Introdução à extração de tabelas
A quantidade de dados coletados está aumentando drasticamente a cada dia com um número crescente de aplicativos, software e plataformas online.
Para manipular/acessar esses dados gigantescos de forma produtiva, é necessário desenvolver ferramentas valiosas de extração de informações.
Uma das subáreas que está demandando atenção no campo de Extração de Informações é a extração de tabelas de imagens ou a detecção de dados tabulares de formulários, PDFs e documentos.
Extração de Tabela é a tarefa de detectar e decompor as informações da tabela em um documento.

Imagine que você tenha muitos documentos com dados tabulares que precisa extrair para processamento adicional. Convencionalmente, você pode copiá-los manualmente (em um papel) ou carregá-los em planilhas do Excel.
No entanto, com o software OCR de tabela, você pode detectar tabelas automaticamente e extrair todos os dados tabulares de documentos de uma só vez. Isso economiza muito tempo e retrabalho.
Neste artigo, veremos primeiro como os Nanonets podem extrair automaticamente tabelas de imagens ou documentos. Em seguida, abordaremos algumas técnicas populares de DL para detectar e extrair tabelas em documentos.
Quer extrair dados tabulares de faturas, recibos ou qualquer outro tipo de documento? Confira os Nanonets Extrator de tabela PDF para extrair dados tabulares. Agende uma demonstração para saber mais sobre automação extração de mesa.
Conteúdo
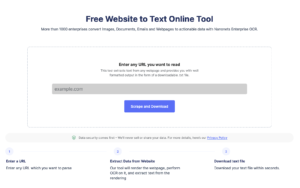
Extraia a tabela da imagem com o OCR da tabela Nanonets
-
Seja um voluntário para uma conta Nanonets gratuita
- Carregar imagens/arquivos para o modelo OCR de tabela Nanonets
- Nanonets detecta e extrai automaticamente todos os dados tabulares
- Edite e revise os dados (se necessário)
- Exporte os dados processados como Excel, csv ou JSON
Quer raspar dados de PDF documentos, converter tabela PDF para Excel or extração automática de tabelas? Descobrir como nanonets Raspador de PDF or analisador de PDF pode impulsionar o seu negócio a ser mais produtivo.
API de OCR de tabela de nanonets

A API Nanonets OCR permite construir modelos OCR com facilidade. Você não precisa se preocupar com o pré-processamento de suas imagens ou com a correspondência de modelos ou construção de mecanismos baseados em regras para aumentar a precisão do seu modelo de OCR.
Você pode fazer upload de seus dados, anotá-los, definir o modelo para treinar e aguardar as previsões por meio de uma interface de usuário baseada em navegador sem escrever uma única linha de código, se preocupar com GPUs ou encontrar as arquiteturas certas para a detecção de sua tabela usando modelos de aprendizado profundo.
Você também pode adquirir as respostas JSON de cada previsão para integrá-las aos seus próprios sistemas e criar aplicativos baseados em aprendizado de máquina criados com algoritmos de última geração e uma infraestrutura forte.
https://nanonets.com/documentation/
Sua empresa lida com reconhecimento de dados ou texto em documentos digitais, PDFs ou imagens? Você já se perguntou como extrair dados tabulares, extrair texto de imagens , extrair dados de PDF or extrair texto do PDF com precisão e eficiência?
Quem achará a extração de tabela útil
Conforme discutido na seção anterior, as tabelas são usadas com frequência para representar dados em um formato limpo. Podemos vê-los com tanta frequência em várias áreas, desde organizar nosso trabalho estruturando dados em tabelas até armazenar enormes ativos de empresas. Existem muitas organizações que precisam lidar com milhões de tabelas todos os dias. Para facilitar tarefas tão trabalhosas de fazer tudo manualmente, precisamos recorrer a técnicas mais rápidas. Vamos discutir alguns casos de uso em que extraindo tabelas pode ser essencial:

