Pandas é uma biblioteca de código aberto poderosa e amplamente utilizada para manipulação e análise de dados usando Python. Um de seus principais recursos é a capacidade de agrupar dados usando a função groupby, dividindo um DataFrame em grupos com base em uma ou mais colunas e, em seguida, aplicando várias funções de agregação a cada uma delas.

Imagem da Unsplash
A groupby A função é incrivelmente poderosa, pois permite resumir e analisar rapidamente grandes conjuntos de dados. Por exemplo, você pode agrupar um conjunto de dados por uma coluna específica e calcular a média, a soma ou a contagem das colunas restantes de cada grupo. Você também pode agrupar por várias colunas para obter uma compreensão mais granular dos seus dados. Além disso, permite aplicar funções de agregação personalizadas, que podem ser uma ferramenta muito poderosa para tarefas complexas de análise de dados.
Neste tutorial, você aprenderá como usar a função groupby no Pandas para agrupar diferentes tipos de dados e realizar diferentes operações de agregação. Ao final deste tutorial, você será capaz de usar esta função para analisar e resumir dados de várias maneiras.
Os conceitos são internalizados quando bem praticados e é isso que faremos a seguir, ou seja, colocar em prática a função groupby do Pandas. Recomenda-se usar um Caderno Jupyter para este tutorial, pois você pode ver o resultado de cada etapa.
Gerar dados de amostra
Importe as seguintes bibliotecas:
- Pandas: Para criar um dataframe e aplicar agrupamento por
- Aleatório – Para gerar dados aleatórios
- Pprint – Para imprimir dicionários
import pandas as pd
import random
import pprint
A seguir, inicializaremos um dataframe vazio e preencheremos os valores para cada coluna conforme mostrado abaixo:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Dica bônus – uma maneira mais limpa de fazer a mesma tarefa é criar um dicionário de todas as variáveis e valores e posteriormente convertê-lo em um dataframe.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
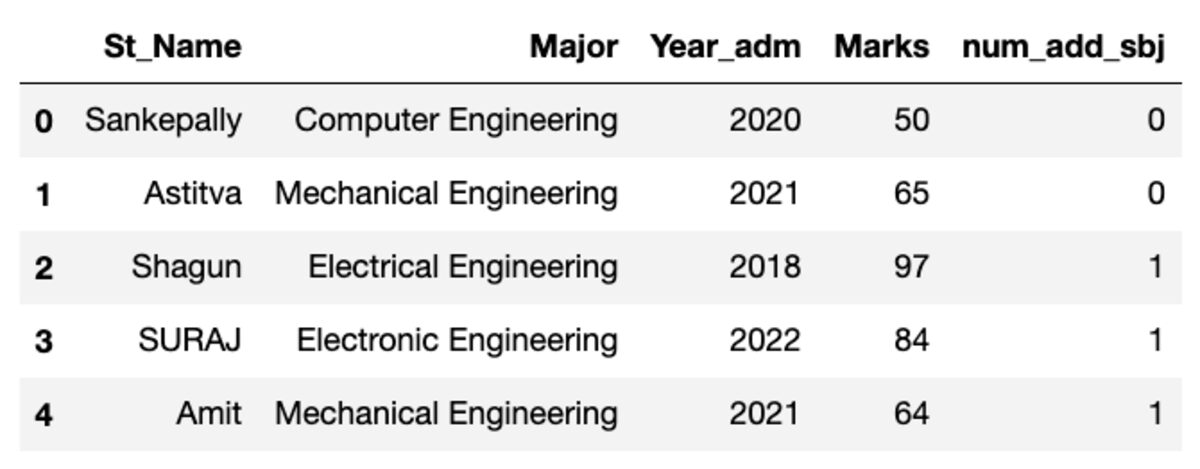
O dataframe se parece com o mostrado abaixo. Ao executar este código, alguns dos valores não corresponderão, pois estamos usando uma amostra aleatória.
