Hoje, estamos disponibilizando um novo recurso de Cola AWS Catálogo de Dados que permite gerar estatísticas em nível de coluna para tabelas do AWS Glue. Estas estatísticas estão agora integradas com os otimizadores baseados em custos (CBO) de Amazona atena e Amazon Espectro Redshift, resultando em melhor desempenho de consulta e possível economia de custos.
Os data lakes são projetados para armazenar grandes quantidades de dados brutos, não estruturados ou semiestruturados a um custo baixo, e as organizações compartilham esses conjuntos de dados entre vários departamentos e equipes. As consultas nesses grandes conjuntos de dados leem grandes quantidades de dados e podem realizar operações complexas de junção em vários conjuntos de dados. Ao conversar com nossos clientes, aprendemos que um dos aspectos desafiadores do desempenho do data lake é como otimizar essas consultas analíticas para serem executadas com mais rapidez.
A otimização do desempenho do data lake é especialmente importante para consultas com múltiplas junções e é aí que os otimizadores baseados em custos ajudam mais. Para que o CBO funcione, as estatísticas das colunas precisam ser coletadas e atualizadas com base nas alterações nos dados. Estamos lançando a capacidade de gerar estatísticas em nível de coluna, como número de distintos, número de nulos, máximo e mínimo em arquivos como Parquet, ORC, JSON, Amazon ION, CSV, XML em tabelas do AWS Glue. Com este lançamento, os clientes agora têm uma experiência integrada de ponta a ponta, na qual as estatísticas das tabelas do Glue são coletadas e armazenadas no catálogo do AWS Glue e disponibilizadas aos serviços de análise para melhorar o planejamento e a execução de consultas.
Usando essas estatísticas, os otimizadores baseados em custos melhoram os planos de execução de consultas e aumentam o desempenho das consultas executadas no Amazon Athena e no Amazon Redshift Spectrum. Por exemplo, o CBO pode usar estatísticas de coluna, como número de valores distintos e número de nulos, para melhorar a previsão de linha. A previsão de linha é o número de linhas de uma tabela que será retornada em uma determinada etapa durante o estágio de planejamento da consulta. Quanto mais precisas forem as previsões de linha, mais eficientes serão as etapas de execução da consulta. Isso leva a uma execução de consulta mais rápida e a custos potencialmente reduzidos. Algumas das otimizações específicas que o CBO pode empregar incluem reordenação de junção e pushdown de agregações com base nas estatísticas disponíveis para cada tabela e coluna.
Para clientes que usam malha de dados de Formação AWS Lake permissões, tabelas de diferentes produtores de dados são catalogadas nas contas de governança centralizadas. À medida que geram estatísticas em tabelas no catálogo centralizado e compartilham essas tabelas com os consumidores, as consultas nessas tabelas nas contas dos consumidores verão melhorias de desempenho de consulta automaticamente. Nesta postagem, demonstraremos a capacidade do AWS Glue Data Catalog de gerar estatísticas de coluna para nossas tabelas de amostra.
Visão geral da solução
Para demonstrar a eficácia desse recurso, empregamos o conjunto de dados TPC-DS de 3 TB, padrão do setor, armazenado em um Amazon Simple Storage Service (Amazon S3) balde público. Compararemos o desempenho da consulta antes e depois de gerar estatísticas de coluna para as tabelas, executando consultas no Amazon Athena e no Amazon Redshift Spectrum. Estamos fornecendo as consultas que usamos nesta postagem e encorajamos você a testar suas próprias consultas seguindo o fluxo de trabalho conforme ilustrado nos detalhes a seguir.
O fluxo de trabalho consiste nas seguintes etapas de alto nível:
- Catalogando o bucket Amazon S3: Utilize o AWS Glue Crawler para rastrear o bucket designado do Amazon S3, extraindo metadados e armazenando-os perfeitamente no catálogo de dados do AWS Glue. Consultaremos essas tabelas usando o Amazon Athena e o Amazon Redshift Spectrum.
- Gerando estatísticas de coluna: Utilize os recursos aprimorados do AWS Glue Data Catalog para gerar estatísticas de coluna abrangentes para os dados rastreados, fornecendo assim insights valiosos sobre o conjunto de dados.
- Consultando com Amazon Athena e Amazon Redshift Spectrum: Avalie o impacto das estatísticas de colunas no desempenho das consultas utilizando o Amazon Athena e o Amazon Redshift Spectrum para executar consultas no conjunto de dados.
O diagrama a seguir ilustra a arquitetura da solução.
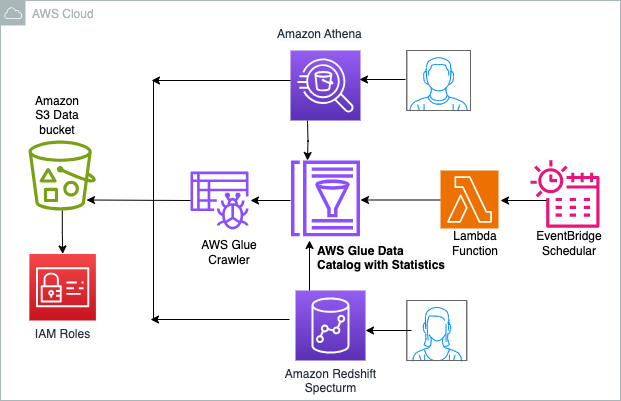
Passo a passo
Para implementar a solução, concluímos as seguintes etapas:
- Configurar recursos com Formação da Nuvem AWS.
- Execute o AWS Glue Crawler no bucket público do Amazon S3 para listar o conjunto de dados TPC-DS de 3 TB.
- Execute consultas no Amazon Athena e no Amazon Redshift e anote a duração da consulta
- Gerar estatísticas para tabelas do AWS Glue Data Catalog
- Execute consultas no Amazon Athena e no Amazon Redshift e compare a duração da consulta com a execução anterior
- Opcional: programe trabalhos de estatísticas de coluna do AWS Glue usando o AWS Lambda e o Amazon EventBridge Scheduler
Configure recursos com AWS CloudFormation
Esta postagem inclui um Formação da Nuvem AWS modelo para uma configuração rápida. Você pode revisá-lo e personalizá-lo para atender às suas necessidades. O modelo gera os seguintes recursos:
- Uma nuvem privada virtual da Amazon (Amazon VPC), sub-redes públicas, sub-redes privadas e tabelas de rotas.
