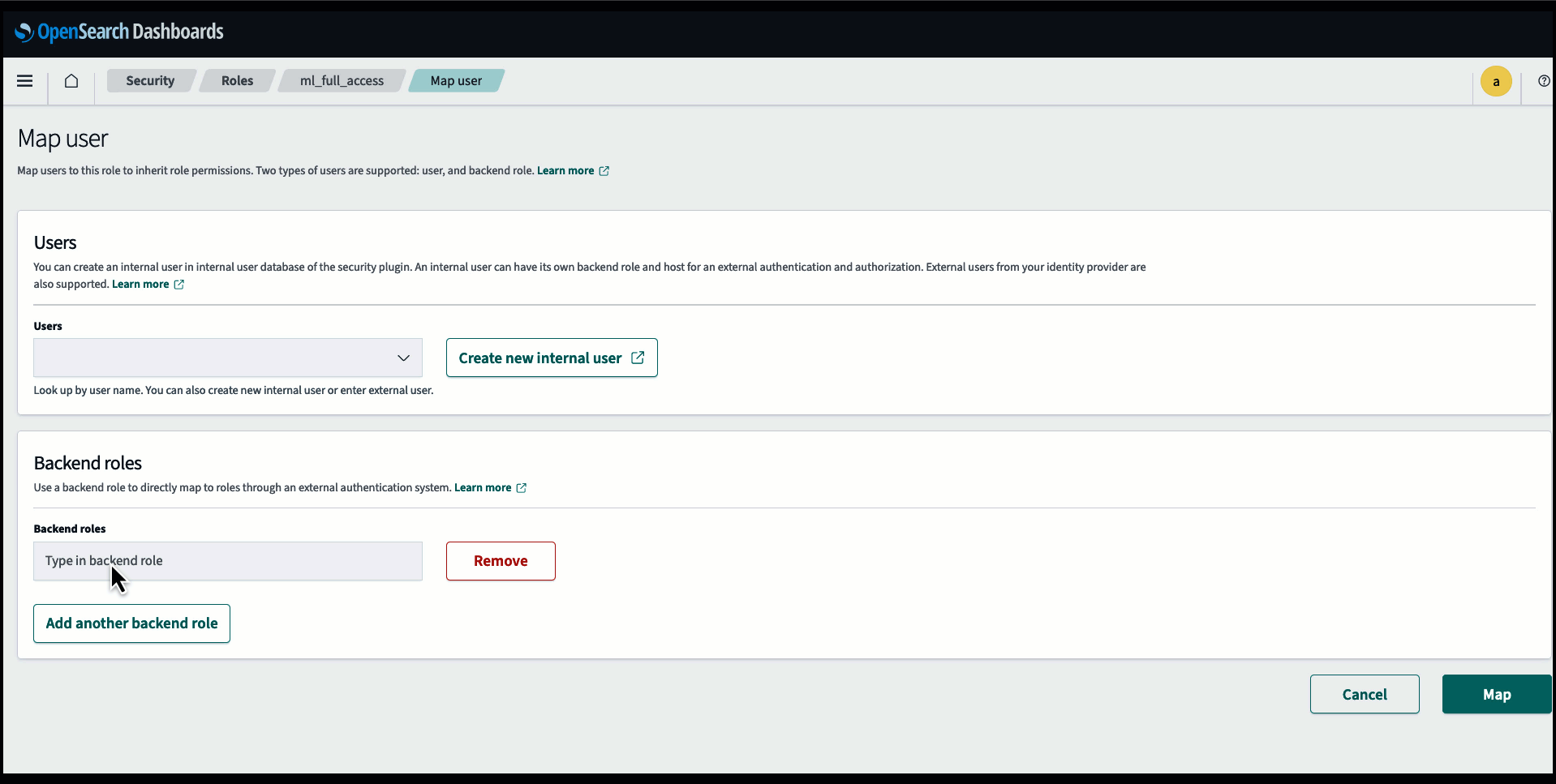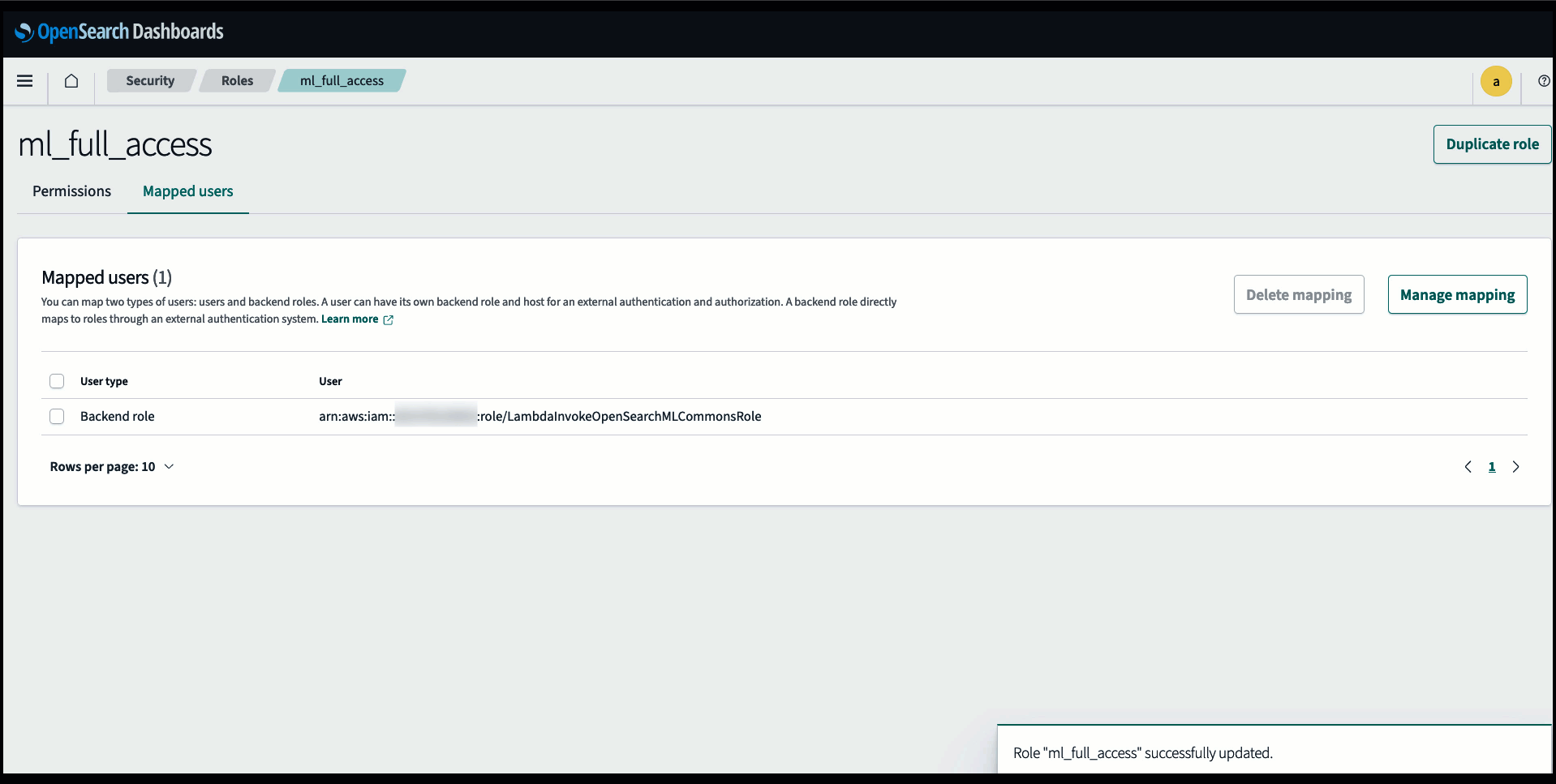
Antes de conectar o modelo por meio do console do OpenSearch Service, crie um domínio do OpenSearch Service. Mapear um Gerenciamento de acesso e identidade da AWS (IAM) função pelo nome LambdaInvokeOpenSearchMLCommonsRole como a função de back-end no ml_full_access função usando o plug-in de segurança no OpenSearch Dashboards, conforme mostrado no vídeo a seguir. O fluxo de trabalho de integrações do OpenSearch Service é pré-preenchido para usar o LambdaInvokeOpenSearchMLCommonsRole Função IAM por padrão para criar o conector entre o domínio do OpenSearch Service e o modelo implantado no SageMaker. Se você usar uma função personalizada do IAM nas integrações do console do OpenSearch Service, certifique-se de que a função personalizada esteja mapeada como a função de back-end com ml_full_access permissões antes de implantar o modelo.
Implante o modelo usando AWS CloudFormation
O vídeo a seguir demonstra as etapas para usar o console do OpenSearch Service para implantar um modelo em minutos no Amazon SageMaker e gerar o ID do modelo por meio dos conectores de IA. O primeiro passo é escolher Integrações no painel de navegação do console AWS do OpenSearch Service, que direciona para uma lista de integrações disponíveis. A integração é configurada por meio de uma UI, que solicitará as entradas necessárias.
Para configurar a integração, você só precisa fornecer o endpoint de domínio do OpenSearch Service e fornecer um nome de modelo para identificar exclusivamente a conexão do modelo. Por padrão, o modelo implanta o modelo de transformadores de frases Hugging Face, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
Quando você escolhe Criar Pilha, você será encaminhado para o Formação da Nuvem AWS console. O modelo CloudFormation implanta a arquitetura detalhada no diagrama a seguir.

