Hoje temos o prazer de anunciar que o Guarda Lhama modelo agora está disponível para clientes que usam JumpStart do Amazon SageMaker. O Llama Guard fornece proteções de entrada e saída na implantação de modelo de linguagem grande (LLM). É um dos componentes do Purple Llama, a iniciativa da Meta que apresenta ferramentas e avaliações abertas de confiança e segurança para ajudar os desenvolvedores a construir de forma responsável com modelos de IA. Purple Llama reúne ferramentas e avaliações para ajudar a comunidade a construir de forma responsável com modelos generativos de IA. A versão inicial inclui foco em segurança cibernética e salvaguardas de entrada e saída do LLM. Os componentes do projeto Purple Llama, incluindo o modelo Llama Guard, são licenciados de forma permissiva, permitindo tanto a pesquisa quanto o uso comercial.
Agora você pode usar o modelo Llama Guard no SageMaker JumpStart. SageMaker JumpStart é o centro de aprendizado de máquina (ML) de Amazon Sage Maker que fornece acesso a modelos de base, além de algoritmos integrados e modelos de solução de ponta a ponta para ajudá-lo a começar a usar o ML rapidamente.
Nesta postagem, explicamos como implantar o modelo Llama Guard e construir soluções de IA generativas e responsáveis.
Modelo Lhama Guard
Llama Guard é um novo modelo da Meta que fornece proteções de entrada e saída para implantações LLM. Llama Guard é um modelo disponível abertamente que funciona de forma competitiva em benchmarks abertos comuns e fornece aos desenvolvedores um modelo pré-treinado para ajudar na defesa contra a geração de resultados potencialmente arriscados. Este modelo foi treinado em uma combinação de conjuntos de dados disponíveis publicamente para permitir a detecção de tipos comuns de conteúdo potencialmente arriscado ou violador que pode ser relevante para vários casos de uso de desenvolvedores. Em última análise, a visão do modelo é permitir que os desenvolvedores personalizem este modelo para apoiar casos de uso relevantes e facilitar a adoção de melhores práticas e a melhoria do ecossistema aberto.
O Llama Guard pode ser usado como uma ferramenta complementar para desenvolvedores integrarem suas próprias estratégias de mitigação, como chatbots, moderação de conteúdo, atendimento ao cliente, monitoramento de mídia social e educação. Ao passar o conteúdo gerado pelo usuário pelo Llama Guard antes de publicá-lo ou responder a ele, os desenvolvedores podem sinalizar linguagem insegura ou inadequada e tomar medidas para manter um ambiente seguro e respeitoso.
Vamos explorar como podemos usar o modelo Llama Guard no SageMaker JumpStart.
Modelos de fundação no SageMaker
O SageMaker JumpStart fornece acesso a uma variedade de modelos de hubs de modelos populares, incluindo Hugging Face, PyTorch Hub e TensorFlow Hub, que você pode usar em seu fluxo de trabalho de desenvolvimento de ML no SageMaker. Avanços recentes em ML deram origem a uma nova classe de modelos conhecida como modelos de fundação, que normalmente são treinados em bilhões de parâmetros e são adaptáveis a uma ampla categoria de casos de uso, como resumo de texto, geração de arte digital e tradução de idiomas. Como o treinamento desses modelos é caro, os clientes desejam usar modelos básicos pré-treinados existentes e ajustá-los conforme necessário, em vez de treinar eles próprios esses modelos. O SageMaker fornece uma lista selecionada de modelos que você pode escolher no console do SageMaker.
Agora você pode encontrar modelos de base de diferentes fornecedores de modelos no SageMaker JumpStart, permitindo que você comece a usar modelos de base rapidamente. Você pode encontrar modelos básicos baseados em diferentes tarefas ou provedores de modelos e revisar facilmente as características do modelo e os termos de uso. Você também pode experimentar esses modelos usando um widget de IU de teste. Quando quiser usar um modelo básico em escala, você pode fazer isso facilmente, sem sair do SageMaker, usando notebooks pré-construídos de fornecedores de modelos. Como os modelos são hospedados e implantados na AWS, você pode ter certeza de que seus dados, sejam usados para avaliação ou para uso do modelo em escala, nunca serão compartilhados com terceiros.
Vamos explorar como podemos usar o modelo Llama Guard no SageMaker JumpStart.
