By David Wendt e Gregório Kimball
O processamento eficiente de dados de string é vital para muitos aplicativos de ciência de dados. Para extrair informações valiosas de dados de string, RAPIDS libcudf fornece ferramentas poderosas para acelerar as transformações de dados de string. libcudf é uma biblioteca C++ GPU DataFrame usada para carregar, juntar, agregar e filtrar dados.
Na ciência de dados, os dados de string representam fala, texto, sequências genéticas, registro e muitos outros tipos de informações. Ao trabalhar com dados de string para aprendizado de máquina e engenharia de recursos, os dados devem ser frequentemente normalizados e transformados antes de serem aplicados a casos de uso específicos. A libcudf fornece APIs de uso geral, bem como utilitários do lado do dispositivo para permitir uma ampla gama de operações de string personalizadas.
Este post demonstra como transformar habilmente colunas de strings com a API de uso geral libcudf. Você obterá novos conhecimentos sobre como desbloquear desempenho máximo usando kernels personalizados e utilitários do lado do dispositivo libcudf. Esta postagem também mostra exemplos de como gerenciar melhor a memória da GPU e construir colunas libcudf com eficiência para acelerar suas transformações de string.
libcudf armazena dados de string na memória do dispositivo usando Formato de seta, que representa colunas de strings como duas colunas filhas: chars and offsets (Figura 1).
A chars A coluna contém os dados da string como bytes de caracteres codificados em UTF-8 que são armazenados continuamente na memória.
A offsets A coluna contém uma sequência crescente de números inteiros que são posições de byte que identificam o início de cada string individual dentro da matriz de dados chars. O elemento de deslocamento final é o número total de bytes na coluna chars. Isso significa o tamanho de uma string individual na linha i é definido como (offsets[i+1]-offsets[i]).
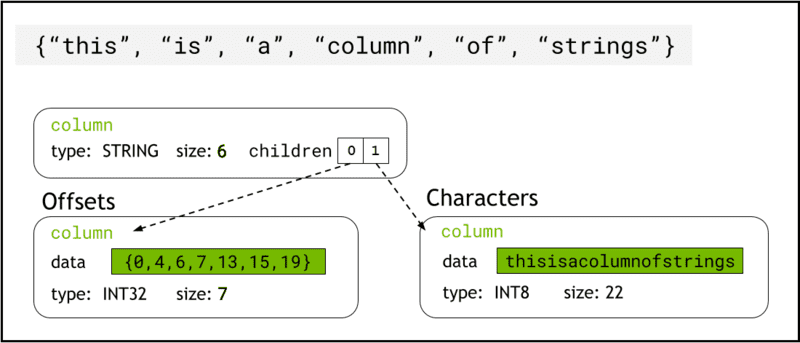 Figura 1. Esquema mostrando como o formato Arrow representa colunas de strings com
Figura 1. Esquema mostrando como o formato Arrow representa colunas de strings com chars e offsets colunas filhas
Para ilustrar uma transformação de string de exemplo, considere uma função que recebe duas colunas de strings de entrada e produz uma coluna de strings de saída editada.
Os dados de entrada têm o seguinte formato: uma coluna “nomes” contendo nomes e sobrenomes separados por um espaço e uma coluna “visibilidades” contendo o status de “público” ou “privado”.
Propomos a função “redact” que opera nos dados de entrada para produzir dados de saída que consistem na primeira inicial do sobrenome seguida de um espaço e o primeiro nome completo. No entanto, se a coluna de visibilidade correspondente for "privada", a string de saída deve ser totalmente redigida como "X X".
