Soluções generativas de IA têm o potencial de transformar os negócios, aumentando a produtividade e melhorando as experiências dos clientes, e o uso de grandes modelos de linguagem (LLMs) com essas soluções tem se tornado cada vez mais popular. Construir provas de conceito é relativamente simples porque modelos de fundação estão disponíveis em provedores especializados por meio de uma simples chamada de API. Portanto, organizações de vários tamanhos e de diferentes setores começaram a reimaginar os seus produtos e processos utilizando IA generativa.
Apesar de sua riqueza de conhecimentos gerais, os LLMs de última geração só têm acesso às informações nas quais foram treinados. Isto pode levar a imprecisões factuais (alucinações) quando o LLM é solicitado a gerar texto com base em informações que não viu durante a sua formação. Portanto, é crucial preencher a lacuna entre o conhecimento geral do LLM e seus dados proprietários para ajudar o modelo a gerar respostas mais precisas e contextuais, ao mesmo tempo que reduz o risco de alucinações. O método tradicional de ajuste fino, embora eficaz, pode exigir muita computação, ser caro e exigir conhecimentos técnicos. Outra opção a considerar é chamada Geração Aumentada de Recuperação (RAG), que fornece aos LLMs informações adicionais de uma fonte de conhecimento externa que pode ser facilmente atualizada.
Além disso, as empresas devem garantir a segurança dos dados ao lidar com dados proprietários e confidenciais, como dados pessoais ou propriedade intelectual. Isto é particularmente importante para organizações que operam em setores fortemente regulamentados, como serviços financeiros e cuidados de saúde e ciências da vida. Portanto, é importante compreender e controlar o fluxo dos seus dados através da aplicação generativa de IA: Onde está localizado o modelo? Onde os dados são processados? Quem tem acesso aos dados? Os dados serão usados para treinar modelos, arriscando eventualmente o vazamento de dados confidenciais para LLMs públicos?
Esta postagem discute como as empresas podem criar aplicativos generativos de IA precisos, transparentes e seguros, mantendo ao mesmo tempo controle total sobre dados proprietários. A solução proposta é um pipeline RAG usando uma pilha de tecnologia nativa de IA, cujos componentes são projetados desde o início com IA em seu núcleo, em vez de ter recursos de IA adicionados posteriormente. Demonstramos como construir uma aplicação RAG ponta a ponta usando Modelos de linguagem de Cohere NFT`s Rocha Amazônica e de um Weavie banco de dados de vetores no AWS Marketplace. O código-fonte que o acompanha está disponível no repositório GitHub relacionado hospedado por Weaviate. Embora a AWS não seja responsável por manter ou atualizar o código no repositório do parceiro, incentivamos os clientes a se conectarem diretamente com a Weaviate em relação a quaisquer atualizações desejadas.
Visão geral da solução
O diagrama de arquitetura de alto nível a seguir ilustra o pipeline RAG proposto com uma pilha de tecnologia nativa de IA para construir soluções de IA generativas precisas, transparentes e seguras.
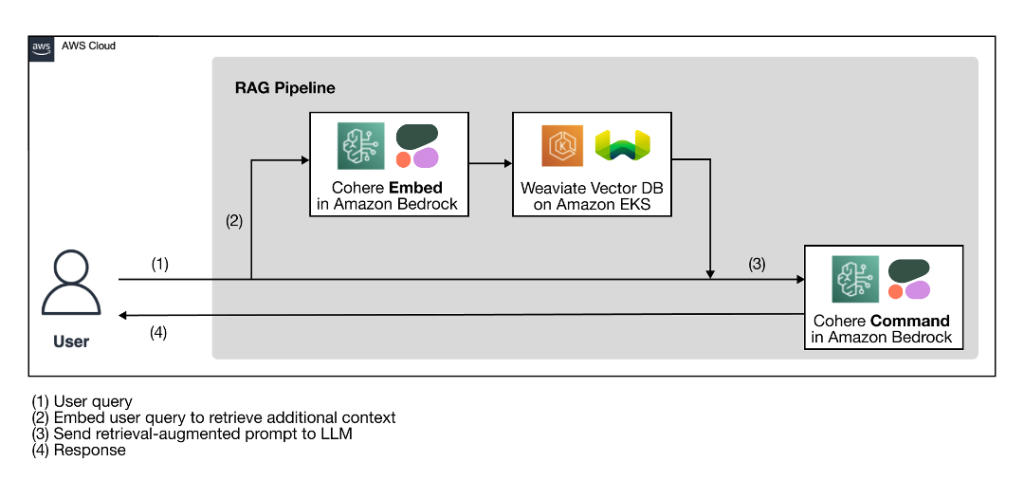
Figura 1: Fluxo de trabalho RAG usando modelos de linguagem Cohere por meio do Amazon Bedrock e um banco de dados vetorial Weaviate no AWS Marketplace
Como etapa de preparação para o fluxo de trabalho RAG, um banco de dados vetorial, que serve como fonte externa de conhecimento, é ingerido com o contexto adicional dos dados proprietários. O fluxo de trabalho RAG real segue as quatro etapas ilustradas no diagrama:
- O usuário insere sua consulta.
