Com que frequência os projetos de aprendizado de máquina alcançam uma implantação bem-sucedida? Não com frequência suficiente. Há abundância of indústria pesquisa mostrando que os projetos de ML geralmente não geram retorno, mas poucos avaliaram a proporção entre fracasso e sucesso da perspectiva dos cientistas de dados – as pessoas que desenvolvem os próprios modelos que esses projetos pretendem implantar.
No seguimento uma pesquisa com cientistas de dados que conduzi com o KDnuggets no ano passado, a Pesquisa de Ciência de Dados líder do setor deste ano administrado pela consultoria de ML Rexer Analytics abordou a questão - em parte porque Karl Rexer, o fundador e presidente da empresa, permitiu que você participasse, impulsionando a inclusão de perguntas sobre o sucesso da implantação (parte do meu trabalho durante um ano de cátedra de análise que ocupei na UVA Darden).
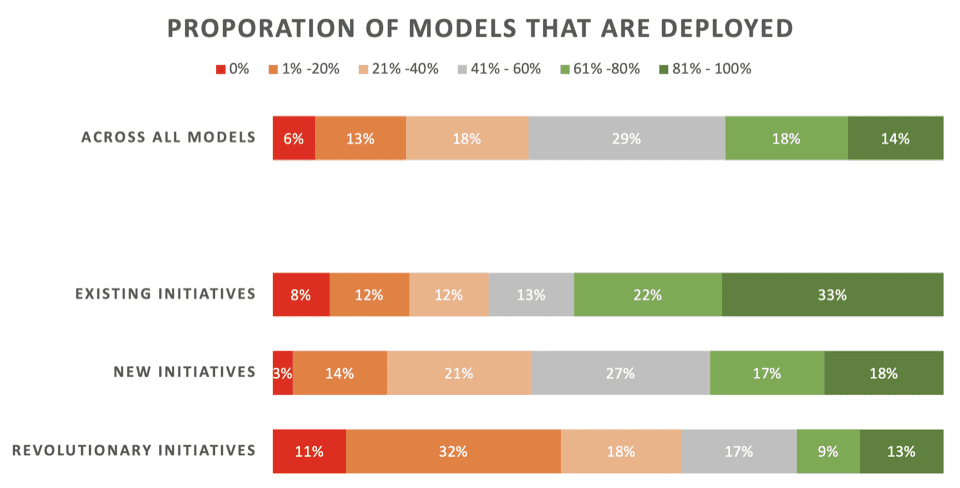
As notícias não são boas. Apenas 22% dos cientistas de dados afirmam que as suas iniciativas “revolucionárias” – modelos desenvolvidos para permitir um novo processo ou capacidade – são geralmente implementadas. 43% dizem que 80% ou mais não conseguem implantar.
Através todos os tipos de projetos de ML – incluindo modelos de atualização para implantações existentes – apenas 32% dizem que seus modelos geralmente são implantados.
Aqui estão os resultados detalhados dessa parte da pesquisa, apresentados pela Rexer Analytics, detalhando as taxas de implantação em três tipos de iniciativas de ML:
Chave:
- Iniciativas existentes: Modelos desenvolvidos para atualizar/atualizar um modelo existente que já foi implantado com sucesso
- Novas iniciativas: Modelos desenvolvidos para aprimorar um processo existente para o qual nenhum modelo já foi implantado
- Iniciativas revolucionárias: Modelos desenvolvidos para permitir um novo processo ou capacidade
Na minha opinião, esta luta para implementar decorre de dois factores principais que contribuem: o subplaneamento endémico e a falta de visibilidade concreta dos intervenientes empresariais. Muitos profissionais de dados e líderes empresariais não reconheceram que a operacionalização pretendida do ML deve ser planejada detalhadamente e perseguida agressivamente desde o início de cada projeto de ML.
Na verdade, escrevi um novo livro exatamente sobre isso: O manual de IA: dominando a rara arte da implantação de aprendizado de máquina. Neste livro, apresento uma prática de seis etapas focada na implantação para conduzir projetos de aprendizado de máquina desde a concepção até a implantação, que chamo bizML (encomende antecipadamente a capa dura ou o e-book e receba uma cópia avançada gratuita da versão do audiolivro agora mesmo).
