SmugMug opera duas grandes plataformas de fotos online, SmugMug e Flickr, permitindo que mais de 100 milhões de clientes armazenem, pesquisem, compartilhem e vendam com segurança dezenas de bilhões de fotos. Os clientes que enviaram e pesquisaram décadas de fotos ajudaram a transformar a pesquisa em uma infraestrutura crítica, crescendo de forma constante desde que o SmugMug usou pela primeira vez Amazon CloudSearch em 2012, seguido por Serviço Amazon OpenSearch desde 2018, após atingir bilhões de documentos e terabytes de armazenamento de pesquisa.
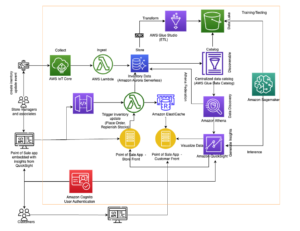
Aqui, Lee Shepherd, engenheiro de equipe do SmugMug, compartilha a arquitetura de pesquisa do SmugMug usada para publicar, preencher e espelhar o tráfego ao vivo para vários clusters. SmugMug usa esses pipelines para avaliar, validar e migrar para novas configurações, incluindo instâncias r6gd.2xlarge baseadas em Graviton de i3.2xlarge, juntamente com testes Amazon OpenSearch sem servidor. Cobrimos três pipelines usados para publicação, preenchimento e consulta sem introduzir padrões de tráfego pontiagudos e irrealistas e sem qualquer impacto nos serviços de produção.
Existem duas peças arquitetônicas principais críticas para o processo:
- Uma fonte durável de verdade para dados de índice. É a melhor prática e parte de nossa estratégia de backup para ter um armazenamento durável além do índice OpenSearch, e Amazon DynamoDB fornece escalabilidade e integração com AWS Lambda isso simplifica muito o processo. Usamos o DynamoDB para outros serviços que não são de pesquisa, então essa foi uma escolha natural.
- Uma função Lambda para publicar dados da fonte da verdade no OpenSearch. Usando apelidos de função ajuda a executar várias configurações da mesma função Lambda ao mesmo tempo e é fundamental para manter os dados sincronizados.
Publishing
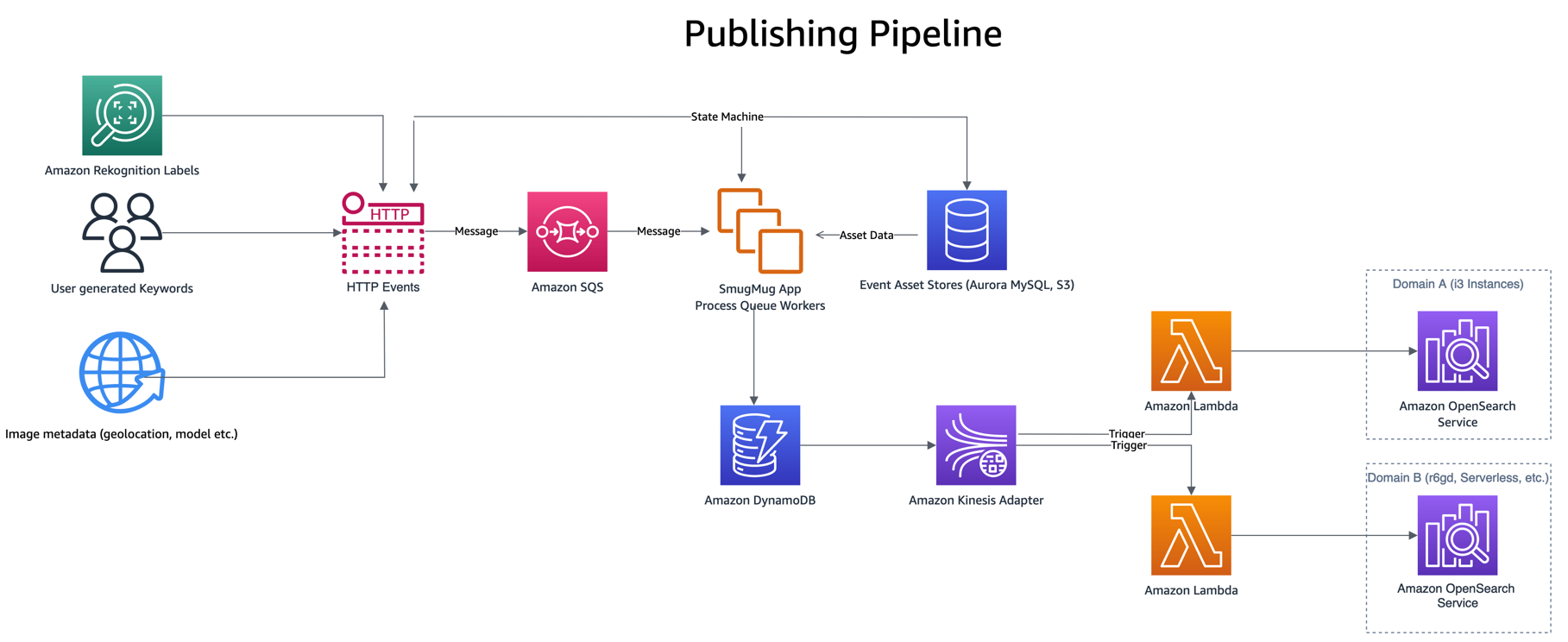
