Com o Amazon EMR 6.15, lançamos Formação AWS Lake controles de acesso refinados (FGAC) baseados em Open Table Formats (OTFs), incluindo Apache Hudi, Apache Iceberg e Delta lake. Isso permite simplificar a segurança e a governança lagos de dados transacionais fornecendo controles de acesso em permissões em nível de tabela, coluna e linha com seus trabalhos do Apache Spark. Muitas grandes empresas procuram usar seu data lake transacional para obter insights e melhorar a tomada de decisões. Você pode construir uma arquitetura de casa no lago usando o Amazon EMR integrado ao Lake Formation para FGAC. Essa combinação de serviços permite realizar análises de dados em seu data lake transacional, garantindo acesso seguro e controlado.
O componente do servidor de registros do Amazon EMR oferece suporte à funcionalidade de filtragem de dados em nível de tabela, coluna, linha, célula e atributos aninhados. Ele estende o suporte aos formatos Hive, Apache Hudi, Apache Iceberg e Delta lake para leitura (incluindo viagem no tempo e consulta incremental) e operações de gravação (em instruções DML como INSERT). Além disso, com a versão 6.15, o Amazon EMR introduz proteção de controle de acesso para a interface web de seu aplicativo, como Spark History Server no cluster, Yarn Timeline Server e Yarn Resource Manager UI.
Neste post, demonstramos como implementar o FGAC em Apache Hudi tabelas usando o Amazon EMR integrado ao Lake Formation.
Caso de uso de data lake de transação
Os clientes do Amazon EMR costumam usar formatos de tabela abertos para oferecer suporte às suas transações ACID e às necessidades de viagem no tempo em um data lake. Ao preservar versões históricas, a viagem no tempo do data lake oferece benefícios como auditoria e conformidade, recuperação e reversão de dados, análise reproduzível e exploração de dados em diferentes momentos.
Outro caso de uso popular de data lake de transação é a consulta incremental. A consulta incremental refere-se a uma estratégia de consulta que se concentra no processamento e análise apenas dos dados novos ou atualizados em um data lake desde a última consulta. A ideia principal por trás das consultas incrementais é usar metadados ou mecanismos de controle de alterações para identificar os dados novos ou modificados desde a última consulta. Ao identificar essas alterações, o mecanismo de consulta pode otimizar a consulta para processar apenas os dados relevantes, reduzindo significativamente o tempo de processamento e os requisitos de recursos.
Visão geral da solução
Nesta postagem, demonstramos como implementar FGAC em tabelas Apache Hudi usando Amazon EMR em Amazon Elastic Compute Nuvem (Amazon EC2) integrado ao Lake Formation. Apache Hudi é uma estrutura de data lake transacional de código aberto que simplifica muito o processamento incremental de dados e o desenvolvimento de pipelines de dados. Este novo recurso FGAC oferece suporte a todos os OTF. Além de demonstrar com o Hudi aqui, acompanharemos outras tabelas OTF em outros blogs. Nós usamos laptops in Estúdio Amazon SageMaker para ler e gravar dados Hudi por meio de diferentes permissões de acesso de usuário por meio de um cluster EMR. Isso reflete cenários reais de acesso a dados – por exemplo, se um usuário de engenharia precisar de acesso total aos dados para solucionar problemas em uma plataforma de dados, enquanto os analistas de dados podem precisar acessar apenas um subconjunto desses dados que não contém informações de identificação pessoal (PII). ). Integrando com Lake Formation através do Função de tempo de execução do Amazon EMR permite ainda melhorar sua postura de segurança de dados e simplifica o gerenciamento de controle de dados para cargas de trabalho do Amazon EMR. Esta solução garante um ambiente seguro e controlado para acesso aos dados, atendendo às diversas necessidades e requisitos de segurança dos diferentes usuários e funções de uma organização.
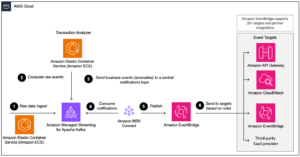
O diagrama a seguir ilustra a arquitetura da solução.
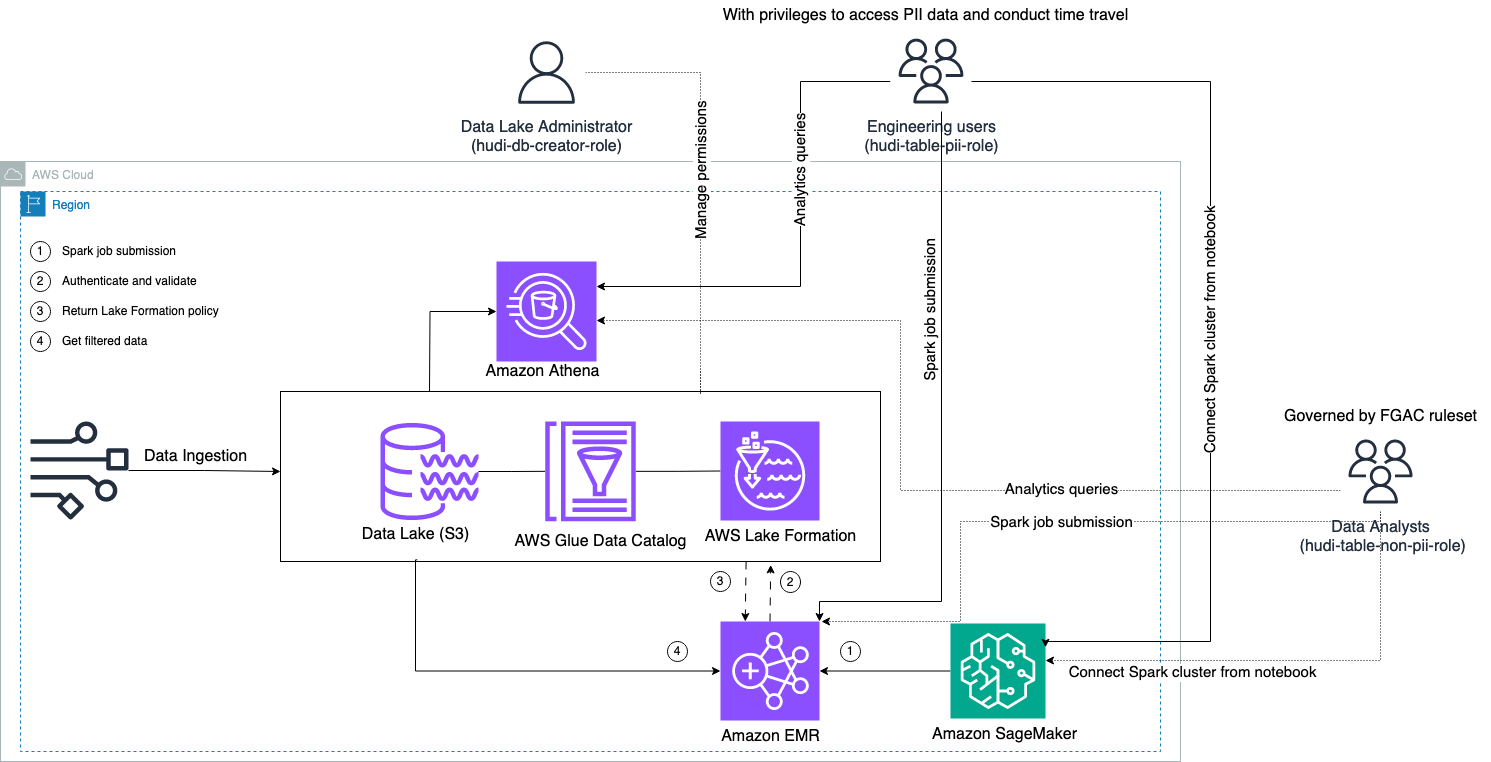
Conduzimos um processo de ingestão de dados para atualizar (atualizar e inserir) um conjunto de dados Hudi para um Serviço de armazenamento simples da Amazon (Amazon S3) e persistir ou atualizar o esquema da tabela no Cola AWS Catálogo de dados. Sem movimentação de dados, podemos consultar a tabela Hudi governada pelo Lake Formation por meio de vários serviços AWS, como Amazona atena, Amazon EMR e Amazon Sage Maker.
Quando os usuários enviam um trabalho Spark por meio de qualquer endpoint de cluster EMR (EMR Steps, Livy, EMR Studio e SageMaker), o Lake Formation valida seus privilégios e instrui o cluster EMR a filtrar dados confidenciais, como dados PII.
Esta solução possui três tipos diferentes de usuários com diferentes níveis de permissões para acessar os dados do Hudi:
- função de criador de hudi-db – Isso é usado pelo administrador do data lake que tem privilégios para realizar operações DDL, como criar, modificar e excluir objetos de banco de dados. Eles podem definir regras de filtragem de dados no Lake Formation para controle de acesso a dados em nível de linha e coluna. Estas regras do FGAC garantem que o data lake esteja protegido e cumpra os regulamentos de privacidade de dados exigidos.
- hudi-table-pii-role – Isso é usado por usuários de engenharia. Os usuários de engenharia são capazes de realizar viagens no tempo e consultas incrementais tanto em Copy-on-Write (CoW) quanto em Merge-on-Read (MoR). Eles também têm privilégio de acessar dados PII com base em qualquer carimbo de data/hora.
- hudi-tabela-não-pii-role – Isso é usado por analistas de dados. Os direitos de acesso aos dados dos analistas de dados são regidos pelas regras autorizadas pelo FGAC, controladas pelos administradores do data lake. Eles não têm visibilidade em colunas que contêm dados PII, como nomes e endereços. Além disso, eles não podem acessar linhas de dados que não atendam a determinadas condições. Por exemplo, os usuários só podem acessar linhas de dados que pertencem ao seu país.
Pré-requisitos
Você pode baixar os três cadernos usados nesta postagem no site GitHub repo.
Antes de implantar a solução, certifique-se de ter o seguinte:
Conclua as etapas a seguir para configurar suas permissões:
- Faça login em sua conta da AWS com seu usuário administrador do IAM.
Certifique-se de que você está nous-east-1Região.
- Crie um bucket S3 no
us-east-1Região (por exemplo,emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
A seguir, habilitamos Lake Formation por alterando o modelo de permissão padrão.
- Faça login no console do Lake Formation como usuário administrador.
- Escolha Configurações do catálogo de dados para Áreas de Suporte no painel de navegação.
- Debaixo Permissões padrão para bancos de dados e tabelas recém-criados, desmarque Use apenas controle de acesso IAM para novos bancos de dados e Use apenas controle de acesso IAM para novas tabelas em novos bancos de dados.
