Apache Hudi é um formato de tabela aberto que traz recursos de banco de dados e data warehouse para data lakes. O Apache Hudi ajuda os engenheiros de dados a gerenciar desafios complexos, como o gerenciamento de conjuntos de dados em constante evolução com transações, mantendo o desempenho das consultas. Os engenheiros de dados usam o Apache Hudi para streaming de cargas de trabalho, bem como para criar pipelines de dados incrementais eficientes. Hudi fornece tabelas, transações, upserts e exclusões eficientes, índices avançados, serviços de ingestão de streamingdados agrupamento e compactação otimizações e controle de concorrência, tudo isso mantendo seus dados em formatos de arquivo de código aberto. As otimizações avançadas de desempenho do Hudi tornam as cargas de trabalho analíticas mais rápidas com qualquer um dos mecanismos de consulta populares, incluindo Apache Spark, Presto, Trino, Hive e assim por diante.
Muitos clientes da AWS adotaram o Apache Hudi em seus data lakes criados com base no Amazon S3 usando Cola AWS, um serviço de integração de dados sem servidor que facilita descobrir, preparar, mover e integrar dados de diversas fontes para análise, aprendizado de máquina (ML) e desenvolvimento de aplicativos. Rastreador do AWS Glue é um componente do AWS Glue, que permite criar metadados de tabela a partir do conteúdo de dados automaticamente, sem exigir definição manual dos metadados.
Os rastreadores do AWS Glue agora oferecem suporte a tabelas Apache Hudi, simplificando a adoção de Catálogo de dados do AWS Glue como o catálogo de tabelas Hudi. Um caso de uso típico é registrar tabelas Hudi, que não possuem definição de tabela de catálogo. Outro caso de uso típico é a migração de outros catálogos Hudi, como o metastore Hive. Ao migrar de outros catálogos do Hudi, você pode criar e programar um crawler do AWS Glue e fornecer um ou mais caminhos do Amazon S3 onde os arquivos da tabela do Hudi estão localizados. Você tem a opção de fornecer a profundidade máxima dos caminhos do Amazon S3 que o rastreador do AWS Glue pode percorrer. A cada execução, os rastreadores do AWS Glue extrairão informações de esquema e partição e atualizarão o AWS Glue Data Catalog com as alterações de esquema e partição. Os rastreadores do AWS Glue atualizam o local mais recente do arquivo de metadados no catálogo de dados do AWS Glue que os mecanismos analíticos da AWS podem usar diretamente.
Com este lançamento, você pode criar e programar um crawler do AWS Glue para registrar tabelas Hudi no AWS Glue Data Catalog. Você pode então fornecer um ou vários caminhos do Amazon S3 onde as tabelas Hudi estão localizadas. Você tem a opção de fornecer a profundidade máxima dos caminhos do Amazon S3 que os rastreadores podem percorrer. A cada execução do rastreador, ele inspeciona cada um dos caminhos do S3 e cataloga as informações do esquema, como novas tabelas, exclusões e atualizações de esquemas no AWS Glue Data Catalog. Os rastreadores inspecionam informações de partição e adicionam partições recém-adicionadas ao AWS Glue Data Catalog. Os rastreadores também atualizam o local do arquivo de metadados mais recente no Catálogo de dados do AWS Glue que os mecanismos analíticos da AWS podem usar diretamente.
Esta postagem demonstra como funciona esse novo recurso de rastrear tabelas Hudi.
Como o rastreador AWS Glue funciona com tabelas Hudi
As tabelas Hudi têm duas categorias, com implicações específicas para cada uma:
- Copiar na gravação (CoW) – Os dados são armazenados em formato colunar (Parquet) e cada atualização cria uma nova versão dos arquivos durante uma gravação.
- Mesclar na leitura (MoR) – Os dados são armazenados usando uma combinação de formatos colunares (Parquet) e baseados em linhas (Avro). As atualizações são registradas com base em linhas
deltaarquivos e são compactados conforme necessário para criar novas versões dos arquivos colunares.
Com conjuntos de dados CoW, cada vez que há uma atualização em um registro, o arquivo que contém o registro é reescrito com os valores atualizados. Com um conjunto de dados MoR, cada vez que há uma atualização, Hudi grava apenas a linha do registro alterado. MoR é mais adequado para cargas de trabalho com muitas gravações ou alterações e com menos leituras. O CoW é mais adequado para cargas de trabalho com muita leitura em dados que mudam com menos frequência.
Hudi fornece três tipos de consulta para acessar os dados:
- Consultas de instantâneo – Consultas que veem o instantâneo mais recente da tabela a partir de uma determinada ação de confirmação ou compactação. Para tabelas MoR, as consultas de instantâneo expõem o estado mais recente da tabela mesclando os arquivos base e delta da fatia de arquivo mais recente no momento da consulta.
- Consultas incrementais – As consultas veem apenas novos dados gravados na tabela, desde um determinado commit ou compactação. Isso fornece efetivamente fluxos de mudança para permitir pipelines de dados incrementais.
- Leia consultas otimizadas – Para tabelas MoR, as consultas veem os dados compactados mais recentes. Para tabelas CoW, as consultas veem os últimos dados confirmados.
Para tabelas copy-on-write, os crawlers criam uma única tabela no AWS Glue Data Catalog com o ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
Para tabelas mescladas ao ler, os rastreadores criam duas tabelas no AWS Glue Data Catalog para o mesmo local da tabela:
- Uma tabela com sufixo
_ro, que usa o ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - Uma tabela com sufixo
_rt, que usa o RealTime Serde permitindo consultas de instantâneo:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Durante cada rastreamento, para cada caminho Hudi fornecido, os rastreadores fazem uma chamada de API de lista do Amazon S3, filtram com base no .hoodie pastas e encontre o arquivo de metadados mais recente na pasta de metadados da tabela Hudi.
Rastrear uma tabela Hudi CoW usando o rastreador AWS Glue
Nesta seção, veremos como rastrear um Hudi CoW usando rastreadores AWS Glue.
Pré-requisitos
Aqui estão os pré-requisitos para este tutorial:
- Instale e configure Interface de linha de comando AWS (AWS CLI).
- Crie seu bucket S3 se você não o tiver.
- Crie sua função IAM para AWS Glue se você não tiver. Você precisa
s3:GetObjectparas3://your_s3_bucket/data/sample_hudi_cow_table/. - Execute o comando a seguir para copiar a tabela de amostra do Hudi em seu bucket S3. (Substituir
your_s3_bucketcom o nome do seu bucket S3.)
Esta instrução orienta você a copiar dados de amostra, mas você pode criar facilmente qualquer tabela Hudi usando AWS Glue. Saiba mais em Apresentando o suporte nativo para Apache Hudi, Delta Lake e Apache Iceberg no AWS Glue para Apache Spark, Parte 2: AWS Glue Studio Visual Editor.
Crie um rastreador Hudi
Nesta instrução, crie o rastreador por meio do console. Conclua as etapas a seguir para criar um rastreador Hudi:
- No console AWS Glue, escolha Rastreadores.
- Escolha Criar rastreador.
- Escolha Nome, entrar
hudi_cow_crawler. Escolher Próximo. - Debaixo Configuração da fonte de dados, escolher Adicionar fonte de dados.
