Introdução ao aprendizado de máquina automatizado
O AutoML permite que os desenvolvedores com conhecimento limitado em ML (e experiência em codificação) treinem modelos de alta qualidade específicos para suas necessidades de negócios. Neste artigo, vamos nos concentrar em sistemas AutoML que atendem aos negócios diários e aplicativos de tecnologia.

O que são sistemas AutoML?
O aprendizado de máquina (ML) - como um subcampo do domínio mais amplo da Inteligência Artificial (IA) - está assumindo todos os tipos de setores e domínios de negócios. Isso inclui varejo, saúde, automotivo, finanças, entretenimento e muito mais. Com essa adoção mais ampla em todos os tipos de operações e por uma força de trabalho com um conjunto diversificado de habilidades, aprender a trabalhar com aprendizado de máquina está se tornando cada vez mais importante.
Devido a esta expansão do uso de ML pelo seção transversal cada vez maior de funcionários em uma organização, tornou-se crítico desenvolver sistemas que possam ser usados por profissionais de negócios de todos os tipos de origens. E isso significa que esses sistemas não pode ser exclusivamente orientado para codificação ou programação como os usados por engenheiros de software ou cientistas de dados.
É aqui que os sistemas AutoML entram em cena.
Resumindo, o AutoML permite desenvolvedores com experiência limitada em ML (e experiência de codificação) para treinar modelos de alta qualidade específicos para seus necessidades de negócios. Existem outros aspectos do AutoML de um ponto de vista de pesquisa acadêmica (ou seja, pesquisar os melhores algoritmos de ML para determinados tipos de dados e provar propriedades teóricas sobre esses sistemas); mas, neste artigo, vamos nos concentrar nos sistemas AutoML que atendem aos negócios do dia-a-dia e aos aplicativos de tecnologia.
Por que os sistemas AutoML estão ganhando popularidade?
Conforme mencionado acima, profissionais de todos os tipos de origens e conjuntos de habilidades estão entrando no campo da ciência de dados e aprendizado de máquina para seus respectivos negócios ou atividades de P&D. Nem todos eles têm uma formação rigorosa ou treinamento formal em ciências estatísticas ou teoria de aprendizado de máquina.
Eles só precisam ser capazes de originar ou ingerir um conjunto de dados, seguir um fluxo de trabalho completo de exploração de dados e treinamento de modelo e produzir um modelo treinado para um aplicativo de ML downstream.
Seria mais demorado da parte deles se tiverem que fazer tudo isso sozinhos:
- pesquisar em todos os algoritmos de ML possíveis,
- avalie-os no conjunto de dados de treinamento,
- verifique o desempenho do conjunto de validação de maneira rigorosa,
- aplique julgamento adicional (memória e pegada da CPU) para selecionar o melhor modelo para o aplicativo final.
Os sistemas AutoML, em grande medida, fazem tudo isso levantamento de peso para cientistas de dados ou analistas e automatizar ou agilizar a geração de modelos de ML treinados altamente otimizados para uso pronto para produção.
Consequentemente, esses sistemas estão ganhando popularidade entre as organizações que utilizam intensamente a ciência de dados porque:
- economiza o custo de mão de obra e número de funcionários da organização, pois uma força de trabalho relativamente enxuta pode utilizar esses sistemas para treinar e otimizar um grande número de modelos de ML
- reduzir a chance de erro automatizando não apenas o treinamento e a otimização do modelo, mas também os chamados aspectos enfadonhos da ciência de dados (ou seja, ingestão de dados, análise, conversão e exploração de recursos em grande medida)
- reduzir o tempo de colocação no mercado de uma grande porcentagem de aplicativos baseados em ML com um padrão de desempenho relativamente alto
Com relação ao tempo de lançamento no mercado, pode-se argumentar que o resultado final produzido por um sistema AutoML pode não ser tão bom ou otimizado em comparação com aquele arquitetado por um engenheiro especialista em ML (usando engenharia de recursos feita à mão ou ajuste de aprendizado profundo )
No entanto, esse tipo de ajuste manual costuma ser um processo demorado e, para a maioria das situações, chegar a um status de pronto para produção com um modelo de ML decente em um período de tempo relativamente menor é muito mais crítico para uma organização do que perder tempo em produzir o modelo de melhor desempenho absoluto. Os sistemas AutoML ajudam as organizações a atingir esse objetivo crítico de negócios, daí sua crescente popularidade e adoção mais ampla.
Agora as organizações podem simplesmente obter estações de trabalho de aprendizado de máquina personalizadas para sua força de trabalho, instale ferramentas como o AutoML para ativar rapidamente um sistema funcional baseado em aprendizado de máquina e seguir em frente com as próximas etapas na produção pronta para IA para chegar ao mercado com seus resultados mais rápido do que nunca.
Tipos de sistemas AutoML e alguns exemplos proeminentes
Existem alguns tipos diferentes de sistemas AutoML, pois eles atendem a diferentes categorias de tarefas em uma ciência de dados ou fluxo de trabalho de ML.
Alguns tipos de sistemas AutoML incluem:
- AutoML para ajuste automatizado de parâmetros (um tipo relativamente básico)
- AutoML para aprendizado não profundo, por exemplo, Auto-Sklearn. Esse tipo é aplicado principalmente no pré-processamento de dados, análise automatizada de recursos, detecção automatizada de recursos, seleção automática de recursos e seleção automática de modelos.
- AutoML para aprendizagem profunda / redes neurais, incluindo sistemas projetados especificamente para pesquisa de arquitetura neural (NAS), bem como pacotes de utilitários como Auto Keras construído sobre a estrutura de aprendizado profundo altamente popular.
Auto-Sklearn
Como o nome sugere, o Auto-Sklearn é um pacote de software de aprendizado de máquina automatizado baseado no scikit-learn. O Auto-Sklearn libera um cientista de dados da tarefa de seleção de algoritmo e ajuste de hiperparâmetros. Essencialmente, ele procura automaticamente o algoritmo de aprendizado certo para um novo conjunto de dados de aprendizado de máquina e otimiza seus hiperparâmetros.
Ele estende a ideia de configurar uma estrutura geral de aprendizado de máquina com otimização global eficiente que foi introduzida com Auto-WEKA. Para melhorar a generalização, Auto-Sklearn constrói um conjunto de todos os modelos testado durante o processo de otimização global. Para acelerar o processo de otimização, o Auto-Sklearn usa meta-aprendizagem para identificar conjuntos de dados semelhantes e usar o conhecimento adquirido no passado.
Inclui métodos de engenharia de recursos, como codificação one-hot, padronização de recursos digitais e análise de componentes principais (PCA). Basicamente, a biblioteca usa estimadores scikit-learn para processar problemas de classificação e regressão.