- Escolha Salvar.
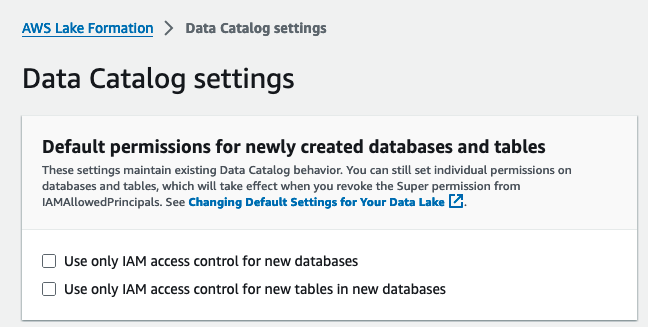
Como alternativa, você precisa revogar IAMAllowedPrincipals em recursos (bancos de dados e tabelas) criados se você iniciou o Lake Formation com a opção padrão.
Por fim, criamos um par de chaves para o Amazon EMR.
- No console do Amazon EC2, escolha Pares de chaves no painel de navegação.
- Escolha Criar par de chaves.
- Escolha Nome, insira um nome (por exemplo
emr-fgac-hudi-keypair). - Escolha Criar par de chaves.
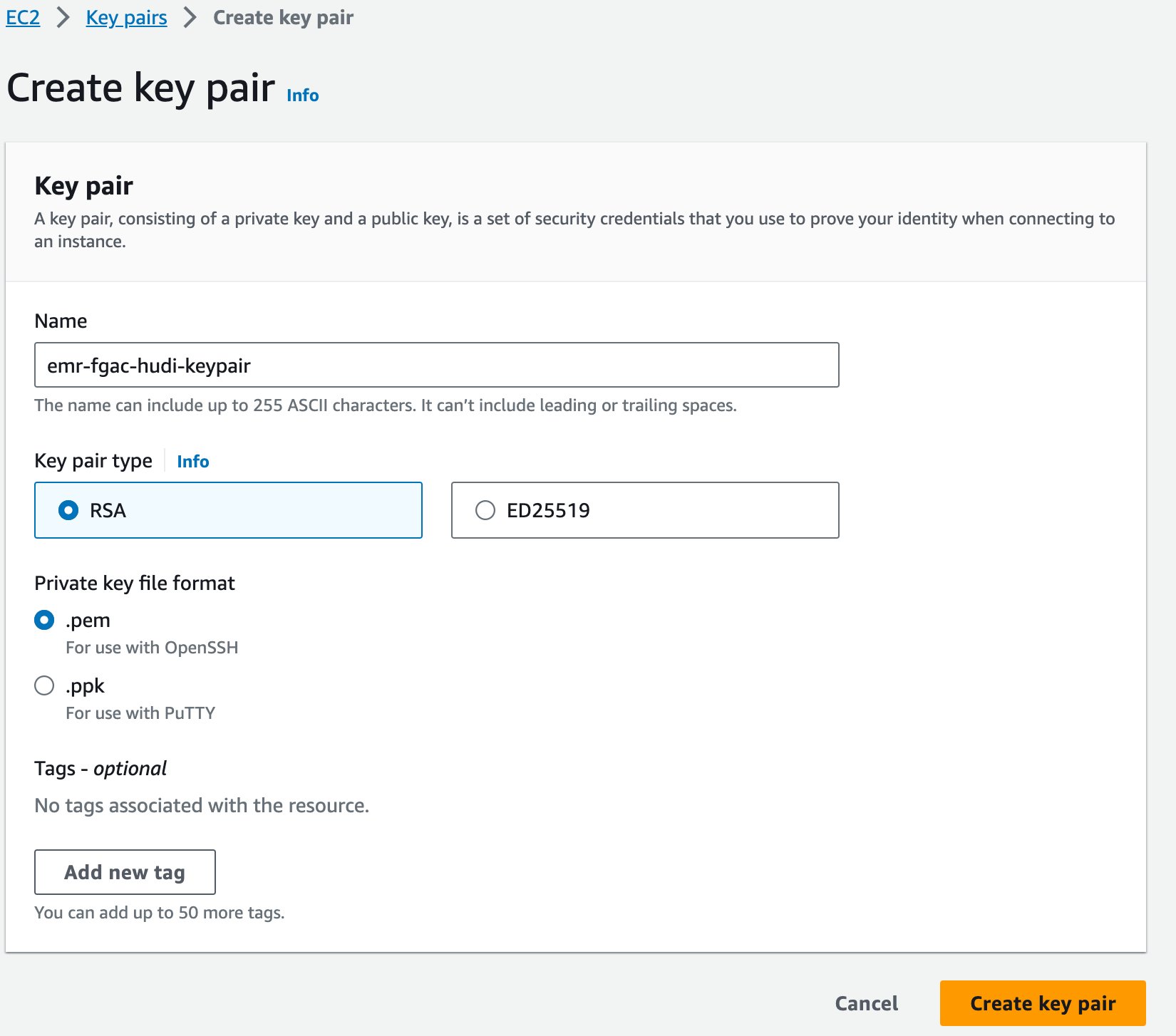
O par de chaves gerado (para esta postagem, emr-fgac-hudi-keypair.pem) será salvo em seu computador local.
A seguir, criamos um Nuvem AWS9 ambiente de desenvolvimento interativo (IDE).
- No console AWS Cloud9, escolha Ambientes no painel de navegação.
- Escolha Criar ambiente.
- Escolha Nome¸ insira um nome (por exemplo,
emr-fgac-hudi-env). - Mantenha as outras configurações como padrão.
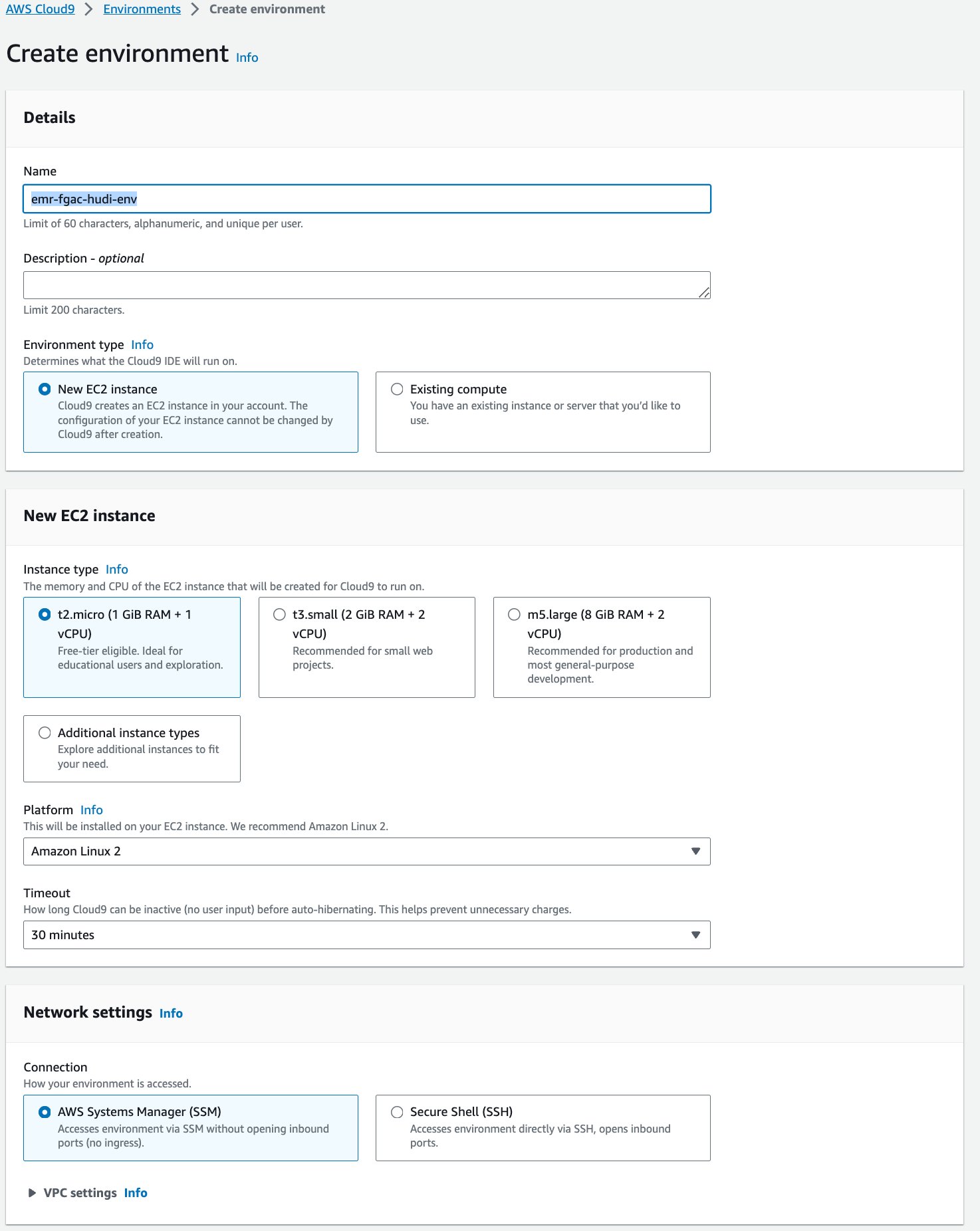
- Escolha Crie.