Casos de uso pessoal
A extração de mesa também pode ser útil para pequenos casos de uso pessoal. Às vezes, capturamos documentos no celular e depois os copiamos para nossos computadores. Em vez de usar esse processo, podemos capturar diretamente os documentos e salvá-los como formatos editáveis em nossos modelos personalizados. Abaixo estão alguns casos de uso sobre como podemos encaixar a extração de tabelas em nossa rotina pessoal –
Digitalizando documentos para o telefone: Frequentemente capturamos imagens de tabelas importantes no telefone e as salvamos, mas com a técnica de extração de tabelas, podemos capturar as imagens das tabelas e armazená-las diretamente em um formato tabular, seja em planilhas do Excel ou google. Com isso, não precisamos buscar imagens ou copiar o conteúdo da tabela para novos arquivos, em vez disso, podemos usar diretamente as tabelas importadas e começar a trabalhar nas informações extraídas.
Documentos para HTML: Nas páginas da web, encontramos muitas informações apresentadas em tabelas. Eles nos ajudam na comparação com os dados e nos dão uma nota rápida sobre os números de forma organizada. Ao usar o processo de extração de tabela, podemos digitalizar documentos PDF ou imagens JPG / PNG e carregar as informações diretamente em um formato de tabela personalizado criado por você mesmo. Podemos escrever scripts para adicionar tabelas adicionais com base nas tabelas existentes e, assim, digitalizar as informações. Isso nos ajuda na edição do conteúdo e agiliza o processo de armazenamento.
Casos de uso industrial
Existem vários setores em todo o mundo que funcionam enormemente com papelada e documentação, especialmente nos setores de bancos e seguros. Desde o armazenamento de detalhes dos clientes até o atendimento às necessidades dos clientes, as tabelas são amplamente utilizadas. Essas informações novamente são passadas como um documento (cópia impressa) para diferentes ramos para aprovações, onde às vezes, a falta de comunicação pode levar a erros ao obter informações das tabelas. Em vez disso, usar a automação aqui torna nossas vidas muito mais fáceis. Depois que os dados iniciais são capturados e aprovados, podemos digitalizar diretamente esses documentos em tabelas e trabalhar mais com os dados digitalizados. Sem falar na redução do consumo de tempo e falhas, podemos avisar os clientes sobre o horário e local onde as informações são processadas. Isso, portanto, garante a confiabilidade dos dados e simplifica nossa maneira de lidar com as operações. Vejamos agora os outros casos de uso possíveis:
Controle de Qualidade: O controle de qualidade é um dos principais serviços fornecidos pelas principais indústrias. Geralmente é feito internamente e para as partes interessadas. Como parte disso, existem muitos formulários de feedback que são coletados dos consumidores para extrair feedback sobre o serviço fornecido. Nos setores industriais, eles usam tabelas para fazer listas de verificação diárias e notas para ver como as linhas de produção estão funcionando. Tudo isso pode ser documentado em um único lugar usando a extração de tabela com facilidade.
Rastreamento de ativos: Nas indústrias de manufatura, as pessoas usam tabelas codificadas para manter o controle de entidades manufaturadas como aço, ferro, plástico, etc. Cada item manufaturado é rotulado com um número exclusivo onde usam tabelas para controlar os itens fabricados e entregues todos os dias. A automação pode ajudar a economizar muito tempo e recursos em termos de erros ou inconsistência de dados.
Casos de uso de negócios
Existem vários setores de negócios que funcionam em planilhas do Excel e formulários off-line. Mas, em determinado momento, é difícil pesquisar essas planilhas e formulários. Se inserirmos essas tabelas manualmente, isso consumirá muito tempo e a chance de os dados inseridos incorretamente ser alta. Portanto, a extração de tabela é a melhor alternativa para resolver os casos de uso de negócios, pois os abaixo são poucos.
Fatura Automação: Existem muitas indústrias de pequena e grande escala cujos faturas ainda são gerados em formatos tabulares. Eles não fornecem declarações fiscais devidamente protegidas. Para superar esses obstáculos, podemos usar a extração de tabela para converter todos faturas em um formato editável e, assim, atualize-os para uma versão mais recente.
Automação de formulário: Os formulários on-line estão interrompendo esse método testado e comprovado, ajudando as empresas a coletar as informações de que precisam e, simultaneamente, conectá-las a outras plataformas de software incorporadas ao fluxo de trabalho. Além de reduzir a necessidade de entrada manual de dados (com entrada de dados automatizada) e e-mails de acompanhamento, a extração de tabelas pode eliminar o custo de impressão, envio, armazenamento, organização e destruição das alternativas tradicionais de papel.
Tem um problema de OCR em mente? Quer digitalizar faturas, PDFs ou matrículas? Vá para Nanoredes e construir modelos OCR gratuitamente!
Aprendizado profundo em ação
O aprendizado profundo faz parte de uma família mais ampla de métodos de aprendizado de máquina baseados em redes neurais artificiais.
Rede Neural é uma estrutura que reconhece os relacionamentos subjacentes nos dados fornecidos por meio de um processo que imita a maneira como o cérebro humano opera. Eles têm diferentes camadas artificiais pelas quais os dados passam, onde aprendem sobre os recursos. Existem diferentes arquiteturas como Convolution NNs, Recurrent NNs, Autoencoders, Generative Adversarial NNs para processar diferentes tipos de dados. Eles são complexos, mas apresentam alto desempenho para resolver problemas em tempo real. Vamos agora dar uma olhada na pesquisa que tem sido realizada no campo de extração de tabelas usando Redes Neurais e também, vamos revisá-los brevemente.
TabelaNet
Introdução: TableNet é uma arquitetura moderna de deep learning que foi proposta por uma equipe da TCS Research no ano de 2019. A principal motivação era extrair informações de tabelas digitalizadas por meio de telefones celulares ou câmeras.
Eles propuseram uma solução que inclui a detecção precisa da região tabular dentro de uma imagem e, subsequentemente, detectar e extrair informações das linhas e colunas da tabela detectada.
Conjunto de dados: O conjunto de dados usado foi Marmot. Possui 2000 páginas em formato PDF que foram coletadas com as verdades fundamentais correspondentes. Isso inclui páginas chinesas também. Ligação - http://www.icst.pku.edu.cn/cpdp/sjzy/index.htm
Arquitetura: A arquitetura é baseada em Long et al., Um modelo codificador-decodificador para segmentação semântica. A mesma rede de codificador / decodificador é usada como a arquitetura FCN para extração de tabela. As imagens são pré-processadas e modificadas usando o OCR Tesseract.
O modelo é derivado em duas fases, submetendo a entrada a técnicas de aprendizado profundo. Na primeira fase, eles usaram os pesos de uma rede VGG-19 pré-treinada. Eles substituíram as camadas totalmente conectadas da rede VGG usada por camadas convolucionais 1 × 1. Todas as camadas convolucionais são seguidas pela ativação ReLU e uma camada de dropout de probabilidade 0.8. Eles chamam a segunda fase de rede decodificada, que consiste em dois ramos. Isso está de acordo com a intuição de que a região da coluna é um subconjunto da região da tabela. Assim, a rede de codificação única pode filtrar as regiões ativas com melhor precisão usando recursos de regiões de tabela e coluna. A saída da primeira rede é distribuída para as duas filiais. Na primeira ramificação, duas operações de convolução são aplicadas e o mapa de feições final é aumentado para atender às dimensões da imagem original. No outro ramo para detecção de colunas, há uma camada de convolução adicional com uma função de ativação ReLU e uma camada de dropout com a mesma probabilidade de dropout mencionada anteriormente. Os mapas de características são amostrados usando convoluções com strided fracionários após uma camada de convolução (1 × 1). Abaixo está uma imagem da arquitetura:

