Amazon RedShift é um data warehouse em nuvem totalmente gerenciado e em escala de petabytes que é usado por dezenas de milhares de clientes para processar exabytes de dados todos os dias para potencializar sua carga de trabalho analítica. Você pode estruturar seus dados, medir processos de negócios e obter insights valiosos rapidamente usando um modelo dimensional. O Amazon Redshift fornece recursos integrados para acelerar o processo de modelagem, orquestração e relatórios de um modelo dimensional.
Neste post, discutimos como implementar um modelo dimensional, especificamente o metodologia Kimball. Discutimos a implementação de dimensões e fatos no Amazon Redshift. Mostramos como executar extração, transformação e carregamento (ELT), um processo de integração focado em obter os dados brutos de um data lake em uma camada de preparação para executar a modelagem. No geral, a postagem fornecerá uma compreensão clara de como usar a modelagem dimensional no Amazon Redshift.
Visão geral da solução
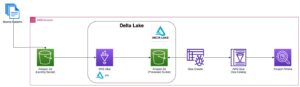
O diagrama a seguir ilustra a arquitetura da solução.

Nas seções a seguir, primeiro discutimos e demonstramos os principais aspectos do modelo dimensional. Depois disso, criamos um data mart usando o Amazon Redshift com um modelo de dados dimensional incluindo dimensões e tabelas de fatos. Os dados são carregados e testados usando o CÓPIA comando, os dados nas dimensões são carregados usando o MERGE declaração, e os fatos serão agregados às dimensões de onde os insights são derivados. Agendamos o carregamento das dimensões e fatos usando o Editor de consultas do Amazon Redshift V2. Por último, usamos AmazonQuickSight para obter informações sobre os dados modelados na forma de um painel do QuickSight.
Para esta solução, usamos um conjunto de dados de amostra (normalizado) fornecido pelo Amazon Redshift para vendas de ingressos de eventos. Para esta postagem, reduzimos o conjunto de dados para fins de simplicidade e demonstração. As tabelas a seguir mostram exemplos de dados para vendas de ingressos e locais.


De acordo com Metodologia de modelagem dimensional de Kimball, há quatro etapas principais na criação de um modelo dimensional:
- Identifique o processo de negócios.
- Declare a granulação de seus dados.
- Identificar e implementar as dimensões.
- Identifique e implemente os fatos.
Além disso, adicionamos uma quinta etapa para fins de demonstração, que é relatar e analisar eventos de negócios.
Pré-requisitos
Para este passo a passo, você deve ter os seguintes pré-requisitos:
Identifique o processo de negócios
Em termos simples, identificar o processo de negócios é identificar um evento mensurável que gera dados dentro de uma organização. Normalmente, as empresas possuem algum tipo de sistema fonte operacional que gera seus dados em seu formato bruto. Este é um bom ponto de partida para identificar várias fontes para um processo de negócios.
O processo de negócio é então persistido como um data mart na forma de dimensões e fatos. Observando nosso conjunto de dados de amostra mencionado anteriormente, podemos ver claramente que o processo de negócios são as vendas feitas para um determinado evento.
Um erro comum cometido é usar os departamentos de uma empresa como processo de negócios. Os dados (processo de negócios) precisam ser integrados em vários departamentos; nesse caso, o marketing pode acessar os dados de vendas. Identificar o processo de negócios correto é crítico - errar nesta etapa pode afetar todo o data mart (pode fazer com que a granulação seja duplicada e métricas incorretas nos relatórios finais).
Declare a granulação dos seus dados
Declarar a granulação é o ato de identificar exclusivamente um registro em sua fonte de dados. A granulação é usada na tabela de fatos para medir com precisão os dados e permitir que você acumule ainda mais. Em nosso exemplo, isso pode ser um item de linha no processo comercial de vendas.
Em nosso caso de uso, uma venda pode ser identificada exclusivamente observando o momento da transação em que a venda ocorreu; este será o nível mais atômico.

Identifique e implemente as dimensões
Sua tabela de dimensões descreve sua tabela de fatos e seus atributos. Ao identificar o contexto descritivo de seu processo de negócios, você armazena o texto em uma tabela separada, mantendo em mente a granulação da tabela de fatos. Ao unir a tabela de dimensões à tabela de fatos, deve haver apenas uma única linha associada à tabela de fatos. Em nosso exemplo, usamos a tabela a seguir para ser separada em uma tabela de dimensões; esses campos descrevem os fatos que mediremos.
