Agentes de sumarização imaginados pela ferramenta de geração de imagens AI Dall-E.
Você faz parte da população que deixa comentários no Google Maps toda vez que visita um novo restaurante?
Ou talvez você seja do tipo que compartilha sua opinião sobre compras na Amazon, especialmente quando é acionado por um produto de baixa qualidade?
Não se preocupe, não vou culpá-lo - todos nós temos nossos momentos!
No mundo dos dados de hoje, todos nós contribuímos para o dilúvio de dados de várias maneiras. Um tipo de dado que considero particularmente interessante por sua diversidade e dificuldade de interpretação são os dados textuais, como as inúmeras resenhas que são postadas na Internet todos os dias. Você já parou para pensar na importância de padronizar e condensar dados textuais? Bem-vindo ao mundo dos agentes de resumo!
Os agentes de resumo integraram-se perfeitamente em nossas vidas diárias, condensando informações e fornecendo acesso rápido a conteúdo relevante em uma infinidade de aplicativos e plataformas.
Neste artigo, exploraremos a utilização do ChatGPT como um poderoso agente de resumo para nossos aplicativos personalizados. Graças à capacidade de Large Language Models (LLM) para processar e compreender textos, eles podem auxiliar na leitura de textos e gerar resumos precisos ou padronizar informações. No entanto, é importante saber extrair o seu potencial na realização dessa tarefa, bem como reconhecer as suas limitações.
A maior limitação para o resumo? Os LLMs geralmente falham quando se trata de aderir a limitações específicas de caracteres ou palavras em seus resumos.
Vamos explorar as melhores práticas para gerar resumos com o ChatGPT para nosso aplicativo personalizado, bem como as razões por trás de suas limitações e como superá-las!
Agentes de resumo são usados em toda a Internet. Por exemplo, os sites usam agentes de resumo para oferecer resumos concisos de artigos, permitindo aos usuários obter uma visão geral rápida das notícias sem mergulhar em todo o conteúdo. As plataformas de mídia social e os mecanismos de pesquisa também fazem isso.
De agregadores de notícias e plataformas de mídia social a sites de comércio eletrônico, os agentes de resumo tornaram-se parte integrante de nosso cenário digital. E com o aumento dos LLMs, alguns desses agentes agora estão usando IA para obter resultados de resumo mais eficazes.
O ChatGPT pode ser um bom aliado na construção de uma aplicação utilizando agentes de sumarização para agilizar tarefas de leitura e classificação de textos. Por exemplo, imagine que temos um negócio de comércio eletrônico e estamos interessados em processar todas as avaliações de nossos clientes. O ChatGPT pode nos ajudar a resumir qualquer revisão em poucas frases, padronizando-a para um formato genérico, determinando o sentimento da revisão, e classificando isso de acordo.
Embora seja verdade que poderíamos simplesmente enviar a avaliação para o ChatGPT, há uma lista de práticas recomendadas — e coisas a evitar — para alavancar o poder do ChatGPT nesta tarefa concreta.
Vamos explorar as opções dando vida a este exemplo!
Exemplo: avaliações de comércio eletrônico
Gif feito por você mesmo.
Considere o exemplo acima em que estamos interessados em processar todas as avaliações de um determinado produto em nosso site de comércio eletrônico. Estaríamos interessados em processar avaliações como a seguinte sobre nosso produto estrela: o primeiro computador para crianças!
prod_review = """
I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlier
than expected, so I got to play with it myself before I gave it to him. """
Neste caso, gostaríamos que o ChatGPT:
Classifique a avaliação em positiva ou negativa.
Forneça um resumo da revisão de 20 palavras.
Envie a resposta com uma estrutura concreta para padronizar todas as revisões em um único formato.