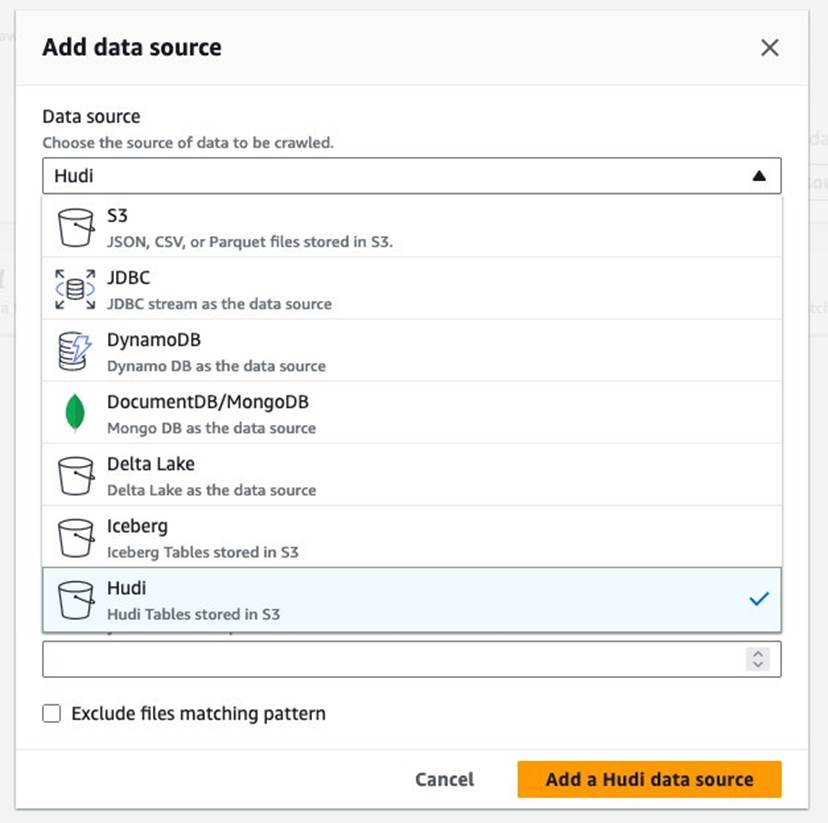
- Escolha Fonte de dados, escolha Hudi.
- Escolha Incluir caminhos de tabela hudi, entrar
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Substituiryour_s3_bucketcom o nome do seu bucket S3.) - Escolha Adicionar fonte de dados Hudi.
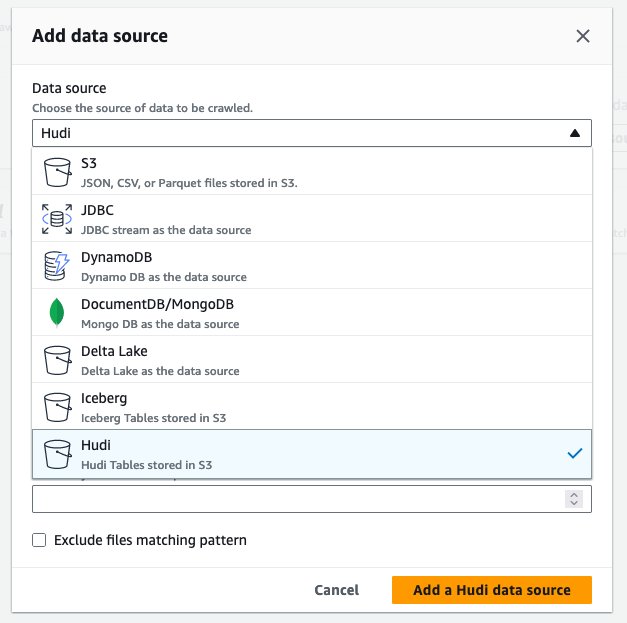
- Escolha Próximo.
- Escolha Função do IAM existente, escolha sua função do IAM e escolha Próximo.
- Escolha Banco de dados de destino, escolha Adicionar banco de dados, Em seguida, o Adicionar banco de dados caixa de diálogo aparece. Para Nome do banco de dados, entrar
hudi_crawler_blog, Em seguida, escolha Crie. Escolher Próximo. - Escolha Criar rastreador.
Agora, um novo rastreador Hudi foi criado com sucesso. O rastreador pode ser acionado para ser executado por meio do console ou do SDK ou da AWS CLI usando o StartCrawl API. Também pode ser programado por meio do console para acionar os rastreadores em horários específicos. Nesta instrução, execute o rastreador por meio do console.
- Escolha Executar rastreador.
- Aguarde a conclusão do rastreador.
Após a execução do rastreador, você poderá ver a definição da tabela Hudi no console do AWS Glue:
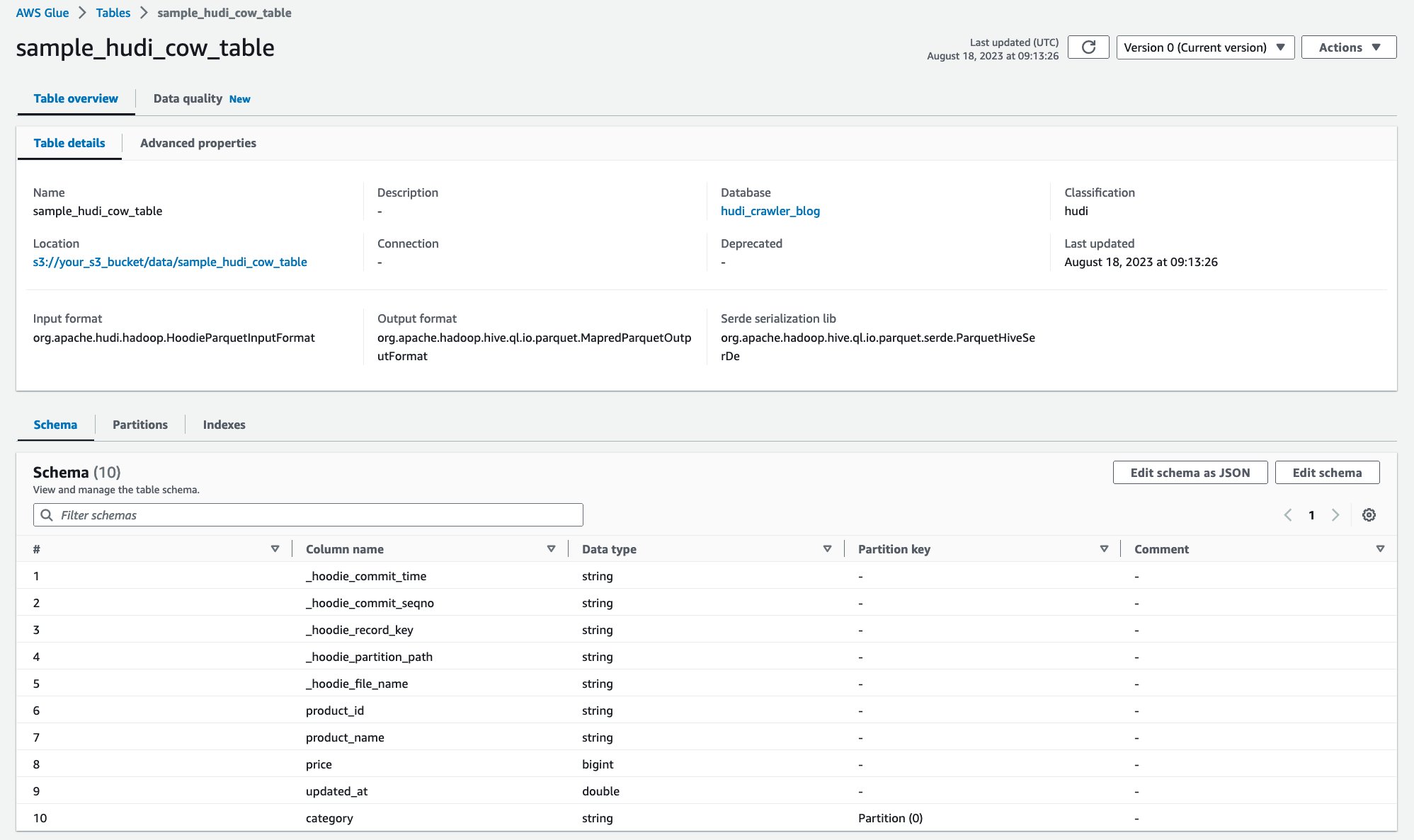
Você rastreou com êxito a tabela Hudi CoR com dados no Amazon S3 e criou uma tabela AWS Glue Data Catalog com o esquema preenchido. Depois de criar a definição da tabela no AWS Glue Data Catalog, os serviços de análise da AWS, como o Amazon Athena, poderão consultar a tabela Hudi.