Ao projetar a estrutura do modelo dimensional (o esquema), você pode criar um estrela or floco de neve esquema. A estrutura deve estar alinhada com o processo de negócios; portanto, um esquema em estrela é mais adequado para nosso exemplo. A figura a seguir mostra nosso Diagrama Entidade Relacionamento (ERD).

Nas seções a seguir, detalhamos as etapas para implementar as dimensões.
Prepare os dados de origem
Antes de podermos criar e carregar a tabela de dimensões, precisamos dos dados de origem. Portanto, preparamos os dados de origem em uma tabela temporária ou temporária. Isto é muitas vezes referido como o camada de preparação, que é a cópia bruta dos dados de origem. Para fazer isso no Amazon Redshift, usamos o comando COPIAR para carregar os dados do bucket S3 público dimensional-modeling-in-amazon-redshift localizado no us-east-1 Região. Observe que o comando COPY usa um Gerenciamento de acesso e identidade da AWS (IAM) função com acesso ao Amazon S3. O papel precisa ser associado ao cluster. Conclua as etapas a seguir para preparar os dados de origem:
- Criar o
venuetabela de origem:
- Carregue os dados do local:
- Criar o
salestabela de origem:
- Carregue os dados da fonte de vendas:
- Criar o
calendartabela:
- Carregue os dados do calendário:
Criar a tabela de dimensões
Projetar a tabela de dimensões pode depender de seus requisitos de negócios — por exemplo, você precisa acompanhar as alterações nos dados ao longo do tempo? Há sete tipos de dimensões diferentes. Para o nosso exemplo, usamos Tipo 1 porque não precisamos rastrear mudanças históricas. Para mais informações sobre o tipo 2, consulte Simplifique o carregamento de dados em dimensões de alteração lenta do Tipo 2 no Amazon Redshift. A tabela de dimensões será desnormalizada com uma chave primária, chave substituta e alguns campos adicionados para indicar alterações na tabela. Veja o seguinte código:
Algumas observações sobre a criação da tabela de dimensões:
- Os nomes dos campos são transformados em nomes amigáveis para os negócios
- Nossa chave primária é
VenueID, que usamos para identificar exclusivamente um local no qual a venda ocorreu - Duas linhas adicionais serão adicionadas, indicando quando um registro foi inserido e atualizado (para rastrear alterações)
- Estamos usando um Estilo de distribuição AUTOMÁTICO para dar ao Amazon Redshift a responsabilidade de escolher e ajustar o estilo de distribuição
Outro fator importante a considerar na modelagem dimensional é o uso de chaves substitutas. As chaves substitutas são chaves artificiais usadas na modelagem dimensional para identificar exclusivamente cada registro em uma tabela de dimensões. Eles são normalmente gerados como um número inteiro sequencial e não têm nenhum significado no domínio de negócios. Elas oferecem vários benefícios, como garantir a exclusividade e melhorar o desempenho nas junções, porque normalmente são menores que as chaves naturais e, como chaves substitutas, não mudam com o tempo. Isso nos permite ser consistentes e juntar fatos e dimensões com mais facilidade.
No Amazon Redshift, as chaves substitutas geralmente são criadas usando a palavra-chave IDENTITY. Por exemplo, a instrução CREATE anterior cria uma tabela de dimensão com um VenueSkey Chave substituta. O VenueSkey coluna é preenchida automaticamente com valores exclusivos conforme novas linhas são adicionadas à tabela. Esta coluna pode então ser usada para juntar a tabela do local à FactSaleTransactions tabela.
Algumas dicas para projetar chaves substitutas:
- Use um tipo de dados pequeno e de largura fixa para a chave substituta. Isso melhorará o desempenho e reduzirá o espaço de armazenamento.
- Use a palavra-chave IDENTITY ou gere a chave substituta usando um valor sequencial ou GUID. Isso garantirá que a chave substituta seja exclusiva e não possa ser alterada.
Carregue a tabela dim usando MERGE
Existem inúmeras maneiras de carregar sua mesa dim. Certos fatores precisam ser considerados, por exemplo, desempenho, volume de dados e talvez tempos de carregamento do SLA. Com o MERGE declaração, executamos um upsert sem precisar especificar vários comandos de inserção e atualização. Você pode configurar o MERGE declaração em um procedimento armazenado para preencher os dados. Em seguida, você agenda o procedimento armazenado para ser executado programaticamente por meio do editor de consultas, que demonstramos mais adiante na postagem. O código a seguir cria um procedimento armazenado chamado SalesMart.DimVenueLoad:
Algumas notas sobre o carregamento da dimensão:
- Quando um registro for inserido pela primeira vez, a data inserida e a data atualizada serão preenchidas. Quando algum valor muda, os dados são atualizados e a data atualizada reflete a data em que foi alterada. A data inserida permanece.