- A consulta do usuário é usada para recuperar contexto adicional relevante do banco de dados vetorial. Isso é feito gerando os embeddings vetoriais da consulta do usuário com um modelo de incorporação para realizar uma pesquisa vetorial para recuperar o contexto mais relevante do banco de dados.
- O contexto recuperado e a consulta do usuário são usados para aumentar um modelo de prompt. O prompt de recuperação aumentada ajuda o LLM a gerar uma conclusão mais relevante e precisa, minimizando alucinações.
- O usuário recebe uma resposta mais precisa com base em sua consulta.
A pilha de tecnologia nativa de IA ilustrada no diagrama de arquitetura tem dois componentes principais: modelos de linguagem Cohere e um banco de dados vetorial Weaviate.
Modelos de linguagem coerentes no Amazon Bedrock
A Plataforma Cohere traz modelos de linguagem com desempenho de última geração para empresas e desenvolvedores por meio de uma simples chamada de API. Existem dois tipos principais de recursos de processamento de linguagem que a Plataforma Cohere oferece – generativos e incorporados – e cada um é servido por um tipo diferente de modelo:
- Geração de texto de Command – Os desenvolvedores podem acessar endpoints que potencializam recursos generativos de IA, permitindo aplicações como conversação, resposta a perguntas, redação, resumo, extração de informações e muito mais.
- Representação de texto de Embutir – Os desenvolvedores podem acessar endpoints que capturam o significado semântico do texto, habilitando aplicativos como mecanismos de pesquisa vetorial, classificação e clustering de texto e muito mais. Cohere Embed vem em duas formas, um modelo em inglês e um modelo multilíngue, ambos agora disponível no Amazon Bedrock.
A plataforma Cohere permite que as empresas personalizem suas soluções de IA generativa de maneira privada e segura por meio da implantação do Amazon Bedrock. O Amazon Bedrock é um serviço de nuvem totalmente gerenciado que permite que equipes de desenvolvimento criem e dimensionem aplicações generativas de IA rapidamente ao mesmo tempo que ajuda a manter seus dados e aplicativos seguros e privados. Seus dados não são usados para melhorias de serviço, nunca são compartilhados com fornecedores de modelos terceirizados e permanecem no Região onde a chamada da API é processada. Os dados são sempre criptografados em trânsito e em repouso, e você pode criptografar os dados usando suas próprias chaves. O Amazon Bedrock oferece suporte a requisitos de segurança, incluindo elegibilidade à Lei de Portabilidade e Responsabilidade de Seguros de Saúde (HIPAA) dos EUA e conformidade com o Regulamento Geral de Proteção de Dados (GDPR). Além disso, você pode integrar com segurança e implantar facilmente seus aplicativos generativos de IA usando as ferramentas da AWS com as quais você já está familiarizado.
Weavie banco de dados de vetores no AWS Marketplace
Tecer é um Nativo de IA banco de dados de vetores isso torna mais fácil para as equipes de desenvolvimento criar aplicativos de IA generativos seguros e transparentes. Weaviate é usado para armazenar e pesquisar dados vetoriais e objetos de origem, o que simplifica o desenvolvimento, eliminando a necessidade de hospedar e integrar bancos de dados separados. O Weaviate oferece desempenho de pesquisa semântica em segundos e pode ser dimensionado para lidar com bilhões de vetores e milhões de locatários. Com uma arquitetura extensível exclusiva, o Weaviate se integra nativamente aos modelos básicos Cohere implantados no Amazon Bedrock para facilitar a vetorização conveniente de dados e usar seus recursos geradores no banco de dados.