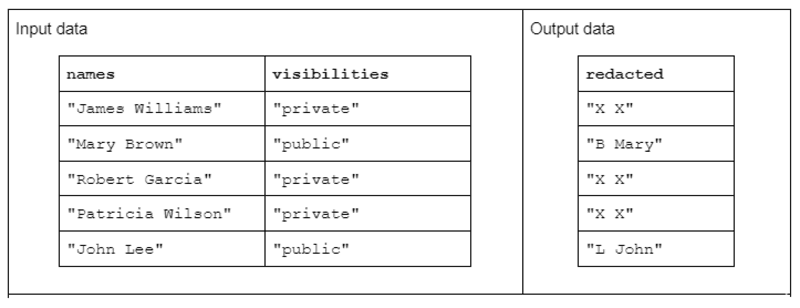 Tabela 1. Exemplo de uma transformação de string “redigida” que recebe nomes e colunas de strings de visibilidade como entrada e dados parcial ou totalmente editados como saída
Tabela 1. Exemplo de uma transformação de string “redigida” que recebe nomes e colunas de strings de visibilidade como entrada e dados parcial ou totalmente editados como saída
Primeiro, a transformação de string pode ser realizada usando o API de strings libcudf. A API de uso geral é um excelente ponto de partida e uma boa linha de base para comparar o desempenho.
As funções da API operam em uma coluna inteira de strings, iniciando pelo menos um kernel por função e atribuindo um thread por string. Cada thread lida com uma única linha de dados em paralelo na GPU e gera uma única linha como parte de uma nova coluna de saída.
Para concluir a função de exemplo de redação usando a API de uso geral, siga estas etapas:
- Converta a coluna de strings “visibilidades” em uma coluna booleana usando
contains - Crie uma nova coluna de strings a partir da coluna de nomes copiando “XX” sempre que a entrada da linha correspondente na coluna booleana for “false”
- Divida a coluna “redigido” em colunas de nome e sobrenome
- Corte o primeiro caractere dos sobrenomes como as iniciais do sobrenome
- Construa a coluna de saída concatenando a última coluna de iniciais e a coluna de nomes com separador de espaço (” “).
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
Essa abordagem leva cerca de 3.5 ms em um A6000 com 600 mil linhas de dados. Este exemplo usa contains, copy_if_else, split, slice_strings e concatenate para realizar uma transformação de string personalizada. Uma análise de perfil com Sistemas Nsight mostra que o split função leva mais tempo, seguida por slice_strings e concatenate.
A Figura 2 mostra os dados de criação de perfil do Nsight Systems do exemplo redact, mostrando o processamento de string de ponta a ponta em até ~600 milhões de elementos por segundo. As regiões correspondem às faixas NVTX associadas a cada função. Os intervalos em azul claro correspondem aos períodos em que os kernels CUDA estão em execução.
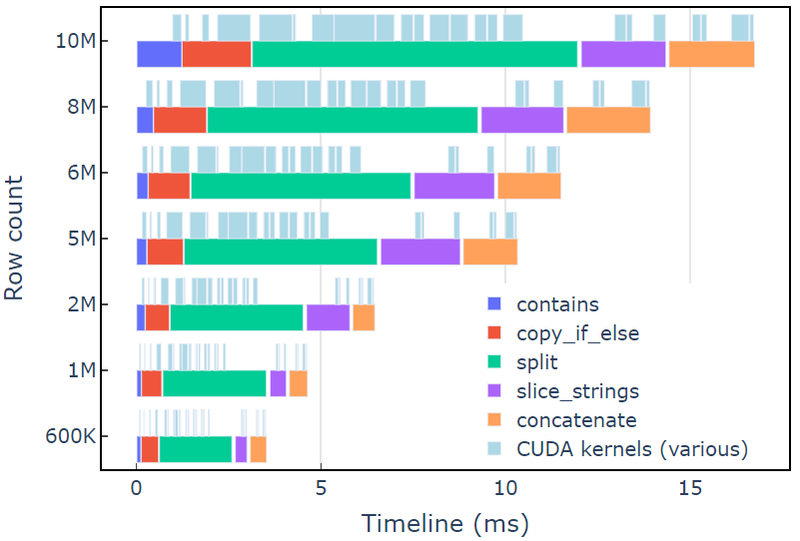 Figura 2. Criação de perfil de dados dos sistemas Nsight do exemplo redact
Figura 2. Criação de perfil de dados dos sistemas Nsight do exemplo redact
A API libcudf strings é um kit de ferramentas rápido e eficiente para transformar strings, mas às vezes funções críticas de desempenho precisam ser executadas ainda mais rápido. Uma fonte importante de trabalho extra na API de strings libcudf é a criação de pelo menos uma nova coluna de strings na memória global do dispositivo para cada chamada de API, abrindo a oportunidade de combinar várias chamadas de API em um kernel personalizado.
