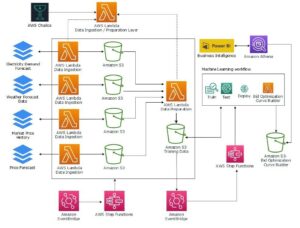
Os embeddings desempenham um papel fundamental no processamento de linguagem natural (PNL) e no aprendizado de máquina (ML). Incorporação de texto refere-se ao processo de transformação de texto em representações numéricas que residem em um espaço vetorial de alta dimensão. Esta técnica é conseguida através da utilização de algoritmos de ML que permitem a compreensão do significado e do contexto dos dados (relações semânticas) e a aprendizagem de relações e padrões complexos dentro dos dados (relações sintáticas). Você pode usar as representações vetoriais resultantes para uma ampla variedade de aplicações, como recuperação de informações, classificação de texto, processamento de linguagem natural e muitas outras.
Incorporações de texto do Amazon Titan é um modelo de incorporação de texto que converte texto em linguagem natural – consistindo em palavras únicas, frases ou até mesmo documentos grandes – em representações numéricas que podem ser usadas para potencializar casos de uso como pesquisa, personalização e agrupamento com base na similaridade semântica.
Nesta postagem, discutimos o modelo Amazon Titan Text Embeddings, seus recursos e exemplos de casos de uso.
Alguns conceitos-chave incluem:
- A representação numérica do texto (vetores) captura a semântica e as relações entre as palavras
- Incorporações ricas podem ser usadas para comparar semelhanças de texto
- Incorporações de texto multilíngue podem identificar o significado em diferentes idiomas
Como um trecho de texto é convertido em um vetor?
Existem várias técnicas para converter uma frase em um vetor. Um método popular é usar algoritmos de incorporação de palavras, como Word2Vec, GloVe ou FastText, e depois agregar as incorporações de palavras para formar uma representação vetorial em nível de frase.
Outra abordagem comum é usar grandes modelos de linguagem (LLMs), como BERT ou GPT, que podem fornecer incorporações contextualizadas para frases inteiras. Esses modelos são baseados em arquiteturas de aprendizagem profunda, como Transformers, que podem capturar as informações contextuais e as relações entre as palavras em uma frase de forma mais eficaz.
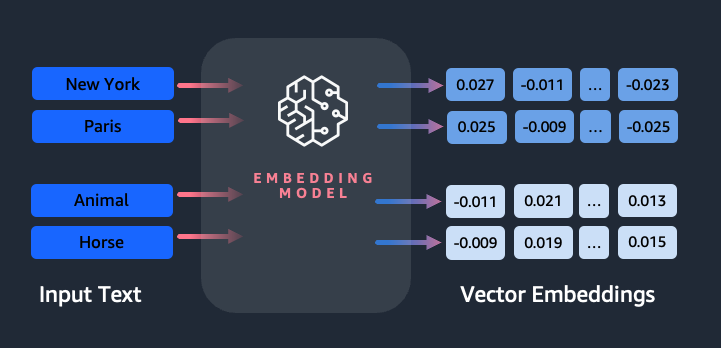
Por que precisamos de um modelo de incorporação?
As incorporações de vetores são fundamentais para que os LLMs entendam os graus semânticos da linguagem e também permitem que os LLMs tenham um bom desempenho em tarefas downstream de PNL, como análise de sentimento, reconhecimento de entidade nomeada e classificação de texto.
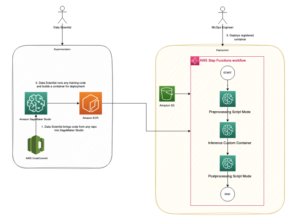
Além da pesquisa semântica, você pode usar embeddings para aumentar seus prompts e obter resultados mais precisos por meio da Retrieval Augmented Generation (RAG), mas para usá-los, você precisará armazená-los em um banco de dados com recursos vetoriais.
