A construção de modelos básicos (FMs) requer a construção, manutenção e otimização de grandes clusters para treinar modelos com dezenas a centenas de bilhões de parâmetros em grandes quantidades de dados. Criar um ambiente resiliente que possa lidar com falhas e mudanças ambientais sem perder dias ou semanas de progresso no treinamento do modelo é um desafio operacional que exige que você implemente escalabilidade de cluster, monitoramento proativo de integridade, pontos de verificação de trabalho e recursos para retomar automaticamente o treinamento caso surjam falhas ou problemas. .
Estamos empolgados em compartilhar isso HyperPod do Amazon SageMaker agora está disponível para permitir modelos básicos de treinamento com milhares de aceleradores até 40% mais rápidos, fornecendo um ambiente de treinamento altamente resiliente e eliminando o trabalho pesado indiferenciado envolvido na operação de clusters de treinamento em grande escala. Com o SageMaker HyperPod, os profissionais de aprendizado de máquina (ML) podem treinar FMs por semanas e meses sem interrupções e sem ter que lidar com problemas de falha de hardware.
Clientes como Stability AI usam o SageMaker HyperPod para treinar seus modelos básicos, incluindo Stable Diffusion.
“Como empresa líder em IA generativa de código aberto, nosso objetivo é maximizar a acessibilidade da IA moderna. Estamos construindo modelos básicos com dezenas de bilhões de parâmetros, que exigem que a infraestrutura dimensione o desempenho do treinamento de maneira ideal. Com a infraestrutura gerenciada e as bibliotecas de otimização do SageMaker HyperPod, podemos reduzir o tempo e os custos de treinamento em mais de 50%. Isso torna nosso treinamento de modelo mais resiliente e de alto desempenho para construir modelos de última geração com mais rapidez.”
– Emad Mostaque, fundador e CEO da Stability AI.
Para tornar o ciclo completo de desenvolvimento de FMs resiliente a falhas de hardware, o SageMaker HyperPod ajuda a criar clusters, monitorar a integridade do cluster, reparar e substituir nós defeituosos dinamicamente, salvar pontos de verificação frequentes e retomar automaticamente o treinamento sem perder o progresso. Além disso, o SageMaker HyperPod é pré-configurado com Amazon Sage Maker bibliotecas de treinamento distribuídas, incluindo o Biblioteca de paralelismo de dados SageMaker (SMDDP) e Biblioteca de paralelismo de modelo SageMaker (SMP), para melhorar o desempenho do treinamento FM, simplificando a divisão de dados e modelos de treinamento em partes menores e processando-os em paralelo nos nós do cluster, ao mesmo tempo em que utiliza totalmente a infraestrutura de rede e computação do cluster. O SageMaker HyperPod integra o Slurm Workload Manager para cluster e orquestração de trabalhos de treinamento.
Visão geral do Slurm Workload Manager
Xingar, anteriormente conhecido como Simple Linux Utility for Resource Management, é um agendador de tarefas para executar tarefas em um cluster de computação distribuído. Ele também fornece uma estrutura para executar tarefas paralelas usando o Biblioteca de Comunicações Coletivas NVIDIA (NCCL) or Interface de passagem de mensagens (MPI) padrões. Slurm é um popular sistema de gerenciamento de recursos de cluster de código aberto usado amplamente por computação de alto desempenho (HPC) e cargas de trabalho generativas de treinamento de IA e FM. O SageMaker HyperPod fornece uma maneira simples de colocar em funcionamento um cluster Slurm em questão de minutos.
A seguir está um diagrama arquitetônico de alto nível de como os usuários interagem com o SageMaker HyperPod e como os vários componentes do cluster interagem entre si e com outros serviços da AWS, como Amazon FSx para Lustre e Serviço de armazenamento simples da Amazon (Amazônia S3).