Fazendo grupos
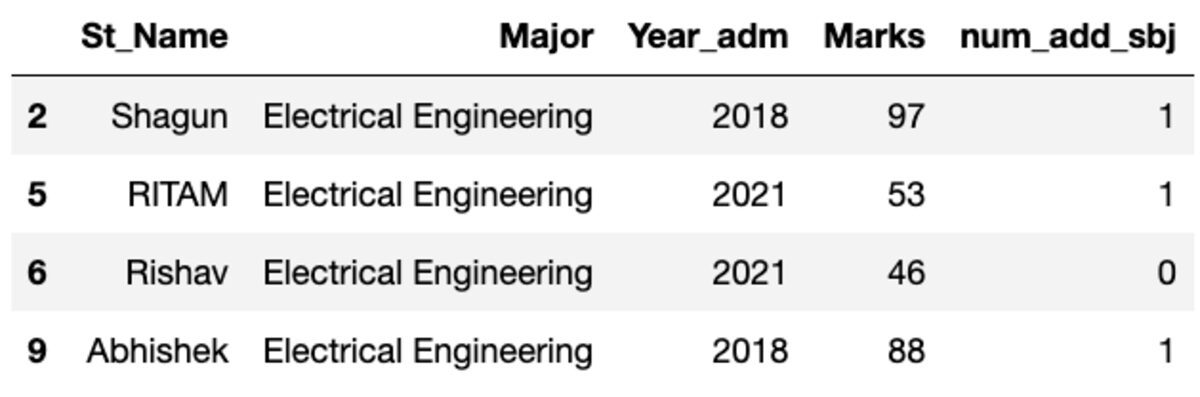
Vamos agrupar os dados pelo assunto “Principal” e aplicar o filtro de grupo para ver quantos registros se enquadram neste grupo.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Assim, quatro alunos pertencem ao curso de Engenharia Elétrica.
Você também pode agrupar por mais de uma coluna (Major e num_add_sbj neste caso).
groups = df.groupby(['Major', 'num_add_sbj'])
Observe que todas as funções agregadas que podem ser aplicadas a grupos com uma coluna podem ser aplicadas a grupos com múltiplas colunas. No restante do tutorial, vamos nos concentrar nos diferentes tipos de agregações usando uma única coluna como exemplo.
Vamos criar grupos usando groupby na coluna “Principal”.