Saídas: Depois que os documentos são processados usando o modelo, as máscaras de tabelas e colunas são geradas. Essas máscaras são usadas para filtrar a tabela e suas regiões de coluna da imagem. Agora, usando o Tesseract OCR, as informações são extraídas das regiões segmentadas. Abaixo está uma imagem mostrando as máscaras que são geradas e posteriormente extraídas das tabelas:

Eles também propuseram o mesmo modelo ajustado com o ICDAR, que teve um desempenho melhor do que o modelo original. O recall, precisão e pontuação F1 do modelo ajustado são 0.9628, 0.9697, 0.9662, respectivamente. O modelo original tem as métricas registradas de 0.9621, 0.9547, 0.9583 na mesma ordem. Vamos agora mergulhar em mais uma arquitetura.
DeepDeSRT
Introdução: DeepDeSRT é uma estrutura de rede neural usada para detectar e compreender as tabelas nos documentos ou imagens. Ele tem duas soluções, conforme mencionado no título:
- Ele apresenta uma solução baseada em aprendizado profundo para detecção de tabelas em imagens de documentos.
- Ele propõe uma nova abordagem baseada em aprendizado profundo para o reconhecimento da estrutura da tabela, ou seja, identificando linhas, colunas e posições de células nas tabelas detectadas.
O modelo proposto é totalmente baseado em dados, não requer heurísticas ou metadados dos documentos ou imagens. Uma vantagem principal em relação ao treinamento é que eles não usaram grandes conjuntos de dados de treinamento, em vez disso, usaram o conceito de aprendizagem por transferência e adaptação de domínio para detecção de tabelas e reconhecimento de estrutura de tabelas.
Conjunto de dados: O conjunto de dados usado é um conjunto de dados de competição de mesa ICDAR 2013 contendo 67 documentos com 238 páginas no total.
Arquitetura:
- Detecção de mesa O modelo proposto utilizou Fast RCNN como framework básico para detecção das tabelas. A arquitetura é dividida em duas partes diferentes. Na primeira parte, eles geraram propostas de região com base na imagem de entrada por uma chamada rede de proposta de região (RPN). Na segunda parte, eles classificaram as regiões usando Fast-RCNN. Para apoiar esta arquitetura, eles usaram ZFNetGenericName e os pesos de VGG-16.
- Reconhecimento de Estrutura Depois que uma tabela foi detectada com sucesso e sua localização conhecida pelo sistema, o próximo desafio para entender seu conteúdo é reconhecer e localizar as linhas e colunas que compõem a estrutura física da tabela. Portanto, eles usaram uma rede totalmente conectada com os pesos do VGG-16 que extrai informações das linhas e colunas. Abaixo estão as saídas do DeepDeSRT:
Saídas:


Os resultados da avaliação revelam que o DeepDeSRT supera os métodos de última geração para detecção de tabela e reconhecimento de estrutura e atinge medidas F1 de 96.77% e 91.44% para detecção de tabela e reconhecimento de estrutura, respectivamente até 2015.
Redes Neurais de Grafo
Papel: Repensando o reconhecimento de tabelas usando redes neurais de gráfico
Introdução: Nesta pesquisa, os autores do Deep Learning Laboratory, National Center of Artificial Intelligence (NCAI) propuseram Redes Neurais de Grafo para extrair informações de tabelas. Eles argumentaram que as redes de grafos são uma escolha mais natural para esses problemas e exploraram duas redes neurais de grafos baseadas em gradiente.
Este modelo proposto combina os benefícios de ambas, redes neurais convolucionais para extração de características visuais e redes de grafos para lidar com a estrutura do problema.
Conjunto de dados: Os autores propuseram um novo grande conjunto de dados gerado sinteticamente de 0.5 milhões de tabelas dividido em quatro categorias.
- As imagens são imagens simples, sem mesclagem e com linhas dominantes
- As imagens têm diferentes tipos de borda, incluindo a ausência ocasional de linhas de contorno
- Introduz a fusão de células e colunas
- A câmera capturou imagens com a transformação de perspectiva linear
Arquitetura: Eles usaram uma rede convolucional rasa que gera os respectivos recursos convolucionais. Se as dimensões espaciais dos recursos de saída não forem iguais às da imagem de entrada, eles coletam posições que são linearmente reduzidas dependendo da proporção entre as dimensões de entrada e saída e as enviam para uma rede de interação que tem duas redes de gráfico conhecidas como DGCNN e GravNet. Os parâmetros da rede gráfica são iguais aos da CNN original. No final, eles usaram uma amostragem de par de tempo de execução para classificar o conteúdo extraído que usava internamente o algoritmo baseado em Monte Carlo. Abaixo estão as saídas:
Saídas:

Abaixo estão os números de precisão tabulados que são gerados pelas redes para quatro categorias da rede, conforme apresentado no Conjunto de dados seção:

CGANs e Algoritmos Genéticos
Introdução: Nesta pesquisa, os autores usaram uma abordagem de cima para baixo em vez de uma abordagem de baixo para cima (integrando linhas em células, linhas ou colunas).
Nesse método, usando uma rede adversária generativa, eles mapearam a imagem da mesa em um formato de mesa "esqueleto" padronizado. Esta tabela de esqueleto denota as bordas aproximadas de linha e coluna sem o conteúdo da tabela. Em seguida, eles ajustam as renderizações de estruturas de tabelas latentes candidatas à estrutura de esqueleto usando uma medida de distância otimizada por um algoritmo genético.
Conjunto de dados: Os autores usaram seu próprio conjunto de dados com 4000 tabelas.
Arquitetura: O modelo proposto consiste em duas partes. Na primeira parte, as imagens de entrada são abstraídas em tabelas de esqueleto usando uma rede neural adversarial condicional gerativa. Um GAN tem novamente duas redes, o gerador que gera amostras aleatórias e o discriminador que informa se as imagens geradas são falsas ou originais. O Gerador G é uma rede de codificador-decodificador onde uma imagem de entrada é passada por uma série de camadas de redução progressiva até uma camada de gargalo onde o processo é revertido. Para passar informações suficientes para as camadas de decodificação, uma arquitetura U-Net com conexões de salto é usada e uma conexão de salto é adicionada entre as camadas i e n - i por meio de concatenação, onde n é o número total de camadas e i é o número da camada no codificador. Uma arquitetura PatchGAN é usada para o discriminador D. Isso penaliza a estrutura da imagem de saída na escala dos patches. Eles produzem a saída como uma mesa esqueleto.
Na segunda parte, eles otimizam o ajuste de estruturas de dados latentes candidatas à imagem de esqueleto gerada usando uma medida da distância entre cada candidata e o esqueleto. É assim que o texto dentro das imagens é extraído. Abaixo está uma imagem que descreve a arquitetura:

saída: As estruturas de tabela estimadas são avaliadas comparando - Número da linha e coluna, posição do canto superior esquerdo, alturas das linhas e larguras das colunas
O algoritmo genético deu 95.5% de precisão em linhas e 96.7% em colunas, ao extrair informações das tabelas.

Necessidade de digitalizar documentos, recibos or faturas mas com preguiça de codificar? Vá para Nanoredes e construir modelos OCR gratuitamente!
[Código] Abordagens Tradicionais
Nesta seção, aprenderemos o processo de como extrair informações de tabelas usando Deep Learning e OpenCV. Você pode pensar nesta explicação como uma introdução, no entanto, construir modelos de última geração exigirá muita experiência e prática. Isso ajudará você a entender os fundamentos de como podemos treinar computadores com várias abordagens e algoritmos possíveis.
Para entender o problema de forma mais precisa, definimos alguns termos básicos, que serão usados ao longo do artigo:
- Texto: contém uma string e cinco atributos (topo, esquerda, largura, altura, fonte)
- Line: contém objetos de texto que se supõe estarem na mesma linha do arquivo original
- Única linha: objeto de linha com apenas um objeto de texto.
- Multi-Linha: objeto de linha com mais de um objeto de texto.
- Multi-Linha Bloquear: um conjunto de objetos multilinhas contínuos.
- Linha: Blocos horizontais na mesa
- Coluna: Blocos verticais na tabela
- Célula: a interseção de uma linha e coluna
- Cell - Padding: o preenchimento interno ou espaço dentro da célula.
Detecção de mesa com OpenCV
Usaremos técnicas tradicionais de visão computacional para extrair informações das tabelas digitalizadas. Aqui está nosso pipeline; inicialmente capturamos os dados (as tabelas de onde precisamos extrair as informações) usando câmeras normais e, em seguida, usando a visão computacional, tentaremos encontrar as bordas, bordas e células. Usaremos diferentes filtros e contornos e destacaremos os principais recursos das tabelas.
Precisaremos da imagem de uma mesa. Podemos capturar isso em um telefone ou usar qualquer imagem existente. Abaixo está o snippet de código,
file = r’table.png’
table_image_contour = cv2.imread(file, 0)
table_image = cv2.imread(file)
Aqui, carregamos a mesma imagem de imagem duas variáveis, pois usaremos o tabela_imagem_contour ao desenhar nossos contornos detectados na imagem carregada. Abaixo está a imagem da mesa que estamos usando em nosso programa:

Devemos empregar uma técnica chamada Limiar de imagem inversa que realça os dados presentes na imagem dada.
ret, thresh_value = cv2.threshold( table_image_contour, 180, 255, cv2.THRESH_BINARY_INV)
Outra etapa importante de pré-processamento é dilatação da imagem. A dilatação é uma operação matemática simples aplicada a imagens binárias (preto e branco) que aumenta gradualmente os limites das regiões dos pixels do primeiro plano (ou seja pixels brancos, normalmente).
kernel = np.ones((5,5),np.uint8)
dilated_value = cv2.dilate(thresh_value,kernel,iterations = 1)
No OpenCV, usamos o método, encontrarContornos para obter os contornos da imagem presente. Este método leva três argumentos, o primeiro é a imagem dilatada (a imagem que é usada para gerar a imagem dilatada é table_image_contour - o método findContours só suporta imagens binárias), o segundo é o cv2.RETR_TREE que nos diz para usar o modo de recuperação de contorno, o terceiro é o cv2.CHAIN_APPROX_SIMPLE que é o modo de aproximação do contorno. O encontrarContornos descompacta dois valores, portanto, adicionaremos mais uma variável chamada hierarquia. Quando as imagens são aninhadas, os contornos exalam interdependência. Para representar esses relacionamentos, a hierarquia é usada.
contours, hierarchy = cv2.findContours( dilated_value, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
Os contornos marcam exatamente onde os dados estão presentes na imagem. Agora, iteramos sobre a lista de contornos que calculamos na etapa anterior e calculamos as coordenadas das caixas retangulares conforme observado na imagem original usando o método, cv2.boundingRect. Na última iteração, colocamos essas caixas na imagem original table_image usando o método, cv2.rectangle ().
for cnt in contours: x, y, w, h = cv2.boundingRect(cnt) # bounding the images if y < 50: table_image = cv2.rectangle(table_image, (x, y), (x + w, y + h), (0, 0, 255), 1) Esta é nossa última etapa. Aqui usamos o método chamadoJanela para renderizar nossa tabela com o conteúdo extraído e contornos embutidos nela. Abaixo está o snippet de código:
plt.imshow(table_image)
plt.show()
cv2.namedWindow('detecttable', cv2.WINDOW_NORMAL)