Notas de Implementação
Aqui está a estrutura de código básica que poderíamos usar para solicitar o ChatGPT de nosso aplicativo personalizado. Eu também forneço um link para um Caderno Jupyter com todos os exemplos usados neste artigo.
import openai
import os openai.api_key_path = "/path/to/key" def get_completion(prompt, model="gpt-3.5-turbo"): """
This function calls ChatGPT API with a given prompt
and returns the response back. """ messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=0 ) return response.choices[0].message["content"] user_text = f"""
<Any given text> """ prompt = f"""
<Any prompt with additional text> """{user_text}""" """ # A simple call to ChatGPT
response = get_completion(prompt)
A função get_completion() chama a API ChatGPT com um determinado pronto. Se o prompt contiver informações adicionais texto do usuário, como a própria revisão em nosso caso, ela é separada do restante do código por aspas triplas.
Vamos usar o get_completion() função para solicitar ChatGPT!
Aqui está um prompt que atende aos requisitos descritos acima:
prompt = f"""
Your task is to generate a short summary of a product review from an e-commerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """
response = get_completion(prompt)
print(response)
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface and educational games. Volume could be louder.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Como podemos observar na saída, a revisão é precisa e bem estruturada, embora falta algumas informações que poderiam nos interessar como proprietários do e-commerce, como informações sobre a entrega do produto.
Resuma com foco em
Podemos melhorar iterativamente nosso prompt pedindo ao ChatGPT para se concentrar em certas coisas no resumo. Neste caso, estamos interessados em quaisquer detalhes fornecidos sobre o envio e a entrega:
prompt = f"""
Your task is to generate a short summary of a product review from an ecommerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words and focusing on any aspects that mention shipping and delivery of the product. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
Desta vez, a resposta do ChatGPT é a seguinte:
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface. Arrived a day earlier than expected.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Agora a revisão está muito mais completa. Fornecer detalhes sobre o foco importante da revisão original é crucial para evitar que o ChatGPT pule algumas informações que podem ser valiosas para o nosso caso de uso.
Você notou que, embora este segundo teste inclua informações sobre a entrega, ele pulou o único aspecto negativo da revisão original?
Vamos consertar isso!
“Extrair” em vez de “Resumir”
Ao investigar tarefas de sumarização, descobri que o resumo pode ser uma tarefa complicada para LLMs se o prompt do usuário não for preciso o suficiente.
Ao pedir ao ChatGPT para fornecer um resumo de um determinado texto, ele pode pular informações que podem ser relevantes para nós — como experimentamos recentemente — ou dará a mesma importância a todos os tópicos do texto, apresentando apenas uma visão geral dos pontos principais.
Especialistas em LLMs usam o termo extrato e informações adicionais sobre seus focos em vez de resumir ao fazer essas tarefas assistidas por esses tipos de modelos.
Enquanto o resumo visa fornecer uma visão geral concisa dos pontos principais do texto, incluindo tópicos não relacionados ao tópico em foco, a extração de informações se concentra na recuperação de detalhes específicos e pode nos dar exatamente o que estamos procurando. Vamos tentar então com extração!
prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department. From the review below, delimited by triple quotes extract the information relevant to shipping and delivery. Use 100 characters. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
Neste caso, usando a extração, obtemos apenas informações sobre o nosso tópico de foco: Shipping: Arrived a day earlier than expected.
Automatização
Este sistema funciona para uma única revisão. No entanto, ao projetar um prompt para um aplicativo concreto, é importante testá-lo em um lote de exemplos para que possamos detectar quaisquer outliers ou mau comportamento no modelo.
No caso de processar várias revisões, aqui está um exemplo de estrutura de código Python que pode ajudar.
reviews = [ "The children's computer I bought for my daughter is absolutely fantastic! She loves it and can't get enough of the educational games. The delivery was fast and arrived right on time. Highly recommend!", "I was really disappointed with the children's computer I received. It didn't live up to my expectations, and the educational games were not engaging at all. The delivery was delayed, which added to my frustration.", "The children's computer is a great educational toy. My son enjoys playing with it and learning new things. However, the delivery took longer than expected, which was a bit disappointing.", "I am extremely happy with the children's computer I purchased. It's highly interactive and keeps my kids entertained for hours. The delivery was swift and hassle-free.", "The children's computer I ordered arrived damaged, and some of the features didn't work properly. It was a huge letdown, and the delivery was also delayed. Not a good experience overall."