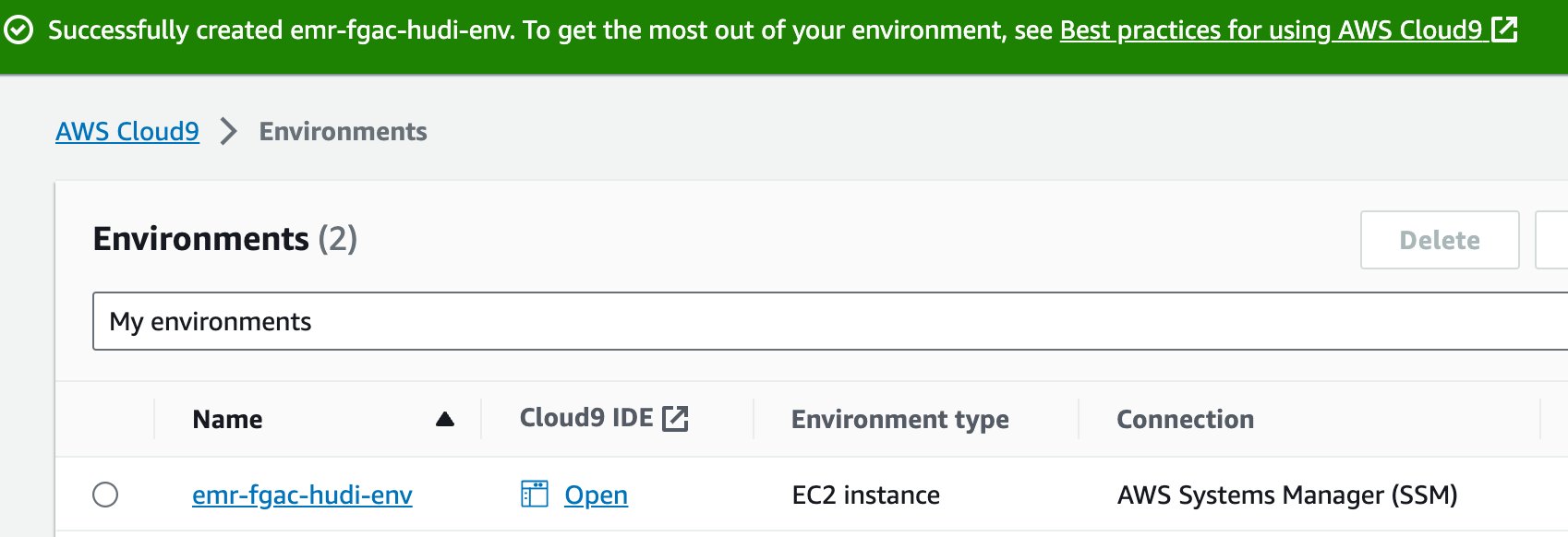
- Quando o IDE estiver pronto, escolha Abra para abri-lo.
- No IDE do AWS Cloud9, na página Envie o menu, escolha Carregar arquivos locais.

- Carregue o arquivo do par de chaves (
emr-fgac-hudi-keypair.pem). - Escolha o sinal de mais e escolha Novo Terminal.
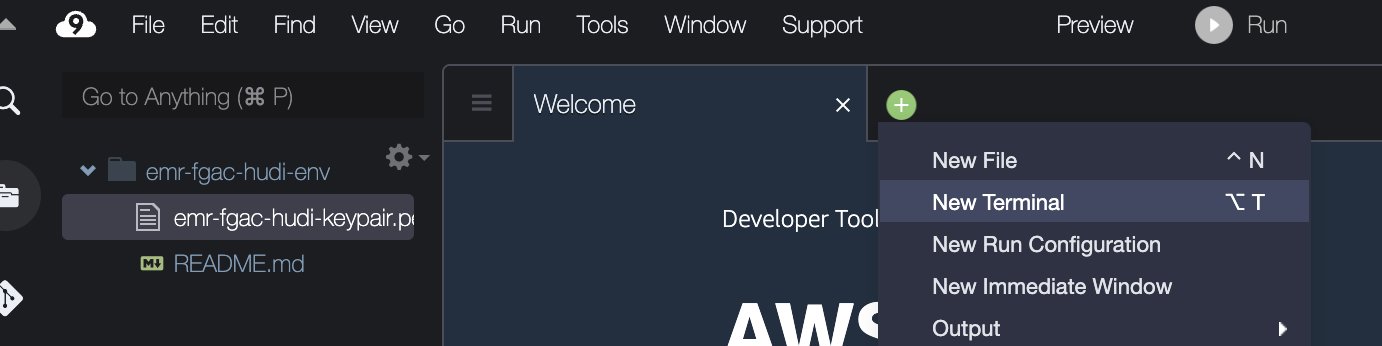
- No terminal, insira as seguintes linhas de comando:
Observe que o código de exemplo é uma prova de conceito apenas para fins de demonstração. Para sistemas de produção, use uma autoridade de certificação (CA) confiável para emitir certificados. Referir-se Fornecimento de certificados para criptografia de dados em trânsito com criptografia do Amazon EMR para obter detalhes.
Implante a solução por meio do AWS CloudFormation
Nós fornecemos um Formação da Nuvem AWS modelo que configura automaticamente os seguintes serviços e componentes:
- Um bucket S3 para o data lake. Ele contém o conjunto de dados TPC-DS de amostra.
- Um cluster EMR com configuração de segurança e DNS público habilitado.
- Funções IAM do tempo de execução do EMR com permissões refinadas do Lake Formation:
- -hudi-db-creator-role – Esta função é usada para criar bancos de dados e tabelas Apache Hudi.
- -hudi-table-pii-role – Esta função fornece permissão para consultar todas as colunas das tabelas Hudi, incluindo colunas com PII.
- -hudi-table-non-pii-role – Esta função fornece permissão para consultar tabelas Hudi que filtraram colunas PII por Lake Formation.
- Funções de execução do SageMaker Studio que permitem aos usuários assumir suas funções de tempo de execução EMR correspondentes.
- Recursos de rede, como VPC, sub-redes e grupos de segurança.
Conclua as etapas a seguir para implementar os recursos:
- Escolha Pilha de criação rápida para iniciar a pilha do CloudFormation.
- Escolha Nome da pilha, insira um nome de pilha (por exemplo,
rsv2-emr-hudi-blog). - Escolha Ec2KeyPair, insira o nome do seu par de chaves.
- Escolha IdleTimeout, insira um tempo limite de inatividade para o cluster do EMR para evitar pagar pelo cluster quando ele não estiver sendo usado.
- Escolha InitS3Bucket, insira o nome do bucket S3 que você criou para salvar o arquivo .zip do certificado de criptografia do Amazon EMR.
- Escolha S3CertsZip, insira o URI do S3 do arquivo .zip do certificado de criptografia do Amazon EMR.
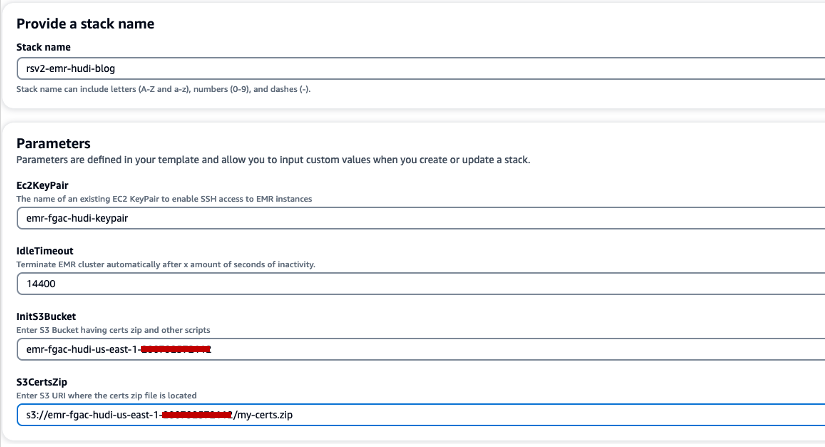
- Selecionar Eu reconheço que o AWS CloudFormation pode criar recursos IAM com nomes personalizados.
- Escolha Criar pilha.
A implantação da pilha CloudFormation leva cerca de 10 minutos.
Configurar o Lake Formation para integração do Amazon EMR
Conclua as etapas a seguir para configurar o Lake Formation:
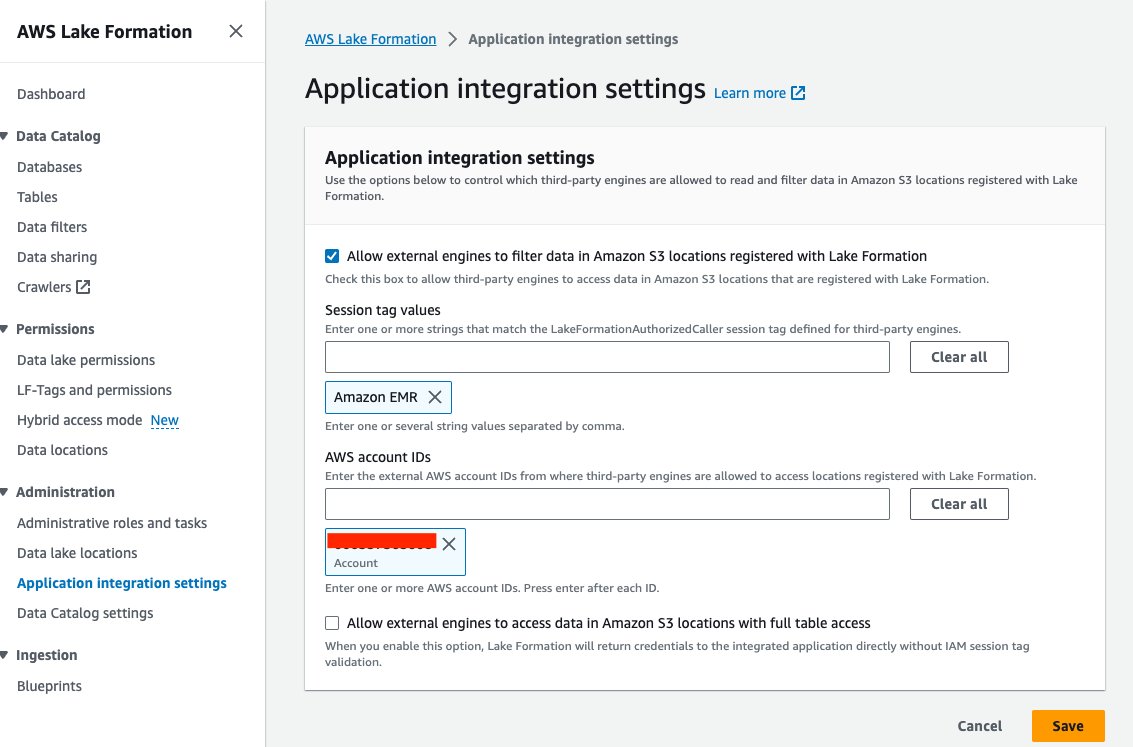
- No console do Lake Formation, escolha Configurações de integração de aplicativos para Áreas de Suporte no painel de navegação.
- Selecionar Permitir que mecanismos externos filtrem dados em locais do Amazon S3 registrados no Lake Formation.
- Escolha Amazon EMR para Valores de tag de sessão.
- Insira o ID da sua conta AWS para IDs de conta da AWS.
- Escolha Salvar.