O pipeline de publicação é orientado a partir de eventos como a inserção de palavras-chave ou legendas pelo usuário, novos uploads ou detecção de rótulos por meio de Reconhecimento da Amazônia. Esses eventos são processados, combinando dados de alguns outros armazenamentos de ativos, como Edição compatível com Amazon Aurora MySQL e Serviço de armazenamento simples da Amazon (Amazon S3), antes de gravar um único item no DynamoDB.
Escrever no DynamoDB invoca uma função de publicação Lambda, por meio do Adaptador DynamoDB Streams Kinesis, que pega um lote de itens atualizados do DynamoDB e os indexa no OpenSearch. Há outros benefícios em usar o DynamoDB Streams Kinesis Adapter, como a redução do número de Lambdas simultâneos necessários.
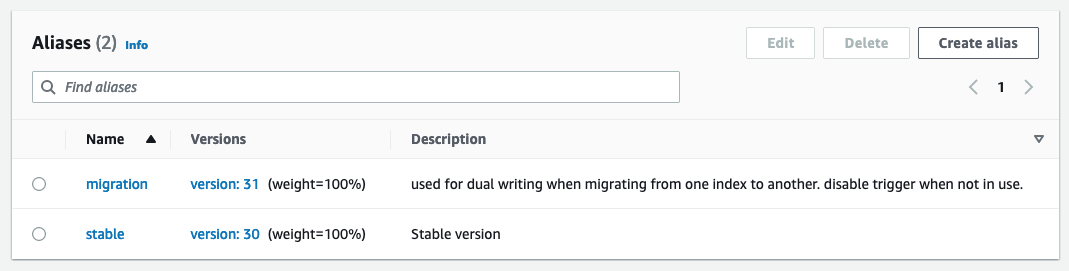
A função de publicação do Lambda usa variáveis de ambiente para determinar em qual domínio e índice do OpenSearch publicar. Um alias de produção é configurado para gravar no domínio de produção do OpenSearch, fora da tabela do DynamoDB ou do Kinesis Stream
Ao testar novas configurações ou migrar, um alias de migração é configurado para gravar no novo domínio OpenSearch, mas usa o mesmo gatilho que o alias de produção. Isso permite a indexação dupla de dados para ambos os domínios do OpenSearch Service simultaneamente.
Aqui está um exemplo do esquema de tabela do DynamoDB:
O valor 'LastUpdated' é usado como a versão do documento durante a indexação, permitindo que o OpenSearch rejeite quaisquer atualizações fora de ordem.
Preenchimento
Agora que as alterações estão sendo publicadas em ambos os domínios, o novo domínio (índice) precisa ser preenchido com dados históricos. Para preencher um índice recém-criado, uma combinação de Serviço de fila simples da Amazon (Amazon SQS) e o DynamoDB é usado. Um script preenche uma fila SQS com mensagens que contêm instruções para varredura paralela um segmento da tabela DynamoDB.