] prompt = f""" Your task is to generate a short summary of each product review from an e-commerce site. Extract positive and negative information from each of the given reviews below, delimited by triple backticks in at most 20 words each. Extract information about the delivery, if included. Review: ```{reviews}``` """
Aqui estão os resumos de nosso lote de análises:
1. Positive: Fantastic children's computer, fast delivery. Highly recommend.
2. Negative: Disappointing children's computer, unengaging games, delayed delivery.
3. Positive: Great educational toy, son enjoys it. Delivery took longer than expected.
4. Positive: Highly interactive children's computer, swift and hassle-free delivery.
5. Negative: Damaged children's computer, some features didn't work, delayed delivery.
⚠️ Observe que, embora a restrição de palavras de nossos resumos tenha sido clara o suficiente em nossos prompts, podemos ver facilmente que essa limitação de palavras não é realizada em nenhuma das iterações.
Essa incompatibilidade na contagem de palavras ocorre porque os LLMs não têm uma compreensão precisa da contagem de palavras ou caracteres. A razão por trás disso depende de um dos principais componentes importantes de sua arquitetura: o tokenizador.
Tokenizador
LLMs como o ChatGPT são projetados para gerar texto com base em padrões estatísticos aprendidos a partir de grandes quantidades de dados de idiomas. Embora sejam altamente eficazes na geração de texto fluente e coerente, carecem de controle preciso sobre a contagem de palavras.
Nos exemplos acima, quando demos instruções sobre uma contagem de palavras muito precisa, O ChatGPT estava lutando para atender a esses requisitos. Em vez disso, ele gerou um texto que é realmente menor do que a contagem de palavras especificada.
Em outros casos, pode gerar textos mais longos ou simplesmente textos excessivamente prolixos ou com falta de detalhes. Adicionalmente, O ChatGPT pode priorizar outros fatores, como coerência e relevância, em detrimento do cumprimento estrito da contagem de palavras. Isso pode resultar em um texto de alta qualidade em termos de conteúdo e coerência, mas que não corresponde exatamente ao requisito de contagem de palavras.
O tokenizador é o elemento-chave na arquitetura do ChatGPT que claramente influencia o número de palavras na saída gerada.
Gif feito por você mesmo.
Arquitetura do tokenizador
O tokenizer é o primeiro passo no processo de geração de texto. Ele é responsável por dividir o texto que inserimos no ChatGPT em elementos individuais — fichas —, que são então processados pelo modelo de linguagem para gerar um novo texto.
Quando o tokenizador divide um pedaço de texto em tokens, ele o faz com base em um conjunto de regras que são projetadas para identificar as unidades significativas do idioma de destino. No entanto, essas regras nem sempre são perfeitas e pode haver casos em que o tokenizador divide ou mescla tokens de uma maneira que afeta a contagem geral de palavras do texto.
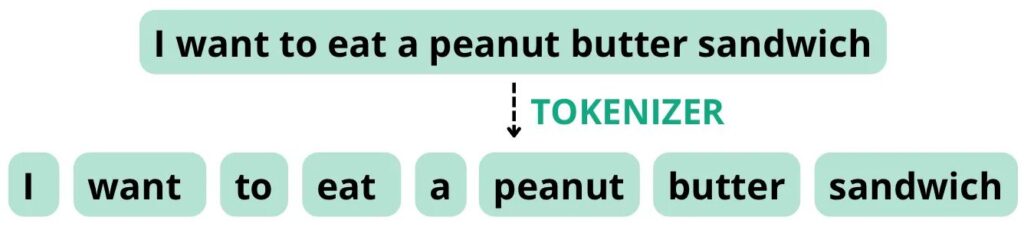
Por exemplo, considere a seguinte frase: “Quero comer um sanduíche de pasta de amendoim”. Se o tokenizador estiver configurado para dividir tokens com base em espaços e pontuação, ele pode dividir esta sentença nos seguintes tokens com uma contagem total de palavras de 8, igual à contagem de token.
