Imagem do editor
Principais lições
- O teste t é um teste estatístico que pode ser usado para determinar se há uma diferença significativa entre as médias de duas amostras independentes de dados.
- Ilustramos como um teste t pode ser aplicado usando o conjunto de dados iris e a biblioteca Scipy do Python.
O teste t é um teste estatístico que pode ser usado para determinar se há uma diferença significativa entre as médias de duas amostras independentes de dados. Neste tutorial, ilustramos a versão mais básica do teste t, para a qual assumiremos que as duas amostras têm variâncias iguais. Outras versões avançadas do teste t incluem o teste t de Welch, que é uma adaptação do teste t e é mais confiável quando as duas amostras têm variâncias desiguais e tamanhos de amostra possivelmente desiguais.
A estatística t ou valor t é calculado da seguinte forma:
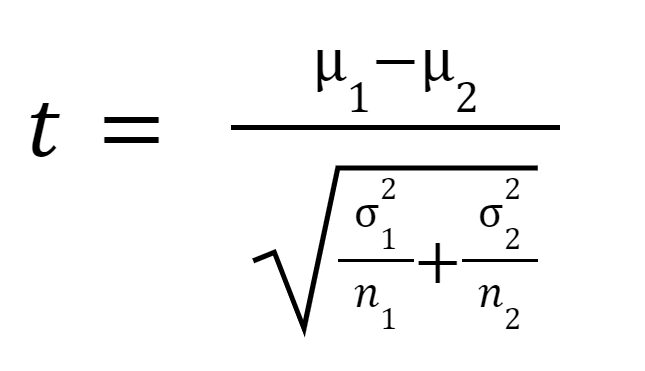
onde
é a média da amostra 1,
é a média da amostra 2,
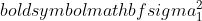 é a variância da amostra 1,
é a variância da amostra 1, 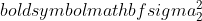 é a variância da amostra 2,
é a variância da amostra 2, 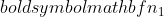 é o tamanho da amostra da amostra 1, e
é o tamanho da amostra da amostra 1, e 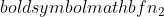 é o tamanho da amostra da amostra 2.
é o tamanho da amostra da amostra 2.
Para ilustrar o uso do teste t, mostraremos um exemplo simples usando o conjunto de dados da íris. Suponha que observamos duas amostras independentes, por exemplo, comprimentos de sépalas de flores, e estamos considerando se as duas amostras foram retiradas da mesma população (por exemplo, a mesma espécie de flor ou duas espécies com características de sépalas semelhantes) ou duas populações diferentes.
O teste t quantifica a diferença entre as médias aritméticas das duas amostras. O valor-p quantifica a probabilidade de obtenção dos resultados observados, assumindo que a hipótese nula (que as amostras são retiradas de populações com as mesmas médias populacionais) é verdadeira. Um valor-p maior que um limite escolhido (por exemplo, 5% ou 0.05) indica que nossa observação não é tão improvável de ter ocorrido por acaso. Portanto, aceitamos a hipótese nula de médias populacionais iguais. Se o valor-p for menor que nosso limite, então temos evidências contra a hipótese nula de médias populacionais iguais.
Entrada de teste t
As entradas ou parâmetros necessários para realizar um teste t são:
- Duas matrizes a e b contendo os dados para a amostra 1 e amostra 2
Saídas do Teste T
O teste t retorna o seguinte:
- As estatísticas t calculadas
- O valor p
Importar bibliotecas necessárias
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Carregar conjunto de dados de íris
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Calcular as médias e variâncias amostrais
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Implementar teste t