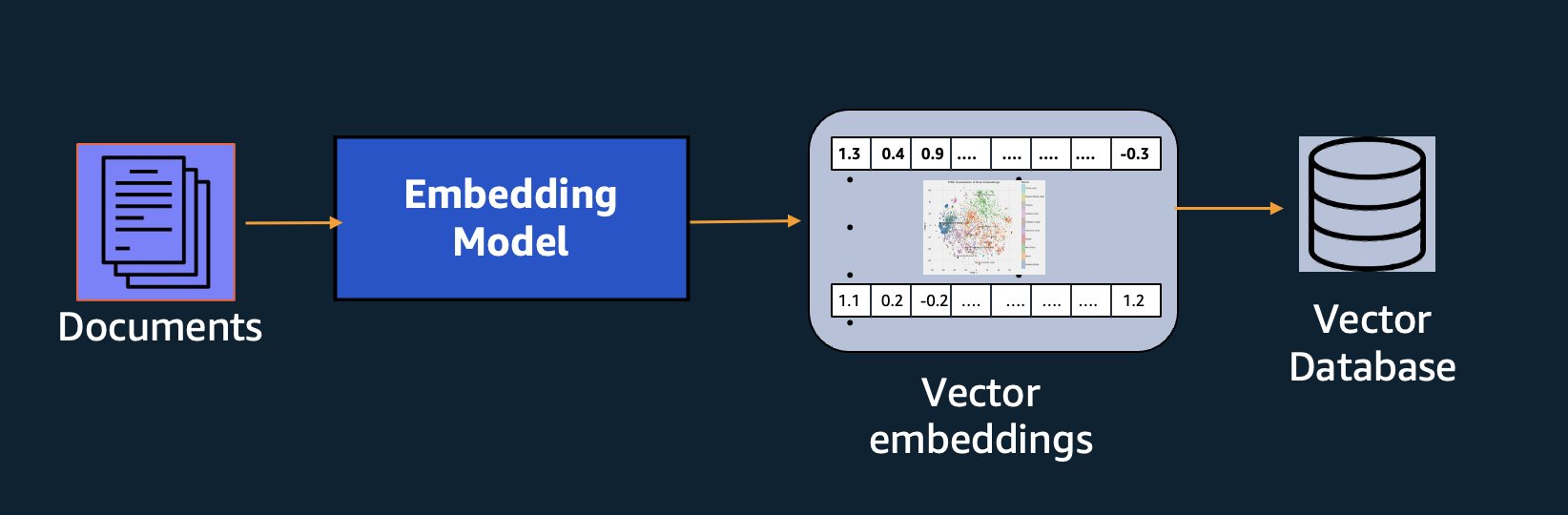
O modelo Amazon Titan Text Embeddings é otimizado para recuperação de texto para permitir casos de uso RAG. Ele permite que você primeiro converta seus dados de texto em representações numéricas ou vetores e, em seguida, use esses vetores para pesquisar com precisão passagens relevantes em um banco de dados vetorial, permitindo aproveitar ao máximo seus dados proprietários em combinação com outros modelos básicos.
Como o Amazon Titan Text Embeddings é um modelo gerenciado no Rocha Amazônica, é oferecido como uma experiência totalmente sem servidor. Você pode usá-lo por meio do Amazon Bedrock REST API ou o SDK da AWS. Os parâmetros necessários são o texto do qual você gostaria de gerar os embeddings e o modelID parâmetro, que representa o nome do modelo Amazon Titan Text Embeddings. O código a seguir é um exemplo usando o AWS SDK for Python (Boto3):
A saída será semelhante a esta:
Consulte Configuração do Amazon Bedrock boto3 para obter mais detalhes sobre como instalar os pacotes necessários, conectar-se ao Amazon Bedrock e invocar modelos.
Recursos de incorporações de texto do Amazon Titan
Com o Amazon Titan Text Embeddings, você pode inserir até 8,000 tokens, tornando-o adequado para trabalhar com palavras únicas, frases ou documentos inteiros com base no seu caso de uso. O Amazon Titan retorna vetores de saída de dimensão 1536, proporcionando um alto grau de precisão e, ao mesmo tempo, otimizando resultados econômicos e de baixa latência.
