Estúdio do AWS Glue agora está integrado com Produção de dados do AWS Glue. O AWS Glue Studio é uma interface gráfica que facilita a criação, execução e monitoramento de trabalhos de extração, transformação e carregamento (ETL) em Cola AWS. DataBrew é uma ferramenta visual de preparação de dados que permite limpar e normalizar dados sem escrever nenhum código. As mais de 200 transformações que ele fornece agora estão disponíveis para serem usadas em um trabalho visual do AWS Glue Studio.
No DataBrew, um receita é um conjunto de etapas de transformação de dados que você pode criar interativamente em sua interface visual intuitiva. Nesta postagem, você verá como criar uma receita no DataBrew e aplicá-la como parte de um trabalho ETL visual do AWS Glue Studio.
Os usuários existentes do DataBrew também se beneficiarão dessa integração — agora você pode executar suas receitas como parte de um fluxo de trabalho visual maior com todos os outros componentes que o AWS Glue Studio oferece, além de poder usar a configuração de trabalho avançada e a versão mais recente do mecanismo AWS Glue .
Esta integração traz benefícios distintos para os usuários existentes de ambas as ferramentas:
- Você tem uma visão centralizada no AWS Glue Studio do diagrama ETL geral, de ponta a ponta
- Você pode definir uma receita interativamente, vendo valores, estatísticas e distribuição no console do DataBrew e, em seguida, reutilizar essa lógica de processamento testada e com versão em tarefas visuais do AWS Glue Studio
- Você pode orquestrar várias receitas DataBrew em um trabalho ETL do AWS Glue ou até mesmo vários trabalhos usando fluxos de trabalho do AWS Glue
- As receitas do DataBrew agora podem usar os recursos de trabalho do AWS Glue, como marcadores para processamento de dados incrementais, novas tentativas automáticas, dimensionamento automático ou agrupamento de pequenos arquivos para maior eficiência
Visão geral da solução
Em nosso caso de uso fictício, o requisito é limpar um conjunto de dados sintéticos de reivindicações médicas criado para esta postagem, que apresenta alguns problemas de qualidade de dados introduzidos com o propósito de demonstrar os recursos do DataBrew na preparação de dados. Em seguida, os dados das reivindicações são inseridos no catálogo (para que fiquem visíveis para os analistas), depois de enriquecidos com alguns detalhes relevantes sobre os provedores médicos correspondentes provenientes de uma fonte separada.
A solução consiste em um trabalho visual do AWS Glue Studio que lê dois arquivos CSV com declarações e provedores, respectivamente. O trabalho aplica uma receita do primeiro para resolver os problemas de qualidade, seleciona colunas do segundo, une os dois conjuntos de dados e, finalmente, armazena o resultado em Serviço de armazenamento simples da Amazon (Amazon S3), criando uma tabela no catálogo para que os dados de saída possam ser utilizados por outras ferramentas como Amazona atena.
Criar uma receita DataBrew
Comece registrando o armazenamento de dados para o arquivo de reivindicações. Isso permitirá que você construa a receita em seu editor interativo usando os dados reais para que você possa avaliar o resultado das transformações à medida que as define.
- Baixe o arquivo CSV de reivindicações usando o seguinte link: Alabama_claims_data_Jun2023.csv.
- No console DataBrew, escolha Conjuntos de dados no painel de navegação e escolha Conecte um novo conjunto de dados.
- Escolha a opção Upload de arquivo.
- Escolha Nome do conjunto de dados, entrar
Alabama claims. - Escolha Selecione um arquivo para carregar, escolha o arquivo que você acabou de baixar no seu computador.
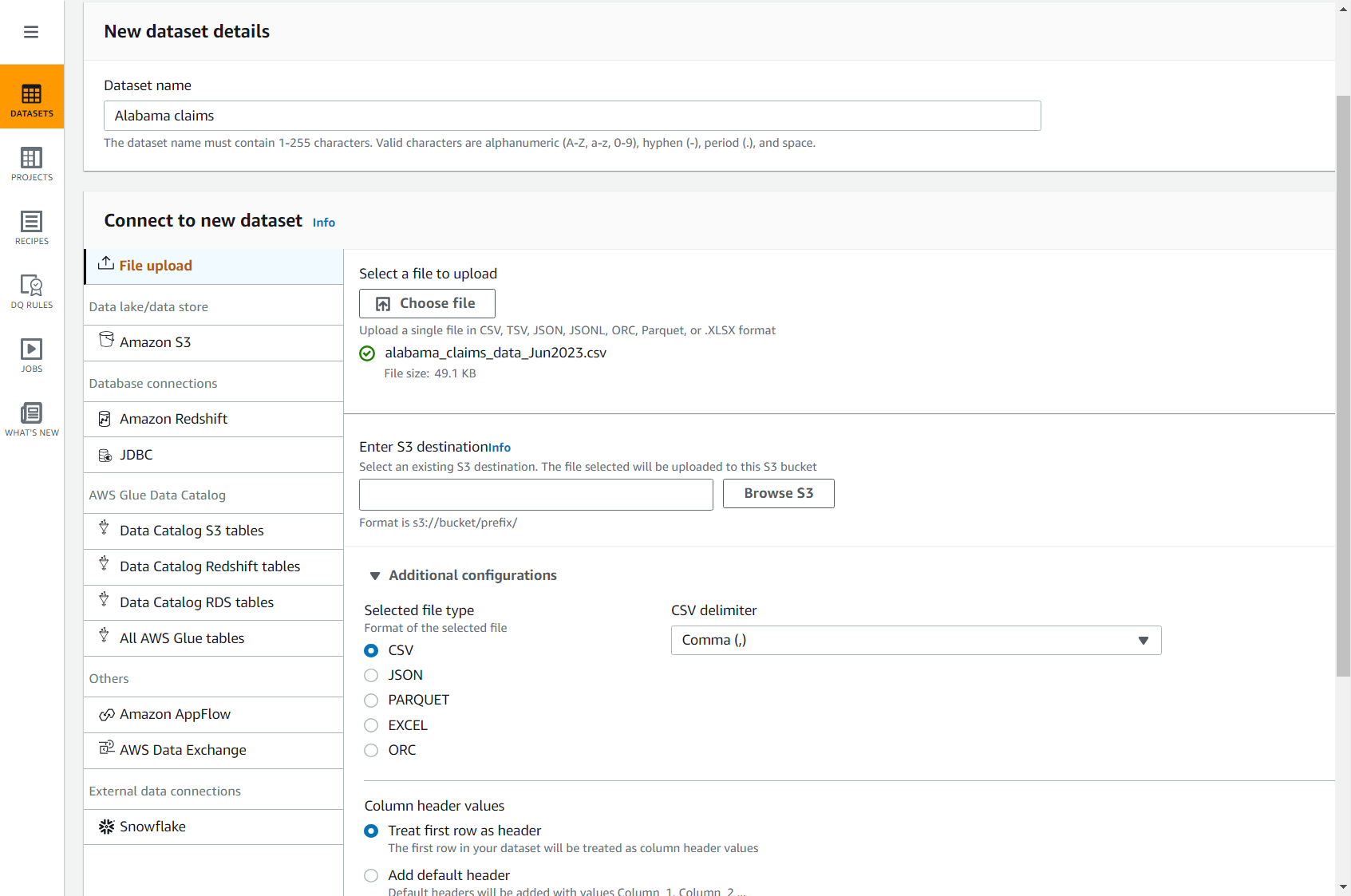
- Escolha Digite o destino S3, insira ou navegue até um bucket em sua conta e região.
- Deixe o restante das opções por padrão (CSV separado por vírgula e com cabeçalho) e conclua a criação do conjunto de dados.
- Escolha Projeto no painel de navegação e escolha Criar projeto.
- Escolha Nome do Projeto, diga
ClaimsCleanup. - Debaixo Detalhes da receita, Por Receita anexada, escolha Criar nova receita, diga
ClaimsCleanup-recipee escolha oAlabama claimsconjunto de dados que você acabou de criar.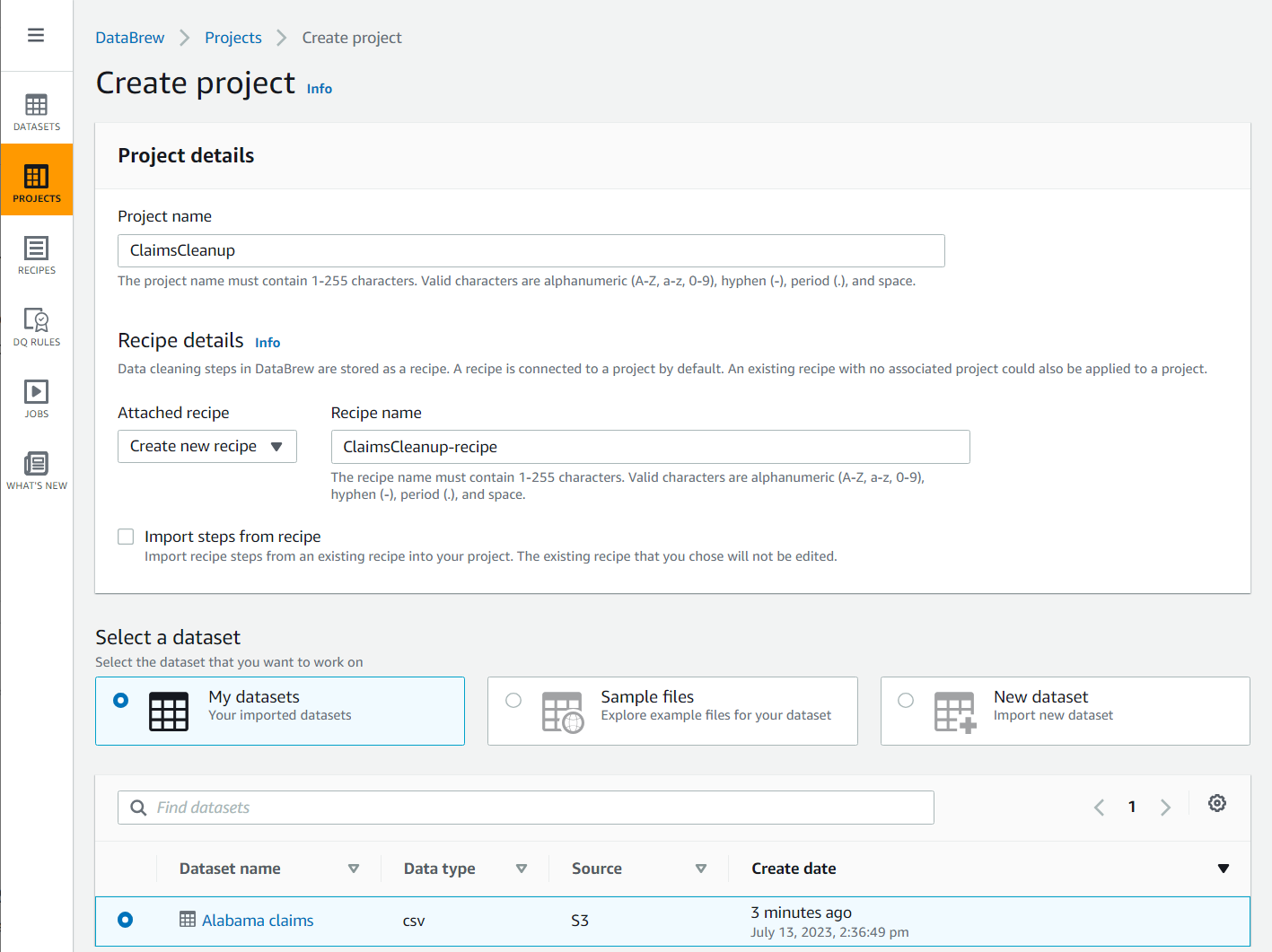
- Selecione um função adequada para DataBrew ou crie um novo e conclua a criação do projeto.
