Amazon RedShift é um data warehouse em nuvem rápido e totalmente gerenciado em escala de petabytes que torna simples e econômica a análise de todos os seus dados usando SQL padrão e suas ferramentas de business intelligence (BI) existentes. Dezenas de milhares de clientes hoje usam o Amazon Redshift para analisar exabytes de dados e executar consultas analíticas, tornando-o o data warehouse em nuvem mais utilizado. O Amazon Redshift está disponível em configurações sem servidor e provisionadas.
O Amazon Redshift permite acessar diretamente os dados armazenados em Serviço de armazenamento simples da Amazon (Amazon S3) usando consultas SQL e una dados em seu data warehouse e data lake. Com o Amazon Redshift, você pode consultar os dados no data lake do S3 usando uma central Cola AWS metastore do seu data warehouse do Redshift.
O Amazon Redshift oferece suporte à consulta de uma ampla variedade de formatos de dados, como CSV, JSON, Parquet e ORC, e formatos de tabela, como Apache Hudi e Delta. O Amazon Redshift também oferece suporte à consulta de dados aninhados com tipos de dados complexos, como struct, array e map.
Com esse recurso, o Amazon Redshift estende seu data warehouse em escala de petabytes para um data lake em escala de exabytes no Amazon S3 de maneira econômica.
Apache Iceberg é o formato de tabela mais recente compatível agora em versão prévia pelo Amazon Redshift. Nesta postagem, mostramos como consultar tabelas Iceberg usando o Amazon Redshift e explorar o suporte e as opções do Iceberg.
Visão geral da solução
Iceberg Apache é um formato de tabela aberto para conjuntos de dados analíticos muito grandes em escala de petabytes. O Iceberg gerencia grandes coleções de arquivos como tabelas e oferece suporte a operações modernas de data lake analítico, como inserção, atualização, exclusão e consultas de viagem no tempo em nível de registro. A especificação Iceberg permite a evolução contínua da tabela, como a evolução do esquema e da partição, e seu design é otimizado para uso no Amazon S3.
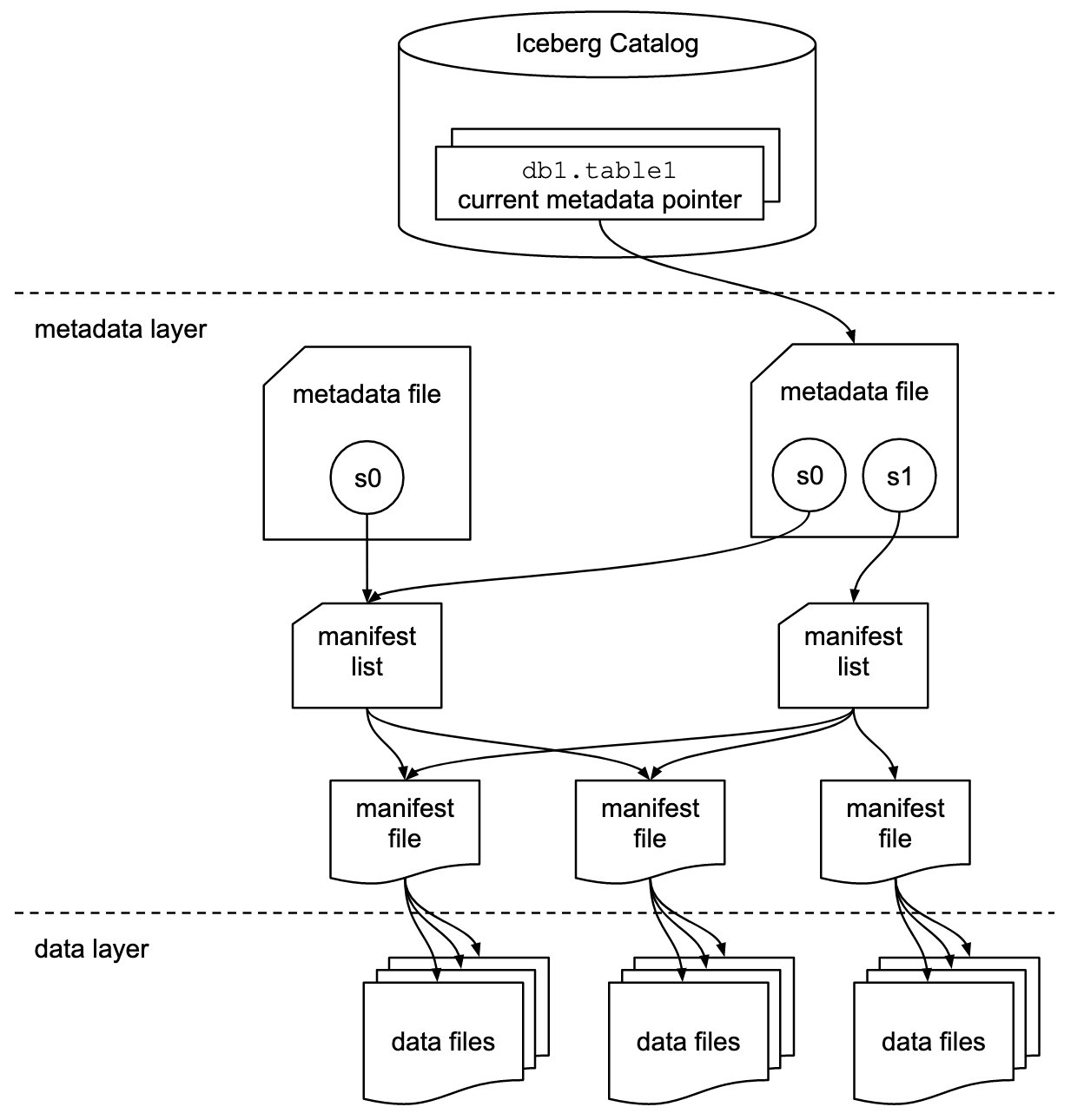
Iceberg armazena o ponteiro de metadados para todos os arquivos de metadados. Quando uma consulta SELECT está lendo uma tabela Iceberg, o mecanismo de consulta primeiro vai para o catálogo Iceberg e, em seguida, recupera a entrada do local do arquivo de metadados mais recente, conforme mostrado no diagrama a seguir.