stats.ttest_ind(a_1, b_1, equal_var = False)
saída
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
saída
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
saída
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Observações
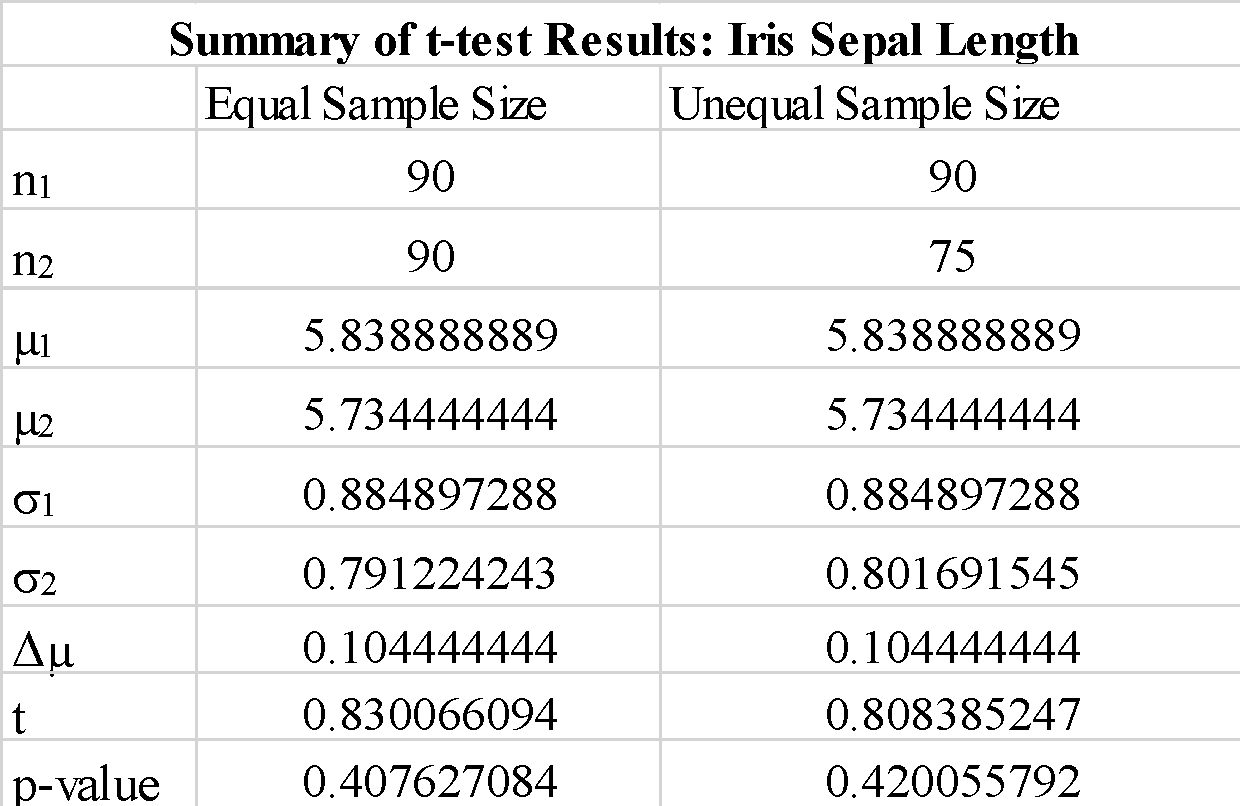
Observamos que o uso de “true” ou “false” para o parâmetro “equal-var” não altera muito os resultados do teste t. Também observamos que trocar a ordem das matrizes de amostra a_1 e b_1 produz um valor negativo do teste t, mas não altera a magnitude do valor do teste t, como esperado. Como o valor-p calculado é muito maior do que o valor limite de 0.05, podemos rejeitar a hipótese nula de que a diferença entre as médias da amostra 1 e da amostra 2 são significativas. Isso mostra que os comprimentos das sépalas para a amostra 1 e a amostra 2 foram extraídos dos mesmos dados populacionais.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Calcular as médias e variâncias amostrais
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Implementar teste t
stats.ttest_ind(a_1, b_1, equal_var = False)
saída
stats.ttest_ind(a_1, b_1, equal_var = False)Observações
Observamos que o uso de amostras com tamanho desigual não altera significativamente a estatística t e o valor p.
Em resumo, mostramos como um teste t simples pode ser implementado usando a biblioteca scipy em python.
Benjamin O. Tayo é um físico, educador de ciência de dados e escritor, bem como o proprietário do DataScienceHub. Anteriormente, Benjamin estava ensinando Engenharia e Física na U. of Central Oklahoma, Grand Canyon U. e Pittsburgh State U.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- ACEITAR
- avançado
- contra
- e
- aplicado
- basic
- Benjamin
- entre
- calculado
- central
- chance
- alterar
- características
- escolhido
- considerando
- poderia
- dados,
- ciência de dados
- conjuntos de dados
- Determinar
- diferença
- diferente
- desenhado
- Engenharia
- evidência
- exemplo
- esperado
- flor
- seguinte
- segue
- da
- Como funciona o dobrador de carta de canal
- HTTPS
- implementado
- importar
- in
- incluir
- de treinadores em Entrevista Motivacional
- indicam
- KDnuggetsGenericName
- Maior
- Biblioteca
- matplotlib
- significa
- mais
- a maioria
- necessário
- negativo
- numpy
- observar
- obtendo
- ocorreu
- Oklahoma
- ordem
- Outros
- proprietário
- parâmetro
- parâmetros
- realização
- Física
- Pittsburgh
- platão
- Inteligência de Dados Platão
- PlatãoData
- população
- populações
- anteriormente
- probabilidade
- Python
- confiável
- Resultados
- Retorna
- mesmo
- Ciência
- mostrar
- mostrando
- Shows
- periodo
- de forma considerável
- semelhante
- simples
- desde
- Tamanho
- tamanhos
- menor
- So
- Estado
- estatístico
- stats
- RESUMO
- Ensino
- teste
- A
- assim sendo
- limiar
- para
- verdadeiro
- tutorial
- usar
- valor
- versão
- se
- qual
- precisarão
- escritor
- rendimentos
- zefirnet