- Um grupo de trabalho e namespace sem servidor do Amazon Redshift.
- Um rastreador do AWS Glue para rastrear o bucket público do Amazon S3 e criar uma tabela para o conjunto de dados Glue Data Catalog for TPC-DS
- Bancos de dados e tabelas de catálogo do AWS Glue
- Um bucket do Amazon S3 para armazenar o resultado do Athena.
- Gerenciamento de acesso e identidade da AWS (AWS IAM) usuários e políticas.
- Agendador AWS Lambda e Amazon Event Bridge para agendar as estatísticas da coluna AWS Glue
Para iniciar a pilha do AWS CloudFormation, execute as seguintes etapas:
Note: as tabelas do catálogo de dados do AWS Glue são geradas usando o bucket público s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned/, hospedado no us-east-1 região. Se você pretende implantar esse modelo do AWS CloudFormation em uma região diferente, será necessário copiar os dados para a região correspondente ou compartilhar os dados na região implantada para que possam ser acessados no Amazon Redshift.
- Faça o login no Console de gerenciamento da AWS como AWS Identity and Access Management (AWS IAM) administrador.
- Escolha Launch Stack para implantar um modelo do AWS CloudFormation.

- Escolha Próximo.
- Na próxima página, mantenha todas as opções como padrão ou faça as alterações apropriadas com base em sua necessidade, escolha Próximo.
- Revise os detalhes na página final e selecione Reconheço que o AWS CloudFormation pode criar recursos do IAM.
- Escolha Crie.
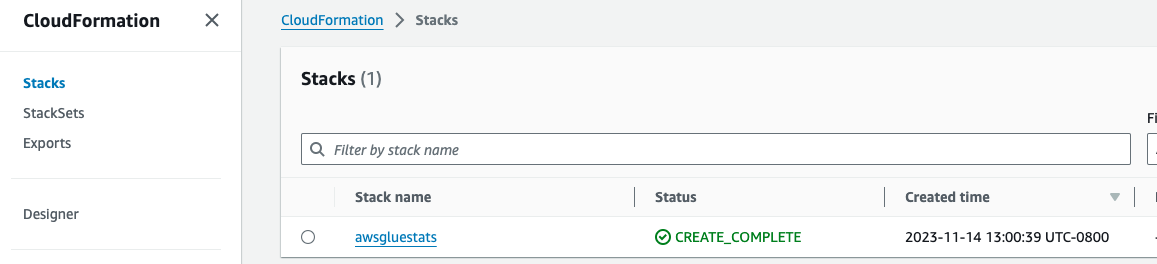
Essa pilha pode levar cerca de 10 minutos para ser concluída, após o que você pode visualizar a pilha implantada no console do AWS CloudFormation.
Execute os crawlers do AWS Glue criados pela pilha do AWS CloudFormation