O Amazon Titan Text Embeddings oferece suporte à criação e consulta de embeddings de texto em mais de 25 idiomas diferentes. Isso significa que você pode aplicar o modelo aos seus casos de uso sem precisar criar e manter modelos separados para cada linguagem que deseja oferecer suporte.
Ter um único modelo de embeddings treinado em vários idiomas oferece os seguintes benefícios principais:
- Alcance mais amplo – Ao oferecer suporte imediato a mais de 25 idiomas, você pode expandir o alcance de seus aplicativos para usuários e conteúdo em muitos mercados internacionais.
- Desempenho consistente – Com um modelo unificado que abrange vários idiomas, você obtém resultados consistentes em todos os idiomas, em vez de otimizar separadamente por idioma. O modelo é treinado de forma holística para que você obtenha vantagem em todos os idiomas.
- Suporte a consultas multilíngues – Amazon Titan Text Embeddings permite consultar embeddings de texto em qualquer um dos idiomas suportados. Isso fornece flexibilidade para recuperar conteúdo semanticamente semelhante em vários idiomas, sem ficar restrito a um único idioma. Você pode criar aplicativos que consultam e analisam dados multilíngues usando o mesmo espaço de incorporação unificado.
No momento em que este livro foi escrito, os seguintes idiomas eram suportados:
- Arabe
- Chinês (simplificado)
- Chinês (tradicional)
- Checo
- Neerlandês
- Inglês
- Francês
- Alemão
- Hebraico
- Hindi
- Italiano
- Japonês
- kannada
- Coreana
- malayalam
- marata
- Polaco
- Português
- Russo
- Espanhol
- Sueco
- Tagalo filipino
- tâmil
- telugu
- Turco
Usando incorporações de texto do Amazon Titan com LangChain
LangChain é uma estrutura de código aberto popular para trabalhar com modelos generativos de IA e tecnologias de suporte. Inclui um Cliente BedrockEmbeddings que envolve convenientemente o Boto3 SDK com uma camada de abstração. O BedrockEmbeddings O cliente permite que você trabalhe diretamente com texto e embeddings, sem conhecer os detalhes da solicitação JSON ou das estruturas de resposta. O seguinte é um exemplo simples:
Você também pode usar o LangChain BedrockEmbeddings junto com o cliente Amazon Bedrock LLM para simplificar a implementação de RAG, pesquisa semântica e outros padrões relacionados a incorporações.
Casos de uso para incorporações
Embora o RAG seja atualmente o caso de uso mais popular para trabalhar com embeddings, existem muitos outros casos de uso onde os embeddings podem ser aplicados. A seguir estão alguns cenários adicionais onde você pode usar embeddings para resolver problemas específicos, por conta própria ou em cooperação com um LLM:
- Pergunta e resposta – Os embeddings podem ajudar a oferecer suporte a interfaces de perguntas e respostas por meio do padrão RAG. A geração de embeddings combinada com um banco de dados vetorial permite encontrar correspondências próximas entre perguntas e conteúdo em um repositório de conhecimento.
- Recomendações personalizadas – Semelhante às perguntas e respostas, você pode usar embeddings para encontrar destinos de férias, faculdades, veículos ou outros produtos com base nos critérios fornecidos pelo usuário. Isto pode assumir a forma de uma simples lista de correspondências, ou então você pode usar um LLM para processar cada recomendação e explicar como ela satisfaz os critérios do usuário. Você também pode usar essa abordagem para gerar os “10 melhores” artigos personalizados para um usuário com base em suas necessidades específicas.
- Gestão de dados – Quando você tem fontes de dados que não são mapeadas de forma clara entre si, mas tem conteúdo de texto que descreve o registro de dados, você pode usar incorporações para identificar possíveis registros duplicados. Por exemplo, você pode usar embeddings para identificar candidatos duplicados que podem usar formatação e abreviações diferentes ou até mesmo ter nomes traduzidos.