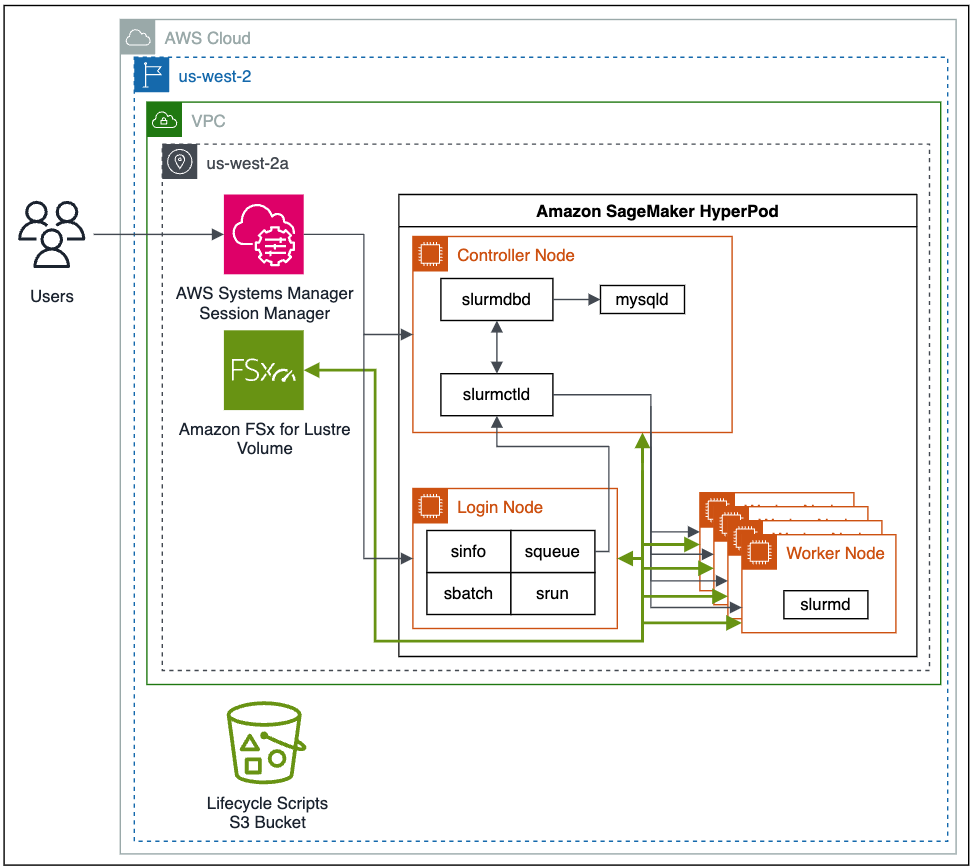
Os trabalhos Slurm são enviados por comandos na linha de comando. Os comandos para executar trabalhos Slurm são srun e sbatch. O srun comando executa o trabalho de treinamento em modo interativo e de bloqueio, e sbatch é executado em processamento em lote e modo sem bloqueio. srun é usado principalmente para executar trabalhos imediatos, enquanto sbatch pode ser usado para execuções posteriores de trabalhos.
Para obter informações sobre comandos e configurações adicionais do Slurm, consulte o Documentação do Slurm Workload Manager.
Recursos de retomada automática e cura
Um dos novos recursos do SageMaker HyperPod é a capacidade de retomar automaticamente seus trabalhos. Anteriormente, quando um nó de trabalho falhava durante a execução de um trabalho de treinamento ou ajuste fino, cabia ao usuário verificar o status do trabalho, reiniciar o trabalho a partir do ponto de verificação mais recente e continuar monitorando o trabalho durante toda a execução. Com trabalhos de treinamento ou trabalhos de ajuste fino que precisam ser executados por dias, semanas ou até meses seguidos, isso se torna caro devido à sobrecarga administrativa extra do usuário que precisa gastar ciclos para monitorar e manter o trabalho no caso de um falhas de nó, bem como o custo do tempo ocioso de instâncias caras de computação acelerada.
O SageMaker HyperPod aborda a resiliência do trabalho usando verificações de integridade automatizadas, substituição de nós e recuperação de trabalho. Os trabalhos Slurm no SageMaker HyperPod são monitorados usando um plug-in Slurm personalizado do SageMaker usando o Estrutura SPANK. Quando um trabalho de treinamento falha, o SageMaker HyperPod inspeciona a integridade do cluster por meio de um conjunto de verificações de integridade. Se um nó com defeito for encontrado no cluster, o SageMaker HyperPod removerá automaticamente o nó do cluster, substituirá-o por um nó íntegro e reiniciará o trabalho de treinamento. Ao usar o ponto de verificação em trabalhos de treinamento, qualquer trabalho interrompido ou com falha pode ser retomado a partir do ponto de verificação mais recente.