Altere o valor de y para 300 no snippet de código acima, esta será sua saída:

Depois de extrair as tabelas, você pode executar cada corte de contorno por meio do mecanismo de OCR tesseract, cujo tutorial pode ser encontrado SUA PARTICIPAÇÃO FAZ A DIFERENÇA. Uma vez que temos caixas de cada texto, podemos agrupá-los com base em suas coordenadas xey para derivar a qual linha e coluna correspondentes eles pertencem.
Além disso, há a opção de usar o PDFMiner para transformar seus documentos pdf em arquivos HTML que podemos analisar usando expressões regulares para finalmente obter nossas tabelas. Veja como você pode fazer isso.
Análise PDFMiner e Regex
Para extrair informações de documentos menores, é hora de configurar modelos de aprendizado profundo ou escrever algoritmos de visão computacional. Em vez disso, podemos usar expressões regulares em Python para extrair texto dos documentos PDF. Além disso, lembre-se de que essa técnica não funciona com imagens. Só podemos usar isso para extrair informações de arquivos HTML ou documentos PDF. Isso ocorre porque, ao usar uma expressão regular, você precisará combinar o conteúdo com a fonte e extrair as informações. Com imagens, você não conseguirá corresponder ao texto e as expressões regulares falharão. Agora vamos trabalhar com um documento PDF simples e extrair informações das tabelas nele. Abaixo está a imagem:

Na primeira etapa, carregamos o PDF em nosso programa. Feito isso, convertemos o PDF em HTML para que possamos usar diretamente as expressões regulares e, assim, extrair o conteúdo das tabelas. Para isso, o módulo que usamos é pdfminer. Isso ajuda a ler o conteúdo de PDF e convertê-lo em um arquivo HTML.
Abaixo está o snippet de código:
from pdfminer.pdfinterp import PDFResourceManager from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.converter import HTMLConverter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from cStringIO import StringIO
import re def convert_pdf_to_html(path): rsrcmgr = PDFResourceManager() retstr = StringIO() codec = 'utf-8' laparams = LAParams() device = HTMLConverter(rsrcmgr, retstr, codec=codec, laparams=laparams) fp = file(path, 'rb') interpreter = PDFPageInterpreter(rsrcmgr, device) password = "" maxpages = 0 #is for all caching = True pagenos=set() for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages,password=password,caching=caching, check_extractable=True): interpreter.process_page(page) fp.close() device.close() str = retstr.getvalue() retstr.close() return str
Créditos de código: Zevross
Importamos muitos módulos, inclusive de Expressão Regular e bibliotecas relacionadas a PDF. No método converter_pdf_para_html, enviamos o caminho do arquivo PDF que precisa ser convertido em um arquivo HTML. A saída do método será uma string HTML, conforme mostrado abaixo:
'<span style="font-family: XZVLBD+GaramondPremrPro-LtDisp; font-size:12px">Changing Echoesn<br>7632 Pool Station Roadn<br>Angels Camp, CA 95222n<br>(209) 785-3667n<br>Intake: (800) 633-7066n<br>SA </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> TX DT BU </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> RS RL OP PH </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> CO CJ n<br></span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> SF PI </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> AH SPn<br></span></div>' A expressão regular é uma das técnicas de programação mais complicadas e interessantes usadas para correspondência de padrões. Eles são amplamente usados em vários aplicativos, digamos, para formatação de código, web scraping e validação. Antes de começarmos a extrair conteúdo de nossas tabelas HTML, vamos aprender rapidamente algumas coisas sobre expressões regulares.
Esta biblioteca fornece vários métodos embutidos para combinar e pesquisar padrões. Abaixo estão alguns:
import re # Match the pattern in the string
re.match(pattern, string) # Search for a pattern in a string
re.search(pattern, string) # Finds all the pattern in a string
re.findall(pattern, string) # Splits string based on the occurrence of pattern
re.split(pattern, string, [maxsplit=0] # Search for the pattern and replace it with the given string
re.sub(pattern, replace, string)
Os caracteres / expressões que você geralmente vê em expressões regulares incluem:
- [AZ] - qualquer letra maiúscula
- d - dígito
- w - caractere de palavra (letras, dígitos e sublinhados)
- s - espaço em branco (espaços, guias e espaço em branco)
Agora, para descobrir um determinado padrão em HTML, usamos expressões regulares e, em seguida, escrevemos os padrões de acordo. Primeiro dividimos os dados de forma que os blocos de endereço sejam segregados em blocos separados de acordo com o nome do programa (ANGELS CAMP, APPLE VALLEY, etc.):
pattern = '(?<=<span style="font-family: XZVLBD+GaramondPremrPro-LtDisp; font-size:12px">)(.*?)(?=<br></span></div>)' for programinfo in re.finditer(pattern, biginputstring, re.DOTALL): do looping stuff…
Mais tarde, encontramos o nome do programa, cidade, estado e CEP que sempre seguem o mesmo padrão (texto, vírgula, letras maiúsculas de dois dígitos, 5 números (ou 5 números, hífen, quatro números) - estes estão presentes no arquivo PDF que consideramos como entrada). Verifique o seguinte snippet de código:
# To identify the program name
programname = re.search('^(?!<br>).*(?=\n)', programinfo.group(0))
# since some programs have odd characters in the name we need to escape
programname = re.escape(programname) citystatezip =re.search('(?<=>)([a-zA-Zs]+, [a-zA-Zs]{2} d{5,10})(?=\n)', programinfo.group(0))
mainphone =re.search('(?<=<br>)(d{3}) d{3}-d{4}x{0,1}d{0,}(?=\n)', programinfo.group(0))
altphones = re.findall('(?<=<br>)[a-zA-Zs]+: (d{3}) d{3}-d{4}x{0,1}d{0,}(?=\n)(?=\n)', programinfo.group(0)) Este é um exemplo simples que explica como extraímos informações de arquivos PDF usando uma expressão regular. Depois de extrair todas as informações necessárias, carregamos esses dados em um arquivo CSV.
def createDirectory(instring, outpath, split_program_pattern): i = 1 with open(outpath, 'wb') as csvfile: filewriter = csv.writer(csvfile, delimiter=',' , quotechar='"', quoting=csv.QUOTE_MINIMAL) # write the header row filewriter.writerow(['programname', 'address', 'addressxtra1', 'addressxtra2', 'city', 'state', 'zip', 'phone', 'altphone', 'codes']) # cycle through the programs for programinfo in re.finditer(split_program_pattern, instring, re.DOTALL): print i i=i+1 # pull out the pieces programname = getresult(re.search('^(?!<br>).*(?=\n)', programinfo.group(0))) programname = re.escape(programname) # some facilities have odd characters in the name
Portanto, este é um exemplo simples que explica como você pode enviar o HTML extraído para um arquivo CSV. Primeiro, criamos um arquivo CSV, encontramos todos os nossos atributos e colocamos um por um em suas respectivas colunas. Abaixo está uma captura de tela:

Às vezes, as técnicas discutidas acima parecem complicadas e representam desafios para os programadores se todas as tabelas forem aninhadas e complexas. Aqui, escolher um currículo ou modelo de aprendizado profundo economiza muito tempo. Vamos ver quais desvantagens e desafios dificultam o uso desses métodos tradicionais.
Desafios com métodos tradicionais
Nesta seção, aprenderemos em detalhes sobre onde os processos de extração de tabelas podem falhar e entenderemos melhor as maneiras de superar esses obstáculos usando métodos modernos nascidos do Deep Learning. No entanto, este processo não é uma moleza. A razão é que as tabelas geralmente não permanecem constantes o tempo todo. Eles têm estruturas diferentes para representar os dados, e os dados dentro das tabelas podem ser multilíngues com vários estilos de formatação (estilo, cor, tamanho e altura da fonte). Portanto, para construir um modelo robusto, deve-se estar ciente de todos esses desafios. Normalmente, esse processo inclui três etapas: detecção de tabela, extração e conversão. Vamos identificar os problemas em todas as fases, uma a uma:
Detecção de mesa
Nesta fase, identificamos onde exatamente as tabelas estão presentes na entrada fornecida. A entrada pode ser de qualquer formato, como imagens, documentos PDF / Word e, às vezes, vídeos. Usamos diferentes técnicas e algoritmos para detectar as tabelas, seja por linhas ou por coordenadas. Em alguns casos, podemos encontrar tabelas sem nenhuma borda, onde precisamos optar por métodos diferentes. Além desses, aqui estão alguns outros desafios:
- Transformação da imagem: A transformação da imagem é a etapa principal na detecção de rótulos. Isso inclui aprimorar os dados e as bordas presentes na tabela. Precisamos escolher algoritmos de pré-processamento adequados com base nos dados apresentados na tabela. Por exemplo, quando estamos trabalhando com imagens, precisamos aplicar limiares e detectores de borda. Essa etapa de transformação nos ajuda a encontrar o conteúdo com mais precisão. Em alguns casos, os contornos podem dar errado e os algoritmos não conseguem aprimorar a imagem. Portanto, escolher as etapas corretas de transformação de imagem e o pré-processamento é crucial.
- Qualidade da imagem: Quando digitalizamos tabelas para extração de informações, precisamos ter certeza de que esses documentos são digitalizados em ambientes mais claros, o que garante imagens de boa qualidade. Quando as condições de iluminação são ruins, os algoritmos CV e DL podem falhar em detectar tabelas nas entradas fornecidas. Se estivermos usando aprendizado profundo, precisamos ter certeza de que o conjunto de dados é consistente e tem um bom conjunto de imagens padrão. Se usarmos esses modelos em tabelas presentes em papéis velhos amassados, primeiro precisamos pré-processar e eliminar o ruído nessas fotos.
- Variedade de layouts estruturais e modelos: Todas as tabelas não são exclusivas. Uma célula pode abranger várias células, vertical ou horizontalmente, e combinações de células abrangentes podem criar um grande número de variações estruturais. Além disso, alguns enfatizam os recursos do texto e as linhas da tabela podem afetar a maneira como a estrutura da tabela é compreendida. Por exemplo, linhas horizontais ou texto em negrito podem enfatizar vários cabeçalhos da tabela. A estrutura da tabela define visualmente as relações entre as células. Os relacionamentos visuais nas tabelas tornam difícil localizar computacionalmente as células relacionadas e extrair informações delas. Portanto, é importante construir algoritmos que sejam robustos para lidar com diferentes estruturas de tabelas.
- Preenchimento de células, margens, fronteiras: Esses são os elementos essenciais de qualquer tabela - preenchimentos, margens e bordas nem sempre serão os mesmos. Algumas tabelas têm muito preenchimento dentro das células, outras não. Usar imagens de boa qualidade e etapas de pré-processamento ajudará o processo de extração da tabela a funcionar sem problemas.
Extração de Tabela
Esta é a fase em que as informações são extraídas após a identificação das tabelas. Existem muitos fatores relacionados a como o conteúdo é estruturado e qual conteúdo está presente na tabela. Portanto, é importante entender todos os desafios antes de construir um algoritmo.
- Conteúdo Denso: O conteúdo das células pode ser numérico ou textual. No entanto, o conteúdo textual geralmente é denso, contendo trechos curtos ambíguos com o uso de siglas e abreviações. Para entender as tabelas, o texto precisa ser eliminado e as abreviações e acrônimos precisam ser expandidos.