O banco de dados vetorial nativo de IA da Weaviate oferece aos clientes a flexibilidade de implantá-lo como uma solução traga sua própria nuvem (BYOC) ou como um serviço gerenciado. Esta vitrine usa o Weaviate Kubernetes Cluster no AWS Marketplace, parte da oferta BYOC da Weaviate, que permite implantação escalonável baseada em contêiner dentro de seu locatário AWS e VPC com apenas alguns cliques usando um Formação da Nuvem AWS modelo. Essa abordagem garante que seu banco de dados vetorial seja implantado em sua região específica, próximo aos modelos básicos e aos dados proprietários, para minimizar a latência, dar suporte à localidade dos dados e proteger dados confidenciais, ao mesmo tempo em que atende a possíveis requisitos regulatórios, como o GDPR.
Visão geral do caso de uso
Nas seções a seguir, demonstramos como construir uma solução RAG usando a pilha de tecnologia nativa de IA com Cohere, AWS e Weaviate, conforme ilustrado na visão geral da solução.
O caso de uso de exemplo gera anúncios direcionados para listagens de estadias de férias com base em um público-alvo. O objetivo é usar a consulta do usuário para o público-alvo (por exemplo, “família com filhos pequenos”) para recuperar o anúncio de estadia de férias mais relevante (por exemplo, um anúncio com parques infantis próximos) e, em seguida, gerar um anúncio para o listagem recuperada adaptada ao público-alvo.

Figura 2: Primeiras linhas de anúncios de estadias de férias disponíveis no Inside Airbnb.
O conjunto de dados está disponível em Dentro do Airbnb e está licenciado sob uma Licença Internacional Creative Commons Attribution 4.0. Você pode encontrar o código que acompanha no Repositório GitHub.
Pré-requisitos
Para acompanhar e usar qualquer serviço da AWS no tutorial a seguir, certifique-se de ter um Conta da AWS.
Habilite componentes da pilha de tecnologia nativa de IA
Primeiro, você precisa habilitar os componentes relevantes discutidos na visão geral da solução em sua conta AWS. Conclua as seguintes etapas:
- No lado esquerdo Console Amazon Bedrock, escolha Acesso ao modelo no painel de navegação.
- Escolha Gerenciar o acesso ao modelo no canto superior direito.
- Selecione os modelos de fundação de sua preferência e solicite o acesso.
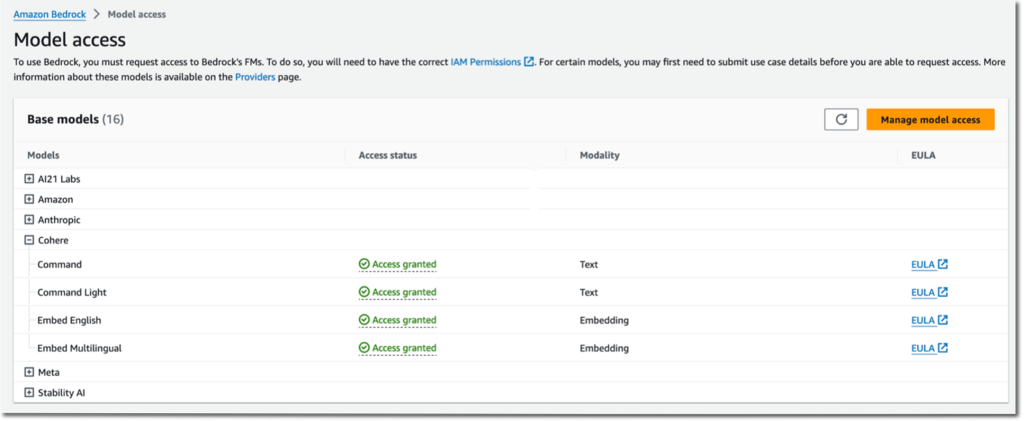
Figura 3: Gerenciar o acesso ao modelo no console do Amazon Bedrock.
Em seguida, você configura um cluster Weaviate.
- Assine o Weaviate Kubernetes Cluster no AWS Marketplace.
- Inicie o software usando um Modelo CloudFormation de acordo com sua zona de disponibilidade preferida.
O modelo CloudFormation é pré-preenchido com valores padrão.
- Escolha Nome da pilha, insira um nome de pilha.
- Escolha helmauthenticationtype, é recomendado ativar a autenticação configurando
helmauthenticationtypeparaapikeye definindo um helmauthenticationapikey. - Escolha helmauthenticationapikey, insira sua chave de API do Weaviate.
- Escolha versão do helmchart, insira o número da sua versão. Deve ser pelo menos v.16.8.0. Consulte o GitHub repo para a versão mais recente.
