Nesta postagem, demonstramos como usar a poda estrutural baseada em pesquisa de arquitetura neural (NAS) para compactar um modelo BERT ajustado para melhorar o desempenho do modelo e reduzir os tempos de inferência. Modelos de linguagem pré-treinados (PLMs) estão passando por rápida adoção comercial e empresarial nas áreas de ferramentas de produtividade, atendimento ao cliente, pesquisa e recomendações, automação de processos de negócios e criação de conteúdo. A implantação de endpoints de inferência de PLM normalmente está associada a maior latência e maiores custos de infraestrutura devido aos requisitos de computação e à redução da eficiência computacional devido ao grande número de parâmetros. A remoção de um PLM reduz o tamanho e a complexidade do modelo, mantendo seus recursos preditivos. PLMs eliminados alcançam menor consumo de memória e menor latência. Demonstramos isso, eliminando um PLM e trocando a contagem de parâmetros e o erro de validação para uma tarefa de destino específica, e somos capazes de obter tempos de resposta mais rápidos quando comparados ao modelo PLM básico.
A otimização multiobjetivo é uma área de tomada de decisão que otimiza mais de uma função objetivo, como consumo de memória, tempo de treinamento e recursos computacionais, para serem otimizados simultaneamente. A poda estrutural é uma técnica para reduzir o tamanho e os requisitos computacionais do PLM, removendo camadas ou neurônios/nós enquanto tenta preservar a precisão do modelo. Ao remover camadas, a poda estrutural atinge taxas de compressão mais altas, o que leva a uma dispersão estruturada amigável ao hardware que reduz os tempos de execução e de resposta. A aplicação de uma técnica de remoção estrutural a um modelo PLM resulta em um modelo mais leve com menor consumo de memória que, quando hospedado como um endpoint de inferência no SageMaker, oferece maior eficiência de recursos e custo reduzido quando comparado ao PLM original ajustado.
Os conceitos ilustrados nesta postagem podem ser aplicados a aplicações que utilizam recursos de PLM, como sistemas de recomendação, análise de sentimento e mecanismos de busca. Especificamente, você pode usar essa abordagem se tiver equipes dedicadas de aprendizado de máquina (ML) e ciência de dados que ajustam seus próprios modelos de PLM usando conjuntos de dados específicos de domínio e implantam um grande número de pontos de extremidade de inferência usando Amazon Sage Maker. Um exemplo é um varejista on-line que implanta um grande número de pontos de extremidade de inferência para resumo de texto, classificação de catálogo de produtos e classificação de sentimento de feedback de produto. Outro exemplo pode ser um prestador de cuidados de saúde que utiliza pontos finais de inferência PLM para classificação de documentos clínicos, reconhecimento de entidades nomeadas a partir de relatórios médicos, chatbots médicos e estratificação de risco do paciente.
Visão geral da solução
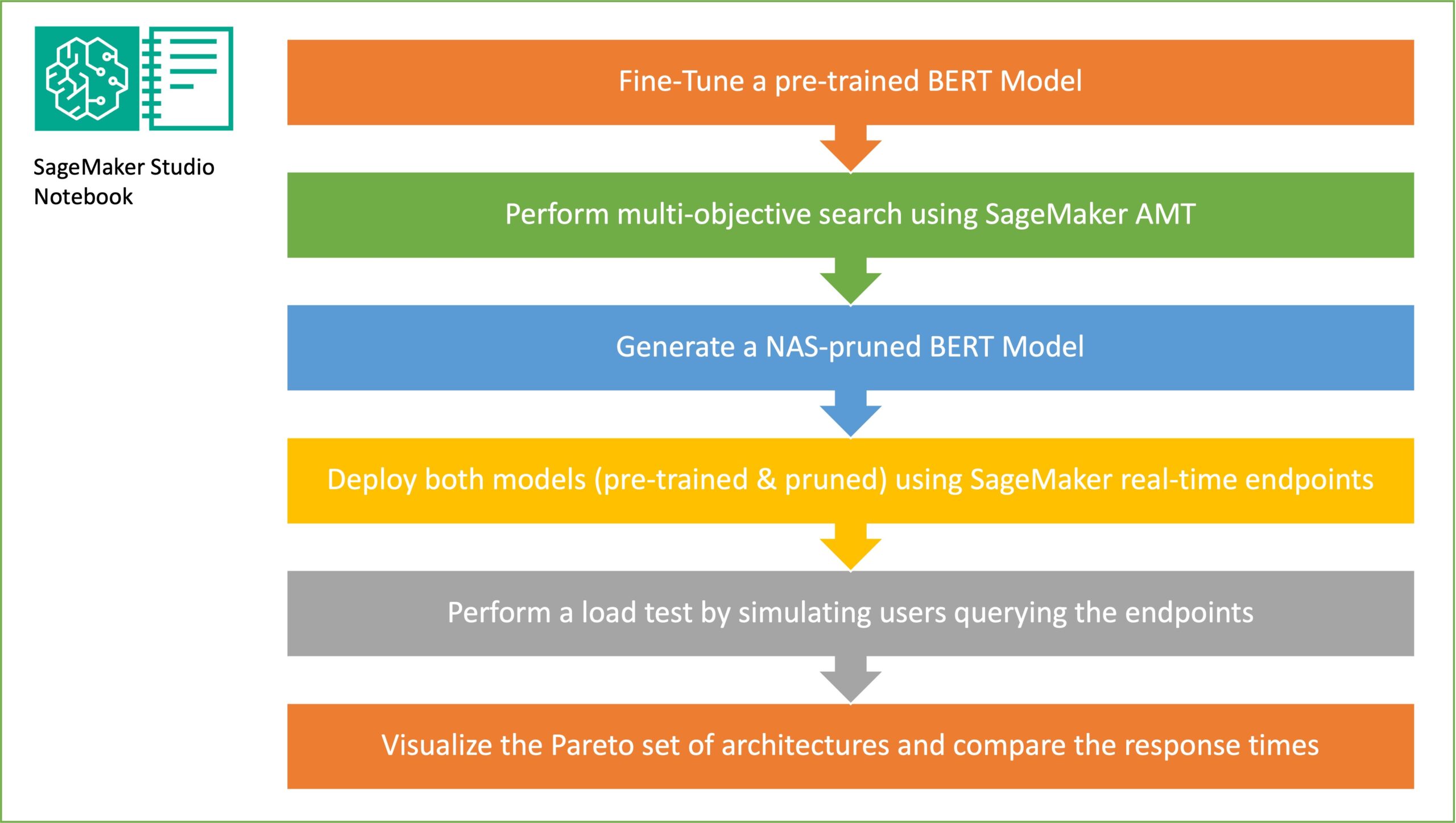