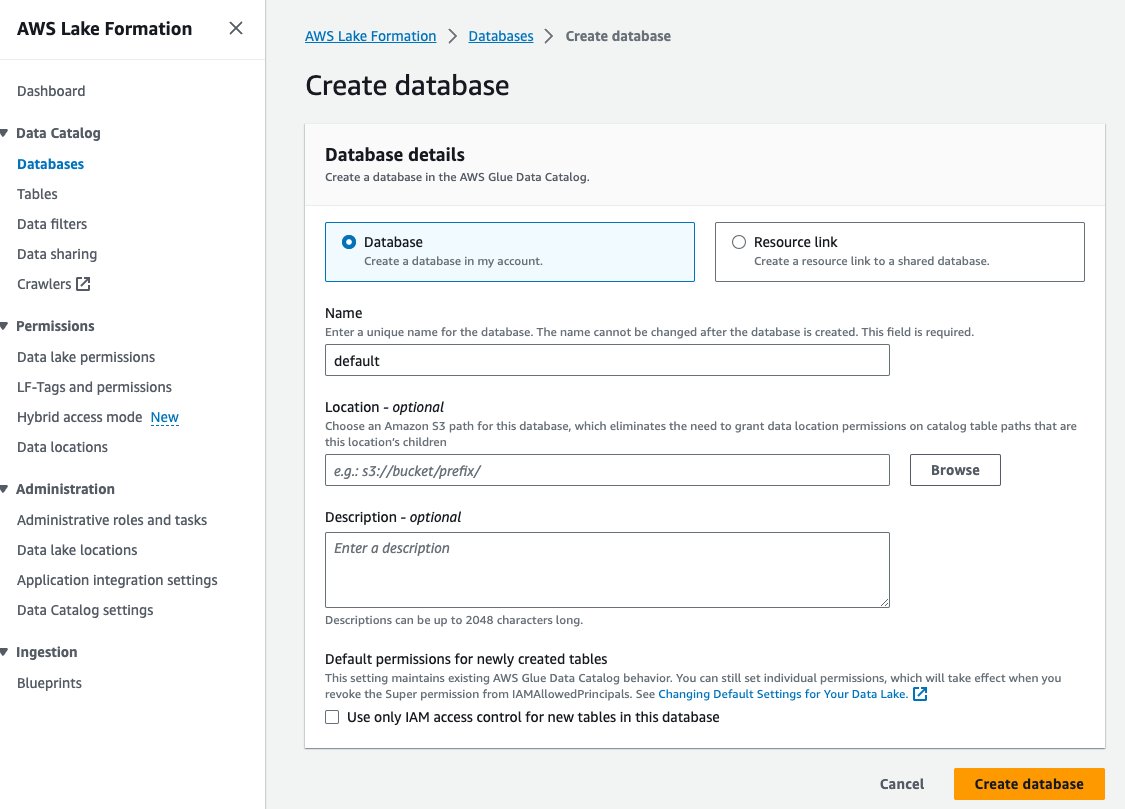
- Escolha Bases de dados para Catálogo de Dados no painel de navegação.
- Escolha Criar banco de dados.
- Escolha Nome, insira o padrão.
- Escolha Criar banco de dados.
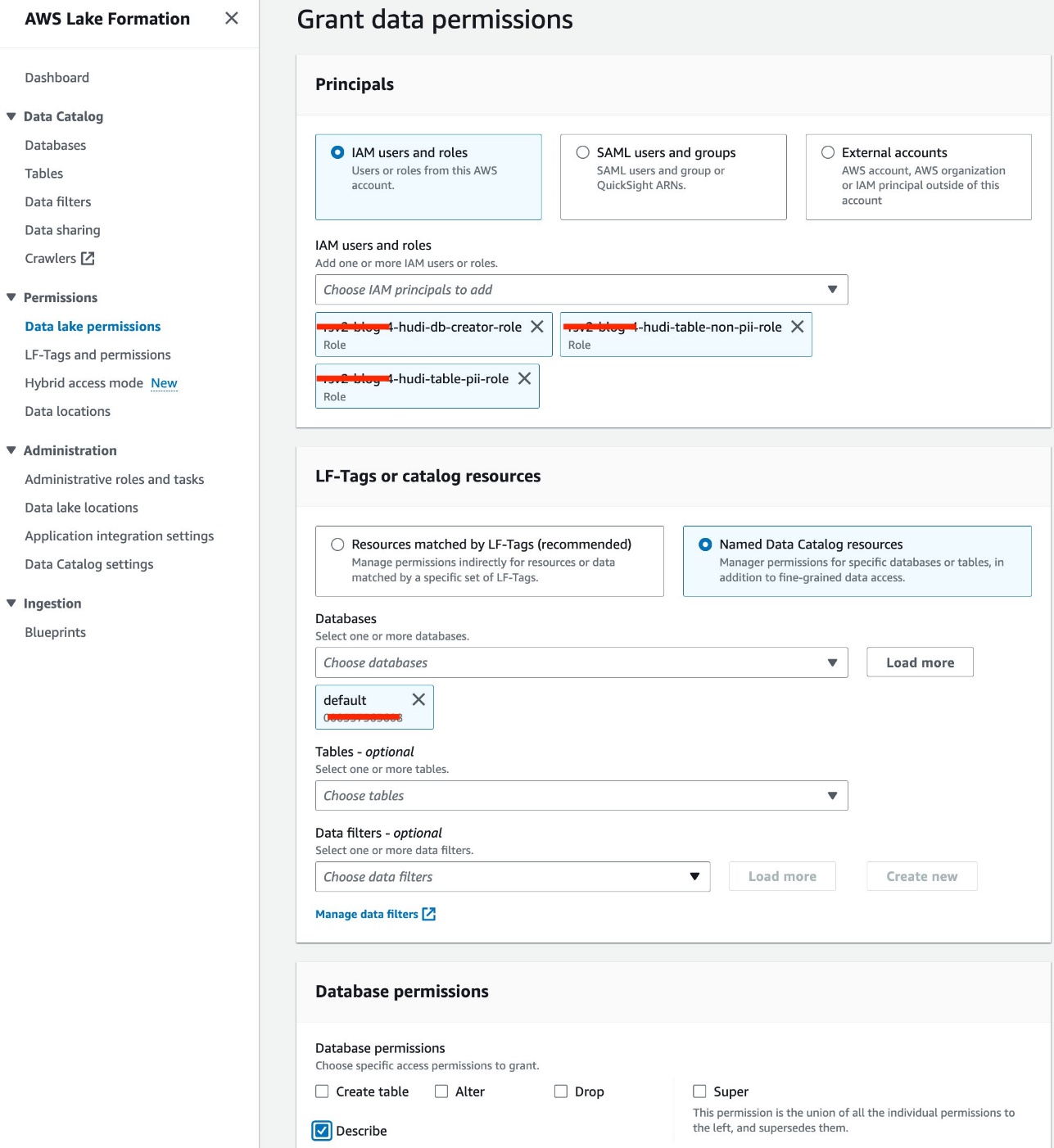
- Escolha Permissões do data lake para Permissões no painel de navegação.
- Escolha Conceda.
- Selecionar Usuários e funções IAM.
- Escolha suas funções do IAM.
- Escolha Bases de dados, escolha o padrão.
- Escolha Permissões de banco de dados, selecione Descrever.
- Escolha Conceda.
Copie o arquivo JAR do Hudi para o Amazon EMR HDFS
Para use Hudi com notebooks Jupyter, será necessário concluir as etapas a seguir para o cluster do EMR, que incluem a cópia de um arquivo JAR do Hudi do diretório local do Amazon EMR para seu armazenamento HDFS, para que você possa configurar uma sessão do Spark para usar o Hudi:
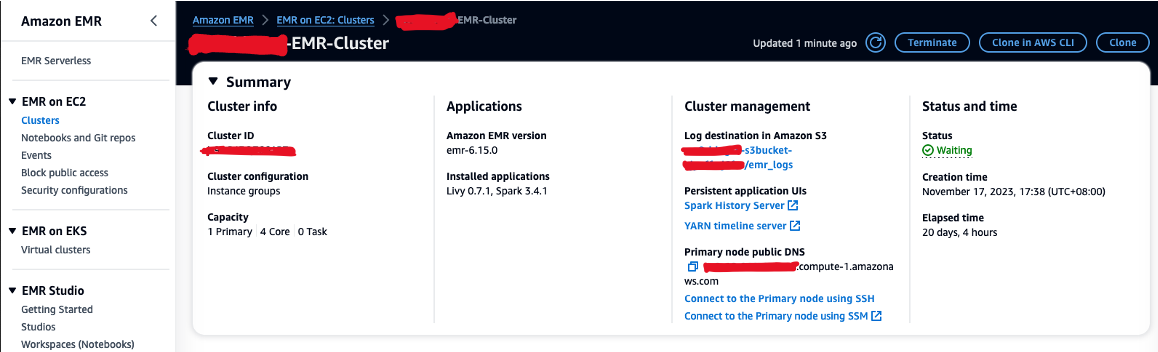
- Autorizar tráfego SSH de entrada (porta 22).
- Copie o valor para DNS público do nó primário (por exemplo, ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) do cluster EMR Resumo seção.
- Volte para o terminal AWS Cloud9 anterior que você usou para criar o par de chaves EC2.
- Execute o seguinte comando para SSH no nó primário do EMR. Substitua o espaço reservado pelo nome de host DNS do EMR:
- Execute o seguinte comando para copiar o arquivo Hudi JAR para HDFS:
Crie o banco de dados e as tabelas Hudi no Lake Formation
Agora estamos prontos para criar o banco de dados e tabelas Hudi com FGAC habilitado pela função de tempo de execução EMR. O Função de tempo de execução do EMR é uma função do IAM que você pode especificar ao enviar um trabalho ou consulta a um cluster do EMR.
Conceder permissão ao criador do banco de dados
Primeiro, vamos conceder ao criador do banco de dados Lake Formation permissão para<STACK-NAME>-hudi-db-creator-role:
- Faça login em sua conta AWS como administrador.
- No console do Lake Formation, escolha Funções e tarefas administrativas para Áreas de Suporte no painel de navegação.
- Confirme se seu usuário de login da AWS foi adicionado como administrador do data lake.
- No Criador de banco de dados seção, escolha Conceda.
- Escolha Usuários e funções IAM, escolha
<STACK-NAME>-hudi-db-creator-role. - Escolha Permissões de catálogo, selecione Criar banco de dados.
- Escolha Conceda.