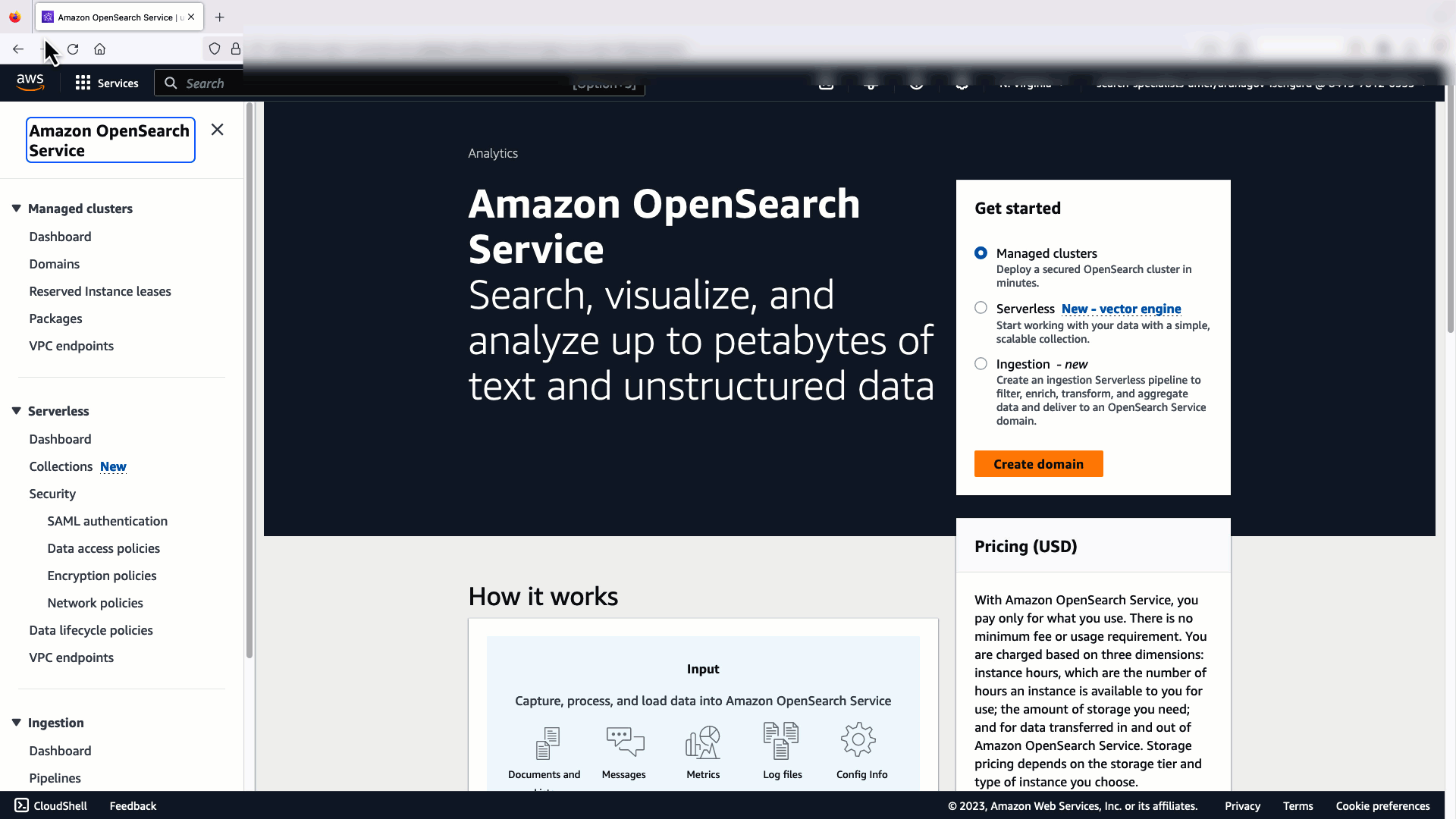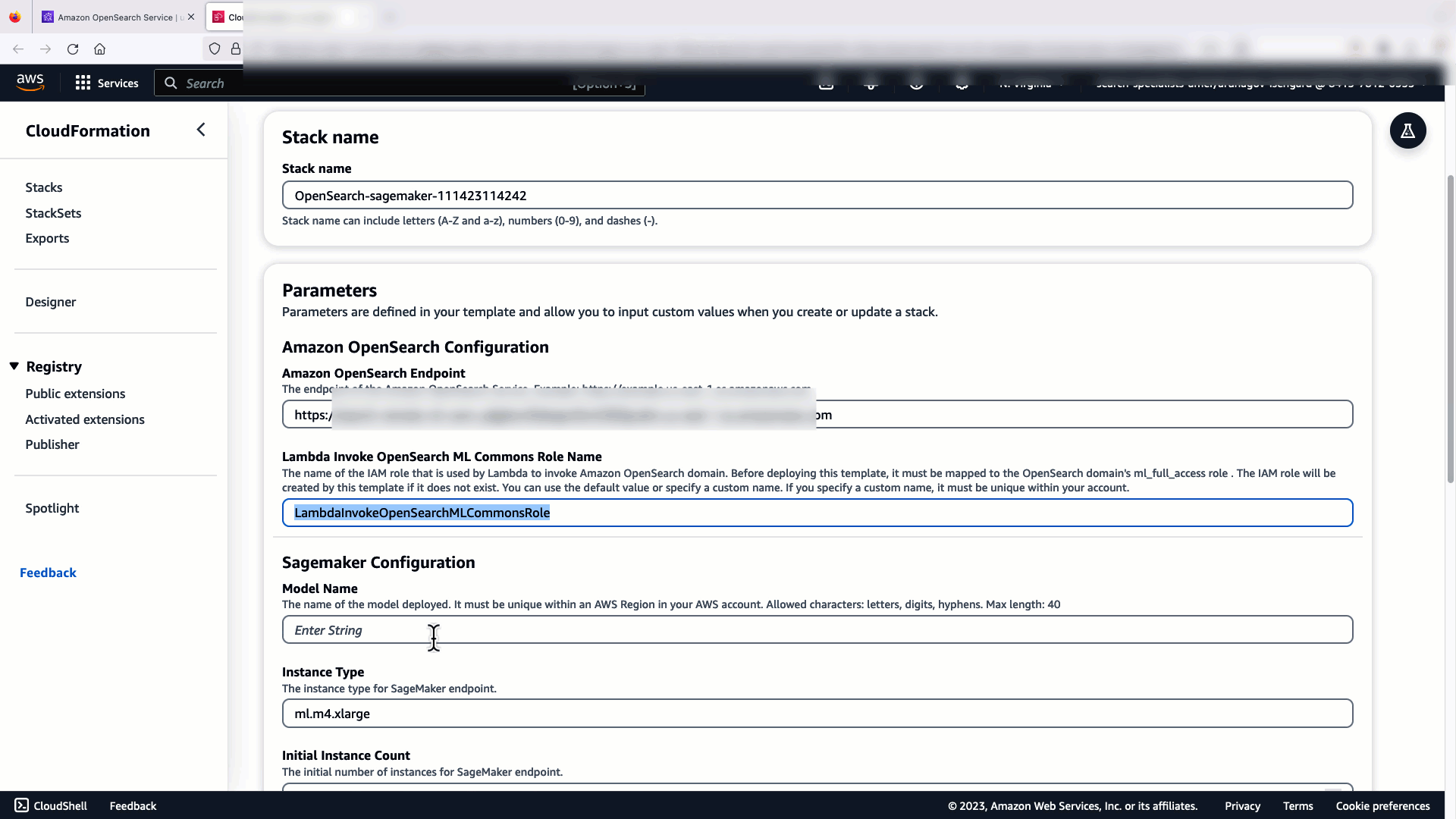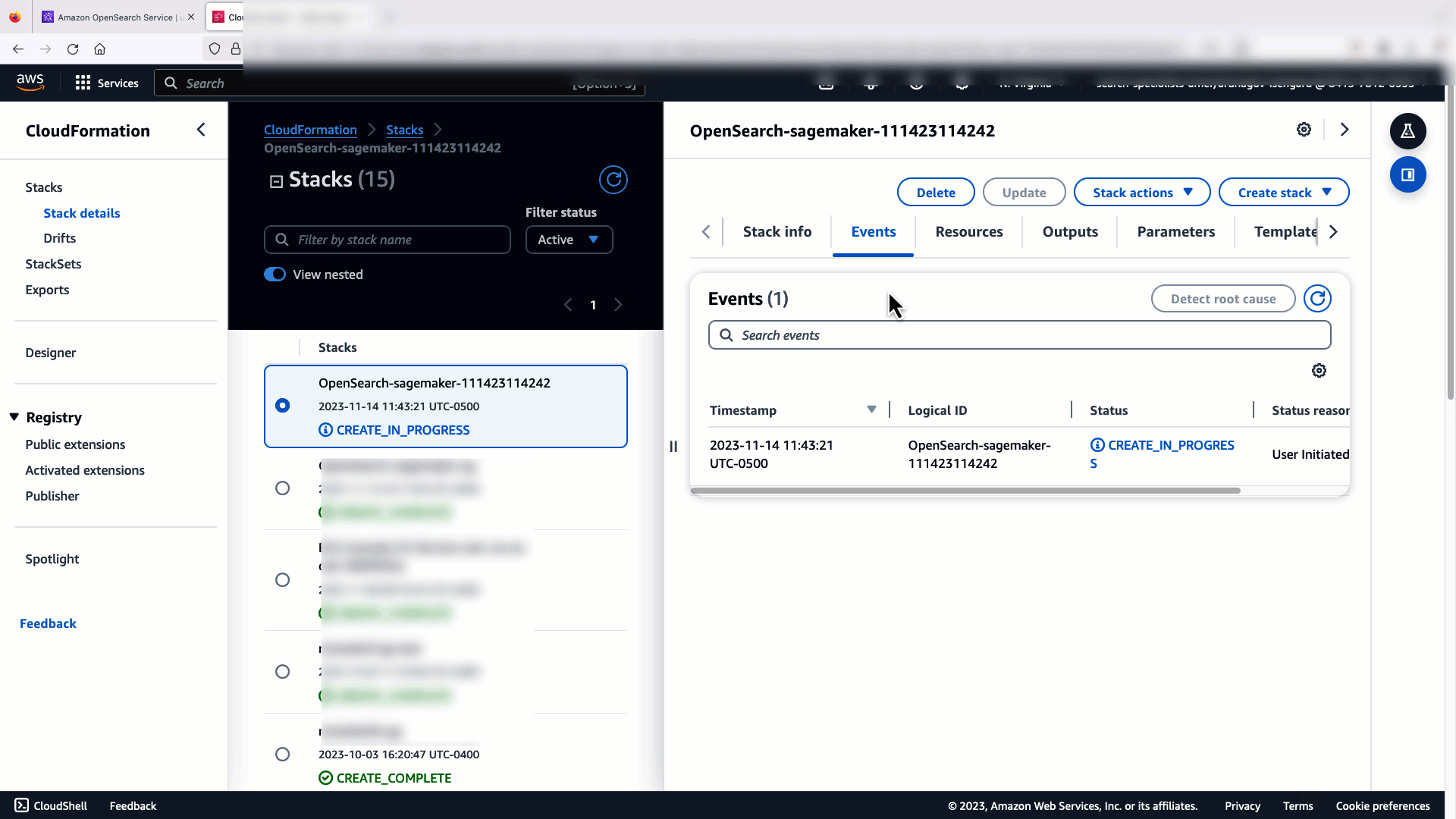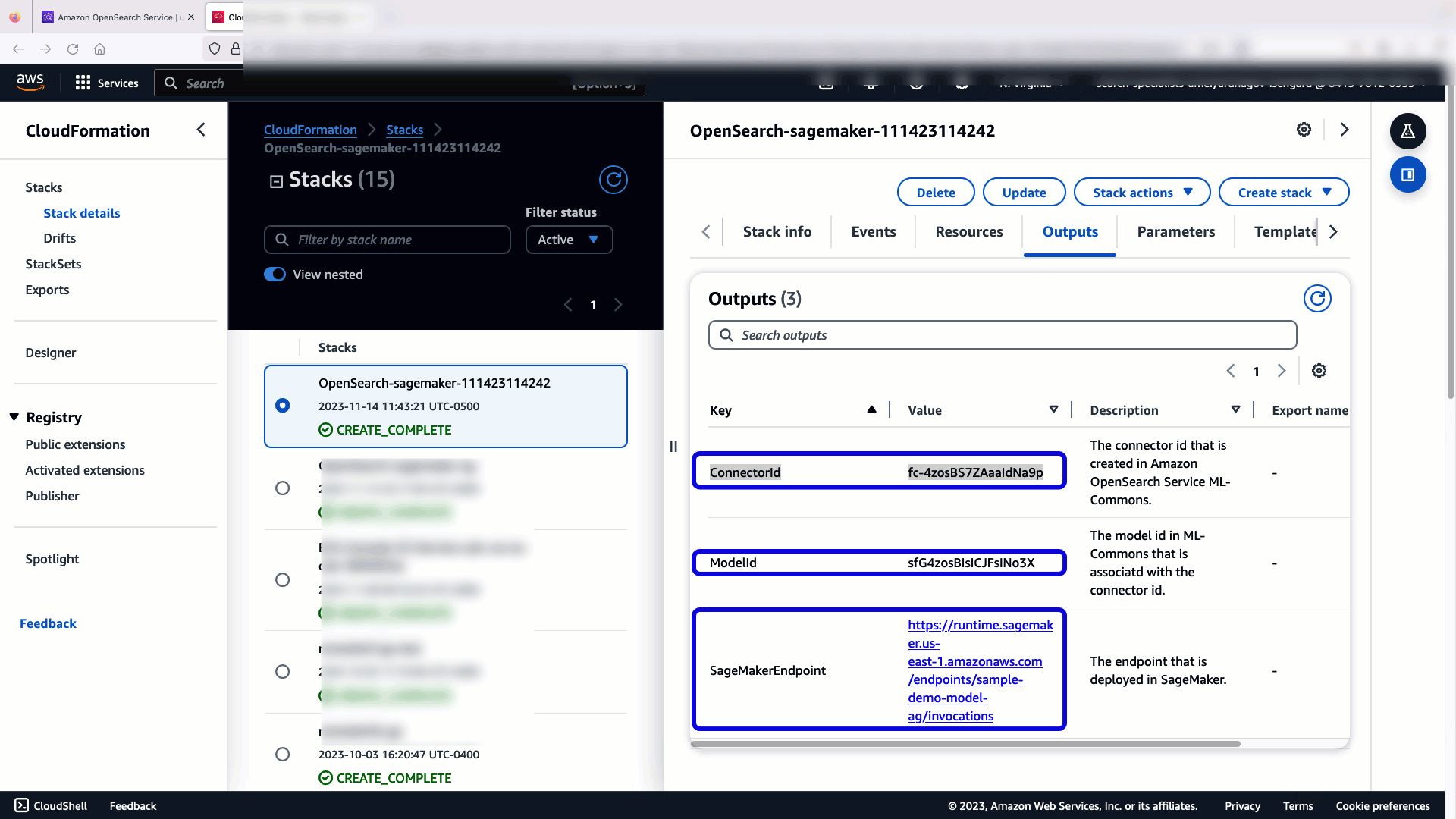
A pilha CloudFormation cria um AWS Lambda aplicativo que implanta um modelo de Serviço de armazenamento simples da Amazon (Amazon S3), cria o conector e gera o ID do modelo na saída. Você pode então usar esse ID de modelo para criar um índice semântico.
Se o modelo padrão totalmente MiniLM-L6-v2 não atender ao seu propósito, você poderá implantar qualquer modelo de incorporação de texto de sua escolha no host do modelo escolhido (SageMaker ou Amazon Bedrock), fornecendo os artefatos do modelo como um objeto S3 acessível. Alternativamente, você pode selecionar um dos