Nesta seção, apresentamos o fluxo de trabalho geral e explicamos a abordagem. Primeiro, usamos um Estúdio Amazon SageMaker caderno para ajustar um modelo BERT pré-treinado em uma tarefa de destino usando um conjunto de dados específico de domínio. BERT (Representações de codificador bidirecional de transformadores) é um modelo de linguagem pré-treinado baseado no arquitetura do transformador usado para tarefas de processamento de linguagem natural (PNL). A pesquisa de arquitetura neural (NAS) é uma abordagem para automatizar o projeto de redes neurais artificiais e está intimamente relacionada à otimização de hiperparâmetros, uma abordagem amplamente utilizada na área de aprendizado de máquina. O objetivo do NAS é encontrar a arquitetura ideal para um determinado problema, pesquisando um grande conjunto de arquiteturas candidatas usando técnicas como otimização sem gradiente ou otimizando as métricas desejadas. O desempenho da arquitetura normalmente é medido usando métricas como perda de validação. Ajuste automático de modelos do SageMaker (AMT) automatiza o processo tedioso e complexo de encontrar as combinações ideais de hiperparâmetros do modelo de ML que produzem o melhor desempenho do modelo. AMT usa algoritmos de pesquisa inteligentes e avaliações iterativas usando uma variedade de hiperparâmetros especificados por você. Ele escolhe os valores dos hiperparâmetros que criam um modelo com melhor desempenho, conforme medido por métricas de desempenho, como precisão e pontuação F-1.
A abordagem de ajuste fino descrita nesta postagem é genérica e pode ser aplicada a qualquer conjunto de dados baseado em texto. A tarefa atribuída ao BERT PLM pode ser uma tarefa baseada em texto, como análise de sentimento, classificação de texto ou perguntas e respostas. Nesta demonstração, a tarefa alvo é um problema de classificação binária onde o BERT é usado para identificar, a partir de um conjunto de dados que consiste em uma coleção de pares de fragmentos de texto, se o significado de um fragmento de texto pode ser inferido do outro fragmento. Nós usamos o Reconhecendo conjunto de dados de implicação textual do conjunto de benchmarking GLUE. Realizamos uma pesquisa multiobjetivo usando o SageMaker AMT para identificar as sub-redes que oferecem compensações ideais entre a contagem de parâmetros e a precisão da previsão para a tarefa alvo. Ao realizar uma pesquisa multiobjetivo, começamos definindo a precisão e a contagem de parâmetros como os objetivos que pretendemos otimizar.
Dentro da rede BERT PLM, pode haver sub-redes modulares e independentes que permitem que o modelo tenha recursos especializados, como compreensão de linguagem e representação de conhecimento. O BERT PLM usa uma sub-rede de autoatenção com várias cabeças e uma sub-rede feed-forward. Uma camada de autoatenção com múltiplas cabeças permite que o BERT relacione diferentes posições de uma única sequência, a fim de calcular uma representação da sequência, permitindo que múltiplas cabeças atendam a vários sinais de contexto. A entrada é dividida em vários subespaços e a autoatenção é aplicada a cada um dos subespaços separadamente. Múltiplos cabeçotes em um PLM de transformador permitem que o modelo atenda conjuntamente às informações de diferentes subespaços de representação. Uma sub-rede feed-forward é uma rede neural simples que obtém a saída da sub-rede de autoatenção com várias cabeças, processa os dados e retorna as representações finais do codificador.
