Introdução
A fusão de inteligência artificial (IA) e a arte revelam novos caminhos na arte digital criativa, principalmente através de modelos de difusão. Esses modelos se destacam na geração de arte criativa de IA, oferecendo uma abordagem distinta das redes neurais convencionais. Este artigo leva você a uma jornada exploratória nas profundezas dos modelos de difusão, elucidando seu mecanismo único na criação de obras de arte visualmente deslumbrantes e criativamente ricas. Entenda as nuances dos modelos de difusão e obtenha insights sobre seu papel na redefinição da expressão artística através das lentes das tecnologias avançadas de IA.

Objetivos de aprendizagem
- Compreender os conceitos fundamentais dos modelos de difusão em IA.
- Explore a distinção entre modelos de difusão e redes neurais tradicionais na geração de arte.
- Analise o processo de criação de arte usando modelos de difusão.
- Avalie as implicações criativas e estéticas da IA na arte digital.
- Discuta as considerações éticas nas obras de arte geradas por IA.
Este artigo foi publicado como parte do Blogatona de Ciência de Dados.
Índice
Compreendendo os modelos de difusão

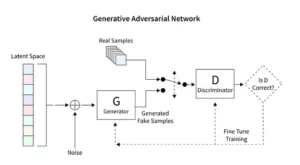
Os modelos de difusão revolucionam a IA generativa, apresentando um método único de criação de imagens, distinto das técnicas convencionais como Redes Adversariais Generativas (GANs). Começando com ruído aleatório, estes modelos refinam-no progressivamente, assemelhando-se a um artista afinando uma pintura, resultando em imagens intrincadas e coerentes.
Este processo de refinamento incremental reflete a natureza metódica da difusão. Aqui, cada iteração altera sutilmente o ruído, aproximando-o da visão artística final. O resultado não é apenas um produto da aleatoriedade, mas uma obra de arte evoluída, distinta em sua progressão e acabamento.
A codificação para modelos de difusão exige um conhecimento profundo de redes neurais e estruturas de aprendizado de máquina, como TensorFlow ou PyTorch. O código resultante é complexo, exigindo treinamento extensivo em conjuntos de dados expansivos para alcançar os efeitos diferenciados observados na arte gerada por IA.
Aplicação de Difusão Estável na Arte
O advento de geradores de arte de IA, como modelos de difusão estáveis, requer codificação sofisticada em plataformas como TensorFlow ou PyTorch. Esses modelos se destacam por sua capacidade de transformar metodicamente a aleatoriedade em estrutura, como um artista que transforma um esboço preliminar em uma obra-prima vívida.
Modelos de difusão estável remodelam o cenário artístico da IA, esculpindo imagens ordenadas a partir da aleatoriedade, evitando a dinâmica competitiva característica dos GANs. Eles se destacam na interpretação de sugestões conceituais em artes visuais, promovendo uma dança sinérgica entre as capacidades de IA e a engenhosidade humana. Ao aproveitar o PyTorch, observamos como esses modelos refinam iterativamente o caos em clareza, espelhando a jornada do artista desde uma ideia nascente até uma criação refinada.
Experimentando arte gerada por IA
Esta demonstração investiga o fascinante mundo da arte gerada por IA usando uma rede neural convolucional chamada ConvDiffusionModel. Este modelo é treinado em diversas imagens artísticas, abrangendo desenhos, pinturas, esculturas e gravuras, provenientes de este conjunto de dados Kaggle. Nosso objetivo é explorar a capacidade do modelo de capturar e reproduzir a estética complexa dessas obras de arte.
Arquitetura e treinamento de modelo
Projeto arquitetônico
O ConvDiffusionModel, em sua essência, é uma maravilha da engenharia neural, apresentando uma sofisticada arquitetura codificadora-decodificadora adaptada às demandas da geração de arte. A estrutura do modelo é uma rede neural complexa, integrando mecanismos refinados de codificador-decodificador especificamente aprimorados para geração de arte. Com camadas convolucionais adicionais e conexões de salto que emulam a intuição artística, o modelo pode dissecar e remontar a arte com uma compreensão astuta de composição e estilo.