seguintes modelos de linguagem pré-treinados e implante-o no SageMaker. Para obter instruções sobre como configurar seu endpoint e modelos, consulte Imagens disponíveis do Amazon SageMaker.
SageMaker é um serviço totalmente gerenciado que reúne um amplo conjunto de ferramentas para permitir ML de alto desempenho e baixo custo para qualquer caso de uso, oferecendo benefícios importantes, como monitoramento de modelo, hospedagem sem servidor e automação de fluxo de trabalho para treinamento e implantação contínuos. O SageMaker permite hospedar e gerenciar o ciclo de vida de modelos de incorporação de texto e usá-los para potencializar consultas de pesquisa semântica no OpenSearch Service. Quando conectado, o SageMaker hospeda seus modelos e o OpenSearch Service é usado para consultar com base nos resultados de inferência do SageMaker.
Visualize o modelo implantado por meio do OpenSearch Dashboards
Para verificar se o modelo CloudFormation implantou com êxito o modelo no domínio do OpenSearch Service e obter o ID do modelo, você pode usar a API REST GET do ML Commons por meio das ferramentas de desenvolvimento do OpenSearch Dashboards.
A API REST GET _plugins agora fornece APIs adicionais para visualizar também o status do modelo. O comando a seguir permite ver o status de um modelo remoto:
Como mostrado na captura de tela a seguir, um DEPLOYED status na resposta indica que o modelo foi implementado com sucesso no cluster do OpenSearch Service.

