Ao implantar um modelo de linguagem grande (LLM), os profissionais de aprendizado de máquina (ML) normalmente se preocupam com duas medidas para o desempenho do serviço de modelo: latência, definida pelo tempo necessário para gerar um único token, e taxa de transferência, definida pelo número de tokens gerados por segundo. Embora uma única solicitação para o terminal implantado exiba uma taxa de transferência aproximadamente igual ao inverso da latência do modelo, esse não é necessariamente o caso quando diversas solicitações simultâneas são enviadas simultaneamente ao terminal. Devido às técnicas de serviço de modelo, como lote contínuo de solicitações simultâneas do lado do cliente, a latência e a taxa de transferência têm um relacionamento complexo que varia significativamente com base na arquitetura do modelo, nas configurações de serviço, no tipo de hardware da instância, no número de solicitações simultâneas e nas variações nas cargas úteis de entrada, como como número de tokens de entrada e tokens de saída.
Esta postagem explora essas relações por meio de um benchmarking abrangente de LLMs disponíveis no Amazon SageMaker JumpStart, incluindo as variantes Llama 2, Falcon e Mistral. Com o SageMaker JumpStart, os profissionais de ML podem escolher entre uma ampla seleção de modelos básicos disponíveis publicamente para implantar em servidores dedicados. Amazon Sage Maker instâncias em um ambiente isolado de rede. Fornecemos princípios teóricos sobre como as especificações do acelerador impactam o benchmarking LLM. Também demonstramos o impacto da implantação de múltiplas instâncias atrás de um único endpoint. Por fim, fornecemos recomendações práticas para adaptar o processo de implantação do SageMaker JumpStart para se alinhar aos seus requisitos de latência, taxa de transferência, custo e restrições nos tipos de instância disponíveis. Todos os resultados de benchmarking, bem como recomendações, são baseados em um versátil caderno que você pode adaptar ao seu caso de uso.
Comparativo de mercado de endpoint implantado
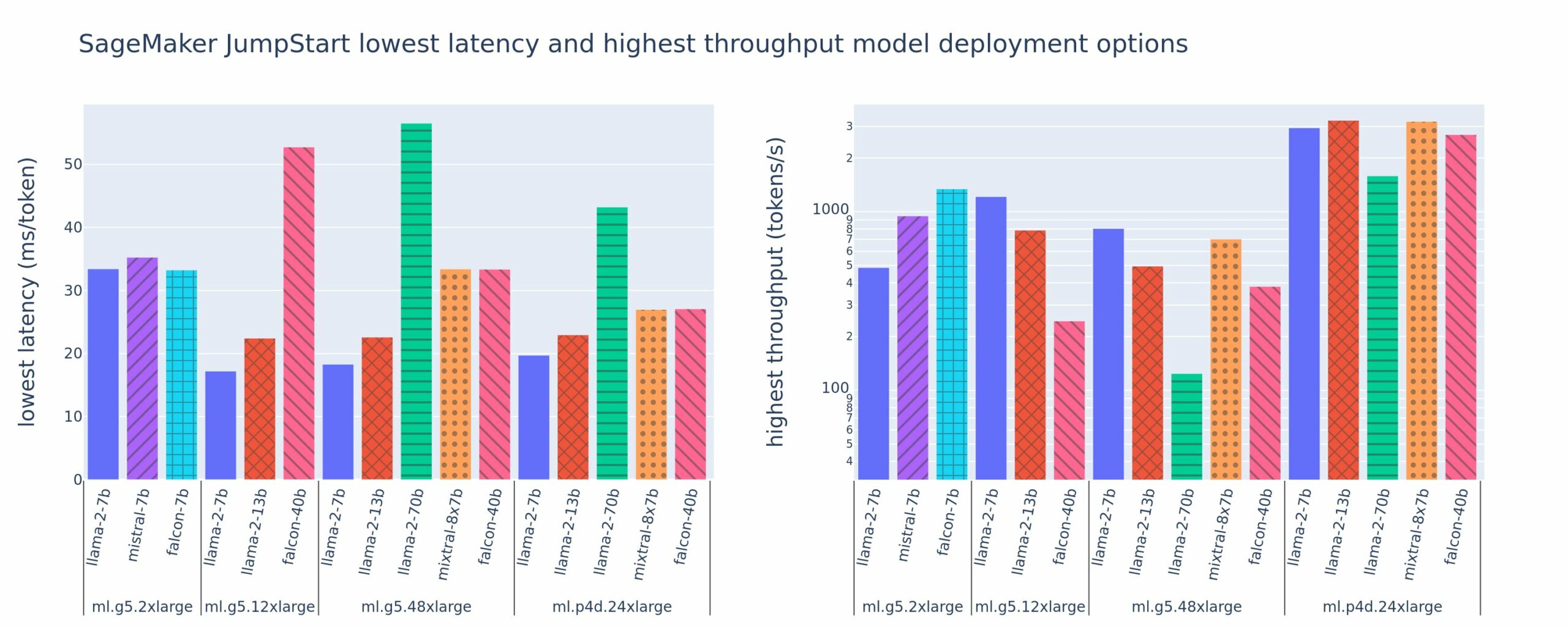
A figura a seguir mostra os valores de latência mais baixa (esquerda) e taxa de transferência mais alta (direita) para configurações de implantação em vários tipos de modelos e tipos de instância. É importante ressaltar que cada uma dessas implantações de modelo usa configurações padrão fornecidas pelo SageMaker JumpStart, considerando o ID do modelo desejado e o tipo de instância para implantação.
Esses valores de latência e taxa de transferência correspondem a cargas com 256 tokens de entrada e 256 tokens de saída. A configuração de menor latência limita o modelo que atende a uma única solicitação simultânea, e a configuração de maior rendimento maximiza o número possível de solicitações simultâneas. Como podemos ver em nosso benchmarking, o aumento de solicitações simultâneas aumenta monotonicamente o rendimento, com diminuição da melhoria para grandes solicitações simultâneas. Além disso, os modelos são totalmente fragmentados na instância compatível. Por exemplo, como a instância ml.g5.48xlarge tem 8 GPUs, todos os modelos SageMaker JumpStart que usam esta instância são fragmentados usando paralelismo de tensor em todos os oito aceleradores disponíveis.