Limitações de desempenho em chamadas malloc do kernel
Primeiro, construiremos um kernel customizado para implementar a transformação de exemplo redigida. Ao projetar este kernel, devemos ter em mente que as colunas de strings da libcudf são imutáveis.
As colunas de strings não podem ser alteradas no local porque os bytes de caracteres são armazenados de forma contínua e qualquer alteração no comprimento de uma string invalidaria os dados de deslocamento. Portanto, o redact_kernel kernel personalizado gera uma nova coluna de strings usando uma fábrica de colunas libcudf para construir ambas offsets e chars colunas filho.
Nesta primeira abordagem, a string de saída para cada linha é criada em memória dinâmica do dispositivo usando uma chamada malloc dentro do kernel. A saída personalizada do kernel é um vetor de ponteiros de dispositivo para cada saída de linha, e esse vetor serve como entrada para uma fábrica de colunas de strings.
O kernel personalizado aceita um cudf::column_device_view para acessar os dados da coluna de strings e usa o element método para retornar um cudf::string_view representando os dados da string no índice de linha especificado. A saída do kernel é um vetor do tipo cudf::string_view que contém ponteiros para a memória do dispositivo contendo a string de saída e o tamanho dessa string em bytes.
A cudf::string_view A classe é semelhante à classe std::string_view, mas é implementada especificamente para libcudf e envolve um comprimento fixo de dados de caracteres na memória do dispositivo codificado como UTF-8. Ele tem muitos dos mesmos recursos (find e substr funções, por exemplo) e limitações (sem terminador nulo) como o std contrapartida. UMA cudf::string_view representa uma sequência de caracteres armazenada na memória do dispositivo e, portanto, podemos usá-la aqui para gravar a memória malloc'd para um vetor de saída.
semente de Malloc
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
Isso pode parecer uma abordagem razoável, até que o desempenho do kernel seja medido. Essa abordagem leva cerca de 108 ms em um A6000 com 600 mil linhas de dados — mais de 30 vezes mais lenta do que a solução fornecida acima usando a API libcudf strings.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
O principal gargalo é a malloc/free chamadas dentro dos dois kernels aqui. A memória dinâmica do dispositivo CUDA requer malloc/free chamadas em um kernel para serem sincronizadas, fazendo com que a execução paralela degenere em execução sequencial.
Pré-alocação de memória de trabalho para eliminar gargalos
Elimine o malloc/free gargalo, substituindo o malloc/free chamadas no kernel com memória de trabalho pré-alocada antes de iniciar o kernel.
Para o exemplo de redação, o tamanho de saída de cada string neste exemplo não deve ser maior que a própria string de entrada, pois a lógica remove apenas caracteres. Portanto, um único buffer de memória de dispositivo pode ser usado com o mesmo tamanho do buffer de entrada. Use os deslocamentos de entrada para localizar cada posição de linha.