groups = df.groupby('Major')Aplicando Funções Diretas
Digamos que você queira encontrar as notas médias em cada especialização. O que você faria?
- Escolha a coluna Marcas
- Aplicar função média
- Aplicar função de arredondamento para arredondar marcas para duas casas decimais (opcional)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
Agregado
Outra maneira de obter o mesmo resultado é usando uma função agregada conforme mostrado abaixo:
groups['Marks'].aggregate('mean').round(2)
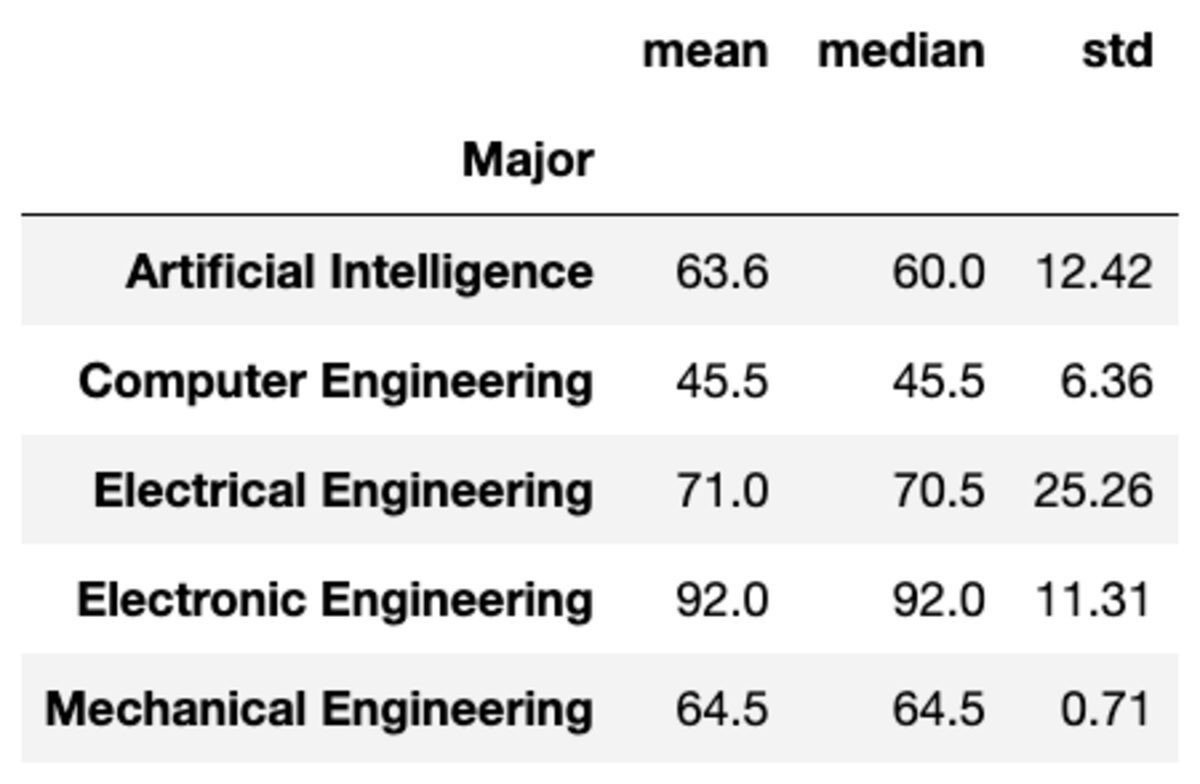
Você também pode aplicar múltiplas agregações aos grupos, passando as funções como uma lista de strings.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
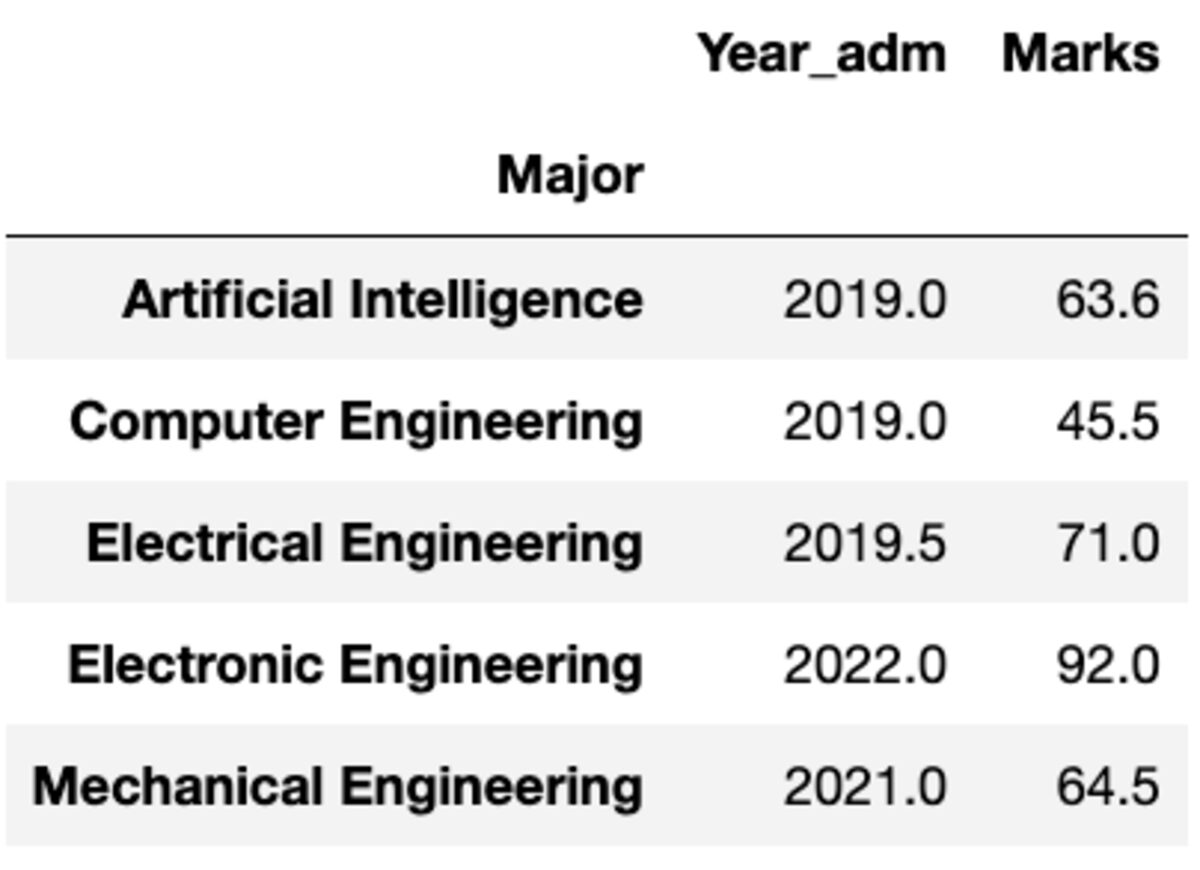