Isso criará uma sessão usando um subconjunto configurável dos dados. Depois de inicializar a sessão, você pode observar que algumas das células têm valores inválidos ou ausentes.
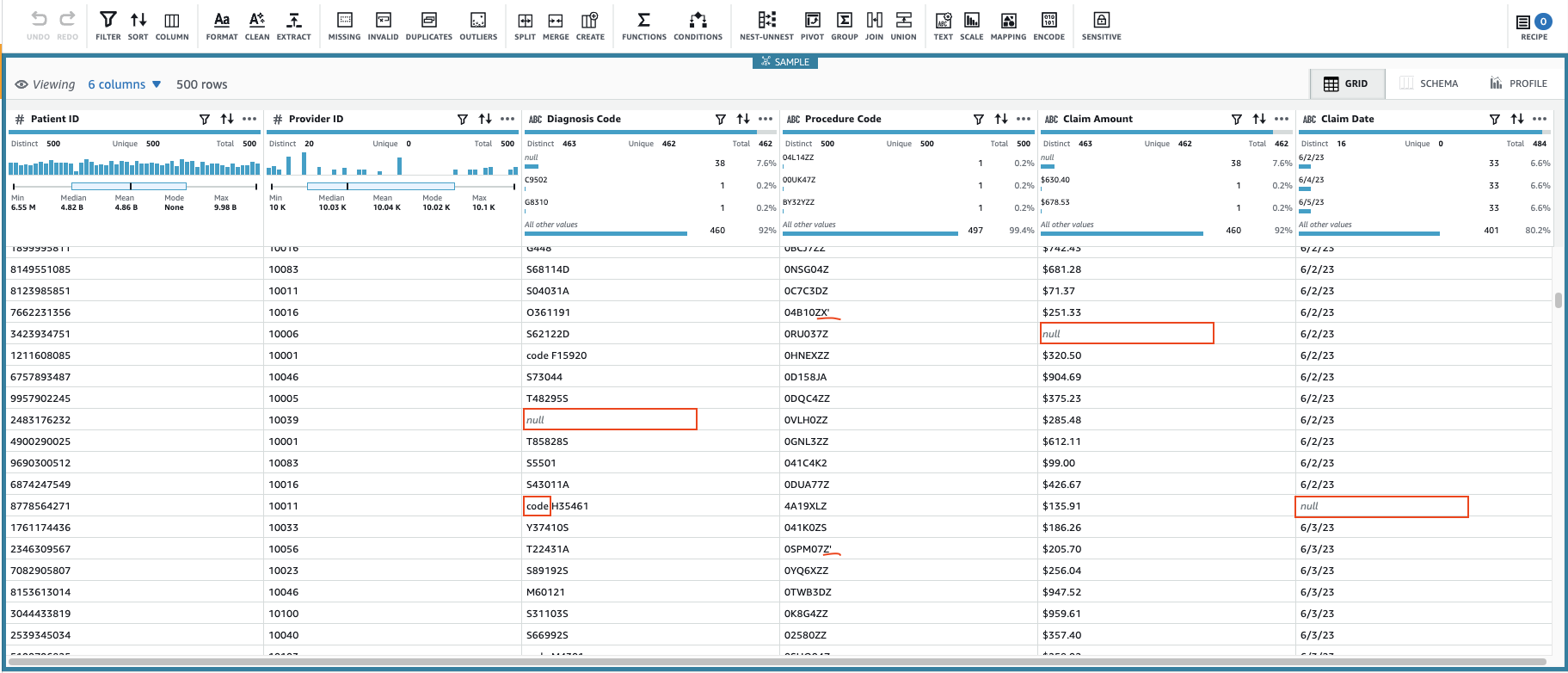
Além dos valores ausentes nas colunas Código de Diagnóstico, Valor da reivindicação e Data de Reivindicação, alguns valores nos dados possuem alguns caracteres extras: Código de Diagnóstico os valores às vezes são prefixados com "código" (espaço incluído) e Código de procedimento os valores às vezes são seguidos por aspas simples.
Valor da reivindicação os valores provavelmente serão usados para alguns cálculos, portanto, converta em número e Dados de Reivindicação deve ser convertido para o tipo de data.
Agora que identificamos os problemas de qualidade de dados a serem resolvidos, precisamos decidir como lidar com cada caso.
Existem várias maneiras de adicionar etapas de receita, inclusive usando o menu de contexto da coluna, a barra de ferramentas na parte superior ou o resumo da receita. Usando o último método, você pode pesquisar o tipo de etapa indicado para replicar a receita criada neste post.
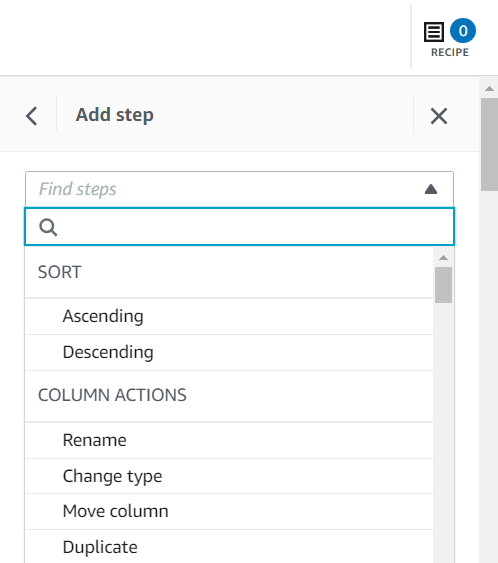
Valor da reivindicação é essencial para este caso de uso e a decisão é remover essas linhas.
- Adicione a etapa Remover valores ausentes.
- Escolha Coluna de origem, escolha Valor da reivindicação.
- Deixe a ação padrão Excluir linhas com valores ausentes e escolha Aplicar para salvá-lo.
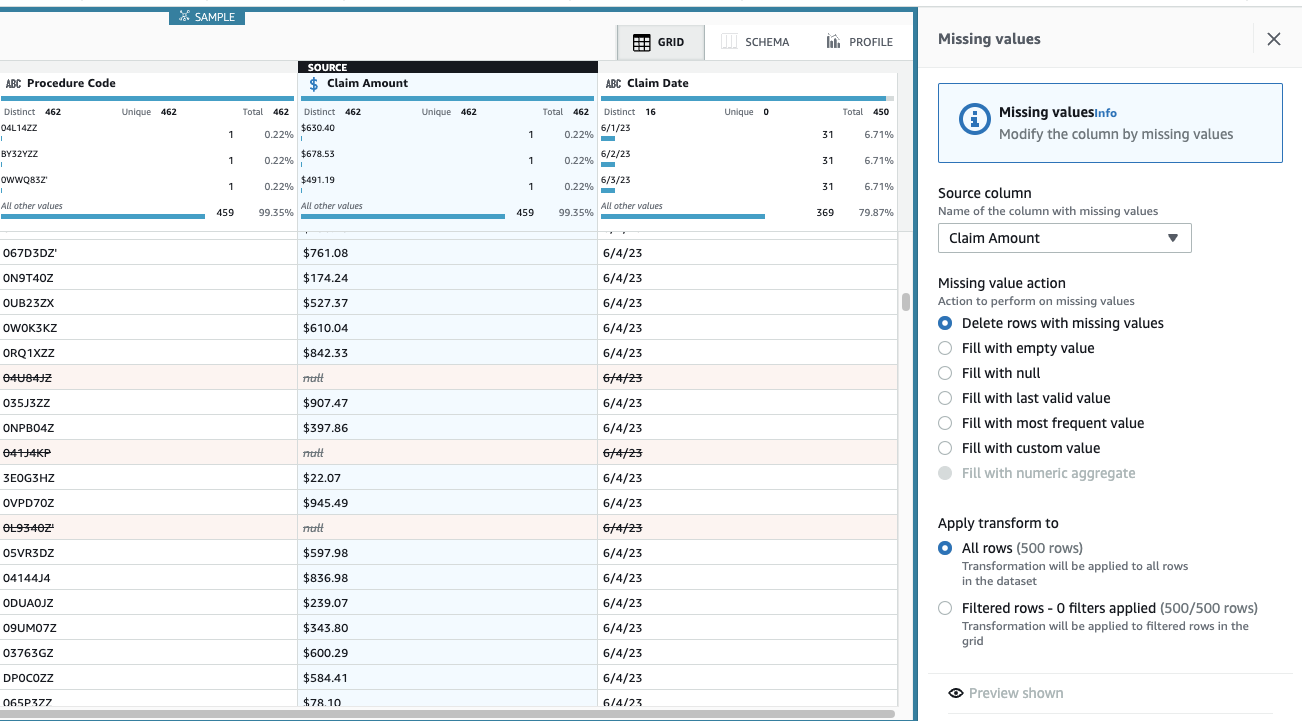
A exibição agora é atualizada para refletir a aplicação da etapa e as linhas com valores ausentes não estão mais lá.