O objetivo da amostragem aleatória de sub-redes é treinar modelos BERT menores que possam funcionar bem o suficiente nas tarefas alvo. Amostramos 100 sub-redes aleatórias do modelo BERT básico ajustado e avaliamos 10 redes simultaneamente. As sub-redes treinadas são avaliadas quanto às métricas objetivas e o modelo final é escolhido com base nas compensações encontradas entre as métricas objetivas. Visualizamos o Frente de Pareto para as sub-redes amostradas, que contém o modelo podado que oferece o compromisso ideal entre a precisão do modelo e o tamanho do modelo. Selecionamos a sub-rede candidata (modelo BERT podado por NAS) com base no tamanho do modelo e na precisão do modelo que estamos dispostos a negociar. Em seguida, hospedamos os endpoints, o modelo base BERT pré-treinado e o modelo BERT podado em NAS usando SageMaker. Para realizar testes de carga, usamos Gafanhoto, uma ferramenta de teste de carga de código aberto que você pode implementar usando Python. Executamos testes de carga em ambos os endpoints usando Locust e visualizamos os resultados usando a frente de Pareto para ilustrar a compensação entre tempos de resposta e precisão para ambos os modelos. O diagrama a seguir fornece uma visão geral do fluxo de trabalho explicado nesta postagem.
Pré-requisitos
Para esta postagem são necessários os seguintes pré-requisitos:
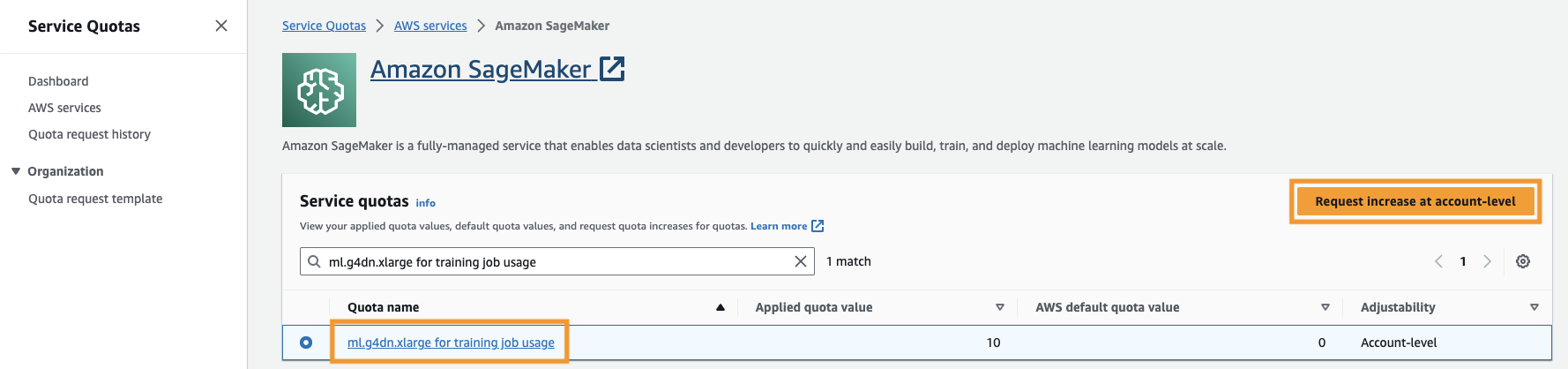
Você também precisa aumentar o cota de serviço para acessar pelo menos três instâncias de instâncias ml.g4dn.xlarge no SageMaker. O tipo de instância ml.g4dn.xlarge é a instância de GPU econômica que permite executar PyTorch nativamente. Para aumentar a cota de serviço, conclua as etapas a seguir:
- No console, navegue até Cotas de serviço.
- Escolha Gerenciar cotas, escolha Amazon Sage Maker, Em seguida, escolha Ver cotas.

- Pesquise “ml-g4dn.xlarge para uso de trabalho de treinamento” e selecione o item de cota.
- Escolha Solicitar aumento no nível da conta.
- Escolha Aumentar o valor da cota, insira um valor de 5 ou superior.
- Escolha SOLICITAÇÃO.
A aprovação da cota solicitada pode levar algum tempo para ser concluída, dependendo das permissões da conta.

- Abra o SageMaker Studio no console do SageMaker.

- Escolha Terminal do sistema para Utilitários e arquivos.

- Execute o seguinte comando para clonar o GitHub repo para a instância do SageMaker Studio:
- Navegar para
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Abra o arquivo
nas_for_llm_with_amt.ipynb. - Configure o ambiente com um
ml.g4dn.xlargeinstância e escolha Selecionar.

Configure o modelo BERT pré-treinado
Nesta seção, importamos o conjunto de dados Recognizing Textual Entailment da biblioteca de conjuntos de dados e dividimos o conjunto de dados em conjuntos de treinamento e validação. Este conjunto de dados consiste em pares de frases. A tarefa do BERT PLM é reconhecer, dados dois fragmentos de texto, se o significado de um fragmento de texto pode ser inferido do outro fragmento. No exemplo a seguir, podemos inferir o significado da primeira frase a partir da segunda frase:
Carregamos o conjunto de dados de implicação de reconhecimento textual do COLA conjunto de benchmarking através do biblioteca de conjunto de dados do Hugging Face dentro do nosso roteiro de treinamento (./training.py). Dividimos o conjunto de dados de treinamento original do GLUE em um conjunto de treinamento e validação. Em nossa abordagem, ajustamos o modelo BERT básico usando o conjunto de dados de treinamento e, em seguida, realizamos uma pesquisa multiobjetivo para identificar o conjunto de sub-redes que se equilibram de maneira ideal entre as métricas objetivas. Usamos o conjunto de dados de treinamento exclusivamente para ajustar o modelo BERT. No entanto, usamos dados de validação para a pesquisa multiobjetivo, medindo a precisão no conjunto de dados de validação de validação.