A fila SQS inicia uma função Lambda que lê as instruções da mensagem, busca um lote de itens do segmento correspondente da tabela DynamoDB e os grava em um índice OpenSearch. Novas mensagens são gravadas na fila SQS para acompanhar o progresso do segmento. Após a conclusão do segmento, nenhuma mensagem será gravada na fila SQS e o processo será interrompido.
A simultaneidade é determinada pelo número de segmentos, com controles adicionais fornecidos pela escalabilidade de simultaneidade do Lambda. O SmugMug é capaz de indexar mais de 1 bilhão de documentos por hora em sua configuração OpenSearch, sem causar impacto no domínio de produção.
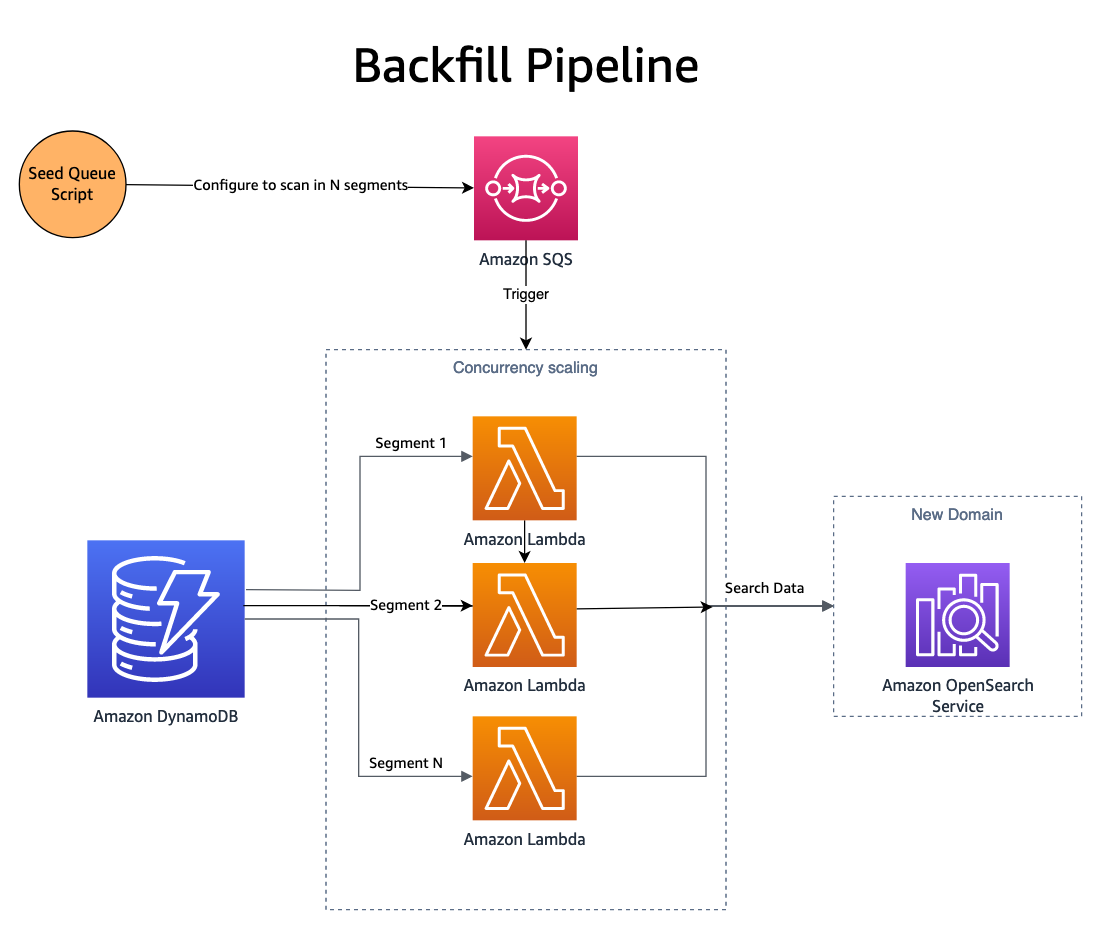