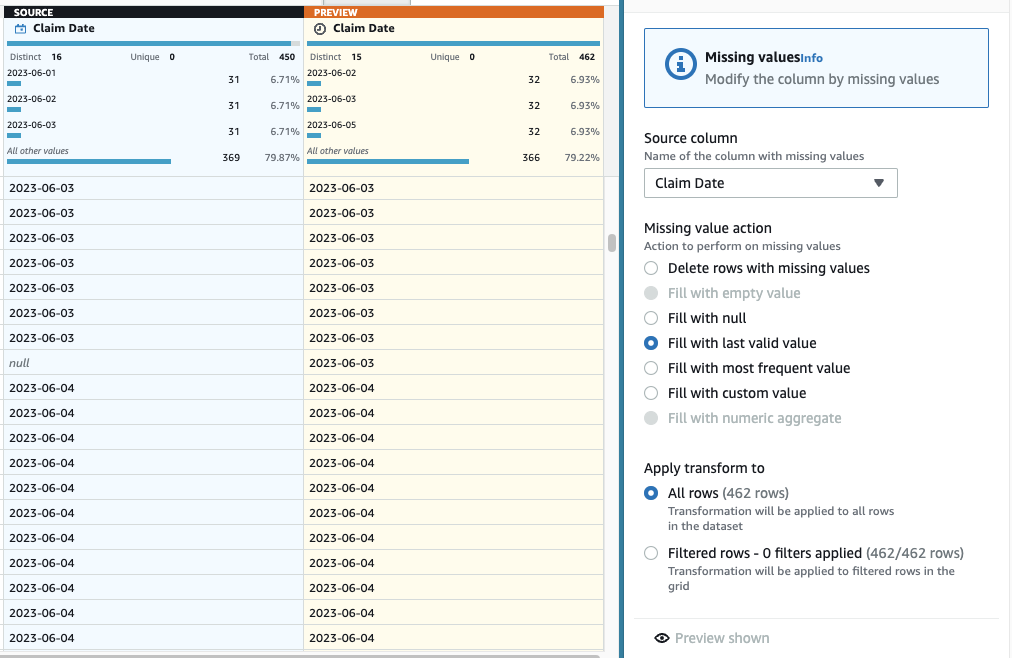
Código de Diagnóstico pode estar vazio, então isso é aceito, mas no caso de Data de Reivindicação, queremos ter uma estimativa razoável. As linhas nos dados são classificadas em ordem cronológica, para que você possa imputar as datas ausentes usando o valor válido de visualização das linhas anteriores. Supondo que todos os dias tenham sinistros, o maior erro seria atribuí-lo ao dia de visualização se fosse o primeiro sinistro naquele dia sem a data; para fins de ilustração, vamos considerar esse erro potencial aceitável.
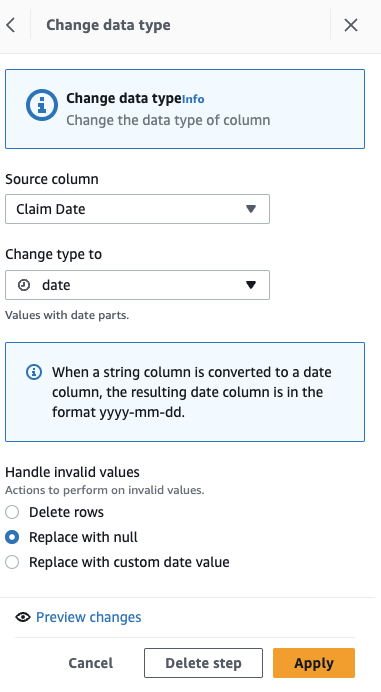
Primeiro, converta a coluna de string para tipo de data.
- Adicione a etapa Alterar tipo.
- Escolha Data de Reivindicação como a coluna e dados como o tipo, então escolha Aplicar.
- Agora para fazer a imputação das datas faltantes, adicione o passo Preencher ou imputar valores ausentes.
- Selecione Preencher com o último valor válido como a ação e escolha Data de Reivindicação como a fonte.
- Escolha Pré-visualizar alterações para validá-lo, então escolha Aplicar para salvar a etapa.
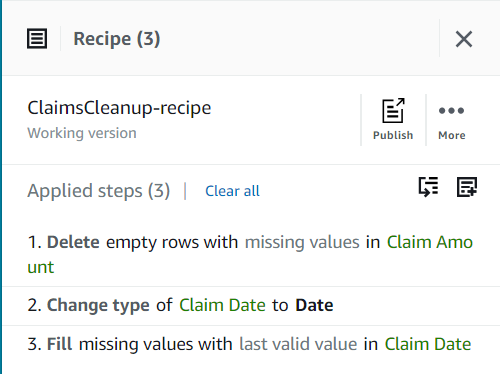
Até agora, sua receita deve ter três etapas, conforme mostrado na captura de tela a seguir.
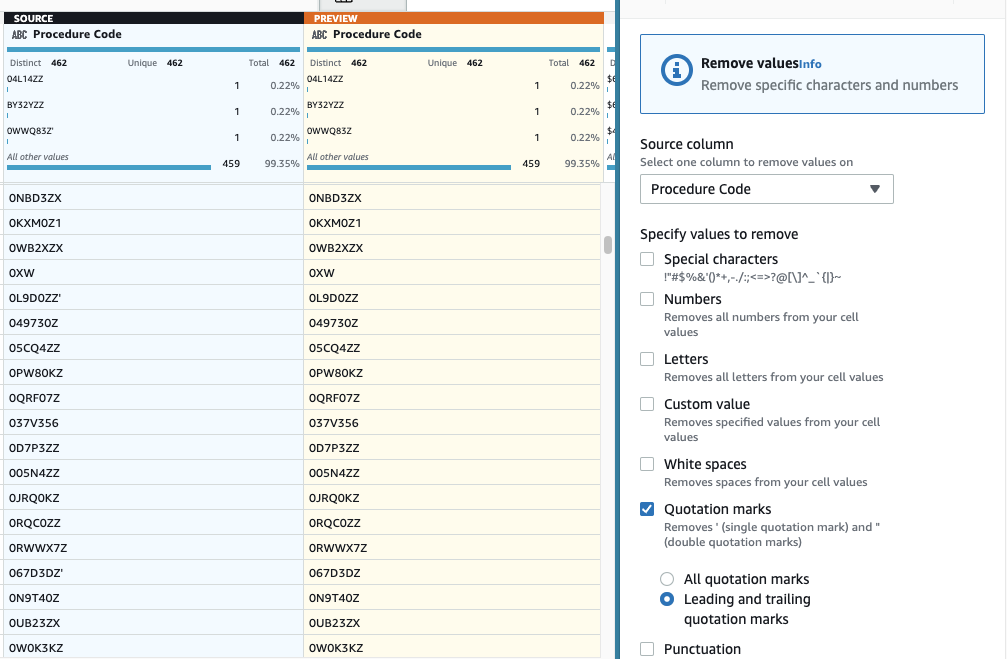
- Em seguida, adicione a etapa Remover aspas.
- Escolha o Código de procedimento coluna e selecione Aspas iniciais e finais.
- Visualize para verificar se tem o efeito desejado e aplique a nova etapa.
- Adicione a etapa Remover caracteres especiais.