Visão geral da solução
Para implantar seu SageMaker HyperPod, primeiro prepare seu ambiente configurando seu Nuvem virtual privada da Amazon (Amazon VPC) e grupos de segurança, implantando serviços de suporte como FSx for Lustre em sua VPC e publicando seus scripts de ciclo de vida Slurm em um bucket S3. Em seguida, você implanta e configura seu SageMaker HyperPod e se conecta ao nó principal para iniciar seus trabalhos de treinamento.
Pré-requisitos
Antes de criar seu SageMaker HyperPod, primeiro você precisa configurar seu VPC, criar um sistema de arquivos FSx for Lustre e estabelecer um bucket S3 com os scripts de ciclo de vida do cluster desejados. Você também precisa da versão mais recente do Interface de linha de comando da AWS (AWS CLI) e o plugin CLI instalado para Gerenciador de sessões da AWS, uma capacidade de Gerente de Sistemas AWS.
O SageMaker HyperPod está totalmente integrado ao seu VPC. Para obter informações sobre como criar uma nova VPC, consulte Crie uma VPC padrão or Criar uma VPC. Para permitir uma conexão perfeita com o mais alto desempenho entre recursos, você deve criar todos os seus recursos na mesma região e zona de disponibilidade, bem como garantir que as regras do grupo de segurança associadas permitam a conexão entre recursos de cluster.
Em seguida, você crie um sistema de arquivos FSx for Lustre. Isso servirá como sistema de arquivos de alto desempenho para uso durante todo o treinamento do modelo. Certifique-se de que o FSx for Lustre e os grupos de segurança do cluster permitam a comunicação de entrada e saída entre os recursos do cluster e o sistema de arquivos FSx for Lustre.
Para configurar os scripts de ciclo de vida do cluster, que são executados quando ocorrem eventos como uma nova instância de cluster, crie um bucket S3 e, em seguida, copie e, opcionalmente, personalize os scripts de ciclo de vida padrão. Neste exemplo, armazenamos todos os scripts de ciclo de vida em um prefixo de bucket de lifecycle-scripts.
Primeiro, você faz download dos scripts de ciclo de vida de amostra do GitHub repo. Você deve personalizá-los para se adequar aos comportamentos de cluster desejados.
Em seguida, crie um bucket S3 para armazenar os scripts de ciclo de vida personalizados.
Em seguida, copie os scripts de ciclo de vida padrão do diretório local para o bucket e o prefixo desejados usando aws s3 sync:
Finalmente, para configurar o cliente para conexão simplificada ao nó principal do cluster, você deve instalar ou atualizar a AWS CLI e instale o Plug-in CLI do AWS Session Manager para permitir conexões de terminal interativo para administrar o cluster e executar trabalhos de treinamento.
Você pode criar um cluster SageMaker HyperPod com recursos sob demanda disponíveis ou solicitando uma reserva de capacidade com o SageMaker. Para criar uma reserva de capacidade, crie uma solicitação de aumento de cota para reservar tipos específicos de instâncias de computação e alocação de capacidade no painel Cotas de Serviço.