Ajuste o BERT PLM usando um conjunto de dados específico do domínio
Os casos de uso típicos para um modelo BERT bruto incluem previsão da próxima frase ou modelagem de linguagem mascarada. Para usar o modelo BERT básico para tarefas posteriores, como implicação de reconhecimento textual, temos que ajustar ainda mais o modelo usando um conjunto de dados específico do domínio. Você pode usar um modelo BERT ajustado para tarefas como classificação de sequência, resposta a perguntas e classificação de token. No entanto, para os fins desta demonstração, usamos o modelo ajustado para classificação binária. Ajustamos o modelo BERT pré-treinado com o conjunto de dados de treinamento que preparamos anteriormente, usando os seguintes hiperparâmetros:
Salvamos o ponto de verificação do treinamento do modelo em um Serviço de armazenamento simples da Amazon (Amazon S3), para que o modelo possa ser carregado durante a pesquisa multiobjetivo baseada em NAS. Antes de treinarmos o modelo, definimos as métricas como época, perda de treinamento, número de parâmetros e erro de validação:
Após o início do processo de ajuste fino, o trabalho de treinamento leva cerca de 15 minutos para ser concluído.
Realize uma pesquisa multiobjetivo para selecionar sub-redes e visualizar os resultados
Na próxima etapa, realizamos uma pesquisa multiobjetivo no modelo BERT de base ajustado, amostrando sub-redes aleatórias usando SageMaker AMT. Para acessar uma sub-rede dentro da super-rede (o modelo BERT ajustado), mascaramos todos os componentes do PLM que não fazem parte da sub-rede. Mascarar uma super-rede para encontrar sub-redes em um PLM é uma técnica usada para isolar e identificar padrões de comportamento do modelo. Observe que os transformadores Hugging Face precisam que o tamanho oculto seja um múltiplo do número de cabeças. O tamanho oculto em um PLM de transformador controla o tamanho do espaço vetorial de estado oculto, o que afeta a capacidade do modelo de aprender representações e padrões complexos nos dados. Em um BERT PLM, o vetor de estado oculto tem tamanho fixo (768). Não podemos alterar o tamanho oculto e, portanto, o número de caras deve estar em [1, 3, 6, 12].
Em contraste com a otimização de objetivo único, no cenário multiobjetivo, normalmente não temos uma solução única que otimize simultaneamente todos os objetivos. Em vez disso, pretendemos coletar um conjunto de soluções que domine todas as outras soluções em pelo menos um objetivo (como erro de validação). Agora podemos iniciar a busca multiobjetivo através do AMT definindo as métricas que queremos reduzir (erro de validação e número de parâmetros). As sub-redes aleatórias são definidas pelo parâmetro max_jobs e o número de jobs simultâneos é definido pelo parâmetro max_parallel_jobs. O código para carregar o ponto de verificação do modelo e avaliar a sub-rede está disponível no arquivo evaluate_subnetwork.py script.
A tarefa de ajuste do AMT leva aproximadamente 2 horas e 20 minutos para ser executada. Após a execução bem-sucedida do trabalho de ajuste AMT, analisamos o histórico do trabalho e coletamos as configurações da sub-rede, como número de cabeçotes, número de camadas, número de unidades e as métricas correspondentes, como erro de validação e número de parâmetros. A captura de tela a seguir mostra o resumo de um trabalho de sintonizador AMT bem-sucedido.
A seguir, visualizamos os resultados usando um conjunto de Pareto (também conhecido como fronteira de Pareto ou conjunto ótimo de Pareto), que nos ajuda a identificar conjuntos ideais de sub-redes que dominam todas as outras sub-redes na métrica objetiva (erro de validação):
Primeiro, coletamos os dados do trabalho de ajuste do AMT. Então plotamos o conjunto de Pareto usando matplotlob.pyplot com número de parâmetros no eixo x e erro de validação no eixo y. Isto implica que quando passamos de uma sub-rede do conjunto de Pareto para outra, devemos sacrificar o desempenho ou o tamanho do modelo, mas melhorar o outro. Em última análise, o conjunto de Pareto nos proporciona flexibilidade para escolher a sub-rede que melhor atende às nossas preferências. Podemos decidir quanto queremos reduzir o tamanho da nossa rede e quanto desempenho estamos dispostos a sacrificar.

Implante o modelo BERT ajustado e o modelo de sub-rede otimizado para NAS usando SageMaker
Em seguida, implantamos o maior modelo em nosso conjunto de Pareto que leva à menor quantidade de degeneração de desempenho para um Endpoint SageMaker. O melhor modelo é aquele que fornece um equilíbrio ideal entre o erro de validação e o número de parâmetros para o nosso caso de uso.