Acessar os deslocamentos da coluna de strings envolve agrupar o cudf::column_view com uma cudf::strings_column_view e chamando seu offsets_begin método. o tamanho do chars coluna filha também pode ser acessada usando o chars_size método. Então uma rmm::device_uvector é pré-alocado antes de chamar o kernel para armazenar os dados de saída do caractere.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);Kernel pré-alocado
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
O kernel emite um vetor de cudf::string_view objetos que são passados para o cudf::make_strings_column função de fábrica. O segundo parâmetro para esta função é usado para identificar entradas nulas na coluna de saída. Os exemplos neste post não têm entradas nulas, portanto, um espaço reservado nullptr cudf::string_view{nullptr,0} é usado.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
Essa abordagem leva cerca de 1.1 ms em um A6000 com 600 mil linhas de dados e, portanto, supera a linha de base em mais de 2 vezes. A divisão aproximada é mostrada abaixo:
redact_kernel 66us make_strings_column 400us
O tempo restante é gasto em cudaMalloc, cudaFree, cudaMemcpy, que é típico da sobrecarga para gerenciar instâncias temporárias de rmm::device_uvector. Este método funciona bem se todas as strings de saída tiverem o mesmo tamanho ou menores que as strings de entrada.
No geral, mudar para uma alocação de memória de trabalho em massa com RAPIDS RMM é uma melhoria significativa e uma boa solução para uma função de cadeias de caracteres personalizadas.
Otimizando a criação de colunas para tempos de computação mais rápidos
Existe uma maneira de melhorar isso ainda mais? O gargalo agora é o cudf::make_strings_column função de fábrica que constrói os dois componentes da coluna de strings, offsets e chars, do vetor de cudf::string_view objetos.
Na libcudf, muitas funções de fábrica são incluídas para construir colunas de strings. A função de fábrica usada nos exemplos anteriores leva um cudf::device_span of cudf::string_view objetos e, em seguida, constrói a coluna executando um gather nos dados de caractere subjacentes para criar os deslocamentos e colunas filhas de caractere. UMA rmm::device_uvector é automaticamente conversível em um cudf::device_span sem copiar nenhum dado.
No entanto, se o vetor de caracteres e o vetor de deslocamentos forem construídos diretamente, uma função de fábrica diferente pode ser usada, que simplesmente cria a coluna de strings sem exigir uma coleta para copiar os dados.
A sizes_kernel faz uma primeira passagem pelos dados de entrada para calcular o tamanho de saída exato de cada linha de saída:
Kernel otimizado: Parte 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
Os tamanhos de saída são então convertidos em deslocamentos, executando uma operação no local exclusive_scan. Observe que o offsets vetor foi criado com names.size()+1 elementos. A última entrada será o número total de bytes (todos os tamanhos somados) enquanto a primeira entrada será 0. Ambos são manipulados pelo exclusive_scan ligar. o tamanho do chars coluna é recuperada da última entrada do offsets coluna para construir o vetor chars.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
A redact_kernel a lógica ainda é praticamente a mesma, exceto que aceita a saída d_offsets vetor para resolver o local de saída de cada linha:
Kernel otimizado: Parte 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
O tamanho da saída d_chars coluna é recuperada da última entrada do d_offsets coluna para alocar o vetor chars. O kernel é iniciado com o vetor de deslocamentos pré-computado e retorna o vetor de caracteres preenchido. Por fim, a fábrica de colunas de strings libcudf cria as colunas de strings de saída.
Esta cudf::make_strings_column A função de fábrica constrói a coluna de strings sem fazer uma cópia dos dados. o offsets dados e chars os dados já estão no formato correto e esperado e esta fábrica simplesmente move os dados de cada vetor e cria a estrutura da coluna em torno dele. Depois de concluído, o rmm::device_uvectors para offsets e chars estão vazios, seus dados foram movidos para a coluna de saída.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
Essa abordagem leva cerca de 300 us (0.3 ms) em um A6000 com 600 mil linhas de dados e melhora em mais de 2 vezes a abordagem anterior. Você pode notar que sizes_kernel e redact_kernel compartilham muito da mesma lógica: uma vez para medir o tamanho da saída e novamente para preencher a saída.
Do ponto de vista da qualidade do código, é benéfico refatorar a transformação como uma função de dispositivo chamada pelos tamanhos e redact kernels. De uma perspectiva de desempenho, você pode se surpreender ao ver o custo computacional da transformação sendo pago duas vezes.