- Como os dados serão usados por usuários corporativos, precisamos substituir os valores NULL, se houver, por valores mais apropriados aos negócios.
Identifique e implemente os fatos
Agora que declaramos nosso grão como o evento de uma venda que ocorreu em um horário específico, nossa tabela de fatos armazenará os fatos numéricos para nosso processo de negócios.
Identificamos os seguintes fatos numéricos para medir:
- Quantidade de ingressos vendidos por venda
- comissão pela venda
Implementando o fato
Tem três tipos de tabelas de fatos (tabela de fatos de transações, tabela de fatos de instantâneos periódicos e tabela de fatos de instantâneos acumulativos). Cada um oferece uma visão diferente do processo de negócios. Para nosso exemplo, usamos uma tabela de fatos de transação. Conclua as seguintes etapas:
- Criar a tabela de fatos
Uma data inserida com um valor padrão é adicionada, indicando se e quando um registro foi carregado. Você pode usar isso ao recarregar a tabela de fatos para remover os dados já carregados para evitar duplicatas.
O carregamento da tabela de fatos consiste em uma simples instrução de inserção que une suas dimensões associadas. Nós nos juntamos a partir do DimVenue tabela que foi criada, que descreve nossos fatos. É uma prática recomendada, mas é opcional ter data do calendário dimensões, que permitem ao usuário final navegar na tabela de fatos. Os dados podem ser carregados quando houver uma nova venda ou diariamente; é aqui que a data inserida ou a data de carregamento são úteis.
Carregamos a tabela de fatos usando um procedimento armazenado e usamos um parâmetro de data.
- Crie o procedimento armazenado com o seguinte código. Para manter a mesma integridade de dados que aplicamos no carregamento da dimensão, substituímos os valores NULL, se houver, por valores mais apropriados aos negócios:
- Carregue os dados chamando o procedimento com o seguinte comando:
Agendar o carregamento de dados
Agora podemos automatizar o processo de modelagem agendando os procedimentos armazenados no Amazon Redshift Query Editor V2. Conclua as seguintes etapas:
- Primeiro chamamos o dimension load e depois que o dimension load é executado com sucesso, o fact load começa:
Se o carregamento da dimensão falhar, o carregamento de fatos não será executado. Isso garante consistência nos dados porque não queremos carregar a tabela de fatos com dimensões desatualizadas.
- Para agendar a carga, escolha Programação do dia no Editor de consultas V2.

- Agendamos a consulta para ser executada todos os dias às 5h.
- Opcionalmente, você pode adicionar notificações de falha ativando Serviço de notificação simples da Amazon (Amazon SNS) notificações.

Relate e analise os dados no Amazon Quicksight
O QuickSight é um serviço de business intelligence que facilita a entrega de insights. Como um serviço totalmente gerenciado, o QuickSight permite que você crie e publique facilmente painéis interativos que podem ser acessados de qualquer dispositivo e incorporados em seus aplicativos, portais e sites.
Usamos nosso data mart para apresentar visualmente os fatos na forma de um painel. Para começar e configurar o QuickSight, consulte Criando um conjunto de dados usando um banco de dados que não é descoberto automaticamente.
Depois de criar sua fonte de dados no QuickSight, juntamos os dados modelados (data mart) com base em nossa chave substituta skey. Usamos esse conjunto de dados para visualizar o data mart.

Nosso painel final conterá os insights do data mart e responderá a perguntas críticas de negócios, como comissão total por local e datas com as vendas mais altas. A captura de tela a seguir mostra o produto final do data mart.

limpar
Para evitar cobranças futuras, exclua todos os recursos que você criou como parte desta postagem.
Conclusão
Agora implementamos com sucesso um data mart usando nosso DimVenue, DimCalendar e FactSaleTransactions tabelas. Nosso armazém não está completo; à medida que podemos expandir o data mart com mais fatos e implementar mais marts, e conforme o processo de negócios e os requisitos crescem com o tempo, o data warehouse também crescerá. Nesta postagem, fornecemos uma visão completa sobre como entender e implementar a modelagem dimensional no Amazon Redshift.