Configure seu cluster de treinamento
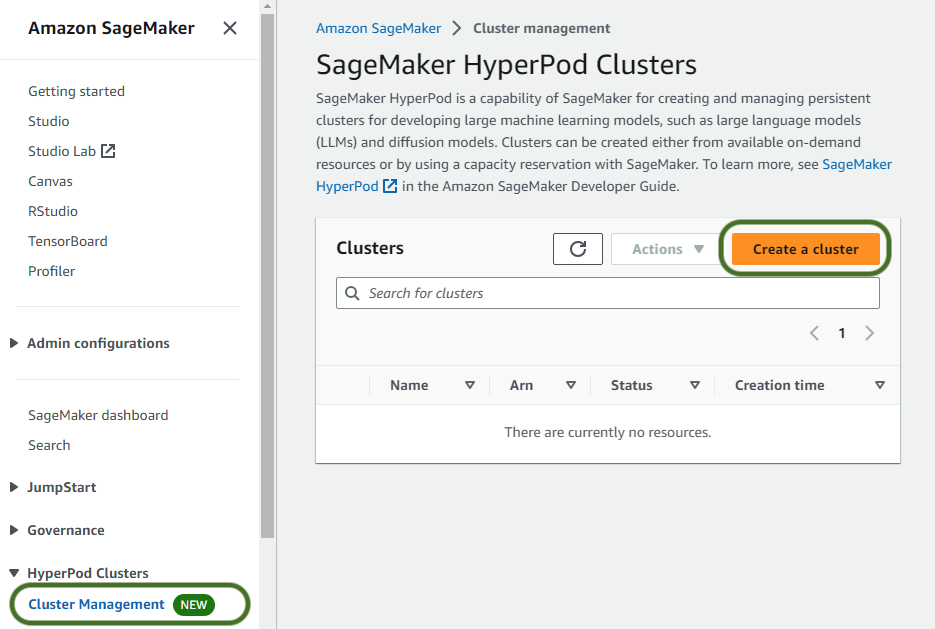
Para criar seu cluster SageMaker HyperPod, conclua as seguintes etapas:
- No console SageMaker, escolha Gerenciamento de cluster para Clusters de HyperPod no painel de navegação.
- Escolha Crie um cluster.
- Forneça um nome de cluster e, opcionalmente, quaisquer tags a serem aplicadas aos recursos do cluster e escolha Próximo.
- Selecionar Criar grupo de instâncias e especifique o nome do grupo de instâncias, o tipo de instância necessário, a quantidade de instâncias desejadas e o bucket S3 e o caminho do prefixo onde você copiou os scripts de ciclo de vida do cluster anteriormente.
É recomendado ter diferentes grupos de instâncias para os nós controladores usados para administrar o cluster e enviar trabalhos e os nós de trabalho usados para executar trabalhos de treinamento usando instâncias de computação aceleradas. Opcionalmente, você pode configurar um grupo de instâncias adicional para nós de login.
- Primeiro, você cria o grupo de instâncias do controlador, que incluirá o nó principal do cluster.
- Para este grupo de instâncias Gerenciamento de acesso e identidade da AWS (IAM), escolha Crie uma nova função e especifique quaisquer buckets S3 aos quais você gostaria que as instâncias de cluster no grupo de instâncias tivessem acesso.
A função gerada receberá acesso somente leitura aos buckets especificados por padrão.
- Escolha Criar função.
- Insira o nome do script a ser executado em cada criação de instância no prompt do script ao criar. Neste exemplo, o script on-create é chamado
on_create.sh.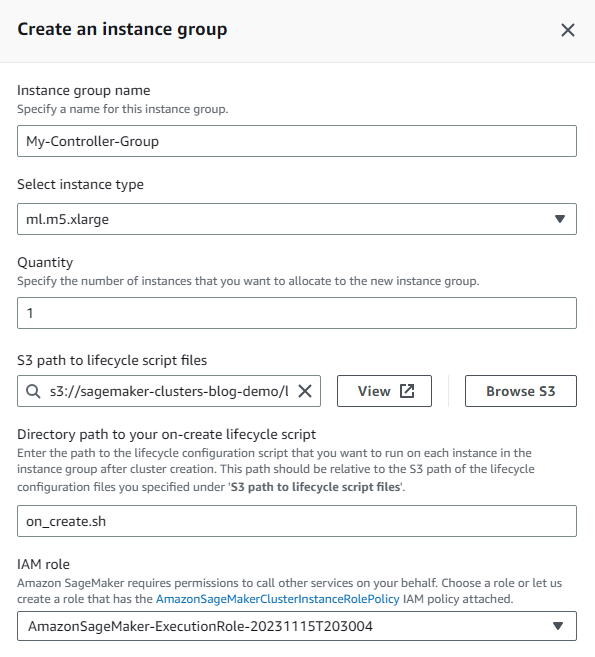
- Escolha Salvar.