- Codificador: O codificador é o olho analítico do modelo, examinando minuciosamente os mínimos detalhes de cada imagem de entrada. À medida que as imagens passam pelas camadas convolucionais do codificador, elas são progressivamente comprimidas em um espaço latente – uma representação compacta e codificada da obra de arte original. Nosso codificador não apenas examina imagens de entrada, mas agora o faz com maior profundidade de percepção, cortesia de camadas adicionais e técnicas de normalização de lote. Este exame prolongado permite uma representação mais rica e condensada dentro do espaço latente, espelhando a contemplação profunda de um artista sobre um assunto.
- Decodificador: Em contraste, o decodificador serve como mão criativa do modelo, pegando os esboços abstratos do codificador e dando vida a eles. Ele reconstrói a obra de arte a partir do espaço latente, camada por camada, detalhe por detalhe, até surgir uma imagem completa. Nosso decodificador se beneficia de conexões saltadas e pode reconstruir obras de arte com maior precisão. Ele revisita a essência abstrata da entrada e a embeleza progressivamente, alcançando uma representação mais fiel ao material de origem. As camadas aprimoradas funcionam em conjunto para garantir que a imagem final seja uma peça vívida e complexa que reflita a arte da entrada.
Processo de Treinamento
A formação do ConvDiffusionModel é uma viagem por uma paisagem artística que abrange 150 épocas. Cada época representa uma passagem completa por todo o conjunto de dados, com o modelo se esforçando para refinar sua compreensão e melhorar a fidelidade das imagens geradas.
- Função de perda híbrida: No centro do treinamento está a função de perda do erro quadrático médio (MSE). Esta função quantifica a diferença entre a obra-prima original e a recriação do modelo, fornecendo uma métrica clara para minimizar. Apresentaremos um componente de perda perceptual derivado de uma rede VGG pré-treinada que complementa a métrica do erro quadrático médio (MSE). Esta estratégia de dupla perda impulsiona o modelo a honrar a integridade artística dos originais, ao mesmo tempo que aperfeiçoa a reprodução técnica dos seus detalhes.
- Otimizador: Com sua taxa de aprendizado ajustada dinamicamente por um escalonador, o otimizador Adam orienta o aprendizado do modelo com maior sagacidade. Esta abordagem adaptativa garante que o progresso do modelo na aprendizagem para replicar e inovar a arte seja constante e robusto.
- Iteração e refinamento: As iterações de treinamento são uma dança entre a preservação da essência artística e a busca pela replicação técnica. A cada ciclo, o modelo se aproxima de uma síntese de fidelidade e criatividade.
- Visualização do Progresso: As imagens são salvas em intervalos regulares durante o treinamento para visualizar o progresso do modelo. Esses instantâneos oferecem uma janela para a curva de aprendizado do modelo, mostrando como a arte gerada evolui, tornando-se mais clara, mais detalhada e mais artisticamente coerente a cada época.



O acima é demonstrado através do seguinte trecho de código:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')
Visualizando a arte gerada
Manifestando a arte criada pela IA
Com o ConvDiffusionModel agora totalmente treinado, o foco muda do abstrato para o concreto – do potencial para a atualização da arte criada por IA. O trecho de código subsequente materializa as capacidades artísticas aprendidas do modelo, transformando os dados de entrada em uma tela digital de expressão.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()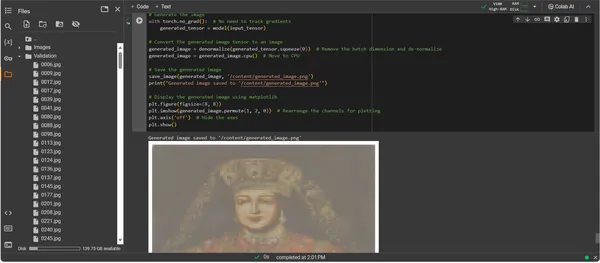

Passo a passo do código de geração de arte
- Ressurreição Modelo: A primeira etapa na geração da arte é reviver nosso ConvDiffusionModel treinado. Os pesos aprendidos do modelo são carregados e colocados em modo de avaliação, preparando o terreno para a criação sem alterar ainda mais seus parâmetros.