Descubra o modelo Llama Guard no SageMaker JumpStart
Você pode acessar os modelos básicos do Code Llama por meio do SageMaker JumpStart na IU do SageMaker Studio e do SageMaker Python SDK. Nesta seção, veremos como descobrir os modelos em Estúdio Amazon SageMaker.
SageMaker Studio é um ambiente de desenvolvimento integrado (IDE) que fornece uma única interface visual baseada na web onde você pode acessar ferramentas específicas para executar todas as etapas de desenvolvimento de ML, desde a preparação de dados até a construção, treinamento e implantação de seus modelos de ML. Para obter mais detalhes sobre como começar e configurar o SageMaker Studio, consulte Estúdio Amazon SageMaker.
No SageMaker Studio, você pode acessar o SageMaker JumpStart, que contém modelos pré-treinados, notebooks e soluções pré-construídas, em Soluções pré-construídas e automatizadas.
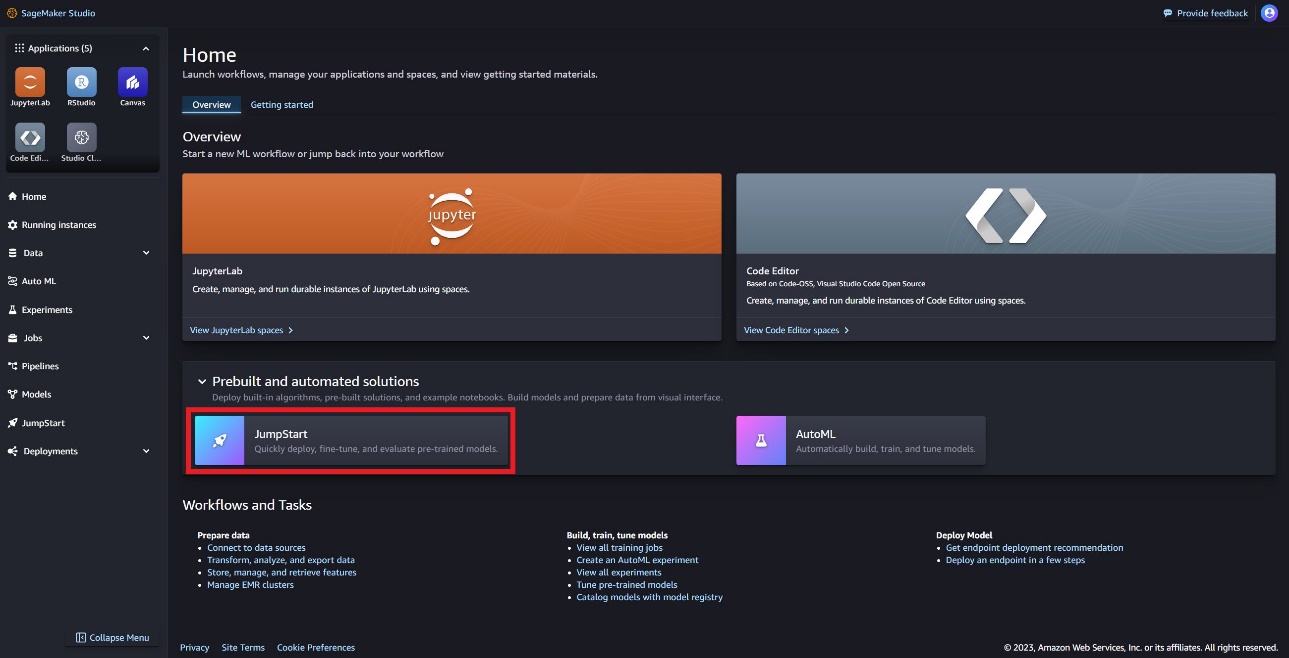
Na página inicial do SageMaker JumpStart, você pode encontrar o modelo Llama Guard escolhendo o hub Meta ou pesquisando por Llama Guard.

Você pode selecionar entre uma variedade de variantes de modelo Llama, incluindo Llama Guard, Llama-2 e Code Llama.

Você pode escolher o cartão do modelo para visualizar detalhes sobre o modelo, como licença, dados usados para treinar e como usar. Você também encontrará um Implantação opção, que o levará a uma página de destino onde você pode testar a inferência com um exemplo de carga útil.