- Fontes e formatos diferentes: As fontes geralmente são de diferentes estilos, cores e alturas. Precisamos ter certeza de que são genéricos e fáceis de identificar. Poucas famílias de fontes, especialmente aquelas que se enquadram em letras cursivas ou manuscritas, são um pouco difíceis de extrair. Portanto, o uso de uma boa fonte e formatação adequada ajuda o algoritmo a identificar as informações com mais precisão.
- PDFs de várias páginas e quebras de página: A linha de texto nas tabelas é sensível a um limite predefinido. Além disso, com células estendidas em várias páginas, torna-se difícil identificar as tabelas. Em uma página com várias tabelas, é difícil distinguir tabelas diferentes umas das outras. É difícil trabalhar com tabelas esparsas e irregulares. Portanto, as linhas de orientação gráfica e o layout do conteúdo devem ser usados juntos como fontes importantes para identificar as regiões da tabela.
Conversão de Tabela
A última fase inclui a conversão das informações extraídas das tabelas para compilá-las como um documento editável, seja no Excel ou usando outro software. Vamos aprender sobre alguns desafios.
- Definir layouts: Quando diferentes formatos de tabelas são extraídos de documentos digitalizados, precisamos ter um layout de tabela adequado para inserir o conteúdo. Às vezes, o algoritmo falha ao extrair informações das células. Conseqüentemente, projetar um layout adequado também é igualmente importante.
- Variedade de padrões de apresentação de valor: Os valores nas células podem ser apresentados usando diferentes padrões de representação sintática. Considere o texto na tabela com 6 ± 2. O algoritmo pode falhar ao converter essas informações em particular. Portanto, a extração de valores numéricos requer conhecimento de possíveis padrões de apresentação.
- Representação para visualização: A maioria dos formatos de representação para tabelas, como linguagens de marcação em que as tabelas podem ser descritas, são projetados para visualização. Portanto, é um desafio processar tabelas automaticamente.
Esses são os desafios que enfrentamos durante o processo de extração de mesa usando técnicas tradicionais. Agora vamos ver como superá-los com a ajuda do Deep Learning. Está sendo amplamente pesquisado em diversos setores.
Precisa digitalizar documentos, recibos ou faturas mas com preguiça de codificar? Vá para Nanoredes e construir modelos OCR gratuitamente!
Resumo
Neste artigo, revisamos em detalhes sobre a extração de informações de tabelas. Vimos como tecnologias modernas, como Deep Learning e Computer Vision, podem automatizar tarefas rotineiras, criando algoritmos robustos para gerar resultados precisos. Nas seções iniciais, aprendemos sobre a função de extração de tabela em facilitar as tarefas de indivíduos, indústrias e setores de negócios, e também revisamos casos de uso elaborando em extrair tabelas de PDFs / HTML, automação de formulário, fatura Automação, etc. Codificamos um algoritmo usando visão computacional para encontrar a posição das informações nas tabelas usando técnicas de limiar, dilatação e detecção de contorno. Discutimos os desafios que podemos enfrentar durante os processos de detecção, extração e conversão de tabelas ao usar as técnicas convencionais e declaramos como o aprendizado profundo pode nos ajudar a superar esses problemas. Por último, revisamos algumas arquiteturas de rede neural e entendemos suas maneiras de obter extração de tabela com base nos dados de treinamento fornecidos.
Update:
Adicionado mais material de leitura sobre diferentes abordagens na detecção de tabelas e extração de informações usando aprendizado profundo.
- &
- 2019
- 67
- Sobre
- Segundo
- conformemente
- preciso
- adquirir
- em
- ativo
- Adicional
- endereço
- Vantagem
- algoritmo
- algoritmos
- Todos os Produtos
- alternativa
- alternativas
- sempre
- quantidade
- anjos
- Apple
- aplicações
- Aplicar
- abordagem
- Aplicativos
- arquitetura
- argumentos
- Arte
- artigo
- artificial
- inteligência artificial
- Ativos
- por WhatsApp.
- atributos
- autores
- automatizar
- Automação
- fundo
- Bancário
- antes
- ser
- abaixo
- Benefícios
- Pouco
- Preto
- fronteira
- quebra
- navegador
- construir
- Prédio
- Constrói
- negócio
- negócios
- chamada
- câmeras
- candidato
- capital
- capturar
- casos
- desafiar
- desafios
- desafiante
- chinês
- escolha
- Escolha
- Cidades
- CNN
- código
- coletar
- Coluna
- combinações