- Escolha Criar grupo de instâncias para criar seu grupo de instâncias de trabalho.
- Forneça todos os detalhes solicitados, incluindo tipo de instância e quantidade desejada.
Este exemplo usa quatro instâncias aceleradas ml.trn1.32xl para realizar nosso trabalho de treinamento. Você pode usar a mesma função do IAM de antes ou personalizar a função para as instâncias de trabalho. Da mesma forma, você pode usar scripts de ciclo de vida na criação diferentes para este grupo de instâncias de trabalho do que para o grupo de instâncias anterior.
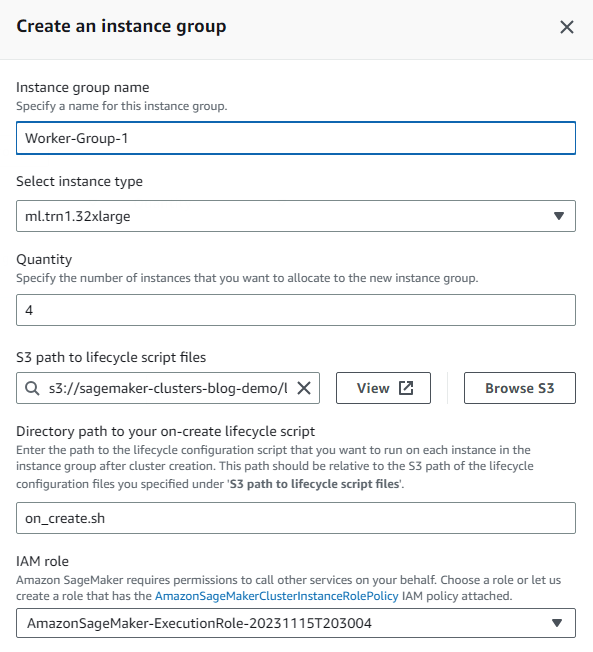
- Escolha Próximo para prosseguir.
- Escolha a VPC, a sub-rede e os grupos de segurança desejados para suas instâncias de cluster.
Hospedamos as instâncias de cluster em uma única zona de disponibilidade e sub-rede para garantir baixa latência.
Observe que se você acessar dados do S3 com frequência, é recomendável criar um VPC endpoint associado à tabela de roteamento da sub-rede privada para reduzir quaisquer custos potenciais de transferência de dados.
- Escolha Próximo.

- Revise o resumo dos detalhes do cluster e escolha Submeter.
Como alternativa, para criar seu SageMaker HyperPod usando a AWS CLI, primeiro personalize os parâmetros JSON usados para criar o cluster:
Em seguida, use o seguinte comando para criar o cluster usando as entradas fornecidas:
Execute seu primeiro trabalho de treinamento com o Llama 2
Observe que o uso do modelo Llama 2 é regido pela licença Meta. Para baixar os pesos do modelo e o tokenizer, visite o site do Network Development Group e aceite a licença antes de solicitar acesso em Site Hugging Face da Meta.
Depois que o cluster estiver em execução, faça login no Session Manager usando o ID do cluster, o nome do grupo de instâncias e o ID da instância. Use o seguinte comando para visualizar os detalhes do seu cluster:
Anote o ID do cluster incluído no ARN do cluster na resposta.
Use o comando a seguir para recuperar o nome do grupo de instâncias e o ID da instância necessários para fazer login no cluster.
Tome nota do InstanceGroupName e os votos de InstanceId na resposta, pois eles serão usados para conectar-se à instância com o Session Manager.
Agora você usa o Session Manager para fazer login no nó principal ou em um dos nós de login e executar seu trabalho de treinamento:
A seguir, vamos preparar o ambiente e baixar o Llama 2 e o conjunto de dados RedPajama. Para obter o código completo e um passo a passo, siga as instruções no Treinamento distribuído incrível Repo do GitHub.
Siga os passos detalhados no 2.test_cases/8.neuronx-nemo-megatron/README.md arquivo. Depois de seguir as etapas para preparar o ambiente, preparar o modelo, baixar e tokenizar o conjunto de dados e pré-compilar o modelo, você deverá editar o arquivo 6.pretrain-model.sh script e o sbatch comando de envio de trabalho para incluir um parâmetro que permitirá que você aproveite o recurso de retomada automática do SageMaker HyperPod.