Um script NodeJS baseado em AWS-SDK é usado para propagar a fila SQS. Aqui está um trecho das opções do script de configuração do SQS:
Junto com o formato da mensagem SQS resultante:
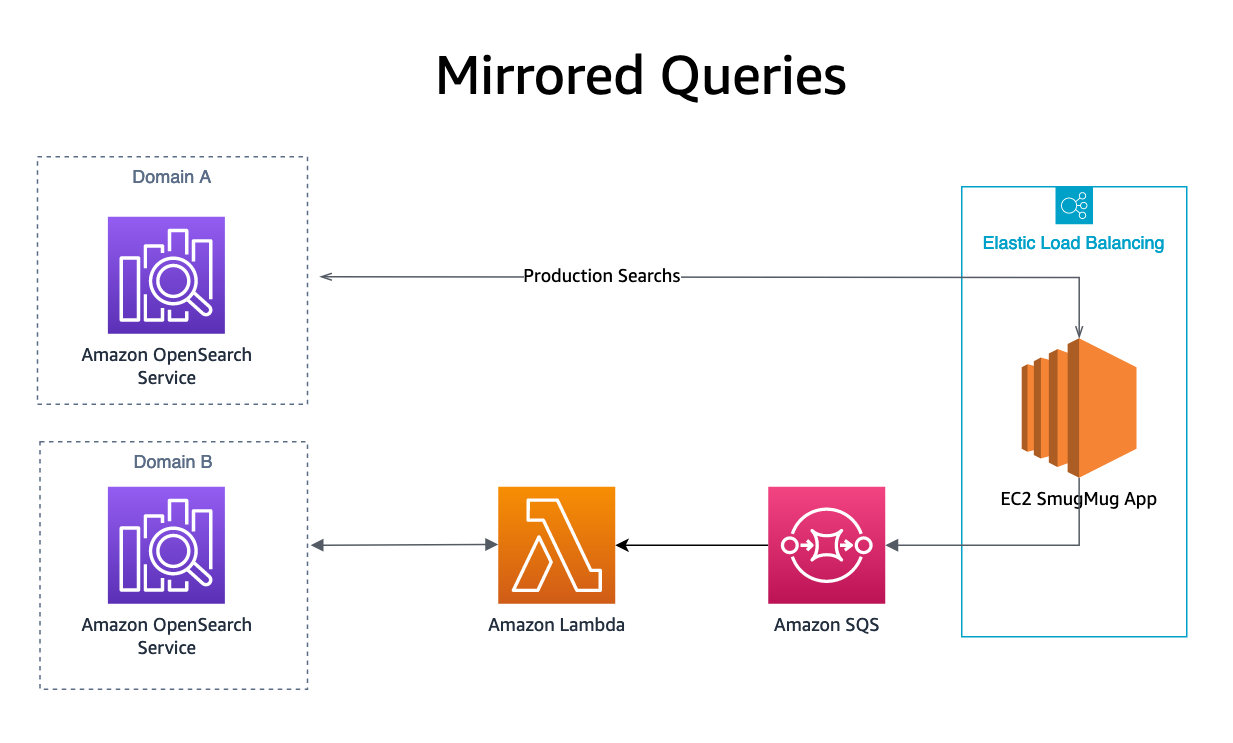
Espelhando
Por último, nosso consulta de pesquisa espelhada os resultados são executados enviando uma consulta OpenSearch para uma fila SQS, além de nosso domínio de produção. A fila SQS inicia uma função Lambda que reproduz a consulta no domínio de réplica. Os resultados da pesquisa dessas solicitações não são enviados a nenhum usuário, mas permitem replicar a carga de produção no serviço OpenSearch em teste sem impacto nos sistemas de produção ou nos clientes.