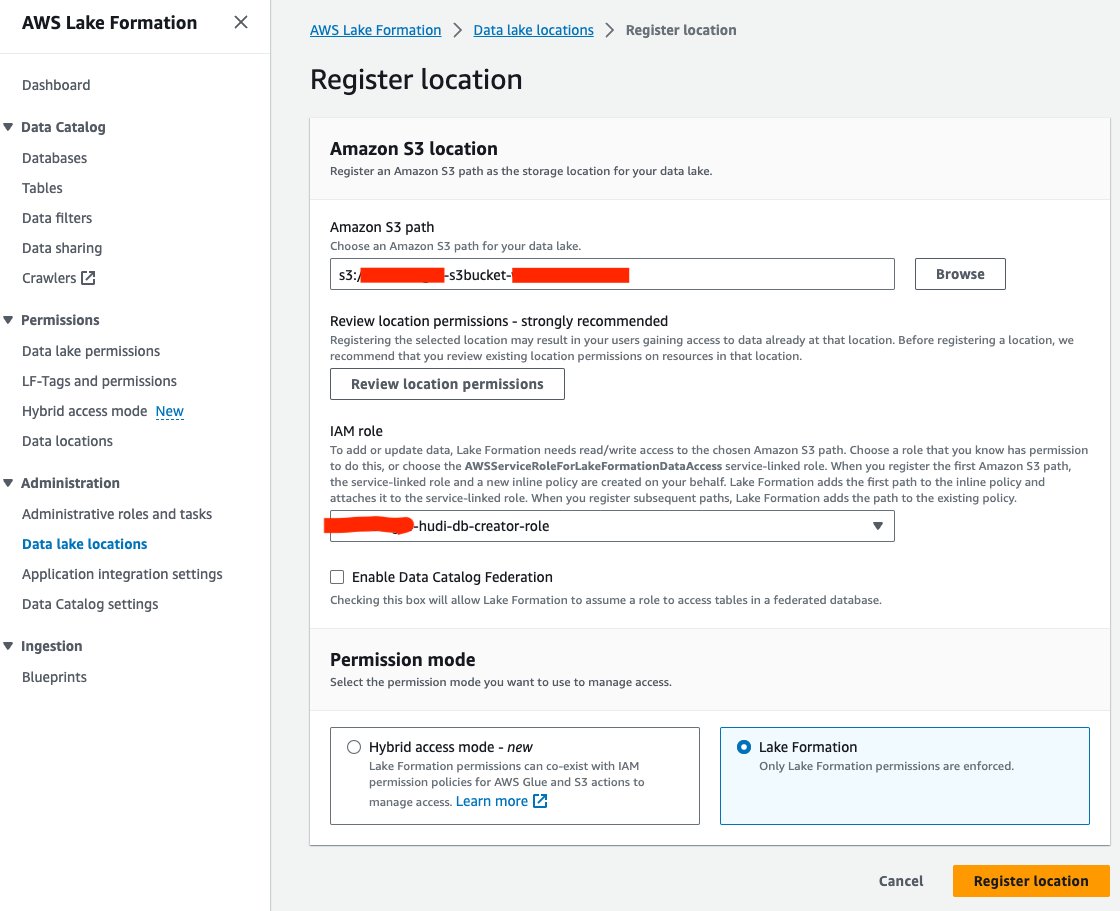
Registre o local do data lake
A seguir, vamos registrar a localização do data lake S3 no Lake Formation:
- No console do Lake Formation, escolha Localizações de data lake para Áreas de Suporte no painel de navegação.
- Escolha Registrar localização.
- Escolha Caminho Amazon S3Escolher Procurar e escolha o bucket S3 do data lake. (
<STACK_NAME>s3bucket-XXXXXXX) criado a partir da pilha do CloudFormation. - Escolha Papel do IAM, escolha
<STACK-NAME>-hudi-db-creator-role. - Escolha Modo de permissão, selecione Formação de Lago.
- Escolha Registrar localização.
Conceder permissão de localização de dados
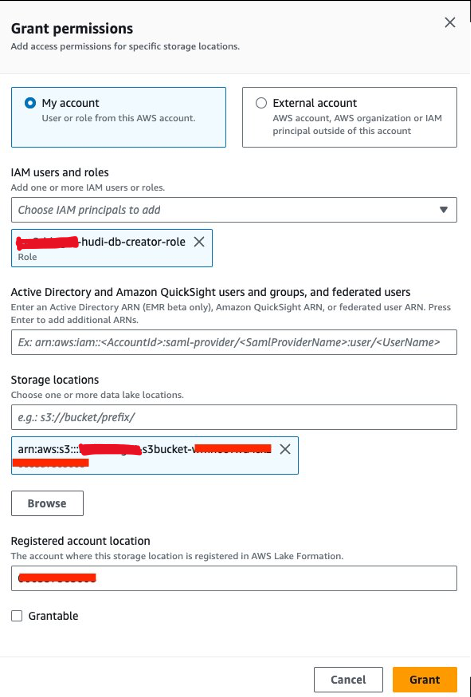
Em seguida, precisamos conceder<STACK-NAME>-hudi-db-creator-rolea permissão de localização de dados:
- No console do Lake Formation, escolha Localizações de dados para Permissões no painel de navegação.
- Escolha Conceda.
- Escolha Usuários e funções IAM, escolha
<STACK-NAME>-hudi-db-creator-role. - Escolha Locais de armazenamento, insira o intervalo S3 (
<STACK_NAME>-s3bucket-XXXXXXX). - Escolha Conceda.
Conecte-se ao cluster EMR
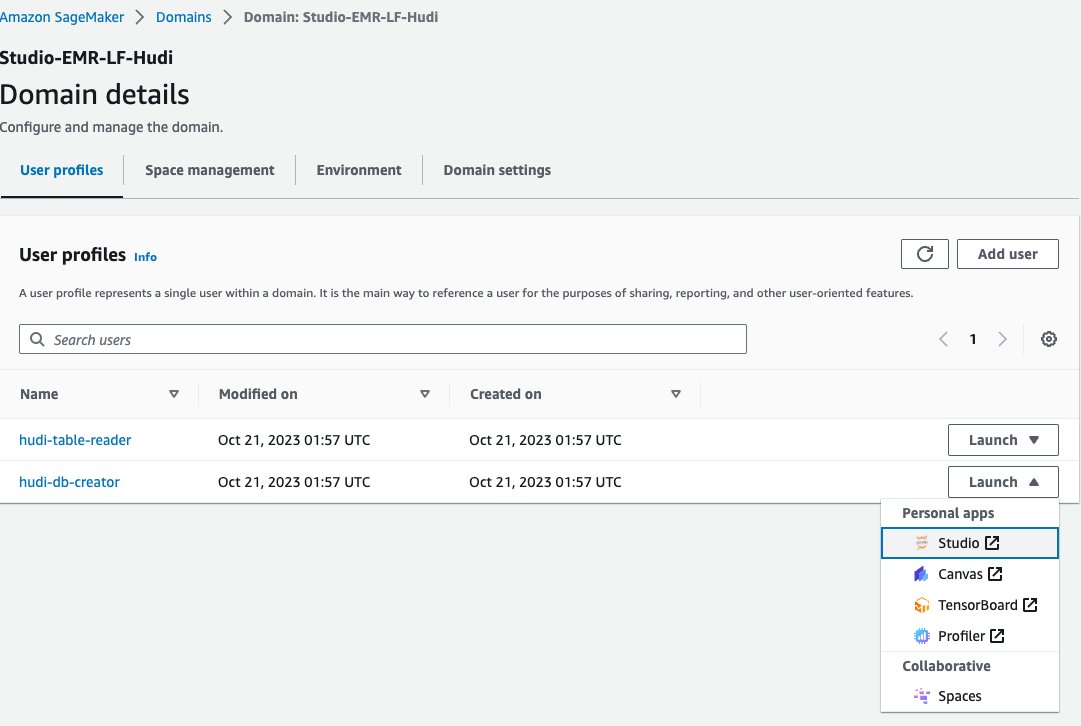
Agora, vamos usar um notebook Jupyter no SageMaker Studio para conectar-se ao cluster EMR com a função de tempo de execução EMR do criador do banco de dados:
- No console SageMaker, escolha domínios no painel de navegação.
- Escolha o domínio
<STACK-NAME>-Studio-EMR-LF-Hudi. - No Apresentação livro menu ao lado do perfil do usuário
<STACK-NAME>-hudi-db-creator, escolha Studio.
- Baixe o caderno rsv2-hudi-db-creator-notebook.
- Escolha o ícone de upload.
- Escolha o notebook Jupyter baixado e escolha Abra.
- Abra o bloco de notas carregado.
- Escolha Imagem, escolha SparkMagicGenericName.
- Escolha Núcleo, escolha PySparkGenericName.
- Deixe as outras configurações como padrão e escolha Selecionar.
- Escolha Agrupar para se conectar ao cluster EMR.

- Escolha o EMR no cluster EC2 (
<STACK-NAME>-EMR-Cluster) criado com a pilha CloudFormation. - Escolha Contato.
- Escolha Função de execução do EMR, escolha
<STACK-NAME>-hudi-db-creator-role. - Escolha Contato.
Criar banco de dados e tabelas
Agora você pode seguir as etapas do notebook para criar o banco de dados e as tabelas Hudi. As principais etapas são as seguintes:
- Ao iniciar o notebook, configure
“spark.sql.catalog.spark_catalog.lf.managed":"true"para informar ao Spark que spark_catalog é protegido pelo Lake Formation. - Crie tabelas Hudi usando o Spark SQL a seguir.
- Insira dados da tabela de origem nas tabelas Hudi.
- Insira os dados novamente nas tabelas Hudi.
Consulte as tabelas Hudi via Lake Formation com FGAC
Depois de criar o banco de dados e as tabelas Hudi, você estará pronto para consultar as tabelas usando controle de acesso refinado com Lake Formation. Criamos dois tipos de tabelas Hudi: Copy-On-Write (COW) e Merge-On-Read (MOR). A tabela COW armazena dados em formato colunar (Parquet) e cada atualização cria uma nova versão de arquivos durante uma gravação. Isso significa que, para cada atualização, o Hudi reescreve o arquivo inteiro, o que pode consumir mais recursos, mas fornece desempenho de leitura mais rápido. O MOR, por outro lado, é introduzido para casos em que o COW pode não ser ideal, especialmente para cargas de trabalho com muitas gravações ou alterações. Em uma tabela MOR, cada vez que há uma atualização, o Hudi grava apenas a linha do registro alterado, o que reduz custos e permite gravações de baixa latência. No entanto, o desempenho de leitura pode ser mais lento em comparação com as tabelas COW.
Conceder permissão de acesso à tabela
Usamos a função IAM<STACK-NAME>-hudi-table-pii-rolepara consultar Hudi COW e MOR contendo colunas PII. Primeiro concedemos permissão de acesso à tabela por meio do Lake Formation:
- No console do Lake Formation, escolha Permissões do data lake para Permissões no painel de navegação.