Implante o modelo com o SageMaker Python SDK
Você pode encontrar o código que mostra a implantação do Llama Guard no Amazon JumpStart e um exemplo de como usar o modelo implantado em isto Caderno GitHub.
No código a seguir, especificamos o ID do modelo do hub do modelo SageMaker e a versão do modelo a ser usada ao implantar o Llama Guard:
Agora você pode implantar o modelo usando o SageMaker JumpStart. O código a seguir usa a instância padrão ml.g5.2xlarge para o endpoint de inferência. Você pode implantar o modelo em outros tipos de instância passando instance_type no JumpStartModel aula. A implantação pode levar alguns minutos. Para uma implantação bem-sucedida, você deve alterar manualmente o accept_eula argumento no método de implantação do modelo para True.
Este modelo é implantado usando o contêiner de aprendizagem profunda Text Generation Inference (TGI). As solicitações de inferência suportam muitos parâmetros, incluindo os seguintes:
- comprimento máximo – O modelo gera texto até que o comprimento de saída (que inclui o comprimento do contexto de entrada) atinja
max_length. Se especificado, deve ser um número inteiro positivo. - max_new_tokens – O modelo gera texto até que o comprimento de saída (excluindo o comprimento do contexto de entrada) atinja
max_new_tokens. Se especificado, deve ser um número inteiro positivo. - num_beams – Indica o número de feixes utilizados na busca gananciosa. Se especificado, deve ser um número inteiro maior ou igual a
num_return_sequences. - no_repeat_ngram_size – O modelo garante que uma sequência de palavras de
no_repeat_ngram_sizenão é repetido na sequência de saída. Se especificado, deve ser um número inteiro positivo maior que 1. - temperatura – Este parâmetro controla a aleatoriedade na saída. Um maior
temperatureresulta em uma sequência de saída com palavras de baixa probabilidade e um menortemperatureresulta em uma sequência de saída com palavras de alta probabilidade. Setemperatureé 0, resulta em decodificação gananciosa. Se especificado, deve ser um ponto flutuante positivo. - Early_stopping - Se
True, a geração do texto termina quando todas as hipóteses de feixe atingem o final do token da frase. Se especificado, deve ser booleano. - do_sample - Se
True, o modelo amostra a próxima palavra de acordo com a probabilidade. Se especificado, deve ser booleano. - topo_k – Em cada etapa da geração de texto, o modelo faz amostras apenas do
top_kpalavras mais prováveis. Se especificado, deve ser um número inteiro positivo. - topo_p – Em cada etapa da geração de texto, o modelo amostra o menor conjunto possível de palavras com probabilidade cumulativa
top_p. Se especificado, deve ser um float entre 0–1. - retorno_texto_completo - Se
True, o texto de entrada fará parte do texto gerado de saída. Se especificado, deve ser booleano. o valor padrão éFalse. - Pare – Se especificado, deve ser uma lista de strings. A geração de texto é interrompida se qualquer uma das strings especificadas for gerada.
Invocar um endpoint do SageMaker
Você pode recuperar programaticamente exemplos de cargas do JumpStartModel objeto. Isso o ajudará a começar rapidamente, observando os prompts de instruções pré-formatados que o Llama Guard pode ingerir. Veja o seguinte código:
Depois de executar o exemplo anterior, você poderá ver como sua entrada e saída seriam formatadas pelo Llama Guard:
Semelhante ao Llama-2, o Llama Guard usa fichas especiais para indicar instruções de segurança ao modelo. Em geral, o payload deve seguir o formato abaixo:
Prompt do usuário mostrado como {user_prompt} acima, pode incluir ainda seções para definições de categorias de conteúdo e conversas, que se parecem com o seguinte:
Na próxima seção, discutiremos os valores padrão recomendados para a tarefa, categoria de conteúdo e definições de instrução. A conversa deve alternar entre User e Agent texto da seguinte forma:
Modere uma conversa com Llama-2 Chat
Agora você pode implantar um endpoint do modelo Llama-2 7B Chat para bate-papo conversacional e, em seguida, usar o Llama Guard para moderar a entrada e a saída de texto proveniente do Llama-2 7B Chat.
Mostramos o exemplo da entrada e saída do modelo de bate-papo Llama-2 7B moderada por meio do Llama Guard, mas você pode usar o Llama Guard para moderação com qualquer LLM de sua escolha.