Podemos observar algumas conclusões desta figura. Primeiro, nem todos os modelos são suportados em todas as instâncias; alguns modelos menores, como o Falcon 7B, não suportam fragmentação de modelo, enquanto modelos maiores têm requisitos de recursos de computação mais elevados. Em segundo lugar, à medida que a fragmentação aumenta, o desempenho normalmente melhora, mas pode não necessariamente melhorar para modelos pequenos. Isso ocorre porque modelos pequenos como 7B e 13B incorrem em uma sobrecarga de comunicação substancial quando fragmentados em muitos aceleradores. Discutiremos isso com mais profundidade posteriormente. Por fim, as instâncias ml.p4d.24xlarge tendem a ter um rendimento significativamente melhor devido às melhorias na largura de banda de memória do A100 em relação às GPUs A10G. Conforme discutiremos mais tarde, a decisão de usar um tipo de instância específico depende dos requisitos de implantação, incluindo latência, taxa de transferência e restrições de custo.
Como você pode obter esses valores de configuração de menor latência e maior rendimento? Vamos começar traçando latência versus taxa de transferência para um endpoint Llama 2 7B em uma instância ml.g5.12xlarge para uma carga útil com 256 tokens de entrada e 256 tokens de saída, conforme visto na curva a seguir. Existe uma curva semelhante para cada terminal LLM implantado.

À medida que a simultaneidade aumenta, a taxa de transferência e a latência também aumentam monotonicamente. Portanto, o ponto de latência mais baixo ocorre em um valor de solicitação simultânea de 1, e você pode aumentar o rendimento do sistema de maneira econômica aumentando as solicitações simultâneas. Existe um “joelho” distinto nesta curva, onde é óbvio que os ganhos de rendimento associados à simultaneidade adicional não compensam o aumento associado na latência. A localização exata deste joelho é específica para cada caso de uso; alguns profissionais podem definir o joelho no ponto onde um requisito de latência pré-especificado é excedido (por exemplo, 100 ms/token), enquanto outros podem usar benchmarks de teste de carga e métodos de teoria de filas, como a regra de meia latência, e outros podem usar especificações teóricas do acelerador.
Observamos também que o número máximo de solicitações simultâneas é limitado. Na figura anterior, o rastreamento de linha termina com 192 solicitações simultâneas. A origem dessa limitação é o limite de tempo limite de invocação do SageMaker, em que os endpoints do SageMaker atingem o tempo limite de uma resposta de invocação após 60 segundos. Essa configuração é específica da conta e não pode ser configurada para um endpoint individual. Para LLMs, a geração de um grande número de tokens de saída pode levar segundos ou até minutos. Portanto, grandes cargas úteis de entrada ou saída podem causar falha nas solicitações de invocação. Além disso, se o número de solicitações simultâneas for muito grande, muitas solicitações passarão por longos tempos de fila, gerando esse limite de tempo limite de 60 segundos. Para os fins deste estudo, usamos o limite de tempo limite para definir o rendimento máximo possível para uma implantação de modelo. É importante ressaltar que, embora um endpoint do SageMaker possa lidar com um grande número de solicitações simultâneas sem observar um tempo limite de resposta de invocação, você pode querer definir o máximo de solicitações simultâneas em relação ao joelho na curva de latência-taxa de transferência. Este é provavelmente o ponto em que você começa a considerar o dimensionamento horizontal, onde um único endpoint provisiona múltiplas instâncias com réplicas de modelo e equilibra a carga de solicitações recebidas entre as réplicas, para suportar mais solicitações simultâneas.
Indo um passo adiante, a tabela a seguir contém resultados de benchmarking para diferentes configurações do modelo Llama 2 7B, incluindo diferentes números de tokens de entrada e saída, tipos de instância e número de solicitações simultâneas. Observe que a figura anterior representa apenas uma única linha desta tabela.
| . | Taxa de transferência (tokens/s) | Latência (ms/token) | ||||||||||||||||||
| Solicitações Simultâneas | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Número total de tokens: 512, Número de tokens de saída: 256 | ||||||||||||||||||||
| ml.g5.2xgrande | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xgrande | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xgrande | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xgrande | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Número total de tokens: 4096, Número de tokens de saída: 256 | ||||||||||||||||||||
| ml.g5.2xgrande | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xgrande | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xgrande | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xgrande | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
Observamos alguns padrões adicionais nesses dados. Ao aumentar o tamanho do contexto, a latência aumenta e a taxa de transferência diminui. Por exemplo, em ml.g5.2xlarge com uma simultaneidade de 1, a taxa de transferência é de 30 tokens/s quando o número total de tokens for 512, versus 20 tokens/s se o número total de tokens for 4,096. Isso ocorre porque leva mais tempo para processar a entrada maior. Também podemos ver que o aumento da capacidade e da fragmentação da GPU afeta o rendimento máximo e o máximo de solicitações simultâneas suportadas. A tabela mostra que o Llama 2 7B tem valores de rendimento máximo notavelmente diferentes para diferentes tipos de instância, e esses valores de rendimento máximo ocorrem em valores diferentes de solicitações simultâneas. Essas características levariam um profissional de ML a justificar o custo de uma instância em detrimento de outra. Por exemplo, dado um requisito de baixa latência, o profissional pode selecionar uma instância ml.g5.12xlarge (4 GPUs A10G) em vez de uma instância ml.g5.2xlarge (1 GPU A10G). Se for necessário um requisito de alto rendimento, o uso de uma instância ml.p4d.24xlarge (8 GPUs A100) com fragmentação total só seria justificado em alta simultaneidade. Observe, entretanto, que muitas vezes é benéfico carregar vários componentes de inferência de um modelo 7B em uma única instância ml.p4d.24xlarge; esse suporte multimodelo será discutido posteriormente nesta postagem.
As observações anteriores foram feitas para o modelo Llama 2 7B. No entanto, padrões semelhantes também permanecem verdadeiros para outros modelos. A principal conclusão é que os números de desempenho de latência e taxa de transferência dependem da carga útil, do tipo de instância e do número de solicitações simultâneas, portanto, você precisará encontrar a configuração ideal para seu aplicativo específico. Para gerar os números anteriores para o seu caso de uso, você pode executar o link caderno, onde você pode configurar essa análise de teste de carga para seu modelo, tipo de instância e carga útil.
Entendendo as especificações do acelerador
A seleção de hardware adequado para inferência de LLM depende muito de casos de uso específicos, objetivos de experiência do usuário e do LLM escolhido. Esta seção tenta criar uma compreensão do joelho na curva latência-rendimento com relação aos princípios de alto nível baseados nas especificações do acelerador. Estes princípios por si só não são suficientes para tomar uma decisão: são necessários parâmetros de referência reais. O termo dispositivo é usado aqui para abranger todos os aceleradores de hardware de ML. Afirmamos que o joelho na curva latência-rendimento é impulsionado por um de dois fatores:
- O acelerador esgotou a memória para armazenar matrizes KV em cache, portanto, as solicitações subsequentes são enfileiradas
- O acelerador ainda tem memória sobressalente para o cache KV, mas está usando um tamanho de lote grande o suficiente para que o tempo de processamento seja determinado pela latência da operação de computação, e não pela largura de banda da memória.