Para executar seus rastreadores, conclua as etapas a seguir:
- No console do AWS Glue para Console do AWS Glue, escolha Crawlers em Catálogo de dados no painel de navegação.
- Localize e execute dois rastreadores
tpcdsdb-without-statsetpcdsdb-with-stats. Pode levar alguns minutos para ser concluído.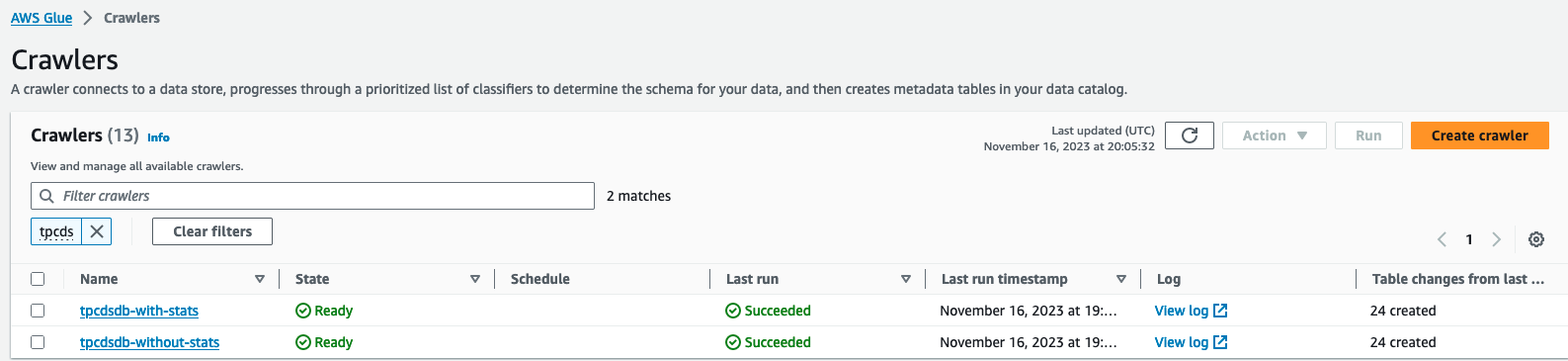
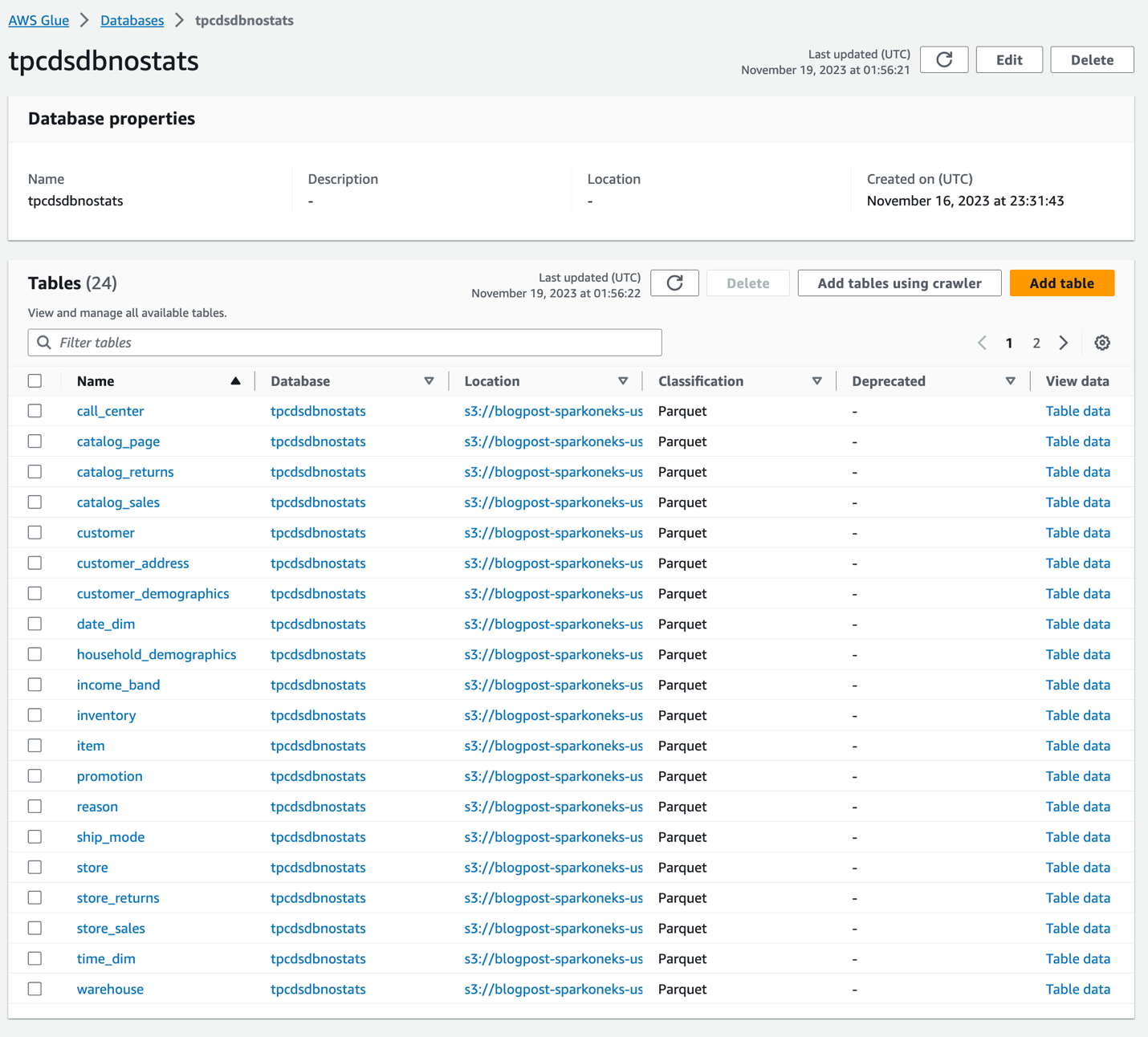
Assim que o rastreador for concluído com êxito, ele criará dois bancos de dados idênticos tpcdsdbnostats e tpcdsdbwithstats. As tabelas em tpcdsdbnostats não terão estatísticas e as usaremos como referência. Geramos estatísticas em tabelas em tpcdsdbwithstats. Verifique se você possui esses dois bancos de dados e tabelas subjacentes do console do AWS Glue. O banco de dados tpcdsdbnostats terá a aparência abaixo. No momento não há estatísticas geradas nessas tabelas.
Execute a consulta fornecida usando o Amazon Athena em tabelas sem estatísticas
Para executar sua consulta no Amazon Athena em tabelas sem estatísticas, conclua as seguintes etapas:
- Baixe as consultas do athena em Aqui.
- Na amazônia Console Athena, escolha a consulta fornecida, uma de cada vez, para tabelas no banco de dados
tpcdsdbnostats. - Execute a consulta e anote o Tempo de execução para cada consulta.

Execute a consulta fornecida usando o Amazon Redshift Spectrum em tabelas sem estatísticas
Para executar sua consulta no Amazon Redshift, execute as seguintes etapas:
- Baixe as consultas do Amazon Redshift em SUA PARTICIPAÇÃO FAZ A DIFERENÇA.
- No Editor de consultas Redshift v2, execute o Consulta Redshift para tabelas sem estatísticas seção da consulta baixada.
- Execute a consulta e anote a execução de cada consulta.