- Escolha módulos helmenabled, certificar-se de que
tex2vec-awsegenerative-awsestão presentes na lista de módulos habilitados no Weaviate.

Figura 4: modelo CloudFormation.
Este modelo leva cerca de 30 minutos para ser concluído.
Conecte-se ao Weaviate
Conclua as etapas a seguir para se conectar ao Weaviate:
- No Console do Amazon SageMaker, navegar para Instâncias de notebook no painel de navegação por meio de Portátil > Instâncias de notebook à esquerda.
- Crie uma nova instância de notebook.
- Instale o pacote do cliente Weaviate com as dependências necessárias:
- Conecte-se à sua instância do Weaviate com o seguinte código:
- URL de tecelagem – Acesse o Weaviate por meio da URL do balanceador de carga. No Amazon Elastic Compute Nuvem (Amazon EC2) console, escolha Balanceadores de carga no painel de navegação e encontre o balanceador de carga. Procure a coluna do nome DNS e adicione
http://na frente dele. - Chave de API Weaviate – Esta é a chave que você definiu anteriormente no modelo CloudFormation (
helmauthenticationapikey). - Chave de acesso AWS e chave de acesso secreta – Você pode recuperar a chave de acesso e a chave de acesso secreta do seu usuário no Gerenciamento de acesso e identidade da AWS (IAM).
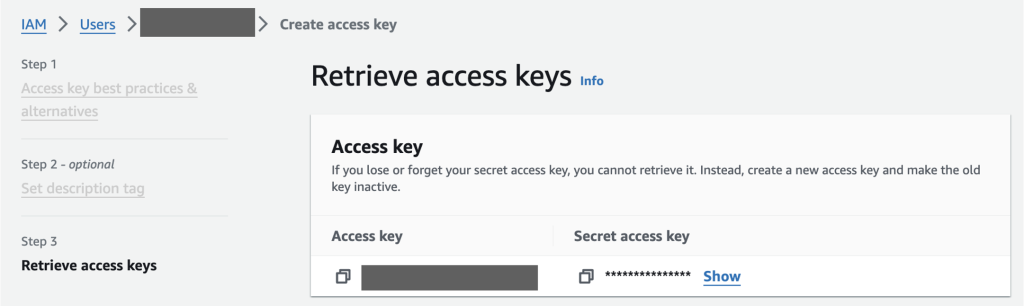
Figura 5: Console do AWS Identity and Access Management (IAM) para recuperar a chave de acesso e a chave de acesso secreta da AWS.
Configure o módulo Amazon Bedrock para habilitar modelos Cohere
A seguir, você define uma coleta de dados (class) chamado Listings para armazenar os objetos de dados das listagens, o que é análogo à criação de uma tabela em um banco de dados relacional. Nesta etapa, você configura os módulos relevantes para permitir o uso de modelos de linguagem Cohere hospedados no Amazon Bedrock nativamente no banco de dados de vetores Weaviate. O vetorizador (“text2vec-aws“) e módulo generativo (“generative-aws“) são especificados na definição de coleta de dados. Ambos os módulos utilizam três parâmetros:
- "serviço" - Usar "
bedrock”Para Amazon Bedrock (como alternativa, use“sagemaker" para JumpStart do Amazon SageMaker) - "Região" – Insira a região onde seu modelo está implantado
- "modelo" – Forneça o nome do modelo de fundação
Veja o seguinte código:
Ingerir dados no banco de dados vetorial do Weaviate
Nesta etapa, você define a estrutura da coleta de dados configurando suas propriedades. Além do nome e tipo de dados da propriedade, você também pode configurar se apenas o objeto de dados será armazenado ou se será armazenado junto com seus embeddings vetoriais. Neste exemplo, host_name e property_type não são vetorizados:
Execute o código a seguir para criar a coleção em sua instância do Weaviate:
Agora você pode adicionar objetos ao Weaviate. Você usa um processo de importação em lote para máxima eficiência. Execute o código a seguir para importar dados. Durante a importação, o Weaviate usará o vetorizador definido para criar uma incorporação vetorial para cada objeto. O código a seguir carrega objetos, inicializa um processo em lote e adiciona objetos à coleção de destino, um por um:
Geração Aumentada de Recuperação
Você pode construir um pipeline RAG implementando uma consulta de pesquisa generativa em sua instância do Weaviate. Para isso, primeiro você define um modelo de prompt na forma de uma string f que pode receber a consulta do usuário ({target_audience}) diretamente e o contexto adicional ({{host_name}}, {{property_type}}, {{description}} e {{neighborhood_overview}}) do banco de dados vetorial em tempo de execução:
Em seguida, você executa uma consulta de pesquisa generativa. Isso solicita ao modelo generativo definido um prompt que compreende a consulta do usuário, bem como os dados recuperados. A consulta a seguir recupera um objeto de listagem (.with_limit(1)) de Listings coleção que é mais semelhante à consulta do usuário (.with_near_text({"concepts": target_audience})). Em seguida, a consulta do usuário (target_audience) e as propriedades das listagens recuperadas (["description", "neighborhood", "host_name", "property_type"]) são inseridos no modelo de prompt. Veja o seguinte código:
No exemplo a seguir, você pode ver que o trecho de código anterior para target_audience = “Family with small children” recupera uma listagem do host Marre. O modelo de prompt é aumentado com os detalhes da listagem de Marre e o público-alvo:
Com base no prompt de recuperação aumentada, o modelo Command de Cohere gera o seguinte anúncio direcionado:
Personalizações alternativas
Você pode fazer personalizações alternativas em diferentes componentes da solução proposta, como os seguintes:
- Os modelos de linguagem da Cohere também estão disponíveis através JumpStart do Amazon SageMaker, que fornece acesso a modelos básicos de ponta e permite que os desenvolvedores implantem LLMs para Amazon Sage Maker, um serviço totalmente gerenciado que reúne um amplo conjunto de ferramentas para permitir aprendizado de máquina de alto desempenho e baixo custo para qualquer caso de uso. O Weaviate também está integrado ao SageMaker.
- Uma adição poderosa a esta solução é o Ponto final de reclassificação Cohere, disponível através do SageMaker JumpStart. A reclassificação pode melhorar a relevância dos resultados da pesquisa lexical ou semântica. A reclassificação funciona calculando pontuações de relevância semântica para documentos recuperados por um sistema de pesquisa e classificando os documentos com base nessas pontuações. Adicionar Reclassificação a um aplicativo requer apenas uma única linha de alteração de código.
- Para atender aos diferentes requisitos de implantação de diferentes ambientes de produção, o Weaviate pode ser implantado de várias maneiras adicionais. Por exemplo, está disponível para download direto em Site Weaviate, que roda em Serviço Amazon Elastic Kubernetes (Amazon EKS) ou localmente via Estivador or Kubernetes. Também está disponível como um serviço gerenciado que pode ser executado com segurança em uma VPC ou como um serviço de nuvem pública hospedado na AWS com uma avaliação gratuita de 14 dias.
- Você pode servir sua solução em uma VPC usando Nuvem virtual privada da Amazon (Amazon VPC), que permite que as organizações lancem serviços AWS em uma rede virtual logicamente isolada, semelhante a uma rede tradicional, mas com os benefícios da infraestrutura escalonável da AWS. Dependendo do nível classificado de confidencialidade dos dados, as organizações também podem desabilitar o acesso à Internet nessas VPCs.
limpar
Para evitar cobranças inesperadas, exclua todos os recursos implantados como parte desta postagem. Se você iniciou a pilha do CloudFormation, poderá excluí-la por meio do console do AWS CloudFormation. Observe que pode haver alguns recursos da AWS, como Loja de blocos elásticos da Amazon (Amazon EBS) volumes e Serviço de gerenciamento de chaves AWS (AWS KMS), que não podem ser excluídas automaticamente quando a pilha do CloudFormation é excluída.

Figura 6: Exclua todos os recursos por meio do console AWS CloudFormation.
Conclusão
Esta postagem discutiu como as empresas podem criar aplicativos generativos de IA precisos, transparentes e seguros e, ao mesmo tempo, ter controle total sobre seus dados. A solução proposta é um pipeline RAG usando uma pilha de tecnologia nativa de IA como uma combinação de modelos básicos Cohere no Amazon Bedrock e um banco de dados vetorial Weaviate no AWS Marketplace. A abordagem RAG permite que as empresas preencham a lacuna entre o conhecimento geral do LLM e os dados proprietários, ao mesmo tempo que minimizam as alucinações. Uma pilha de tecnologia nativa de IA permite desenvolvimento rápido e desempenho escalonável.