- Racionalização do portfólio de aplicativos – Ao procurar alinhar portfólios de aplicativos entre uma empresa controladora e uma aquisição, nem sempre é óbvio por onde começar a encontrar possíveis sobreposições. A qualidade dos dados de gerenciamento de configuração pode ser um fator limitante e pode ser difícil coordenar as equipes para compreender o cenário dos aplicativos. Ao usar a correspondência semântica com incorporações, podemos fazer uma análise rápida em portfólios de aplicativos para identificar aplicativos candidatos de alto potencial para racionalização.
- Agrupamento de conteúdo – Você pode usar incorporações para ajudar a facilitar o agrupamento de conteúdo semelhante em categorias que você talvez não conheça com antecedência. Por exemplo, digamos que você tenha uma coleção de e-mails de clientes ou análises de produtos online. Você pode criar embeddings para cada item e, em seguida, executar esses embeddings agrupamento k-means para identificar agrupamentos lógicos de preocupações dos clientes, elogios ou reclamações de produtos ou outros temas. Você pode então gerar resumos específicos a partir do conteúdo desses agrupamentos usando um LLM.
Exemplo de pesquisa semântica
No nosso exemplo no GitHub, demonstramos um aplicativo simples de pesquisa de embeddings com Amazon Titan Text Embeddings, LangChain e Streamlit.
O exemplo corresponde a consulta de um usuário às entradas mais próximas em um banco de dados vetorial na memória. Em seguida, exibimos essas correspondências diretamente na interface do usuário. Isso pode ser útil se você quiser solucionar problemas de um aplicativo RAG ou avaliar diretamente um modelo de incorporação.
Para simplificar, usamos o in-memory FAISS banco de dados para armazenar e pesquisar vetores de embeddings. Em um cenário real em escala, você provavelmente desejará usar um armazenamento de dados persistente como o mecanismo de vetor para Amazon OpenSearch Serverless ou de vetor pg extensão para PostgreSQL.
Experimente alguns prompts do aplicativo Web em diferentes idiomas, como este:
- Como posso monitorar meu uso?
- Como posso personalizar modelos?
- Quais linguagens de programação posso usar?
- Comment mes données sont-elles sécurisées ?
- 私のデータはどのように保護されていますか?
- Quais fornecedores de modelos estão disponíveis por meio da Bedrock?
- Na região de Welchen, o Amazon Bedrock está disponível?
- 有哪些级别的支持?
Observe que, embora o material de origem estivesse em inglês, as consultas em outros idiomas foram correspondidas com entradas relevantes.
Conclusão
Os recursos de geração de texto dos modelos básicos são muito interessantes, mas é importante lembrar que compreender o texto, encontrar conteúdo relevante em um corpo de conhecimento e fazer conexões entre passagens são cruciais para alcançar o valor total da IA generativa. Continuaremos a ver casos de uso novos e interessantes para embeddings surgirem nos próximos anos, à medida que esses modelos continuarem a melhorar.
Próximos passos
Você pode encontrar exemplos adicionais de incorporações como notebooks ou aplicativos de demonstração nos seguintes workshops:
Sobre os autores
 Jason Stehle é arquiteto de soluções sênior na AWS, baseado na região da Nova Inglaterra. Ele trabalha com os clientes para alinhar os recursos da AWS aos seus maiores desafios de negócios. Fora do trabalho, ele passa o tempo construindo coisas e assistindo filmes de quadrinhos com a família.
Jason Stehle é arquiteto de soluções sênior na AWS, baseado na região da Nova Inglaterra. Ele trabalha com os clientes para alinhar os recursos da AWS aos seus maiores desafios de negócios. Fora do trabalho, ele passa o tempo construindo coisas e assistindo filmes de quadrinhos com a família.
 Nitin Eusébio See More é arquiteto sênior de soluções empresariais na AWS, com experiência em engenharia de software, arquitetura empresarial e IA/ML. Ele é profundamente apaixonado por explorar as possibilidades da IA generativa. Ele colabora com os clientes para ajudá-los a criar aplicativos bem arquitetados na plataforma AWS e se dedica a solucionar desafios tecnológicos e auxiliá-los em sua jornada para a nuvem.