Mas e se você precisar aplicar uma função diferente a uma coluna diferente? Não se preocupe. Você também pode fazer isso passando o par {column: function}.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
Transformações
Você pode muito bem precisar realizar transformações personalizadas em uma coluna específica, o que pode ser facilmente alcançado usando groupby(). Vamos definir um escalar padrão semelhante ao disponível no módulo de pré-processamento do sklearn. Você pode transformar todas as colunas chamando o método transform e passando a função personalizada.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
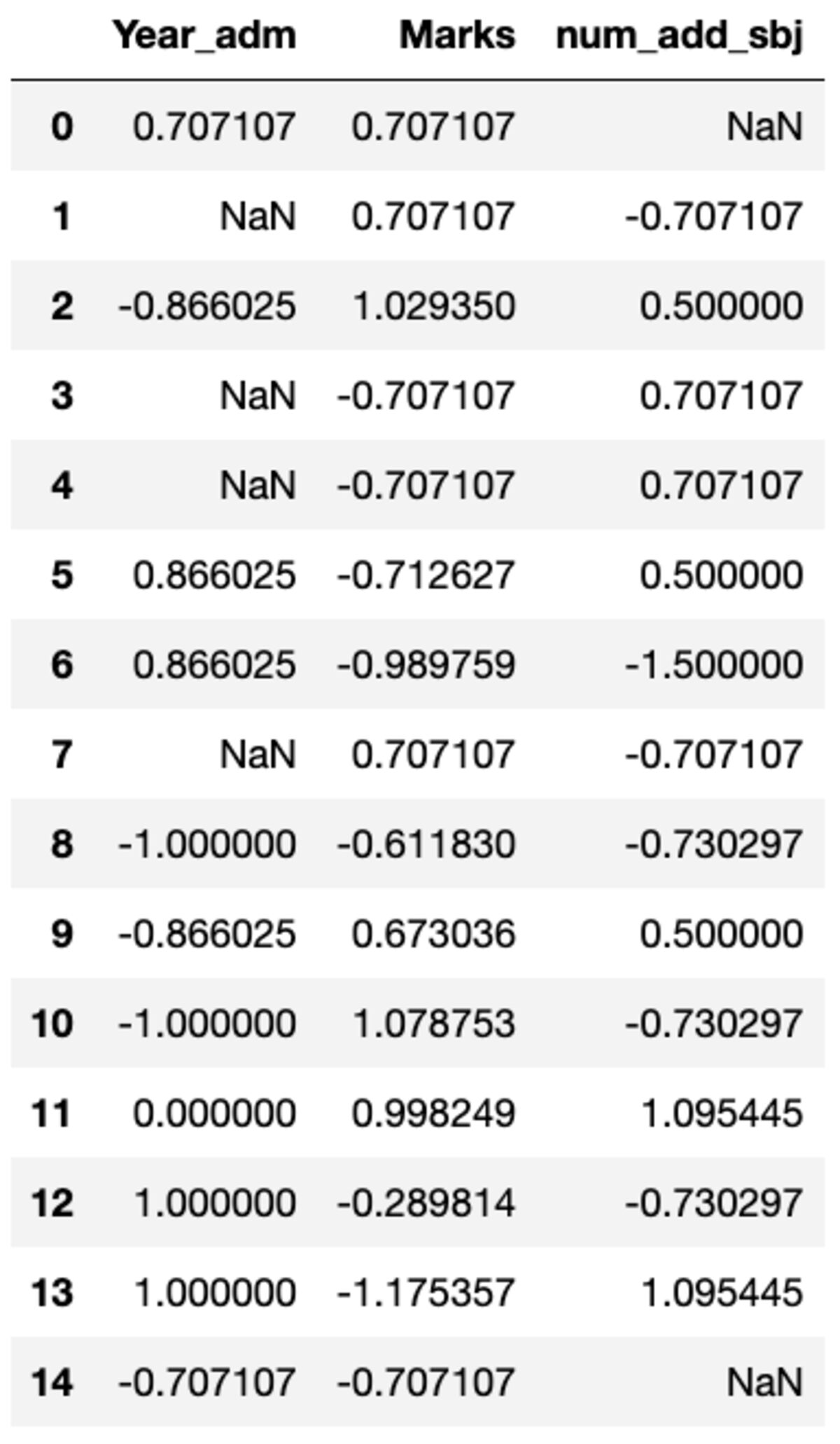
Observe que “NaN” representa grupos com desvio padrão zero.