Conclua as etapas a seguir para iniciar consultas no Athena:
- Abra o console do Amazon Athena.
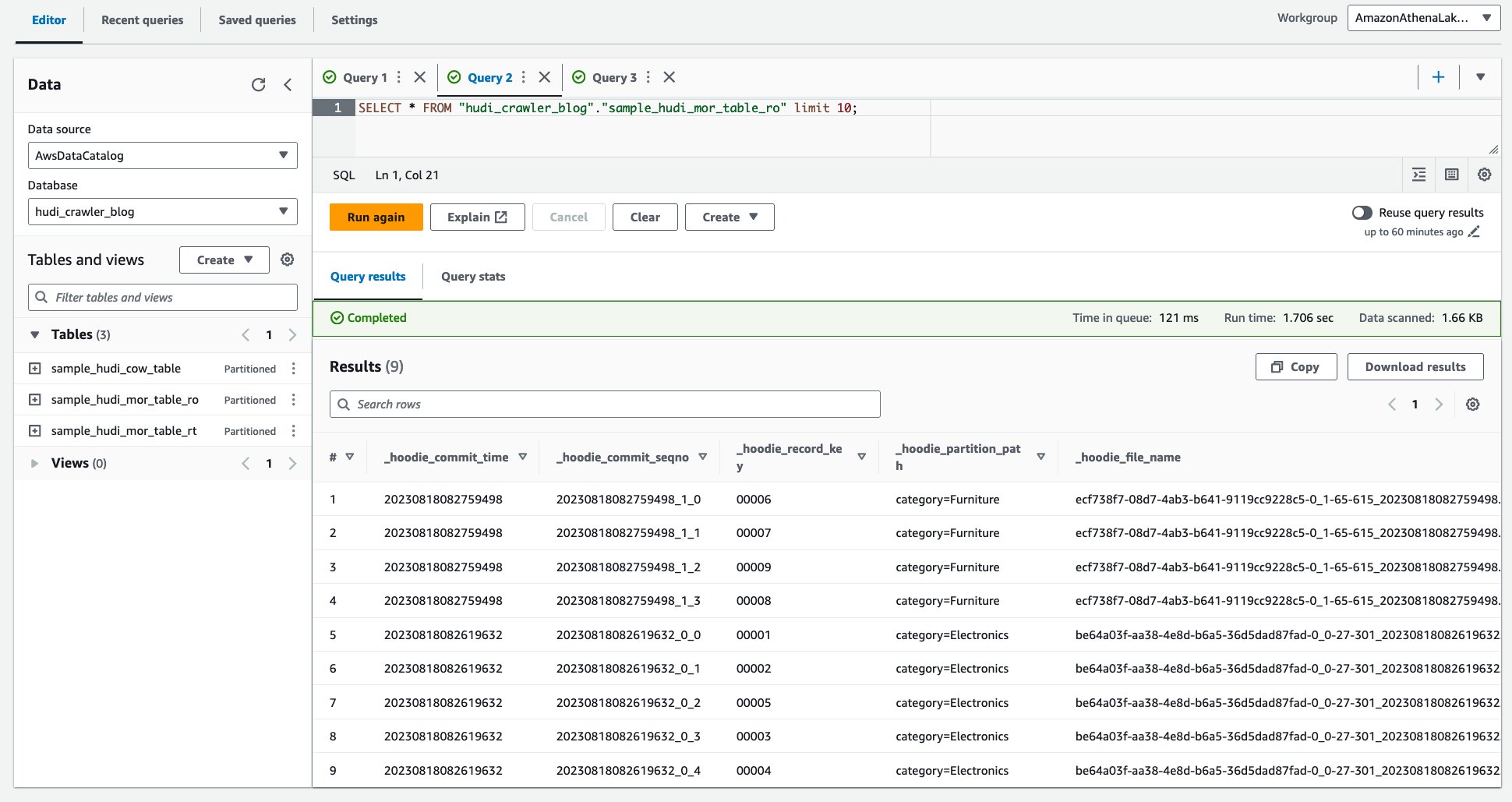
- Execute a consulta a seguir.
A captura de tela a seguir mostra nossa saída:
Rastrear uma tabela Hudi MoR usando o rastreador AWS Glue com permissões de dados do AWS Lake Formation
Nesta seção, veremos como rastrear uma tabela Hudi MoR usando AWS Glue. Desta vez, você usa a permissão de dados do AWS Lake Formation para rastrear fontes de dados do Amazon S3 em vez da permissão do IAM e do Amazon S3. Isso é opcional, mas simplifica as configurações de permissão quando seu data lake é gerenciado por permissões do AWS Lake Formation.
Pré-requisitos
Aqui estão os pré-requisitos para este tutorial:
- Instale e configure Interface de linha de comando AWS (AWS CLI).
- Crie seu bucket S3 se você não o tiver.
- Crie sua função IAM para AWS Glue se você não tiver. Você precisa
lakeformation:GetDataAccess. Mas você não precisas3:GetObjectparas3://your_s3_bucket/data/sample_hudi_mor_table/porque usamos a permissão de dados do Lake Formation para acessar os arquivos. - Execute o comando a seguir para copiar a tabela de amostra do Hudi em seu bucket S3. (Substituir
your_s3_bucketcom o nome do seu bucket S3.)
Além das etapas de processamento, conclua as etapas a seguir para atualizar as configurações do AWS Glue Data Catalog para usar permissões do Lake Formation para controlar recursos do catálogo em vez do controle de acesso baseado em IAM:
- Faça login no console do Lake Formation como administrador do data lake.
- Se esta for a primeira vez que acessa o console do Lake Formation, adicione-se como o administrador do data lake.
- Debaixo Áreas de Suporte, escolha Configurações do catálogo de dados.
- Escolha Permissões padrão para bancos de dados e tabelas recém-criados, desmarque Use apenas controle de acesso IAM para novos bancos de dados e Use apenas controle de acesso IAM para novas tabelas em novos bancos de dados.
- Escolha Configuração de versão entre contas, escolha versão 3.
- Escolha Salvar.
A próxima etapa é registrar seu bucket S3 em locais de data lake do Lake Formation:
- No console do Lake Formation, escolha Localizações de data lakee escolha Registrar localização.
- Escolha Caminho Amazon S3, entrar
s3://your_s3_bucket/. (Substituiryour_s3_bucketcom o nome do seu bucket S3.) - Escolha Registrar localização.