- Escolha o Valor da reivindicação coluna e para ser mais específico, selecione Caracteres especiais personalizados e entre
$para Insira caracteres especiais personalizados.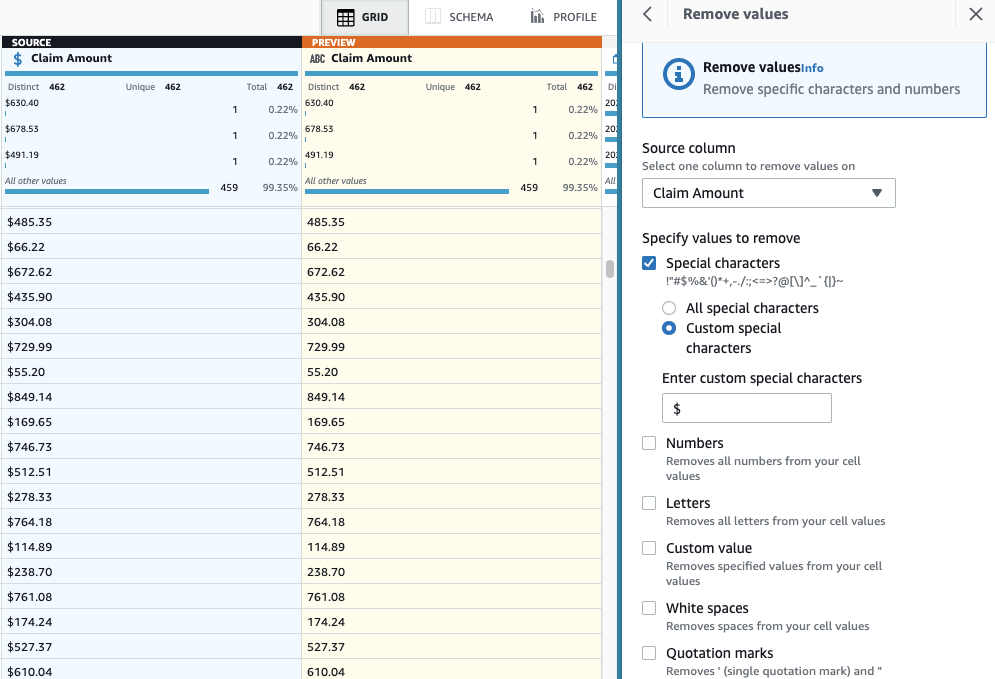
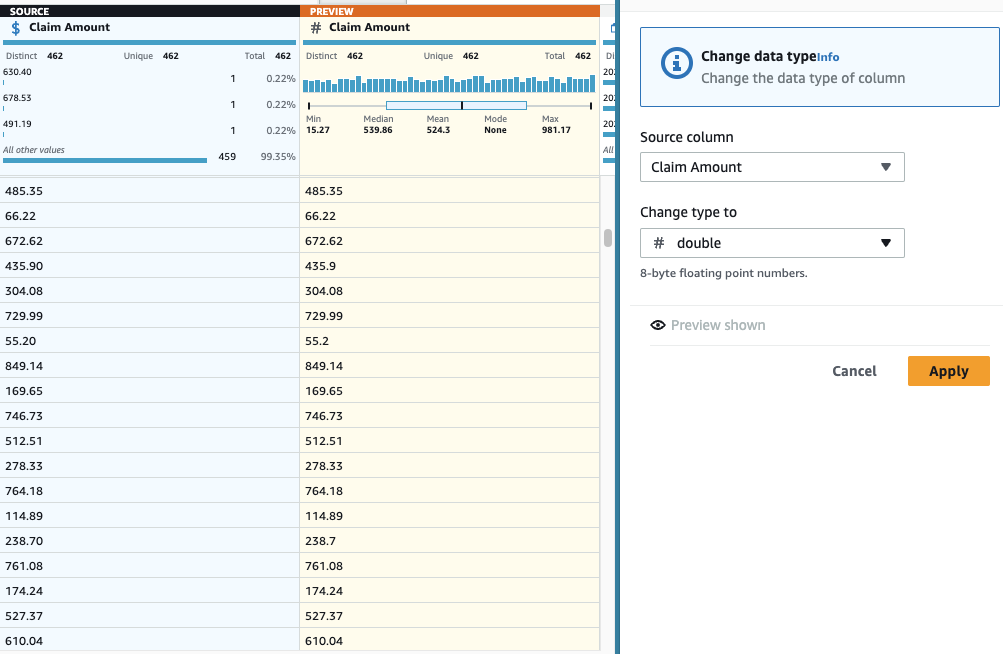
- Adicionar uma Alterar tipo passo na coluna Valor da reivindicação e escolha duplo como o tipo.
- Como último passo, para remover o prefixo “código” supérfluo, adicione um Substituir valor ou padrão degrau.
- Escolha a coluna Código de Diagnóstico, E para Insira o valor personalizado, entrar
code(com um espaço no final).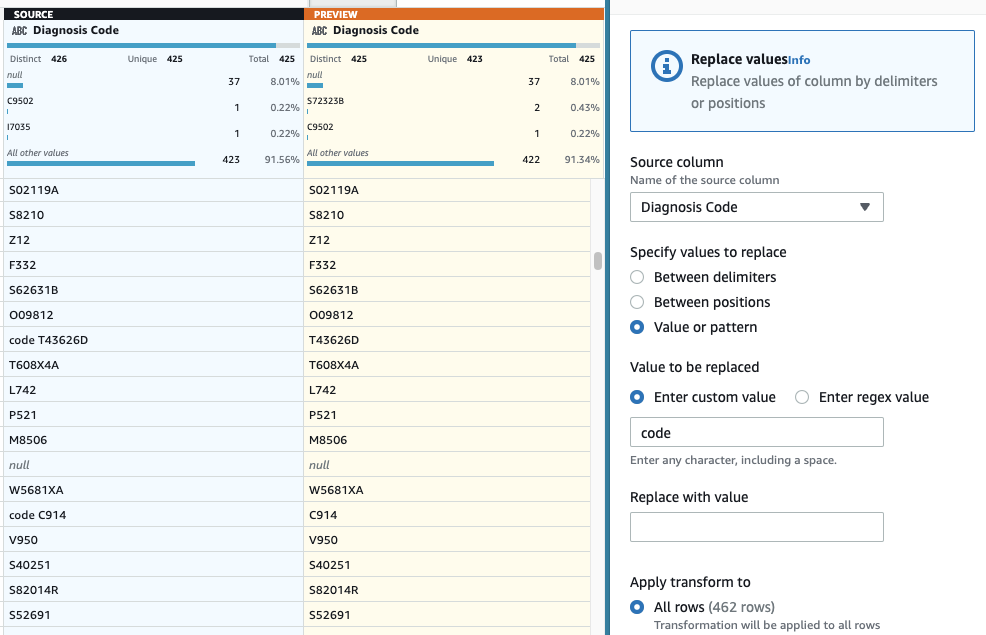
Agora que você abordou todos os problemas de qualidade de dados identificados na amostra, publique o projeto como uma receita.
- Escolha Publique no Receita painel, insira uma descrição opcional e conclua a publicação.
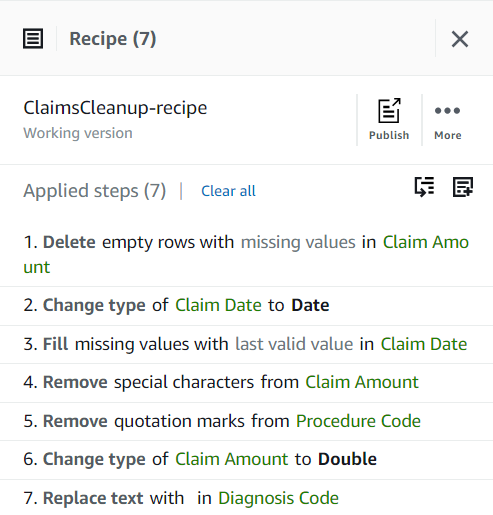
Cada vez que você publicar, será criada uma versão diferente da receita. Posteriormente, você poderá escolher qual versão da receita usar.
Crie um trabalho ETL visual no AWS Glue Studio
Em seguida, você cria o trabalho que usa a receita. Conclua as seguintes etapas:
- No console do AWS Glue Studio, escolha ETL visual no painel de navegação.
- Escolha Visual com uma tela em branco e criar o trabalho visual.
- Na parte superior do trabalho, substitua “Trabalho sem título” por um nome de sua escolha.
- No Detalhes do trabalho guia, especifique uma função que o trabalho usará.
Isso precisa ser um Gerenciamento de acesso e identidade da AWS (IAM) função adequada para AWS Glue com permissões para o Amazon S3 e o Catálogo de dados do AWS Glue. Observe que a função usada antes para DataBrew não pode ser usada para tarefas de execução, portanto, não será listada na Papel IAM menu suspenso aqui.
Se você usou apenas trabalhos DataBrew antes, observe que no AWS Glue Studio, você pode escolher configurações de desempenho e custo, incluindo tamanho do trabalhador, dimensionamento automático e Execução flexível, além de usar o tempo de execução mais recente do AWS Glue 4.0 e se beneficiar das melhorias significativas de desempenho que ele traz. Para este trabalho, você pode usar as configurações padrão, mas reduza o número solicitado de trabalhadores para economizar. Para este exemplo, dois trabalhadores servirão. - No visual guia, adicione uma fonte S3 e nomeie-a
Providers. - Escolha URL do S3, entrar
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.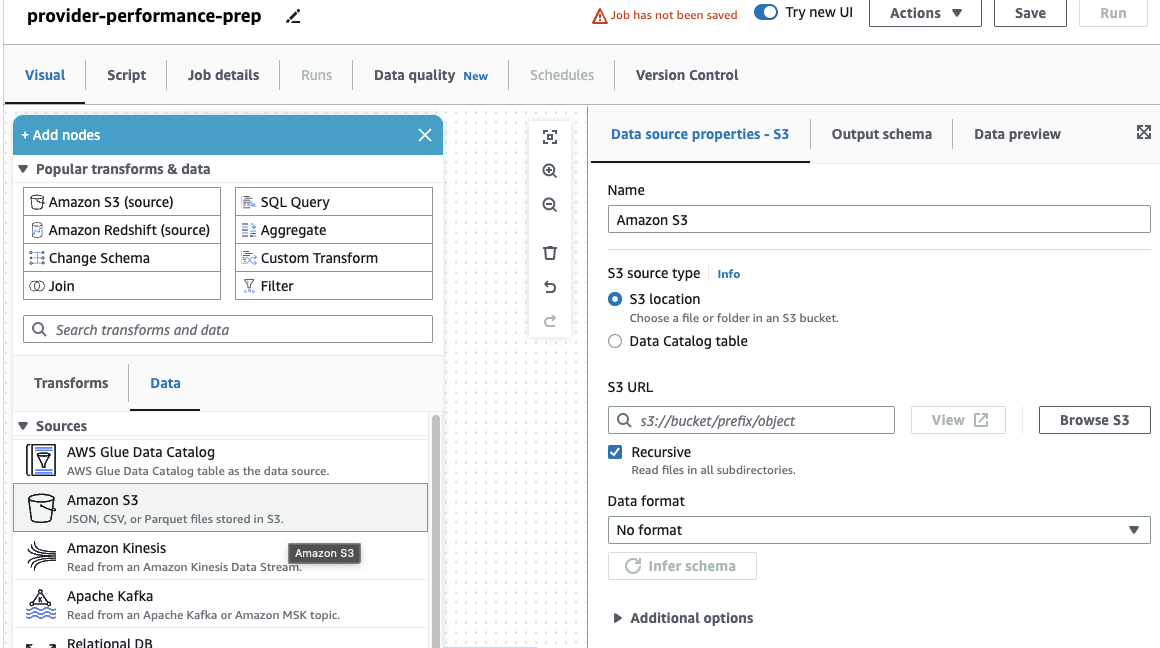
- Selecione o formato como CSV e escolha Inferir esquema.