Edite o sbatch linha para se parecer com o seguinte:
Depois de enviar o trabalho, você receberá um JobID que você pode usar para verificar o status do trabalho usando o seguinte código:
Além disso, você pode monitorar o trabalho seguindo o log de saída do trabalho usando o seguinte código:
limpar
Para excluir seu cluster SageMaker HyperPod, use o console do SageMaker ou o seguinte comando AWS CLI:
Conclusão
Esta postagem mostrou como preparar seu ambiente AWS, implantar seu primeiro cluster SageMaker HyperPod e treinar um modelo Llama 7 de 2 bilhões de parâmetros. O SageMaker HyperPod está disponível hoje nas regiões das Américas (Norte da Virgínia, Ohio e Oregon), Ásia-Pacífico (Singapura, Sydney e Tóquio) e Europa (Frankfurt, Irlanda e Estocolmo). Eles podem ser implantados por meio do console SageMaker, AWS CLI e AWS SDKs e oferecem suporte às famílias de instâncias p4d, p4de, p5, trn1, inf2, g5, c5, c5n, m5 e t3.
Para saber mais sobre o SageMaker HyperPod, visite HyperPod do Amazon SageMaker.
Sobre os autores
 Brad Doran é gerente técnico sênior de contas na Amazon Web Services, com foco em IA generativa. Ele é responsável por resolver desafios de engenharia para clientes de IA generativa no segmento de mercado empresarial digital nativo. Ele tem experiência em infraestrutura e desenvolvimento de software e atualmente está realizando estudos de doutorado e pesquisa em inteligência artificial e aprendizado de máquina.
Brad Doran é gerente técnico sênior de contas na Amazon Web Services, com foco em IA generativa. Ele é responsável por resolver desafios de engenharia para clientes de IA generativa no segmento de mercado empresarial digital nativo. Ele tem experiência em infraestrutura e desenvolvimento de software e atualmente está realizando estudos de doutorado e pesquisa em inteligência artificial e aprendizado de máquina.
 Keita Watanabe é arquiteto de soluções especialista sênior em GenAI na Amazon Web Services, onde ajuda a desenvolver soluções de aprendizado de máquina usando projetos OSS, como Slurm e Kubernetes. Sua formação é em pesquisa e desenvolvimento de aprendizado de máquina. Antes de ingressar na AWS, Keita trabalhou no setor de comércio eletrônico como cientista pesquisador, desenvolvendo sistemas de recuperação de imagens para pesquisa de produtos. Keita possui doutorado em Ciências pela Universidade de Tóquio.
Keita Watanabe é arquiteto de soluções especialista sênior em GenAI na Amazon Web Services, onde ajuda a desenvolver soluções de aprendizado de máquina usando projetos OSS, como Slurm e Kubernetes. Sua formação é em pesquisa e desenvolvimento de aprendizado de máquina. Antes de ingressar na AWS, Keita trabalhou no setor de comércio eletrônico como cientista pesquisador, desenvolvendo sistemas de recuperação de imagens para pesquisa de produtos. Keita possui doutorado em Ciências pela Universidade de Tóquio.
 Justin Pirtle é arquiteto de soluções principal da Amazon Web Services. Ele aconselha regularmente clientes de IA generativa no projeto, implantação e dimensionamento de sua infraestrutura. Ele é palestrante regular em conferências da AWS, incluindo re:Invent, bem como em outros eventos da AWS. Justin é bacharel em Sistemas de Informação Gerencial pela Universidade do Texas em Austin e mestre em Engenharia de Software pela Universidade de Seattle.