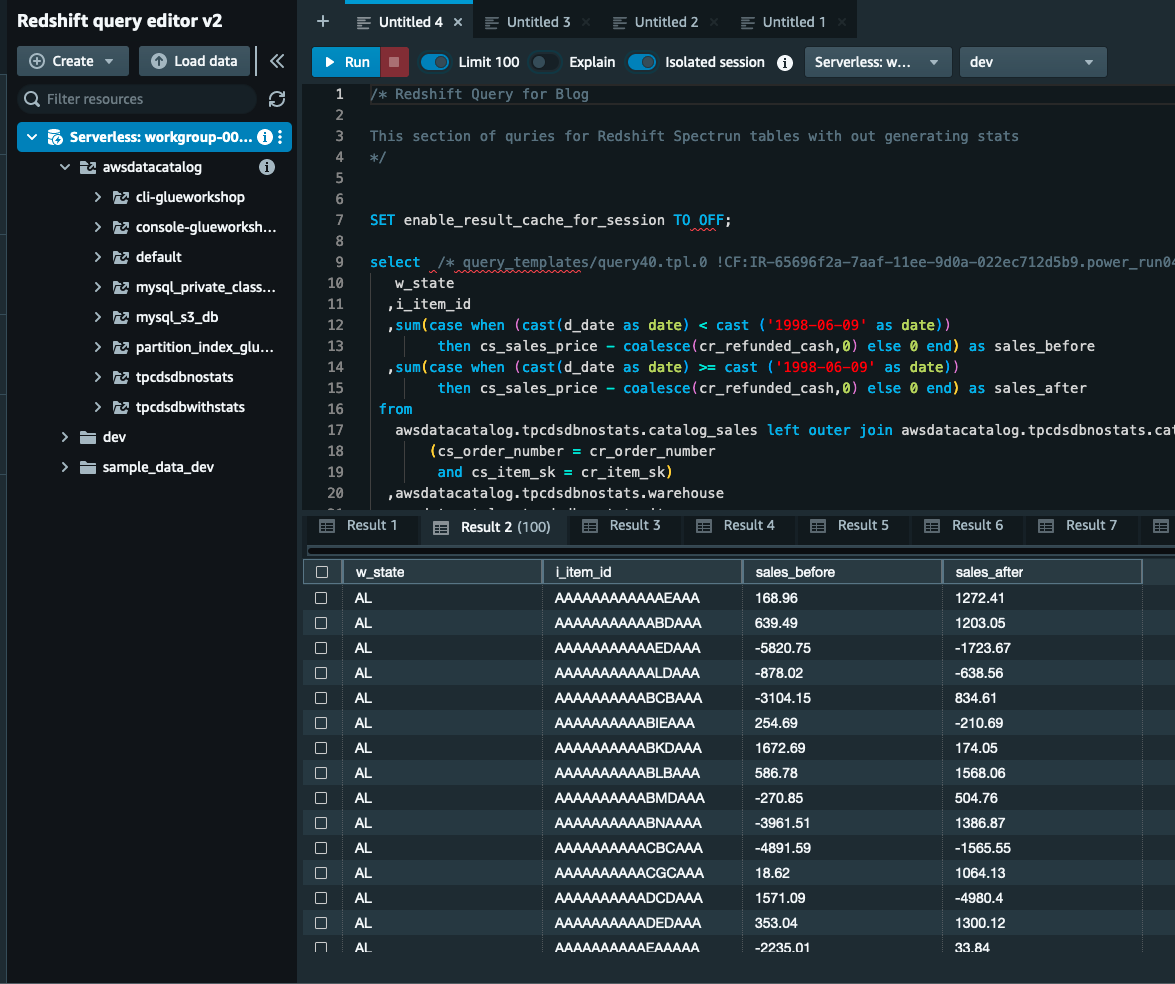
Gerar estatísticas sobre tabelas do AWS Glue Catalog
Para gerar estatísticas nas tabelas do AWS Glue Catalog, conclua as seguintes etapas:
- Navegue até a Console do AWS Glue e escolha os bancos de dados em Catálogo de Dados.
- Clique em
tpcdsdbwithstatsbanco de dados e listará todas as tabelas disponíveis. - Selecione qualquer uma dessas tabelas (por exemplo,
call_center). - Acesse Estatísticas de coluna – novo aba e escolha Gere estatísticas.
- Mantenha a opção padrão. Sob Escolha as colunas manter Tabela (todas as colunas) e abaixo Opções de amostragem de linha Guarda Todas as linhas, Sob IAM escolha de função Blog AWSGluestats e selecione Gere estatísticas.
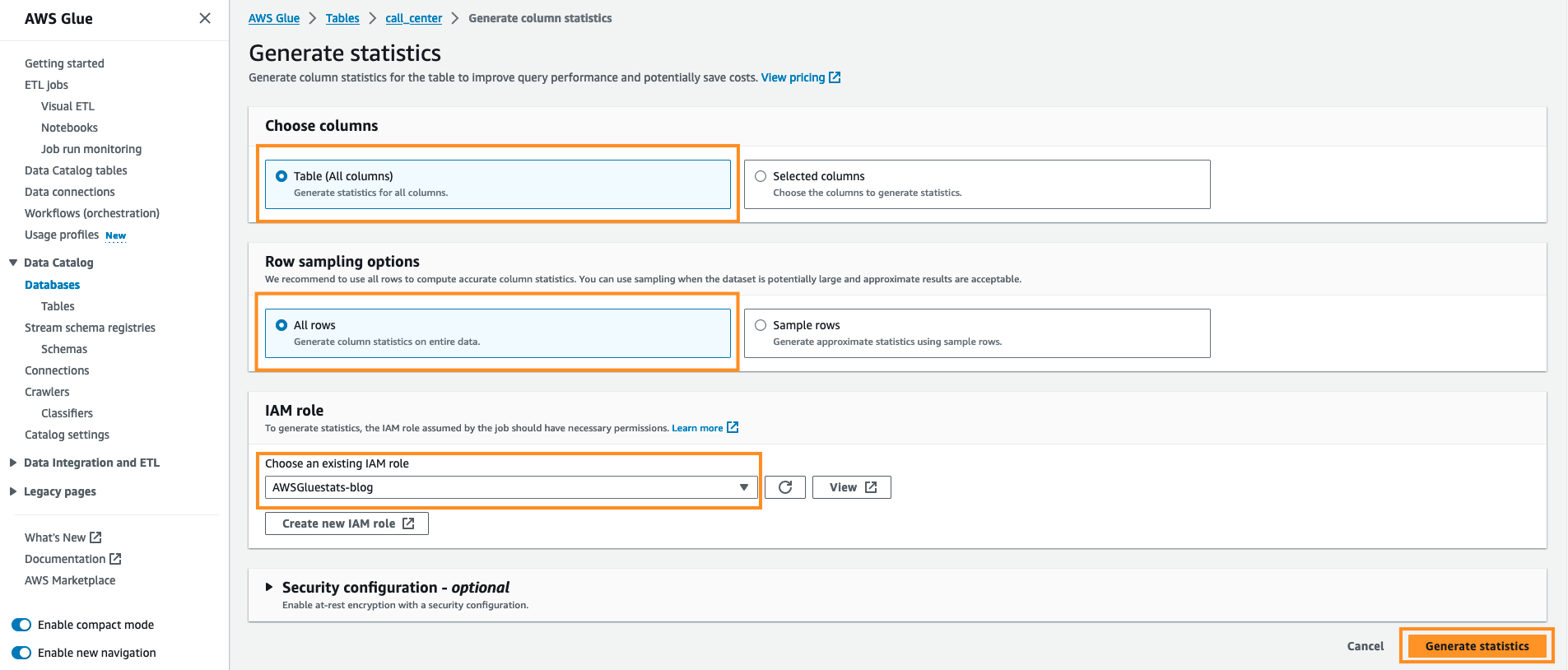
Você poderá ver o status da execução de geração de estatísticas conforme mostrado na ilustração a seguir:

Depois de gerar estatísticas nas tabelas do AWS Glue Catalog, você poderá ver estatísticas detalhadas das colunas dessa tabela:
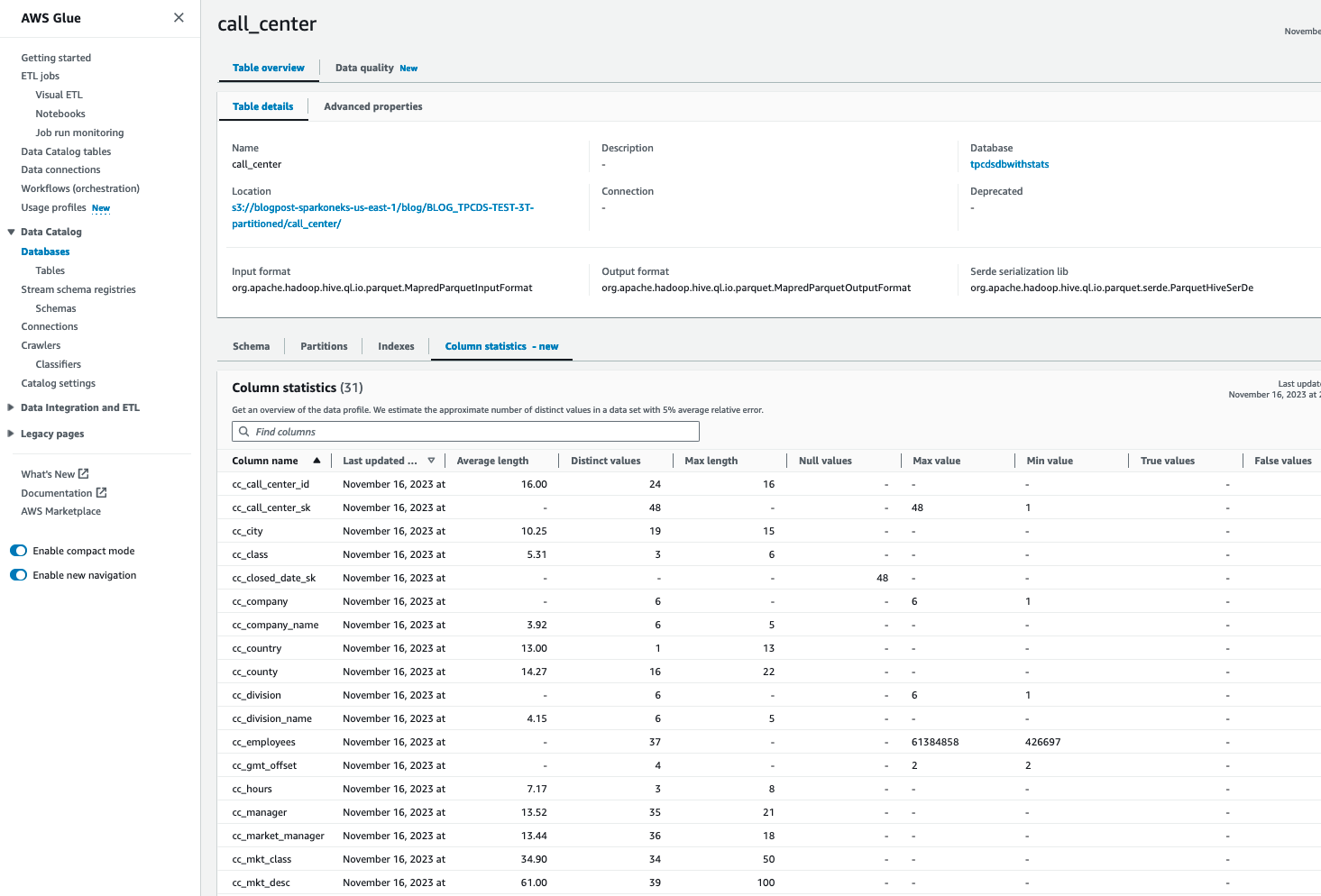
Reitere as etapas 2 a 5 para gerar estatísticas para todas as tabelas necessárias, como catalog_sales, catalog_returns, warehouse, item, date_dim, store_sales, customer, customer_address, web_sales, time_dim, ship_mode, web_site, web_returns. Alternativamente, você pode seguir o “Programar execuções de estatísticas do AWS Glue”perto do final deste blog para gerar estatísticas para todas as tabelas. Uma vez feito isso, avalie o desempenho de cada consulta.
Execute a consulta fornecida usando o Console do Athena em tabelas de estatísticas
- Na amazônia Consola Athena, execute o Consulta Athena para tabelas com estatísticas seção da consulta baixada.
- Execute e anote a execução de cada consulta.