Em seguida, conceda à função do rastreador Glue acesso ao local dos dados para que o rastreador possa usar a permissão do Lake Formation para acessar os dados e criar tabelas no local:
- No console do Lake Formation, escolha Localizações de dados e escolha Conceda.
- Escolha Usuários e funções IAM, selecione a função do IAM usada para o rastreador.
- Escolha Local de armazenamento, entrar
s3://your_s3_bucket/data/. (Substituiryour_s3_bucketcom o nome do seu bucket S3.) - Escolha Conceda.
Em seguida, conceda a função de rastreador para criar tabelas no banco de dados hudi_crawler_blog:
- No console do Lake Formation, escolha Permissões do data lake.
- Escolha Conceda.
- Escolha Principais, escolha Usuários e funções IAMe escolha a função do rastreador.
- Escolha Tags LF ou recursos de catálogo, escolha Recursos de catálogo de dados nomeados.
- Escolha banco de dados, escolha o banco de dados
hudi_crawler_blog. - Debaixo Permissões de banco de dados, selecione Criar tabela.
- Escolha Conceda.
Crie um rastreador Hudi com permissões de dados do Lake Formation
Conclua as etapas a seguir para criar um rastreador Hudi:
- No console AWS Glue, escolha Rastreadores.
- Escolha Criar rastreador.
- Escolha Nome, entrar
hudi_mor_crawler. Escolher Próximo. - Debaixo Configuração da fonte de dados, escolher Adicionar fonte de dados.
- Escolha Fonte de dados, escolha Hudi.
- Escolha Incluir caminhos de tabela hudi, entrar
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Substituiryour_s3_bucketcom o nome do seu bucket S3.) - Escolha Adicionar fonte de dados Hudi.
- Escolha Próximo.
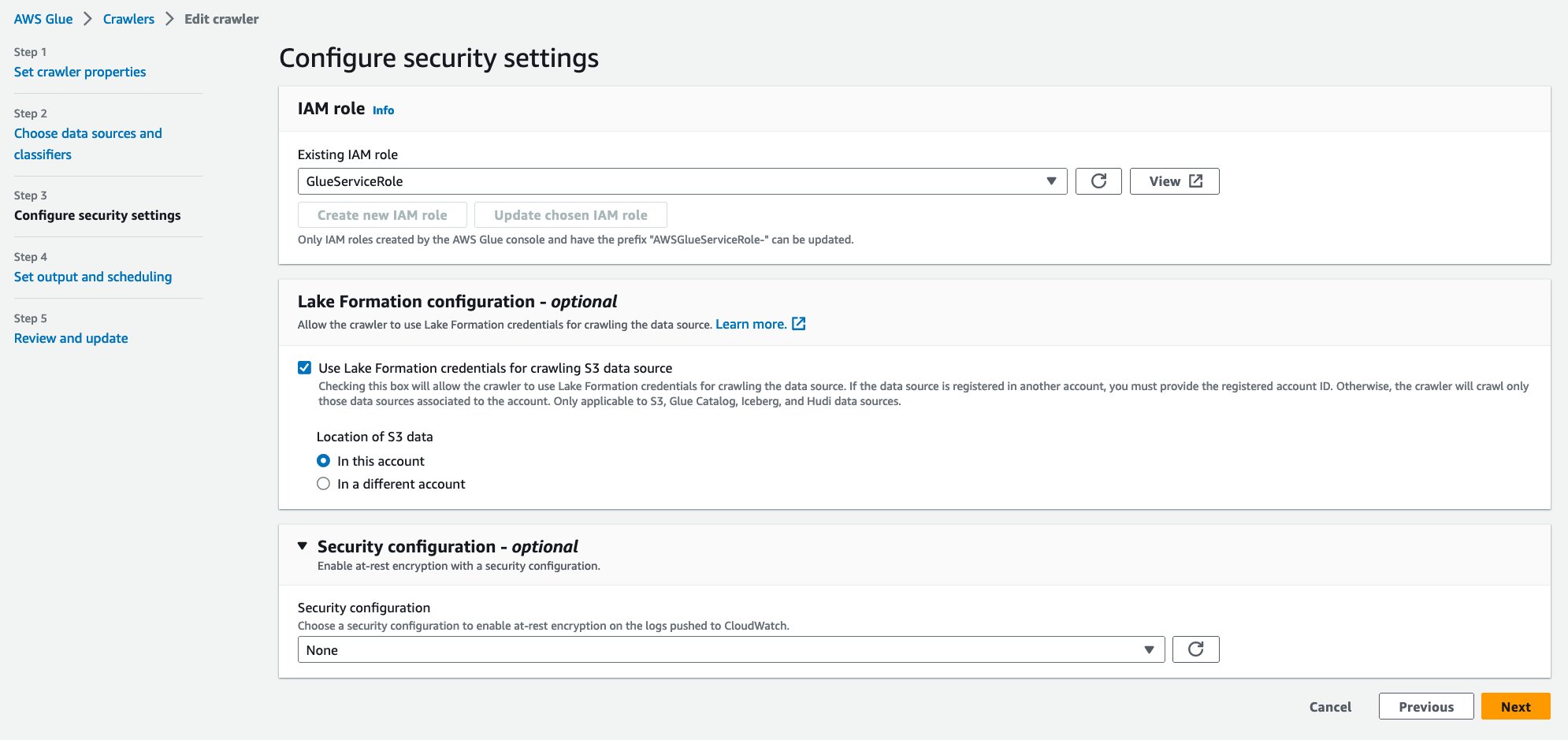
- Escolha Função do IAM existente, escolha sua função IAM.
- Debaixo Configuração do Lake Formation – opcional, selecione Use as credenciais do Lake Formation para rastrear a fonte de dados S3.
- Escolha Próximo.
- Escolha Banco de dados de destino, escolha
hudi_crawler_blog. Escolher Próximo. - Escolha Criar rastreador.
Agora, um novo rastreador Hudi foi criado com sucesso. O rastreador usa credenciais do Lake Formation para rastrear arquivos do Amazon S3. Vamos executar o novo rastreador:
- Escolha Executar rastreador.
- Aguarde a conclusão do rastreador.