Justin Pirtle é arquiteto de soluções principal da Amazon Web Services. Ele aconselha regularmente clientes de IA generativa no projeto, implantação e dimensionamento de sua infraestrutura. Ele é palestrante regular em conferências da AWS, incluindo re:Invent, bem como em outros eventos da AWS. Justin é bacharel em Sistemas de Informação Gerencial pela Universidade do Texas em Austin e mestre em Engenharia de Software pela Universidade de Seattle.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/introducing-amazon-sagemaker-hyperpod-to-train-foundation-models-at-scale/
- :é
- :onde
- $UP
- 1
- 100
- 12
- 14
- 24
- 7
- a
- habilidade
- Sobre
- acelerado
- aceleradores
- ACEITAR
- Acesso
- acessibilidade
- acessando
- Conta
- em
- Adição
- Adicional
- endereços
- administrar
- administrativo
- Vantagem
- Depois de
- AI
- Todos os Produtos
- alocação
- permitir
- permite
- tb
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- Américas
- quantidades
- an
- e
- qualquer
- Aplicar
- arquitetônico
- SOMOS
- surgir
- artificial
- inteligência artificial
- Inteligência Artificial e Aprendizado de Máquinas
- AS
- Ásia
- Ásia-Pacífico
- associado
- At
- austin
- Automatizado
- automaticamente
- disponibilidade
- disponível
- AWS
- fundo
- BE
- torna-se
- antes
- entre
- bilhões
- bloqueio
- construir
- Prédio
- negócio
- by
- chamado
- CAN
- capacidades
- capacidade
- Capacidade
- Chefe executivo
- desafiar
- desafios
- Alterações
- verificar
- Cheques
- Escolha
- cliente
- Agrupar
- código
- Collective
- vem
- Comunicação
- Comunicações
- Empresa
- completar
- componentes
- Computar
- computação
- conferências
- Configuração
- configurando
- Contato
- da conexão
- Coneções
- cônsul
- continuar
- controlador
- Custo
- dispendioso
- custos
- crio
- Criar
- criação
- Atualmente
- personalizadas
- Clientes
- personalizar
- personalizado
- ciclo
- ciclos
- painel de instrumentos
- dados,
- dias
- acordo
- Padrão
- Grau
- implantar
- implantado
- Implantação
- concepção
- desejado
- detalhado
- detalhes
- desenvolver
- em desenvolvimento
- Desenvolvimento
- diferente
- Distribuição
- digital
- Rompimento
- distribuído
- computação distribuída
- treinamento distribuído
- download
- dois
- durante
- cada
- Loja virtual
- ou
- eliminando
- permitir
- Ponto final
- Engenharia
- garantir
- Todo
- Meio Ambiente
- ambiental
- estabelecer
- Éter (ETH)
- Europa
- Mesmo
- Evento
- eventos
- exemplo
- animado
- caro
- extra
- Rosto
- fracassado
- falha
- Falha
- falhas
- famílias
- mais rápido
- defeituoso
- Característica
- Funcionalidades
- Envie o
- Primeiro nome
- focado
- seguir
- seguinte
- Escolha
- Antigamente
- encontrado
- Foundation
- fundador
- Fundadora e CEO
- quatro
- Quadro
- Frankfurt
- freqüente
- freqüentemente
- da
- cheio
- totalmente
- geralmente
- gerado
- generativo
- IA generativa
- ter
- GitHub
- meta
- vai
- governado
- concedido
- Grupo
- Do grupo
- manipular
- Hardware
- Ter
- ter
- he
- cabeça
- cura
- Saúde
- saudável
- pesado
- levantamento pesado
- ajuda
- Alta
- Computação de Alto Desempenho
- de alto nível
- alta performance
- mais
- altamente
- sua
- detém
- hospedeiro
- Como funciona o dobrador de carta de canal
- Como Negociar
- hpc
- HTML
- http
- HTTPS
- Centenas
- IAM
- ID
- Identidade
- inativo
- if
- imagem
- Imediato
- executar
- melhorar
- in
- incluir
- incluído
- Incluindo
- Crescimento
- indústria
- INFORMAÇÕES
- Sistemas de Informação
- Infraestrutura
- inputs
- instalar
- instância
- instâncias
- instruções
- integrado
- Integra-se
- Inteligência
- interagir
- interativo
- Interface
- interrompido
- para dentro
- introduzindo
- envolvido
- Irlanda
- questões
- IT
- Trabalho
- Empregos
- juntando
- jpg
- json
- Justin
- conhecido
- Kubernetes
- grande
- em grande escala
- Latência
- mais tarde
- mais recente
- principal
- APRENDER
- aprendizagem
- bibliotecas
- Biblioteca
- Licença
- wifecycwe
- facelift
- como
- Line
- linux
- lhama
- local
- log
- entrar
- olhar
- parece
- perder
- Baixo
- máquina
- aprendizado de máquina
- a manter
- manutenção
- fazer
- FAZ
- Fazendo
- gerenciados
- de grupos
- Sistema de gestão
- Gerente
- mercado
- mestre
- Importância
- Maximizar
- Meta
- minutos
- ML
- Moda
- modelo
- modelos
- EQUIPAMENTOS
- Monitore
- monitorados
- monitoração
- mês
- mais
- na maioria das vezes
- nome
- nativo
- Navegação
- você merece...