Comece com o seu Amazon RedShift modelo dimensional hoje.
Sobre os autores
 Bernard Verster é um engenheiro de nuvem experiente com anos de experiência na criação de modelos de dados escaláveis e eficientes, definindo estratégias de integração de dados e garantindo governança e segurança de dados. Ele é apaixonado pelo uso de dados para gerar insights, ao mesmo tempo em que se alinha aos requisitos e objetivos de negócios.
Bernard Verster é um engenheiro de nuvem experiente com anos de experiência na criação de modelos de dados escaláveis e eficientes, definindo estratégias de integração de dados e garantindo governança e segurança de dados. Ele é apaixonado pelo uso de dados para gerar insights, ao mesmo tempo em que se alinha aos requisitos e objetivos de negócios.
 Abhishek Pan é um especialista em WWSO SA-Analytics que trabalha com clientes do setor público da AWS na Índia. Ele interage com os clientes para definir a estratégia baseada em dados, fornecer sessões de aprofundamento em casos de uso analítico e projetar aplicativos analíticos escaláveis e de alto desempenho. Ele tem 12 anos de experiência e é apaixonado por bancos de dados, análises e AI/ML. Ele é um viajante ávido e tenta capturar o mundo através das lentes de sua câmera.
Abhishek Pan é um especialista em WWSO SA-Analytics que trabalha com clientes do setor público da AWS na Índia. Ele interage com os clientes para definir a estratégia baseada em dados, fornecer sessões de aprofundamento em casos de uso analítico e projetar aplicativos analíticos escaláveis e de alto desempenho. Ele tem 12 anos de experiência e é apaixonado por bancos de dados, análises e AI/ML. Ele é um viajante ávido e tenta capturar o mundo através das lentes de sua câmera.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Automotivo / EVs, Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- BlockOffsets. Modernizando a Propriedade de Compensação Ambiental. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :tem
- :é
- :não
- :onde
- $UP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- Sobre
- acelerar
- Acesso
- acessadas
- exatamente
- em
- Aja
- adicionar
- adicionado
- Adicional
- Depois de
- AI / ML
- alinhar
- alinhando
- permitir
- permite
- já
- am
- Amazon
- Amazon Web Services
- an
- análise
- Análises
- analítica
- analisar
- e
- responder
- qualquer
- aplicações
- aplicado
- apropriado
- arquitetura
- SOMOS
- artificial
- AS
- aspectos
- associado
- At
- atributos
- auto
- automatizar
- automaticamente
- evitar
- AWS
- b
- baseado
- BE
- Porque
- começar
- Benefícios
- MELHOR
- construídas em
- negócio
- inteligência de negócios
- Processo de negócio
- processos de negócios
- mas a
- by
- Calendário
- chamada
- chamado
- chamada
- Câmera
- CAN
- capturar
- casas
- casos
- Causar
- certo
- alterar
- mudado
- Alterações
- mudança
- personagem
- acusações
- Escolha
- remover filtragem
- claramente
- de perto
- Na nuvem
- código
- Coluna
- vem
- de referência
- comum
- Empresas
- Empresa
- completar
- Considerar
- consistente
- consiste
- contexto
- correta
- poderia
- crio
- criado
- cria
- Criar
- criação
- crítico
- Clientes
- diariamente
- painel de instrumentos
- painéis
- dados,
- integração de dados
- lago data
- data warehouse
- orientado por dados
- Estratégia baseada em dados
- banco de dados
- bases de dados
- Data
- Datas
- datetime
- dia
- profundo
- mergulho profundo
- Padrão
- definição
- entregar
- demonstrar
- departamentos
- Derivado
- descreve
- Design
- concepção
- detalhe
- dispositivo
- diferente
- Dimensão
- dimensões
- discutir
- distinto
- distribuição
- do
- domínio
- feito
- não
- down
- distância
- duplicatas
- cada
- Mais cedo
- facilmente
- fácil
- editor
- eficiente
- ou
- incorporado
- permitir
- permitindo
- final
- end-to-end
- envolve
- engenheiro
- garantir
- garante
- assegurando