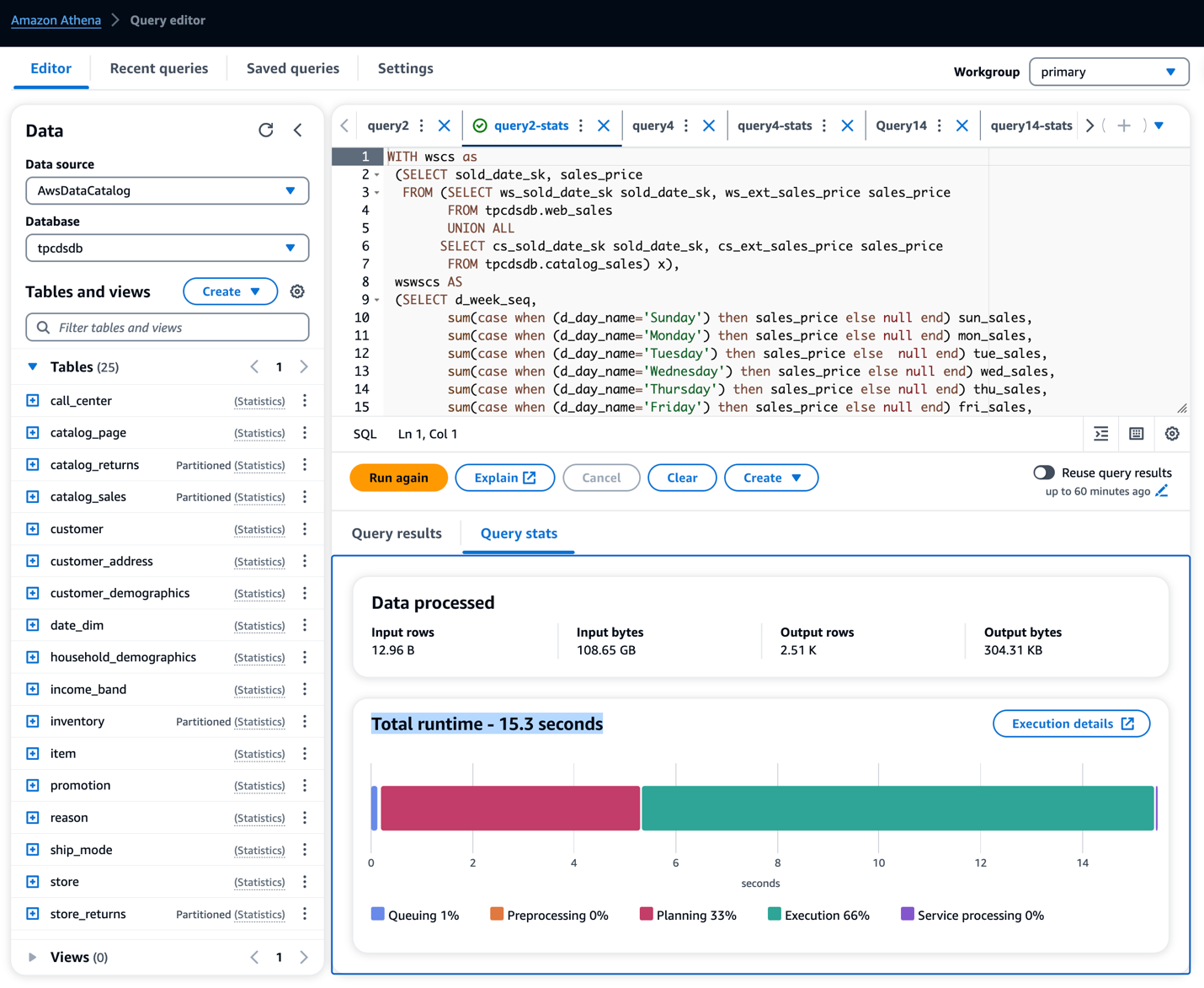
Em nosso exemplo de execução das consultas nas tabelas, observamos o tempo de execução da consulta conforme tabela abaixo. Vimos uma clara melhoria no desempenho das consultas, variando de 13 a 55%.
Melhoria no tempo de consulta do Athena
| Consultas TPC-DS 3T | sem estatísticas de cola (seg) | com estatísticas de cola (seg) | melhoria de desempenho (%) |
| Consulta 2 | 33.62 | 15.17 | 55% |
| Consulta 4 | 132.11 | 72.94 | 45% |
| Consulta 14 | 134.77 | 91.48 | 32% |
| Consulta 28 | 55.99 | 39.36 | 30% |
| Consulta 38 | 29.32 | 25.58 | 13% |
Execute a consulta fornecida usando o Amazon Redshift Spectrum em tabelas de estatísticas
- Na amazônia Editor de consultas Redshift v2, execute o Consulta Redshift para tabelas com estatísticas seção da consulta baixada.
- Execute a consulta e anote a execução de cada consulta.
Em nosso exemplo de execução das consultas nas tabelas, observamos o tempo de execução da consulta conforme tabela abaixo. Vimos uma clara melhoria no desempenho das consultas, variando de 13 a 89%.
Melhoria no tempo de consulta do Amazon Redshift Spectrum
| Consultas TPC-DS 3T | sem estatísticas de cola (seg) | com estatísticas de cola (seg) | melhoria de desempenho (%) |
| Consulta 40 | 124.156 | 13.12 | 89% |
| Consulta 60 | 29.52 | 16.97 | 42% |
| Consulta 66 | 18.914 | 16.39 | 13% |
| Consulta 95 | 308.806 | 200 | 35% |
| Consulta 99 | 20.064 | 16 | 20% |
Programar execuções de estatísticas do AWS Glue
Neste segmento da postagem, orientaremos você nas etapas de agendamento de execuções de estatísticas de colunas do AWS Glue usando AWS Lambda e os votos de Amazon Event Bridge Agendador. Para agilizar esse processo, uma função AWS Lambda e um agendador Amazon EventBridge foram criados como parte da implantação da pilha CloudFormation.