Os benefícios para gerenciamento de memória e criação de coluna mais eficiente geralmente superam o custo de computação de executar a transformação duas vezes.
A Tabela 2 mostra o tempo de computação, contagem de kernel e bytes processados para as quatro soluções discutidas neste post. “Total kernel launchs” reflete o número total de kernels lançados, incluindo kernels computacionais e auxiliares. “Total de bytes processados” é a taxa de transferência acumulada de leitura e gravação da DRAM e “mínimo de bytes processados” é uma média de 37.9 bytes por linha para nossas entradas e saídas de teste. O caso ideal de “largura de banda de memória limitada” assume uma largura de banda de 768 GB/s, a taxa de transferência de pico teórica do A6000.
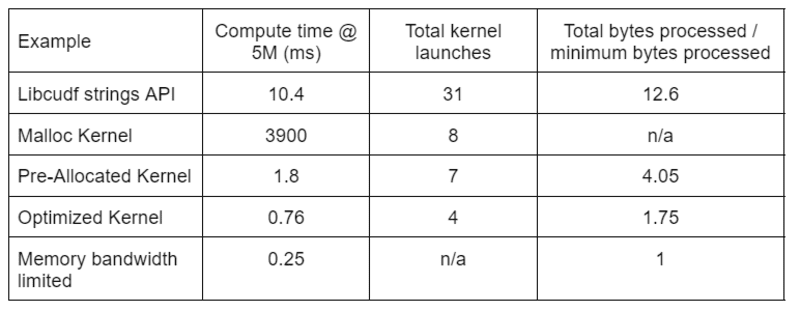 Tabela 2. Tempo de computação, contagem de kernel e bytes processados para as quatro soluções discutidas neste post
Tabela 2. Tempo de computação, contagem de kernel e bytes processados para as quatro soluções discutidas neste post
O “kernel otimizado” fornece o maior rendimento devido ao número reduzido de inicializações do kernel e ao menor número total de bytes processados. Com kernels personalizados eficientes, o total de inicializações do kernel cai de 31 para 4 e o total de bytes processados de 12.6x para 1.75x da entrada mais o tamanho da saída.
Como resultado, o kernel personalizado atinge uma taxa de transferência >10 vezes maior do que a API de strings de uso geral para a transformação de redação.
O recurso de memória do pool em Gerenciador de memória RAPIDS (RMM) é outra ferramenta que você pode usar para aumentar o desempenho. Os exemplos acima usam o “recurso de memória CUDA” padrão para alocar e liberar memória global do dispositivo. No entanto, o tempo necessário para alocar memória de trabalho adiciona uma latência significativa entre as etapas das transformações de string. O “recurso de memória do pool” no RMM reduz a latência alocando um grande pool de memória antecipadamente e atribuindo subalocações conforme necessário durante o processamento.
Com o recurso de memória CUDA, “Optimized Kernel” mostra uma aceleração de 10x-15x que começa a cair em contagens de linhas mais altas devido ao aumento do tamanho da alocação (Figura 3). O uso do recurso de memória do pool mitiga esse efeito e mantém acelerações de 15x a 25x em relação à abordagem da API libcudf strings.