- Todo
- entidade
- Éter (ETH)
- Evento
- eventos
- Cada
- todo dia
- exemplo
- exemplos
- Expandir
- vasta experiência
- experiente
- Exposição
- extrato
- fato
- fator
- fatores
- fatos
- falha
- Falha
- Funcionalidades
- poucos
- campo
- Campos
- quinto
- Figura
- filtro
- final
- Primeiro nome
- primeira vez
- caber
- focado
- seguinte
- Escolha
- formulário
- formato
- quatro
- da
- totalmente
- mais distante
- futuro
- Ganho
- gerar
- gerado
- gera
- ter
- obtendo
- OFERTE
- dado
- Bom estado, com sinais de uso
- governo
- Cresça:
- acessível
- Ter
- he
- mais
- sua
- histórico
- Feriado
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- IAM
- identificado
- identificar
- identificar
- Identidade
- if
- ilustra
- Impacto
- executar
- implementado
- implementação
- importante
- melhorar
- melhorar
- in
- Incluindo
- Índia
- indicam
- indicador
- info
- insights
- integrado
- integração
- integridade
- Inteligência
- interativo
- para dentro
- IT
- ESTÁ
- juntar
- ingressou
- juntando
- Junta
- jpg
- Guarda
- manutenção
- Chave
- chaves
- lago
- língua
- mais tarde
- mais recente
- camada
- esquerda
- Lente
- Permite
- Nível
- Line
- carregar
- carregamento
- cargas
- localizado
- procurando
- moldadas
- FAZ
- gerenciados
- Marketing
- correspondido
- significado
- a medida
- mencionado
- ir
- Métrica
- mente
- erro
- modelo
- modelagem
- modelagem
- modelos
- Mês
- mais
- a maioria
- múltiplo
- nomes
- natural
- Navegar
- você merece...
- necessitando
- Cria
- Novo
- Notas
- notificação
- notificações
- agora
- numeroso
- objetivos
- of
- oferecer
- frequentemente
- on
- só
- operacional
- or
- organização
- A Nossa
- Acima de
- global
- parâmetro
- parte
- apaixonado
- para
- realizar
- atuação
- possivelmente
- periodicamente
- Lugar
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- populosa
- Publique
- poder
- prática
- pré-requisitos
- presente
- primário
- procedimentos
- procedimentos
- processo
- processos
- Produto
- fornecer
- fornecido
- fornece
- público
- publicar
- fins
- Frequentes
- rapidamente
- aumentar
- Cru
- dados não tratados
- registro
- registros
- reduzir
- a que se refere
- reflete
- região
- relacionamento
- permanece
- remover
- substituir
- Denunciar
- Relatórios
- Relatórios
- Requisitos
- Recursos
- responsabilidade
- Tipo
- Rolo
- LINHA
- Execute
- é executado
- Promoção
- vendas
- mesmo
- Conjunto de dados de amostra
- escalável
- cronograma
- agendamento
- seções
- setor
- segurança
- Vejo
- separado
- serve
- serviço
- Serviços
- sessões
- conjunto
- vários
- rede de apoio social
- mostrar
- Shows
- simples
- simplicidade
- solteiro
- Lentamente
- pequeno
- menor
- Instantâneo
- So
- vendido
- solução
- alguns
- fonte
- Fontes
- Espaço
- especialista
- específico
- especificamente
- Etapa
- encenação
- Estrela
- começado
- Comece
- Declaração
- Passo
- Passos
- armazenamento
- loja
- armazenadas
- estratégias
- Estratégia
- estrutura
- bem sucedido
- entraram com sucesso
- tal
- .
- mesa
- temporário
- dezenas
- condições
- do que
- que
- A
- A fonte
- o mundo
- deles
- então
- Lá.
- assim sendo
- Este
- deles
- isto
- milhares
- Através da
- bilhete
- venda de ingressos
- bilhetes
- tempo
- vezes
- timestamp
- dicas
- para
- hoje
- juntos
- levou
- Total
- pista
- transação
- Transformar
- transformado
- viajante
- tipo
- tipos
- tipicamente
- compreensão
- único
- unicamente
- singularidade
- desconhecido
- Atualizar
- Atualizada
- us
- Uso
- usar
- caso de uso
- usava
- usuários
- usos
- utilização
- geralmente
- Valioso
- valor
- Valores
- vário
- Local
- locais
- via
- Ver
- volume
- Passo a passo
- queremos
- Armazém
- foi
- maneiras
- we
- web
- serviços web
- sites
- semana
- quando
- qual
- enquanto
- precisarão
- de
- dentro
- sem
- trabalhar
- mundo
- Errado
- ano
- anos
- Você
- investimentos
- zefirnet