O Amazon Redshift agora oferece suporte para tabelas Apache Iceberg, o que permite que os clientes de data lake executem consultas analíticas somente leitura de maneira transacionalmente consistente. Isso permite que você gerencie e mantenha facilmente suas tabelas em data lakes transacionais.
O Amazon Redshift oferece suporte ao esquema nativo do Apache Iceberg e aos recursos de evolução de partição usando o Catálogo de dados do AWS Glue, eliminando a necessidade de alterar definições de tabela para adicionar novas partições ou mover e processar grandes quantidades de dados para alterar o esquema de uma tabela de data lake existente. O Amazon Redshift usa as estatísticas de coluna armazenadas nos metadados da tabela Apache Iceberg para otimizar seus planos de consulta e reduzir as verificações de arquivos necessárias para executar consultas.
Nesta postagem, usamos o Conjunto de dados públicos de táxi amarelo da NYC Taxi & Limousine Commission como nossos dados de origem. O conjunto de dados contém arquivos de dados em Parquet Apache formato no Amazon S3. Nós usamos Amazona atena para converter este conjunto de dados Parquet e depois usar Espectro Amazon Redshift para consultar e ingressar em uma tabela local do Redshift, realizar exclusões e atualizações em nível de linha e evolução de partições, tudo coordenado por meio do Catálogo de dados do AWS Glue em um data lake S3.
Pré-requisitos
Você deve ter os seguintes pré-requisitos:
Converter dados do Parquet em uma tabela Iceberg
Para esta postagem, você precisa do Conjunto de dados públicos de táxi amarelo da NYC Taxi & Limousine Commission disponível no formato Iceberg. Você pode fazer download dos arquivos e usar o Athena para converter o conjunto de dados Parquet em uma tabela Iceberg ou consultar Crie um data lake Apache Iceberg usando Amazon Athena, Amazon EMR e AWS Glue postagem no blog para criar a tabela Iceberg.
Neste post, usamos Athena para converter os dados. Conclua as seguintes etapas:
- Baixe os arquivos usando o link anterior ou use o Interface de linha de comando da AWS (AWS CLI) para copiar os arquivos do bucket S3 público dos anos 2020 e 2021 para seu bucket S3 usando o seguinte comando:
Para mais informações, consulte Configurar a CLI do Amazon Redshift.
- Crie um banco de dados
Icebergdbe crie uma tabela usando Athena apontando para os arquivos no formato Parquet usando a seguinte instrução: - Valide os dados na tabela Parquet usando o seguinte SQL:

- Crie uma tabela Iceberg no Athena com o código a seguir. Você pode ver as propriedades do tipo de tabela como uma tabela Iceberg com formato Parquet e compactação rápida a seguir
create tabledeclaração. Você precisa atualizar o local do S3 antes de executar o SQL. Observe também que a tabela Iceberg é particionada com oYearchave. - Depois de criar a tabela, carregue os dados na tabela Iceberg usando a tabela Parquet carregada anteriormente
nyc_taxi_yellow_parquetcom o seguinte SQL: - Quando a instrução SQL for concluída, valide os dados na tabela Iceberg
nyc_taxi_yellow_iceberg. Esta etapa é necessária antes de passar para a próxima etapa. - Você pode validar se a tabela nyc_taxi_yellow_iceberg está no formato Iceberg e particionada na coluna Ano usando o seguinte comando:



Criar um esquema externo no Amazon Redshift
Nesta seção, demonstramos como criar um esquema externo no Amazon Redshift apontando para o banco de dados AWS Glue icebergdb para consultar a tabela Iceberg nyc_taxi_yellow_iceberg que vimos na seção anterior usando Athena.
Faça login no Redshift via Editor de consultas v2 ou um cliente SQL e execute o seguinte comando (observe que o banco de dados AWS Glue icebergdb e informações de região estão sendo usadas):

Para saber mais sobre a criação de esquemas externos no Amazon Redshift, consulte criar esquema externo
Depois de criar o esquema externo spectrum_iceberg_schema, você pode consultar a tabela Iceberg no Amazon Redshift.
Consulte a tabela Iceberg no Amazon Redshift
Execute a seguinte consulta no Query Editor v2. Observe que spectrum_iceberg_schema é o nome do esquema externo criado no Amazon Redshift e nyc_taxi_yellow_iceberg é a tabela no banco de dados AWS Glue usada na consulta:
A saída de dados de consulta na captura de tela a seguir mostra que a tabela AWS Glue com formato Iceberg pode ser consultada usando o Redshift Spectrum.

Verifique o plano de explicação de consulta da tabela Iceberg
Você pode usar a consulta a seguir para obter a saída do plano de explicação, que mostra que o formato é ICEBERG:

Valide atualizações para consistência de dados
Depois que a atualização for concluída na tabela Iceberg, você poderá consultar o Amazon Redshift para ver a visualização transacionalmente consistente dos dados. Vamos executar uma consulta escolhendo um vendorid e para uma determinada coleta e entrega:

A seguir, atualize o valor de passenger_count para 4 e trip_distance a 9.4 por um vendorid e certas datas de coleta e entrega em Athena:

Por fim, execute a seguinte consulta no Query Editor v2 para ver o valor atualizado de passenger_count e trip_distance:
Conforme mostrado na captura de tela a seguir, as operações de atualização na tabela Iceberg estão disponíveis no Amazon Redshift.