Implante o modelo com o seguinte código:
Agora você pode definir o modelo de tarefa do Llama Guard. As categorias de conteúdo inseguro podem ser ajustadas conforme desejado para seu caso de uso específico. Você pode definir em texto simples o significado de cada categoria de conteúdo, incluindo qual conteúdo deve ser sinalizado como inseguro e qual conteúdo deve ser permitido como seguro. Veja o seguinte código:
A seguir, definimos funções auxiliares format_chat_messages e format_guard_messages para formatar o prompt para o modelo de chat e para o modelo Llama Guard que exigia tokens especiais:
Você pode então usar essas funções auxiliares em um prompt de entrada de mensagem de exemplo para executar a entrada de exemplo por meio do Llama Guard para determinar se o conteúdo da mensagem é seguro:
A saída a seguir indica que a mensagem é segura. Você pode perceber que a mensagem inclui palavras que podem estar associadas à violência, mas, neste caso, o Llama Guard é capaz de compreender o contexto em relação às instruções e definições de categorias inseguras que fornecemos anteriormente e determinar que é uma mensagem segura e não relacionado à violência.
Agora que você confirmou que o texto de entrada foi determinado como seguro em relação às categorias de conteúdo do Llama Guard, você pode passar essa carga útil para o modelo Llama-2 7B implantado para gerar texto:
A seguir está a resposta do modelo:
Por fim, você pode querer confirmar se o texto de resposta do modelo contém conteúdo seguro. Aqui, você estende a resposta de saída do LLM às mensagens de entrada e executa toda essa conversa por meio do Llama Guard para garantir que a conversa seja segura para seu aplicativo:
Você poderá ver a seguinte saída, indicando que a resposta do modelo de chat é segura:
limpar
Depois de testar os endpoints, exclua os endpoints de inferência do SageMaker e o modelo para evitar cobranças.
Conclusão
Nesta postagem, mostramos como você pode moderar entradas e saídas usando Llama Guard e colocar proteções para entradas e saídas de LLMs no SageMaker JumpStart.
À medida que a IA continua a avançar, é fundamental priorizar o desenvolvimento e a implantação responsáveis. Ferramentas como CyberSecEval e Llama Guard da Purple Llama são fundamentais para promover a inovação segura, oferecendo identificação precoce de riscos e orientação de mitigação para modelos de linguagem. Estes devem estar enraizados no processo de concepção da IA para aproveitar todo o potencial dos LLMs de forma ética desde o primeiro dia.
Experimente hoje mesmo o Llama Guard e outros modelos de base no SageMaker JumpStart e deixe-nos saber sua opinião!
Esta orientação é apenas para fins informativos. Você ainda deve realizar sua própria avaliação independente e tomar medidas para garantir o cumprimento de suas próprias práticas e padrões específicos de controle de qualidade e das regras, leis, regulamentos, licenças e termos de uso locais que se aplicam a você, seu conteúdo, e o modelo de terceiros mencionado nesta orientação. A AWS não tem controle ou autoridade sobre o modelo de terceiros mencionado nesta orientação e não faz nenhuma representação ou garantia de que o modelo de terceiros seja seguro, livre de vírus, operacional ou compatível com seu ambiente e padrões de produção. A AWS não faz nenhuma representação ou garantia de que qualquer informação nesta orientação resultará em um resultado ou resultado específico.
Sobre os autores
 Dr. é um Cientista Aplicado com o Algoritmos integrados do Amazon SageMaker equipe. Seus interesses de pesquisa incluem algoritmos de aprendizado de máquina escaláveis, visão computacional, séries temporais, processos não paramétricos bayesianos e processos gaussianos. Seu PhD é pela Duke University e ele publicou artigos em NeurIPS, Cell e Neuron.
Dr. é um Cientista Aplicado com o Algoritmos integrados do Amazon SageMaker equipe. Seus interesses de pesquisa incluem algoritmos de aprendizado de máquina escaláveis, visão computacional, séries temporais, processos não paramétricos bayesianos e processos gaussianos. Seu PhD é pela Duke University e ele publicou artigos em NeurIPS, Cell e Neuron.