Nitin Eusébio See More é arquiteto sênior de soluções empresariais na AWS, com experiência em engenharia de software, arquitetura empresarial e IA/ML. Ele é profundamente apaixonado por explorar as possibilidades da IA generativa. Ele colabora com os clientes para ajudá-los a criar aplicativos bem arquitetados na plataforma AWS e se dedica a solucionar desafios tecnológicos e auxiliá-los em sua jornada para a nuvem.
 Raj Pathak é arquiteto de soluções principal e consultor técnico de grandes empresas da Fortune 50 e instituições de serviços financeiros (FSI) de médio porte no Canadá e nos Estados Unidos. Ele é especialista em aplicações de aprendizado de máquina, como IA generativa, processamento de linguagem natural, processamento inteligente de documentos e MLOps.
Raj Pathak é arquiteto de soluções principal e consultor técnico de grandes empresas da Fortune 50 e instituições de serviços financeiros (FSI) de médio porte no Canadá e nos Estados Unidos. Ele é especialista em aplicações de aprendizado de máquina, como IA generativa, processamento de linguagem natural, processamento inteligente de documentos e MLOps.
 Mani Khanuja é líder de tecnologia – Generative AI Specialists, autora do livro – Applied Machine Learning and High Performance Computing on AWS e membro do Conselho de Administração da Women in Manufacturing Education Foundation Board. Ela lidera projetos de aprendizado de máquina (ML) em vários domínios, como visão computacional, processamento de linguagem natural e IA generativa. Ela ajuda os clientes a construir, treinar e implantar grandes modelos de aprendizado de máquina em escala. Ela fala em conferências internas e externas como re:Invent, Women in Manufacturing West, webinars no YouTube e GHC 23. Em seu tempo livre, ela gosta de fazer longas corridas na praia.
Mani Khanuja é líder de tecnologia – Generative AI Specialists, autora do livro – Applied Machine Learning and High Performance Computing on AWS e membro do Conselho de Administração da Women in Manufacturing Education Foundation Board. Ela lidera projetos de aprendizado de máquina (ML) em vários domínios, como visão computacional, processamento de linguagem natural e IA generativa. Ela ajuda os clientes a construir, treinar e implantar grandes modelos de aprendizado de máquina em escala. Ela fala em conferências internas e externas como re:Invent, Women in Manufacturing West, webinars no YouTube e GHC 23. Em seu tempo livre, ela gosta de fazer longas corridas na praia.
 Marcos Roy é o principal arquiteto de aprendizado de máquina da AWS, ajudando os clientes a projetar e criar soluções de IA/ML. O trabalho de Mark abrange uma ampla variedade de casos de uso de ML, com interesse principal em visão computacional, aprendizado profundo e dimensionamento de ML em toda a empresa. Ele ajudou empresas em muitos setores, incluindo seguros, serviços financeiros, mídia e entretenimento, saúde, serviços públicos e manufatura. Mark possui seis certificações da AWS, incluindo a certificação de especialidade de ML. Antes de ingressar na AWS, Mark foi arquiteto, desenvolvedor e líder de tecnologia por mais de 25 anos, incluindo 19 anos em serviços financeiros.