- Configuração da função AWS Lambda:
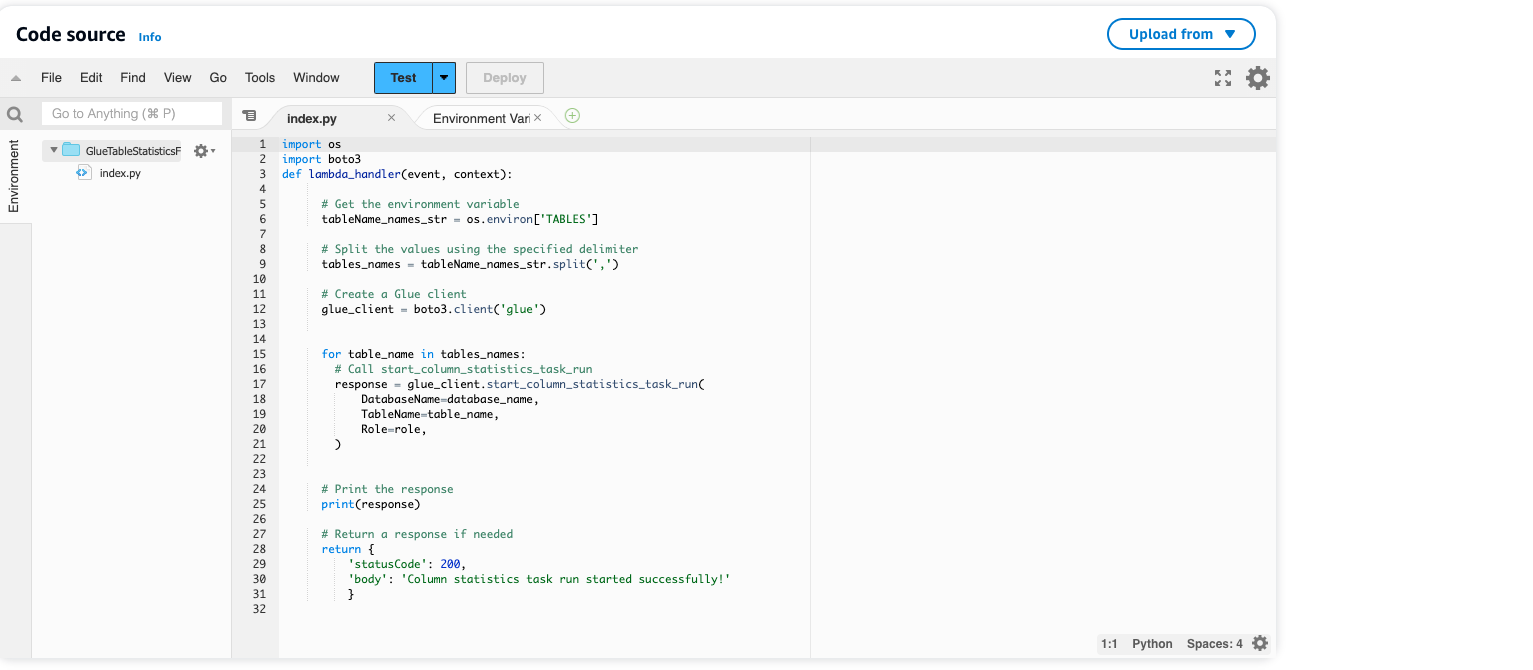
Para começar, utilizamos uma função AWS Lambda para acionar a execução do trabalho de estatísticas da coluna AWS Glue. A função AWS Lambda invoca o start_column_statistics_task_run API por meio da biblioteca boto3 (AWS SDK for Python). Isso estabelece a base para automatizar a atualização das estatísticas da coluna.
Vamos explorar a função AWS Lambda:
-
- Vou ao Console AWS Glue Lambda.
- Selecionar Funções e localize o
GlueTableStatisticsFunctionv1. - Para uma compreensão mais clara da função AWS Lambda, recomendamos revisar o código no Code seção e examinando as variáveis de ambiente em Configuração.
- Configuração do agendador do Amazon EventBridge
A próxima etapa envolve agendar a invocação da função AWS Lambda usando o Amazon Agendador EventBridge. O agendador é configurado para acionar a função AWS Lambda diariamente em um horário específico – neste caso, 08h. Isso garante que o trabalho de estatísticas da coluna do AWS Glue seja executado de maneira regular e previsível.
Agora, vamos explorar como você pode atualizar a programação:
Limpando
Para evitar cobranças indesejadas em sua conta da AWS, exclua os recursos da AWS:
- Faça login no console do AWS CloudFormation como administrador do AWS IAM usado para criar a pilha do AWS CloudFormation.
- Exclua a pilha do AWS CloudFormation que você criou.
Conclusão
Neste post, mostramos como você pode usar Catálogo de dados do AWS Glue para gerar estatísticas em nível de coluna para Cola AWS tabelas. Essas estatísticas agora estão integradas ao otimizador baseado em custos da Amazona atena e Amazon Espectro Redshift, resultando em melhor desempenho de consulta e possíveis economias de custos. Referir-se Docs para suporte ao Glue Catalog Statistics em vários serviços analíticos da AWS.
Se você tiver dúvidas ou sugestões, envie-as na seção de comentários.
Sobre os autores
 Sandeep Adwankar é gerente de produto técnico sênior da AWS. Com sede na área da baía da Califórnia, ele trabalha com clientes em todo o mundo para traduzir requisitos comerciais e técnicos em produtos que permitem aos clientes melhorar a forma como gerenciam, protegem e acessam dados.
Sandeep Adwankar é gerente de produto técnico sênior da AWS. Com sede na área da baía da Califórnia, ele trabalha com clientes em todo o mundo para traduzir requisitos comerciais e técnicos em produtos que permitem aos clientes melhorar a forma como gerenciam, protegem e acessam dados.
 Navnit Shukla atua como arquiteto de soluções especialista da AWS com foco em análises. Ele possui um grande entusiasmo em ajudar os clientes a descobrir informações valiosas a partir de seus dados. Através de sua experiência, ele constrói soluções inovadoras que capacitam as empresas a chegarem a escolhas informadas e baseadas em dados. Notavelmente, Navnit Shukla é o autor talentoso do livro intitulado Data Wrangling on AWS. Ele pode ser contatado através LinkedIn.