A principal parte interessada de um projeto de ML – a pessoa responsável pela eficácia operacional alvo de melhoria, como um gestor de linha de negócios – precisa de visibilidade sobre como o ML irá melhorar precisamente as suas operações e quanto valor se espera que a melhoria proporcione. Eles precisam disso para, em última análise, dar luz verde à implantação de um modelo, bem como, antes disso, avaliar a execução do projeto durante os estágios de pré-implantação.
Mas o desempenho do ML muitas vezes não é medido! Quando a pesquisa da Rexer perguntou: “Com que frequência sua empresa/organização mede o desempenho de projetos analíticos?” apenas 48% dos cientistas de dados disseram “Sempre” ou “Na maioria das vezes”. Isso é muito selvagem. Deveria ser mais como 99% ou 100%.
E quando o desempenho é medido, é em termos de métricas técnicas que são misteriosas e, em sua maioria, irrelevantes para as partes interessadas do negócio. Os cientistas de dados sabem melhor, mas geralmente não obedecem – em parte porque as ferramentas de ML geralmente fornecem apenas métricas técnicas. De acordo com a pesquisa, os cientistas de dados classificam os KPIs de negócios, como ROI e receita, como as métricas mais importantes, mas listam métricas técnicas, como aumento e AUC, como as mais comumente medidas.
As métricas de desempenho técnico são “fundamentalmente inúteis e desconectadas das partes interessadas do negócio”, de acordo com Revisão de ciência de dados de Harvard. Aqui está o porquê: eles apenas dizem a você o relativo desempenho de um modelo, por exemplo, como ele se compara a uma estimativa ou outra linha de base. As métricas de negócios informam o absoluto valor de negócio que se espera que o modelo forneça – ou, ao avaliar após a implementação, que comprovadamente oferece. Essas métricas são essenciais para projetos de ML focados na implantação.
Além do acesso às métricas de negócios, as partes interessadas também precisam se desenvolver. Quando a pesquisa da Rexer perguntou: “Os gerentes e tomadores de decisão da sua organização que devem aprovar a implantação do modelo têm conhecimento suficiente para tomar tais decisões de maneira bem informada?” apenas 49% dos entrevistados responderam “Na maioria das vezes” ou “Sempre”.
Aqui está o que acredito que está acontecendo. O “cliente” do cientista de dados, a parte interessada do negócio, muitas vezes fica com medo quando se trata de autorizar a implantação, uma vez que isso significaria fazer uma mudança operacional significativa no pão com manteiga da empresa, nos seus processos de maior escala. Eles não têm a estrutura contextual. Por exemplo, eles se perguntam: “Como posso entender o quanto este modelo, que tem um desempenho muito inferior à perfeição de uma bola de cristal, realmente ajudará?” Assim o projeto morre. Então, colocar criativamente algum tipo de visão positiva nos “insights obtidos” serve para varrer o fracasso para debaixo do tapete. O hype da IA permanece intacto mesmo quando o valor potencial, o propósito do projeto, é perdido.
Sobre este tópico – aumentar as partes interessadas – vou divulgar meu novo livro, O manual de IA, só mais uma vez. Ao mesmo tempo que aborda a prática do bizML, o livro também aprimora as habilidades dos profissionais de negócios, fornecendo uma dose vital, porém amigável, de conhecimento prévio semitécnico que todas as partes interessadas precisam para liderar ou participar de projetos de aprendizado de máquina, de ponta a ponta. Isso coloca os profissionais de negócios e de dados na mesma página para que possam colaborar profundamente, estabelecendo em conjunto com precisão o que o aprendizado de máquina deve prever, quão bem ele prevê e como suas previsões são aplicadas para melhorar as operações. Esses princípios essenciais determinam o sucesso ou o fracasso de cada iniciativa – acertá-los abre o caminho para a implantação orientada por valor do aprendizado de máquina.
É seguro dizer que as coisas estão difíceis, especialmente para iniciativas de ML novas e de primeira tentativa. À medida que a força do hype da IA perde a sua capacidade de compensar continuamente
menos valor realizado do que o prometido, haverá cada vez mais pressão para provar o valor operacional do ML.? Então eu digo, saia na frente agora – comece a incutir uma cultura mais eficaz de colaboração entre empresas e liderança de projetos orientada para a implantação!