Marcos Roy é o principal arquiteto de aprendizado de máquina da AWS, ajudando os clientes a projetar e criar soluções de IA/ML. O trabalho de Mark abrange uma ampla variedade de casos de uso de ML, com interesse principal em visão computacional, aprendizado profundo e dimensionamento de ML em toda a empresa. Ele ajudou empresas em muitos setores, incluindo seguros, serviços financeiros, mídia e entretenimento, saúde, serviços públicos e manufatura. Mark possui seis certificações da AWS, incluindo a certificação de especialidade de ML. Antes de ingressar na AWS, Mark foi arquiteto, desenvolvedor e líder de tecnologia por mais de 25 anos, incluindo 19 anos em serviços financeiros.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :tem
- :é
- :não
- :onde
- $UP
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- Sobre
- abstração
- ACEITAR
- precisão
- preciso
- exatamente
- alcançado
- alcançar
- aquisição
- em
- Adição
- Adicional
- Vantagem
- assessor
- à frente
- AI
- Modelos de IA
- AI / ML
- algoritmos
- alinhar
- Todos os Produtos
- permitir
- Permitindo
- permite
- juntamente
- ao lado de
- tb
- sempre
- Amazon
- Amazon Web Services
- an
- análise
- analisar
- e
- responder
- qualquer
- Aplicação
- aplicações
- aplicado
- Aplicar
- abordagem
- arquitetura
- Arquiteturas
- SOMOS
- ÁREA
- artigos
- AS
- ajudando
- At
- aumentar
- aumentado
- autor
- disponível
- AWS
- baseado
- BE
- Beach
- ser
- Benefícios
- entre
- borda
- conselho de administração
- corpo
- livro
- Caixa
- construir
- Prédio
- negócio
- mas a
- by
- CAN
- Localização: Canadá
- candidato
- candidatos
- capacidades
- capturar
- capturas
- casas
- casos
- Categorias
- FDA
- certificações
- desafios
- classificação
- cliente
- Fechar
- Na nuvem
- agrupamento
- código
- coleção
- Faculdades
- combinação
- comum
- Empresas
- Empresa
- comparar
- queixas
- integrações
- computador
- Visão de Computador
- computação
- conceitos
- Preocupações
- conferências
- Configuração
- Contato
- da conexão
- Coneções
- consistente
- conteúdo
- contexto
- contextual
- continuar
- convenientemente
- converter
- convertido
- cooperação
- coordenando
- relação custo-benefício
- poderia
- cobertura
- cobre
- crio
- Criar
- critérios
- crucial
- Atualmente
- personalizadas
- cliente
- Clientes
- personalizar
- dados,
- banco de dados
- de
- dedicado
- profundo
- deep learning
- profundamente
- definir
- Grau
- Demo
- demonstrar
- implantar
- descreve
- Design
- destinos
- detalhes
- Developer
- diferente
- difícil
- Dimensão
- diretamente
- Administração
- discutir
- Ecrã
- do
- documento
- INSTITUCIONAIS
- domínios
- não
- cada
- Educação
- efetivamente
- ou
- e-mails
- embutindo
- emergem
- permitir
- permite
- Motor
- Engenharia
- Inglaterra
- Inglês
- Empreendimento
- Soluções Empresariais
- Entretenimento
- Todo
- inteiramente
- entidade
- Éter (ETH)
- avaliar
- Mesmo
- exemplo
- exemplos
- emocionante
- Expandir
- vasta experiência
- experiente
- Explicação
- Explorando
- extensão
- externo
- facilitar
- fator
- família
- Funcionalidades
- poucos
- financeiro
- serviços financeiros
- Encontre
- descoberta
- Primeiro nome
- Flexibilidade
- focado
- seguinte
- Escolha
- formulário
- Fortune
- Foundation
- Quadro
- Gratuito
- da
- cheio
- fundamental
- gerar
- geração
- generativo
- IA generativa
- ter
- obtendo
- Dando
- luva
- Go
- maior
- tinha
- Ter
- he
- saúde
- ajudar
- ajudou
- ajuda
- ajuda
- sua experiência
- Alta
- Computação de Alto Desempenho
- sua
- detém
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- i
- identificar
- if
- implementação
- importar
- importante
- melhorar
- in
- Em outra
- incluir
- inclui
- Incluindo
- indústrias
- INFORMAÇÕES
- entrada
- instalar
- em vez disso
- instituições
- com seguro
- Inteligente
- Processamento inteligente de documentos
- interesse
- interessante
- Interface
- interfaces de
- interno
- Internacionais
- para dentro
- IT
- ESTÁ
- juntando
- viagem
- jpg
- json
- Chave
- Saber
- Conhecimento
- Conhecimento
- paisagem
- língua
- Idiomas
- grande
- camada
- conduzir
- líder
- Leads
- aprendizagem
- deixar
- como
- Provável
- gostos
- limitando
- Lista
- Ilm
- lógico
- longo
- olhar
- procurando
- máquina
- aprendizado de máquina
- a manter
- fazer
- Fazendo
- gerenciados
- de grupos
- fabrica
- muitos
- mapa,
- marca
- Mark's
- Mercados
- correspondido
- fósforos
- correspondente
- material
- me
- significado
- significa
- Mídia
- membro
- método
- poder
- ML
- Algoritmos de ML
- MLOps
- modelo
- modelos
- Monitore
- mais
- a maioria
- Mais populares
- Filmes
- múltiplo
- my
- nome
- Nomeado
- nomes
- natural
- Linguagem Natural
- Processamento de linguagem natural
- você merece...