Navnit Shukla atua como arquiteto de soluções especialista da AWS com foco em análises. Ele possui um grande entusiasmo em ajudar os clientes a descobrir informações valiosas a partir de seus dados. Através de sua experiência, ele constrói soluções inovadoras que capacitam as empresas a chegarem a escolhas informadas e baseadas em dados. Notavelmente, Navnit Shukla é o autor talentoso do livro intitulado Data Wrangling on AWS. Ele pode ser contatado através LinkedIn.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/enhance-query-performance-using-aws-glue-data-catalog-column-level-statistics/
- :é
- :onde
- $UP
- 08
- 1
- 10
- 100
- 13
- 264
- 30
- a
- Capaz
- Acesso
- gerenciamento de acesso
- acessível
- realizado
- Conta
- Contas
- preciso
- reconhecer
- em
- Depois de
- Todos os Produtos
- permite
- Amazon
- Amazona atena
- Amazon Web Services
- quantidades
- an
- Análises
- analítica
- e
- qualquer
- api
- apropriado
- arquitetura
- SOMOS
- ÁREA
- por aí
- AS
- aspecto
- avaliar
- ajudando
- At
- autor
- automaticamente
- automatizando
- disponível
- evitar
- AWS
- Formação da Nuvem AWS
- Cola AWS
- AWS Lambda
- baseado
- base
- Bay
- BE
- antes
- começar
- abaixo
- Blog
- livro
- aumenta
- PONTE
- negócio
- negócios
- by
- Califórnia
- CAN
- capacidades
- capacidade
- casas
- catálogo
- centralizada
- certo
- desafiante
- Alterações
- acusações
- escolhas
- Escolha
- remover filtragem
- mais claro
- clientes
- Na nuvem
- código
- Coluna
- colunas
- comentários
- comparar
- completar
- Completa
- integrações
- compreensivo
- configurado
- consiste
- cônsul
- consumidor
- Consumidores
- Correspondente
- Custo
- economia de custos
- custos
- rastreador
- crio
- criado
- Criar
- Clientes
- personalizar
- diariamente
- dados,
- lago data
- orientado por dados
- banco de dados
- bases de dados
- conjuntos de dados
- Padrão
- demonstrar
- departamentos
- implantar
- implantado
- desenvolvimento
- designado
- projetado
- detalhado
- detalhes
- diferente
- descobrindo
- distinto
- feito
- down
- duração
- durante
- e
- cada
- editor
- eficácia
- eficiente
- ou
- autorizar
- permitir
- encorajar
- final
- end-to-end
- aumentar
- aprimorada
- garante
- entusiasmo
- Meio Ambiente
- especialmente
- Éter (ETH)
- avaliar
- Evento
- Examinando
- exemplo
- executar
- execução
- vasta experiência
- experiência
- explorar
- mais rápido
- poucos
- Arquivos
- final
- Foco
- seguir
- seguinte
- Escolha
- da
- função
- gerar
- gerado
- gera
- gerando
- geração
- globo
- governo
- base
- guia
- Ter
- he
- ajuda
- Alta
- sua
- hospedado
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- IAM
- idêntico
- Identidade
- gerenciamento de identidade e acesso
- if
- ilustra
- Impacto
- executar
- importante
- melhorar
- melhorado
- melhoria
- melhorias
- melhora
- in
- incluir
- inclui
- informado
- inovadores
- insights
- integrado
- pretender
- para dentro
- invoca
- envolve
- IT
- Trabalho
- Empregos
- juntar
- Junta
- jpg
- json
- Guarda
- lago
- lagos
- grande
- lançamento
- de lançamento
- Leads
- aprendido
- Nível
- Biblioteca
- como
- Lista
- olhar
- parece
- Baixo
- moldadas
- fazer
- Fazendo
- gerencia
- de grupos
- Gerente
- max
- Posso..
- metadados
- poder
- minutos
- minutos
- mais
- mais eficiente
- a maioria
- múltiplo
- Navegação
- Perto
- necessário
- você merece...
- Cria
- Novo
- Próximo
- não
- notavelmente
- nota
- agora
- número
- observado
- of
- on
- uma vez
- ONE
- Operações
- otimização
- Otimize
- Opção
- or
- ordem
- organizações
- A Nossa
- Fora
- próprio
- página
- pão
- parte
- para
- realizar
- atuação
- permissões
- planejamento
- planos
- platão
- Inteligência de Dados Platão
- PlatãoData
- por favor
- pm
- políticas
- possui
- Publique
- potencial
- potencialmente
- Previsível
- predição
- Previsões
- anterior
- privado
- processo
- Produtores
- Produto
- gerente de produto
- Produtos
- fornecido
- fornecendo
- público
- Python
- consultas
- Frequentes
- Links
- variando
- Cru
- alcançado
- Leia
- recomendar
- Reduzido
- referir
- referência
- região
- regular
- requerimento
- Requisitos
- Recursos
- resultar
- resultando
- rever
- revendo
- Tipo
- Rota
- LINHA
- Execute
- corrida
- é executado
- Poupança
- serra
- cronograma
- agendamento
- Sdk
- sem problemas
- SEC
- Seção
- seguro
- Vejo
- segmento
- selecionar
- senior
- Serverless
- serve
- serviço
- Serviços
- Conjuntos
- instalação
- Partilhar
- rede de apoio social
- mostrou
- mostrando
- simples
- solução
- Soluções
- alguns
- especialista
- específico
- Espectro
- SQL
- pilha
- Etapa
- estatística
- stats
- Status
- Passo
- Passos
- armazenamento
- loja
- armazenadas
- simplificar
- mais forte,
- enviar
- sub-rede
- sub-redes
- entraram com sucesso
- tal
- terno
- ajuda
- mesa
- Tire
- falando
- equipes
- Dados Técnicos:
- modelo
- que
- A
- deles
- Eles
- Lá.
- assim
- Este
- deles
- isto
- aqueles
- Através da
- tempo
- intitulado
- para
- traduzir
- desencadear
- tentar
- dois
- para
- subjacente
- compreensão
- não desejado
- Atualizar
- Atualizada
- usar
- usava
- usuários
- utilização
- utilizar
- Utilizando
- Valioso
- Valores
- vário
- Grande
- verificar
- Ver
- Virtual
- we
- web
- serviços web
- foram
- quando
- qual
- precisarão
- de
- dentro
- sem
- Atividades:
- de gestão de documentos
- Workgroup
- trabalho
- seria
- XML
- yaml
- Você
- investimentos
- zefirnet