Agora o esquema está listado no Esquema de saída guia usando o cabeçalho do arquivo.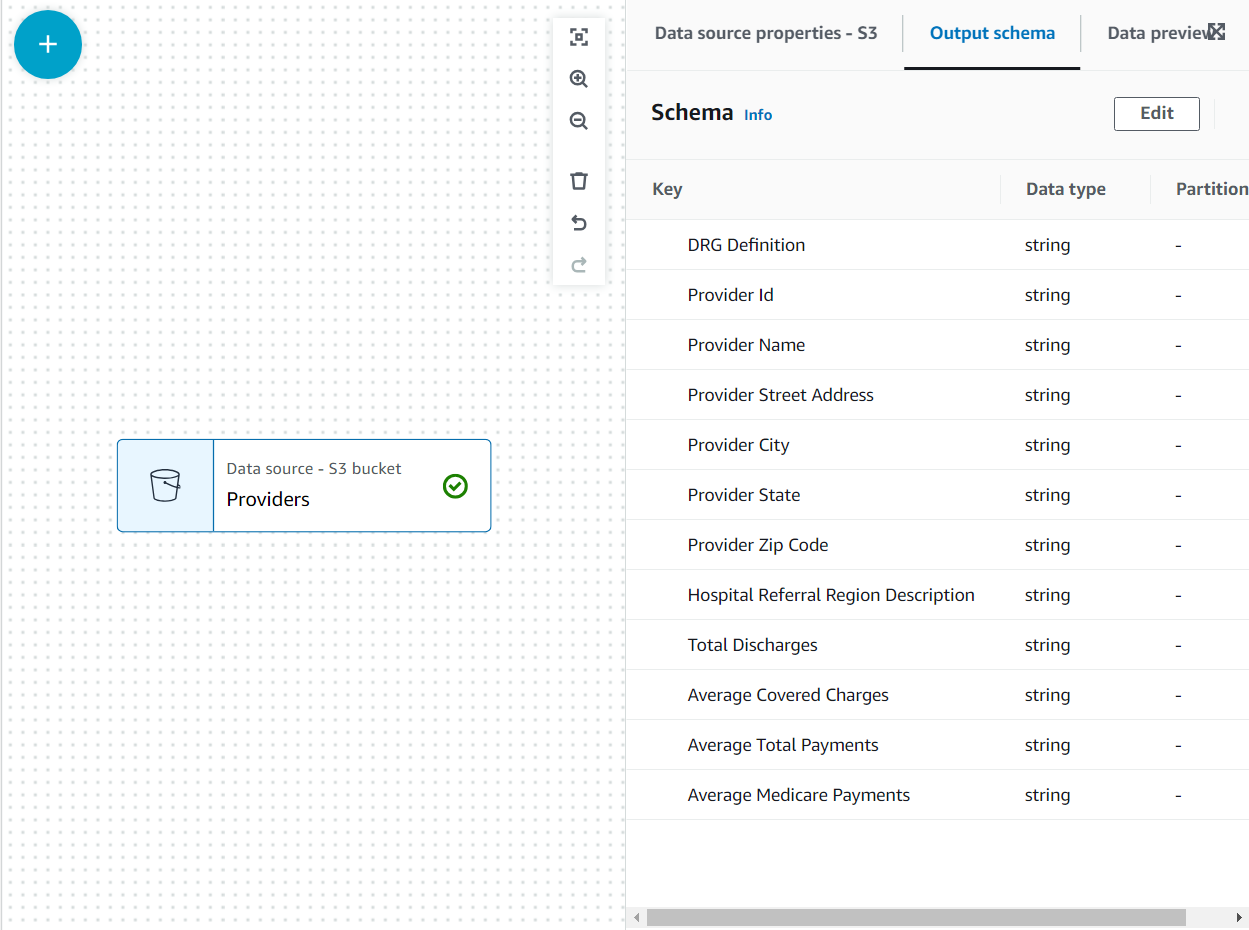
Nesse caso de uso, a decisão é que nem todas as colunas no conjunto de dados dos provedores são necessárias, portanto, podemos descartar o restante.
- Com o prestadores nó selecionado, adicione um Soltar campos transform (se você não selecionou o nó pai, ele não terá um; nesse caso, atribua o nó pai manualmente).
- Selecione todos os campos após CEP do provedor.
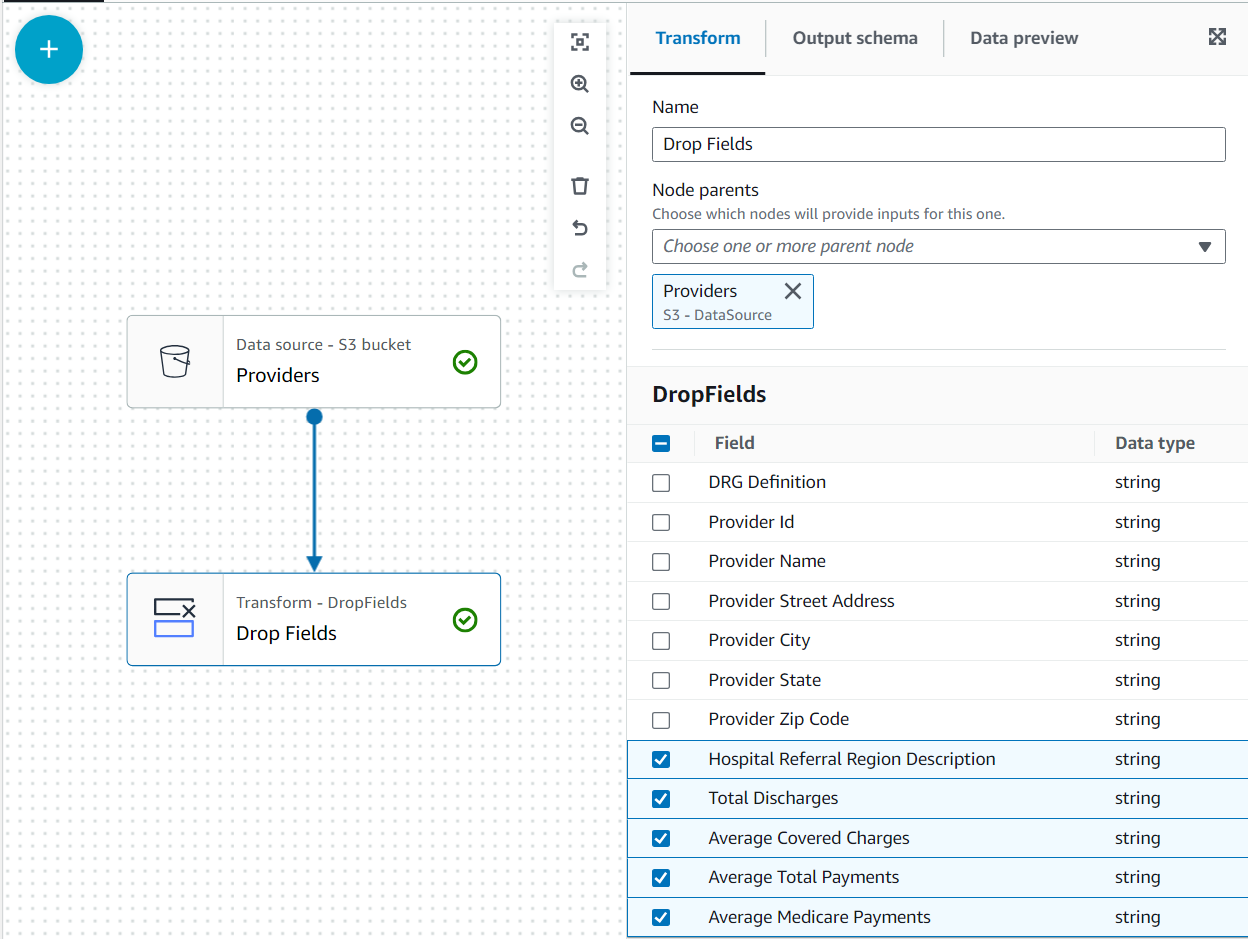
Mais tarde, esses dados serão acompanhados pelas reivindicações do estado do Alabama usando o provedor; no entanto, esse segundo conjunto de dados não tem o estado especificado. Podemos usar o conhecimento dos dados para otimizar a junção, filtrando os dados que realmente precisamos.
- Adicionar uma filtros transformar como filho de Soltar campos.