Normalmente preferimos ficar limitados pelo segundo fator porque isso implica que os recursos do acelerador estão saturados. Basicamente, você está maximizando os recursos pelos quais pagou. Vamos explorar essa afirmação com mais detalhes.
Cache KV e memória do dispositivo
Os mecanismos padrão de atenção do transformador calculam a atenção para cada novo token em relação a todos os tokens anteriores. A maioria dos servidores de ML modernos armazena chaves de atenção e valores na memória do dispositivo (DRAM) para evitar recálculo em cada etapa. Isso é chamado de Cache KV, e cresce com o tamanho do lote e o comprimento da sequência. Ele define quantas solicitações de usuário podem ser atendidas em paralelo e determinará o joelho na curva de latência-taxa de transferência se o regime limitado à computação no segundo cenário mencionado anteriormente ainda não for atendido, dada a DRAM disponível. A fórmula a seguir é uma aproximação aproximada do tamanho máximo do cache KV.

Nesta fórmula, B é o tamanho do lote e N é o número de aceleradores. Por exemplo, o modelo Llama 2 7B em FP16 (2 bytes/parâmetro) servido em uma GPU A10G (24 GB DRAM) consome aproximadamente 14 GB, deixando 10 GB para o cache KV. Conectando o comprimento total do contexto do modelo (N = 4096) e os parâmetros restantes (n_layers=32, n_kv_attention_heads=32 e d_attention_head=128), esta expressão mostra que estamos limitados a servir um tamanho de lote de quatro usuários em paralelo devido a restrições de DRAM . Se você observar os benchmarks correspondentes na tabela anterior, esta é uma boa aproximação para o joelho observado nesta curva de latência-rendimento. Métodos como atenção de consulta agrupada (GQA) pode reduzir o tamanho do cache KV, no caso do GQA pelo mesmo fator que reduz o número de cabeças KV.
Intensidade aritmética e largura de banda da memória do dispositivo
O crescimento no poder computacional dos aceleradores de ML ultrapassou a largura de banda da memória, o que significa que eles podem realizar muito mais cálculos em cada byte de dados no tempo necessário para acessar esse byte.
A intensidade aritmética, ou a proporção entre operações de computação e acessos à memória, pois uma operação determina se ela é limitada pela largura de banda da memória ou pela capacidade de computação no hardware selecionado. Por exemplo, uma GPU A10G (família de tipo de instância g5) com 70 TFLOPS FP16 e largura de banda de 600 GB/s pode calcular aproximadamente 116 operações/byte. Uma GPU A100 (família de tipo de instância p4d) pode computar aproximadamente 208 ops/byte. Se a intensidade aritmética de um modelo de transformador estiver abaixo desse valor, ele estará vinculado à memória; se estiver acima, está vinculado à computação. O mecanismo de atenção para Llama 2 7B requer 62 ops/byte para tamanho de lote 1 (para uma explicação, consulte Um guia para inferência e desempenho LLM), o que significa que está vinculado à memória. Quando o mecanismo de atenção está limitado à memória, FLOPS caros ficam sem utilização.
Existem duas maneiras de utilizar melhor o acelerador e aumentar a intensidade aritmética: reduzir os acessos à memória necessários para a operação (é isso que FlashAtenção foca) ou aumentar o tamanho do lote. No entanto, talvez não consigamos aumentar o tamanho do lote o suficiente para atingir um regime limitado por computação se nossa DRAM for muito pequena para conter o cache KV correspondente. Uma aproximação grosseira do tamanho crítico do lote B* que separa os regimes vinculados à computação dos regimes vinculados à memória para inferência do decodificador GPT padrão é descrita pela seguinte expressão, onde A_mb é a largura de banda da memória do acelerador, A_f é o acelerador FLOPS e N é o número de aceleradores. Esse tamanho crítico de lote pode ser derivado descobrindo onde o tempo de acesso à memória é igual ao tempo de computação. Referir-se este blog para entender a Equação 2 e suas suposições com mais detalhes.

Esta é a mesma proporção de operações/byte que calculamos anteriormente para A10G, então o tamanho crítico do lote nesta GPU é 116. Uma maneira de abordar esse tamanho teórico e crítico do lote é aumentar a fragmentação do modelo e dividir o cache em mais aceleradores N. Isso aumenta efetivamente a capacidade do cache KV, bem como o tamanho do lote vinculado à memória.
Outro benefício da fragmentação do modelo é a divisão dos parâmetros do modelo e do trabalho de carregamento de dados entre N aceleradores. Este tipo de fragmentação é um tipo de paralelismo de modelo também conhecido como paralelismo tensorial. Ingenuamente, há N vezes a largura de banda da memória e o poder de computação agregados. Assumindo que não há sobrecarga de qualquer tipo (comunicação, software e assim por diante), isso diminuiria a latência de decodificação por token em N se estivéssemos limitados pela memória, porque a latência de decodificação do token neste regime está limitada pelo tempo que leva para carregar o modelo pesos e cache. Na vida real, entretanto, aumentar o grau de fragmentação resulta em maior comunicação entre dispositivos para compartilhar ativações intermediárias em cada camada do modelo. Esta velocidade de comunicação é limitada pela largura de banda de interconexão do dispositivo. É difícil estimar com precisão o seu impacto (para obter detalhes, consulte Paralelismo de modelo), mas isso pode eventualmente deixar de gerar benefícios ou deteriorar o desempenho — isso é especialmente verdadeiro para modelos menores, porque transferências de dados menores levam a taxas de transferência mais baixas.
Para comparar aceleradores de ML com base em suas especificações, recomendamos o seguinte. Primeiro, calcule o tamanho do lote crítico aproximado para cada tipo de acelerador de acordo com a segunda equação e o tamanho do cache KV para o tamanho do lote crítico de acordo com a primeira equação. Você pode então usar a DRAM disponível no acelerador para calcular o número mínimo de aceleradores necessários para ajustar o cache KV e os parâmetros do modelo. Ao decidir entre vários aceleradores, priorize os aceleradores na ordem de menor custo por GB/s de largura de banda de memória. Por fim, compare essas configurações e verifique qual é o melhor custo/token para o limite superior da latência desejada.