Após a execução do rastreador, você poderá ver duas tabelas da definição da tabela Hudi no console do AWS Glue:
sample_hudi_mor_table_ro(leia a tabela otimizada)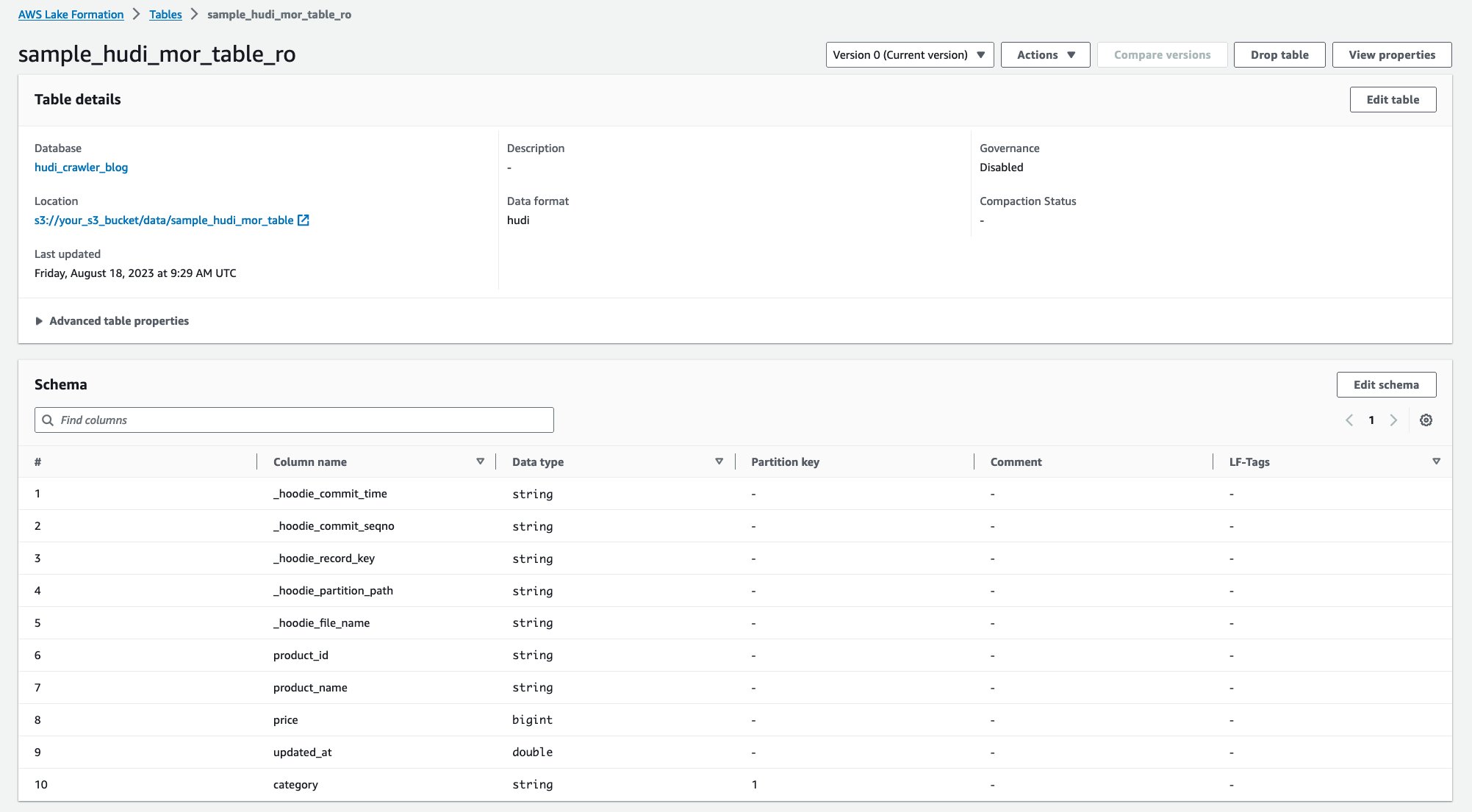
sample_hudi_mor_table_rt(tabela em tempo real)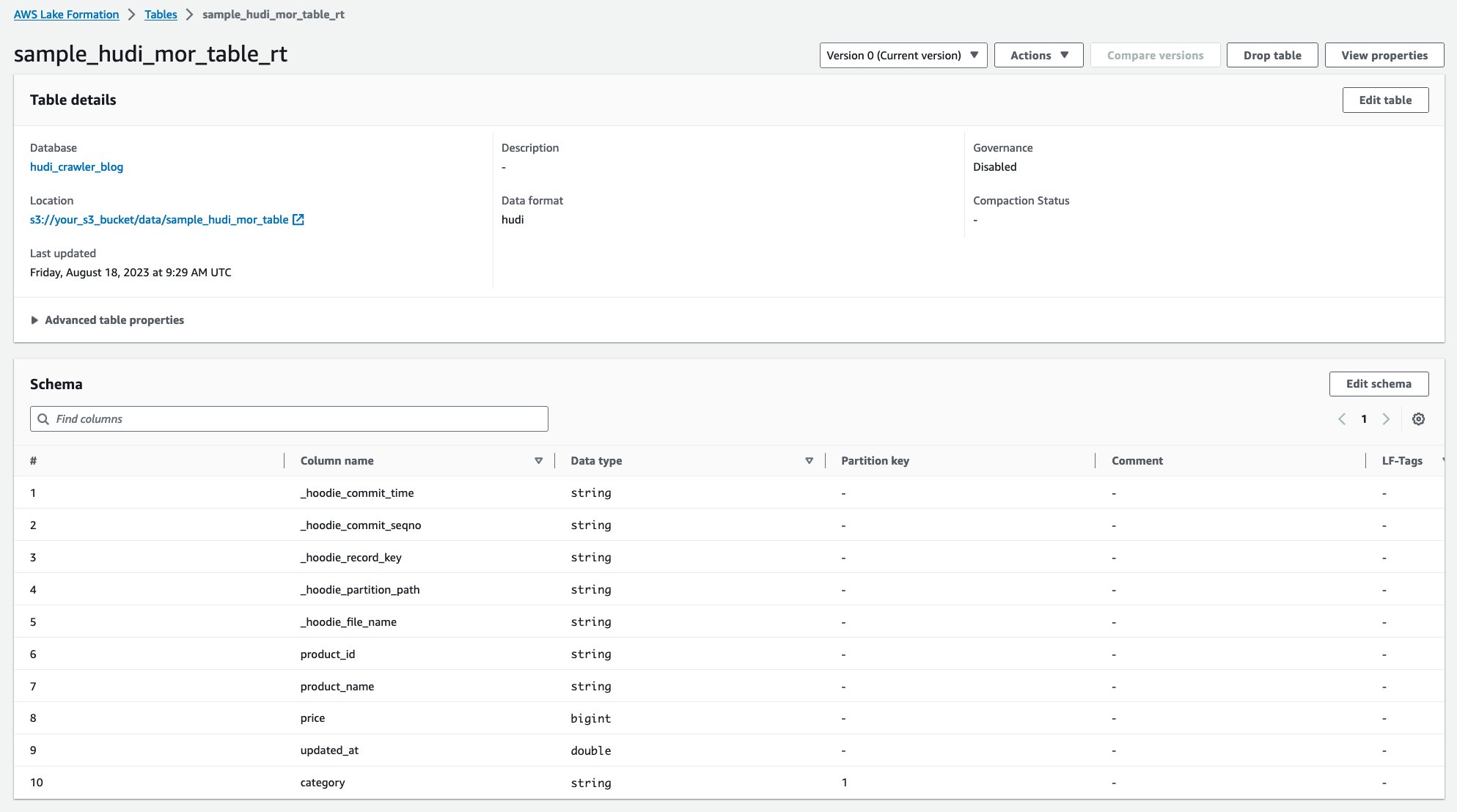
Você registrou o bucket do data lake no Lake Formation e ativou o acesso de rastreamento ao data lake usando permissões do Lake Formation. Você rastreou com êxito a tabela Hudi MoR com dados no Amazon S3 e criou uma tabela AWS Glue Data Catalog com o esquema preenchido. Depois de criar as definições de tabela no AWS Glue Data Catalog, os serviços de análise da AWS, como o Amazon Athena, poderão consultar a tabela Hudi.
Conclua as etapas a seguir para iniciar consultas no Athena:
- Abra o console do Amazon Athena.
- Execute a consulta a seguir.
A captura de tela a seguir mostra nossa saída:
- Execute a consulta a seguir.