filtros
Você pode querer verificar qual “Major” está com baixo desempenho, ou seja, aquele em que as “notas” médias dos alunos são inferiores a 60. Isso requer que você aplique um método de filtro a grupos com uma função dentro dele. O código abaixo usa um função lambda para obter os resultados filtrados.
groups.filter(lambda x: x['Marks'].mean() 60)

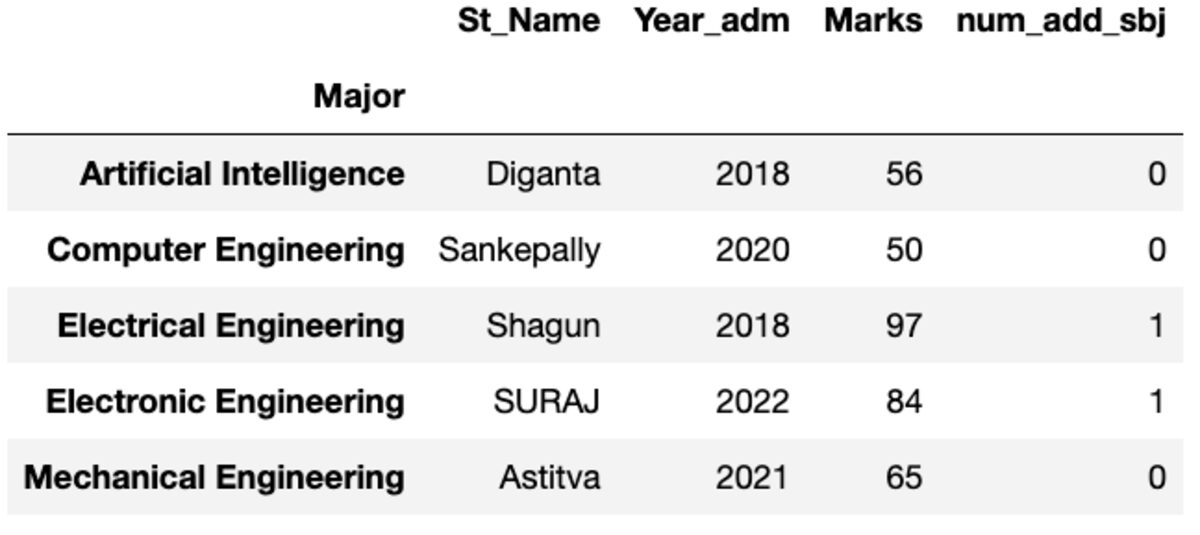
Primeiro nome
Fornece sua primeira instância classificada por índice.