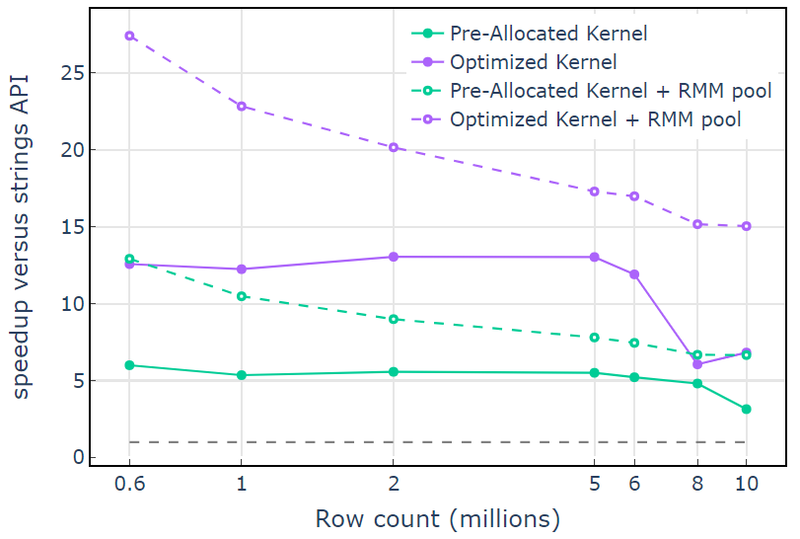 Figura 3. Aceleração dos kernels personalizados “Kernel pré-alocado” e “Kernel otimizado” com o recurso de memória CUDA padrão (sólido) e o recurso de memória de pool (tracejado), em comparação com a API de string libcudf usando o recurso de memória CUDA padrão
Figura 3. Aceleração dos kernels personalizados “Kernel pré-alocado” e “Kernel otimizado” com o recurso de memória CUDA padrão (sólido) e o recurso de memória de pool (tracejado), em comparação com a API de string libcudf usando o recurso de memória CUDA padrão
Com o recurso de pool de memória, é demonstrada uma taxa de transferência de memória de ponta a ponta que se aproxima do limite teórico para um algoritmo de duas passagens. O “kernel otimizado” atinge taxa de transferência de 320-340 GB/s, medida usando o tamanho das entradas mais o tamanho das saídas e o tempo de computação (Figura 4).
A abordagem de duas passagens primeiro mede os tamanhos dos elementos de saída, aloca memória e, em seguida, define a memória com as saídas. Dado um algoritmo de processamento de duas passagens, a implementação em “Optimized Kernel” executa perto do limite de largura de banda da memória. “Taxa de transferência de memória de ponta a ponta” é definida como a entrada mais o tamanho da saída em GB dividido pelo tempo de computação. *Largura de banda de memória RTX A6000 (768 GB/s).
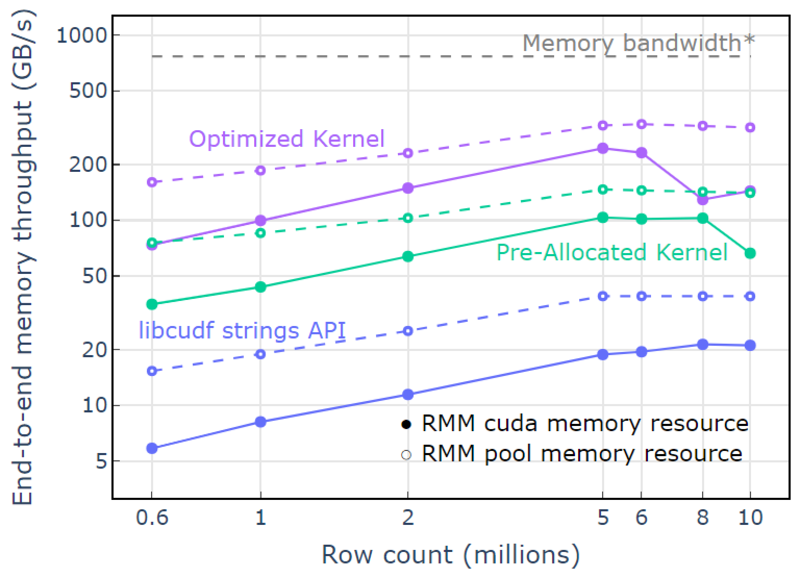 Figura 4. Taxa de transferência de memória para “Kernel otimizado”, “Kernel pré-alocado” e “API de strings libcudf” como uma função da contagem de linhas de entrada/saída
Figura 4. Taxa de transferência de memória para “Kernel otimizado”, “Kernel pré-alocado” e “API de strings libcudf” como uma função da contagem de linhas de entrada/saída
Este post demonstra duas abordagens para escrever transformações de dados de string eficientes em libcudf. A API de uso geral libcudf é rápida e direta para desenvolvedores e oferece bom desempenho. O libcudf também fornece utilitários do lado do dispositivo projetados para uso com kernels personalizados, neste exemplo, desbloqueando um desempenho 10 vezes mais rápido.