A captura de tela a seguir mostra nossa saída:
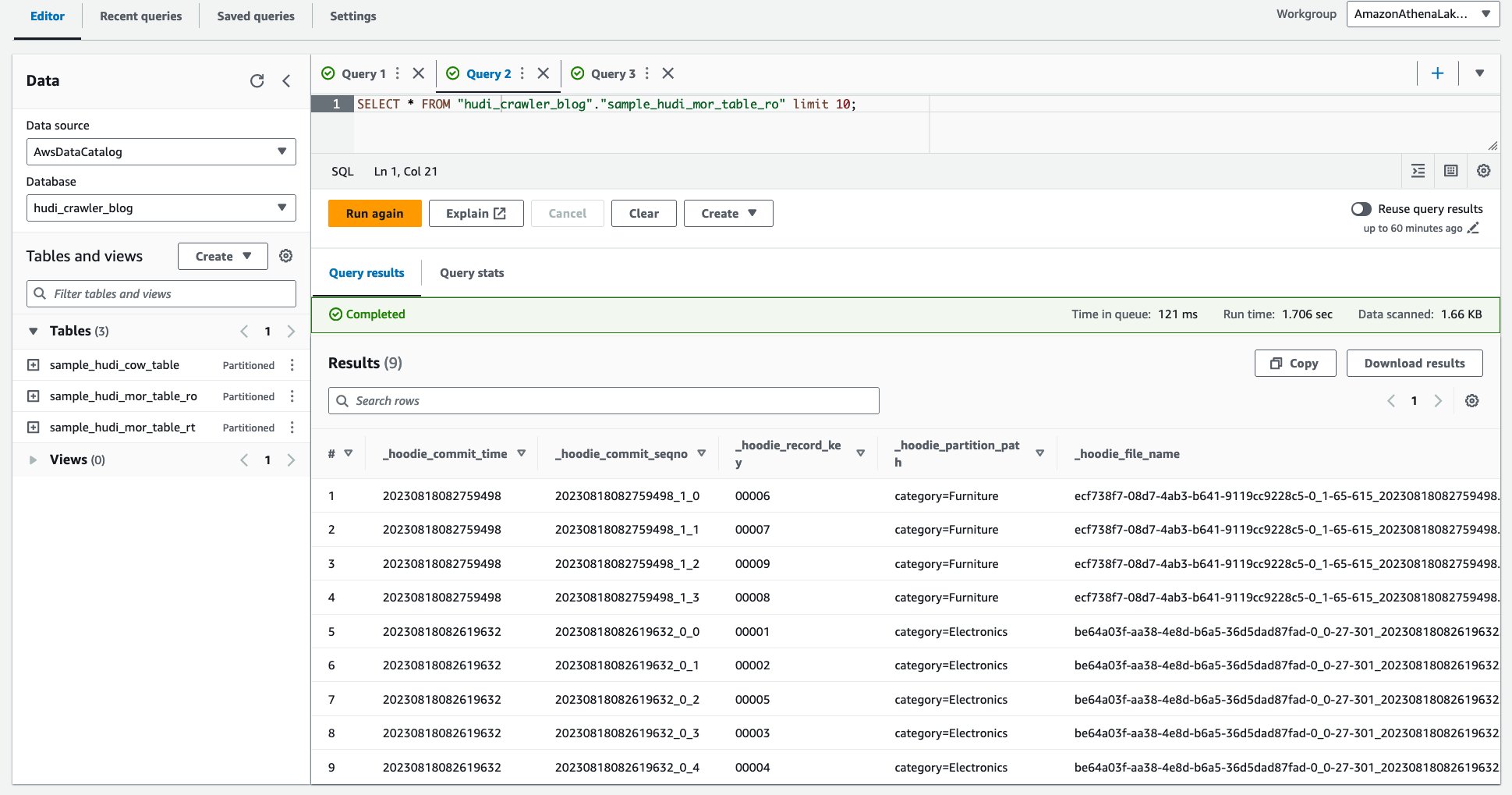
Controle de acesso refinado usando permissões do AWS Lake Formation
Para aplicar controle de acesso refinado na tabela Hudi, você pode se beneficiar das permissões do AWS Lake Formation. As permissões do Lake Formation permitem restringir o acesso a tabelas, colunas ou linhas específicas e, em seguida, consultar as tabelas Hudi por meio do Amazon Athena com controle de acesso refinado. Vamos configurar a permissão do Lake Formation para a tabela Hudi MoR.
Pré-requisitos
Aqui estão os pré-requisitos para este tutorial:
- Conclua a seção anterior Rastrear uma tabela Hudi MoR usando o rastreador AWS Glue com permissões de dados do AWS Lake Formation.
- Crie um usuário IAM DataAnalyst, que tenha uma política gerenciada pela AWS AmazonAthenaFullAccess.
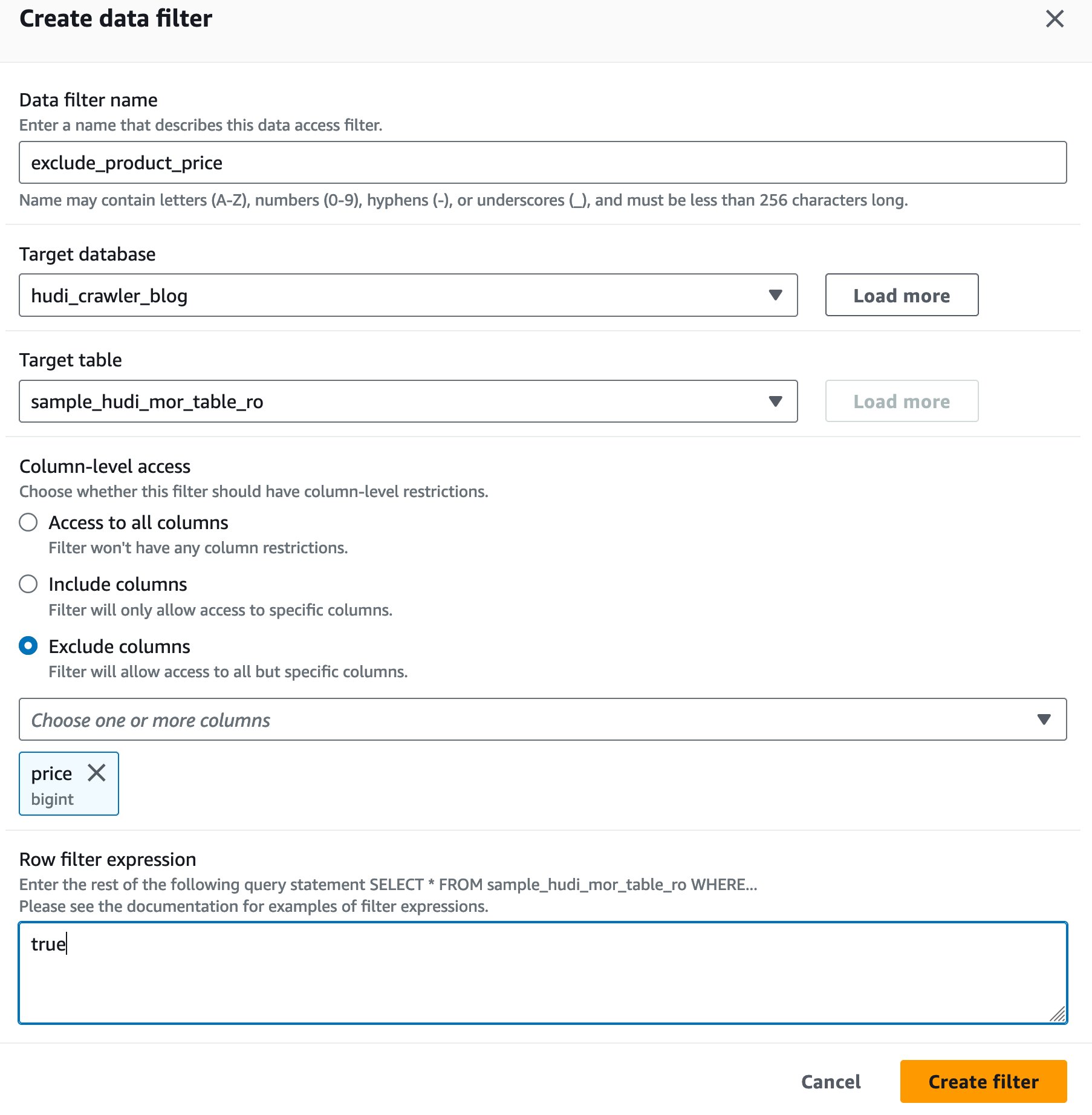
Criar um filtro de célula de dados do Lake Formation
Vamos primeiro configurar um filtro para a tabela otimizada para leitura de MoR.