- Escolha Conceda.
- Escolha
<STACK-NAME>-hudi-table-pii-rolepara Usuários e funções IAM. - Escolha o
rsv2_blog_hudi_db_1banco de dados para Bases de dados. - Escolha Tabelas, escolha as quatro tabelas Hudi que você criou no notebook Jupyter.
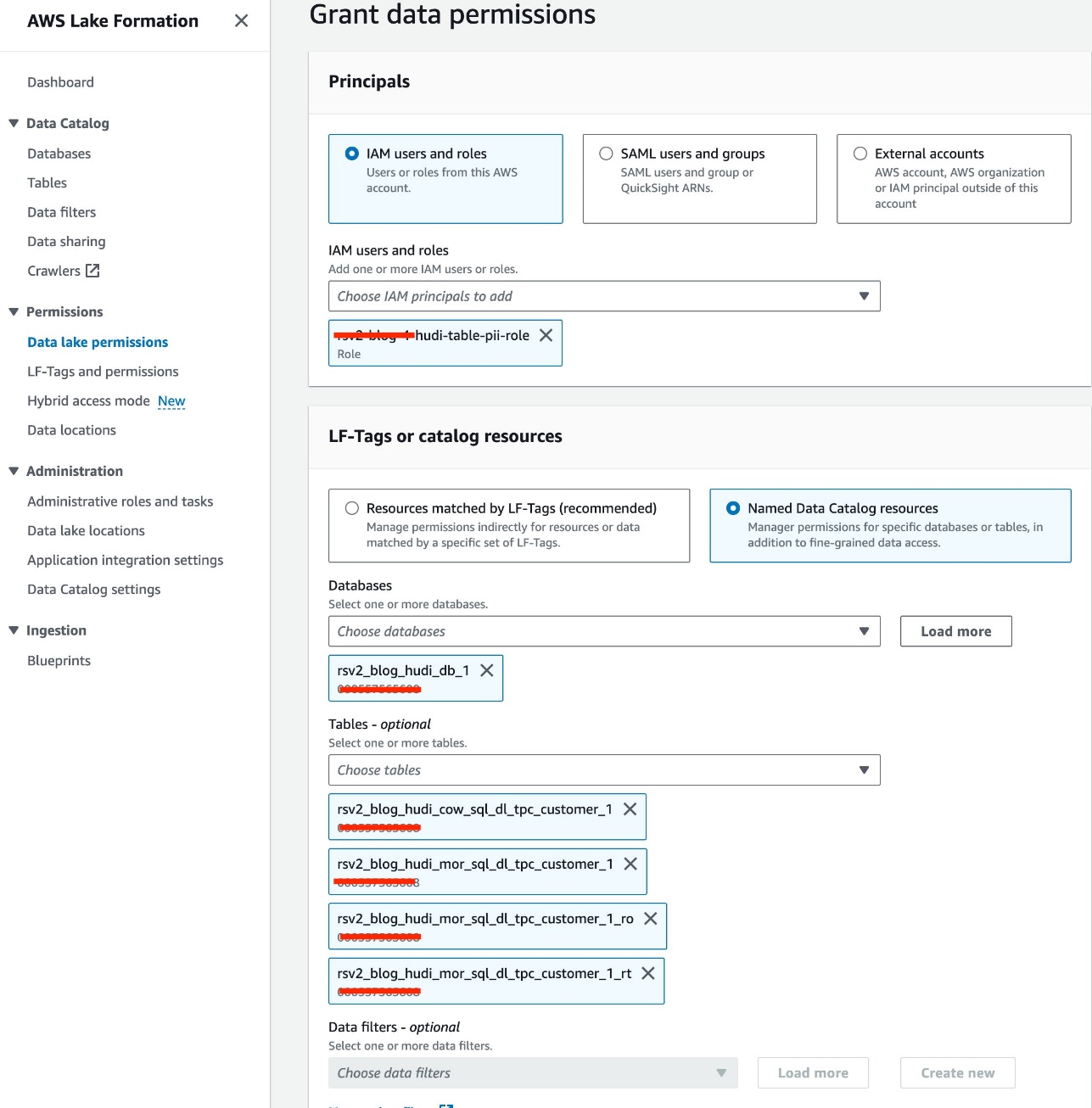
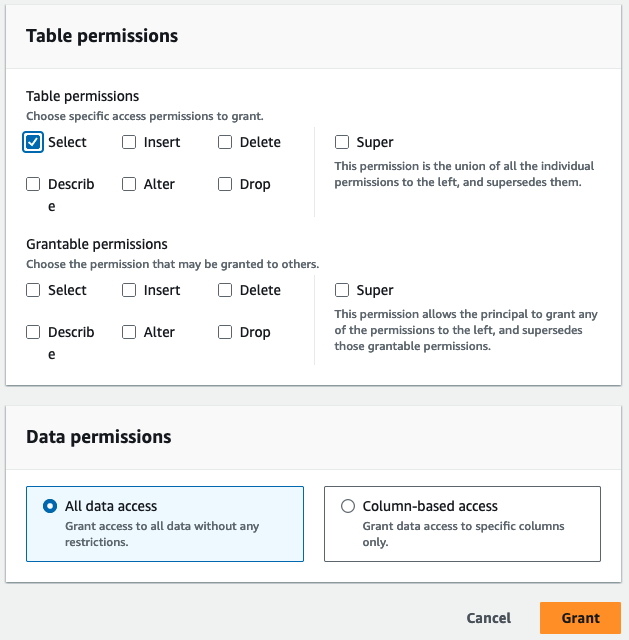
- Escolha Permissões de mesa, selecione Selecionar.
- Escolha Conceda.
Consultar colunas PII
Agora você está pronto para executar o notebook para consultar as tabelas Hudi. Vamos seguir etapas semelhantes à seção anterior para executar o notebook no SageMaker Studio:
- No console do SageMaker, navegue até o
<STACK-NAME>-Studio-EMR-LF-Hudidomínio. - No Apresentação livro menu ao lado do
<STACK-NAME>-hudi-table-readerperfil de usuário, escolha Studio. - Carregar o notebook baixado rsv2-hudi-table-pii-reader-notebook.
- Abra o bloco de notas carregado.
- Repita as etapas de configuração do notebook e conecte-se ao mesmo cluster do EMR, mas use a função
<STACK-NAME>-hudi-table-pii-role.
No estágio atual, o cluster EMR habilitado para FGAC precisa consultar a coluna de tempo de commit do Hudi para realizar consultas incrementais e viagens no tempo. Ele não suporta a sintaxe “timestamp as of” do Spark e Spark.read(). Estamos trabalhando ativamente para incorporar suporte para ambas as ações em versões futuras do Amazon EMR com FGAC habilitado.
Agora você pode seguir as etapas no notebook. A seguir estão algumas etapas destacadas:
- Execute uma consulta de instantâneo.
- Execute uma consulta incremental.
- Execute uma consulta de viagem no tempo.
- Execute consultas de tabela MOR otimizadas para leitura e em tempo real.
Consulte as tabelas Hudi com filtros de dados em nível de coluna e em nível de linha
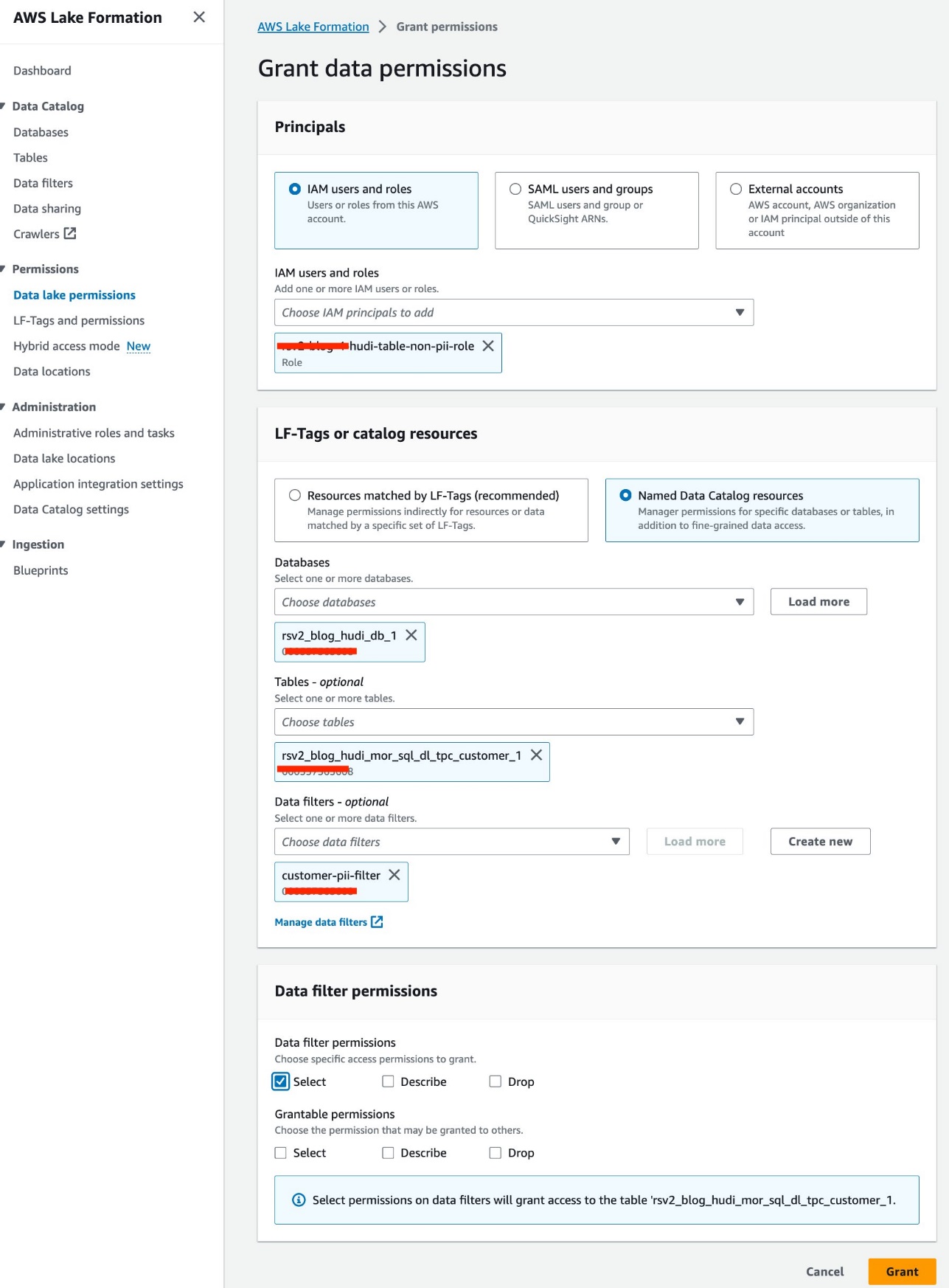
Usamos a função IAM<STACK-NAME>-hudi-table-non-pii-rolepara consultar tabelas Hudi. Esta função não tem permissão para consultar colunas que contenham PII. Usamos os filtros de dados em nível de coluna e linha do Lake Formation para implementar controle de acesso refinado:
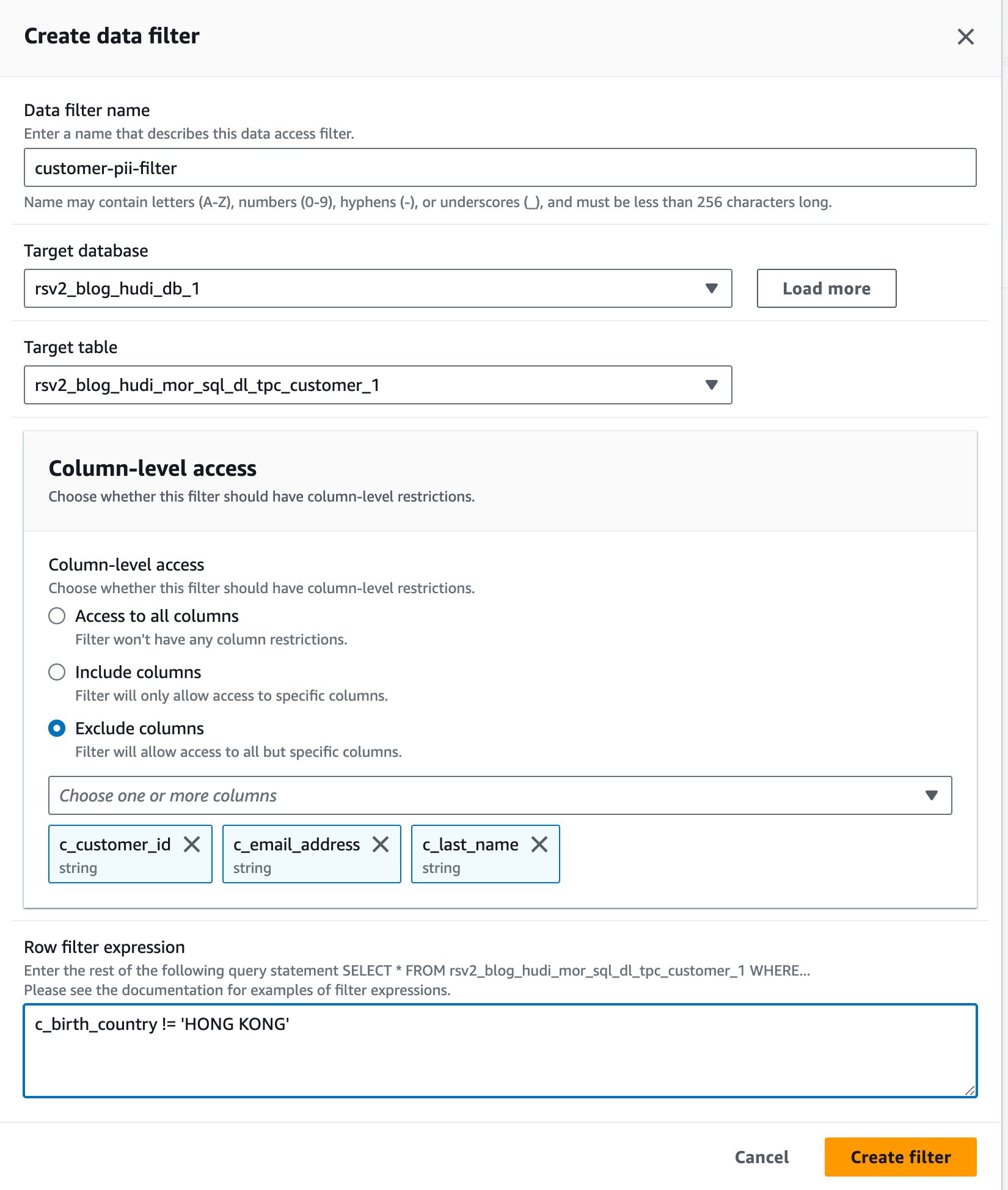
- No console do Lake Formation, escolha Filtros de dados para Catálogo de Dados no painel de navegação.
- Escolha Crie um novo filtro.
- Escolha Nome do filtro de dados, entrar
customer-pii-filter. - Escolha
rsv2_blog_hudi_db_1para Banco de dados de destino. - Escolha
rsv2_blog_hudi_mor_sql_dl_customer_1para Tabela de destino. - Selecionar Excluir colunas e escolha o
c_customer_id,c_email_addressec_last_namecolunas. - Entrar
c_birth_country != 'HONG KONG'para Expressão de filtro de linha. - Escolha Criar filtro.
- Escolha Permissões do data lake para Permissões no painel de navegação.
- Escolha Conceda.
- Escolha
<STACK-NAME>-hudi-table-non-pii-rolepara Usuários e funções IAM. - Escolha
rsv2_blog_hudi_db_1para Bases de dados. - Escolha
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1para Tabelas. - Escolha
customer-pii-filterpara Filtros de dados. - Escolha Permissões de filtro de dados, selecione Selecionar.
- Escolha Conceda.
Vamos seguir etapas semelhantes para executar o notebook no SageMaker Studio:
- No console do SageMaker, navegue até o domínio
Studio-EMR-LF-Hudi. - No Apresentação livro cardápio para o