Para resultados mais detalhados do Pesquisa de ciência de dados da Rexer Analytics 2023, clique em SUA PARTICIPAÇÃO FAZ A DIFERENÇA. Esta é a maior pesquisa com profissionais de ciência e análise de dados do setor. Consiste em aproximadamente 35 questões abertas e de múltipla escolha que cobrem muito mais do que apenas taxas de sucesso de implantação – sete áreas gerais da ciência e prática de mineração de dados: (1) Campo e objetivos, (2) Algoritmos, (3) Modelos, ( 4) Ferramentas (pacotes de software utilizados), (5) Tecnologia, (6) Desafios e (7) Futuro. É conduzido como um serviço (sem patrocínio corporativo) para a comunidade de ciência de dados, e os resultados geralmente são anunciados em a conferência da Semana de Aprendizado de Máquina e compartilhados por meio de relatórios resumidos disponíveis gratuitamente.
Este artigo é produto do trabalho do autor enquanto ele ocupou o cargo de Professor do Bicentenário Corporal em Análise na UVA Darden School of Business por um ano, que culminou com a publicação de O manual de IA: dominando a rara arte da implantação de aprendizado de máquina (oferta de audiolivro grátis).
Eric Siegel, Ph.D., é um consultor líder e ex-professor da Universidade de Columbia que torna o aprendizado de máquina compreensível e cativante. Ele é o fundador do Mundo da análise preditiva e os votos de Mundo do aprendizado profundo série de conferências, que atendeu mais de 17,000 participantes desde 2009, o instrutor do aclamado curso Liderança e prática de aprendizado de máquina - domínio de ponta a ponta, um palestrante popular que foi comissionado para Mais de 100 discursos principais, e editor executivo da Os tempos de aprendizado de máquina. Ele foi o autor do best-seller Análise preditiva: o poder de prever quem vai clicar, comprar, mentir ou morrer, que foi usado em cursos em mais de 35 universidades, e ele ganhou prêmios de ensino quando era professor na Columbia University, onde cantou canções educacionais para seus alunos. Eric também publica artigos de opinião sobre análise e justiça social. Siga-o em @predictanalytic.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy?utm_source=rss&utm_medium=rss&utm_campaign=survey-machine-learning-projects-still-routinely-fail-to-deploy
- :tem
- :é
- :não
- :onde
- $UP
- 000
- 1
- 17
- 35%
- 7
- a
- habilidade
- Sobre
- Acesso
- aclamado
- Segundo
- em
- endereçado
- avançado
- Depois de
- agressivamente
- à frente
- AI
- algoritmos
- Todos os Produtos
- permitidas
- já
- tb
- sempre
- am
- an
- Analítico
- analítica
- e
- anunciou
- Outro
- aprovar
- aproximadamente
- Arcane
- SOMOS
- áreas
- Arte
- artigo
- AS
- At
- participantes
- Nenhum
- Autoria
- disponível
- prêmios
- longe
- fundo
- Linha de Base
- BE
- Porque
- sido
- antes
- Acreditar
- best-seller
- Melhor
- livro
- Pão
- Break
- Quebra
- negócio
- Líderes de negócios
- mas a
- comprar
- by
- chamada
- chamado
- CAN
- capacidade
- cativante
- desafios
- alterar
- carregar
- escolha
- clique
- cliente
- frio
- colaborar
- colaboração
- Columbia
- COM
- como
- vem
- geralmente
- comunidade
- Empresa
- Empresa
- concepção
- concreto
- conduzido
- Conferência
- consiste
- consultoria
- consultor
- contextual
- continuamente
- contribuindo
- Responsabilidade
- curso
- cursos
- cobrir
- cobertura
- Criativamente
- cs
- Cultura
- dados,
- mineração de dados
- ciência de dados
- cientista de dados
- decisores
- decisões
- profundamente
- entregar
- entregando
- implantar
- implantado
- desenvolvimento
- Implantações
- detalhe
- detalhado