- Transformação da imagem: Para garantir consistência com o regime de treinamento, as imagens de entrada são processadas através da mesma sequência de transformações. Isso inclui redimensionamento para corresponder às dimensões de entrada do modelo, conversão de tensor para compatibilidade com PyTorch e normalização com base no perfil estatístico dos dados de treinamento.
- Utilitário de desnormalização: Uma função personalizada reverte os efeitos de pré-processamento, redimensionando o tensor para a faixa de cores da imagem original. Esta etapa é essencial para renderizar a saída gerada em uma representação visualmente precisa.
- Preparação de entrada: Uma imagem é carregada e submetida às transformações mencionadas. É crucial notar que esta imagem serve como musa na qual a IA irá se inspirar – o sussurro silencioso acende a imaginação sintética do modelo.
- Síntese de Arte: Numa dança delicada de propagação para frente, o modelo interpreta o tensor de entrada, permitindo que suas camadas colaborem na produção de uma nova visão artística. Execute esse processo sem rastrear gradientes, pois agora estamos na área de aplicação, não de treinamento.
- Conversão de imagem: A saída tensora do modelo, que agora contém a obra de arte nascida digitalmente, é desnormalizada, traduzindo a criação do modelo de volta ao espaço familiar de cor e luz que nossos olhos podem apreciar.
- Revelação de arte: O tensor transformado é disposto em uma tela digital, culminando em um arquivo de imagem salvo. Este arquivo é uma janela para a alma criativa da IA, um eco estático do processo dinâmico que lhe deu vida.
- Recuperação de arte: O script termina salvando a imagem gerada em um caminho designado e anunciando sua conclusão. A imagem salva, uma síntese de princípios artísticos aprendidos e criatividade emergente, está pronta para exibição e contemplação.
Analisando a saída
A saída do ConvDiffusionModel apresenta uma figura com uma clara referência à arte histórica. Envolta em trajes elaborados, a imagem renderizada por IA ecoa a grandeza dos retratos clássicos, mas com um toque distinto e moderno. O traje do sujeito é rico em textura, combinando os padrões aprendidos do modelo com uma interpretação nova. Características faciais delicadas e uma interação sutil de luz e sombra mostram a compreensão diferenciada da IA das técnicas artísticas tradicionais. Esta obra de arte é uma prova do treinamento sofisticado do modelo, refletindo uma síntese elegante da arte histórica através do prisma do aprendizado de máquina avançado. Em essência, é uma homenagem digital ao passado, elaborada com os algoritmos do presente.
Desafios e Considerações Éticas
A implementação de modelos de difusão para geração de arte traz consigo vários desafios e considerações éticas que você deve considerar:
- Proveniência dos dados: Os conjuntos de dados de treinamento devem ser selecionados de forma responsável. É essencial verificar se os dados usados para treinar modelos de difusão não contêm obras protegidas ou protegidas por direitos autorais sem a devida autorização.
- Viés e Representação: Os modelos de IA podem perpetuar preconceitos nos seus dados de treinamento. Garantir conjuntos de dados diversificados e inclusivos é importante para evitar o reforço de estereótipos na arte gerada pela IA.
- Controle sobre a saída: Uma vez que os modelos de difusão podem gerar uma ampla gama de resultados, é necessário estabelecer limites para evitar a criação de conteúdo impróprio ou ofensivo.
- Enquadramento jurídico: A falta de um quadro jurídico robusto para abordar as nuances da IA no processo criativo representa um desafio. A legislação precisa evoluir para proteger os direitos de todas as partes envolvidas.
Conclusão
A ascensão dos modelos de difusão na IA e na arte marca uma era de transformação, fundindo a precisão computacional com a exploração estética. A sua jornada no mundo da arte destaca um potencial de inovação significativo, mas apresenta complexidades. Equilibrar originalidade, influência, criação ética e respeito pelas obras existentes é parte integrante do processo artístico.
Principais lições
- Os modelos de difusão estão na vanguarda de uma mudança transformadora na criação artística. Oferecem novas ferramentas digitais que expandem o âmbito da expressão artística para além das fronteiras tradicionais.