Selecione uma configuração de implantação de endpoint
Muitos LLMs distribuídos pelo SageMaker JumpStart usam o inferência de geração de texto (TGI) Contêiner SageMaker para servir modelo. A tabela a seguir discute como ajustar uma variedade de parâmetros de serviço de modelo para afetar o serviço de modelo que impacta a curva de latência-taxa de transferência ou proteger o ponto de extremidade contra solicitações que sobrecarregariam o ponto de extremidade. Esses são os parâmetros principais que você pode usar para configurar a implantação do endpoint para seu caso de uso. A menos que especificado de outra forma, usamos o padrão parâmetros de carga útil de geração de texto e Variáveis de ambiente TGI.
| Variável de ambiente | Descrição | Valor padrão do SageMaker JumpStart |
| Configurações de exibição de modelo | . | . |
MAX_BATCH_PREFILL_TOKENS |
Limita o número de tokens na operação de preenchimento prévio. Esta operação gera o cache KV para uma nova sequência de prompt de entrada. Ele consome muita memória e é limitado pela computação, portanto, esse valor limita o número de tokens permitidos em uma única operação de preenchimento prévio. As etapas de decodificação para outras consultas são pausadas enquanto o preenchimento prévio está ocorrendo. | 4096 (padrão TGI) ou comprimento máximo de contexto suportado específico do modelo (fornecido pelo SageMaker JumpStart), o que for maior. |
MAX_BATCH_TOTAL_TOKENS |
Controla o número máximo de tokens a serem incluídos em um lote durante a decodificação ou uma única passagem direta pelo modelo. Idealmente, isso é definido para maximizar o uso de todo o hardware disponível. | Não especificado (padrão TGI). O TGI definirá este valor em relação à memória CUDA restante durante o aquecimento do modelo. |
SM_NUM_GPUS |
O número de fragmentos a serem usados. Ou seja, o número de GPUs usadas para executar o modelo usando paralelismo tensorial. | Dependente da instância (fornecido pelo SageMaker JumpStart). Para cada instância suportada para um determinado modelo, o SageMaker JumpStart fornece a melhor configuração para paralelismo de tensor. |
| Configurações para proteger seu endpoint (defina-as para seu caso de uso) | . | . |
MAX_TOTAL_TOKENS |
Isso limita o orçamento de memória de uma única solicitação do cliente, limitando o número de tokens na sequência de entrada mais o número de tokens na sequência de saída (o max_new_tokens parâmetro de carga útil). |
Comprimento máximo de contexto suportado específico do modelo. Por exemplo, 4096 para Lhama 2. |
MAX_INPUT_LENGTH |
Identifica o número máximo permitido de tokens na sequência de entrada para uma única solicitação do cliente. Os itens a serem considerados ao aumentar esse valor incluem: sequências de entrada mais longas exigem mais memória, o que afeta o lote contínuo, e muitos modelos têm um comprimento de contexto compatível que não deve ser excedido. | Comprimento máximo de contexto suportado específico do modelo. Por exemplo, 4095 para Lhama 2. |
MAX_CONCURRENT_REQUESTS |
O número máximo de solicitações simultâneas permitidas pelo endpoint implantado. Novas solicitações além desse limite gerarão imediatamente um erro de modelo sobrecarregado para evitar baixa latência para as solicitações de processamento atuais. | 128 (padrão TGI). Essa configuração permite obter alto rendimento para uma variedade de casos de uso, mas você deve fixar conforme apropriado para mitigar erros de tempo limite de invocação do SageMaker. |
O servidor TGI usa lote contínuo, que agrupa dinamicamente solicitações simultâneas para compartilhar uma única passagem de encaminhamento de inferência de modelo. Existem dois tipos de passes de encaminhamento: pré-preenchimento e decodificação. Cada nova solicitação deve executar uma única passagem de pré-preenchimento para preencher o cache KV para os tokens de sequência de entrada. Depois que o cache KV é preenchido, uma passagem direta de decodificação executa uma única previsão do próximo token para todas as solicitações em lote, que é repetida iterativamente para produzir a sequência de saída. À medida que novas solicitações são enviadas ao servidor, a próxima etapa de decodificação deve aguardar para que a etapa de pré-preenchimento possa ser executada para as novas solicitações. Isso deve ocorrer antes que essas novas solicitações sejam incluídas nas etapas subseqüentes de decodificação em lote contínuo. Devido a restrições de hardware, o lote contínuo usado para decodificação pode não incluir todas as solicitações. Neste ponto, as solicitações entram em uma fila de processamento e a latência de inferência começa a aumentar significativamente, com apenas um pequeno ganho de rendimento.
É possível separar as análises de benchmarking de latência do LLM em latência de pré-preenchimento, latência de decodificação e latência de fila. O tempo consumido por cada um desses componentes é de natureza fundamentalmente diferente: o pré-preenchimento é um cálculo único, a decodificação ocorre uma vez para cada token na sequência de saída e o enfileiramento envolve processos em lote do servidor. Quando múltiplas solicitações simultâneas estão sendo processadas, torna-se difícil separar as latências de cada um desses componentes porque a latência experimentada por qualquer solicitação do cliente envolve latências de fila impulsionadas pela necessidade de preencher previamente novas solicitações simultâneas, bem como latências de fila impulsionadas pela inclusão da solicitação em processos de decodificação em lote. Por esse motivo, esta postagem foca na latência de processamento ponta a ponta. O joelho na curva latência-taxa de transferência ocorre no ponto de saturação onde as latências da fila começam a aumentar significativamente. Esse fenômeno ocorre para qualquer servidor de inferência de modelo e é impulsionado pelas especificações do acelerador.
Os requisitos comuns durante a implantação incluem satisfazer um rendimento mínimo exigido, latência máxima permitida, custo máximo por hora e custo máximo para gerar 1 milhão de tokens. Você deve condicionar esses requisitos a cargas que representem solicitações do usuário final. Um projeto para atender a esses requisitos deve considerar muitos fatores, incluindo a arquitetura específica do modelo, o tamanho do modelo, os tipos de instâncias e a contagem de instâncias (escalonamento horizontal). Nas seções a seguir, nos concentraremos na implantação de endpoints para minimizar a latência, maximizar o rendimento e minimizar custos. Esta análise considera 512 tokens totais e 256 tokens de saída.
