Recentemente, percebemos que há algum tempo não trazíamos nenhuma cheatsheet de ciência de dados. E não é por falta de disponibilidade; as cheatsheets da ciência de dados estão por toda parte, desde o introdutório ao avançado, cobrindo tópicos de algoritmos a estatísticas, dicas para entrevistas e muito mais.
Mas o que constitui uma boa folha de dicas? O que torna uma folha de dicas digna de ser destacada como particularmente boa? É difícil apontar o dedo justamente o que constitui uma boa folha de dicas, mas obviamente uma que transmite informações essenciais de forma concisa - seja essa informação de natureza específica ou geral - é definitivamente um bom começo. E é isso que torna os nossos candidatos hoje dignos de nota. Portanto, leia quatro cheatsheets complementares selecionados para ajudá-lo em seu aprendizado ou revisão de ciência de dados.
O primeiro é Folha de dicas de ciência de dados 2.0 de Aaron Wang, uma compilação de quatro páginas de abstrações estatísticas, algoritmos fundamentais de aprendizado de máquina e tópicos e conceitos de aprendizado profundo. Não pretende ser exaustivo, mas sim uma referência rápida para situações como preparação para entrevistas e revisões de exames, e qualquer outra coisa que exija um nível semelhante de profundidade de revisão. O autor observa que, embora aqueles com um conhecimento básico de estatística e álgebra linear considerem este recurso mais benéfico, os iniciantes também devem ser capazes de obter informações úteis de seu conteúdo.

Captura de tela de Aaron Wang Folha de dicas de ciência de dados 2.0
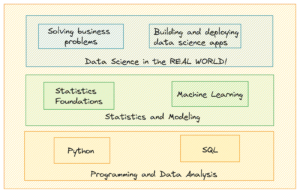
Nossa próxima oferta de cheatsheet hoje é aquela em que o recurso de Aaron Wang se baseia, Folha de referências de ciência de dados de Maverick Lin (A referência de Wang ao seu próprio como 2.0 é uma referência direta ao “original” de Lin). Podemos pensar na folha de dicas de Lin como mais aprofundada do que a de Wang (embora a decisão de Wang de torná-la menos aprofundada pareça intencional e uma alternativa útil), cobrindo conceitos mais fundamentais da ciência de dados, como limpeza de dados, a ideia de modelagem, fazendo “ big data” com Hadoop, SQL e até mesmo o básico de Python.
É evidente que isto irá agradar àqueles que estão mais firmemente no campo dos “iniciantes” e faz um bom trabalho ao aguçar o apetite e conscientizar os leitores sobre o amplo campo da ciência de dados e muitos dos diversos conceitos que ela abrange. Este é definitivamente outro recurso sólido, especialmente se o leitor for iniciante na ciência de dados.

Captura de tela de Maverick Lin Folha de dicas de ciência de dados
À medida que recuamos no tempo - em busca de inspiração para o cheatsheet de Lin - nos deparamos com Folha de dados de probabilidade 2.0 de William Chen. A folha de dicas de Chen atraiu muita atenção e elogios ao longo dos anos e, portanto, você pode ter se deparado com ela em algum momento. Claramente com um foco diferente (devido ao seu nome), o cheatsheet de Chen é um curso intensivo ou uma revisão profunda de conceitos de probabilidade, incluindo uma variedade de distribuições, covariância e transformações, expectativa condicional, cadeias de Markov, várias fórmulas de importância e muito mais.
Em 10 páginas, você deverá ser capaz de imaginar a amplitude dos tópicos de probabilidade abordados aqui. Mas não deixe que isso o detenha; A capacidade de Chen de resumir conceitos aos seus pontos essenciais e explicá-los em inglês simples, sem sacrificar o essencial, é digna de nota. Também é rico em visualizações explicativas, algo bastante útil quando o espaço é limitado e a vontade de ser conciso é forte.
A compilação de Chen não é apenas de qualidade e digna do seu tempo, como iniciante ou alguém interessado em uma revisão completa, eu trabalharia na ordem inversa de como esses recursos foram apresentados - da folha de dicas de Chen, à de Lin e, finalmente, à de Wang, construindo sobre conceitos conforme você avança.
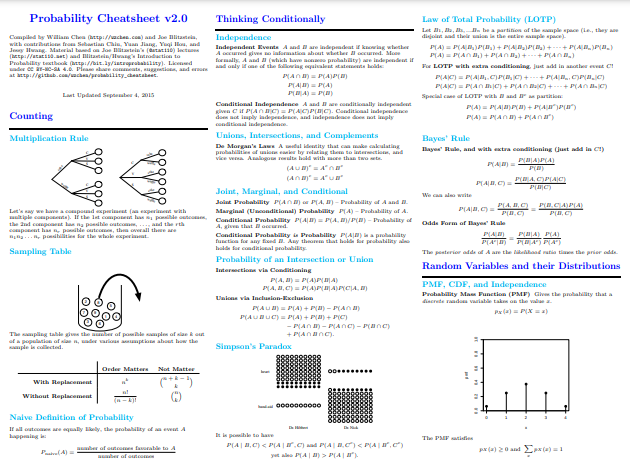
Captura de tela de William Chen Folha de dicas de probabilidade 2.0
Um recurso final que estou incluindo aqui, embora não seja tecnicamente uma folha de dicas, é Mordidas de aprendizado de máquina de Rishabh Anand. Apresentando-se como “[um] guia de entrevista sobre conceitos, melhores práticas, definições e teoria comuns de aprendizado de máquina”, Anand compilou uma ampla coleção de “pedaços” de conhecimento, cuja utilidade definitivamente transcende a preparação da entrevista originalmente pretendida. Os tópicos abordados incluem:
- Métricas de pontuação de modelo
- Compartilhamento de parâmetros
- Validação cruzada k-Fold
- Tipos de dados Python
- Melhorando o desempenho do modelo
- Modelos de visão computacional
- Atenção e suas variantes
- Lidando com desequilíbrio de classe
- Glossário de Visão Computacional
- Retropropagação baunilha
- Regularização
- Referências