 Evan Kravitz é engenheiro de software na Amazon Web Services e trabalha no SageMaker JumpStart. Ele está interessado na confluência do aprendizado de máquina com a computação em nuvem. Evan recebeu seu diploma de graduação pela Cornell University e mestrado pela University of California, Berkeley. Em 2021, ele apresentou um artigo sobre redes neurais adversárias na conferência ICLR. Em seu tempo livre, Evan gosta de cozinhar, viajar e correr pela cidade de Nova York.
Evan Kravitz é engenheiro de software na Amazon Web Services e trabalha no SageMaker JumpStart. Ele está interessado na confluência do aprendizado de máquina com a computação em nuvem. Evan recebeu seu diploma de graduação pela Cornell University e mestrado pela University of California, Berkeley. Em 2021, ele apresentou um artigo sobre redes neurais adversárias na conferência ICLR. Em seu tempo livre, Evan gosta de cozinhar, viajar e correr pela cidade de Nova York.
 Rachna Chadha é Arquiteto Principal de Soluções AI/ML em Contas Estratégicas na AWS. Rachna é uma otimista que acredita que o uso ético e responsável da IA pode melhorar a sociedade no futuro e trazer prosperidade econômica e social. Em seu tempo livre, Rachna gosta de passar o tempo com sua família, fazer caminhadas e ouvir música.
Rachna Chadha é Arquiteto Principal de Soluções AI/ML em Contas Estratégicas na AWS. Rachna é uma otimista que acredita que o uso ético e responsável da IA pode melhorar a sociedade no futuro e trazer prosperidade econômica e social. Em seu tempo livre, Rachna gosta de passar o tempo com sua família, fazer caminhadas e ouvir música.
 Dr. é um cientista aplicado sênior com algoritmos integrados do Amazon SageMaker e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele obteve seu PhD pela University of Illinois Urbana-Champaign. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos em conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
Dr. é um cientista aplicado sênior com algoritmos integrados do Amazon SageMaker e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele obteve seu PhD pela University of Illinois Urbana-Champaign. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos em conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
 Carlos Albertsen lidera produtos, engenharia e ciência para algoritmos do Amazon SageMaker e JumpStart, o hub de aprendizado de máquina do SageMaker. Ele é apaixonado por aplicar o aprendizado de máquina para gerar valor comercial.
Carlos Albertsen lidera produtos, engenharia e ciência para algoritmos do Amazon SageMaker e JumpStart, o hub de aprendizado de máquina do SageMaker. Ele é apaixonado por aplicar o aprendizado de máquina para gerar valor comercial.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/llama-guard-is-now-available-in-amazon-sagemaker-jumpstart/
- :tem
- :é
- :não
- :onde
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 2021
- 39
- 7
- 8
- 9
- a
- Capaz
- Sobre
- acima
- ACEITAR
- Acesso
- Segundo
- Contas
- Aja
- Açao Social
- ações
- ativo
- atividades
- real
- Adição
- Ajustado
- adotar
- avançar
- avanços
- adversarial
- conselho
- contra
- Agente
- AI
- Modelos de IA
- AI / ML
- Álcool
- algoritmos
- Todos os Produtos
- tb
- Amazon
- Amazon Sage Maker
- JumpStart do Amazon SageMaker
- Amazon Web Services
- an
- e
- Anunciar
- responder
- qualquer
- Aplicação
- aplicado
- Aplicar
- Aplicando
- apropriado
- SOMOS
- argumento
- argumentos
- Arte
- AS
- avaliação
- auxiliar
- Assistente
- associado
- certo
- At
- autoridade
- Automatizado
- disponível
- evitar
- AWS
- baseado
- basic
- Bayesiano
- BE
- viga
- Porque
- sido
- antes
- começar
- comportamento
- acredita
- abaixo
- benchmarks
- Berkeley
- MELHOR
- melhores práticas
- entre
- bilhões
- corpo
- ambos
- trazer
- Traz
- construir
- Prédio
- construídas em
- negócio
- mas a
- by
- Califórnia
- CAN
- canabis
- cartão
- casas
- casos
- Categorias