- Faça login no console do Lake Formation como administrador do data lake.
- Escolha Filtros de dados.
- Escolha Crie um novo filtro.
- Escolha Nome do filtro de dados, entrar
exclude_product_price. - Escolha Banco de dados de destino, escolha o banco de dados
hudi_crawler_blog. - Escolha Tabela de destino, escolha a mesa
sample_hudi_mor_table_ro. - Escolha Nível de coluna acessar, selecione Excluir colunase escolha o preço da coluna.
- Escolha Expressão de filtro de linha, entrar
true. - Escolha Criar filtro.
Conceda permissões do Lake Formation ao usuário DataAnalyst
Conclua as etapas a seguir para conceder permissão do Lake Formation ao DataAnalyst usuário
- No console do Lake Formation, escolha Permissões do data lake.
- Escolha Conceda.
- Escolha Principais, escolha Usuários e funções IAMe escolha o usuário
DataAnalyst. - Escolha Tags LF ou recursos de catálogo, escolha Recursos de catálogo de dados nomeados.
- Escolha banco de dados, escolha o banco de dados
hudi_crawler_blog. - Escolha Tabela – opcional, escolha a mesa
sample_hudi_mor_table_ro. - Escolha Filtros de dados – opcional, selecione
exclude_product_price. - Escolha Permissões de filtro de dados, selecione Selecionar.
- Escolha Conceda.
Você concedeu permissão ao Lake Formation no banco de dados hudi_crawler_blog e a mesa sample_hudi_mor_table_ro, excluindo a coluna price para o usuário DataAnalyst. Agora vamos validar o acesso do usuário aos dados usando o Athena.
- Faça login no console do Athena como usuário do DataAnalyst.
- No editor de consultas, execute a seguinte consulta:
A captura de tela a seguir mostra nossa saída:
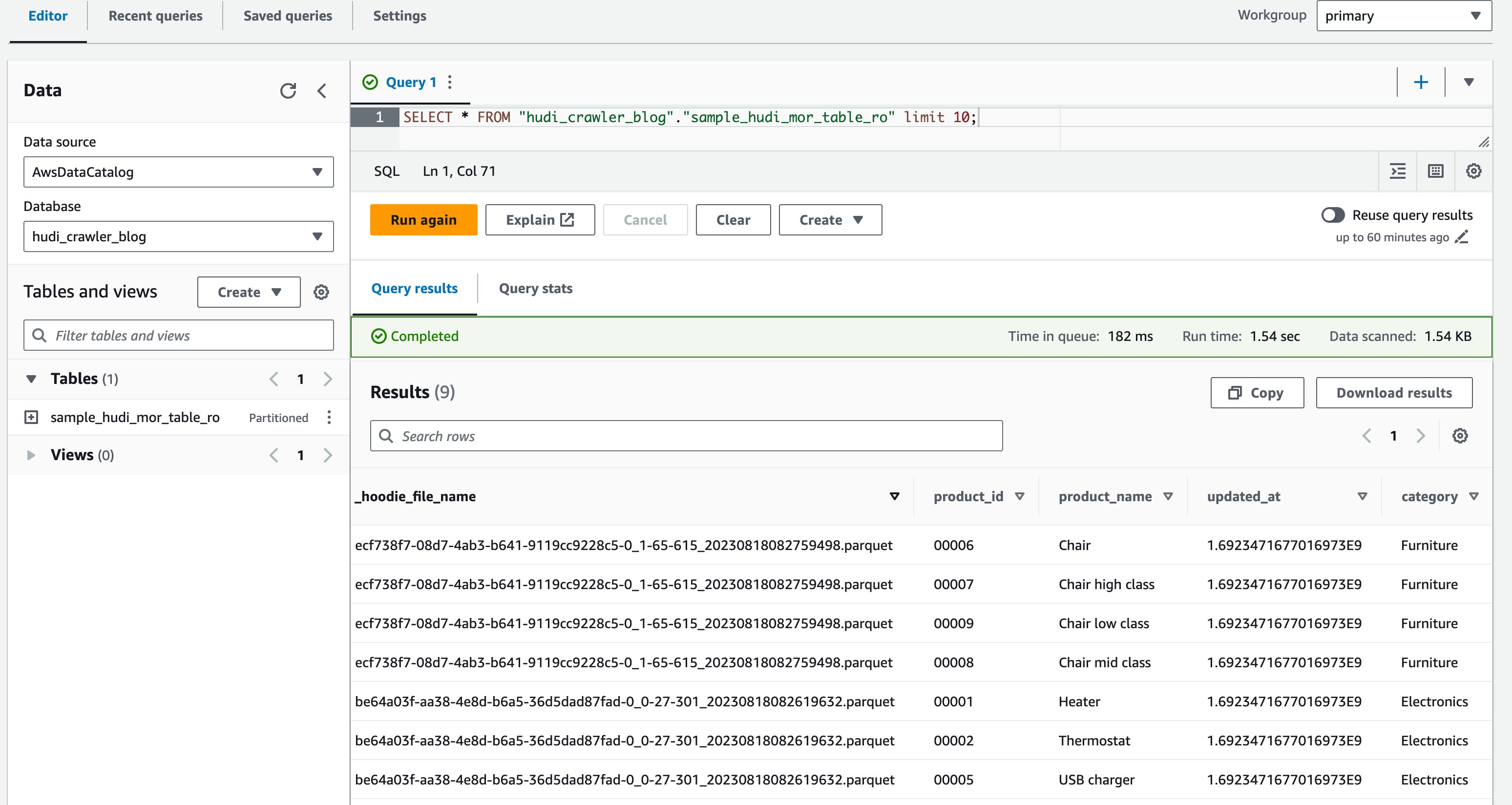
Agora você validou que a coluna price não é mostrado, mas as outras colunas product_id, product_name, update_at e category são mostrados.
limpar
Para evitar cobranças indesejadas em sua conta da AWS, exclua os seguintes recursos da AWS:
- Excluir banco de dados AWS Glue
hudi_crawler_blog. - Excluir rastreadores do AWS Glue
hudi_cow_crawlerehudi_mor_crawler. - Exclua os arquivos do Amazon S3 em
s3://your_s3_bucket/data/sample_hudi_cow_table/es3://your_s3_bucket/data/sample_hudi_mor_table/.