groups.first()
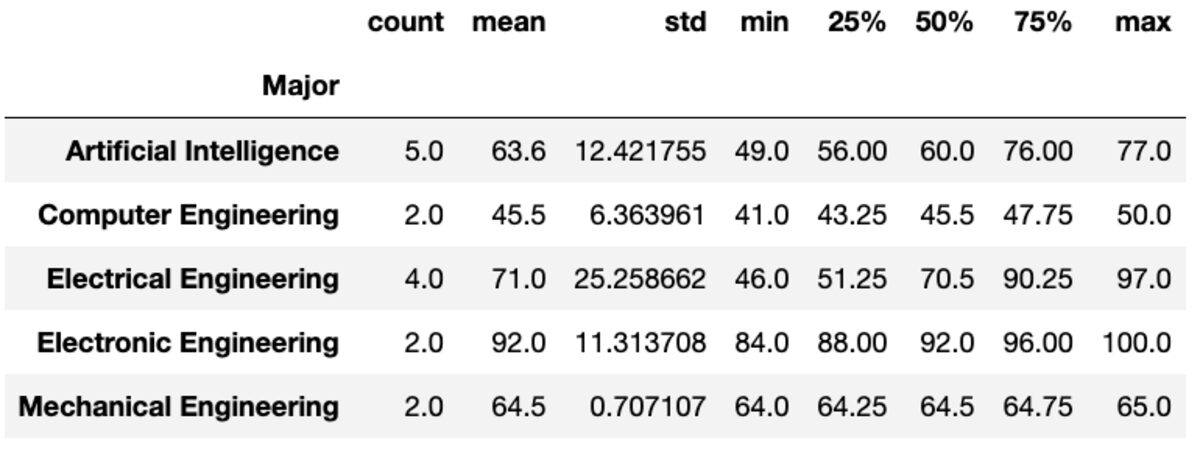
Descrever
O método “describe” retorna estatísticas básicas como contagem, média, padrão, mínimo, máximo, etc.
groups['Marks'].describe()
Tamanho
Size, como o nome sugere, retorna o tamanho de cada grupo em termos do número de registros.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
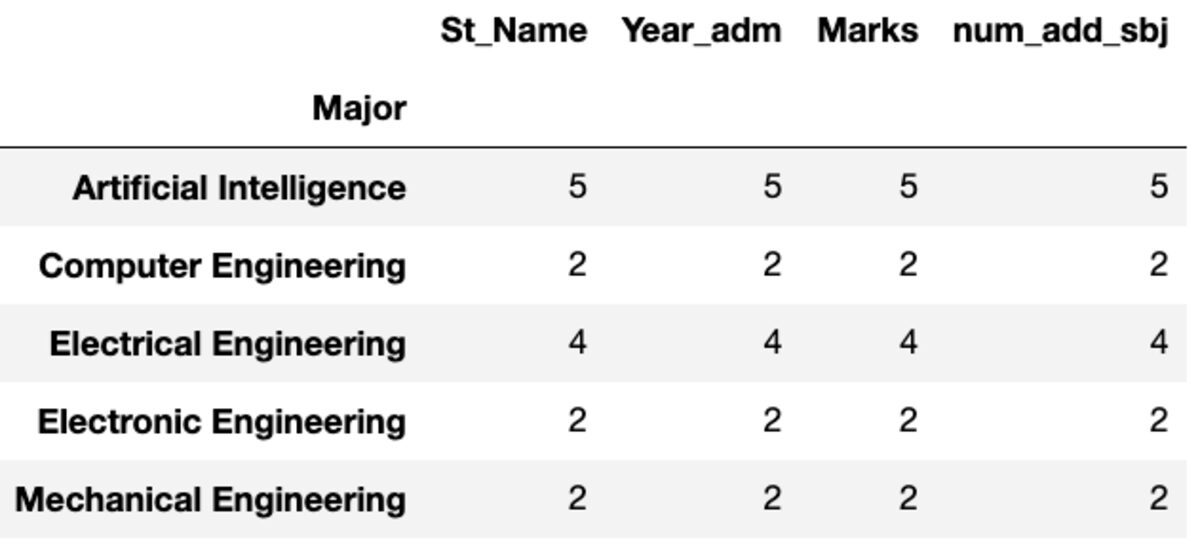
dtype: int64Conde e Nunique
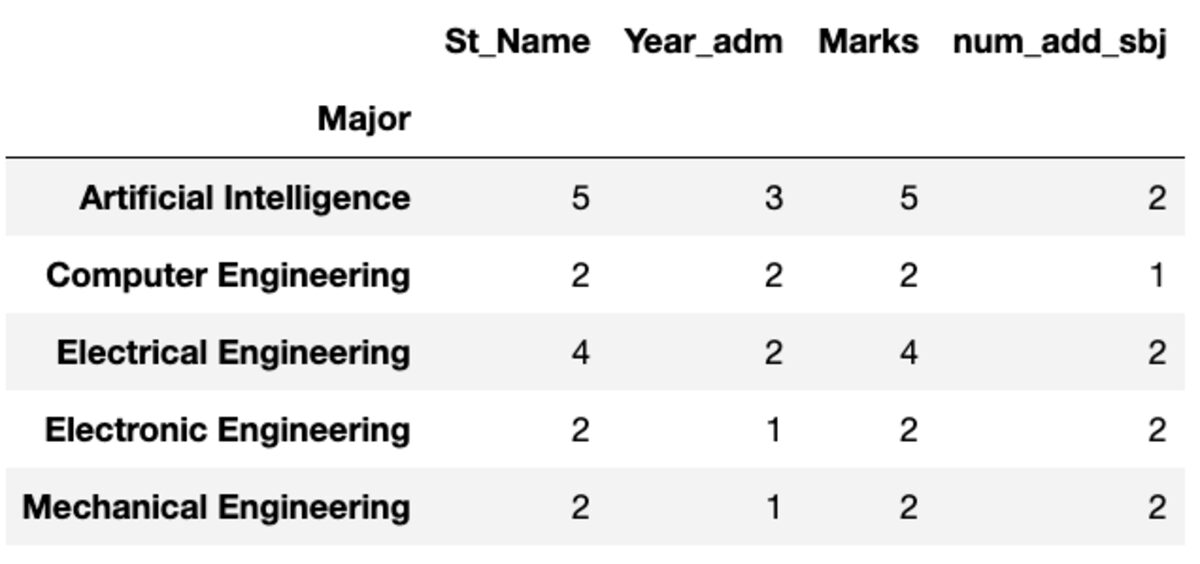
“Count” retorna todos os valores, enquanto “Nunique” retorna apenas os valores únicos nesse grupo.
groups.count()
groups.nunique()
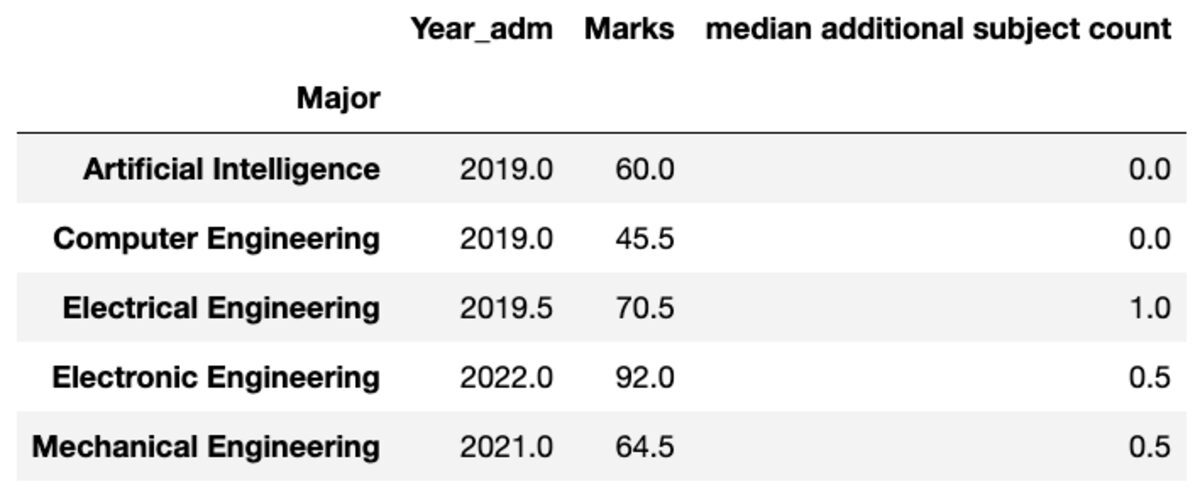
Rebatizar
Você também pode renomear o nome das colunas agregadas conforme sua preferência.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- Seja claro sobre o propósito do groupby: Você está tentando agrupar os dados por uma coluna para obter a média de outra coluna? Ou você está tentando agrupar os dados por várias colunas para obter a contagem das linhas em cada grupo?
- Entenda a indexação do quadro de dados: A função groupby usa o índice para agrupar os dados. Se você deseja agrupar os dados por uma coluna, certifique-se de que a coluna esteja definida como índice ou você pode usar .set_index()
- Use a função agregada apropriada: Pode ser usado com várias funções de agregação como média(), soma(), contagem(), min(), max()
- Use o parâmetro as_index: Quando definido como False, este parâmetro diz ao pandas para usar as colunas agrupadas como colunas regulares em vez de índice.