Minimize a latência
A latência é um requisito importante em muitos casos de uso em tempo real. Na tabela a seguir, analisamos a latência mínima para cada modelo e cada tipo de instância. Você pode obter latência mínima definindo MAX_CONCURRENT_REQUESTS = 1.
| Latência Mínima (ms/token) | |||||
| ID do modelo | ml.g5.2xgrande | ml.g5.12xgrande | ml.g5.48xgrande | ml.p4d.24xgrande | ml.p4de.24xgrande |
| Lhama 2 7B | 33 | 17 | 18 | 20 | - |
| Lhama 2 7B Bate-papo | 33 | 17 | 18 | 20 | - |
| Lhama 2 13B | - | 22 | 23 | 23 | - |
| Lhama 2 13B Bate-papo | - | 23 | 23 | 23 | - |
| Lhama 2 70B | - | - | 57 | 43 | - |
| Lhama 2 70B Bate-papo | - | - | 57 | 45 | - |
| Mistral 7B | 35 | - | - | - | - |
| Instrução Mistral 7B | 35 | - | - | - | - |
| Mixtral 8x7B | - | - | 33 | 27 | - |
| Falcão 7B | 33 | - | - | - | - |
| Instrução do Falcon 7B | 33 | - | - | - | - |
| Falcão 40B | - | 53 | 33 | 27 | - |
| Instrução do Falcon 40B | - | 53 | 33 | 28 | - |
| Falcão 180B | - | - | - | - | 42 |
| Bate-papo do Falcão 180B | - | - | - | - | 42 |
Para atingir a latência mínima para um modelo, você pode usar o código a seguir ao substituir o ID do modelo e o tipo de instância desejados:
Observe que os números de latência mudam dependendo do número de tokens de entrada e saída. No entanto, o processo de implantação permanece o mesmo, exceto as variáveis de ambiente MAX_INPUT_TOKENS e MAX_TOTAL_TOKENS. Aqui, essas variáveis de ambiente são definidas para ajudar a garantir os requisitos de latência do endpoint porque sequências de entrada maiores podem violar o requisito de latência. Observe que o SageMaker JumpStart já fornece outras variáveis de ambiente ideais ao selecionar o tipo de instância; por exemplo, usar ml.g5.12xlarge definirá SM_NUM_GPUS para 4 no ambiente do modelo.
Maximize o rendimento
Nesta seção, maximizamos o número de tokens gerados por segundo. Isso normalmente é alcançado com o máximo de solicitações simultâneas válidas para o modelo e o tipo de instância. Na tabela a seguir, relatamos a taxa de transferência alcançada no maior valor de solicitação simultânea alcançado antes de encontrar um tempo limite de invocação do SageMaker para qualquer solicitação.
| Taxa de transferência máxima (tokens/s), solicitações simultâneas | |||||
| ID do modelo | ml.g5.2xgrande | ml.g5.12xgrande | ml.g5.48xgrande | ml.p4d.24xgrande | ml.p4de.24xgrande |
| Lhama 2 7B | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Lhama 2 7B Bate-papo | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Lhama 2 13B | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Lhama 2 13B Bate-papo | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Lhama 2 70B | - | - | 124 (16) | 1585 (256) | - |
| Lhama 2 70B Bate-papo | - | - | 114 (16) | 1546 (256) | - |
| Mistral 7B | 947 (64) | - | - | - | - |
| Instrução Mistral 7B | 986 (128) | - | - | - | - |
| Mixtral 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Falcão 7B | 1340 (128) | - | - | - | - |
| Instrução do Falcon 7B | 1313 (128) | - | - | - | - |
| Falcão 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Instrução do Falcon 40B | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Falcão 180B | - | - | - | - | 1100 (128) |
| Bate-papo do Falcão 180B | - | - | - | - | 1081 (128) |
Para atingir o rendimento máximo para um modelo, você pode usar o seguinte código:
Observe que o número máximo de solicitações simultâneas depende do tipo de modelo, tipo de instância, número máximo de tokens de entrada e número máximo de tokens de saída. Portanto, você deve definir esses parâmetros antes de definir MAX_CONCURRENT_REQUESTS.
Observe também que um usuário interessado em minimizar a latência geralmente está em desacordo com um usuário interessado em maximizar o rendimento. O primeiro está interessado em respostas em tempo real, enquanto o último está interessado no processamento em lote, de modo que a fila do terminal esteja sempre saturada, minimizando assim o tempo de inatividade do processamento. Os usuários que desejam maximizar o rendimento condicionado aos requisitos de latência geralmente estão interessados em operar no joelho na curva de rendimento-latência.
Minimizar custos
A primeira opção para minimizar custos envolve minimizar o custo por hora. Com isso, você pode implantar um modelo selecionado na instância do SageMaker com o menor custo por hora. Para preços em tempo real de instâncias do SageMaker, consulte Preços do Amazon SageMaker. Em geral, o tipo de instância padrão para SageMaker JumpStart LLMs é a opção de implantação de menor custo.
A segunda opção para minimizar custos envolve minimizar o custo para gerar 1 milhão de tokens. Esta é uma transformação simples da tabela que discutimos anteriormente para maximizar o rendimento, onde você pode primeiro calcular o tempo que leva em horas para gerar 1 milhão de tokens (1e6 / rendimento / 3600). Você pode então multiplicar esse tempo para gerar 1 milhão de tokens pelo preço por hora da instância do SageMaker especificada.
Observe que as instâncias com o menor custo por hora não são iguais às instâncias com o menor custo para gerar 1 milhão de tokens. Por exemplo, se as solicitações de invocação forem esporádicas, uma instância com o menor custo por hora poderá ser ideal, enquanto nos cenários de limitação, o menor custo para gerar um milhão de tokens poderá ser mais apropriado.
Tensor paralelo vs. trade-off multimodelo
Em todas as análises anteriores, consideramos a implantação de uma réplica de modelo único com um grau paralelo de tensor igual ao número de GPUs no tipo de instância de implantação. Este é o comportamento padrão do SageMaker JumpStart. No entanto, como observado anteriormente, a fragmentação de um modelo pode melhorar a latência e o rendimento do modelo apenas até um certo limite, além do qual os requisitos de comunicação entre dispositivos dominam o tempo de computação. Isso implica que muitas vezes é benéfico implantar vários modelos com um grau paralelo de tensor mais baixo em uma única instância, em vez de um único modelo com um grau paralelo de tensor mais alto.