Aplique seu conhecimento
Para começar a usar o RAPIDS cuDF, visite o rapidsai/cudf repositório GitHub. Se você ainda não experimentou cuDF e libcudf para suas cargas de trabalho de processamento de strings, recomendamos que você teste a versão mais recente. Recipientes Docker são fornecidos para lançamentos, bem como compilações noturnas. pacotes conda também estão disponíveis para facilitar o teste e a implantação. Se você já estiver usando o cuDF, recomendamos que execute o novo exemplo de transformação de strings visitando rapidsai/cudf/árvore/HEAD/cpp/exemplos/strings no GitHub.
David Wendt é engenheiro sênior de software de sistemas na NVIDIA, desenvolvendo código C++/CUDA para RAPIDS. David possui mestrado em engenharia elétrica pela Johns Hopkins University.
Gregório Kimball é gerente de engenharia de software da NVIDIA e trabalha na equipe RAPIDS. Gregory lidera o desenvolvimento da libcudf, a biblioteca CUDA/C++ para processamento de dados colunares que capacita o RAPIDS cuDF. Gregory é PhD em física aplicada pelo California Institute of Technology.
Óptimo estado. Original. Republicado com permissão.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- Sobre
- acima
- acelerando
- Aceita
- Acesso
- acessadas
- realizado
- em
- adicionado
- Adiciona
- algoritmo
- Todos os Produtos
- aloca
- alocação
- já
- quantidade
- análise
- e
- Outro
- apache
- api
- APIs
- aplicações
- aplicado
- abordagem
- se aproxima
- Aproximando
- por aí
- Ordem
- associado
- auto
- automaticamente
- disponível
- média
- Largura de Banda
- Linha de Base
- Porque
- antes
- ser
- abaixo
- benéfico
- Benefícios
- MELHOR
- entre
- Azul
- Breakdown
- amortecer
- construir
- Prédio
- Constrói
- construído
- C + +
- Califórnia
- chamada
- chamado
- chamada
- chamadas
- não podes
- casas
- casos
- causando
- Alterações
- personagem
- caracteres
- criança
- classe
- Fechar
- código
- Coluna
- colunas
- combinar
- comparando
- completar
- Efetuado
- componentes
- computação
- Computar
- Considerar
- Consistindo
- construir
- contém
- converter
- convertido
- copiando
- Correspondente
- Custo
- crio
- criado
- cria
- criação
- personalizadas
- dados,
- informática
- ciência de dados
- David
- Padrão
- Grau
- entrega
- demonstraram
- desenvolvimento
- projetado
- concepção
- desenvolvedores
- em desenvolvimento
- Desenvolvimento
- dispositivo
- diferente
- diretamente
- discutido
- dividido
- Estivador
- Cair
- durante
- dinâmico
- cada
- mais fácil
- efeito
- eficiente
- eficientemente
- Engenharia elétrica
- elementos
- eliminado
- permitir
- encorajar
- end-to-end
- engenheiro
- Engenharia
- Todo
- entrada
- Éter (ETH)
- Mesmo
- tudo
- exemplo
- exemplos
- excelente
- Exceto
- execução
- esperado
- externo
- extra
- extrato
- fábrica
- RÁPIDO
- mais rápido
- Característica
- Funcionalidades
- Figura
- filtragem
- final
- Finalmente
- Primeiro nome
- fixado
- seguir
- seguido
- seguinte
- formulário
- formato
- Gratuito
- freqüentemente
- da
- frente
- totalmente
- função
- funções
- mais distante
- Ganho
- Geral
- gera
- ter
- GitHub
- dado
- Global