Você também pode usar groupby() em conjunto com outras funções do pandas, como pivot_table(), crosstab() e cut() para extrair mais insights de seus dados.
Uma função groupby é uma ferramenta poderosa para análise e manipulação de dados, pois permite agrupar linhas de dados com base em uma ou mais colunas e, em seguida, realizar cálculos agregados nos grupos. O tutorial demonstrou várias maneiras de usar a função groupby com a ajuda de exemplos de código. Espero que ele lhe forneça uma compreensão das diferentes opções que o acompanham e também como elas ajudam na análise de dados.
Vidhi Chugh é um estrategista de IA e um líder de transformação digital que trabalha na interseção de produtos, ciências e engenharia para construir sistemas escaláveis de aprendizado de máquina. Ela é uma líder em inovação premiada, autora e palestrante internacional. Ela tem a missão de democratizar o aprendizado de máquina e quebrar o jargão para que todos façam parte dessa transformação.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- habilidade
- Capaz
- Alcançar
- alcançado
- Adicional
- Adicionalmente
- agregação
- AI
- Todos os Produtos
- permite
- análise
- analisar
- e
- Outro
- aplicado
- Aplicar
- Aplicando
- apropriado
- artificial
- inteligência artificial
- autor
- disponível
- média
- premiado
- baseado
- basic
- abaixo
- biotecnologia
- Break
- construir
- calcular
- chamada
- casas
- verificar
- remover filtragem
- código
- Coluna
- colunas
- como
- integrações
- computador
- Engenharia computacional
- crio
- Criar
- personalizadas
- dados,
- análise de dados
- conjuntos de dados
- democratizar
- demonstraram
- desvio
- diferente
- digital
- Transformação Digital
- diretamente
- não
- cada
- facilmente
- efetivamente
- Engenharia elétrica
- Eletrônico
- Engenharia
- etc.
- todos
- exemplo
- exemplos
- extrato
- Cair
- Funcionalidades
- preencher
- filtro
- Encontre
- Primeiro nome
- Foco
- seguinte
- QUADRO
- da
- função
- funções
- gerar
- ter
- dado
- dá
- vai
- Grupo
- Do grupo
- mãos em
- ajudar
- esperança
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- importar
- in
- incrivelmente
- índice
- Inovação
- insights
- instância
- em vez disso
- Inteligência
- Internacionais
- interseção
- IT
- jargão
- KDnuggetsGenericName
- Chave
- grande
- líder
- APRENDER
- aprendizagem
- bibliotecas
- Biblioteca
- Lista
- OLHARES
- máquina
- aprendizado de máquina
- principal
- fazer
- Manipulação
- muitos
- Match
- max
- mecânico
- Engenharia Mecânica
- média
- método
- Missão
- módulo
- mais
- múltiplo
- nome
- nomes
- você merece...
- Próximo
- número
- ONE
- open source
- Operações
- Opções
- Outros
- pandas
- parâmetro
- parte
- particular
- Passagem
- realizar
- Locais
- platão
- Inteligência de Dados Platão
- PlatãoData
- poderoso
- Impressão
- Produto
- fornece
- propósito
- Python
- rapidamente
- acaso
- Recomenda
- registros
- regular
- remanescente
- representa
- exige
- DESCANSO
- resultar
- Resultados
- retorno
- Retorna
- Richard
- volta
- corrida
- mesmo
- escalável
- CIÊNCIAS
- conjunto
- rede de apoio social
- mostrando
- semelhante
- solteiro
- Tamanho
- alguns
- Palestrantes
- específico
- padrão
- estatística
- Passo
- Estrategista
- estudante
- Estudantes
- sujeito
- Sugere
- resumir
- sistemas
- Tarefa
- tarefas
- conta
- condições
- A
- tipo
- para
- ferramenta
- Transformar
- Transformação
- transformações
- tutorial
- tipos
- compreensão
- único
- usar
- Valores
- vário
- maneiras
- O Quê
- qual
- precisarão
- trabalhar
- seria
- X
- ano
- investimentos
- zefirnet
- zero