- Diga
Alabama providerse adicione uma condição que o estado deve corresponderAL.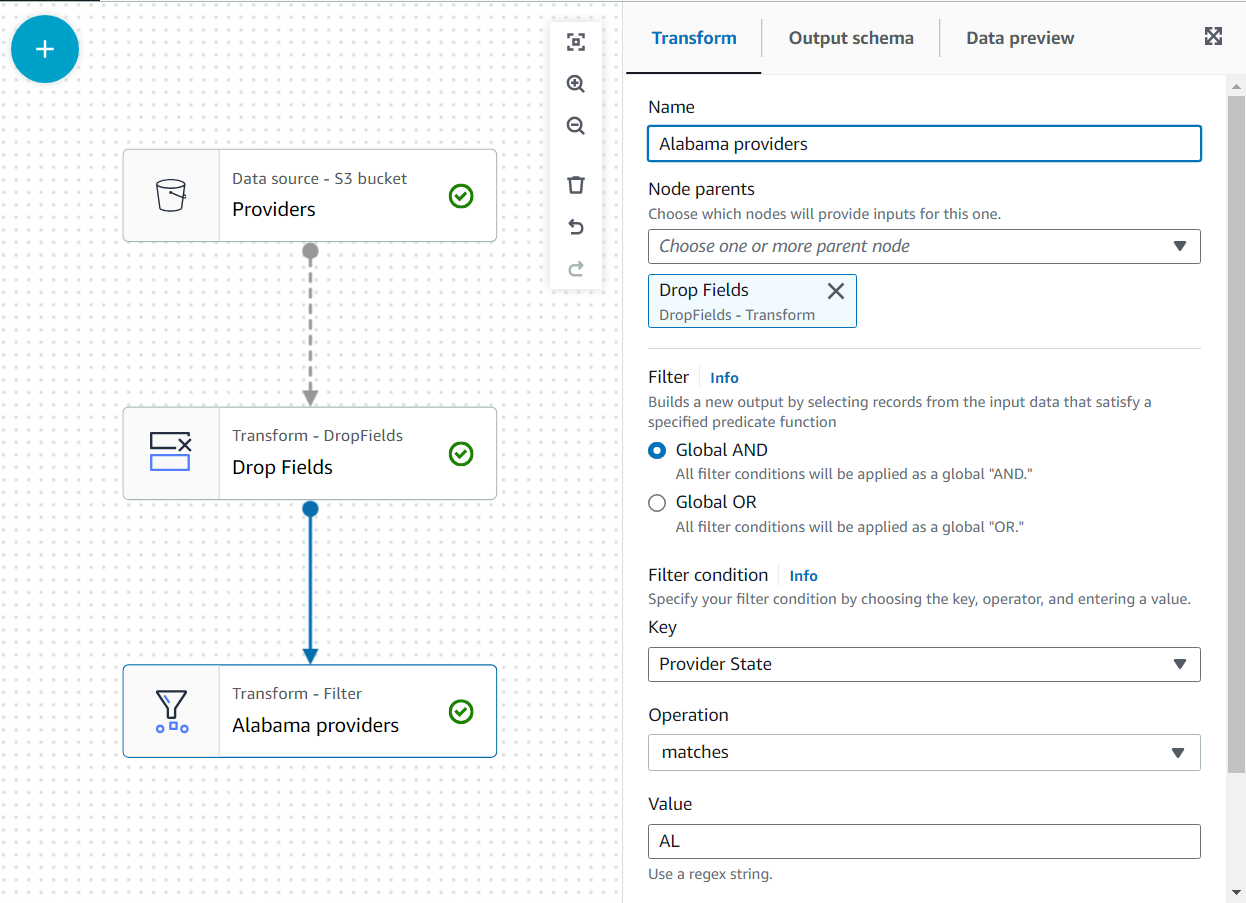
- Adicione a segunda fonte (uma nova fonte S3) e nomeie-a
Alabama claims. - Para entrar no URL do S3, abra o DataBrew em uma guia separada do navegador, escolha Conjuntos de dados no painel de navegação e, na tabela, copie o local mostrado na tabela para reivindicações de Alabama (copie o texto começando com s3://, não o link http associado). Em seguida, de volta ao trabalho visual, cole-o como URL do S3; se estiver correto, você verá no Esquema de saída aba os campos de dados listados.
- Selecione o formato CSV e infira o esquema como você fez com a outra fonte.
- Como filho desta fonte, pesquise no Adicionar nós menu para
recipee escolha Receita de preparação de dados.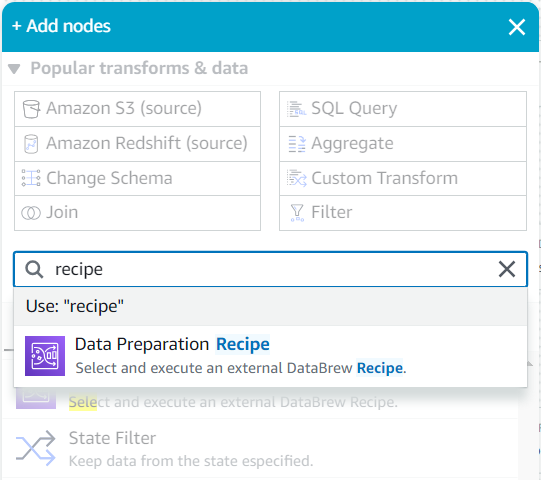
- Nas propriedades deste novo nó, dê a ele o nome
Claim cleanup recipee escolha a receita e a versão que você publicou anteriormente. - Você pode revisar as etapas da receita aqui e usar o link para DataBrew para fazer alterações, se necessário.
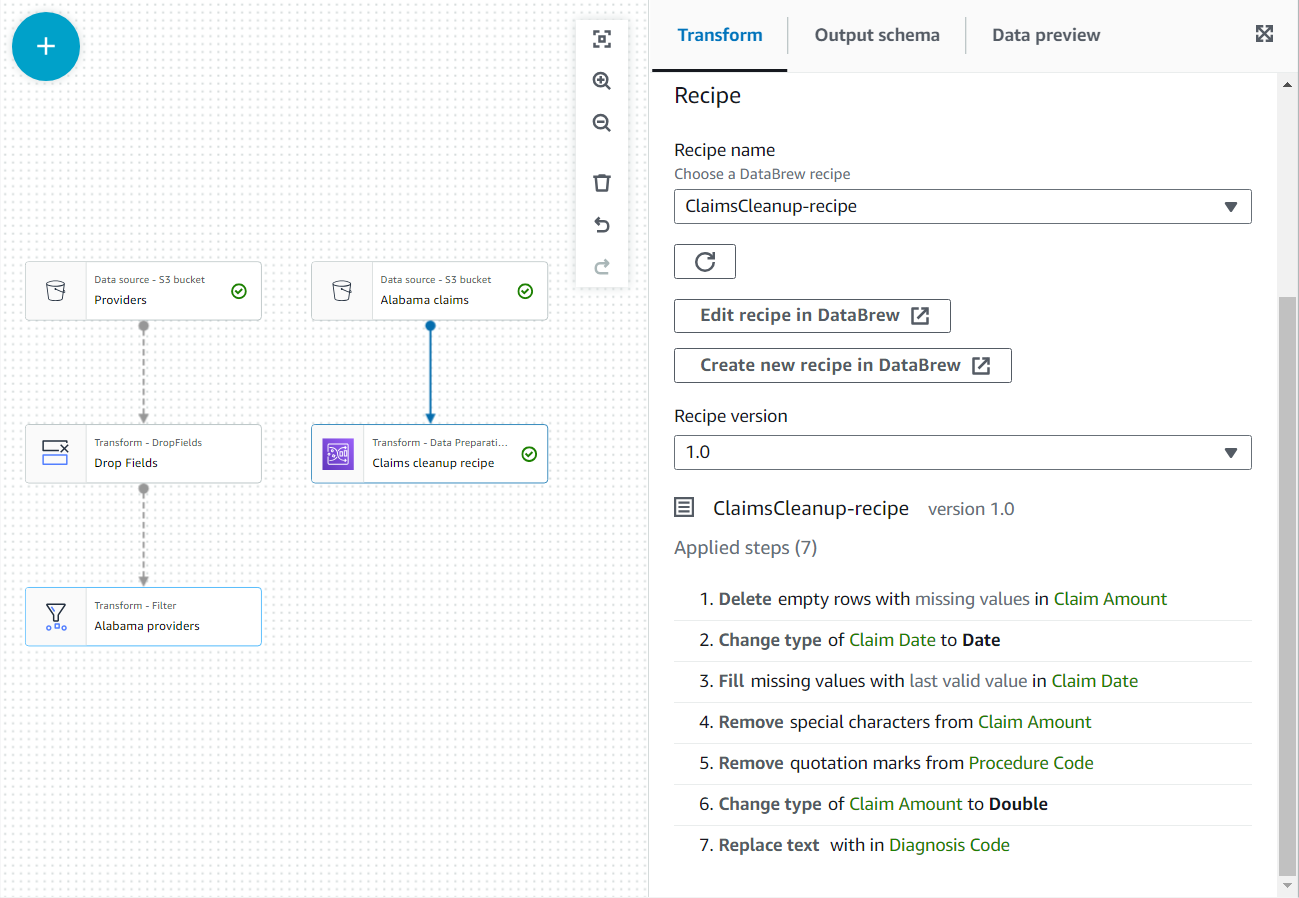
- Adicionar uma Cadastrar nó e selecione ambos Provedores do Alabama e Reivindicar receitas de limpeza como o pai.
- Adicione uma condição de associação igual ao ID do provedor de ambas as origens.
- Como última etapa, adicione um nó S3 como destino (observe que o primeiro listado ao pesquisar é a origem; certifique-se de selecionar a versão listada como destino).
- Na configuração do nó, deixe o formato padrão JSON e insira uma URL do S3 na qual a função de trabalho tenha permissão para gravar.
Além disso, disponibilize a saída de dados como uma tabela no catálogo.
- No Opções de atualização do catálogo de dados seção, selecione a segunda opção Crie uma tabela no Catálogo de Dados e nas execuções subsequentes, atualize o esquema e adicione novas partições, em seguida, selecione um banco de dados no qual você tem permissão para criar tabelas.