Crie uma visualização unificada da tabela local e dos dados históricos no Amazon Redshift
Como uma estratégia moderna de arquitetura de dados, você pode organizar dados históricos ou dados acessados com menos frequência no data lake e manter os dados acessados com frequência no data warehouse do Redshift. Isso proporciona flexibilidade para gerenciar análises em escala e encontrar a solução de arquitetura mais econômica.
Neste exemplo, carregamos 2 anos de dados em uma tabela Redshift; o restante dos dados permanece no data lake S3 porque esse conjunto de dados é consultado com menos frequência.
- Use o código a seguir para carregar 2 anos de dados no
nyc_taxi_yellow_recenttabela no Amazon Redshift, proveniente da tabela Iceberg:
- Em seguida, você pode remover os dados dos últimos 2 anos da tabela Iceberg usando o seguinte comando no Athena porque você carregou os dados em uma tabela Redshift na etapa anterior:

Depois de concluir essas etapas, a tabela Redshift terá dois anos de dados e o restante dos dados estará na tabela Iceberg no Amazon S2.
- Crie uma visualização usando o
nyc_taxi_yellow_icebergMesa de iceberg enyc_taxi_yellow_recenttabela no Amazon Redshift: - Agora consulte a visualização, dependendo das condições do filtro, o Redshift Spectrum irá verificar os dados do Iceberg, a tabela Redshift ou ambos. O exemplo de consulta a seguir retorna vários registros de cada uma das tabelas de origem verificando ambas as tabelas:

Evolução da partição
Usos do iceberg particionamento oculto, o que significa que você não precisa adicionar partições manualmente às tabelas do Apache Iceberg. Novos valores de partição ou novas especificações de partição (adicionar ou remover colunas de partição) nas tabelas do Apache Iceberg são detectados automaticamente pelo Amazon Redshift e nenhuma operação manual é necessária para atualizar partições na definição da tabela. O exemplo a seguir demonstra isso.
No nosso exemplo, se a tabela Iceberg nyc_taxi_yellow_iceberg foi originalmente particionado por ano e mais tarde a coluna vendorid foi adicionado como uma coluna de partição adicional, o Amazon Redshift poderá consultar perfeitamente a tabela Iceberg nyc_taxi_yellow_iceberg com dois esquemas de partição diferentes durante um período de tempo.