- desenvolver
- desenvolvido
- desligado
- do
- parece
- don
- não
- dosar
- down
- condução
- durante
- cada
- editor
- Eficaz
- eficácia
- permitir
- final
- end-to-end
- endêmico
- aumentar
- suficiente
- eric
- especialmente
- essencial
- fundamentos
- estabelecendo
- Éter (ETH)
- avaliação
- Mesmo
- Cada
- exemplo
- execução
- executivo
- existente
- esperado
- fato
- fatores
- FALHA
- Falha
- longe
- pés
- poucos
- campo
- seguir
- Escolha
- força
- Antigo
- fundador
- Quadro
- Gratuito
- livremente
- amigável
- da
- futuro
- ganhou
- Geral
- geralmente
- ter
- obtendo
- Objetivos
- ótimo
- Acontecimento
- Ter
- he
- Herói
- ajudar
- ele
- sua
- Como funciona o dobrador de carta de canal
- HTML
- http
- HTTPS
- Hype
- i
- IBM
- importante
- melhorar
- melhoria
- in
- começo
- Incluindo
- inclusão
- indústria
- líder da indústria
- Iniciativa
- iniciativas
- insights
- Pretendido
- para dentro
- introduzir
- isn
- IT
- ESTÁ
- apenas por
- apenas um
- karl
- KDnuggetsGenericName
- Chave
- Principal
- Tipo
- Saber
- Conhecimento
- sem
- maior
- Sobrenome
- Ano passado
- conduzir
- líderes
- Liderança
- principal
- aprendizagem
- mentira
- como
- Lista
- ll
- Perde
- perdido
- máquina
- aprendizado de máquina
- a Principal
- fazer
- FAZ
- Fazendo
- Gerente
- Gerentes
- maneira
- muitos
- Dominar
- significar
- significava
- a medida
- medido
- Métrica
- Mineração
- MIT
- ML
- modelo
- modelos
- mais
- a maioria
- na maioria das vezes
- muito
- múltiplo
- devo
- my
- você merece...
- Cria
- Novo
- notícias
- não
- agora
- of
- frequentemente
- on
- ONE
- queridos
- só
- operacional
- Operações
- or
- ordem
- organização
- Fora
- pacotes
- página
- parte
- participar
- pavimentar
- perfeição
- atuação
- executa
- pessoa
- perspectiva
- planejado
- platão
- Inteligência de Dados Platão
- PlatãoData
- plugue
- Popular
- posição
- positivo
- potencial
- poder
- prática
- pré-encomenda
- Precioso
- justamente
- predizer
- Previsões
- Previsões
- apresentado
- presidente
- pressão
- bastante
- processo
- processos
- Produto
- Professor
- projeto
- projetos
- prometido
- Prove
- comprovado
- Publicação
- Publica
- propósito
- Coloca
- Colocar
- questão
- Frequentes
- Rampa
- rampa
- classificar
- RARO
- Preços
- relação
- alcançar
- realizado
- reconhecer
- permanece
- Relatórios
- respondentes
- Resultados
- Retorna
- receita
- revolucionário
- certo
- rochoso
- ROI
- rotineiramente
- Execute
- s
- seguro
- Dito
- mesmo
- dizer
- Escala
- Escola
- Ciência
- Cientista
- cientistas
- Série
- servir
- servido
- serve
- serviço
- Sete
- compartilhado
- periodo
- desde
- So
- Redes Sociais
- Software
- alguns
- Palestrantes
- Spin
- de patrocínio
- Estágio
- partes interessadas
- partes interessadas
- começo
- deriva
- Ainda
- Lutar
- Estudantes
- sucesso
- bem sucedido
- entraram com sucesso
- tal
- RESUMO
- Vistorias
- Varrer
- T
- visadas
- Ensino
- Dados Técnicos:
- Tecnologia
- dizer
- condições
- do que
- que
- A
- deles
- Eles
- então
- Lá.
- Este
- deles
- isto
- três
- todo
- Assim
- tempo
- para
- ferramentas
- tópico
- verdadeiramente
- dois
- Em última análise
- para
- compreender
- compreensível
- Universidades
- universidade
- sobre
- usava
- inaugurando
- geralmente
- valor
- Ve
- muito
- via
- Ver
- visibilidade
- vital
- foi
- Caminho..
- semana
- pesar
- BEM
- O Quê
- quando
- qual
- enquanto
- QUEM
- porque
- Selvagem
- precisarão
- de
- sem
- Ganhou
- maravilha
- Atividades:
- seria
- escrito
- ano
- ainda
- Você
- investimentos
- zefirnet