Você pode começar a experimentar provas de conceito RAG para seus aplicativos generativos de IA prontos para empresas usando as etapas descritas nesta postagem. O código-fonte que o acompanha está disponível no repositório GitHub relacionado. Obrigado por ler. Sinta-se à vontade para fornecer comentários ou feedback na seção de comentários.
Sobre os autores
 James Yi é arquiteto sênior de soluções de parceiros de IA/ML na equipe de tecnologia COE de parceiros de tecnologia da Amazon Web Services. Ele adora trabalhar com clientes empresariais e parceiros para projetar, implantar e dimensionar aplicativos de IA/ML para obter valor comercial. Fora do trabalho, ele gosta de jogar futebol, viajar e passar tempo com a família.
James Yi é arquiteto sênior de soluções de parceiros de IA/ML na equipe de tecnologia COE de parceiros de tecnologia da Amazon Web Services. Ele adora trabalhar com clientes empresariais e parceiros para projetar, implantar e dimensionar aplicativos de IA/ML para obter valor comercial. Fora do trabalho, ele gosta de jogar futebol, viajar e passar tempo com a família.
 Leonie Monigatti é um defensor do desenvolvedor na Weaviate. Sua área de foco é IA/ML e ela ajuda os desenvolvedores a aprender sobre IA generativa. Fora do trabalho, ela também compartilha seus aprendizados em ciência de dados e ML em seu blog e no Kaggle.
Leonie Monigatti é um defensor do desenvolvedor na Weaviate. Sua área de foco é IA/ML e ela ajuda os desenvolvedores a aprender sobre IA generativa. Fora do trabalho, ela também compartilha seus aprendizados em ciência de dados e ML em seu blog e no Kaggle.
 Melhor Amer é Developer Advocate na Cohere, fornecedora de tecnologia de ponta em processamento de linguagem natural (PNL). Ele ajuda os desenvolvedores a criar aplicativos de ponta com os Large Language Models (LLMs) da Cohere.
Melhor Amer é Developer Advocate na Cohere, fornecedora de tecnologia de ponta em processamento de linguagem natural (PNL). Ele ajuda os desenvolvedores a criar aplicativos de ponta com os Large Language Models (LLMs) da Cohere.
 Shun Mao é arquiteto sênior de soluções parceiras de IA/ML na equipe de tecnologias emergentes da Amazon Web Services. Ele adora trabalhar com clientes empresariais e parceiros para projetar, implantar e dimensionar aplicativos de IA/ML para derivar seus valores de negócios. Fora do trabalho, gosta de pescar, viajar e jogar pingue-pongue.
Shun Mao é arquiteto sênior de soluções parceiras de IA/ML na equipe de tecnologias emergentes da Amazon Web Services. Ele adora trabalhar com clientes empresariais e parceiros para projetar, implantar e dimensionar aplicativos de IA/ML para derivar seus valores de negócios. Fora do trabalho, gosta de pescar, viajar e jogar pingue-pongue.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/build-enterprise-ready-generative-ai-solutions-with-cohere-foundation-models-in-amazon-bedrock-and-weaviate-vector-database-on-aws-marketplace/
- :tem
- :é
- :não
- :onde
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 16
- 17
- 19
- 23
- 30
- 32
- 33
- 7
- 8
- 9
- a
- Sobre
- Acesso
- gerenciamento de acesso
- Segundo
- Conta
- responsabilidade
- preciso
- em
- Aja
- real
- adicionar
- adicionado
- acrescentando
- Adição
- Adicional
- Informação adicional
- Adicionalmente
- endereçando
- Adiciona
- adultos
- Anúncios
- advogado
- AI
- AI / ML
- Airbnb
- Todos os Produtos
- permite
- juntamente
- já
- tb
- alternativa
- Apesar
- sempre
- Amazon
- Amazon EC2
- Amazon Sage Maker
- Amazon Web Services
- amsterdam
- an
- e
- Outro
- responder
- qualquer
- api
- Aplicação
- aplicações
- abordagem
- arquitetura
- SOMOS
- ÁREA
- áreas
- AS
- de lado
- At
- atrações
- público
- aumentar
- aumentado
- Autenticação
- automaticamente
- disponibilidade
- disponível
- longe
- AWS
- Formação da Nuvem AWS
- AWS Identity and Access Management (IAM)
- Mercado da AWS
- balanceador