Comparação de modelos
Pegamos um modelo BERT básico pré-treinado, ajustamos-o usando um conjunto de dados específico de domínio, executamos uma pesquisa NAS para identificar sub-redes dominantes com base nas métricas objetivas e implantamos o modelo removido em um endpoint SageMaker. Além disso, pegamos o modelo BERT básico pré-treinado e implantamos o modelo básico em um segundo endpoint SageMaker. A seguir, corremos teste de carga usando Locust em ambos os endpoints de inferência e avaliou o desempenho em termos de tempo de resposta.
Primeiro, importamos as bibliotecas Locust e Boto3 necessárias. Em seguida, construímos metadados de solicitação e registramos o horário de início a ser usado para teste de carga. Em seguida, a carga útil é passada para a API de invocação do endpoint SageMaker por meio do BotoClient para simular solicitações reais do usuário. Usamos o Locust para gerar vários usuários virtuais para enviar solicitações em paralelo e medir o desempenho do endpoint sob carga. Os testes são executados aumentando o número de usuários para cada um dos dois terminais, respectivamente. Após a conclusão dos testes, o Locust gera um arquivo CSV de estatísticas de solicitação para cada um dos modelos implantados.
A seguir, geramos os gráficos de tempo de resposta a partir dos arquivos CSV baixados após a execução dos testes com o Locust. O objetivo de traçar o tempo de resposta versus o número de usuários é analisar os resultados do teste de carga, visualizando o impacto do tempo de resposta dos endpoints do modelo. No gráfico a seguir, podemos ver que o endpoint do modelo podado NAS atinge um tempo de resposta menor em comparação com o endpoint do modelo BERT base.
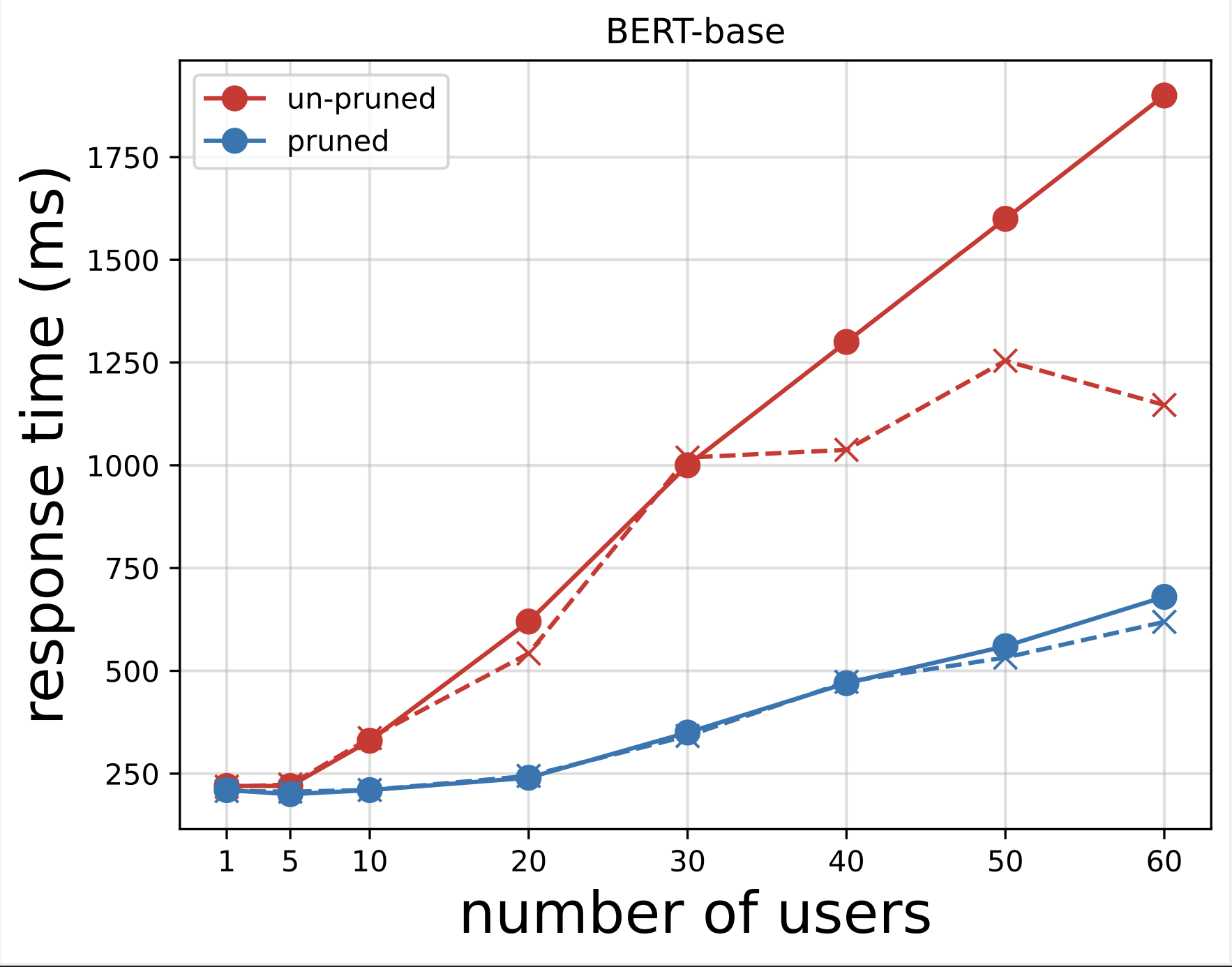
No segundo gráfico, que é uma extensão do primeiro gráfico, observamos que após cerca de 70 usuários, o SageMaker começa a limitar o endpoint do modelo BERT básico e lança uma exceção. No entanto, para o endpoint do modelo removido do NAS, a limitação ocorre entre 90 e 100 usuários e com um tempo de resposta menor.