- Na arte aprimorada por IA, priorizar a coleta ética de dados de treinamento e respeitar a propriedade intelectual dos criadores é fundamental para manter a integridade na arte digital.
- A convergência da visão artística e da inovação tecnológica abre portas para uma relação simbiótica entre artistas e desenvolvedores de IA. Promova um ambiente colaborativo que possa dar origem a arte inovadora.
- É vital garantir que a arte gerada pela IA represente um amplo espectro de perspectivas. Incorporar uma gama variada de dados que reflitam a riqueza de diferentes culturas e pontos de vista, promovendo assim a inclusão.
- O crescente interesse na arte criada pela IA exige o estabelecimento de quadros jurídicos robustos. Estas estruturas devem esclarecer questões de direitos autorais, reconhecer contribuições e reger o uso comercial de obras de arte geradas por IA.
O alvorecer desta evolução artística oferece um caminho repleto de potencial criativo, mas requer uma tutela cuidadosa. Cabe-nos cultivar uma paisagem onde a fusão da IA e da arte prospere, guiada por práticas responsáveis e culturalmente sensíveis.
Perguntas Frequentes
A. Os modelos de difusão são algoritmos generativos de ML que criam imagens começando com um padrão de ruído aleatório e gradualmente moldando-o em uma imagem coerente. Este processo é semelhante a um artista que começa com uma tela em branco e adiciona lentamente camadas de detalhes.
A. GANs, modelos de difusão não requerem uma rede separada para avaliar a saída. Eles funcionam adicionando e removendo ruído de forma iterativa, geralmente resultando em imagens mais detalhadas e diferenciadas.
R. Sim, os modelos de difusão podem gerar peças de arte originais aprendendo com um conjunto de dados de imagens. No entanto, a originalidade é influenciada pela diversidade e escopo dos dados de treinamento. Há um debate contínuo sobre a ética do uso de obras de arte existentes para treinar esses modelos.
R. As preocupações éticas incluem evitar a violação dos direitos de autor da arte gerada pela IA. Respeitar a originalidade dos artistas humanos, evitar a perpetuação de preconceitos e garantir a transparência no processo criativo da IA.
R. O futuro da arte gerada pela IA parece promissor, com modelos de difusão oferecendo novas ferramentas para artistas e criadores. Podemos esperar ver obras de arte mais sofisticadas e complexas à medida que a tecnologia avança. No entanto, a comunidade criativa deve navegar por considerações éticas e trabalhar no sentido de diretrizes claras e melhores práticas.
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do Autor.
Relacionado
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :é
- :não
- :onde
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- habilidade
- Sobre
- acima
- RESUMO
- preciso
- Alcançar
- alcançar
- Adam
- adaptativo
- acrescentando
- Adicional
- endereço
- Ajustado
- avançado
- avanços
- advento
- adversarial
- AI
- arte ai
- aparentado
- algoritmos
- Todos os Produtos
- Permitindo
- permite
- an
- Análises
- analítica
- Análise Vidhya
- e
- Anunciando
- Aplicação
- apreciar
- abordagem
- arquitetura
- SOMOS
- Arte
- artigo
- artista
- artístico
- artisticamente
- arte
- Artistas
- arte
- obras de arte
- AS
- At
- aumentado
- autorização
- disponível
- avenidas
- evitar
- evitando
- MACHADOS
- em caminho duplo
- Mau
- equilíbrio
- baseado
- BE
- tornando-se
- Benefícios
- MELHOR
- melhores práticas
- entre
- Pós
- viés
- vieses
- em branco
- blending
- blogatona
- nascido
- ambos
- limites
- respiração
- transbordando
- Traz
- amplo
- Trazido
- florescente
- mas a
- by
- calcular
- chamado
- CAN
- lona
- capacidades
- capacidade
- capturar
- desafiar
- desafios
- canais
- Chaos
- característica
- verificar
- a verificação
- braçadeira
- clareza
- classe
- remover filtragem
- mais claro
- mais próximo
- código
- Codificação