- Empresas
- competição
- completamente
- integrações
- computador
- computadores
- conceito
- conectado
- Conexão de
- da conexão
- Coneções
- consistente
- Consumidores
- consumo
- contém
- conteúdo
- conteúdo
- ao controle
- Conversão
- núcleo
- Correspondente
- cobrir
- crio
- Créditos
- colheita
- crucial
- personalizadas
- Clientes
- dados,
- dia
- acordo
- lidar
- entregue
- Dependendo
- descrito
- projetado
- concepção
- detalhe
- detalhes
- detectou
- Detecção
- desenvolver
- dispositivo
- DID
- diferente
- difícil
- digital
- digitalizar
- dígitos
- diretamente
- discutir
- distância
- distribuído
- INSTITUCIONAIS
- domínio
- down
- desvantagens
- desenho
- durante
- borda
- eficientemente
- eliminado
- incorporado
- end-to-end
- Motor
- entrou
- entidades
- especialmente
- essencial
- fundamentos
- estimado
- etc.
- tudo
- exemplo
- Excel
- existente
- expandido
- vasta experiência
- expressões
- Extractos
- Rosto
- fatores
- falsificação
- famílias
- família
- RÁPIDO
- mais rápido
- Característica
- Funcionalidades
- retornos
- filtros
- Finalmente
- descoberta
- encontra
- Primeiro nome
- Primeiro Olhar
- caber
- seguir
- seguinte
- formulário
- formato
- formas
- encontrado
- Quadro
- Gratuito
- função
- Fundamentos
- mais distante
- gerar
- generativo
- gerador
- obtendo
- Bom estado, com sinais de uso
- Crescente
- Manipulação
- cabeça
- altura
- ajudar
- útil
- ajuda
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- hierarquia
- Alta
- Destaques
- Horizontal
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTTPS
- enorme
- humano
- Obstáculos
- identificar
- identificar
- imagem
- importante
- incluir
- inclui
- Incluindo
- Crescimento
- aumentando
- indivíduos
- industrial
- indústrias
- INFORMAÇÕES
- Infraestrutura
- entrada
- com seguro
- integrar
- Inteligência
- interação
- interseção
- questões
- IT
- Conhecimento
- conhecido
- Rótulos
- Idiomas
- grande
- camada
- conduzir
- APRENDER
- aprendido
- aprendizagem
- Biblioteca
- Line
- LINK
- Lista
- carregar
- localização
- longo
- máquina
- aprendizado de máquina
- FAZ
- manual
- manualmente
- fabrica
- mapa,
- mapas
- marca
- Máscaras
- Match
- correspondente
- material
- matemática
- a medida
- mencionado
- métodos
- Métrica
- poder
- milhão
- milhões
- mente
- Móvel Esteira
- telefone móvel
- celulares
- modelo
- modelos
- Mês
- mais
- a maioria
- múltiplo
- Nacional
- natural
- necessário
- Cria
- rede
- redes
- Ruído
- normal
- Notas
- número
- números
- modo offline
- online
- plataformas online
- operação
- Operações
- Otimize
- otimizado
- Opção
- ordem
- organizações
- Organizado
- organização
- Outros
- global
- próprio
- Papel
- parte
- particular
- Senha
- Patches
- padrão
- Pessoas
- atuação
- pessoal
- perspectiva
- fase
- telefones
- físico
- plástico
- Plataformas
- ponto
- piscina
- pobre
- Popular
- posição
- possível
- poder
- prática
- justamente
- predição
- Previsões
- presente
- apresentação de negócios
- anterior
- primário
- Problema
- problemas
- processo
- processos
- em processamento
- produzir
- Produção
- Agenda
- Programadores
- Programação
- Programas
- proposta
- proposto
- fornecer
- fornece
- fins
- qualidade
- Links
- rapidamente
- RE
- Leitura
- em tempo real
- reconhecer
- reconhece
- redução
- em relação a
- regular
- Relacionamentos
- permanecem
- substituído
- representar
- representação
- requerer
- requeridos
- exige
- pesquisa
- Resort
- Resultados
- retorno
- rever
- Execute
- Escala
- digitalização
- Pesquisar
- Setores
- segmentação
- Série
- serviço
- Serviços
- conjunto
- vários
- Baixo
- mostrando
- simples
- desde
- Tamanho
- pequeno
- So
- Software
- sólido
- solução
- Soluções
- RESOLVER
- alguns
- Espaço
- espaços
- divisão
- splits
- padrão
- começo
- Estado
- estado-da-arte
- estabelecido
- declarações
- estação
- armazenamento
- loja
- mais forte,
- estruturada
- estilo
- Subseqüentemente
- entraram com sucesso
- suportes
- .
- sistemas
- tomar
- tarefas
- imposto
- Profissionais
- técnicas
- Tecnologias
- conta
- modelos
- A fonte
- assim sendo
- limiar
- Através da
- todo
- tempo
- demorado
- vezes
- Título
- juntos
- ferramentas
- topo
- pista
- tradicional
- Training
- transferência
- Transformação
- TX
- tipos
- tipicamente
- ui
- para
- compreender
- compreensão
- Entendido
- único
- us
- usar
- geralmente
- validação
- valor
- vário
- versão
- VÍDEOS
- visão
- visualização
- W
- esperar
- web
- O Quê
- enquanto
- dentro
- sem
- Atividades:
- trabalhar
- escrita
- X
- ano
- Youtube