Conclusão
Ao avaliar um novo domínio ou configuração do OpenSearch, as principais métricas nas quais estamos interessados são o desempenho da latência de consulta, ou seja, as latências obtidas (latências por tempo) e, mais importante, as latências para pesquisa. Em nossa mudança para o Graviton R6gd, vimos latências P40-P50 cerca de 99% mais baixas, junto com ganhos semelhantes no uso da CPU em comparação com o i3 (ignorando os custos mais baixos do Graviton). Outro benefício bem-vindo foi a pressão de memória da JVM mais previsível e monitorável com as alterações na coleta de lixo decorrentes da adição do G1GC no R6gd e em outras novas instâncias.
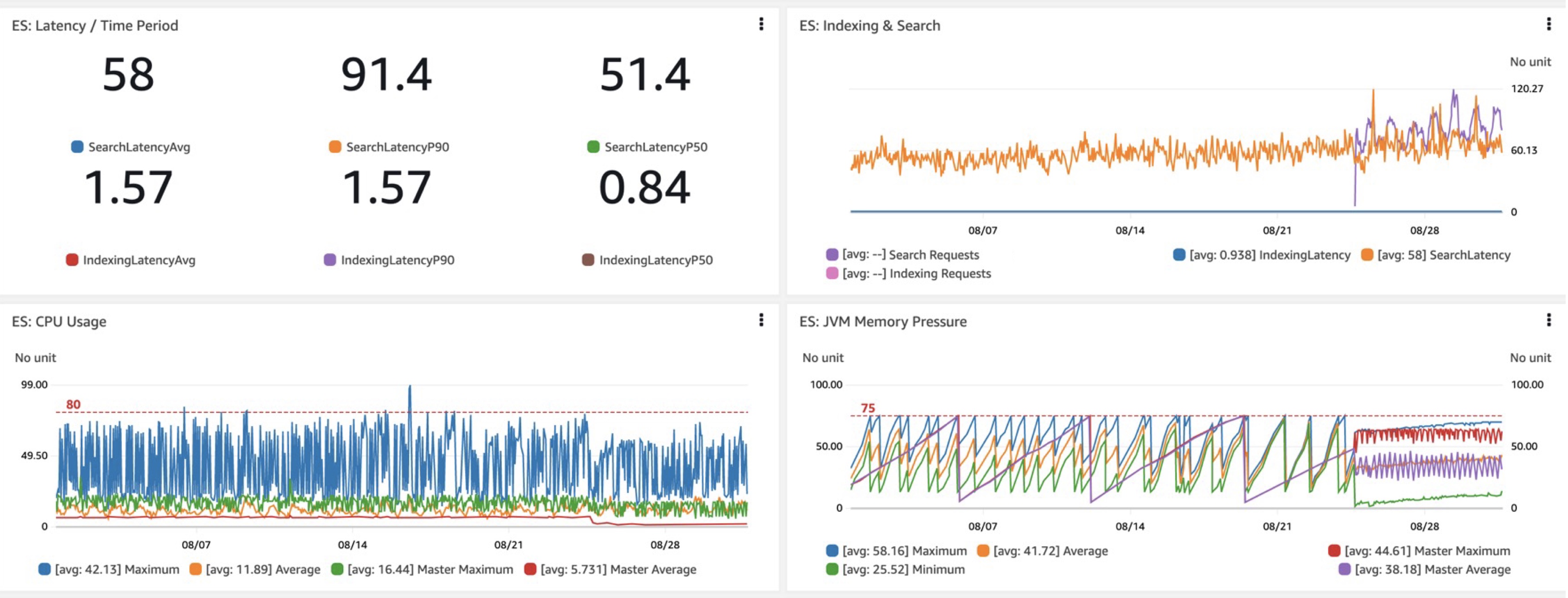
Usando esse pipeline, também estamos testando o OpenSearch Serverless e encontrando seus melhores casos de uso. Estamos entusiasmados com esse serviço e pretendemos ter uma arquitetura totalmente sem servidor com o tempo. Fique atento aos resultados.