- COERENTE
- colaborar
- colaborativo
- cor
- vem
- comercial
- comunidade
- compacto
- compatibilidade
- competitivo
- completar
- realização
- integrações
- complexidades
- componente
- composição
- computacional
- Computar
- conceitos
- conceptual
- Preocupações
- concerto
- conclui
- Coneções
- Considerar
- Considerações
- não contenho
- conteúdo
- contraste
- contribuições
- convencional
- Convergência
- Conversão
- conversão
- rede neural convolucional
- direitos autorais
- violação de direitos autorais
- núcleo
- corrupto
- CPU
- Crafted
- crio
- Criar
- criação
- Criatividade
- Criativamente
- criatividade
- criadores
- crucial
- culminando
- Cultivar
- culturalmente
- comissariada
- curva
- personalizadas
- ciclo
- dança
- dados,
- conjuntos de dados
- debate
- profundo
- definição
- demandas
- demonstraram
- profundidade
- Abismo
- Derivado
- designado
- detalhe
- detalhado
- detalhes
- desenvolvedores
- dispositivo
- diferir
- diferença
- diferente
- Distribuição
- digital
- Art digitais
- digitalmente
- Dimensão
- dimensões
- critério
- Ecrã
- exibindo
- distinto
- distinção
- diferente
- Diversidade
- do
- parece
- portas
- desenhar
- Desenhos
- durante
- dinâmico
- dinamicamente
- dinâmica
- e
- cada
- eco
- ecos
- efeitos
- Elaborar
- outro
- emerge
- codificado
- abranger
- abrangente
- Engenharia
- aprimorada
- garantir
- garante
- assegurando
- Todo
- Meio Ambiente
- época
- épocas
- Era
- erro
- essência
- essencial
- estabelecimento
- Éter (ETH)
- considerações éticas
- ética
- avaliação
- Cada
- evolução
- evolui
- evoluiu
- evolui
- exame
- Excel
- Exceto
- existente
- Expandir
- expansivo
- esperar
- exploração
- explorar
- expressão
- opção
- extenso
- olho
- Olhos
- Facial
- fiel
- falso
- familiar
- fascinante
- Funcionalidades
- Apresentando
- fidelidade
- Figura
- Envie o
- Arquivos
- final
- acabamento
- Primeiro nome
- Foco
- seguinte
- Escolha
- Frente
- para a frente
- Promover
- fomento
- Quadro
- enquadramentos
- da
- totalmente
- função
- funcional
- fundamental
- mais distante
- fusão
- futuro
- Ganho
- GANs
- coleta
- deu
- gerar
- gerado
- gerando
- geração
- generativo
- redes adversárias geradoras
- IA generativa
- geradores
- OFERTE
- meta
- GPU
- gradientes
- gradualmente
- grandeza
- aperto
- maior
- inovador
- dirigido
- orientações
- Guias
- mão
- Aproveitamento
- Coração
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Esconder
- destaques
- histórico
- segurando
- homenagem
- honra
- Como funciona o dobrador de carta de canal
- Contudo
- HTTPS
- humano
- i
- idéia
- if
- inflama
- imagem
- imagens
- imaginação
- imperativo
- implementação
- implicações
- importar
- importante
- melhorar
- in
- inclui
- Inclusivo
- Inclusão
- incorporar
- aumentou
- incrementais
- Titular
- influência
- influenciado
- violação
- ingenuidade
- inovar
- Inovação
- entrada
- inputs
- introspecção
- integral
- Integração
- integridade
- intelectual
- propriedade intelectual
- interesse
- interpretação
- para dentro
- intricado
- introduzir
- intuição
- envolvido
- questões
- IT
- iteração
- iterações
- ESTÁ
- viagem
- jpg
- juiz
- Falta
- paisagem
- camada
- camadas
- aprendido
- aprendizagem
- Legal
- enquadramento jurídico
- Legislação
- Lente
- encontra-se
- vida
- leve
- como
- carregamento
- OLHARES
- fora
- perdas
- máquina
- aprendizado de máquina
- a manter
- maravilha
- Obra-prima
- Match
- material
- matplotlib
- significar
- mecanismo
- mecanismos
- Mídia
- apenas
- fusão
- método
- metódico
- métrico
- minimizar
- minuto
- espelhamento
- ML
- Algoritmos de ML
- Moda
- modelo
- modelos
- EQUIPAMENTOS
- módulo
- mais
- mover
- muito
- MUSE
- devo
- nomes
- nascente
- Natureza
- Navegar
- necessário
- Cria
- rede
- redes
- Neural
- Engenharia neural
- rede neural
- redes neurais
- Novo
- Ruído
- nota
- romance
- agora
- nuances
- observar
- observado
- of
- WOW!