Captura de tela de Mordidas de aprendizado de máquina
Embora os “conceitos, melhores práticas, definições e teoria” do aprendizado de máquina sejam abordados, conforme prometido na descrição do próprio recurso, essas “mordidas” são definitivamente voltadas para a prática, o que torna o site complementar a grande parte do material abordado em as três cheatsheets mencionadas anteriormente. Se eu quisesse cobrir todo o material em todos os quatro recursos deste post, certamente examinaria isso depois dos outros três.
Portanto, você tem quatro cheatsheets (ou três cheatsheets e um recurso adjacente à cheatsheet) para usar em seu aprendizado ou revisão. Espero que algo aqui seja útil para você e convido qualquer pessoa a compartilhar as cheatsheets que consideraram úteis nos comentários abaixo.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2021/03/more-data-science-cheatsheets.html?utm_source=rss&utm_medium=rss&utm_campaign=more-data-science-cheatsheets
- 10
- a
- Aaron
- habilidade
- Capaz
- em
- avançado
- Depois de
- algoritmos
- Todos os Produtos
- alternativa
- e
- Outro
- qualquer um
- apelar
- por WhatsApp.
- autor
- disponibilidade
- em caminho duplo
- baseado
- basic
- fundamentos básicos
- Iniciantes
- ser
- abaixo
- beneficiar
- MELHOR
- melhores práticas
- Pós
- Grande
- Big Data
- morada
- largura
- amplo
- Trazido
- Prédio
- Acampamento
- candidatos
- certamente
- correntes
- chen
- classe
- Limpeza
- claramente
- coleção
- como
- comentários
- comum
- complementar
- conceitos
- conteúdo
- curso
- cobrir
- coberto
- cobertura
- Crash
- Atravessar
- comissariada
- dados,
- ciência de dados
- decisão
- profundo
- mergulho profundo
- deep learning
- definitivamente
- profundidade
- descrição
- diferente
- difícil
- diretamente
- distribuições
- fazer
- down
- engloba
- Inglês
- especialmente
- essencial
- fundamentos
- Éter (ETH)
- Mesmo
- exame
- expectativa
- Explicação
- campo
- Figura
- final
- Finalmente
- Encontre
- firmemente
- Foco
- encontrado
- da
- cheio
- fundamental
- mais distante
- engrenado
- Geral
- dado
- Go
- Bom estado, com sinais de uso
- bom trabalho
- guia
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Esperançosamente
- Como funciona o dobrador de carta de canal
- HTTPS
- idéia
- desequilíbrio
- importância
- in
- em profundidade
- incluir
- Incluindo
- INFORMAÇÕES
- Inspiração
- em vez disso
- Intencional
- interessado
- Entrevista
- introdutório
- convidar
- IT
- se
- Trabalho
- Conhecimento
- Falta
- aprendizagem
- Nível
- Limitado
- olhar
- procurando
- máquina
- aprendizado de máquina
- fazer
- FAZ
- Fazendo
- muitos
- material
- dissidente
- mencionado
- Métrica
- modelo
- modelos
- mais
- a maioria
- mover
- nome
- Natureza
- Próximo
- Notas
- notável
- Noção
- oferecendo treinamento para distância
- ONE
- ordem
- original
- originalmente
- Outros
- próprio
- particularmente
- atuação
- Avião
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- pontos
- Publique
- Prática
- práticas
- apresentado
- anteriormente
- prometido
- colocar
- Python
- qualidade
- Links
- variando
- Leia
- Leitor
- leitores
- realizado
- recentemente
- recurso
- Recursos
- reverso
- rever
- Opinões
- Rico
- sacrificando
- Ciência
- marcar
- busca
- parece
- Partilhar
- compartilhando
- rede de apoio social
- semelhante
- local
- situações
- So
- sólido
- alguns
- Alguém
- algo
- Espaço
- específico
- começo
- estatístico
- estatística
- mais forte,
- tal
- A
- O Básico
- deles
- três
- tempo
- dicas
- para
- hoje
- topo
- Temas
- para
- transformações
- tipos
- compreensão
- usar
- validação
- variedade
- vário
- visão
- O Quê
- se
- qual
- enquanto
- QUEM
- Largo
- precisarão
- dentro
- Atividades:
- seria
- anos
- investimentos
- zefirnet