- Categoria
- célula
- desafios
- chance
- alterar
- características
- acusações
- bate-papo
- chatbots
- verificar
- químico
- escolha
- Escolha
- escolha
- Cidades
- classe
- limpar
- Na nuvem
- computação em nuvem
- código
- cor
- vinda
- comercial
- comprometido
- comum
- comunidade
- compatível
- obedecer
- componentes
- composição
- computador
- Visão de Computador
- computação
- Conferência
- conferências
- Confirmar
- CONFIRMADO
- confluência
- cônsul
- consumo
- não contenho
- Recipiente
- contém
- conteúdo
- moderação de conteúdo
- contexto
- continua
- ao controle
- controlado
- controles
- Conversa
- conversação
- conversas
- cozinha
- cornell
- poderia
- crio
- criação
- Crimes
- Criminal
- crítico
- comissariada
- cliente
- Atendimento ao Cliente
- Clientes
- personalizar
- cibernético
- cíber segurança
- ciclo
- dados,
- conjuntos de dados
- dia
- decodificação
- profundo
- deep learning
- Padrão
- definir
- definições
- Grau
- implantar
- implantado
- Implantação
- desenvolvimento
- Implantações
- Design
- processo de design
- desejo
- desejado
- detalhado
- detalhes
- Detecção
- Determinar
- determinado
- desenvolver
- Developer
- desenvolvedores
- Desenvolvimento
- DICT
- diferente
- digital
- Art digitais
- Incapacidade
- descobrir
- Discriminação
- discutir
- do
- parece
- Drogas
- Duque
- Universidade Duke
- e
- cada
- Mais cedo
- Cedo
- facilmente
- Econômico
- ecossistema
- Educação
- efeitos
- sem esforço
- permitir
- permitindo
- encorajar
- final
- end-to-end
- Ponto final
- endpoints
- engajar
- engenheiro
- Engenharia
- garantir
- garante
- Meio Ambiente
- igual
- especialmente
- Éter (ETH)
- considerações éticas
- avaliação
- avaliações
- eventos
- exemplo
- Exceto
- exceção
- animado
- excluindo
- execução
- existente
- caro
- explorar
- expresso
- estender
- Rosto
- enfrentou
- falso
- família
- Apresentando
- poucos
- financeiro
- crimes financeiros
- Encontre
- armas de fogo
- Primeiro nome
- marcado
- Flutuador
- Foco
- seguir
- seguido
- seguinte
- segue
- Escolha
- formato
- fomento
- Foundation
- Gratuito
- da
- cheio
- funções
- mais distante
- futuro
- Gênero
- Geral
- gerar
- gerado
- gera
- gerando
- geração
- generativo
- IA generativa
- ter
- GitHub
- dado
- Dando
- Go
- vai
- tem
- maior
- Ganancioso
- garantias
- Guarda
- orientações
- ARMAS
- prejudicar
- arreios
- odiar
- Ter
- he
- Saúde
- ajudar
- ajuda
- sua experiência
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- superior
- caminhadas
- sua
- histórico
- hospedado
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- Hub
- Hubs
- i
- ICLR
- ID
- identificação
- Identidade
- if
- Ilegal
- Illinois
- imediatamente
- importar
- melhorar
- in
- incluir
- inclui
- Incluindo
- de treinadores em Entrevista Motivacional
- indicam
- indicam
- indicador
- INFORMAÇÕES
- Informativa
- arraigado
- do estado inicial,
- Iniciativa
- Inovação
- entrada
- inputs
- instância
- instruções
- instrumental
- integrar
- integrado
- interessado
- interesses
- Interface
- para dentro
- envolvendo
- IT
- ESTÁ
- jpg
- Matar
- Saber
- conhecido
- kyle
- aterrissagem
- página de destino
- língua
- grande
- Sobrenome
- Leis
- Leads
- aprendizagem
- partida
- Comprimento
- deixar
- Licença
- Licenciado
- licenças
- como
- probabilidade
- Provável
- gostos
- Limitado
- Line
- linux
- Lista
- Escuta
- lhama
- local
- OLHARES
- diminuir
- máquina
- aprendizado de máquina
- a manter
- fazer
- manualmente
- fabricado
- muitos
- mestre
- Posso..
- significado
- medidas
- Mídia
- mental
- A saúde mental
- mensagem
- mensagens
- Meta
- método
- métodos
- poder
- minutos
- mitigação
- misturar
- ML
- modelo
- modelos
- moderada
- moderação
- monitoração
- mais
- a maioria
- Música
- devo
- Deve ler
- Nacional
- necessário
- redes
- Neural
- redes neurais
- NeuroIPS
- nunca
- Novo
- New York
- Cidade de Nova Iorque
- Próximo
- não
- caderno
- laptops
- Perceber..