- necessitando
- Cria
- Novo
- Próximo
- PNL
- laptops
- óbvio
- of
- oferecido
- on
- ONE
- online
- aberto
- open source
- otimizado
- otimizando
- or
- ordem
- Outros
- Outros
- A Nossa
- Fora
- saída
- lado de fora
- Acima de
- próprio
- pacotes
- emparelhado
- parâmetro
- parâmetros
- empresa-mãe
- passagens
- apaixonado
- padrão
- padrões
- para
- realizar
- atuação
- Personalização
- Frases
- peça
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- Jogar
- por favor
- Popular
- POR
- pasta
- carteiras
- possibilidades
- Publique
- Postgresql
- potencial
- poder
- primário
- Diretor
- Impressão
- Prévio
- problemas
- processo
- em processamento
- Produto
- Opiniões
- Produtos
- Programação
- linguagens de programação
- projetos
- solicita
- proprietário
- fornecer
- fornecido
- fornece
- Python
- qualidade
- consultas
- pergunta
- questão
- Frequentes
- Links
- trapo
- alcance
- RE
- alcançar
- mundo real
- reconhecimento
- Recomendação
- recomendações
- registro
- registros
- refere-se
- Relacionamentos
- relevante
- lembrar
- repositório
- representação
- representa
- solicitar
- requeridos
- resposta
- DESCANSO
- restringido
- resultando
- Resultados
- recuperação
- Retorna
- Opinões
- Tipo
- Execute
- é executado
- s
- mesmo
- dizer
- Escala
- dimensionamento
- cenário
- cenários
- Sdk
- Pesquisar
- Vejo
- semântico
- semântica
- senior
- sentença
- sentimento
- separado
- Serverless
- Serviços
- ela
- semelhante
- simples
- simplicidade
- simplificada
- simplificar
- solteiro
- SIX
- So
- Software
- Engenharia de software
- Soluções
- RESOLVER
- Resolvendo
- alguns
- algo
- fonte
- Fontes
- Espaço
- fala
- especialistas
- especializada
- Especialidade
- específico
- começo
- começado
- Unidos
- loja
- estruturas
- tal
- ajuda
- Suportado
- Apoiar
- suportes
- Tire
- tarefas
- equipes
- tecnologia
- Dados Técnicos:
- técnica
- técnicas
- Tecnologias
- Tecnologia
- dizer
- texto
- Classificação de Texto
- geração de texto
- que
- A
- A fonte
- deles
- Eles
- temas
- então
- Lá.
- Este
- coisas
- isto
- aqueles
- Apesar?
- Através da
- tempo
- titã
- para
- Tokens
- tradicional
- Trem
- treinado
- transformadores
- transformando
- compreender
- compreensão
- unificado
- Unido
- Estados Unidos
- Uso
- usar
- caso de uso
- usava
- útil
- Utilizador
- Interface de Usuário
- usuários
- utilização
- utilitários
- férias
- valor
- vário
- Veículos
- muito
- via
- visão
- queremos
- foi
- assistindo
- we
- web
- Aplicativo da Web
- serviços web
- Webinars
- BEM
- foram
- Ocidente
- quando
- qual
- enquanto
- Largo
- Ampla variedade
- precisarão
- de
- dentro
- sem
- Mulher
- Word
- palavras
- Atividades:
- trabalhar
- trabalho
- Workshops
- seria
- escrever
- escrita
- anos
- Você
- investimentos
- Youtube
- zefirnet