- ofensivo
- oferecer
- oferecendo treinamento para distância
- Oferece
- frequentemente
- on
- contínuo
- só
- abre
- Otimize
- or
- original
- originalidade
- Originals
- OS
- Outros
- A Nossa
- Fora
- saída
- outputs
- Acima de
- propriedade
- pintura
- pinturas
- parâmetro
- parâmetros
- parte
- partes
- passar
- passado
- caminho
- padrão
- padrões
- percepção
- aperfeiçoamento
- realizar
- perspectivas
- fotografia
- peça
- peças
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- retratos
- potencial
- práticas
- Precisão
- preliminares
- presente
- presentes
- preservando
- evitar
- impedindo
- princípios
- impressão
- priorização
- processo
- processado
- produtor
- Produto
- Perfil
- profundo
- Progresso
- progressão
- progressivamente
- promissor
- Promoção
- solicita
- propagação
- adequado
- propriedade
- proteger
- protegido
- proveniência
- fornecendo
- publicado
- perseguindo
- pytorch
- quantifica
- acaso
- aleatoriedade
- alcance
- Taxa
- pronto
- reino
- reconhecer
- Redefinindo
- refinar
- refinado
- refletindo
- reflete
- regime
- regular
- relacionamento
- removendo
- representação
- réplica
- representação
- representa
- reprodução
- requerer
- exige
- assemelhando-se
- remodelar
- respeito
- respeitando
- responsável
- com responsabilidade
- resultando
- retorno
- revelação
- Reviver
- revolucionar
- RGB
- Rico
- direitos
- Subir
- uma conta de despesas robusta
- Tipo
- mesmo
- salvo
- poupança
- cena
- Ciência
- escopo
- escrita
- Vejo
- AUTO
- sensível
- separado
- Seqüência
- serve
- conjunto
- contexto
- instalação
- vários
- Shadow
- formação
- mudança
- Turnos
- rede de apoio social
- mostrar
- apresentando
- mostrando
- periodo
- desde
- Lentamente
- fragmento
- So
- sofisticado
- alma
- fonte
- de origem
- Espaço
- abrangendo
- especificamente
- Espectro
- Quadrada
- estável
- Etapa
- suporte
- Comece
- estatístico
- estável
- Passo
- Estratégia
- esforçando-se
- estrutura
- Assombroso
- estilo
- sujeito
- subseqüente
- tal
- Simbiótico
- sinérgico
- síntese
- sintético
- adaptados
- toma
- tomar
- Target
- Dados Técnicos:
- técnicas
- tecnológica
- Tecnologias
- Tecnologia
- fluxo tensor
- vontade
- que
- A
- O Futuro
- A fonte
- deles
- Eles
- Lá.
- Este
- deles
- isto
- prospera
- Através da
- Assim
- para
- ferramentas
- tocha
- Visão da tocha
- tocar
- para
- Rastreamento
- tradicional
- Trem
- treinado
- Training
- Transformar
- Transformação
- transformações
- transformadora
- transformado
- transformando
- transformações
- Transparência
- verdadeiro
- tentar
- compreender
- compreensão
- único
- até
- Revela
- atualização
- sobre
- us
- usar
- usava
- utilização
- utilidade
- válido
- verificação
- via
- vendo
- pontos de vista
- visão
- visual
- arte visual
- visualização
- visualizar
- visualmente
- vital
- foi
- we
- webp
- O Quê
- O que é a
- qual
- enquanto
- Sussurro
- QUEM
- Largo
- Ampla variedade
- precisarão
- janela
- de
- dentro
- sem
- Atividades:
- trabalho
- mundo
- X
- sim
- ainda
- Você
- zefirnet
- zero