- barras
- baseado
- BE
- Porque
- tornam-se
- começou
- Benefícios
- MELHOR
- entre
- bilhões
- Bloquear
- Blog
- impulsionar
- ambos
- PONTE
- Traz
- amplo
- construir
- Prédio
- negócio
- negócios
- mas a
- by
- cafés
- chamada
- chamado
- CAN
- capacidades
- capturar
- casas
- fornecer
- central
- Centro
- alterar
- acusações
- Crianças
- escolha
- Escolha
- Cidades
- classe
- classificação
- classificado
- cliente
- Fechar
- Na nuvem
- Agrupar
- agrupamento
- código
- coleção
- Coluna
- combinação
- como
- vem
- comentários
- Commons
- completar
- realização
- compliance
- componentes
- Composto
- Computar
- computação
- conceito
- conceitos
- configurando
- Contato
- Considerar
- cônsul
- contexto
- contextual
- ao controle
- Conveniente
- convenientemente
- conversação
- copywriting
- núcleo
- crio
- Criar
- crucial
- cliente
- Clientes
- personalizar
- ponta
- dados,
- protecção de dados
- ciência de dados
- segurança dos dados
- banco de dados
- bases de dados
- Padrão
- definir
- definido
- definição
- definição
- entrega
- demonstrar
- dependências
- Dependendo
- implantar
- implantado
- desenvolvimento
- derivar
- descrição
- Design
- projetado
- desejado
- detalhes
- Developer
- desenvolvedores
- Desenvolvimento
- equipes de desenvolvimento
- diferente
- jantar
- diretamente
- diretamente
- discutido
- dns
- INSTITUCIONAIS
- feito
- download
- durante
- cada
- Mais cedo
- facilmente
- ebs
- Eficaz
- eficiência
- elevado
- elegibilidade
- eliminando
- embutir
- embutindo
- emergente
- tecnologias emergentes
- empodera
- permitir
- habilitado
- permite
- permitindo
- encorajar
- criptografada
- end-to-end
- endpoints
- Motores
- Inglês
- garantir
- garante
- Entrar
- Empreendimento
- clientes corporativos
- empresas
- Entra
- Todo
- ambientes
- Éter (ETH)
- eventualmente
- exemplo
- caro
- vasta experiência
- Experiências
- experiência
- externo
- Extração
- facilitar
- Fatual
- familiar
- família
- RÁPIDO
- Funcionalidades
- Apresentando
- Alimentado
- retornos
- sentir
- poucos
- Envie o
- financeiro
- serviços financeiros
- Encontre
- Primeiro nome
- Pescaria
- Flexibilidade
- Andar
- fluxo
- Foco
- seguir
- seguinte
- segue
- Escolha
- formulário
- formas
- Foundation
- quatro
- Gratuito
- teste grátis
- da
- frente
- cheio
- totalmente
- mais distante
- lacuna
- RGPD
- Geral
- dados gerais
- Regulamento geral de proteção de dados
- gerar
- gera
- gerando
- geração
- generativo
- IA generativa
- modelo generativo
- GitHub
- dá
- meta
- Solo
- Grupo
- Metade
- manipular
- Manipulação
- Ter
- ter
- he
- Título
- Saúde
- seguro de saúde
- saúde
- Coração
- fortemente
- ajudar
- ajuda
- ajuda
- sua experiência
- de alto nível
- alta performance
- sua
- Início
- hospedeiro
- hospedado
- Como funciona o dobrador de carta de canal
- Como Negociar
- http
- HTTPS
- IAM
- Identidade
- gerenciamento de identidade e acesso
- Gerenciamento de Identidade e Acesso (IAM)
- if
- ilustra
- implementação
- importar
- importante
- melhorar
- melhorias
- melhorar
- in
- Incluindo
- cada vez mais
- indústrias
- INFORMAÇÕES
- extração de informação
- Infraestrutura
- dentro
- instalar
- instância
- com seguro
- integrar
- integrado
- Integra-se
- intelectual
- propriedade intelectual
- Internacionais
- Internet
- Acesso à internet
- para dentro
- isolado
- IT
- ESTÁ
- jpg
- apenas por
- Guarda
- manutenção
- Chave
- chaves
- crianças
- Conhecimento
- Kubernetes
- língua
- grande
- Latência
- mais recente
- lançamento
- lançado
- conduzir
- Leads
- vazar
- APRENDER
- aprendizagem
- mínimo
- esquerda
- Nível
- Licenciado
- vida
- Ciências da Vida
- Line
- Lista
- listagem
- Anúncios
- vida
- carregar
- cargas
- local
- localmente
- localizado
- localização
- olhar
- procurando
- baixo custo
- máquina
- aprendizado de máquina
- manutenção
- fazer
- FAZ
- gerencia
- gerenciados
- de grupos
- marketplace
- dominar
- máximo
- Posso..