- Bom estado, com sinais de uso
- GPU
- garantido
- Alças
- ter
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- superior
- mais
- detém
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- HTTPS
- ideal
- identificar
- imutável
- executar
- implementação
- implementado
- melhorar
- melhoria
- melhora
- in
- incluído
- Incluindo
- Crescimento
- aumentando
- índice
- Individual
- INFORMAÇÕES
- do estado inicial,
- entrada
- Instituto
- interno
- IT
- se
- Johns Hopkins
- Johns Hopkins University
- juntando
- KDnuggetsGenericName
- Guarda
- Chave
- Conhecimento
- O rótulo
- grande
- Maior
- Sobrenome
- Latência
- mais recente
- Último lançamento
- lançado
- lança
- de lançamento
- Leads
- aprendizagem
- Comprimento
- Biblioteca
- leve
- LIMITE
- limitações
- carregamento
- localização
- máquina
- aprendizado de máquina
- a Principal
- mantém
- fazer
- FAZ
- Fazendo
- gerencia
- de grupos
- Gerente
- gestão
- muitos
- dominar
- Dominar
- Match
- significa
- a medida
- medidas
- Memória
- método
- poder
- milhão
- mente
- mais
- mais eficiente
- movimentos
- MS
- múltiplo
- nome
- nomes
- você merece...
- necessário
- Novo
- número
- Nvidia
- objetos
- compensar
- ONE
- abertura
- operar
- opera
- Operações
- Oportunidade
- Outros
- pago
- Paralelo
- parâmetro
- parte
- passou
- Pico
- atuação
- realização
- executa
- períodos
- permissão
- perspectiva
- Física
- Lugar
- platão
- Inteligência de Dados Platão
- PlatãoData
- mais
- ponto
- piscina
- populosa
- posição
- abertas
- Publique
- poderoso
- atribuições
- anterior
- em processamento
- produzir
- profiling
- oferece
- fornecido
- fornece
- público
- propósito
- qualidade
- alcance
- Chega
- Leia
- razoável
- recebe
- registro
- Reduzido
- reduz
- Refatorar
- reflete
- regiões
- liberar
- Releases
- remanescente
- representando
- representa
- recurso
- resultar
- retorno
- Retorna
- LINHA
- Execute
- corrida
- mesmo
- Ciência
- Segundo
- senior
- Seqüência
- serve
- Conjuntos
- Partilhar
- rede de apoio social
- mostrando
- Shows
- periodo
- semelhante
- simplesmente
- desde
- solteiro
- Tamanho
- tamanhos
- menor
- So
- Software
- Engenheiro de Software
- Engenharia de software
- sólido
- solução
- Soluções
- fonte
- Espaço
- específico
- especificamente
- especificada
- discurso
- velocidade
- gasto
- divisão
- começo
- começado
- Comece
- Status
- Passos
- Ainda
- loja
- armazenadas
- lojas
- franco
- transmitir canais
- estrutura
- admirado
- sistemas
- toma
- Profissionais
- Tecnologia
- temporário
- teste
- ensaio
- A
- deles
- teórico
- assim sendo
- Através da
- Taxa de transferência
- tempo
- para
- juntos
- ferramenta
- kit de ferramentas
- ferramentas
- Total
- Transformar
- Transformação
- transformações
- transformado
- transformando
- tv
- tipos
- típico
- subjacente
- universidade
- destravar
- Desbloqueio
- us
- usar
- utilitários
- Valioso
- Informação valiosa
- Contra
- visibilidade
- visível
- vital
- qual
- enquanto
- Largo
- Ampla variedade
- precisarão
- dentro
- sem
- Atividades:
- trabalhar
- trabalho
- seria
- escrever
- escrita
- X
- investimentos
- zefirnet