Nos dois gráficos, observamos que o modelo podado tem um tempo de resposta mais rápido e é melhor dimensionado quando comparado ao modelo não podado. À medida que dimensionamos o número de endpoints de inferência, como é o caso dos usuários que implantam um grande número de endpoints de inferência para seus aplicativos de PLM, os benefícios de custo e a melhoria de desempenho começam a se tornar bastante substanciais.
limpar
Para excluir os endpoints do SageMaker para o modelo BERT básico ajustado e o modelo removido do NAS, conclua as seguintes etapas:
- No console SageMaker, escolha Inferência e Pontos finais no painel de navegação.
- Selecione o endpoint e exclua-o.
Alternativamente, no notebook SageMaker Studio, execute os seguintes comandos fornecendo os nomes dos endpoints:
Conclusão
Nesta postagem, discutimos como usar NAS para podar um modelo BERT ajustado. Primeiro treinamos um modelo BERT básico usando dados específicos do domínio e o implantamos em um endpoint SageMaker. Realizamos uma pesquisa multiobjetivo no modelo BERT básico ajustado usando SageMaker AMT para uma tarefa alvo. Visualizamos a frente de Pareto e selecionamos o modelo BERT otimizado para NAS de Pareto e implantamos o modelo em um segundo endpoint SageMaker. Realizamos testes de carga usando Locust para simular usuários consultando ambos os endpoints e medimos e registramos os tempos de resposta em um arquivo CSV. Plotamos o tempo de resposta versus o número de usuários para ambos os modelos.
Observamos que o modelo BERT removido teve um desempenho significativamente melhor tanto no tempo de resposta quanto no limite de otimização da instância. Concluímos que o modelo removido do NAS foi mais resiliente a um aumento de carga no endpoint, mantendo um tempo de resposta menor mesmo quando mais usuários estressaram o sistema em comparação com o modelo BERT básico. Você pode aplicar a técnica NAS descrita nesta postagem a qualquer modelo de linguagem grande para encontrar um modelo podado que possa executar a tarefa alvo com um tempo de resposta significativamente menor. Você pode otimizar ainda mais a abordagem usando a latência como parâmetro, além da perda de validação.
Embora usemos NAS nesta postagem, a quantização é outra abordagem comum usada para otimizar e compactar modelos PLM. A quantização reduz a precisão dos pesos e ativações em uma rede treinada de ponto flutuante de 32 bits para larguras de bits mais baixas, como números inteiros de 8 ou 16 bits, o que resulta em um modelo compactado que gera inferência mais rápida. A quantização não reduz o número de parâmetros; em vez disso, reduz a precisão dos parâmetros existentes para obter um modelo compactado. A remoção do NAS remove redes redundantes em um PLM, o que cria um modelo esparso com menos parâmetros. Normalmente, a remoção e a quantização do NAS são usadas juntas para compactar PLMs grandes a fim de manter a precisão do modelo, reduzir perdas de validação e, ao mesmo tempo, melhorar o desempenho e reduzir o tamanho do modelo. As outras técnicas comumente usadas para reduzir o tamanho dos PLMs incluem destilação de conhecimento, fatoração de matrizes e cascatas de destilação.
A abordagem proposta na postagem do blog é adequada para equipes que usam o SageMaker para treinar e ajustar os modelos usando dados específicos do domínio e implantar os endpoints para gerar inferência. Se você procura um serviço totalmente gerenciado que ofereça uma escolha de modelos básicos de alto desempenho necessários para criar aplicativos generativos de IA, considere usar Rocha Amazônica. Se você estiver procurando modelos de código aberto pré-treinados para uma ampla variedade de casos de uso de negócios e quiser acessar modelos de soluções e blocos de anotações de exemplo, considere usar JumpStart do Amazon SageMaker. Uma versão pré-treinada do modelo base Hugging Face BERT que usamos nesta postagem também está disponível no SageMaker JumpStart.
Sobre os autores
 Aparajithan Vaidyanathan é arquiteto principal de soluções empresariais na AWS. Ele é um arquiteto de nuvem com mais de 24 anos de experiência projetando e desenvolvendo sistemas de software corporativos, de grande escala e distribuídos. Ele é especialista em IA generativa e engenharia de dados de aprendizado de máquina. Ele é um aspirante a corredor de maratona e seus hobbies incluem caminhadas, andar de bicicleta e passar tempo com sua esposa e dois filhos.