- Atribuir
alabama_claimscomo o nome e escolha Data de Reivindicação como a chave de partição (isto é para fins de ilustração; uma pequena tabela como esta realmente não precisa de partições se mais dados não forem adicionados posteriormente).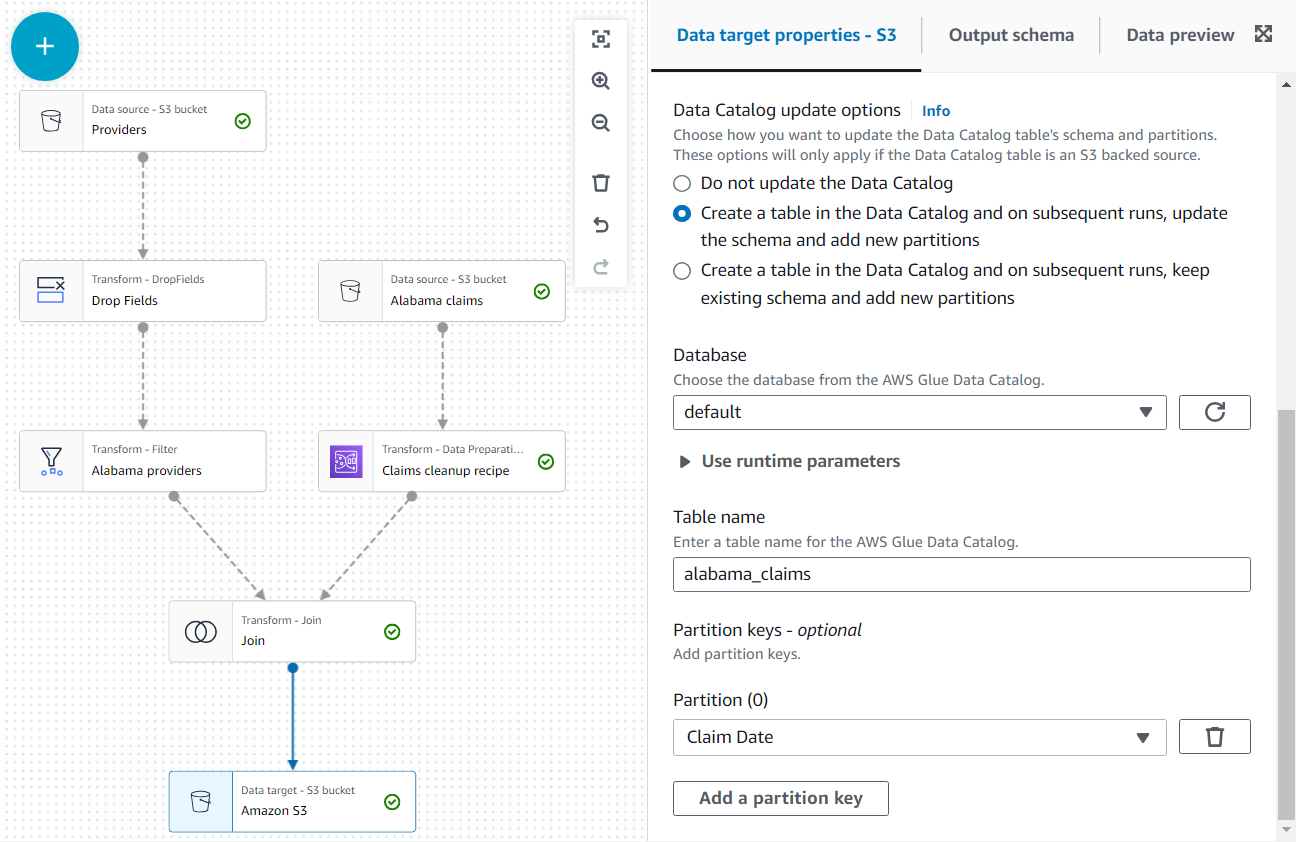
- Agora você pode salvar e executar o trabalho.
- No Runs guia, você pode acompanhar o processo e ver as métricas de trabalho detalhadas usando o link de ID do trabalho.
O trabalho deve levar alguns minutos para ser concluído.
- Quando o trabalho estiver concluído, navegue até o console do Athena.
- Procure a tabela
alabama_claimsno banco de dados que você selecionou e, usando o menu de contexto, escolha Tabela de visualização, que executará uma instrução SELECT * SQL simples na tabela.
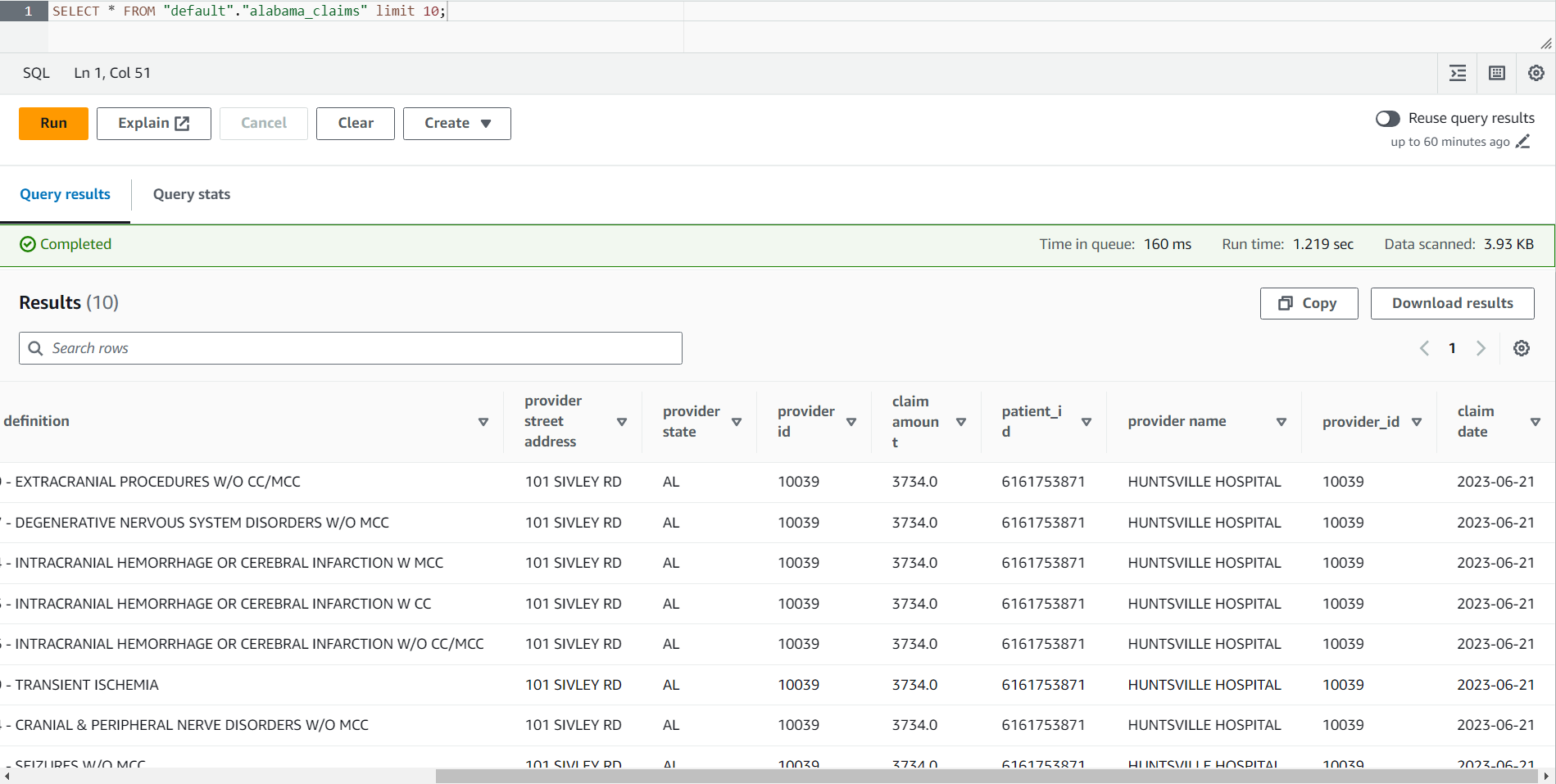
Você pode ver no resultado do trabalho que os dados foram limpos pela receita do DataBrew e enriquecidos pela junção do AWS Glue Studio.
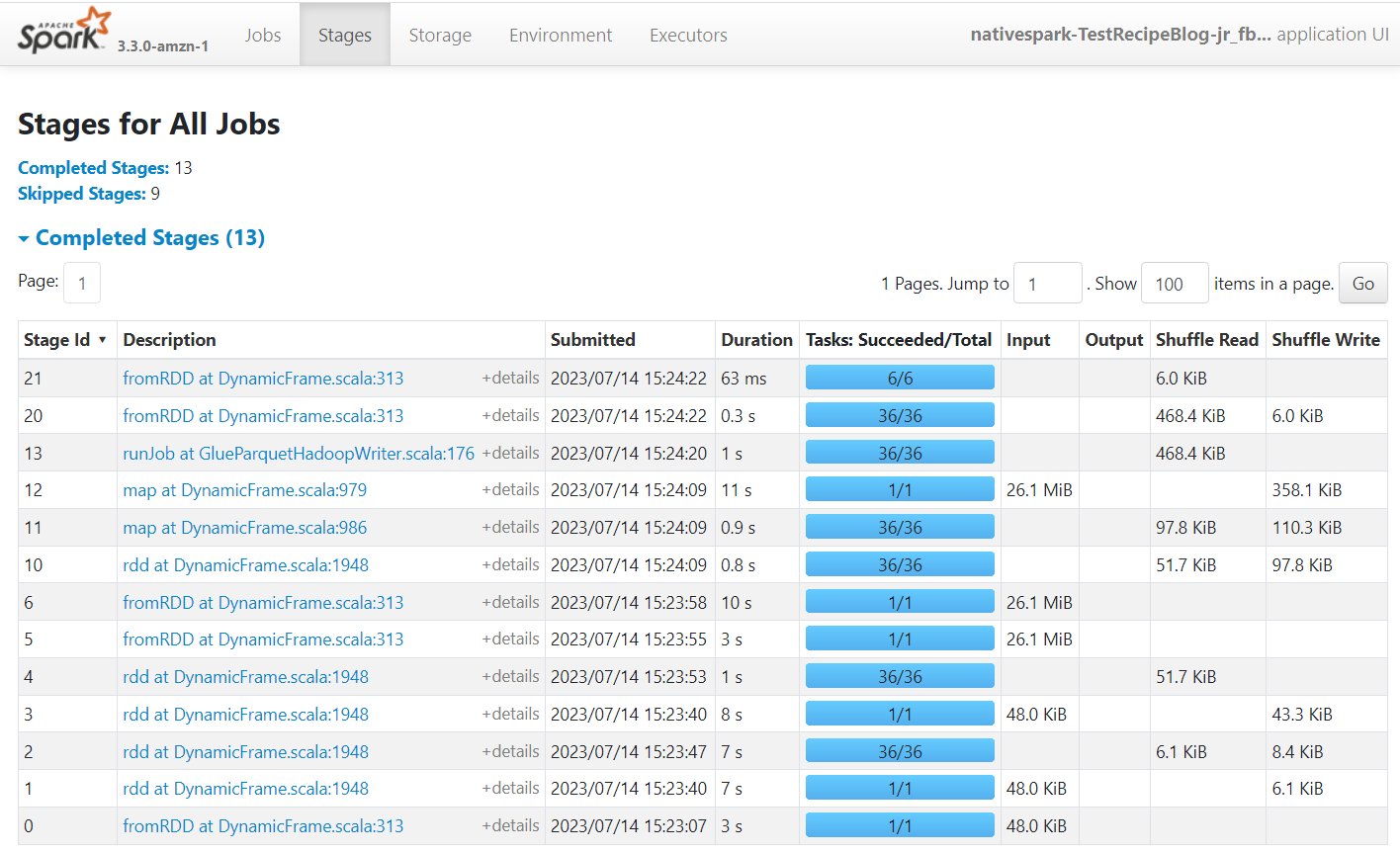
O Apache Spark é o mecanismo que executa os trabalhos criados no AWS Glue Studio. Usando a interface do usuário do Spark nos logs de eventos que ela produz, você pode ver informações sobre o plano de trabalho e a execução, o que pode ajudá-lo a entender o desempenho do seu trabalho e possíveis gargalos de desempenho. Por exemplo, para este trabalho em um grande conjunto de dados, você pode usá-lo para comparar o impacto de filtrar explicitamente o estado do provedor antes de fazer a junção ou identificar se você pode se beneficiar adicionando uma transformação Autobalance para melhorar o paralelismo.