Conclusão
Esta postagem demonstrou como os rastreadores do AWS Glue funcionam para tabelas Hudi. Com o suporte para o rastreador Hudi, você pode passar rapidamente a usar o AWS Glue Data Catalog como seu catálogo de tabelas Hudi principal. Você pode começar a construir seu data lake transacional sem servidor usando Hudi na AWS usando AWS Glue, AWS Glue Data Catalog e controles de acesso refinados do Lake Formation para tabelas e formatos suportados por mecanismos analíticos da AWS.
Sobre os autores
 Noritaka Sekiyama é Arquiteto Principal de Big Data na equipe do AWS Glue. Ele trabalha baseado em Tóquio, Japão. Ele é responsável por construir artefatos de software para ajudar os clientes. Em seu tempo livre, ele gosta de andar de bicicleta com sua bicicleta de estrada.
Noritaka Sekiyama é Arquiteto Principal de Big Data na equipe do AWS Glue. Ele trabalha baseado em Tóquio, Japão. Ele é responsável por construir artefatos de software para ajudar os clientes. Em seu tempo livre, ele gosta de andar de bicicleta com sua bicicleta de estrada.
 Kyle Duong é engenheiro de desenvolvimento de software na equipe AWS Glue e Lake Formation. Ele é apaixonado pela construção de tecnologias de big data e sistemas distribuídos.
Kyle Duong é engenheiro de desenvolvimento de software na equipe AWS Glue e Lake Formation. Ele é apaixonado pela construção de tecnologias de big data e sistemas distribuídos.
 Sandeep Adwankar é gerente de produto técnico sênior da AWS. Com sede na área da baía da Califórnia, ele trabalha com clientes em todo o mundo para traduzir requisitos comerciais e técnicos em produtos que permitem aos clientes melhorar a forma como gerenciam, protegem e acessam dados.
Sandeep Adwankar é gerente de produto técnico sênior da AWS. Com sede na área da baía da Califórnia, ele trabalha com clientes em todo o mundo para traduzir requisitos comerciais e técnicos em produtos que permitem aos clientes melhorar a forma como gerenciam, protegem e acessam dados.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :tem
- :é
- :não
- :onde
- $UP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- Capaz
- Sobre
- Acesso
- Acesso a dados
- acessando
- Conta
- Açao Social
- adicionar
- adicionado
- Adição
- adotado
- Adoção
- avançado
- Depois de
- Todos os Produtos
- permitir
- Permitindo
- permite
- tb
- Amazon
- Amazona atena
- Amazon Web Services
- an
- Análises
- analítica
- e
- Outro
- qualquer
- apache
- Apache Spark
- api
- aparece
- Aplicação
- Desenvolvimento de Aplicações
- Aplicar
- SOMOS
- ÁREA
- por aí
- AS
- At
- automaticamente
- evitar
- AWS
- Cola AWS
- Formação AWS Lake
- base
- baseado
- Bay
- BE
- Porque
- sido
- beneficiar
- Melhor
- Grande
- Big Data
- Traz
- Prédio
- construído
- negócio
- mas a
- by
- Califórnia
- chamada
- CAN
- capacidades
- capacidade
- casas
- catálogo
- catálogos
- Categorias
- célula
- desafios
- alterar
- mudado
- Alterações
- acusações
- Escolha
- Coluna
- colunas
- combinação
- commit
- comprometido
- completar
- integrações
- componente
- Configuração
- cônsul
- contém
- conteúdo
- continuamente
- ao controle
- controles
- poderia
- rastreador
- crio
- criado
- cria
- Credenciais
- Clientes
- dados,
- integração de dados
- lago data
- data warehouse
- banco de dados
- bases de dados
- conjuntos de dados
- definição
- definições
- Delta
- demonstraram
- demonstra
- profundidade
- Desenvolvimento
- diretamente
- descobrir
- distribuído
- Sistemas distribuídos
- do
- parece
- durante
- cada
- mais fácil
- facilmente
- editor
- efetivamente
- eficiente
- permitir
- habilitado
- engenheiro
- Engenheiros
- Motores
- Entrar
- Éter (ETH)
- evolução
- excluindo
- extrato
- mais rápido
- menos
- Envie o
- Arquivos
- filtro
- filtros
- Encontre
- Primeiro nome
- primeira vez
- seguinte
- Escolha
- formato
- treinamento
- freqüentemente
- da
- dado
- globo
- Go
- conceder
- concedido
- Guias
- Hadoop
- Ter
- he
- ajudar
- ajuda
- sua
- Colméia
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- IAM
- if
- implicações
- melhorar
- in
- Incluindo
- incrementais
- INFORMAÇÕES
- em vez disso
- integrar
- integração
- Interface
- para dentro
- introduzindo
- IT
- Japão
- jpg
- manutenção
- lago
- lagos
- mais recente
- lançamento
- APRENDER
- aprendizagem
- menos
- LIMITE
- Line
- Lista
- localizado
- localização
- locais
- registrado
- máquina
- aprendizado de máquina
- manutenção
- fazer
- FAZ
- gerencia
- gerenciados
- Gerente
- gestão
- manual
- máximo
- fusão
- metadados
- migrando
- migração
- ML
- mais
- a maioria
- mover
- múltiplo
- nome
- nativo
- você merece...
- necessário
- Novo
- recentemente
- Próximo
- agora
- of
- on
- ONE
- só
- aberto
- open source
- otimizado
- Opção
- or
- Outros
- A Nossa
- saída
- parte
- apaixonado
- caminho
- caminhos
- atuação
- permissão
- permissões
- platão
- Inteligência de Dados Platão
- PlatãoData
- Popular
- populosa
- Publique
- Preparar
- pré-requisitos
- anterior
- preço
- primário
- Diretor
- em processamento
- Produto
- gerente de produto
- Produtos
- fornecer
- fornecido
- fornece
- consultas
- rapidamente
- Leia
- reais
- em tempo real
- em tempo real
- recentemente
- registro
- cadastre-se
- registrado
- substituir
- Requisitos
- Recursos
- responsável
- restringir
- estrada
- Tipo
- LINHA
- Execute
- mesmo
- cronograma
- programado
- Sdk
- Seção
- seguro
- Vejo
- selecionar
- senior
- Serverless
- serviço
- Serviços
- conjunto
- Configurações
- mostrando
- Shows
- simplifica
- desde
- solteiro
- Fatia
- Instantâneo
- So
- Software
- desenvolvimento de software
- fonte
- Fontes
- Faísca
- específico
- começo
- Estado
- Passo
- Passos
- armazenadas
- de streaming
- córregos
- estudo
- entraram com sucesso
- tal
- ajuda
- Suportado
- sincronizar.
- sistemas
- mesa
- Profissionais
- Dados Técnicos:
- Tecnologias
- que
- A
- deles
- então
- Lá.
- deles
- isto
- três
- Através da
- tempo
- vezes
- para
- Tóquio
- topo
- transacional
- Transações
- traduzir
- atravessar
- desencadear
- desencadeado
- tutorial
- dois
- tipos
- típico
- para
- não desejado
- Atualizar
- Atualizada
- Atualizações
- usar
- caso de uso
- usava
- Utilizador
- usuários
- usos
- utilização
- VALIDAR
- validado
- Valores
- versão
- visual
- Armazém
- we
- web
- serviços web
- BEM
- quando
- qual
- enquanto
- QUEM
- precisarão
- de
- sem
- Atividades:
- trabalho
- escrever
- escrito
- Você
- investimentos
- você mesmo
- zefirnet