- necessário
- necessitando
- rede
- Novo
- Novos Recursos
- nó
- nós
- nota
- agora
- Nvidia
- ocorrer
- of
- Ohio
- on
- Sob demanda
- ONE
- aberto
- open source
- operando
- operacional
- otimização
- otimizando
- or
- orquestração
- Oregon
- Oss
- Outros
- A Nossa
- saída
- Acima de
- Pacífico
- pão
- Paralelo
- parâmetro
- parâmetros
- Passagem
- caminho
- realizar
- atuação
- phd
- platão
- Inteligência de Dados Platão
- PlatãoData
- plug-in
- Popular
- Publique
- potencial
- Preparar
- anterior
- anteriormente
- Diretor
- Prévio
- privado
- Proactive
- prosseguir
- em processamento
- Produto
- Progresso
- projetos
- fornecido
- fornece
- fornecendo
- Publishing
- perseguindo
- quantidade
- RE
- Recomenda
- recuperação
- reduzir
- referir
- região
- regiões
- regular
- regularmente
- remover
- reparar
- substituir
- substituição
- solicitar
- solicitadas
- requerer
- exige
- pesquisa
- pesquisa e desenvolvimento
- reserva
- Reservar
- resiliente
- recurso
- Recursos
- resposta
- responsável
- currículo
- Tipo
- roteamento
- regras
- Execute
- corrida
- é executado
- sábio
- mesmo
- Salvar
- Escala
- dimensionamento
- Ciência
- Cientista
- escrita
- Scripts
- SDK
- desatado
- Pesquisar
- Seattle
- segurança
- Vejo
- segmento
- senior
- servir
- serviço
- Serviços
- Sessão
- conjunto
- Partilhar
- rede de apoio social
- mostrou
- Similarmente
- simples
- simplificada
- Singapore
- solteiro
- menor
- Software
- desenvolvimento de software
- Engenharia de software
- Soluções
- Resolvendo
- fonte
- Palestrantes
- especialista
- específico
- especificada
- gastar
- divisão
- Estabilidade
- estável
- padrões
- começo
- estado-da-arte
- Status
- Passos
- armazenamento
- loja
- franco
- caso
- submissão
- enviar
- apresentado
- sub-rede
- tal
- terno
- suíte
- RESUMO
- ajuda
- Apoiar
- certo
- sydney
- sincronizar.
- .
- sistemas
- mesa
- Tire
- Dados Técnicos:
- dezenas
- terminal
- texas
- do que
- que
- A
- deles
- Eles
- então
- Este
- deles
- isto
- milhares
- Através da
- todo
- tempo
- para
- hoje
- tokenize
- Tóquio
- Trem
- Training
- transferência
- tipo
- tipos
- para
- universidade
- Universidade de Tóquio
- Atualizar
- usar
- usava
- Utilizador
- usuários
- usos
- utilização
- utilidade
- Utilizando
- vário
- Grande
- versão
- via
- Ver
- Virgínia
- Virtual
- Visite a
- Passo a passo
- foi
- Caminho..
- we
- web
- serviços web
- semanas
- BEM
- quando
- qual
- enquanto
- largamente
- Wikipedia
- precisarão
- de
- dentro
- sem
- trabalhou
- trabalhador
- seria
- Você
- investimentos
- zefirnet