Por padrão, o trabalho armazenará os logs de eventos do Apache Spark no caminho s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. Para visualizar os trabalhos, você deve instalar um servidor de histórico usando um dos métodos disponíveis.
limpar
Se você não precisar mais dessa solução, poderá excluir os arquivos gerados no Amazon S3, a tabela criada pelo trabalho, a receita do DataBrew e o trabalho do AWS Glue.
Conclusão
Nesta postagem, mostramos como você pode usar o AWS DataBrew para criar uma receita usando o editor interativo fornecido e, em seguida, usar a receita publicada como parte de um trabalho ETL visual do AWS Glue Studio. Incluímos alguns exemplos de tarefas comuns necessárias ao preparar e ingerir dados nas tabelas do Catálogo do AWS Glue.
Este exemplo usou uma única receita no trabalho visual, mas é possível usar várias receitas em diferentes partes do processo ETL, bem como reutilizar a mesma receita em vários trabalhos.
Essas soluções do AWS Glue permitem que você crie pipelines ETL avançados que são fáceis de criar e manter, tudo sem escrever nenhum código. Você pode começar a criar soluções que combinem ambas as ferramentas hoje mesmo.
Sobre os autores
 Mikhail Smirnov é engenheiro sênior de desenvolvimento de software na equipe do AWS Glue e parte da equipe de desenvolvimento do AWS Glue DataBrew. Fora do trabalho, seus interesses incluem aprender a tocar violão e viajar com a família.
Mikhail Smirnov é engenheiro sênior de desenvolvimento de software na equipe do AWS Glue e parte da equipe de desenvolvimento do AWS Glue DataBrew. Fora do trabalho, seus interesses incluem aprender a tocar violão e viajar com a família.
 Gonzalo herreros é arquiteto sênior de Big Data na equipe do AWS Glue. Com sede em Dublin, na Irlanda, ele ajuda os clientes a obter sucesso com soluções de big data baseadas no AWS Glue. Nas horas vagas, ele gosta de jogos de tabuleiro e andar de bicicleta.
Gonzalo herreros é arquiteto sênior de Big Data na equipe do AWS Glue. Com sede em Dublin, na Irlanda, ele ajuda os clientes a obter sucesso com soluções de big data baseadas no AWS Glue. Nas horas vagas, ele gosta de jogos de tabuleiro e andar de bicicleta.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Automotivo / EVs, Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- BlockOffsets. Modernizando a Propriedade de Compensação Ambiental. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- :tem
- :é
- :não
- $UP
- 10
- 100
- 12
- 15%
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- Capaz
- Sobre
- aceitável
- aceito
- Acesso
- Conta
- Açao Social
- real
- adicionar
- adicionado
- acrescentando
- Adição
- endereço
- avançado
- Depois de
- Alabama
- Todos os Produtos
- permitir
- tb
- Amazon
- Amazon Web Services
- quantidades
- an
- Analistas
- e
- qualquer
- apache
- Apache Spark
- Aplicação
- Aplicar
- SOMOS
- AS
- associado
- At
- autor
- auto
- Automático
- disponível
- AWS
- Cola AWS
- em caminho duplo
- baseado
- BE
- antes
- ser
- beneficiar
- Benefícios
- Grande
- Big Data
- em branco
- borda
- Board Games
- bookmarks
- ambos
- Traz
- navegador
- construir
- mas a
- by
- CAN
- capacidades
- casas
- catálogo
- Células
- centralizada
- alterar
- Alterações
- caracteres
- criança
- escolha
- Escolha
- reivindicar
- reivindicações
- código
- Coluna
- colunas
- combinar
- vinda
- comum
- comparar
- completar
- componentes
- computador
- condição
- Configuração
- Considerar
- consiste
- cônsul
- contexto
- converter
- convertido
- correta
- Correspondente
- Custo
- poderia
- crio
- criado
- Criar
- criação
- personalizadas
- Clientes
- dados,
- Preparação de dados
- informática
- qualidade de dados
- banco de dados
- conjuntos de dados
- Data
- Datas
- dia
- acordo
- decidir
- decisão
- Padrão
- demonstrar
- descrição
- desejado
- detalhado
- detalhes
- Dev
- Desenvolvimento
- equipe de desenvolvimento
- DID
- diferente
- distinto
- distribuição
- do
- Não faz
- fazer
- Dólar
- duplo
- Cair
- Dublin
- cada
- fácil
- editor
- efeito
- efetivamente
- permite
- final
- Motor
- engenheiro
- enriquecido
- enriquecedor
- Entrar
- erro
- essencial
- Éter (ETH)
- avaliar
- Mesmo
- Evento
- Cada
- todo dia
- exemplo
- exemplos
- existente
- extra
- extrato
- família
- longe
- Funcionalidades
- poucos
- Campos
- Envie o
- Arquivos
- preencher
- filtro
- filtragem
- Finalmente
- Primeiro nome
- seguido
- seguinte
- Escolha
- formato
- da
- mais distante
- Games
- gerado
- OFERTE
- maior
- Ter
- he
- ajudar
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- sua
- história
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- http
- HTTPS
- IAM
- ID
- identificado
- identificar
- Identidade
- if
- Impacto
- melhorar
- melhorias
- in
- incluir
- incluído
- Incluindo
- indicado
- entrada
- insights
- instalar
- instância
- integrado
- integração
- interativo
- interesse
- interesses
- Interface
- para dentro
- introduzido
- intuitivo
- Irlanda
- questões
- IT
- ESTÁ
- Trabalho
- Empregos
- juntar
- ingressou
- jpg
- json
- apenas por
- Guarda
- Chave
- Conhecimento
- grande
- Maior
- maior
- Sobrenome
- mais tarde
- mais recente
- aprendizagem
- Deixar
- como
- Provável
- LINK
- Listado
- carregar
- localização
- lógica
- mais
- a manter
- fazer
- FAZ
- manualmente
- Match
- médico
- Menu
- método
- métodos
- Métrica
- minutos
- desaparecido
- Monitore
- mais
- múltiplo
- devo
- nome
- Navegar
- Navegação
- você merece...
- necessário
- Cria
- Novo
- não
- nó
- Perceber..
- agora
- número
- of
- on
- ONE
- só
- aberto
- Otimize
- Opção
- Opções
- or
- ordem
- Outros
- A Nossa
- saída
- lado de fora
- Acima de
- global
- pão
- parte
- peças
- caminho
- atuação
- realização
- permissão
- permissões
- plano
- platão
- Inteligência de Dados Platão
- PlatãoData
- Jogar
- possível
- Publique
- potencial
- preparação
- visualização
- Previews
- processo
- em processamento
- produz
- projeto
- Propriedades
- fornecido
- provedor
- fornecedores
- fornece
- Publicação
- publicar
- publicado
- propósito
- fins
- qualidade
- citações
- clientes
- razoável
- receita
- Receitas
- reduzir
- refletir
- região
- registro
- relevante
- remover
- substituir
- solicitadas
- requeridos
- requerimento
- respectivamente
- DESCANSO
- resultar
- Resultados
- reutilizar
- rever
- Tipo
- Execute
- é executado
- mesmo
- Salvar
- Escala
- dimensionamento
- Pesquisar
- Segundo
- Seção
- Vejo
- visto
- selecionado
- separado
- Serviços
- Sessão
- conjunto
- Configurações
- rede de apoio social
- mostrou
- mostrando
- assinar
- periodo
- simples
- solteiro
- Tamanho
- pequeno
- So
- até aqui
- Software
- solução
- Soluções
- alguns
- fonte
- Fontes
- Espaço
- Faísca
- especial
- específico
- especificada
- SQL
- começo
- Comece
- Estado
- Declaração
- estatística
- Passo
- Passos
- armazenamento
- loja
- franco
- Tanga
- estudo
- subseqüente
- suceder
- tal
- adequado
- RESUMO
- certo
- sintético
- mesa
- Tire
- Target
- tarefas
- Profissionais
- testado
- que
- A
- A fonte
- O Estado
- Eles
- então
- Lá.
- isto
- três
- tempo
- para
- hoje
- ferramenta
- ferramentas
- topo
- pista
- Transformar
- Transformação
- transformações
- Viagens
- dois
- tipo
- ui
- para
- compreender
- Atualizar
- Atualizada
- URL
- utilizável
- usar
- caso de uso
- usava
- usuários
- usos
- utilização
- VALIDAR
- valor
- Valores
- verificar
- versão
- Ver
- visível
- queremos
- foi
- maneiras
- we
- web
- serviços web
- BEM
- foram
- quando
- qual
- precisarão
- de
- sem
- Atividades:
- trabalhador
- trabalhadores
- de gestão de documentos
- seria
- escrever
- escrita
- Você
- investimentos
- zefirnet
- Zip