Aparajithan Vaidyanathan é arquiteto principal de soluções empresariais na AWS. Ele é um arquiteto de nuvem com mais de 24 anos de experiência projetando e desenvolvendo sistemas de software corporativos, de grande escala e distribuídos. Ele é especialista em IA generativa e engenharia de dados de aprendizado de máquina. Ele é um aspirante a corredor de maratona e seus hobbies incluem caminhadas, andar de bicicleta e passar tempo com sua esposa e dois filhos.
 Aaron Klein é cientista aplicado sênior na AWS e trabalha em métodos automatizados de aprendizado de máquina para redes neurais profundas.
Aaron Klein é cientista aplicado sênior na AWS e trabalha em métodos automatizados de aprendizado de máquina para redes neurais profundas.
 Jacek Golebiowski é um cientista aplicado sênior na AWS.
Jacek Golebiowski é um cientista aplicado sênior na AWS.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :tem
- :é
- :não
- :onde
- ][p
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- habilidade
- Capaz
- Acesso
- Conta
- precisão
- Alcançar
- Alcança
- ativações
- Adição
- Adoção
- Depois de
- AI
- visar
- Visando
- algoritmos
- Todos os Produtos
- permitir
- Permitindo
- permite
- tb
- Amazon
- Amazon Web Services
- quantidade
- an
- análise
- analítica
- analisar
- e
- Outro
- responder
- qualquer
- api
- aplicações
- aplicado
- Aplicar
- Aplicando
- abordagem
- aprovação
- aproximadamente
- arquitetura
- SOMOS
- ÁREA
- áreas
- argumentos
- por aí
- artificial
- redes neurais artificiais
- AS
- aspirador
- atribuído
- associado
- At
- tentando
- comparecer
- Automatizado
- aprendizado de máquina automatizado
- automatiza
- Automático
- automatizando
- Automação
- disponível
- AWS
- eixo
- Equilíbrio
- base
- baseado
- BE
- tornam-se
- antes
- comportamento
- aferimento
- Benefícios
- MELHOR
- Melhor
- entre
- Pouco
- corpo
- ambos
- construir
- negócio
- Processo de negócio
- Business Process Automation
- mas a
- by
- CAN
- candidato
- capacidades
- casas
- casos
- catálogo
- alterar
- de cores
- charts
- chatbots
- escolha
- Escolha
- escolhido
- classe
- classificação
- Clínico
- de perto
- Na nuvem
- código
- coletar
- coleção
- combinações
- comercial
- comum
- geralmente
- comparado
- completar
- Efetuado
- integrações
- complexidade
- componentes
- computacional
- Computar
- conceitos
- Concluído
- Considerar
- consiste
- cônsul
- restrições
- construir
- consumo
- contém
- conteúdo
- Criação de conteúdo
- contexto
- continuar
- contraste
- controles
- Correspondente
- Custo
- custos
- contar
- crio
- cria
- criação
- cliente
- Atendimento ao Cliente
- dados,
- ciência de dados
- conjuntos de dados
- datetime
- decidir
- Tomada de Decisão
- dedicado
- profundo
- redes neurais profundas
- definir
- definido
- definição
- Demo
- demonstrar
- Dependendo
- implantar
- implantado
- Implantação
- implanta
- descrito
- Design
- concepção
- desejado
- em desenvolvimento
- diferente
- discutido
- distribuído
- documento
- Não faz
- dominante
- dominar
- não
- dois
- durante
- e
- cada
- eficiência
- eficiente
- ou
- Ponto final
- endpoints
- Engenharia
- Motores
- suficiente
- Entrar
- Empreendimento
- adoção empresarial
- Soluções Empresariais
- entidade
- entrada
- Meio Ambiente
- época
- erro
- Éter (ETH)
- avaliar
- avaliadas
- avaliações
- Mesmo
- eventos
- exemplo
- Exceto
- exceção
- exclusivamente
- existente
- vasta experiência
- Explicação
- explicado
- extensão
- Rosto
- falso
- mais rápido
- Funcionalidades
- retornos
- menos
- campo
- Envie o
- Arquivos
- final
- Encontre
- descoberta
- Primeiro nome
- fixado
- Flexibilidade
- flutuante
- seguinte
- Pegada
- Escolha
- encontrado
- Foundation
- da
- frente
- Frontier
- totalmente
- função
- mais distante
- gerar
- gera
- generativo
- IA generativa
- ter
- dado
- meta
- GPU
- cinza
- acontece
- Ter
- he
- cabeça
- cabeças
- saúde
- ajuda
- oculto
- Alta performance
- superior
- caminhadas
- sua
- história
- Hobbies
- hospedeiro
- hospedado
- HORÁRIO
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- http
- HTTPS
- Abraçando o Rosto
- Otimização de hiperparâmetros
- Ajuste de hiperparâmetros
- i
- identificar
- IDX
- if
- ilustrar
- Impacto
- Impacto
- executar
- importar
- melhorar
- melhorado
- melhoria
- melhorar
- in
- incluir
- Crescimento
- aumentou
- aumentando
- INFORMAÇÕES
- Infraestrutura
- entrada
- instância
- instâncias
- em vez disso
- Inteligente
- para dentro
- IT
- ESTÁ
- Trabalho
- Empregos
- jpg
- json
- Conhecimento
- conhecido
- língua
- grande
- em grande escala
- maior
- Latência
- camada
- camadas
- Leads
- APRENDER
- aprendizagem
- mínimo
- deixar
- bibliotecas
- Biblioteca
- Line
- carregar
- log
- logging
- procurando
- fora
- perdas
- diminuir
- máquina
- aprendizado de máquina
- a manter
- manutenção
- homem
- gerenciados
- Maratona
- máscara
- matplotlib
- máximo
- Posso..