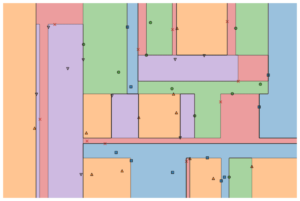
Fluxo de trabalho e diagrama do Auto-Sklearn
Documentação: Você pode encontrar o documentação detalhada aqui.
Exemplo de código: Aqui mostramos um exemplo de código de tarefa de classificação básica com Auto-Sklearn. Construímos um modelo de ML para classificar os dígitos numéricos usando um conjunto de dados integrado no pacote scikit-learn.
import autosklearn.classification
import sklearn.model_selection
import sklearn.datasets
import sklearn.metrics if __name__ == "__main__": X, y = sklearn.datasets.load_digits(return_X_y=True) X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, random_state=1) automl = autosklearn.classification.AutoSklearnClassifier() automl.fit(X_train, y_train) y_hat = automl.predict(X_test) print("Accuracy score", sklearn.metrics.accuracy_score(y_test, y_hat))Nota sobre o sistema operacional: Auto-Sklearn depende muito do recurso do módulo Python. Este módulo é parte dos Serviços específicos do Unix do Python e não está disponível em uma máquina Windows. Portanto, a partir de hoje, não é possível executar o auto-sklearn em uma máquina Windows.
Soluções possíveis:
- Shell bash do Windows 10 (consulte 431 e 860 para obter sugestões)
- Máquina virtual
- Imagem Docker
CaixaML

MLBox é uma poderosa biblioteca python de aprendizado de máquina automatizado. De acordo com a documentação oficial, oferece os seguintes recursos:
- Leitura rápida e pré-processamento / limpeza / formatação de dados distribuídos
- Seleção de recursos altamente robustos e detecção de vazamento, bem como otimização de hiperparâmetro precisa
- Modelos preditivos de última geração para classificação e regressão (Deep Learning, Stacking, LightGBM)
- Predição com interpretação do modelo
- MLBox foi testado no Kaggle e mostra bom desempenho
- Construção de pipeline
TPOT

TPOT é uma ferramenta de aprendizado de máquina automatizado Python que otimiza pipelines de aprendizado de máquina usando programação genética. Ele também foi desenvolvido com base no scikit-learn.