Aqui, implantamos endpoints Llama 2 7B e 13B em instâncias ml.p4d.24xlarge com graus de tensor paralelo (TP) de 1, 2, 4 e 8. Para maior clareza no comportamento do modelo, cada um desses endpoints carrega apenas um único modelo.
| . | Taxa de transferência (tokens/s) | Latência (ms/token) | ||||||||||||||||||
| Solicitações Simultâneas | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Grau TP | Lhama 2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Lhama 2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Nossas análises anteriores já mostraram vantagens significativas de rendimento em instâncias ml.p4d.24xlarge, o que geralmente se traduz em melhor desempenho em termos de custo para gerar 1 milhão de tokens na família de instâncias g5 sob condições de alta carga de solicitação simultânea. Esta análise demonstra claramente que você deve considerar a compensação entre a fragmentação do modelo e a replicação do modelo em uma única instância; ou seja, um modelo totalmente fragmentado normalmente não é o melhor uso dos recursos de computação ml.p4d.24xlarge para famílias de modelos 7B e 13B. Na verdade, para a família de modelos 7B, você obtém o melhor rendimento para uma única réplica de modelo com um grau paralelo de tensor de 4 em vez de 8.
A partir daqui, você pode extrapolar que a configuração de rendimento mais alto para o modelo 7B envolve um grau paralelo de tensor de 1 com oito réplicas de modelo, e a configuração de rendimento mais alto para o modelo 13B é provavelmente um grau paralelo de tensor de 2 com quatro réplicas de modelo. Para saber mais sobre como fazer isso, consulte Reduza os custos de implantação de modelos em 50%, em média, usando os recursos mais recentes do Amazon SageMaker, que demonstra o uso de endpoints baseados em componentes de inferência. Devido às técnicas de balanceamento de carga, roteamento de servidor e compartilhamento de recursos de CPU, talvez você não obtenha melhorias de rendimento exatamente iguais ao número de réplicas multiplicado pelo rendimento de uma única réplica.
Escala horizontal
Conforme observado anteriormente, cada implantação de endpoint tem uma limitação no número de solicitações simultâneas, dependendo do número de tokens de entrada e saída, bem como do tipo de instância. Se isso não atender ao seu requisito de taxa de transferência ou solicitação simultânea, você poderá escalar verticalmente para utilizar mais de uma instância atrás do endpoint implantado. O SageMaker realiza automaticamente o balanceamento de carga de consultas entre instâncias. Por exemplo, o código a seguir implanta um endpoint compatível com três instâncias:
A tabela a seguir mostra o ganho de rendimento como um fator do número de instâncias para o modelo Llama 2 7B.
| . | . | Taxa de transferência (tokens/s) | Latência (ms/token) | ||||||||||||||
| . | Solicitações Simultâneas | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Contagem de instância | Tipo de Instância | Número total de tokens: 512, Número de tokens de saída: 256 | |||||||||||||||
| 1 | ml.g5.2xgrande | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xgrande | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xgrande | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Notavelmente, o joelho na curva de latência-rendimento muda para a direita porque contagens mais altas de instâncias podem lidar com um número maior de solicitações simultâneas dentro do endpoint de múltiplas instâncias. Para esta tabela, o valor da solicitação simultânea é para todo o endpoint, não para o número de solicitações simultâneas que cada instância individual recebe.
Você também pode usar o escalonamento automático, um recurso para monitorar suas cargas de trabalho e ajustar dinamicamente a capacidade para manter um desempenho estável e previsível com o menor custo possível. Isso está além do escopo desta postagem. Para saber mais sobre escalonamento automático, consulte Configurar endpoints de inferência de escalonamento automático no Amazon SageMaker.
Invocar endpoint com solicitações simultâneas
Suponhamos que você tenha um grande lote de consultas que gostaria de usar para gerar respostas de um modelo implantado sob condições de alto rendimento. Por exemplo, no bloco de código a seguir, compilamos uma lista de 1,000 cargas úteis, com cada carga solicitando a geração de 100 tokens. Ao todo, estamos solicitando a geração de 100,000 mil tokens.
Ao enviar um grande número de solicitações para a API de tempo de execução do SageMaker, você pode enfrentar erros de limitação. Para atenuar isso, você pode criar um cliente de tempo de execução SageMaker personalizado que aumenta o número de novas tentativas. Você pode fornecer o objeto de sessão resultante do SageMaker para o JumpStartModel construtor ou sagemaker.predictor.retrieve_default se desejar anexar um novo preditor a um endpoint já implantado. No código a seguir, usamos este objeto de sessão ao implantar um modelo Llama 2 com configurações padrão do SageMaker JumpStart:
Este endpoint implantado tem MAX_CONCURRENT_REQUESTS = 128 por padrão. No bloco a seguir, usamos a biblioteca de futuros simultâneos para iterar sobre a invocação do endpoint para todas as cargas úteis com 128 threads de trabalho. No máximo, o endpoint processará 128 solicitações simultâneas e sempre que uma solicitação retornar uma resposta, o executor enviará imediatamente uma nova solicitação ao endpoint.
Isso resulta na geração de um total de 100,000 tokens com uma taxa de transferência de 1255 tokens/s em uma única instância ml.g5.2xlarge. Isso leva aproximadamente 80 segundos para ser processado.
Observe que esse valor de taxa de transferência é notavelmente diferente da taxa de transferência máxima para Llama 2 7B em ml.g5.2xlarge nas tabelas anteriores desta postagem (486 tokens/seg em 64 solicitações simultâneas). Isso ocorre porque a carga útil de entrada usa 8 tokens em vez de 256, a contagem de tokens de saída é 100 em vez de 256 e as contagens de tokens menores permitem 128 solicitações simultâneas. Este é um lembrete final de que todos os números de latência e taxa de transferência dependem da carga útil! A alteração das contagens de tokens de carga útil afetará os processos em lote durante a veiculação do modelo, o que, por sua vez, afetará o pré-preenchimento emergente, a decodificação e os tempos de fila do seu aplicativo.
Conclusão
Nesta postagem, apresentamos benchmarking de SageMaker JumpStart LLMs, incluindo Llama 2, Mistral e Falcon. Também apresentamos um guia para otimizar a latência, o rendimento e o custo da configuração de implantação do seu endpoint. Você pode começar executando o caderno associado para avaliar seu caso de uso.
Sobre os autores
 Dr. é cientista aplicado da equipe Amazon SageMaker JumpStart. Seus interesses de pesquisa incluem algoritmos escaláveis de aprendizado de máquina, visão computacional, séries temporais, não paramétricos bayesianos e processos gaussianos. Seu doutorado é pela Duke University e publicou artigos em NeurIPS, Cell e Neuron.