Considerações ao consultar tabelas Iceberg usando o Amazon Redshift
Durante o período de visualização, considere o seguinte ao usar o Amazon Redshift com tabelas Iceberg:
- Somente tabelas Iceberg definidas no Catálogo de dados do AWS Glue são compatíveis.
- Os comandos de tabela externa CREATE ou ALTER não são compatíveis, o que significa que a tabela Iceberg já deve existir em um banco de dados do AWS Glue.
- Consultas de viagem no tempo não são suportadas.
- As versões 1 e 2 do Iceberg são suportadas. Para obter mais detalhes sobre as versões do formato Iceberg, consulte Versão do formato.
- Para obter uma lista de tipos de dados suportados com tabelas Iceberg, consulte Tipos de dados suportados com tabelas Apache Iceberg (pré-visualização).
- O preço para consultar uma tabela Iceberg é o mesmo que para acessar qualquer outro formato de dados usando o Amazon Redshift.
Para obter detalhes adicionais sobre considerações para visualização de tabelas no formato Iceberg, consulte Usar tabelas do Apache Iceberg com o Amazon Redshift (pré-visualização).
Feedback do cliente
“A Tinuiti, a maior empresa independente de marketing de desempenho, lida diariamente com grandes volumes de dados e deve ter uma estratégia robusta de data lake e data warehouse para que nossas equipes de inteligência de mercado armazenem e analisem todos os dados de nossos clientes de maneira fácil, acessível e segura. , e robusto”, afirma Justin Manus, diretor de tecnologia da Tinuiti. “O suporte do Amazon Redshift para tabelas Apache Iceberg em nosso data lake, que é a única fonte de verdade, aborda um desafio crítico na otimização do desempenho e da acessibilidade e simplifica ainda mais nossos pipelines de integração de dados para acessar todos os dados ingeridos de diferentes fontes e para potencializar nossos potencial da marca dos clientes.”
Conclusão
Nesta postagem, mostramos um exemplo de consulta de uma tabela Iceberg no Redshift usando arquivos armazenados no Amazon S3, catalogados como uma tabela no AWS Glue Data Catalog, e demonstramos alguns dos principais recursos, como atualização e exclusão eficiente em nível de linha, e a experiência de evolução de esquema para que os usuários possam aproveitar o poder do big data usando o Athena.
Você pode usar o Amazon Redshift para executar consultas em tabelas de data lake em vários arquivos e formatos de tabela, como Apache Hudi e Lago Delta, e agora com Apache Iceberg (visualização), que fornece opções adicionais para suas necessidades de arquiteturas de dados modernas.
Esperamos que isso seja um excelente ponto de partida para consultar tabelas Iceberg no Amazon Redshift.
Sobre os autores
 Rohit Bansal é um arquiteto de soluções especialista em análise na AWS. Ele é especializado no Amazon Redshift e trabalha com clientes para criar soluções analíticas de última geração usando outros serviços do AWS Analytics.
Rohit Bansal é um arquiteto de soluções especialista em análise na AWS. Ele é especializado no Amazon Redshift e trabalha com clientes para criar soluções analíticas de última geração usando outros serviços do AWS Analytics.
 Satish Sathiya é engenheiro de produto sênior na Amazon Redshift. Ele é um ávido entusiasta de big data que colabora com clientes em todo o mundo para alcançar o sucesso e atender às suas necessidades de armazenamento de dados e arquitetura de data lake.
Satish Sathiya é engenheiro de produto sênior na Amazon Redshift. Ele é um ávido entusiasta de big data que colabora com clientes em todo o mundo para alcançar o sucesso e atender às suas necessidades de armazenamento de dados e arquitetura de data lake.
 Ranjan Burman é um arquiteto de soluções especialista em análise na AWS. Ele é especialista no Amazon Redshift e ajuda os clientes a criar soluções analíticas escaláveis. Ele tem mais de 16 anos de experiência em diferentes tecnologias de banco de dados e armazenamento de dados. Ele é apaixonado por automatizar e resolver problemas de clientes com soluções em nuvem.
Ranjan Burman é um arquiteto de soluções especialista em análise na AWS. Ele é especialista no Amazon Redshift e ajuda os clientes a criar soluções analíticas escaláveis. Ele tem mais de 16 anos de experiência em diferentes tecnologias de banco de dados e armazenamento de dados. Ele é apaixonado por automatizar e resolver problemas de clientes com soluções em nuvem.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Automotivo / EVs, Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- ChartPrime. Eleve seu jogo de negociação com ChartPrime. Acesse aqui.