Imagem feita por si.
No entanto, se o tokenizador estiver configurado para tratar "manteiga de amendoim" como uma palavra composta, pode dividir a frase nos seguintes tokens, com uma contagem total de palavras de 8, mas uma contagem de token de 7.
Assim, a forma como o tokenizador é configurado pode afetar a contagem geral de palavras do texto, e isso pode afetar a capacidade do LLM de seguir instruções sobre contagens precisas de palavras. Embora alguns tokenizers ofereçam opções para personalizar como o texto é tokenizado, isso nem sempre é suficiente para garantir a adesão precisa aos requisitos de contagem de palavras. Para ChatGPT neste caso, não podemos controlar esta parte de sua arquitetura.
Isso torna o ChatGPT não tão bom em realizar limitações de caracteres ou palavras, mas pode-se tentar com frases, pois o tokenizador não afeta o número de sentenças, mas seu comprimento.
Estar ciente dessa restrição pode ajudá-lo a criar o prompt mais adequado para seu aplicativo em mente. Tendo esse conhecimento sobre como a contagem de palavras funciona no ChatGPT, vamos fazer uma iteração final com nosso prompt para o aplicativo de comércio eletrônico!
Conclusão: avaliações de comércio eletrônico
Vamos combinar nossos aprendizados deste artigo em um prompt final! Neste caso, estaremos pedindo os resultados em HTML formato para uma saída mais agradável:
from IPython.display import display, HTML prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department and generic feedback from the product. From the review below, delimited by triple quotes construct an HTML table with the sentiment of the review, general feedback from
the product in two sentences and information relevant to shipping and delivery. Review: ```{prod_review}``` """ response = get_completion(prompt)
display(HTML(response))
E aqui está o resultado final do ChatGPT:
Captura de tela feita por você mesmo do Caderno Jupyter com os exemplos usados neste artigo.
Resumo
Neste artigo, discutimos as melhores práticas para usar o ChatGPT como um agente de resumo para nosso aplicativo personalizado.
Vimos que, ao criar um aplicativo, é extremamente difícil encontrar o prompt perfeito que corresponda aos requisitos do aplicativo no primeiro teste. Acho que uma boa mensagem para levar para casa é pense em solicitar como um processo iterativo onde você refina e modela seu prompt até obter exatamente a saída desejada.
Ao refinar iterativamente seu prompt e aplicá-lo a um lote de exemplos antes de implantá-lo na produção, você pode garantir a saída é consistente em vários exemplos e cobre respostas atípicas. No nosso exemplo, pode acontecer de alguém fornecer um texto aleatório em vez de uma crítica. Podemos instruir o ChatGPT a também ter uma saída padronizada para excluir essas respostas atípicas.
Além disso, ao usar o ChatGPT para uma tarefa específica, também é uma boa prática aprender sobre os prós e contras do uso de LLMs para nossa tarefa de destino. Foi assim que descobrimos que as tarefas de extração são mais eficazes do que o resumo quando queremos um resumo humano comum de um texto de entrada. Também aprendemos que fornecer o foco do resumo pode ser uma jogador desafiante sobre o conteúdo gerado.
Por fim, embora os LLMs possam ser altamente eficazes na geração de texto, eles não são ideais para seguir instruções precisas sobre contagem de palavras ou outros requisitos de formatação específicos. Para atingir esses objetivos, pode ser necessário limitar-se à contagem de sentenças ou utilizar outras ferramentas ou métodos, como edição manual ou softwares mais especializados.
Este artigo foi originalmente publicado em Rumo à ciência de dados e republicado no TOPBOTS com permissão do autor.
Gostou deste artigo? Inscreva-se para mais atualizações de pesquisa de IA.
Avisaremos quando lançarmos mais artigos de resumo como este.
Relacionado
Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.