- agora
- número
- objeto
- of
- oferecendo treinamento para distância
- on
- ONE
- só
- aberto
- abertamente
- operacional
- Opção
- Opções
- or
- Origin
- Outros
- A Nossa
- Fora
- Resultado
- saída
- outputs
- Acima de
- próprio
- propriedade
- página
- Papel
- papéis
- parâmetro
- parâmetros
- parte
- particular
- partes
- passar
- Passagem
- apaixonado
- Pessoas
- para
- realizar
- executa
- pessoa
- pessoal
- phd
- Avião
- plano
- planejamento
- platão
- Inteligência de Dados Platão
- PlatãoData
- Privacidade
- Popular
- positivo
- possível
- Publique
- potencial
- potencialmente
- práticas
- precedente
- Predictor
- preparação
- apresentado
- evitar
- Diretor
- Priorizar
- probabilidade
- processo
- processos
- Produto
- Produção
- projeto
- solicita
- prosperidade
- fornecer
- fornecido
- fornecedores
- fornece
- publicamente
- publicado
- Publishing
- fins
- colocar
- Python
- pytorch
- qualidade
- rapidamente
- Corrida
- aleatoriedade
- alcance
- em vez
- alcançar
- Chega
- Leia
- recebido
- recentemente
- Recomenda
- referir
- em relação a
- regulamentadas
- regulamentos
- relacionado
- liberar
- relevante
- religião
- repetido
- substituir
- pedidos
- requeridos
- pesquisa
- investigador
- Recursos
- respeito
- responder
- resposta
- responsável
- com responsabilidade
- DESCANSO
- resultar
- Resultados
- retorno
- rever
- Subir
- Risco
- Arriscado
- roadmap
- Tipo
- papéis
- regras
- Execute
- é executado
- seguro
- proteções
- Segurança
- sábio
- Inferência do SageMaker
- escalável
- Escala
- Ciência
- Cientista
- Sdk
- Pesquisar
- pesquisar
- Segundo
- Seção
- seções
- seguro
- segurança
- Vejo
- selecionar
- senior
- sensível
- sentença
- sentimentos
- Seqüência
- Série
- serviço
- Serviços
- conjunto
- Sexual
- compartilhado
- rede de apoio social
- mostrar
- mostrou
- mostrando
- mostrando
- solteiro
- So
- Redes Sociais
- meios de comunicação social
- Sociedade
- Software
- Engenheiro de Software
- solução
- Soluções
- especial
- específico
- especificada
- Passar
- padrões
- começado
- Comece
- estatístico
- estatística
- Passo
- Passos
- Ainda
- Pára
- Estratégico
- estratégias
- estudo
- bem sucedido
- tal
- Suicídio
- ajuda
- suportes
- certo
- sintaxe
- .
- sistemas
- Tire
- Tarefa
- tarefas
- Profissionais
- modelo
- modelos
- fluxo tensor
- condições
- teste
- testado
- texto
- geração de texto
- do que
- que
- A
- O Futuro
- as informações
- roubo
- deles
- Eles
- si mesmos
- então
- Lá.
- Este
- deles
- Terceiro
- terceiro
- De terceiros
- isto
- aqueles
- Através da
- tempo
- Séries temporais
- para
- tabaco
- hoje
- juntos
- token
- Tokens
- ferramenta
- ferramentas
- Temas
- tráfico
- Trem
- treinado
- Training
- Tradução
- Viagens
- verdadeiro
- Confiança
- tentar
- VIRAR
- tipos
- tipicamente
- ui
- Em última análise
- para
- compreender
- universidade
- Universidade da Califórnia
- destravar
- até
- us
- Uso
- usar
- caso de uso
- usava
- Utilizador
- usos
- utilização
- valor
- Valores
- variedade
- versão
- Ver
- violados
- Violando
- visão
- visual
- andar
- queremos
- Caminho..
- we
- armas
- web
- serviços web
- Web-Based
- O Quê
- quando
- se
- qual
- QUEM
- inteiro
- Largo
- precisarão
- de
- dentro
- sem
- Word
- palavras
- Atividades:
- de gestão de documentos
- trabalhar
- seria
- Iorque
- Você
- investimentos
- zefirnet