- BlockOffsets. Modernizando a Propriedade de Compensação Ambiental. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- :tem
- :é
- :não
- :onde
- $UP
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- Sobre
- Acesso
- acessadas
- acessibilidade
- acessando
- Alcançar
- em
- adicionar
- adicionado
- Adicional
- endereços
- acessível
- Todos os Produtos
- permite
- já
- tb
- Amazon
- Amazona atena
- Amazon EMR
- Amazon Web Services
- quantidades
- an
- Analítico
- Análises
- analítica
- analisar
- e
- qualquer
- apache
- arquitetura
- SOMOS
- por aí
- Ordem
- AS
- At
- automaticamente
- automatizando
- disponível
- AWS
- Cola AWS
- base
- Porque
- antes
- ser
- Grande
- Big Data
- obrigatório
- Blog
- ambos
- interesse?
- construir
- negócio
- inteligência de negócios
- by
- CAN
- capacidades
- capacidade
- catálogo
- central
- certo
- desafiar
- alterar
- chefe
- Chief Technology Officer
- cliente
- Na nuvem
- código
- coleções
- Coluna
- colunas
- completar
- integrações
- condições
- Considerar
- Considerações
- consistente
- contém
- converter
- coordenado
- relação custo-benefício
- crio
- criado
- Criar
- crítico
- cliente
- dados do cliente
- Clientes
- diariamente
- dados,
- integração de dados
- lago data
- data warehouse
- banco de dados
- conjuntos de dados
- Datas
- Padrão
- definido
- definição
- definições
- Delta
- demonstrar
- demonstraram
- demonstra
- Dependendo
- Design
- detalhes
- detectou
- Dev
- diferente
- diretamente
- não
- duplo
- download
- cada
- facilmente
- fácil
- editor
- eficiente
- ou
- eliminando
- permite
- Motor
- engenheiro
- entusiasta
- entrada
- Éter (ETH)
- evolução
- exemplo
- existir
- existente
- vasta experiência
- Explicação
- explorar
- se estende
- externo
- extra
- RÁPIDO
- Funcionalidades
- Envie o
- Arquivos
- filtro
- Encontre
- Empresa
- Primeiro nome
- Flexibilidade
- seguinte
- Escolha
- formato
- freqüentemente
- da
- totalmente
- mais distante
- ter
- dá
- globo
- vai
- ótimo
- Grupo
- Alças
- Ter
- he
- ajuda
- histórico
- esperança
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- if
- in
- de treinadores em Entrevista Motivacional
- INFORMAÇÕES
- integração
- Inteligência
- para dentro
- IT
- ESTÁ
- juntar
- jpg
- json
- Justin
- Guarda
- Chave
- lago
- grande
- maior
- Sobrenome
- mais tarde
- mais recente
- APRENDER
- menos
- como
- LIMITE
- Line
- LINK
- Lista
- carregar
- local
- localização
- a manter
- FAZ
- Fazendo
- gerencia
- gerenciados
- gestão
- maneira
- manual
- manualmente
- mapa,
- mercado
- Marketing
- significa
- Conheça
- metadados
- EQUIPAMENTOS
- mais
- a maioria
- mover
- em movimento
- devo
- nome
- nativo
- você merece...
- necessário
- Cria
- Novo
- Próximo
- próxima geração
- não
- nota
- agora
- número
- NYC
- of
- Oficial
- on
- aberto
- operação
- Operações
- Otimize
- otimizado
- otimizando
- Opções
- or
- originalmente
- Outros
- A Nossa
- saída
- Acima de
- página
- apaixonado
- realizar
- atuação
- significativo
- plano
- planos
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- Publique
- potencial
- poder
- pré-requisitos
- visualização
- anterior
- anteriormente
- problemas
- processo
- Produto
- Propriedades
- fornece
- público
- consultas
- Leitura
- registros
- reduzir
- região
- remover
- substituir
- requeridos
- DESCANSO
- Retorna
- uma conta de despesas robusta
- Execute
- corrida
- mesmo
- serra
- diz
- escalável
- Escala
- digitalização
- exploração
- digitaliza
- esquemas
- desatado
- sem problemas
- Seção
- seguro
- Vejo
- senior
- Serverless
- Serviços
- conjunto
- rede de apoio social
- mostrar
- mostrou
- mostrando
- Shows
- simples
- solteiro
- solução
- Soluções
- Resolvendo
- alguns
- fonte
- Fontes
- Origem
- especialista
- especializada
- especificação
- óculos
- Espectro
- SQL
- padrão
- Comece
- Declaração
- estatística
- Passo
- Passos
- armazenamento
- loja
- armazenadas
- lojas
- Estratégia
- Tanga
- sucesso
- tal
- ajuda
- Suportado
- suportes
- mesa
- equipes
- Tecnologias
- Tecnologia
- dezenas
- do que
- que
- A
- A fonte
- deles
- então
- Este
- isto
- milhares
- Através da
- tempo
- viagem no tempo
- timestamp
- para
- hoje
- ferramentas
- transacional
- viagens
- Verdade
- dois
- tipo
- tipos
- unificado
- união
- destravar
- Atualizar
- Atualizada
- Atualizações
- Uso
- usar
- usava
- usuários
- usos
- utilização
- VALIDAR
- valor
- Valores
- variedade
- vário
- muito
- via
- Ver
- volumes
- Armazém
- Armazenagem
- foi
- Caminho..
- we
- web
- serviços web
- quando
- qual
- QUEM
- Largo
- largamente
- precisarão
- de
- trabalho
- ano
- anos
- Você
- investimentos
- zefirnet