hudi-table-readerperfil de usuário, escolha Studio. - Carregar o notebook baixado rsv2-hudi-table-non-pii-reader-notebook e escolha Abra.
- Repita as etapas de configuração do notebook e conecte-se ao mesmo cluster do EMR, mas selecione a função
<STACK-NAME>-hudi-table-non-pii-role.
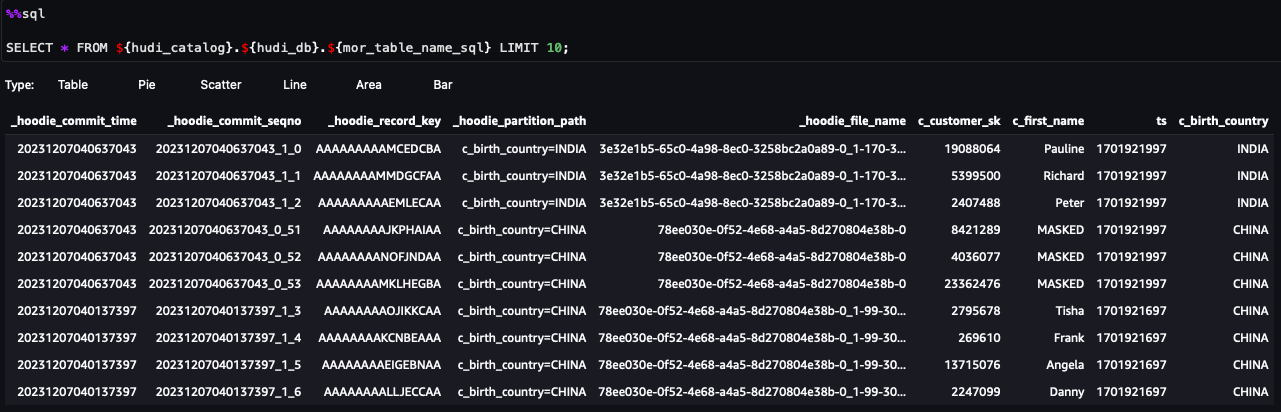
Agora você pode seguir as etapas no notebook. A partir dos resultados da consulta, você pode ver que o FGAC por meio do filtro de dados Lake Formation foi aplicado. A função não consegue ver as colunas PIIc_customer_id,c_last_name ec_email_address. Além disso, as linhas deHONG KONGforam filtrados.
limpar
Depois de experimentar a solução, recomendamos limpar os recursos com as seguintes etapas para evitar custos inesperados:
- Desligue os aplicativos SageMaker Studio para os perfis de usuário.
O cluster EMR será excluído automaticamente após o valor de tempo limite ocioso.
- Excluir o Sistema de arquivos elástico da Amazon (Amazon EFS) volume criado para o domínio.
- Esvazie os buckets do S3 criado pela pilha CloudFormation.
- No console do AWS CloudFormation, exclua a pilha.
Conclusão
Nesta postagem, usamos o Apachi Hudi, um tipo de tabela OTF, para demonstrar esse novo recurso para impor controle de acesso refinado no Amazon EMR. Você pode definir permissões granulares no Lake Formation para tabelas OTF e aplicá-las por meio de consultas Spark SQL em clusters EMR. Você também pode usar recursos de data lake transacionais, como execução de consultas de instantâneo, consultas incrementais, viagem no tempo e consulta DML. Observe que este novo recurso abrange todas as tabelas OTF.
Esse recurso foi lançado a partir da versão 6.15 do Amazon EMR em todos Regiões onde o Amazon EMR está disponível. Com a integração do Amazon EMR com o Lake Formation, você pode gerenciar e processar big data com confiança, desbloqueando insights e facilitando a tomada de decisões informadas, ao mesmo tempo em que mantém a segurança e a governança dos dados.
Para saber mais, consulte Habilite o Lake Formation com o Amazon EMR e sinta-se à vontade para entrar em contato com seus arquitetos de soluções da AWS, que podem ajudá-lo em sua jornada de dados.
Sobre o autor
 Raimundo Lai é um arquiteto de soluções sênior especializado em atender às necessidades de clientes de grandes empresas. Sua experiência consiste em ajudar os clientes na migração de sistemas corporativos e bancos de dados complexos para a AWS, construindo plataformas de armazenamento de dados corporativos e data lake. Raymond é excelente na identificação e design de soluções para casos de uso de IA/ML e tem foco particular em soluções AWS Serverless e design de arquitetura orientada a eventos.
Raimundo Lai é um arquiteto de soluções sênior especializado em atender às necessidades de clientes de grandes empresas. Sua experiência consiste em ajudar os clientes na migração de sistemas corporativos e bancos de dados complexos para a AWS, construindo plataformas de armazenamento de dados corporativos e data lake. Raymond é excelente na identificação e design de soluções para casos de uso de IA/ML e tem foco particular em soluções AWS Serverless e design de arquitetura orientada a eventos.