Sobre os autores
Lee pastor é engenheiro de software da equipe SmugMug
Aydn Bekirov é gerente técnico principal de contas da Amazon Web Services
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/smugmugs-durable-search-pipelines-for-amazon-opensearch-service/
- :é
- :não
- 1
- 100
- 12
- 14
- 20
- 2012
- 2018
- 40
- 7
- 9
- a
- Capaz
- Sobre
- Conta
- adicionado
- Adição
- Adicional
- Depois de
- permitir
- Permitindo
- juntamente
- tb
- Amazon
- Amazon Web Services
- an
- e
- Outro
- qualquer
- arquitetônico
- arquitetura
- SOMOS
- AS
- ativo
- At
- aurora
- AWS
- backup
- baseado
- BE
- antes
- ser
- referência
- beneficiar
- Benefícios
- MELHOR
- Pós
- bilhão
- bilhões
- ambos
- mas a
- by
- legendas
- Alterações
- coleção
- combinação
- combinando
- comparado
- compatível
- Completa
- concorrente
- Configuração
- configurado
- não contenho
- controles
- Correspondente
- custos
- cobrir
- CPU
- criado
- crítico
- Infraestrutura crítica
- Clientes
- dados,
- décadas
- Detecção
- Determinar
- determinado
- documento
- INSTITUCIONAIS
- domínio
- domínios
- dirigido
- cada
- permite
- permitindo
- Ponto final
- engenheiro
- entrar
- inteiramente
- Meio Ambiente
- Éter (ETH)
- avaliação
- eventos
- exemplo
- animado
- poucos
- Campos
- descoberta
- Primeiro nome
- caber
- seguido
- Escolha
- formato
- da
- totalmente
- função
- Ganhos
- Crescente
- Ter
- altura
- ajudou
- ajuda
- histórico
- hora
- HTML
- http
- HTTPS
- i
- i3
- ID
- Impacto
- importante
- in
- Incluindo
- índice
- índices
- Infraestrutura
- instâncias
- instruções
- integração
- pretender
- interessado
- para dentro
- introduzindo
- invoca
- Unid
- iteração
- ESTÁ
- se
- jpg
- Guarda
- manutenção
- Chave
- palavras-chave
- O rótulo
- grande
- Latência
- lança
- Lee
- como
- viver
- carregar
- lote
- diminuir
- a Principal
- Memória
- mensagem
- mensagens
- Métrica
- migrado
- migrando
- migração
- milhão
- milhões de clientes
- espelho
- mais
- a maioria
- mover
- múltiplo
- MySQL
- nome
- nomeadamente
- natural
- Cria
- Novo
- recentemente
- Próximo
- não
- número
- of
- WOW!
- on
- online
- opera
- Opções
- Opta
- or
- Outros
- A Nossa
- Paralelo
- parte
- padrões
- para
- por cento
- atuação
- foto
- Fotos
- peças
- oleoduto
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- Previsível
- pressão
- anterior
- Diretor
- processo
- processado
- Produção
- Progresso
- fornecido
- fornece
- publicar
- publicado
- Publishing
- chegando
- redução
- responder
- pedidos
- requeridos
- resultando
- Resultados
- Execute
- seguramente
- mesmo
- serra
- AMPLIAR
- dimensionamento
- escrita
- Pesquisar
- pesquisar
- semente
- segmento
- segmentos
- vender
- envio
- enviei
- Serverless
- serviço
- Serviços
- Partilhar
- ações
- semelhante
- simples
- simultaneamente
- desde
- solteiro
- fragmento
- So
- Software
- fonte
- Staff
- ficar
- constantemente
- Pára
- armazenamento
- loja
- lojas
- Estratégia
- córregos
- tal
- sistemas
- mesa
- toma
- Dados Técnicos:
- dezenas
- teste
- ensaio
- do que
- que
- A
- A fonte
- deles
- Eles
- Lá.
- Este
- isto
- três
- Através da
- tempo
- para
- levou
- pista
- tráfego
- desencadear
- Verdade
- VIRAR
- dois
- para
- Atualizada
- Atualizações
- Upload
- URL
- Uso
- usar
- casos de uso
- usava
- Utilizador
- usos
- utilização
- VALIDAR
- valor
- versão
- muito
- foi
- we
- web
- serviços web
- boas-vindas
- O Quê
- quando
- enquanto
- de
- sem
- escrever
- escrita
- escrito
- zefirnet
- zero