- significado
- significa
- Memórias
- método
- milhões
- minimizar
- minimizando
- minutos
- ML
- modelo
- modelos
- módulo
- Módulos
- mais
- a maioria
- devo
- nome
- nativamente
- natural
- Linguagem Natural
- Processamento de linguagem natural
- Navegar
- Navegação
- você merece...
- rede
- nunca
- Novo
- PNL
- não
- nota
- caderno
- agora
- número
- objeto
- objetos
- of
- oferecer
- oferecendo treinamento para distância
- on
- ONE
- só
- operando
- Opção
- or
- organizações
- Outros
- A Nossa
- delineado
- lado de fora
- Acima de
- Visão geral
- próprio
- pacote
- pago
- pandas
- pão
- parâmetros
- estacionamento
- parte
- particularmente
- parceiro
- Parceiros
- apaixonado
- perfeita
- realizar
- atuação
- pessoal
- dados pessoais
- peça
- oleoduto
- Lugar
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogar
- Popular
- portabilidade
- Publique
- potencial
- poder
- poderoso
- precedente
- preferido
- preparação
- presente
- evitar
- privado
- processo
- processado
- processos
- em processamento
- Produção
- produtividade
- Produtos
- solicita
- provas
- Propriedades
- propriedade
- proposto
- proprietário
- proteger
- proteção
- fornecer
- provedor
- fornecedores
- fornece
- público
- nuvem pública
- questão
- rapidamente
- trapo
- Posição
- em vez
- RE
- Leia
- Leitura
- recebe
- Recomenda
- redução
- referir
- em relação a
- região
- regulamentadas
- indústrias reguladas
- Regulamento
- reguladores
- relativamente
- relevância
- relevante
- permanece
- repositório
- solicitar
- requeridos
- Requisitos
- exige
- assemelhando-se
- Recursos
- resposta
- respostas
- responsável
- DESCANSO
- Restaurantes
- resultar
- Resultados
- certo
- Risco
- arriscando
- Quarto
- LINHA
- Execute
- é executado
- s
- sábio
- escalável
- Escala
- Ciência
- CIÊNCIAS
- pontuações
- Pesquisar
- Mecanismos de busca
- Segredo
- Seção
- seções
- seguro
- firmemente
- segurança
- Vejo
- semântico
- senior
- sensível
- Sensibilidade
- separado
- servir
- servido
- serve
- serviço
- Serviços
- conjunto
- contexto
- compartilhado
- ações
- ela
- Baixo
- mostrar
- semelhante
- simples
- simplifica
- solteiro
- tamanhos
- pequeno
- futebol
- Software
- solução
- Soluções
- alguns
- fonte
- código fonte
- Espaço
- especializado
- específico
- especificada
- Passar
- pilha
- começo
- estado-da-arte
- ficar
- Passo
- Passos
- Ainda
- loja
- armazenadas
- franco
- estrutura
- tal
- adequado
- ajuda
- suportes
- certo
- .
- mesa
- adaptados
- Tire
- toma
- Target
- visadas
- Profissionais
- equipes
- tecnologia
- Dados Técnicos:
- Tecnologias
- Tecnologia
- modelo
- inquilino
- texto
- Classificação de Texto
- do que
- obrigado
- que
- A
- as informações
- deles
- então
- Lá.
- assim sendo
- Este
- deles
- De terceiros
- isto
- três
- Através da
- tempo
- para
- juntos
- ferramentas
- topo
- tradicional
- Trem
- treinado
- Training
- Transformar
- trânsito
- transparente
- Viagens
- julgamento
- tutorial
- dois
- tipo
- tipos
- nos
- para
- compreender
- Inesperado
- inesquecível
- unicamente
- Atualizada
- Atualizações
- atualização
- andar de cima
- URL
- Uso
- usar
- caso de uso
- usava
- Utilizador
- usos
- utilização
- férias
- valor
- Valores
- vário
- Ve
- versão
- via
- Virtual
- volumes
- andar
- Caminho..
- maneiras
- we
- Riqueza
- web
- serviços web
- boas-vindas
- BEM
- foram
- quando
- qual
- enquanto
- QUEM
- de quem
- precisarão
- de
- dentro
- Atividades:
- de gestão de documentos
- trabalhar
- trabalho
- escrever
- Você
- investimentos
- zefirnet