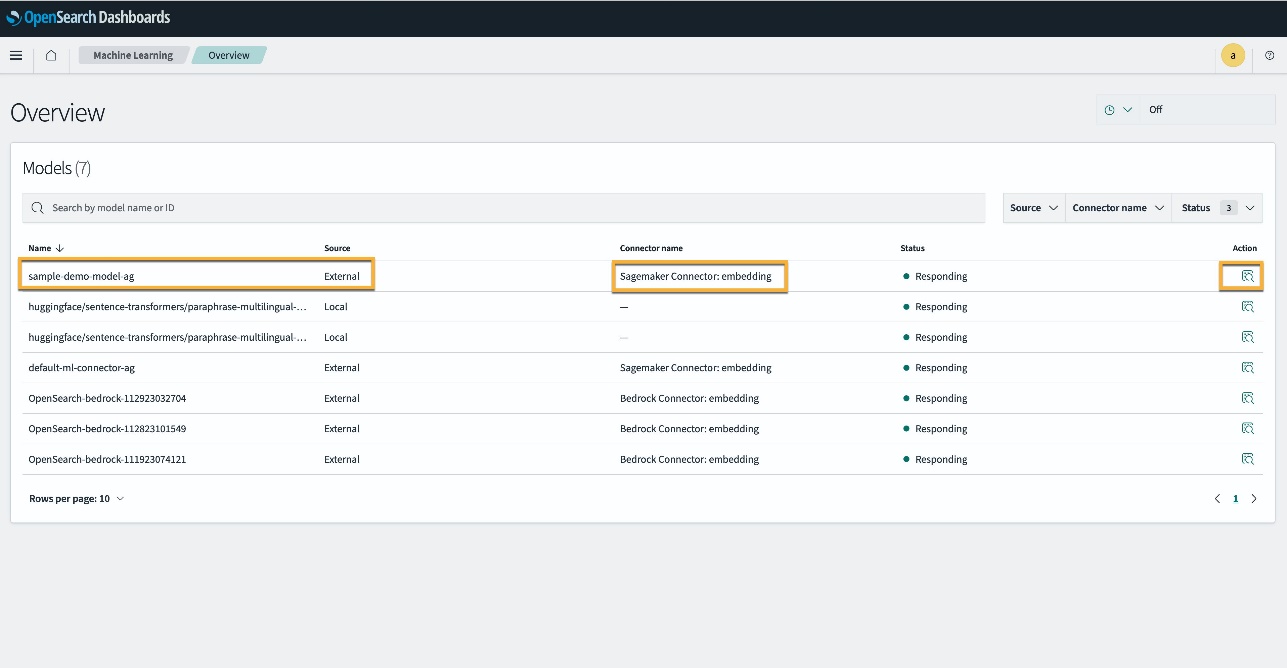
Alternativamente, você pode visualizar o modelo implantado em seu domínio do OpenSearch Service usando o Machine Learning página dos painéis do OpenSearch.

Esta página lista as informações do modelo e os status de todos os modelos implantados.

Crie o pipeline neural usando o ID do modelo
Quando o status do modelo é exibido como DEPLOYED em Dev Tools ou verde e Respondendo no OpenSearch Dashboards, você pode usar o ID do modelo para construir seu pipeline de ingestão neural. O pipeline de ingestão a seguir é executado nas ferramentas de desenvolvimento do OpenSearch Dashboards do seu domínio. Certifique-se de substituir o ID do modelo pelo ID exclusivo gerado para o modelo implantado em seu domínio.

Crie o índice de pesquisa semântica usando o pipeline neural como pipeline padrão
Agora você pode definir seu mapeamento de índice com o pipeline padrão configurado para usar o novo pipeline neural criado na etapa anterior. Certifique-se de que os campos vetoriais sejam declarados como knn_vector e as dimensões são apropriadas ao modelo implantado no SageMaker. Se você manteve a configuração padrão para implantar o modelo totalmente MiniLM-L6-v2 no SageMaker, mantenha as configurações a seguir como estão e execute o comando nas Ferramentas de Desenvolvimento.

Ingerir documentos de amostra para gerar vetores
Para esta demonstração, você pode ingerir o amostra de catálogo de produtos de demonstração de varejo para o novo semantic_demostore índice. Substitua o nome de usuário, a senha e o endpoint do domínio pelas informações do seu domínio e ingerir dados brutos no OpenSearch Service:

Valide o novo índice semantic_demostore
Agora que você ingeriu seu conjunto de dados no domínio do OpenSearch Service, valide se os vetores necessários são gerados usando uma pesquisa simples para buscar todos os campos. Valide se os campos definidos como knn_vectors tem os vetores necessários.

Compare a pesquisa lexical e a pesquisa semântica com base na pesquisa neural usando a ferramenta Comparar resultados da pesquisa
A Ferramenta Comparar resultados de pesquisa no OpenSearch Dashboards está disponível para cargas de trabalho de produção. Você pode navegar até o Compare os resultados da pesquisa página e compare os resultados da consulta entre a pesquisa lexical e a pesquisa neural configurada para usar o ID do modelo gerado anteriormente.

limpar
Você pode excluir os recursos criados seguindo as instruções desta postagem, excluindo a pilha do CloudFormation. Isso excluirá os recursos do Lambda e o bucket S3 que contêm o modelo que foi implantado no SageMaker. Conclua as seguintes etapas:
- No console do AWS CloudFormation, navegue até a página de detalhes da pilha.
- Escolha Apagar.

- Escolha Apagar para confirmar.

Você pode monitorar o progresso da exclusão da pilha no console do AWS CloudFormation.