Exemplo de pipeline TPOT (de https://epistasislab.github.io/tpot/)
Documentação: Aqui está o link de documentação.
Exemplo de código:
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64), iris.target.astype(np.float64), train_size=0.75, test_size=0.25, random_state=42) tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_iris_pipeline.py')
Auto Keras
AutoKeras é uma biblioteca de software de código aberto para aprendizado de máquina automatizado desenvolvido por DATA Lab na Texas A&M University. Construído sobre a estrutura de aprendizado profundo Keras, AutoKeras fornece funções para pesquisar automaticamente a arquitetura e hiperparâmetros de modelos de aprendizado profundo.
O AutoKeras segue o design clássico da API do scikit-learn e, portanto, é fácil de usar. O objetivo desta estrutura é simplificar a prática e a pesquisa de ML usando Pesquisa de arquitetura neural (NAS) algoritmos.
Documentação: Aqui está o detalhado link de documentação.
Exemplo de código: Aqui está um exemplo de código de amostra para a tarefa de classificação de imagens MNIST.
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import autokeras as ak # Data loading
(x_train, y_train), (x_test, y_test) = mnist.load_data() # Initialize the image classifier.
clf = ak.ImageClassifier(overwrite=True, max_trials=1)
# Feed the image classifier with training data.
clf.fit(x_train, y_train, epochs=10) # Predict with the best model.
predicted_y = clf.predict(x_test)
print(predicted_y) # Evaluate the best model with testing data.
print(clf.evaluate(x_test, y_test))Resumo dos sistemas AutoML e sua importância
Neste artigo, começamos explicando a ideia central por trás das estruturas de ML automatizadas ou os chamados sistemas AutoML. Descrevemos sua utilidade e por que estão ganhando força em várias empresas e organizações de tecnologia. Também apresentamos algumas bibliotecas e estruturas de AutoML proeminentes com exemplos de código relevantes e ilustrações de arquitetura, conforme aplicável.
Aprender sobre essas estruturas poderosas será benéfico para qualquer cientista de dados futuro, pois eles continuarão a crescer em recursos e uso generalizado.
Deixe-nos saber sobre qualquer tópico de seu interesse deixando um comentário abaixo ou sinta-se à vontade para Contacte-nos a qualquer momento com perguntas que você tem.
Bio: Kevin Vu gerencia o blog da Exxact Corp e trabalha com muitos de seus talentosos autores que escrevem sobre diferentes aspectos do Deep Learning.
Óptimo estado. Original. Republicado com permissão.
Relacionado:
| Histórias principais nos últimos 30 dias | |||
|---|---|---|---|
|
|||
Fonte: https://www.kdnuggets.com/2021/09/introduction-automated-machine-learning.html
- "
- &
- 9
- absoluto
- atividades
- Adicional
- Adoção
- AI
- algoritmo
- algoritmos
- Todos os Produtos
- entre
- análise
- api
- Aplicação
- aplicações
- Aplicativos
- arquitetura
- Arte
- artigo
- inteligência artificial
- Inteligência artificial (AI)
- autores
- auto
- Automatizado
- aprendizado de máquina automatizado
- automotivo
- MELHOR
- Blog
- construir
- Prédio
- negócio
- classificação
- código
- Codificação
- vinda
- comum
- componente
- continuar
- Corp
- dados,
- ciência de dados
- cientista de dados
- deep learning
- Design
- Detecção
- desenvolver
- desenvolvedores
- digital
- dígitos
- domínios
- colaboradores
- engenheiro
- Engenharia
- Engenheiros
- Entretenimento
- Excel
- expansão
- vasta experiência
- exploração
- Característica
- Funcionalidades
- Figura
- financiar
- Primeiro nome
- Foco
- seguir
- para a frente
- Quadro
- Gratuito
- Geral
- GitHub
- Global
- Bom estado, com sinais de uso
- Cresça:
- saúde
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTTPS
- idéia
- identificar
- imagem
- Incluindo
- indústrias
- Inteligência
- IT
- keras
- grande
- vazar
- aprendizagem
- Biblioteca
- Limitado
- aprendizado de máquina
- mercado
- Métrica
- Microsoft
- ML
- Algoritmos de ML
- modelo
- mover
- redes
- Neural
- redes neurais
- oficial
- Operações
- ordem
- Outros
- atuação
- fotografia
- Ponto de vista
- Popular
- POSTAGENS
- Diretor
- Produzido
- Produção
- Programação
- projeto
- Python
- R & D
- RE
- Leitura
- regressão
- pesquisa
- recurso
- Resultados
- varejo
- Execute
- Ciência
- CIÊNCIAS
- cientistas
- Pesquisar
- Serviços
- conjunto
- concha
- Baixo
- Habilidades
- Software
- Soluções
- velocidade
- Spin
- começado
- Status
- Histórias
- .
- sistemas
- Target
- Tecnologia
- fluxo tensor
- ensaio
- texas
- tempo
- topo
- Temas
- Training
- us
- utilidade
- Ver
- web
- QUEM
- Windows
- Atividades:
- de gestão de documentos
- Força de trabalho
- trabalho
- X