 Bin Wang, PhD, é arquiteto de soluções especialista em análise sênior na AWS, com mais de 12 anos de experiência na indústria de ML, com foco específico em publicidade. Ele possui experiência em processamento de linguagem natural (PNL), sistemas de recomendação, diversos algoritmos de ML e operações de ML. Ele é profundamente apaixonado pela aplicação de técnicas de ML/DL e big data para resolver problemas do mundo real.
Bin Wang, PhD, é arquiteto de soluções especialista em análise sênior na AWS, com mais de 12 anos de experiência na indústria de ML, com foco específico em publicidade. Ele possui experiência em processamento de linguagem natural (PNL), sistemas de recomendação, diversos algoritmos de ML e operações de ML. Ele é profundamente apaixonado pela aplicação de técnicas de ML/DL e big data para resolver problemas do mundo real.
 Aditya Xá é engenheiro de desenvolvimento de software na AWS. Ele está interessado em bancos de dados e mecanismos de data warehouse e trabalhou em otimizações de desempenho, conformidade de segurança e conformidade com ACID para mecanismos como Apache Hive e Apache Spark.
Aditya Xá é engenheiro de desenvolvimento de software na AWS. Ele está interessado em bancos de dados e mecanismos de data warehouse e trabalhou em otimizações de desempenho, conformidade de segurança e conformidade com ACID para mecanismos como Apache Hive e Apache Spark.
 Melodia Yang é arquiteto sênior de soluções de Big Data para Amazon EMR na AWS. Ela é uma líder de análise experiente que trabalha com clientes da AWS para fornecer orientação sobre práticas recomendadas e consultoria técnica para ajudar no sucesso deles na transformação de dados. Suas áreas de interesse são frameworks e automação de código aberto, engenharia de dados e DataOps.
Melodia Yang é arquiteto sênior de soluções de Big Data para Amazon EMR na AWS. Ela é uma líder de análise experiente que trabalha com clientes da AWS para fornecer orientação sobre práticas recomendadas e consultoria técnica para ajudar no sucesso deles na transformação de dados. Suas áreas de interesse são frameworks e automação de código aberto, engenharia de dados e DataOps.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- :tem
- :é
- :não
- :onde
- $UP
- 1
- 10
- 100
- 11
- 12
- 130
- 15%
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- Sobre
- Acesso
- Conta
- reconhecer
- ações
- ativamente
- adicionado
- Adicionalmente
- endereços
- admin
- administradores
- Publicidade
- conselho
- Depois de
- novamente
- AI / ML
- algoritmos
- Todos os Produtos
- permitir
- permitidas
- permite
- ao lado de
- tb
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- an
- análise
- Analistas
- Analítico
- analítica
- análise
- e
- qualquer
- apache
- Apache Spark
- Aplicação
- aplicado
- Aplicar
- Aplicando
- arquitetos
- arquitetura
- SOMOS
- áreas
- por aí
- AS
- auxiliar
- Assistência
- ajudando
- assumir
- At
- auditoria
- autoridade
- autorizado
- automaticamente
- Automação
- disponível
- evitar
- AWS
- Nuvem AWS9
- Formação da Nuvem AWS
- Formação AWS Lake
- em caminho duplo
- baseado
- BE
- sido
- atrás
- ser
- Benefícios
- além de
- MELHOR
- Grande
- Big Data
- Blogs
- vangloriando-se
- ambos
- construir
- mas a
- by
- CA
- CAN
- capaz
- transportar
- transporte
- casas
- casos
- catálogo
- restauração
- certo
- certificado
- certificados
- FDA
- alterar
- mudado
- Alterações
- China
- Escolha
- Limpeza
- Cloud9
- Agrupar
- código
- Coluna
- colunas
- COM
- combinação
- commit
- Empresas
- comparado
- completar
- compliance
- componente
- componentes
- Computar
- computador
- conceito
- condições
- Conduzir
- com confiança
- Configuração
- Contato
- cônsul
- construção
- Contacto
- não contenho
- contém
- ao controle
- controlado
- controles
- copiando
- Correspondente
- Custo
- custos
- país
- cobre
- crio
- criado
- cria
- Criar
- criador
- Atual
- personalizadas
- Clientes
- dados,
- acesso a dados
- análise de dados
- lago data
- Plataforma de dados
- privacidade de dados
- informática
- segurança dos dados
- data warehouse
- banco de dados
- bases de dados
- Tomada de Decisão
- profundamente
- Padrão
- definir
- Delta
- demonstrar
- demonstrando
- implantar
- desenvolvimento
- Design
- concepção
- detalhes
- Desenvolvimento
- diferente
- distinto
- diferente
- dns
- do
- parece
- Não faz
- domínio
- feito
- não
- down
- download
- dirigido
- durante
- cada
- outro
- permitir
- habilitado
- permite
- criptografia
- final
- endpoints
- aplicar
- Motor
- engenheiro
- Engenharia
- Motores
- garantir
- garante
- assegurando
- Entrar
- Empreendimento
- clientes corporativos
- Todo
- Meio Ambiente
- Éter (ETH)
- Evento
- Cada
- exemplo
- execução
- existe
- vasta experiência
- experiente
- experiência
- exploração
- se estende
- externo
- facilitando
- mais rápido
- Característica
- Funcionalidades
- sentir
- Envie o
- Arquivos
- filtro
- filtragem
- filtros
- Primeiro nome
- Foco
- concentra-se
- seguir
- seguinte
- segue
- Escolha
- formato
- treinamento
- quatro
- Quadro
- enquadramentos
- Gratuito
- da
- Cumprir
- cheio
- funcionalidade
- mais distante
- futuro
- Ganho
- gerado
- governo
- governado
- conceder
- grandemente
- Grupo
- Do grupo
- orientações
- mão
- Ter
- he
- sua experiência
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Destaque
- sua
- histórico
- história
- Colméia
- Hong
- 香港
- House
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- http
- HTTPS
- IAM
- ÍCONE
- ID
- idéia
- identificar
- identificar
- inativo
- if
- ilustra
- executar
- melhorar
- in
- inclui
- Incluindo
- incorporando
- incrementais
- Índia
- indústria
- informar
- INFORMAÇÕES
- informado
- entrada
- insights
- integrado
- Integração
- integração
- interativo
- interessado
- interesses
- Interface
- interno
- para dentro
- intricado
- introduzido
- Introduz
- emitem
- IT
- ESTÁ
- Trabalho
- Empregos
- viagem
- jpg
- Caderno Jupyter
- Chave
- Kong
- lago
- língua
- grande
- Sobrenome
- lançamento
- lançado
- líder
- APRENDER
- níveis
- encontra-se
- como
- LIMITE
- linhas
- local
- localização
- locais
- entrar
- principal
- fazer
- gerencia
- gerenciados
- de grupos
- Gerente
- muitos
- Posso..
- significa
- mecanismos
- reunião
- Menu
- metadados
- poder
- migrando
- minutos
- ML
- Algoritmos de ML
- modificada
- mais
- movimento
- nome
- nomes
- natural
- Linguagem Natural
- Processamento de linguagem natural
- Navegar
- Navegação
- você merece...
- Cria
- Novo
- novo recurso
- recentemente
- Próximo
- PNL
- nó
- nota
- caderno
- laptops
- agora
- objetos
- of
- frequentemente
- on
- ONE
- só
- aberto
- open source
- openssl
- Operações
- ideal
- Otimize
- Opção
- Opções
- or
- ordem
- organização
- Outros
- Fora
- Acima de
- par
- pão
- particular
- particularmente
- apaixonado
- pagar
- atuação
- realização
- permissão
- permissões
- Pessoalmente
- phd
- Pii
- espaço reservado
- plataforma
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- por favor
- mais
- pontos
- Popular
- possui
- Publique
- prática
- preservando
- anterior
- primário
- política de privacidade
- privilégio
- privilégios
- problemas
- processo
- em processamento
- Produção
- Perfil
- Perfis
- prova
- prova de conceito
- protegido
- proteção
- fornecer
- fornece
- fornecendo
- público
- fins
- consultas
- Leia
- Leitura
- pronto
- mundo real
- em tempo real
- recomendar
- registro
- recuperação
- reduz
- redução
- referir
- refere-se
- reflete
- região
- cadastre-se
- registrado
- regulamentos
- liberar
- Releases
- relevante
- substituir
- requeridos
- Requisitos
- recurso
- uso intensivo de recursos
- Recursos
- resultar
- Resultados
- direitos
- Tipo
- papéis
- LINHA
- rsa
- regras
- Execute
- corrida
- sábio
- mesmo
- Salvar
- Seção
- seguro
- Secured
- segurança
- Vejo
- Buscar
- selecionar
- senior
- sensível
- servidor
- Serverless
- Serviços
- Sessão
- conjunto
- Conjuntos
- Configurações
- instalação
- ela
- assinar
- de forma considerável
- semelhante
- simples
- simplifica
- simplificar
- desde
- Instantâneo
- So
- Software
- desenvolvimento de software
- solução
- Soluções
- RESOLVER
- alguns
- fonte
- Faísca
- especialista
- especializada
- SQL
- pilha
- Etapa
- começo
- começado
- Comece
- declarações
- Passos
- armazenamento
- lojas
- Estratégia
- Tanga
- estudo
- enviar
- sub-redes
- sucesso
- tal
- RESUMO
- ajuda
- suportes
- certo
- sintaxe
- sistemas
- mesa
- TAG
- toma
- Dados Técnicos:
- técnicas
- modelo
- terminal
- que
- A
- A fonte
- deles
- Eles
- então
- Lá.
- Este
- deles
- isto
- três
- Através da
- tempo
- viagem no tempo
- linha do tempo
- para
- Rastreamento
- transação
- transacional
- Transformação
- trânsito
- viagens
- verdadeiro
- confiável
- Ts
- dois
- tipo
- tipos
- ui
- para
- Inesperado
- desconhecido
- Desbloqueio
- Atualizar
- Atualizada
- sustentação
- carregado
- URI
- usar
- caso de uso
- usava
- Utilizador
- usuários
- utilização
- valida
- valor
- vário
- versão
- via
- visibilidade
- volume
- Armazém
- Armazenagem
- we
- web
- serviços web
- quando
- enquanto que
- qual
- enquanto
- QUEM
- precisarão
- de
- dentro
- trabalhou
- trabalhar
- escrever
- anos
- Você
- investimentos
- zefirnet
- zero
- Zip