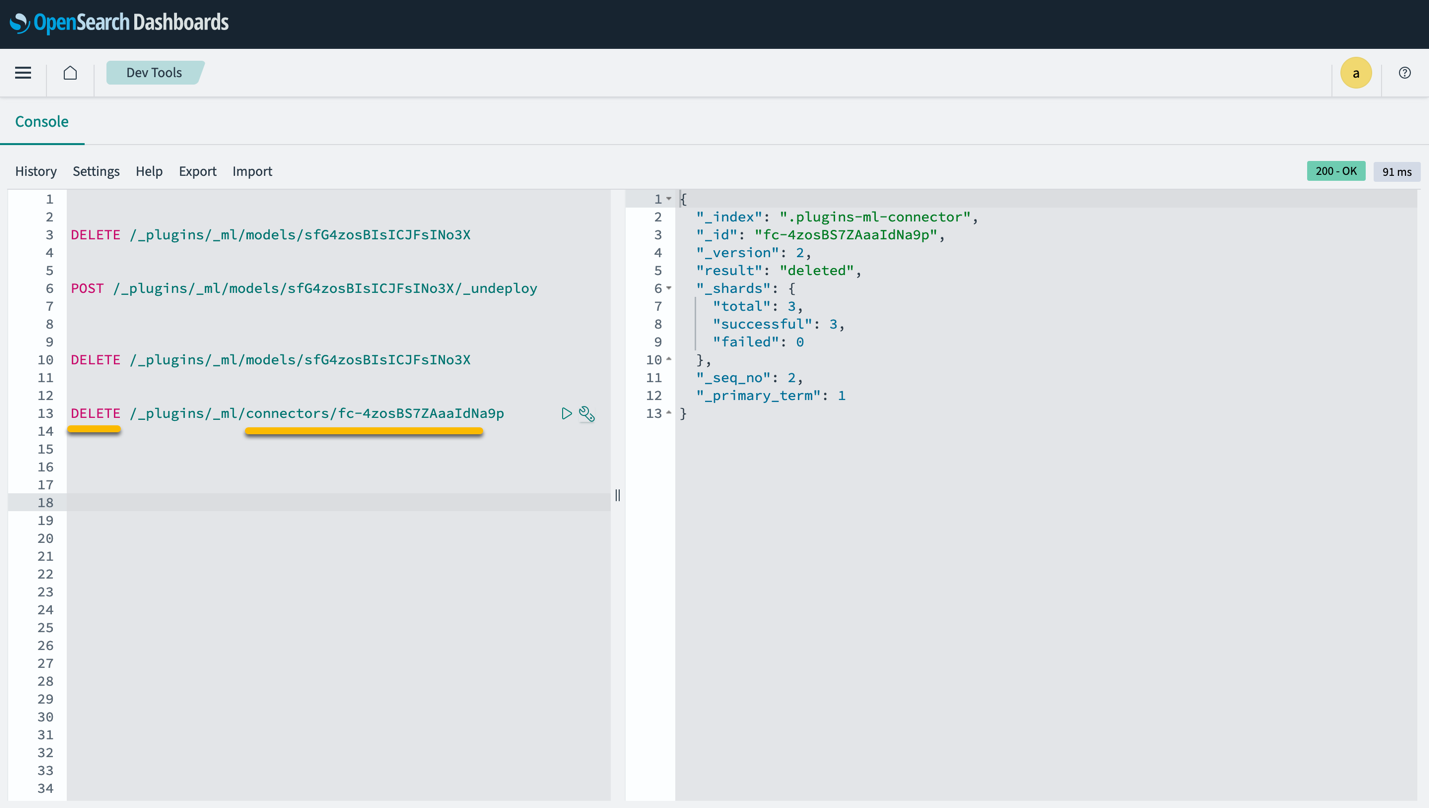
Observe que excluir a pilha do CloudFormation não exclui o modelo implantado no domínio SageMaker e o conector AI/ML criado. Isso ocorre porque esses modelos e o conector podem ser associados a vários índices no domínio. Para excluir especificamente um modelo e seu conector associado, use as APIs do modelo conforme mostrado nas capturas de tela a seguir.
Primeiro, undeploy o modelo da memória de domínio do OpenSearch Service:

Então você pode excluir o modelo do índice do modelo:

Por último, exclua o conector do índice do conector:
Conclusão
Nesta postagem, você aprendeu como implantar um modelo no SageMaker, criar o conector AI/ML usando o console do OpenSearch Service e construir o índice de pesquisa neural. A capacidade de configurar conectores AI/ML no OpenSearch Service simplifica o processo de hidratação do vetor, tornando nativas as integrações com modelos externos. Você pode criar um índice de pesquisa neural em minutos usando o pipeline de ingestão neural e a pesquisa neural que usa o ID do modelo para gerar a incorporação do vetor dinamicamente durante a ingestão e a pesquisa.
Para saber mais sobre esses conectores AI/ML, consulte Conectores de IA do Amazon OpenSearch Service para serviços da AWS, Integrações de modelos do AWS CloudFormation para pesquisa semântica e Criação de conectores para plataformas de ML de terceiros.
Sobre os autores
 Aruna Govindaraju é arquiteto de soluções especialista em Amazon OpenSearch e trabalhou com muitos mecanismos de pesquisa comerciais e de código aberto. Ela é apaixonada por pesquisa, relevância e experiência do usuário. Sua experiência em correlacionar sinais do usuário final com o comportamento do mecanismo de pesquisa ajudou muitos clientes a melhorar sua experiência de pesquisa.