Dr. é cientista aplicado da equipe Amazon SageMaker JumpStart. Seus interesses de pesquisa incluem algoritmos escaláveis de aprendizado de máquina, visão computacional, séries temporais, não paramétricos bayesianos e processos gaussianos. Seu doutorado é pela Duke University e publicou artigos em NeurIPS, Cell e Neuron.
 Dr. Vivek Madan é um cientista aplicado da equipe Amazon SageMaker JumpStart. Ele obteve seu doutorado na Universidade de Illinois em Urbana-Champaign e foi pesquisador de pós-doutorado na Georgia Tech. Ele é um pesquisador ativo em aprendizado de máquina e design de algoritmos e publicou artigos em conferências EMNLP, ICLR, COLT, FOCS e SODA.
Dr. Vivek Madan é um cientista aplicado da equipe Amazon SageMaker JumpStart. Ele obteve seu doutorado na Universidade de Illinois em Urbana-Champaign e foi pesquisador de pós-doutorado na Georgia Tech. Ele é um pesquisador ativo em aprendizado de máquina e design de algoritmos e publicou artigos em conferências EMNLP, ICLR, COLT, FOCS e SODA.
 Dr. é cientista aplicado sênior do Amazon SageMaker JumpStart e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele obteve seu PhD pela Universidade de Illinois Urbana-Champaign. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos em conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
Dr. é cientista aplicado sênior do Amazon SageMaker JumpStart e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele obteve seu PhD pela Universidade de Illinois Urbana-Champaign. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos em conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
 João moura é arquiteto de soluções especialista sênior em IA/ML na AWS. João ajuda os clientes da AWS – desde pequenas startups até grandes empresas – a treinar e implantar grandes modelos com eficiência e a construir plataformas de ML de forma mais ampla na AWS.
João moura é arquiteto de soluções especialista sênior em IA/ML na AWS. João ajuda os clientes da AWS – desde pequenas startups até grandes empresas – a treinar e implantar grandes modelos com eficiência e a construir plataformas de ML de forma mais ampla na AWS.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/
- :tem
- :é
- :não
- :onde
- $UP
- 000
- 1
- 10
- 100
- 11
- 116
- 12
- 14
- 150
- 16
- 17
- 20
- 24
- 28
- 30
- 32
- 60
- 600
- 70
- 8
- 80
- a
- A100
- Capaz
- Sobre
- acima
- acelerador
- aceleradores
- aceitação
- Acesso
- realizar
- Segundo
- Alcançar
- alcançado
- em
- ativações
- ativo
- adaptar
- Adicional
- Adicionalmente
- ajustar
- vantagens
- afetar
- Depois de
- contra
- agregar
- AI / ML
- algoritmo
- algoritmos
- alinhar
- Todos os Produtos
- permitir
- permitidas
- permite
- sozinho
- já
- tb
- Apesar
- sempre
- Amazon
- Amazon Sage Maker
- JumpStart do Amazon SageMaker
- Amazon Web Services
- quantidade
- an
- analisa
- análise
- e
- Outro
- qualquer
- api
- Aplicação
- aplicado
- abordagem
- apropriado
- aproximado
- aproximadamente
- arquitetura
- SOMOS
- AS
- associado
- suposições
- At
- anexar
- Tentativas
- por WhatsApp.
- automaticamente
- disponível
- média
- evitar
- AWS
- b
- saldos
- equilíbrio
- Largura de Banda
- baseado
- Basicamente
- lotes
- Bayesiano
- BE
- Porque
- torna-se
- antes
- comportamento
- atrás
- ser
- Acreditar
- referência
- aferimento
- benchmarks
- benéfico
- beneficiar
- Benefícios
- MELHOR
- Melhor
- entre
- Pós
- Bloquear
- Blog
- obrigado
- amplo
- amplamente
- orçamento
- construir
- mas a
- by
- esconderijo
- calcular
- calculado
- chamado
- CAN
- Pode obter
- capacidade
- Capacidade
- tampas
- Cuidado
- casas
- casos
- Causar
- célula
- certo
- alterar
- mudança
- características
- Escolha
- escolhido
- clareza
- claramente
- cliente
- código
- Comunicação
- comparar
- integrações
- componentes
- compreensivo
- computação
- computacional
- poder computacional
- cálculos
- Computar
- computador
- Visão de Computador
- concorrente
- condição
- condições
- conferências
- Configuração
- Considerar
- considerado
- considera
- restrições
- consumida
- contém
- contexto
- contínuo
- continuamente
- Correspondente
- Custo
- custos
- contar
- CPU
- crio
- crítico
- bruto
- Atual
- curva
- personalizadas
- Clientes
- dados,
- Decidindo
- decisão
- decodificação
- diminuir
- diminui
- dedicado
- Padrão
- definir
- definido
- Define
- Grau
- demonstrar
- demonstra
- dependente
- Dependendo
- depende
- implantar
- implantado
- Implantação
- desenvolvimento
- Implantações
- implanta
- profundidade
- Derivado
- descrito
- Design
- desejado
- detalhe
- detalhes
- Determinar
- determina
- desenvolver
- dispositivo
- Dispositivos/Instrumentos
- diferente
- difícil
- diminuindo
- discutir
- discutido
- distinto
- distribuído
- Não faz
- dominar
- não
- tempo de inatividade
- dr
- distância
- dirigido
- condução
- dois
- Duque
- Universidade Duke
- durante
- dinamicamente
- cada
- Mais cedo
- efetivamente
- eficientemente
- oito
- ou
- abranger
- encontrando
- end-to-end
- Ponto final
- endpoints
- termina
- suficiente
- Entrar
- empresas
- Todo
- Meio Ambiente
- igual
- É igual a
- erro
- erros
- especialmente
- estimativa
- Éter (ETH)
- Mesmo
- eventualmente
- Cada
- exatamente
- exemplo
- excedido
- Exceto
- apresentar
- existe
- caro
- vasta experiência
- experiente
- explicação
- explorar
- explora
- expressão
- fato
- fator
- fatores
- FALHA
- falcão
- famílias
- família
- factível
- Característica
- Funcionalidades
- poucos
- Figura
- final
- Finalmente
- Encontre
- descoberta
- Primeiro nome
- caber
- Foco
- concentra-se
- seguinte
- Escolha
- Antigo
- Fórmula
- para a frente
- Foundation
- quatro
- da
- cheio
- totalmente
- fundamentalmente
- mais distante
- Além disso
- futuros
- Ganho
- Ganhos
- Geral
- gerar
- gerado
- gera
- gerando
- geração
- ter
- dado
- Objetivos
- Bom estado, com sinais de uso
- tem
- GPU
- GPUs
- maior
- Cresce
- Growth
- garanta
- Guarda
- guia
- manipular
- Hardware
- Ter
- he
- cabeças
- fortemente
- ajudar
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Alta
- de alto nível
- superior
- mais
- sua
- segurar
- Horizontal
- hora
- HORÁRIO
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTTPS
- i
- ICLR
- ID
- ideal
- idealmente
- identificar
- if
- Illinois
- imediatamente
- Impacto
- Impacto
- importar
- importante
- importante
- melhorar
- melhoria
- melhorias
- melhora
- in
- incluir
- incluído
- Incluindo
- inclusão
- Entrada
- Crescimento
- aumentou
- Aumenta
- aumentando
- Individual
- entrada
- inputs
- instância
- instâncias
- em vez disso
- interessado
- interesses
- Nível intermediário
- para dentro
- envolve
- IT
- ESTÁ
- jpg
- justificado
- chaves
- Tipo
- kyle
- língua
- grande
- Grandes empresas
- Maior
- maior
- Latência
- mais tarde
- mais recente
- camada
- conduzir
- APRENDER
- aprendizagem
- partida
- esquerda
- Comprimento
- Biblioteca
- vida
- como
- Provável
- LIMITE
- limitação
- Limitado
- limites
- Line
- Lista
- lhama
- carregar
- carregamento
- localização
- mais
- olhar
- Baixo
- diminuir
- menor
- máquina
- aprendizado de máquina
- moldadas
- a manter
- fazer
- muitos
- Maximizar
- maximiza
- maximizando
- máximo
- Posso..