- significado
- a medida
- medido
- medição
- médico
- Conheça
- Memória
- metadados
- métodos
- métrico
- Métrica
- poder
- minimizar
- minutos
- ML
- modelo
- modelagem
- modelos
- modulares
- mais
- mover
- muito
- múltiplo
- devo
- nome
- Nomeado
- nomes
- NAS
- natural
- Linguagem Natural
- Processamento de linguagem natural
- Navegar
- Navegação
- necessário
- você merece...
- necessário
- Cria
- rede
- redes
- Neural
- rede neural
- redes neurais
- Próximo
- PNL
- nenhum
- nota
- caderno
- laptops
- agora
- número
- objeto
- objetivo
- objetivos
- observar
- observado
- of
- WOW!
- oferecer
- Oferece
- on
- ONE
- online
- varejista on-line
- só
- aberto
- open source
- ideal
- otimização
- Otimize
- otimizado
- Otimiza
- otimizando
- or
- ordem
- original
- Outros
- A Nossa
- Fora
- saída
- outputs
- Acima de
- global
- Visão geral
- próprio
- pares
- pão
- Paralelo
- parâmetro
- parâmetros
- Pareto
- parte
- passou
- caminho
- paciente
- padrões
- realizar
- atuação
- realizada
- realização
- executa
- permissões
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- pontos
- abertas
- Publique
- Precisão
- predição
- preditivo
- Predictor
- preferências
- preparado
- pré-requisitos
- presente
- anteriormente
- Diretor
- Problema
- processo
- Automação de Processos
- processos
- em processamento
- Produto
- produtividade
- Ferramentas de Produtividade
- proposto
- provedor
- fornece
- fornecendo
- puxando
- Pullover
- propósito
- fins
- Python
- pytorch
- Dúvidas
- questão
- bastante
- acaso
- alcance
- rápido
- Preços
- Cru
- reais
- reconhecimento
- reconhecer
- reconhecendo
- Recomendação
- recomendações
- registro
- gravado
- Vermelho
- reduzir
- Reduzido
- reduz
- regressão
- relacionado
- remove
- removendo
- Relatórios
- representação
- solicitar
- solicitadas
- pedidos
- requeridos
- Requisitos
- resiliente
- recurso
- Recursos
- respectivamente
- resposta
- Resultados
- varejista
- retenção
- Retorna
- equitação
- Risco
- LINHA
- Execute
- corredor
- corrida
- é executado
- s
- sacrificar
- sábio
- Inferência do SageMaker
- Salvar
- Escala
- Escalas
- Ciência
- Cientista
- Ponto
- escrita
- Pesquisar
- Mecanismos de busca
- pesquisar
- Segundo
- Seção
- Vejo
- selecionar
- selecionado
- AUTO
- enviar
- sentença
- sentimento
- Seqüência
- serviço
- Serviços
- Sessão
- conjunto
- Conjuntos
- contexto
- Shows
- sinais
- de forma considerável
- simples
- Simultâneo
- simultaneamente
- solteiro
- Tamanho
- menor
- So
- Software
- solução
- Soluções
- alguns
- fonte
- Espaço
- O Spawn
- especializado
- especializada
- específico
- especificamente
- Passar
- divisão
- começo
- começa
- Estado
- estatística
- Passo
- Passos
- armazenamento
- estrutural
- estruturada
- estudo
- substancial
- bem sucedido
- entraram com sucesso
- tal
- adequado
- suíte
- RESUMO
- .
- sistemas
- T
- Tire
- toma
- Target
- Tarefa
- tarefas
- equipes
- técnica
- técnicas
- modelos
- condições
- ensaio
- testes
- texto
- Classificação de Texto
- textual
- do que
- que
- A
- deles
- então
- Lá.
- assim sendo
- Este
- isto
- três
- limiar
- Através da
- tempo
- vezes
- para
- juntos
- token
- levou
- ferramenta
- ferramentas
- comércio
- Trading
- Trem
- treinado
- Training
- transformador
- transformadores
- verdadeiro
- tentar
- dois
- tipo
- tipos
- típico
- tipicamente
- Em última análise
- para
- passando
- compreensão
- unidades
- us
- usar
- caso de uso
- usava
- Utilizador
- usuários
- usos
- utilização
- validação
- valor
- Valores
- versão
- via
- Virtual
- visualizar
- vs
- queremos
- foi
- we
- web
- serviços web
- BEM
- quando
- se
- qual
- enquanto
- QUEM
- Largo
- Ampla variedade
- largamente
- mulher
- Wikipedia
- precisarão
- disposto
- de
- dentro
- Atividades:
- de gestão de documentos
- trabalhar
- X
- anos
- Produção
- Você
- investimentos
- zefirnet