Aruna Govindaraju é arquiteto de soluções especialista em Amazon OpenSearch e trabalhou com muitos mecanismos de pesquisa comerciais e de código aberto. Ela é apaixonada por pesquisa, relevância e experiência do usuário. Sua experiência em correlacionar sinais do usuário final com o comportamento do mecanismo de pesquisa ajudou muitos clientes a melhorar sua experiência de pesquisa.
 Dagney Braun é gerente de produto principal da AWS com foco em OpenSearch.
Dagney Braun é gerente de produto principal da AWS com foco em OpenSearch.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- :tem
- :é
- :não
- $UP
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- habilidade
- Sobre
- Acesso
- acessível
- Adicional
- AI
- AI / ML
- Todos os Produtos
- permite
- tb
- alternativas
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- an
- e
- qualquer
- api
- APIs
- Aplicação
- apropriado
- arquitetura
- SOMOS
- AS
- associado
- At
- Automação
- disponível
- AWS
- Formação da Nuvem AWS
- Backend
- baseado
- BE
- Porque
- comportamento
- Benefícios
- entre
- ambos
- Traz
- amplo
- construir
- Prédio
- by
- CAN
- casas
- casos
- catálogo
- escolha
- Escolha
- escolhido
- Agrupar
- comercial
- Commons
- comparar
- completar
- complexidade
- Configuração
- configurado
- configurando
- Confirmar
- conectado
- Conexão de
- da conexão
- cônsul
- não contenho
- continuar
- contínuo
- correlacionando
- crio
- criado
- cria
- Atualmente
- personalizadas
- Clientes
- painéis
- dados,
- Padrão
- definir
- definido
- entregando
- Demo
- demonstrar
- demonstra
- implantar
- implantado
- Implantação
- desenvolvimento
- implanta
- descrição
- detalhado
- detalhes
- Dev
- Dimensão
- dimensões
- INSTITUCIONAIS
- Não faz
- domínio
- durante
- cada
- Mais cedo
- sem esforço
- ou
- embutindo
- permitir
- Ponto final
- Motor
- Motores
- garantir
- Éter (ETH)
- exemplo
- vasta experiência
- experiência
- externo
- Rosto
- facilita
- Característica
- Campos
- Encontre
- Primeiro nome
- focado
- seguinte
- Escolha
- Quadro
- da
- totalmente
- gerar
- gerado
- gera
- ter
- gif
- GitHub
- Verde
- Cresça:
- guia
- Ter
- ajudou
- sua experiência
- alta performance
- hospedeiro
- hospedagem
- anfitriões
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- http
- HTTPS
- Abraçando o Rosto
- hidratação
- IAM
- ID
- identificar
- Identidade
- if
- melhorar
- in
- índice
- índices
- indicam
- INFORMAÇÕES
- inputs
- em vez disso
- instruções
- integrar
- integração
- integrações
- para dentro
- Introdução
- IT
- ESTÁ
- jpg
- json
- Guarda
- Chave
- língua
- lançamento
- APRENDER
- aprendido
- aprendizagem
- wifecycwe
- Lista
- listas
- baixo custo
- máquina
- aprendizado de máquina
- fazer
- Fazendo
- gerencia
- gerenciados
- Gerente
- muitos
- mapa,
- mapeamento
- Memória
- método
- minutos
- ML
- modelo
- modelos
- Monitore
- monitoração
- mais
- muito
- múltiplo
- devo
- nome
- nativo
- Navegar
- Navegação
- necessário
- você merece...
- Neural
- Novo
- agora
- objeto
- of
- on
- ONE
- só
- aberto
- open source
- or
- Outros
- saída
- página
- pão
- apaixonado
- Senha
- permissões
- oleoduto
- platão
- Inteligência de Dados Platão
- PlatãoData
- plug-in
- Publique
- poder
- alimentado
- anterior
- Diretor
- Prévio
- processo
- processadores
- Produto
- gerente de produto
- Produção
- Progresso
- Propriedades
- fornecer
- fornece
- fornecendo
- propósito
- consultas
- Cru
- dados não tratados
- recomendar
- referir
- remoto
- removendo
- substituir
- requeridos
- Recursos
- resposta
- DESCANSO
- Resultados
- varejo
- retida
- retorno
- Tipo
- rotas
- Execute
- sábio
- screenshots
- Pesquisar
- motor de busca
- Mecanismos de busca
- segurança
- Vejo
- selecionar
- servir
- Serverless
- serviço
- Serviços
- conjunto
- Configurações
- ela
- mostrando
- Shows
- sinais
- simples
- simplifica
- simplificar
- desde
- Soluções
- fonte
- especialista
- especificamente
- pilha
- Comece
- Status
- Passo
- Passos
- armazenamento
- entraram com sucesso
- tal
- Suportado
- certo
- modelo
- texto
- que
- A
- deles
- Eles
- então
- assim
- Este
- De terceiros
- isto
- Através da
- para
- juntos
- ferramentas
- Training
- Transformação
- Tradução
- verdadeiro
- tipo
- ui
- único
- unicamente
- usar
- caso de uso
- usava
- Utilizador
- Experiência do Usuário
- utilização
- VALIDAR
- verificar
- versão
- via
- Vídeo
- Ver
- anda
- foi
- we
- web
- serviços web
- quando
- qual
- precisarão
- de
- dentro
- trabalhou
- de gestão de documentos
- automação de fluxo de trabalho
- Você
- investimentos
- zefirnet