- significado
- significa
- medições
- mecanismo
- mecanismos
- Conheça
- Memória
- mencionado
- conheceu
- métodos
- poder
- milhão
- minimizar
- minimizando
- mínimo
- menor
- minutos
- Mitigar
- ML
- Moda
- modelo
- modelos
- EQUIPAMENTOS
- Monitore
- mais
- a maioria
- múltiplo
- devo
- Natureza
- necessariamente
- necessário
- você merece...
- NeuroIPS
- Novo
- Próximo
- não
- notavelmente
- nota
- notado
- número
- números
- objeto
- observações
- observar
- observado
- obter
- óbvio
- ocorrer
- ocorrendo
- Probabilidade
- of
- frequentemente
- on
- ONE
- só
- operando
- operação
- Operações
- ideal
- Otimize
- Opção
- or
- ordem
- Outros
- Outros
- de outra forma
- A Nossa
- saída
- Acima de
- papéis
- Paralelo
- parâmetro
- parâmetros
- particular
- passar
- passes
- padrões
- pausa
- para
- realizar
- atuação
- executa
- phd
- fenómeno
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- mais
- ponto
- pobre
- populosa
- possível
- Publique
- poder
- Prática
- precedente
- justamente
- predizer
- Previsível
- predição
- Predictor
- preferir
- apresentado
- evitar
- anterior
- anteriormente
- preço
- preços
- primário
- princípios
- Priorizar
- processo
- processado
- processos
- em processamento
- produzir
- proteger
- fornecer
- fornecido
- fornece
- publicamente
- publicado
- propósito
- consultas
- aumentar
- Preços
- em vez
- relação
- alcançar
- reais
- vida real
- em tempo real
- razão
- recebe
- recomendar
- recomendações
- reduzir
- reduz
- referir
- a que se refere
- regime
- dietas
- relacionamento
- Relacionamentos
- permanecem
- remanescente
- permanece
- lembrete
- repetido
- responder
- réplica
- Denunciar
- representar
- solicitar
- solicitando
- pedidos
- requerer
- requeridos
- requerimento
- Requisitos
- exige
- pesquisa
- investigador
- recurso
- Recursos
- respeito
- resposta
- respostas
- resultando
- Resultados
- Retorna
- certo
- roteamento
- LINHA
- Regra
- Execute
- corrida
- sábio
- mesmo
- escalável
- Escala
- dimensionamento
- cenário
- cenários
- Cientista
- escopo
- Segundo
- segundo
- Seção
- seções
- Vejo
- visto
- selecionar
- selecionado
- selecionando
- doadores,
- enviar
- envio
- senior
- sentido
- enviei
- separado
- Seqüência
- Série
- servido
- servidor
- Servidores
- Serviços
- de servir
- Sessão
- conjunto
- contexto
- fragmentado
- raspando
- Partilhar
- compartilhando
- Turnos
- rede de apoio social
- mostrou
- Shows
- periodo
- de forma considerável
- semelhante
- simples
- simultaneamente
- solteiro
- Tamanho
- pequeno
- menor
- So
- Software
- Soluções
- alguns
- fonte
- especialista
- específico
- especificações
- especificada
- óculos
- velocidade
- divisão
- esporádico
- padrão
- começo
- começado
- começa
- Startups
- estatístico
- estável
- Passo
- Passos
- Ainda
- Dê um basta
- Estudo
- subseqüente
- substancial
- tal
- adequado
- ajuda
- Suportado
- .
- mesa
- alfaiataria
- Tire
- Takeaways
- toma
- Profissionais
- tecnologia
- técnicas
- Tender
- prazo
- condições
- teste
- do que
- que
- A
- A fonte
- deles
- então
- teórico
- teoria
- Lá.
- assim
- assim sendo
- Este
- deles
- coisas
- isto
- aqueles
- três
- Através da
- Taxa de transferência
- tempo
- Séries temporais
- vezes
- para
- juntos
- token
- Tokens
- também
- Total
- tp
- traçar
- Trem
- transferência
- fáceis
- Transformação
- transformador
- verdadeiro
- VIRAR
- dois
- tipo
- tipos
- tipicamente
- para
- compreender
- compreensão
- universidade
- Uso
- usar
- caso de uso
- usava
- Utilizador
- Experiência do Usuário
- usuários
- usos
- utilização
- utilizar
- válido
- valor
- Valores
- variações
- variedade
- verificar
- versátil
- muito
- via
- visão
- vs
- esperar
- queremos
- quente
- foi
- Caminho..
- maneiras
- we
- web
- serviços web
- BEM
- foram
- O Quê
- O que é a
- quando
- sempre que
- enquanto que
- qual
- enquanto
- QUEM
- precisarão
- de
- dentro
- sem
- Atividades:
- trabalhador
- seria
- ainda
- produzindo
- Você
- investimentos
- zefirnet